
機(jī)器學(xué)習(xí)算法常用指標(biāo)總結(jié)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
機(jī)器學(xué)習(xí)性能評(píng)價(jià)標(biāo)準(zhǔn)是模型優(yōu)化的前提,在設(shè)計(jì)機(jī)器學(xué)習(xí)算法過(guò)程中,不同的問(wèn)題需要用到不同的評(píng)價(jià)標(biāo)準(zhǔn),本文對(duì)機(jī)器學(xué)習(xí)算法常用指標(biāo)進(jìn)行了總結(jié)。
閱讀目錄
1. TPR、FPR&TNR
2. 精確率Precision、召回率Recall和F1值
3. 綜合評(píng)價(jià)指標(biāo)F-measure
4. ROC曲線和AUC
5. 參考內(nèi)容
考慮一個(gè)二分問(wèn)題,即將實(shí)例分成正類(positive)或負(fù)類(negative)。對(duì)一個(gè)二分問(wèn)題來(lái)說(shuō),會(huì)出現(xiàn)四種情況。如果一個(gè)實(shí)例是正類并且也被 預(yù)測(cè)成正類,即為真正類(True positive),如果實(shí)例是負(fù)類被預(yù)測(cè)成正類,稱之為假正類(False positive)。相應(yīng)地,如果實(shí)例是負(fù)類被預(yù)測(cè)成負(fù)類,稱之為真負(fù)類(True negative),正類被預(yù)測(cè)成負(fù)類則為假負(fù)類(false negative)。
TP:正確肯定的數(shù)目;
FN:漏報(bào),沒(méi)有正確找到的匹配的數(shù)目;
FP:誤報(bào),給出的匹配是不正確的;
TN:正確拒絕的非匹配對(duì)數(shù);
列聯(lián)表如下表所示,1代表正類,0代表負(fù)類:

從列聯(lián)表引入兩個(gè)新名詞。其一是真正類率(true positive rate ,TPR),
計(jì)算公式為
TPR = TP / (TP + FN)
刻畫的是分類器所識(shí)別出的正實(shí)例占所有正實(shí)例的比例。另外一個(gè)是負(fù)正類率(false positive rate, FPR),計(jì)算公式為
FPR = FP / (FP + TN)
計(jì)算的是分類器錯(cuò)認(rèn)為正類的負(fù)實(shí)例占所有負(fù)實(shí)例的比例。還有一個(gè)真負(fù)類率(True Negative Rate,TNR),也稱為specificity,計(jì)算公式為
TNR = TN /(FP + TN) = 1 - FPR
精確率(正確率)和召回率是廣泛用于信息檢索和統(tǒng)計(jì)學(xué)分類領(lǐng)域的兩個(gè)度量值,用來(lái)評(píng)價(jià)結(jié)果的質(zhì)量。其中精度是檢索出相關(guān)文檔數(shù)與檢索出的文檔總數(shù)的比率,衡量的是檢索系統(tǒng)的查準(zhǔn)率;召回率是指檢索出的相關(guān)文檔數(shù)和文檔庫(kù)中所有的相關(guān)文檔數(shù)的比率,衡量的是檢索系統(tǒng)的查全率。
一般來(lái)說(shuō),Precision就是檢索出來(lái)的條目(比如:文檔、網(wǎng)頁(yè)等)有多少是準(zhǔn)確的,Recall就是所有準(zhǔn)確的條目有多少被檢索出來(lái)了,兩者的定義分別如下:
Precision = 提取出的正確信息條數(shù) / 提取出的信息條數(shù)
Recall = 提取出的正確信息條數(shù) / 樣本中的信息條數(shù)
為了能夠評(píng)價(jià)不同算法的優(yōu)劣,在Precision和Recall的基礎(chǔ)上提出了F1值的概念,來(lái)對(duì)Precision和Recall進(jìn)行整體評(píng)價(jià)。F1的定義如下:
F1值 = 正確率 * 召回率 * 2 / (正確率 + 召回率)
不妨舉這樣一個(gè)例子:
某池塘有1400條鯉魚,300只蝦,300只鱉。現(xiàn)在以捕鯉魚為目的。撒一大網(wǎng),逮著了700條鯉魚,200只蝦,100只鱉。那么,這些指標(biāo)分別如下:
正確率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
F1值 = 70% * 50% * 2 / (70% + 50%) = 58.3%
不妨看看如果把池子里的所有的鯉魚、蝦和鱉都一網(wǎng)打盡,這些指標(biāo)又有何變化:
正確率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
F1值 = 70% * 100% * 2 / (70% + 100%) = 82.35%
由此可見(jiàn),正確率是評(píng)估捕獲的成果中目標(biāo)成果所占得比例;召回率,顧名思義,就是從關(guān)注領(lǐng)域中,召回目標(biāo)類別的比例;而F值,則是綜合這二者指標(biāo)的評(píng)估指標(biāo),用于綜合反映整體的指標(biāo)。
當(dāng)然希望檢索結(jié)果Precision越高越好,同時(shí)Recall也越高越好,但事實(shí)上這兩者在某些情況下有矛盾的。比如極端情況下,我們只搜索出了一個(gè)結(jié)果,且是準(zhǔn)確的,那么Precision就是100%,但是Recall就很低;而如果我們把所有結(jié)果都返回,那么比如Recall是100%,但是Precision就會(huì)很低。因此在不同的場(chǎng)合中需要自己判斷希望Precision比較高或是Recall比較高。如果是做實(shí)驗(yàn)研究,可以繪制Precision-Recall曲線來(lái)幫助分析。
Precision和Recall指標(biāo)有時(shí)候會(huì)出現(xiàn)的矛盾的情況,這樣就需要綜合考慮他們,最常見(jiàn)的方法就是F-Measure(又稱為F-Score)。
F-Measure是Precision和Recall加權(quán)調(diào)和平均:
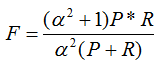
當(dāng)參數(shù)α=1時(shí),就是最常見(jiàn)的F1。因此,F1綜合了P和R的結(jié)果,當(dāng)F1較高時(shí)則能說(shuō)明試驗(yàn)方法比較有效。
4.1 為什么引入ROC曲線?
