
數(shù)分必知數(shù)倉建設(shè)指南
本文將全面講解數(shù)倉建設(shè)規(guī)范,從數(shù)據(jù)模型規(guī)范,到數(shù)倉公共規(guī)范,數(shù)倉各層規(guī)范,最后到數(shù)倉命名規(guī)范,包括表命名,指標(biāo)字段命名規(guī)范等!
目錄:
一、數(shù)據(jù)模型架構(gòu)原則
數(shù)倉分層原則 主題域劃分原則 數(shù)據(jù)模型設(shè)計原則
二、數(shù)倉公共開發(fā)規(guī)范
層次調(diào)用規(guī)范 數(shù)據(jù)類型規(guī)范 數(shù)據(jù)冗余規(guī)范 NULL字段處理規(guī)范 指標(biāo)口徑規(guī)范 數(shù)據(jù)表處理規(guī)范 表的生命周期管理
三、數(shù)倉各層開發(fā)規(guī)范
ODS層設(shè)計規(guī)范 公共維度層設(shè)計規(guī)范 DWD明細層設(shè)計規(guī)范 DWS公共匯總層設(shè)計規(guī)范
四、數(shù)倉命名規(guī)范
詞根設(shè)計規(guī)范 表命名規(guī)范 指標(biāo)命名規(guī)范
一、數(shù)據(jù)模型架構(gòu)原則
1. 數(shù)倉分層原則
優(yōu)秀可靠的數(shù)倉體系,往往需要清晰的數(shù)據(jù)分層結(jié)構(gòu),即要保證數(shù)據(jù)層的穩(wěn)定又要屏蔽對下游的影響,并且要避免鏈路過長。那么問題來了,一直在講數(shù)倉要分層,那數(shù)倉分幾層最好?
目前市場上主流的分層方式眼花繚亂,不過看事情不能只看表面,還要看到內(nèi)在的規(guī)律,不能為了分層而分層,沒有最好的,只有適合的。
分層是以解決當(dāng)前業(yè)務(wù)快速的數(shù)據(jù)支撐為目的,為未來抽象出共性的框架并能夠賦能給其他業(yè)務(wù)線,同時為業(yè)務(wù)發(fā)展提供穩(wěn)定、準(zhǔn)確的數(shù)據(jù)支撐,并能夠按照已有的模型為新業(yè)務(wù)發(fā)展提供方向,也就是數(shù)據(jù)驅(qū)動和賦能。
一個好的分層架構(gòu),要有以下好處:
清晰數(shù)據(jù)結(jié)構(gòu); 數(shù)據(jù)血緣追蹤; 減少重復(fù)開發(fā); 數(shù)據(jù)關(guān)系條理化; 屏蔽原始數(shù)據(jù)的影響。
數(shù)倉分層要結(jié)合公司業(yè)務(wù)進行,并且需要清晰明確各層職責(zé),一般采用如下分層結(jié)構(gòu):

數(shù)倉建模在哪層建設(shè)呢?我們以維度建模為例,建模是在數(shù)據(jù)源層的下一層進行建設(shè),在上圖中,就是在DW層進行數(shù)倉建模,所以DW層是數(shù)倉建設(shè)的核心層。
下面詳細闡述下每層建設(shè)規(guī)范,和上圖的分層稍微有些區(qū)別:
1. 數(shù)據(jù)源層:ODS(Operational Data Store)
ODS 層,是最接近數(shù)據(jù)源中數(shù)據(jù)的一層,為了考慮后續(xù)可能需要追溯數(shù)據(jù)問題,因此對于這一層就不建議做過多的數(shù)據(jù)清洗工作,原封不動地接入原始數(shù)據(jù)即可,至于數(shù)據(jù)的去噪、去重、異常值處理等過程可以放在后面的 DWD 層來做。
