
[讀論文]語言視覺多模態(tài)預(yù)訓(xùn)練模型 ViLBERT
論文地址:https://arxiv.org/abs/1908.02265
代碼實(shí)現(xiàn):https://github.com/facebookresearch/vilbert-multi-task
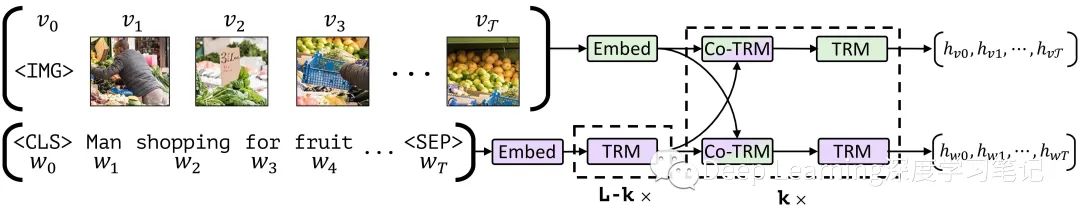 圖1.ViLBERT 模型由視覺(綠色)和語言(紫色) 組成,它們通過 co-attentional transformer layer 進(jìn)行互動。這種結(jié)構(gòu)允許每種模式有不同的深度,并通過共同注意力實(shí)現(xiàn)稀疏的互動。帶有乘數(shù)下標(biāo)的虛線框表示重復(fù)的塊。
圖1.ViLBERT 模型由視覺(綠色)和語言(紫色) 組成,它們通過 co-attentional transformer layer 進(jìn)行互動。這種結(jié)構(gòu)允許每種模式有不同的深度,并通過共同注意力實(shí)現(xiàn)稀疏的互動。帶有乘數(shù)下標(biāo)的虛線框表示重復(fù)的塊。
1. Introduction
針對視覺和語言任務(wù)的預(yù)訓(xùn)練 + 遷移學(xué)習(xí)( pretrain-then-transfer )方法被廣泛用于計算機(jī)視覺和自然語言處理,因為在大規(guī)模數(shù)據(jù)源上訓(xùn)練的大型、公開可用的模型的易用性和強(qiáng)大表現(xiàn)能力,它們已成為事實(shí)上的標(biāo)準(zhǔn)。在這些領(lǐng)域,預(yù)訓(xùn)練的模型可以為目標(biāo)任務(wù)提供有用的信息。為此,作者開發(fā)一個通用的視覺基礎(chǔ)模型,該模型可以學(xué)習(xí)這些聯(lián)系并在廣泛的視覺和語言任務(wù)中運(yùn)用(即尋求對視覺基礎(chǔ)的預(yù)訓(xùn)練模型)。
為了學(xué)習(xí)這些聯(lián)合視覺語言表示,作者希望在自監(jiān)督學(xué)習(xí)取得成功,這些成功通過訓(xùn)練模型執(zhí)行“代理”任務(wù),從大型未標(biāo)記的數(shù)據(jù)源中捕獲了豐富的語義和結(jié)構(gòu)信息。這些代理任務(wù)利用結(jié)構(gòu)在數(shù)據(jù)中自動生成監(jiān)督任務(wù)(例如著色圖像或重建文本中的掩碼詞 )。雖然計算機(jī)視覺社區(qū)內(nèi)的工作展現(xiàn)出越來越大的前景,但迄今為止,自監(jiān)督學(xué)習(xí)的最大影響是通過 ELMo 、BERT 和 GPT 等語言模型,這些模型已經(jīng)在許多 NLP 任務(wù)上創(chuàng)造了新的上限。要通過類似的方法學(xué)習(xí)視覺基礎(chǔ),必須確定一個合適的數(shù)據(jù)源,其中視覺和語言之間可以保持一致。在這項工作中,作者選用了最近發(fā)布的 Conceptual Captions 數(shù)據(jù)集,該數(shù)據(jù)集由約 330 萬幅圖像組成,為網(wǎng)絡(luò)上支持 alt-text 的圖片和其弱關(guān)聯(lián)描述性標(biāo)題。