Motivation1:在一個(gè)二分類模型中,對(duì)于所得到的連續(xù)結(jié)果,假設(shè)已確定一個(gè)閥值,比如說(shuō) 0.6,大于這個(gè)值的實(shí)例劃歸為正類,小于這個(gè)值則劃到負(fù)類中。如果減小閥值,減到0.5,固然能識(shí)別出更多的正類,也就是提高了識(shí)別出的正例占所有正例 的比類,即TPR,但同時(shí)也將更多的負(fù)實(shí)例當(dāng)作了正實(shí)例,即提高了FPR。為了形象化這一變化,引入ROC,ROC曲線可以用于評(píng)價(jià)一個(gè)分類器。
Motivation2:在類不平衡的情況下,如正樣本90個(gè),負(fù)樣本10個(gè),直接把所有樣本分類為正樣本,得到識(shí)別率為90%。但這顯然是沒(méi)有意義的。單純根據(jù)Precision和Recall來(lái)衡量算法的優(yōu)劣已經(jīng)不能表征這種病態(tài)問(wèn)題。
4.2 什么是ROC曲線?
ROC(Receiver Operating Characteristic)翻譯為"接受者操作特性曲線"。曲線由兩個(gè)變量1-specificity 和 Sensitivity繪制. 1-specificity=FPR,即負(fù)正類率。Sensitivity即是真正類率,TPR(True positive rate),反映了正類覆蓋程度。這個(gè)組合以1-specificity對(duì)sensitivity,即是以代價(jià)(costs)對(duì)收益(benefits)。
此外,ROC曲線還可以用來(lái)計(jì)算“均值平均精度”(mean average precision),這是當(dāng)你通過(guò)改變閾值來(lái)選擇最好的結(jié)果時(shí)所得到的平均精度(PPV)。
為了更好地理解ROC曲線,我們使用具體的實(shí)例來(lái)說(shuō)明:
如在醫(yī)學(xué)診斷中,判斷有病的樣本。那么盡量把有病的揪出來(lái)是主要任務(wù),也就是第一個(gè)指標(biāo)TPR,要越高越好。而把沒(méi)病的樣本誤診為有病的,也就是第二個(gè)指標(biāo)FPR,要越低越好。
不難發(fā)現(xiàn),這兩個(gè)指標(biāo)之間是相互制約的。如果某個(gè)醫(yī)生對(duì)于有病的癥狀比較敏感,稍微的小癥狀都判斷為有病,那么他的第一個(gè)指標(biāo)應(yīng)該會(huì)很高,但是第二個(gè)指標(biāo)也就相應(yīng)地變高。最極端的情況下,他把所有的樣本都看做有病,那么第一個(gè)指標(biāo)達(dá)到1,第二個(gè)指標(biāo)也為1。
我們以FPR為橫軸,TPR為縱軸,得到如下ROC空間。
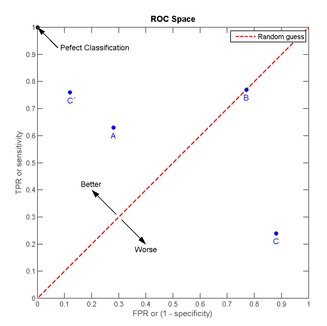
我們可以看出,左上角的點(diǎn)(TPR=1,FPR=0),為完美分類,也就是這個(gè)醫(yī)生醫(yī)術(shù)高明,診斷全對(duì)。點(diǎn)A(TPR>FPR),醫(yī)生A的判斷大體是正確的。中線上的點(diǎn)B(TPR=FPR),也就是醫(yī)生B全都是蒙的,蒙對(duì)一半,蒙錯(cuò)一半;下半平面的點(diǎn)C(TPR<FPR),這個(gè)醫(yī)生說(shuō)你有病,那么你很可能沒(méi)有病,醫(yī)生C的話我們要反著聽(tīng),為真庸醫(yī)。上圖中一個(gè)閾值,得到一個(gè)點(diǎn)。現(xiàn)在我們需要一個(gè)獨(dú)立于閾值的評(píng)價(jià)指標(biāo)來(lái)衡量這個(gè)醫(yī)生的醫(yī)術(shù)如何,也就是遍歷所有的閾值,得到ROC曲線。