2. 數(shù)據(jù)倉庫層:DW(Data Warehouse)
數(shù)據(jù)倉庫層是我們在做數(shù)據(jù)倉庫時要核心設(shè)計的一層,在這里,從 ODS 層中獲得的數(shù)據(jù)按照主題建立各種數(shù)據(jù)模型。
DW 層又細分為 DWD(Data Warehouse Detail)層、DWM(Data WareHouse Middle)層和 DWS(Data WareHouse Servce) 層。
1) 數(shù)據(jù)明細層:DWD(Data Warehouse Detail)
該層一般保持和 ODS 層一樣的數(shù)據(jù)粒度,并且提供一定的數(shù)據(jù)質(zhì)量保證。DWD 層要做的就是將數(shù)據(jù)清理、整合、規(guī)范化、臟數(shù)據(jù)、垃圾數(shù)據(jù)、規(guī)范不一致的、狀態(tài)定義不一致的、命名不規(guī)范的數(shù)據(jù)都會被處理。
同時,為了提高數(shù)據(jù)明細層的易用性,該層會采用一些維度退化手法,將維度退化至事實表中,減少事實表和維表的關(guān)聯(lián)。
另外,在該層也會做一部分的數(shù)據(jù)聚合,將相同主題的數(shù)據(jù)匯集到一張表中,提高數(shù)據(jù)的可用性 。
2) 數(shù)據(jù)中間層:DWM(Data WareHouse Middle)
該層會在 DWD 層的數(shù)據(jù)基礎(chǔ)上,數(shù)據(jù)做輕度的聚合操作,生成一系列的中間表,提升公共指標(biāo)的復(fù)用性,減少重復(fù)加工。
直觀來講,就是對通用的核心維度進行聚合操作,算出相應(yīng)的統(tǒng)計指標(biāo)。
在實際計算中,如果直接從 DWD 或者 ODS 計算出寬表的統(tǒng)計指標(biāo),會存在計算量太大并且維度太少的問題,因此一般的做法是,在 DWM 層先計算出多個小的中間表,然后再拼接成一張 DWS 的寬表。由于寬和窄的界限不易界定,也可以去掉 DWM 這一層,只留 DWS 層,將所有的數(shù)據(jù)再放在 DWS 亦可。
3) 數(shù)據(jù)服務(wù)層:DWS(Data WareHouse Servce)
DWS 層為公共匯總層,會進行輕度匯總,粒度比明細數(shù)據(jù)稍粗,基于 DWD 層上的基礎(chǔ)數(shù)據(jù),整合匯總成分析某一個主題域的服務(wù)數(shù)據(jù),一般是寬表。DWS 層應(yīng)覆蓋 80% 的應(yīng)用場景。又稱數(shù)據(jù)集市或?qū)挶怼?/p>
按照業(yè)務(wù)劃分,如主題域流量、訂單、用戶等,生成字段比較多的寬表,用于提供后續(xù)的業(yè)務(wù)查詢,OLAP 分析,數(shù)據(jù)分發(fā)等。
一般來講,該層的數(shù)據(jù)表會相對比較少,一張表會涵蓋比較多的業(yè)務(wù)內(nèi)容,由于其字段較多,因此一般也會稱該層的表為寬表。
3. 數(shù)據(jù)應(yīng)用層:APP(Application)