作者提出了一個聯(lián)合模型,用于從成對的視覺語言數(shù)據(jù)中學(xué)習(xí)與任務(wù)無關(guān)的視覺基礎(chǔ),作者稱為 Vision & Language BERT(簡稱 ViLBERT )。該方法擴(kuò)展了最近開發(fā)的 BERT 語言模型,以聯(lián)合推理文本和圖像。關(guān)鍵技術(shù)創(chuàng)新是為視覺和語言處理引入單獨(dú)的流,通過共同注意的 Transformer 層(co-attentional transformer layers)進(jìn)行通信。這種結(jié)構(gòu)可以適應(yīng)每種模態(tài)的不同處理需求,并提供不同表示深度的模態(tài)之間的交互。在實(shí)驗中證明了這種結(jié)構(gòu)優(yōu)于單流統(tǒng)一模型。
類似于 BERT 中的訓(xùn)練任務(wù),訓(xùn)練的兩個代理任務(wù)上:在給定未屏蔽輸入的情況下預(yù)測屏蔽詞和圖像區(qū)域的語義,以及預(yù)測圖像和文本段是否對應(yīng)。作者將預(yù)訓(xùn)練模型作為四個既定的視覺和語言基礎(chǔ)任務(wù)( visual question answering , visualcommonsense reasoning, referring expressions, caption-based image retrieval)四項任務(wù)均達(dá)到 SOTA 。與使用單獨(dú)的預(yù)訓(xùn)練視覺和語言模型的任務(wù)特定基線相比這些任務(wù)提高了 2 到 10 個百分點(diǎn)。此外,該結(jié)構(gòu)很容易針對這些任務(wù)進(jìn)行修改——作為跨多個視覺和語言任務(wù)的視覺基礎(chǔ)的共同基礎(chǔ)。
2. Approach
在這一節(jié)中,首先簡要地總結(jié)了BERT語言模型,然后描述了作者如何擴(kuò)展它以聯(lián)合表示視覺和語言數(shù)據(jù)
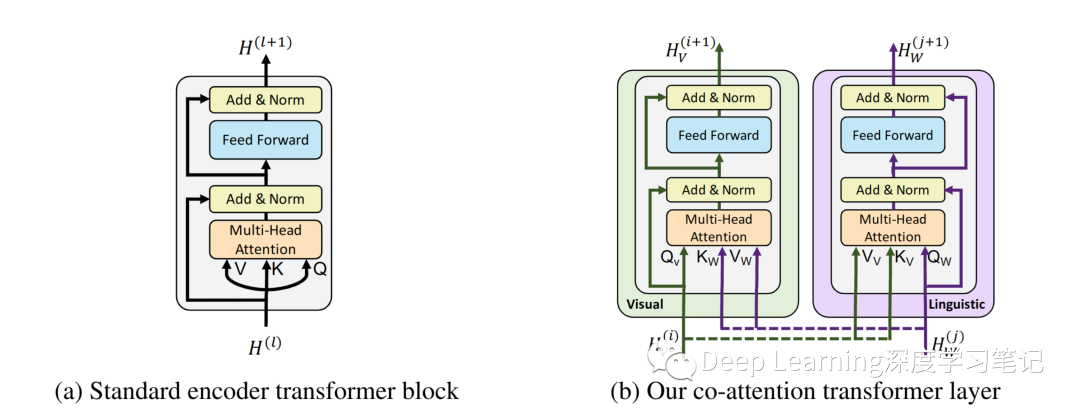 圖2.基于 transformer 架構(gòu)的 co-attention 機(jī)制。通過在多頭注意力中交換鍵值對,這種結(jié)構(gòu)使視覺參與的語言特征能夠被納入視覺表示中(反之亦然)
圖2.基于 transformer 架構(gòu)的 co-attention 機(jī)制。通過在多頭注意力中交換鍵值對,這種結(jié)構(gòu)使視覺參與的語言特征能夠被納入視覺表示中(反之亦然)
2.1 ?Preliminaries: Bidirectional Encoder Representations from Transformers (BERT)
BERT 模型是一個基于注意力的雙向語言模型。當(dāng)在大型語言語料庫上進(jìn)行訓(xùn)練時,BERT 已被證明對多種自然語言處理任務(wù)的遷移學(xué)習(xí)非常有效。
BERT 模型對 Word Token 序列 進(jìn)行操作,這些 Token 被映射到學(xué)習(xí)的編碼上并通過 “encoder-style” transformer blocks 以產(chǎn)生最終表示: 。設(shè) 是一個矩陣,其中第 行 對應(yīng)于第 層之后的中間表示。提取論文( Attention is all you need ) 中發(fā)現(xiàn)的一些內(nèi)部細(xì)節(jié),圖 2a 中 single encoder-style transformer block 的計算,該塊由一個 multi-headed attention block 和一個小的全連接網(wǎng)絡(luò)組成,兩者都包裹在殘差中。該中間層的表示 ?用于計算三個度量—— Q、K 和 V(對應(yīng)于 ?multi-headed attention bloc 的 queries, keys, ?values )。