還是一開(kāi)始的那幅圖,假設(shè)如下就是某個(gè)醫(yī)生的診斷統(tǒng)計(jì)圖,直線代表閾值。我們遍歷所有的閾值,能夠在ROC平面上得到如下的ROC曲線。
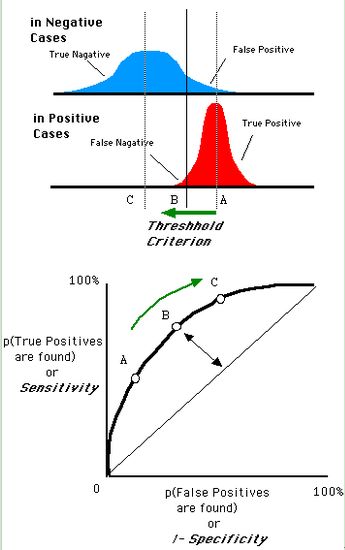
曲線距離左上角越近,證明分類器效果越好。
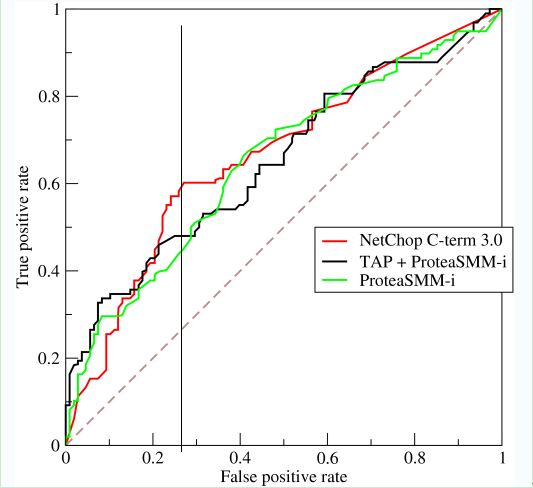
如上,是三條ROC曲線,在0.23處取一條直線。那么,在同樣的低FPR=0.23的情況下,紅色分類器得到更高的PTR。也就表明,ROC越往上,分類器效果越好。我們用一個(gè)標(biāo)量值A(chǔ)UC來(lái)量化它。
4.3 什么是AUC?
AUC值為ROC曲線所覆蓋的區(qū)域面積,顯然,AUC越大,分類器分類效果越好。
AUC = 1,是完美分類器,采用這個(gè)預(yù)測(cè)模型時(shí),不管設(shè)定什么閾值都能得出完美預(yù)測(cè)。絕大多數(shù)預(yù)測(cè)的場(chǎng)合,不存在完美分類器。
0.5 < AUC < 1,優(yōu)于隨機(jī)猜測(cè)。這個(gè)分類器(模型)妥善設(shè)定閾值的話,能有預(yù)測(cè)價(jià)值。
AUC = 0.5,跟隨機(jī)猜測(cè)一樣(例:丟銅板),模型沒(méi)有預(yù)測(cè)價(jià)值。
AUC < 0.5,比隨機(jī)猜測(cè)還差;但只要總是反預(yù)測(cè)而行,就優(yōu)于隨機(jī)猜測(cè)。
AUC的物理意義:假設(shè)分類器的輸出是樣本屬于正類的socre(置信度),則AUC的物理意義為,任取一對(duì)(正、負(fù))樣本,正樣本的score大于負(fù)樣本的score的概率。
4.4 怎樣計(jì)算AUC?
第一種方法:AUC為ROC曲線下的面積,那我們直接計(jì)算面積可得。面積為一個(gè)個(gè)小的梯形面積之和。計(jì)算的精度與閾值的精度有關(guān)。
第二種方法:根據(jù)AUC的物理意義,我們計(jì)算正樣本score大于負(fù)樣本的score的概率。取N*M(N為正樣本數(shù),M為負(fù)樣本數(shù))個(gè)二元組,比較score,最后得到AUC。時(shí)間復(fù)雜度為O(N*M)。
第三種方法:與第二種方法相似,直接計(jì)算正樣本score大于負(fù)樣本的概率。我們首先把所有樣本按照score排序,依次用rank表示他們,如最大score的樣本,rank=n(n=N+M),其次為n-1。那么對(duì)于正樣本中rank最大的樣本,rank_max,有M-1個(gè)其他正樣本比他score小,那么就有(rank_max-1)-(M-1)個(gè)負(fù)樣本比他score小。其次為(rank_second-1)-(M-2)。最后我們得到正樣本大于負(fù)樣本的概率為
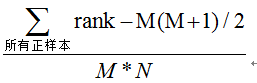
時(shí)間復(fù)雜度為O(N+M)。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~