在這里,主要是提供給數(shù)據(jù)產(chǎn)品和數(shù)據(jù)分析使用的數(shù)據(jù),一般會存放在 ES、 PostgreSql、Redis 等系統(tǒng)中供線上系統(tǒng)使用,也可能會存在 Hive 或者 Druid 中供數(shù)據(jù)分析和數(shù)據(jù)挖掘使用。比如我們經(jīng)常說的報表數(shù)據(jù),一般就放在這里。
4. 維表層(Dimension)
如果維表過多,也可針對維表設(shè)計單獨一層,維表層主要包含兩部分數(shù)據(jù):
高基數(shù)維度數(shù)據(jù):一般是用戶資料表、商品資料表類似的資料表。數(shù)據(jù)量可能是千萬級或者上億級別。
低基數(shù)維度數(shù)據(jù):一般是配置表,比如枚舉值對應(yīng)的中文含義,或者日期維表。數(shù)據(jù)量可能是個位數(shù)或者幾千幾萬。
2. 主題域劃分原則
1) 按照業(yè)務(wù)或業(yè)務(wù)過程劃分
業(yè)務(wù)容易理解,就是指的功能模塊/業(yè)務(wù)線。
業(yè)務(wù)過程:指企業(yè)的業(yè)務(wù)活動事件,如下單、支付、退款都是業(yè)務(wù)過程。不過需要注意的是,一個業(yè)務(wù)過程是一個不可拆分的行為事件,通俗的講,業(yè)務(wù)過程就是企業(yè)活動中的事件。
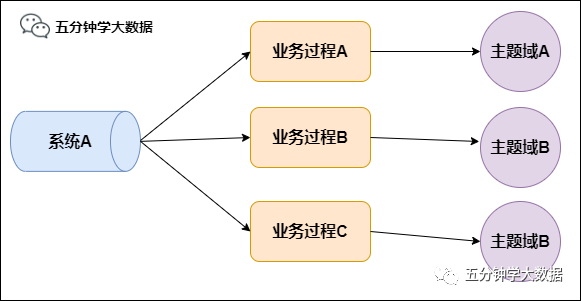
2) 按照數(shù)據(jù)域劃分
數(shù)據(jù)域是指面向業(yè)務(wù)分析,將業(yè)務(wù)過程或者維度進行抽象的集合。其中,業(yè)務(wù)過程可以概括為一個個不可拆分的行為事件,在業(yè)務(wù)過程下,可以定義指標(biāo),維度是指度量的環(huán)境,如買家下單事件,買家是維度。為保障整個體系的生命力,數(shù)據(jù)域是需要抽象提煉,并且長期維護和更新的,但不輕易變動。在劃分數(shù)據(jù)域時,既能涵蓋當(dāng)前所有的業(yè)務(wù)需求,又能在新業(yè)務(wù)進入時無影響地被包含進已有的數(shù)據(jù)域中和擴展新的數(shù)據(jù)域。
3. 數(shù)據(jù)模型設(shè)計原則
1) 高內(nèi)聚、低耦合
即主題內(nèi)部高內(nèi)聚、 不同主題間低耦合。明細層按照業(yè)務(wù)過程劃分主題,匯總層按照“實體+ 活動”劃分不同分析主題,應(yīng)用層根據(jù)應(yīng)用需求劃分不同應(yīng)用主題。
2) 核心模型和擴展模型要分離
建立核心模型與擴展模型體系,核心模型包括的字段支持常用的核心業(yè)務(wù),擴展模型包括的字段支持個性化或少量應(yīng)用的需要,不能讓擴展模型的字段過度侵入核心模型,以免破壞核心模型的架構(gòu)簡潔性與可維護性。
3) 公共處理邏輯下沉及單一
越是底層公用的處理邏輯越應(yīng)該在數(shù)據(jù)調(diào)度依賴的底層進行封裝與實現(xiàn),不要讓公用的處理邏輯暴露給應(yīng)用實現(xiàn),不要讓公共邏輯多處同時存在。
4) 成本與性能平衡
適當(dāng)?shù)臄?shù)據(jù)冗余可換取查詢和刷新性能,不宜過度冗余與數(shù)據(jù)復(fù)制。
5) 數(shù)據(jù)可回滾
處理邏輯不變,在不同時間多次運行數(shù)據(jù)結(jié)果確定不變。