具體來說,queries 和 keys 之間的點(diǎn)積相似度(dot-product similarity )決定了 values 向量上的注意力分布(attentional distributions over value vectors)。得到的權(quán)重平均值向量構(gòu)成了注意力塊的輸出。作者修改了這個以 query 為條件的鍵值注意機(jī)制,為 ViLBERT 開發(fā)了一個多模態(tài)協(xié)同注意轉(zhuǎn)換器模塊( multi-modal co-attentional transformer module )
Text Representation:BERT 對由詞匯詞和一小組特殊標(biāo)記(SEP、CLS 和 MASK)組成的離散標(biāo)記序列進(jìn)行操作。對于給定的 Token ,輸入表示a sum of a token-specific learned embedding 以及 encodings for position(句子中符號的索引) 和 segment(如果存在多個,就標(biāo)記符號句子的索引,the index of the token's sentence)。 Training Tasks and Objectives:BERT 模型在大型語言語料庫上進(jìn)行端到端的訓(xùn)練,有兩個任務(wù):masked language modelling 以及 next sentence prediction。 masked language modelling 任務(wù):隨機(jī)將輸入標(biāo)記分成不相交的集合,對應(yīng)于 Mask Token: 和 Observed Token: (大約 15% 的 Token 被 Mask)。對于 Mask Token :80% 的情況下會被特殊的 MASK 標(biāo)記替換,10% 是隨機(jī)單詞,10% 是未更改的。然后訓(xùn)練 BERT 模型以在給定 Observed Token 的情況下預(yù)測這些 Mask Token 。具體而言,線性層將每個索引(例如:)的最終表示映射到詞匯表的分布上,模型在交叉熵?fù)p失下訓(xùn)練。 next sentence prediction 任務(wù):BERT 模型按照格式 ? ?傳遞兩個文本段 A 和 B。并被訓(xùn)練來預(yù)測原文本中的 B 是否跟隨 A。具體來說,在 CLS token(即 )的最終表示的線性層上訓(xùn)練,以最小化此標(biāo)簽上的二元交叉熵?fù)p失
2.2 ?ViLBERT: Extending BERT to Jointly Represent Images and Text
受 BERT 在語言建模方面的成功啟發(fā),作者希望開發(fā)類似的模型和訓(xùn)練任務(wù),從成對的數(shù)據(jù)中學(xué)習(xí)語言和視覺內(nèi)容的聯(lián)合表示。
一種直接的方法是對 BERT 做最小的改動--從預(yù)先訓(xùn)練的 BERT 模型開始,通過聚類簡單地將視覺輸入的空間離散化,將這些視覺 "Token"與文本輸入完全一樣。但這種結(jié)構(gòu)有一些缺點(diǎn)。首先,**初始聚類可能會導(dǎo)致離散化錯誤,并失去重要的視覺細(xì)節(jié)。**其次,它對來自兩種模式的輸入進(jìn)行了相同的處理,忽略了它們可能需要不同語義層次的處理,這是因為它們固有的復(fù)雜性或其輸入表示的初始抽象層次。例如,圖像區(qū)域可能比句子中的單詞有更弱的關(guān)系,而視覺特征本身往往已經(jīng)是一個非常深入的網(wǎng)絡(luò)的輸出。最后,強(qiáng)迫預(yù)訓(xùn)練的權(quán)重去適應(yīng)大量的額外的視覺 "Token" 可能會損害的 BERT 語言模型。相反,作者開發(fā)了一個雙流架構(gòu),分別對每種模式進(jìn)行建模,并通過一小套基于注意力的互動來融合它們。這種方法允許每個模態(tài)的網(wǎng)絡(luò)深度不同,并使不同深度的跨模態(tài)連接成為可能。
ViLBERT 的模型如圖 1 所示,由兩個并行的 BERT 式模型組成,這些模型在圖像區(qū)域和文本段上運(yùn)行。每個流都是一系列 transformer blocks (TRM) 和作者新提出的 co-attentional transformer layers (Co-TRM),引入它們以實(shí)現(xiàn)模式之間的信息交換。給定一個圖像 ,表示為一組區(qū)域特征 和一個文本輸入 , 模型輸出最終表示為 和 。但兩個流之間的交換僅限于特定的層并且在與視覺特征互動之前,文本流有更多的處理,這與直覺相吻合,即視覺特征已經(jīng)十分具體,即與句子中的單詞相比,需要有限的上下文匯總。
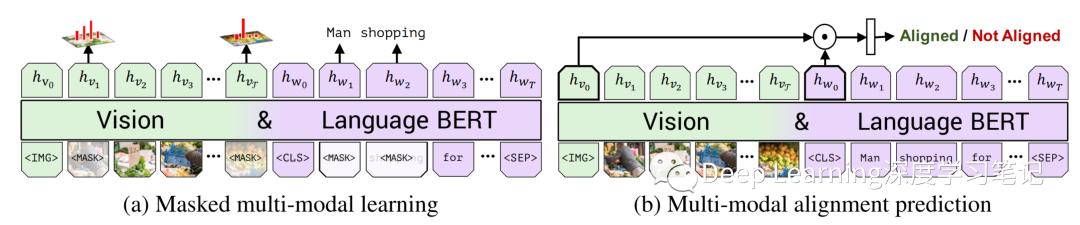 圖 3. 在兩個訓(xùn)練任務(wù)下,在 Conceptual Captions 數(shù)據(jù)集上訓(xùn)練 ViLBERT 以學(xué)習(xí)視覺基礎(chǔ)。在 masked multi-modal learning 中,模型必須根據(jù)觀察到的輸入為 Mask 輸入重建圖像區(qū)域類別或單詞。在 multi-modal alignment prediction 中,該模型必須預(yù)測標(biāo)題是否描述了圖像內(nèi)容。
圖 3. 在兩個訓(xùn)練任務(wù)下,在 Conceptual Captions 數(shù)據(jù)集上訓(xùn)練 ViLBERT 以學(xué)習(xí)視覺基礎(chǔ)。在 masked multi-modal learning 中,模型必須根據(jù)觀察到的輸入為 Mask 輸入重建圖像區(qū)域類別或單詞。在 multi-modal alignment prediction 中,該模型必須預(yù)測標(biāo)題是否描述了圖像內(nèi)容。
Co-Attentional Transformer Layers
給定中間視覺和語言表示 和 ,該模塊像在標(biāo)準(zhǔn)轉(zhuǎn)換器塊中一樣計算query, key, 和 value 矩陣。然而,來自每個模態(tài)的 keys 和 values 作為輸入傳遞到另一個模態(tài)的 ?multi-headed attention block 。因此,attention block 為以另一個為條件的每個模態(tài)產(chǎn)生 attention-pooled features——實(shí)際上在視覺流中執(zhí)行圖像條件語言 attention,在語言流中執(zhí)行語言條件圖像 attention。后者模仿在視覺和語言模型中發(fā)現(xiàn)的常見注意力機(jī)制。Transformer 塊的其余部分與之前一樣進(jìn)行,包括與初始表示的殘差產(chǎn)生多模態(tài)特征。一般來說,視覺和語言的共同注意不是一個新想法并且類似的工作已經(jīng)證明了類似的 co-attentional transformer 結(jié)構(gòu)在視覺問答(VQA)任務(wù)中的有效性。