二、數(shù)倉公共開發(fā)規(guī)范
1. 層次調(diào)用規(guī)范
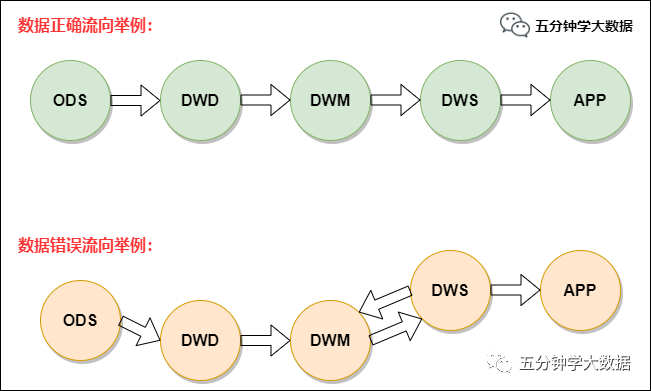
穩(wěn)定業(yè)務(wù)按照標(biāo)準(zhǔn)的數(shù)據(jù)流向進行開發(fā),即 ODS –> DWD –> DWS –> APP。非穩(wěn)定業(yè)務(wù)或探索性需求,可以遵循 ODS -> DWD -> APP 或者 ODS -> DWD -> DWM ->APP 兩個模型數(shù)據(jù)流。
在保障了數(shù)據(jù)鏈路的合理性之后,也必須保證模型分層引用原則:
正常流向:ODS -> DWD -> DWM -> DWS -> APP,當(dāng)出現(xiàn) ODS -> DWD -> DWS -> APP 這種關(guān)系時,說明主題域未覆蓋全。應(yīng)將 DWD 數(shù)據(jù)落到 DWM 中,對于使用頻度非常低的表允許 DWD -> DWS。
盡量避免出現(xiàn) DWS 寬表中使用 DWD 又使用(該 DWD 所歸屬主題域)DWM 的表。
同一主題域內(nèi)對于 DWM 生成 DWM 的表,原則上要盡量避免,否則會影響 ETL 的效率。
DWM、DWS 和 APP 中禁止直接使用 ODS 的表, ODS 的表只能被 DWD 引用。
禁止出現(xiàn)反向依賴,例如 DWM 的表依賴 DWS 的表。
舉例:
2. 數(shù)據(jù)類型規(guī)范
需統(tǒng)一規(guī)定不同的數(shù)據(jù)的數(shù)據(jù)類型,嚴格按照規(guī)定的數(shù)據(jù)類型執(zhí)行:
金額:double 或 使用 decimal(28,6) 控制精度等,明確單位是分還是元。
字符串:string。
id類:bigint。
時間:string。
狀態(tài):string
3. 數(shù)據(jù)冗余規(guī)范
寬表的冗余字段要確保:
冗余字段要使用高頻,下游3個或以上使用。
冗余字段引入不應(yīng)造成本身數(shù)據(jù)產(chǎn)生過多的延后。
冗余字段和已有字段的重復(fù)率不應(yīng)過大,原則上不應(yīng)超過60%,如需要可以選擇join或原表拓展。
4. NULL字段處理規(guī)范
對于維度字段,需設(shè)置為-1
對于指標(biāo)字段,需設(shè)置為 0
5. 指標(biāo)口徑規(guī)范
保證主題域內(nèi),指標(biāo)口徑一致,無歧義。
通過數(shù)據(jù)分層,提供統(tǒng)一的數(shù)據(jù)出口,統(tǒng)一對外輸出的數(shù)據(jù)口徑,避免同一指標(biāo)不同口徑的情況發(fā)生。
1) 指標(biāo)梳理
指標(biāo)口徑的不一致使得數(shù)據(jù)使用的成本極高,經(jīng)常出現(xiàn)口徑打架、反復(fù)核對數(shù)據(jù)的問題。在數(shù)據(jù)治理中,我們將需求梳理到的所有指標(biāo)進行進一步梳理,明確其口徑,如果存在兩個指標(biāo)名稱相同,但口徑不一致,先判斷是否是進行合并,如需要同時存在,那么在命名上必須能夠區(qū)分開。
2) 指標(biāo)管理
指標(biāo)管理分為原子指標(biāo)維護和派生指標(biāo)維護。