Image Representations:作者通過從預(yù)訓(xùn)練的目標(biāo)檢測網(wǎng)絡(luò)中提取邊界框及其視覺特征來生成圖像區(qū)域特征。與文本中的單詞不同,圖像區(qū)域缺乏自然排序。作者改為編碼空間位置,從區(qū)域位置(標(biāo)準(zhǔn)化的左上角和右下角坐標(biāo))和覆蓋的圖像區(qū)域的比例構(gòu)建一個 5 維向量。然后將其投影以匹配視覺特征的維度并將它們相加。作者用代表整個圖像的特殊 IMG token 標(biāo)記圖像區(qū)域序列的開始(即具有對應(yīng)于整個圖像的空間編碼的平均池化視覺特征) Training Tasks and Objectives:與上一節(jié)描述的相似,作者考慮了兩個預(yù)訓(xùn)練任務(wù):masked language modelling 以及 next sentence prediction。 masked language modelling(如圖 3a 所示):遵循標(biāo)準(zhǔn) BERT 中的 masked language modelling ——標(biāo)記 Mask 大約為 15% 的單詞和圖像區(qū)域輸入,并在給定剩余輸入的情況下對模型進(jìn)行重構(gòu)。對于標(biāo)記 Mask 的圖像區(qū)域的圖像特征在 90% 的情況下被歸零,10% 的情況下未改變。掩碼文本輸入的處理方式與 BERT 相同。該模型不是直接回歸掩蔽特征值,而是預(yù)測相應(yīng)圖像區(qū)域的語義類分布。為了對此進(jìn)行監(jiān)督,作者從特征提取中使用的相同預(yù)訓(xùn)練檢測模型中獲取該區(qū)域的輸出分布。作者訓(xùn)練模型以最小化這兩個分布之間的 KL 散度。這個選擇反映了這樣一種觀念,即語言通常只識別視覺內(nèi)容的高級語義,不太可能重建準(zhǔn)確的圖像特征。此外,應(yīng)用回歸損失可能難以平衡由標(biāo)記 Mask 的圖像區(qū)域和文本輸入引起的損失。 multi-modal alignment task (如圖 3b 所示):模型以圖像-文本對的形式呈現(xiàn)為 并且預(yù)測圖像和文本是否對齊,即文本是否描述了圖像。我們將輸出 和 作為視覺和語言輸入的整體表示。借用視覺和語言模型的另一種常見結(jié)構(gòu),作者將整體表示計算為 和 之間的元素乘積,并學(xué)習(xí)一個線性層來進(jìn)行二值預(yù)測圖像和文本是否對齊。然而,Conceptual Captions 數(shù)據(jù)集僅包含對齊的圖像-字幕對。為了生成圖像-字幕對的反例,作者隨機(jī)用另一個圖像或字幕替換。
3. ?Experimental Settings
3.1 ?Training ViLBERT
為了訓(xùn)練完整的 ViLBERT 模型,作者應(yīng)用了第 2.2 節(jié)中介紹的訓(xùn)練任務(wù)。Conceptual Captions是一個由330萬個圖像-標(biāo)題對組成的集合,自動地從支持 alt-text 的網(wǎng)絡(luò)圖像中爬取。自動收集和清理過程會留下一些噪音,“captions”有時候不符合人類正常表達(dá)或缺乏細(xì)節(jié)(例如“演員參加電影節(jié)的首映式”)。然而,它呈現(xiàn)了巨大的視覺內(nèi)容多樣性,并作為目的的數(shù)據(jù)集。由于在作者下載數(shù)據(jù)時某些鏈接已損壞,因此模型使用了大約 310 萬個圖像字幕對進(jìn)行了訓(xùn)練。