原子指標(biāo):
選擇原子指標(biāo)的歸屬產(chǎn)線、業(yè)務(wù)板塊、數(shù)據(jù)域、業(yè)務(wù)過程 選擇原子指標(biāo)的統(tǒng)計數(shù)據(jù)來源于該業(yè)務(wù)過程下的原始數(shù)據(jù)源 錄入原子指標(biāo)的英文名稱、中文名稱、概述 填寫指標(biāo)函數(shù) 系統(tǒng)根據(jù)指標(biāo)函數(shù)自動生成原子指標(biāo)的定義表達式 系統(tǒng)根據(jù)指標(biāo)定義表達式以及數(shù)據(jù)源表生成原子指標(biāo)SQL
派生指標(biāo):
在原子指標(biāo)的基礎(chǔ)之上選擇了一些維度或者修飾限定詞。
6. 數(shù)據(jù)表處理規(guī)范
1) 增量表
新增數(shù)據(jù),增量數(shù)據(jù)是上次導(dǎo)出之后的新數(shù)據(jù)。
記錄每次增加的量,而不是總量;
增量表,只報變化量,無變化不用報;
每天一個分區(qū)。
2) 全量表
每天的所有的最新狀態(tài)的數(shù)據(jù)。
全量表,有無變化,都要報;
每次上報的數(shù)據(jù)都是所有的數(shù)據(jù)(變化的 + 沒有變化的);
只有一個分區(qū)。
3) 快照表
按日分區(qū),記錄截止數(shù)據(jù)日期的全量數(shù)據(jù)。
快照表,有無變化,都要報;
每次上報的數(shù)據(jù)都是所有的數(shù)據(jù)(變化的 + 沒有變化的);
一天一個分區(qū)。
4) 拉鏈表
記錄截止數(shù)據(jù)日期的全量數(shù)據(jù)。
記錄一個事物從開始,一直到當(dāng)前狀態(tài)的所有變化的信息;
拉鏈表每次上報的都是歷史記錄的最終狀態(tài),是記錄在當(dāng)前時刻的歷史總 量;
當(dāng)前記錄存的是當(dāng)前時間之前的所有歷史記錄的最后變化量(總量);
只有一個分區(qū)。
7. 表的生命周期管理
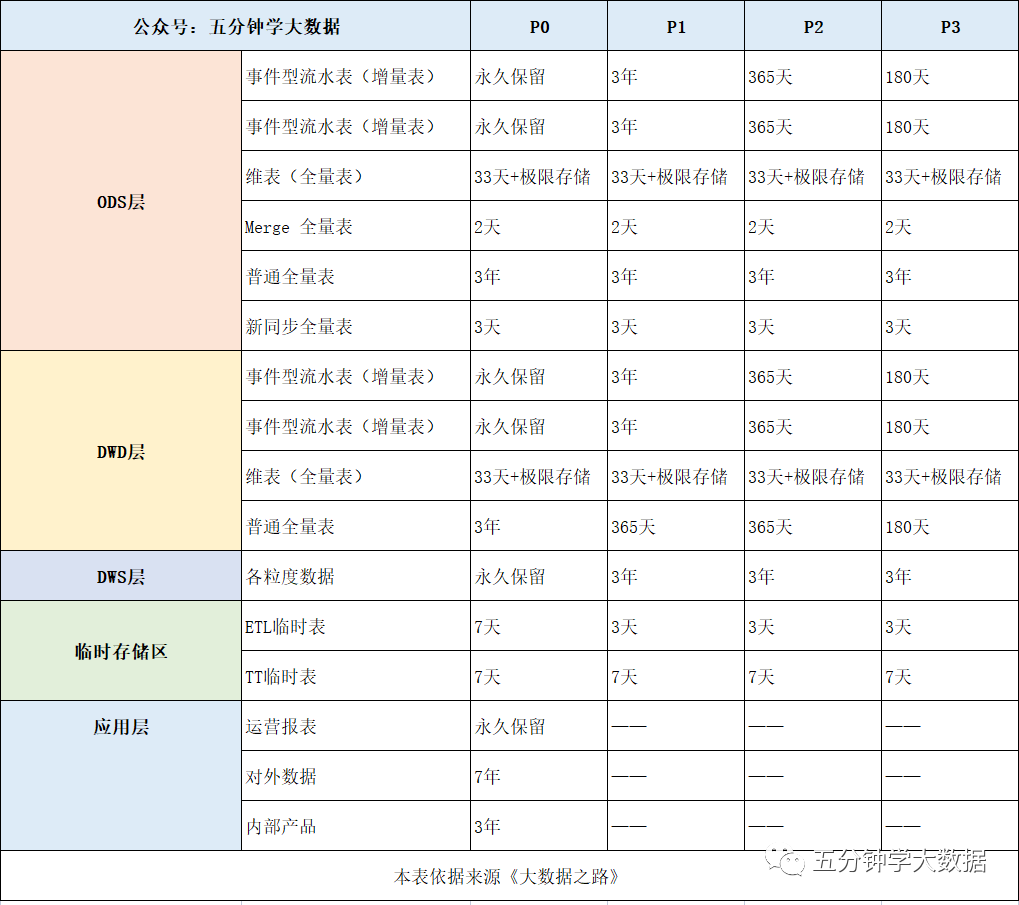
這部分主要是要通過對歷史數(shù)據(jù)的等級劃分與對表類型的劃分生成相應(yīng)的生命周期管理矩陣。
1) 歷史數(shù)據(jù)等級劃分
主要將歷史數(shù)據(jù)劃分P0、Pl、P2、P3 四個等級,其具體定義如下:
P0 :非常重要的主題域數(shù)據(jù)和非常重要的應(yīng)用數(shù)據(jù),具有不可恢復(fù)性,如交易、日志、集團 KPI 數(shù)據(jù)、 IPO 關(guān)聯(lián)表。
Pl :重要的業(yè)務(wù)數(shù)據(jù)和重要的應(yīng)用數(shù)據(jù),具有不可恢復(fù)性,如重要的業(yè)務(wù)產(chǎn)品數(shù)據(jù)。
P2 :重要的業(yè)務(wù)數(shù)據(jù)和重要的應(yīng)用數(shù)據(jù),具有可恢復(fù)性,如交易線 ETL 產(chǎn)生的中間過程數(shù)據(jù)。
P3 :不重要的業(yè)務(wù)數(shù)據(jù)和不重要的應(yīng)用數(shù)據(jù),具有可恢復(fù)性,如某些 SNS 產(chǎn)品報表。
2) 表類型劃分
事件型流水表(增量表)