實(shí)現(xiàn)細(xì)節(jié):作者使用在 BookCorpus 和英文維基百科上預(yù)訓(xùn)練的 BERT 語言模型作為初始化 ViLBERT 模型的 linguistic stream。具體來說,作者使用 模型,它有 12 層 transformer blocks,每個塊的隱藏狀態(tài)大小為 762 和 12 個 attention heads。由于擔(dān)心過度訓(xùn)練時間,作者選擇使用 BASE 模型,但發(fā)現(xiàn)更強(qiáng)大的 模型可能會進(jìn)一步提高性能。作者使用在 Visual Genomedataset 上預(yù)訓(xùn)練的 Faster R-CNN(使用 ResNet-101 為主干網(wǎng)絡(luò))提取區(qū)域特征。作者選擇分類檢測概率超過置信閾值的區(qū)域,并保持 10 到 36 個高閾值框。對于每個選定的區(qū)域 , 定義為來自該區(qū)域的平均池化卷積特征。視覺流中的 Transformer 和 co-attentional Transformer 塊的隱藏狀態(tài)大小為 1024 和 8 個 attention heads 。作者在 8 個 Titan X GPU 上訓(xùn)練,總批大小為 512 為 10 個時期。并使用 Adam 優(yōu)化器,初始學(xué)習(xí)率為 1e-4。作者使用預(yù)熱線性衰減學(xué)習(xí)率方法來訓(xùn)練模型。兩個訓(xùn)練任務(wù)損失的權(quán)重相等
 圖4:作者在實(shí)驗中把 ViLBERT 轉(zhuǎn)換為到視覺和語言任務(wù)
圖4:作者在實(shí)驗中把 ViLBERT 轉(zhuǎn)換為到視覺和語言任務(wù)
3.2 ?Vision-and-Language Transfer Tasks
作者將預(yù)訓(xùn)練的 ViLBERT 模型轉(zhuǎn)移到一組四個既定的視覺和語言任務(wù)(參見圖 4 中的示例)和一個診斷任務(wù)。作者遵循微調(diào)策略(fine-tuning strategy),修改預(yù)訓(xùn)練的基礎(chǔ)模型以執(zhí)行新任務(wù),然后端到端地訓(xùn)練整個模型。在所有情況下,修改都是十分微小的——通常相當(dāng)于學(xué)習(xí)一個分類層。這與社區(qū)內(nèi)為這些任務(wù)中的每一項都專門設(shè)計模型所做的重大努力形成鮮明對比。下面描述了每個任務(wù)的問題、數(shù)據(jù)集、模型修改和訓(xùn)練目標(biāo)。
Visual Question Answering (VQA):VQA 任務(wù)需要回答有關(guān)圖像的自然語言問題。作者對 VQA 2.0 數(shù)據(jù)集進(jìn)行訓(xùn)練和評估,該數(shù)據(jù)集包含 110 萬個關(guān)于 COCO 圖像的問題,每個問題有 10 個答案。為了在 VQA 上fine-tune ViLBERT,作者在圖像和文本表示的元素乘積 和 之上學(xué)習(xí)了一個兩層 MLP,將此表示映射到 3,129 個可能的答案。作者將 VQA 視為多標(biāo)簽分類任務(wù)——根據(jù)每個答案與 10 個人類答案的相關(guān)性,為每個答案分配一個軟目標(biāo)分?jǐn)?shù)。然后,作者在最多 20 個 epoch 內(nèi)使用 256 的 batch size 對軟目標(biāo)分?jǐn)?shù)進(jìn)行二元交叉熵?fù)p失訓(xùn)練。作者使用初始學(xué)習(xí)率為 4e-5 的 Adam 優(yōu)化器。在推理時簡單地取一個 softmax 進(jìn)行歸一化。 Visual Commonsense Reasoning (VCR):給定一張圖像,VCR 任務(wù)提出了兩個問題——視覺問答()和答案證明()——兩者都是多項選擇題。整體設(shè)置()要求選擇的答案和選擇的基本原理都是正確的。VCR 數(shù)據(jù)集由 290k 多選 QA 問題由 110k 電影場景衍生。與 VQA 數(shù)據(jù)集不同,VCR 將目標(biāo)標(biāo)簽集成到語言中,提供直接的基礎(chǔ)監(jiān)督并明確排除了指代表達(dá)。為了對這個任務(wù)進(jìn)行 fine-tuning,作者將問題和每個可能的響應(yīng)連接起來,形成四個不同的文本輸入,并將每個輸入與圖像一起通過 ViLBERT。學(xué)習(xí)一個線性層來預(yù)測每一對的分?jǐn)?shù)。最終預(yù)測是對這四個分?jǐn)?shù)的 softmax,并交叉熵?fù)p失下訓(xùn)練,20 個 epoch 且批量大小為 64,初始學(xué)習(xí)率為 2e-5。 Grounding Referring Expressions:根據(jù)自然語言參考對圖像區(qū)域進(jìn)行定位。作者對 RefCOCO+ 數(shù)據(jù)集進(jìn)行訓(xùn)練和評估。該任務(wù)的一種常見方法是根據(jù)給定參考的一組圖像區(qū)域建議進(jìn)行排序。作者使用在 COCO 數(shù)據(jù)集上預(yù)訓(xùn)練的 Mask R-CNN 。對于 fine-tuning,作者將每個圖像區(qū)域的最終表示 傳遞到學(xué)習(xí)的線性層中以預(yù)測匹配分?jǐn)?shù)。作者通過計算 IoU 并將閾值設(shè)置為 0.5 來標(biāo)記每個預(yù)測框。使用二元交叉熵?fù)p失訓(xùn)練,epoch 為 20 ,批量大小為 256,初始學(xué)習(xí)率為 4e-5。在推理時,作者使用得分最高的區(qū)域作為預(yù)測值。 Caption-Based Image Retrieval:基于標(biāo)題的圖像檢索是指從給定的描述其內(nèi)容的標(biāo)題中識別圖像的任務(wù)。作者在 Flickr30k 數(shù)據(jù)集上進(jìn)行訓(xùn)練和評估,該數(shù)據(jù)集由來自 Flickr 的 31,000 張圖片組成,每張圖片有五個標(biāo)題。作者使用 1,000 張圖片進(jìn)行驗證和測試,其余的進(jìn)行訓(xùn)練。這些標(biāo)題在視覺內(nèi)容上有很好的基礎(chǔ)和描述性,與自動收集的 Conceptual Caption 數(shù)據(jù)集有質(zhì)的區(qū)別。作者通過對每個圖像-標(biāo)題對隨機(jī)抽取三個干擾因素來訓(xùn)練,即從目標(biāo)圖像鄰近的 100 個對象中隨機(jī)抽取一個標(biāo)題、一個隨機(jī)圖像或一個 hard negative(難分樣本)。計算每個的對齊分?jǐn)?shù)(如對齊預(yù)測的預(yù)訓(xùn)練),并應(yīng)用一個 softmax 。在交叉熵?fù)p失下訓(xùn)練這個模型,以選擇真正的圖像-標(biāo)題對,訓(xùn)練 20 個 epoch ,批次大小為64,初始學(xué)習(xí)率為2-5。在推理過程中,對測試集中的每個標(biāo)題-圖像對進(jìn)行評分,然后進(jìn)行排序。為了提高效率,作者在第一個 Co-TRM 層之前緩存了語言流表示--在融合之前有效地凍結(jié)了語言表示。 ‘Zero-shot’ Caption-Based Image Retrieval:前面的任務(wù)都是包括特定 fine-tuning 的轉(zhuǎn)移任務(wù)。