事件型流水表(增量表)指數(shù)據(jù)無重復(fù)或者無主鍵數(shù)據(jù),如日志。
事件型鏡像表(增量表)
事件型鏡像表(增量表)指業(yè)務(wù)過程性數(shù)據(jù),有主鍵,但是對于同樣主鍵的屬性會發(fā)生緩慢變化,如交易、訂單狀態(tài)與時間會根據(jù)業(yè)務(wù)發(fā)生變更。
維表
維表包括維度與維度屬性數(shù)據(jù),如用戶表、商品表。
Merge 全量表
Merge 全量表包括業(yè)務(wù)過程性數(shù)據(jù)或者維表數(shù)據(jù)。由于數(shù)據(jù)本身有新增的或者發(fā)生狀態(tài)變更,對于同樣主鍵的數(shù)據(jù)可能會保留多份,因此可以對這些數(shù)據(jù)根據(jù)主鍵進行 Merge 操作,主鍵對應(yīng)的屬性只會保留最新狀態(tài),歷史狀態(tài)保留在前一天分區(qū) 中。例如,用戶表、交易表等都可以進行 Merge 操作。
ETL 臨時表
ETL 臨時表是指 ETL 處理過程中產(chǎn)生的臨時表數(shù)據(jù),一般不建議保留,最多7天。
TT 臨時數(shù)據(jù)
TT 拉取的數(shù)據(jù)和 DbSync 產(chǎn)生的臨時數(shù)據(jù)最終會流轉(zhuǎn)到 DS 層,ODS 層數(shù)據(jù)作為原始數(shù)據(jù)保留下來,從而使得 TT&DbSync 上游數(shù)據(jù)成為臨時數(shù)據(jù)。這類數(shù)據(jù)不建議保留很長時間,生命周期默認設(shè)置為 93天,可以根據(jù)實際情況適當(dāng)減少保留天數(shù)。
7. 普通全量表
很多小業(yè)務(wù)數(shù)據(jù)或者產(chǎn)品數(shù)據(jù),BI一般是直接全量拉取,這種方式效率快,對存儲壓力也不是很大,而且表保留很長時間,可以根據(jù)歷史數(shù)據(jù)等級確定保留策略。
通過上述歷史數(shù)據(jù)等級劃分與表類型劃分,生成相應(yīng)的生命周期管理矩陣,如下表所示:
三、數(shù)倉各層開發(fā)規(guī)范
1. ODS層設(shè)計規(guī)范
同步規(guī)范:
一個系統(tǒng)源表只允許同步一次;
全量初始化同步和增量同步處理邏輯要清晰;
以統(tǒng)計日期和時間進行分區(qū)存儲;
目標(biāo)表字段在源表不存在時要自動填充處理。
表分類與生命周期:
ods流水全量表:
不可再生的永久保存;
日志可按留存要求;
按需設(shè)置保留特殊日期數(shù)據(jù);
按需設(shè)置保留特殊月份數(shù)據(jù);
ods鏡像型全量表:
推薦按天存儲;
對歷史變化進行保留;
最新數(shù)據(jù)存儲在最大分區(qū);
歷史數(shù)據(jù)按需保留;
ods增量數(shù)據(jù):
推薦按天存儲;
有對應(yīng)全量表的,建議只保留14天數(shù)據(jù);
無對應(yīng)全量表的,永久保留;
ods的etl過程中的臨時表:
推薦按需保留;
最多保留7天;
建議用完即刪,下次使用再生成;
BDSync非去重數(shù)據(jù):
通過中間層保留,默認用完即刪,不建議保留。
數(shù)據(jù)質(zhì)量:
全量表必須配置唯一性字段標(biāo)識;
對分區(qū)空數(shù)據(jù)進行監(jiān)控;