在這個 "Zero-shot "任務(wù)中,作者直接將預(yù)先訓(xùn)練好的多模態(tài)對齊預(yù)測機(jī)制應(yīng)用于 Flickr30k 中基于標(biāo)題的圖像檢索,而沒有進(jìn)行 fine-tuning(因此被描述為 "Zero-shot")。這個任務(wù)的目的是證明預(yù)訓(xùn)練已經(jīng)發(fā)展出了文本定位的能力,而且這可以推廣到視覺和語言的變化,而不需要任何特定的任務(wù) fine-tuning。作者直接使用在第 3.1 節(jié)中描述的 Conceptual Captions 數(shù)據(jù)集上訓(xùn)練的 ViLBERT 模型。使用對齊預(yù)測目標(biāo)作為評分函數(shù),并在與上述 Caption-Based Image Retrieval 相同的分割上進(jìn)行測試
4. ?Results and Analysis
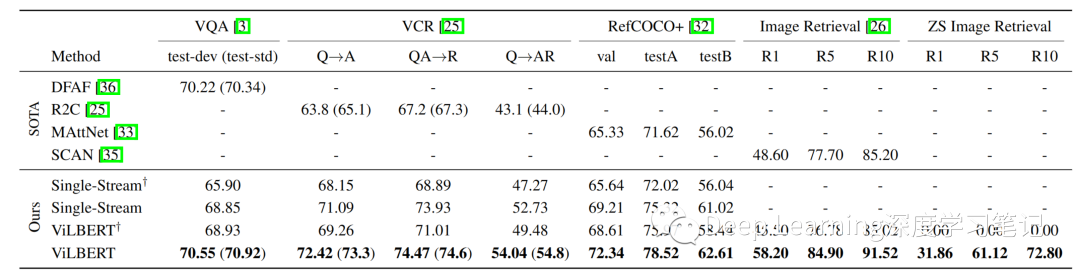 表 1:ViLBERT 模型的傳輸任務(wù)結(jié)果與現(xiàn)有最優(yōu)且合理的架構(gòu)消融相比。? 表示沒有對 Conceptual Captions 進(jìn)行預(yù)訓(xùn)練的模型。對于具有私有測試集的 VCR 和 VQA,作者僅報告完整模型的測試結(jié)果(在括號中)。完整的 ViLBERT 模型在所有任務(wù)中都優(yōu)于特定任務(wù)的最新模型
表 1:ViLBERT 模型的傳輸任務(wù)結(jié)果與現(xiàn)有最優(yōu)且合理的架構(gòu)消融相比。? 表示沒有對 Conceptual Captions 進(jìn)行預(yù)訓(xùn)練的模型。對于具有私有測試集的 VCR 和 VQA,作者僅報告完整模型的測試結(jié)果(在括號中)。完整的 ViLBERT 模型在所有任務(wù)中都優(yōu)于特定任務(wù)的最新模型
 表 2:模型深度與 Co-TRMTRM 塊數(shù)量的消融研究(如圖 1 中的虛線框所示)。作者發(fā)現(xiàn)不同的任務(wù)在不同的網(wǎng)絡(luò)深度上表現(xiàn)更好——這意味著它們可能需要或多或少的上下文聚合
表 2:模型深度與 Co-TRMTRM 塊數(shù)量的消融研究(如圖 1 中的虛線框所示)。作者發(fā)現(xiàn)不同的任務(wù)在不同的網(wǎng)絡(luò)深度上表現(xiàn)更好——這意味著它們可能需要或多或少的上下文聚合
 表3:ViLBERT 的轉(zhuǎn)移任務(wù)結(jié)果與預(yù)訓(xùn)練期間使用 Conceptual Captions 數(shù)據(jù)集的百分比有關(guān)。我們看到,隨著預(yù)訓(xùn)練數(shù)據(jù)集規(guī)模的增長,收益越高。
表3:ViLBERT 的轉(zhuǎn)移任務(wù)結(jié)果與預(yù)訓(xùn)練期間使用 Conceptual Captions 數(shù)據(jù)集的百分比有關(guān)。我們看到,隨著預(yù)訓(xùn)練數(shù)據(jù)集規(guī)模的增長,收益越高。
 圖5:經(jīng)過作者的培訓(xùn)任務(wù),但在特定任務(wù) fine-tuning 之前,ViLBERT 模型圖像采樣描述的定性例子
圖5:經(jīng)過作者的培訓(xùn)任務(wù),但在特定任務(wù) fine-tuning 之前,ViLBERT 模型圖像采樣描述的定性例子