對枚舉類型字段,進行枚舉值變化和分布監(jiān)控;
ods表數(shù)據(jù)量級和記錄數(shù)做環(huán)比監(jiān)控;
ods全表都必須要有注釋;
2. 公共維度層設(shè)計規(guī)范
1) 設(shè)計準(zhǔn)則
一致性
共維度在不同的物理表中的字段名稱、數(shù)據(jù)類型、數(shù)據(jù)內(nèi)容必須保持一致(歷史原因不一致,要做好版本控制)
維度的組合與拆分
組合原則:
將維度與關(guān)聯(lián)性強的字段進行組合,一起查詢,一起展示,兩個維度必須具有天然的關(guān)系,如:商品的基本屬性和所屬品牌。
無相關(guān)性:如一些使用頻率較小的雜項維度,可以構(gòu)建一個集合雜項維度的特殊屬性。
行為維度:經(jīng)過計算的度量,但下游當(dāng)維度處理,例:點擊量 0-1000,100-1000等,可以做聚合分類。
拆分與冗余:
針對重要性,業(yè)務(wù)相關(guān)性、源、使用頻率等可分為核心表、擴展表。
數(shù)據(jù)記錄較大的維度,可以適當(dāng)冗余一些子集。
2) 存儲及生命周期管理
建議按天分區(qū)。
3個月內(nèi)最大訪問跨度<=4天時,建議保留最近7天分區(qū); 3個月內(nèi)最大訪問跨度<=12天時,建議保留最近15天分區(qū); 3個月內(nèi)最大訪問跨度<=30天時,建議保留最近33天分區(qū); 3個月內(nèi)最大訪問跨度<=90天時,建議保留最近120天分區(qū); 3個月內(nèi)最大訪問跨度<=180天時,建議保留最近240天分區(qū); 3個月內(nèi)最大訪問跨度<=300天時,建議保留最近400天分區(qū);
3. DWD明細層設(shè)計規(guī)范
1) 存儲及生命周期管理
建議按天分區(qū)。
3個月內(nèi)最大訪問跨度<=4天時,建議保留最近7天分區(qū); 3個月內(nèi)最大訪問跨度<=12天時,建議保留最近15天分區(qū); 3個月內(nèi)最大訪問跨度<=30天時,建議保留最近33天分區(qū); 3個月內(nèi)最大訪問跨度<=90天時,建議保留最近120天分區(qū); 3個月內(nèi)最大訪問跨度<=180天時,建議保留最近240天分區(qū); 3個月內(nèi)最大訪問跨度<=300天時,建議保留最近400天分區(qū);
2) 事務(wù)型事實表設(shè)計準(zhǔn)則
基于數(shù)據(jù)應(yīng)用需求的分析設(shè)計事務(wù)型事實表,結(jié)合下游較大的針對某個業(yè)務(wù)過程和分析指標(biāo)需求,可考慮基于某個事件過程構(gòu)建事務(wù)型實時表;
一般選用事件的發(fā)生日期或時間作為分區(qū)字段,便于掃描和裁剪;
冗余子集原則,有利于降低后續(xù)IO開銷;
明細層事實表維度退化,減少后續(xù)使用join成本。
3) 周期快照事實表
周期快照事實表中的每行匯總了發(fā)生在某一標(biāo)準(zhǔn)周期,如某一天、某周、某月的多個度量事件。
粒度是周期性的,不是個體的事務(wù)。
通常包含許多事實,因為任何與事實表粒度一致的度量事件都是被允許的。
4) 累積快照事實表
多個業(yè)務(wù)過程聯(lián)合分析而構(gòu)建的事實表,如采購單的流轉(zhuǎn)環(huán)節(jié)。
用于分析事件時間和時間之間的間隔周期。
少量的且當(dāng)前事務(wù)型不支持的,如關(guān)閉、發(fā)貨等相關(guān)的統(tǒng)計。
4. DWS公共匯總層設(shè)計規(guī)范
數(shù)據(jù)倉庫的性能是數(shù)據(jù)倉庫建設(shè)是否成功的重要標(biāo)準(zhǔn)之一。聚集主要是通過匯總明細粒度數(shù)據(jù)來獲得改進查詢性能的效果。通過訪問聚集數(shù)據(jù),可以減少數(shù)據(jù)庫在響應(yīng)查詢時必須執(zhí)行的工作量,能夠快速響應(yīng)用戶的查詢,同時有利于減少不同用訪問明細數(shù)據(jù)帶來的結(jié)果不一致問題。
1) 聚集的基本原則
一致性。聚集表必須提供與查詢明細粒度數(shù)據(jù)一致的查詢結(jié)果。
避免單一表設(shè)計。不要在同一個表中存儲不同層次的聚集數(shù)據(jù)。
聚集粒度可不同。聚集并不需要保持與原始明細粒度數(shù)據(jù)一樣的粒度,聚集只關(guān)心所需要查詢的維度。
2) 聚集的基本步驟
第一步:確定聚集維度
在原始明細模型中會存在多個描述事實的維度,如日期、商品類別、賣家等,這時候需要確定根據(jù)什么維度聚集,如果只關(guān)心商品的交易額情況,那么就可以根據(jù)商品維度聚集數(shù)據(jù)。
第二步:確定一致性上鉆
這時候要關(guān)心是按月匯總還是按天匯總,是按照商品匯總還是按照類目匯總,如果按照類目匯總,還需要關(guān)心是按照大類匯總還是小類匯總。當(dāng)然,我們要做的只是了解用戶需要什么,然后按照他們想要的進行聚集。
第三步:確定聚集事實
在原始明細模型中可能會有多個事實的度量,比如在交易中有交易額、交易數(shù)量等,這時候要明確是按照交易額匯總還是按照成交數(shù)量匯總。
3) 公共匯總層設(shè)計原則
除了聚集基本的原則外,公共匯總層還必須遵循以下原則:
數(shù)據(jù)公用性。匯總的聚集會有第三者使用嗎?基于某個維度的聚集是不是經(jīng)常用于數(shù)據(jù)分析中?如果答案是肯定的,那么就有必要把明細數(shù)據(jù)經(jīng)過匯總沉淀到聚集表中。
不跨數(shù)據(jù)域。數(shù)據(jù)域是在較高層次上對數(shù)據(jù)進行分類聚集的抽象。如以業(yè)務(wù)
區(qū)分統(tǒng)計周期。在表的命名上要能說明數(shù)據(jù)的統(tǒng)計周期,如
_Id表示最近1天,_td表示截至當(dāng)天,_nd表示最近N天。
四、數(shù)倉命名規(guī)范
1. 詞根設(shè)計規(guī)范
詞根屬于數(shù)倉建設(shè)中的規(guī)范,屬于元數(shù)據(jù)管理的范疇,現(xiàn)在把這個劃到數(shù)據(jù)治理的一部分。完整的數(shù)倉建設(shè)是包含數(shù)據(jù)治理的,只是現(xiàn)在談到數(shù)倉偏向于數(shù)據(jù)建模, 而談到數(shù)據(jù)治理,更多的是關(guān)于數(shù)據(jù)規(guī)范、數(shù)據(jù)管理。
表命名,其實在很大程度上是對元數(shù)據(jù)描述的一種體現(xiàn),表命名規(guī)范越完善,我 們能從表名獲取到的信息就越多。比如:一部分業(yè)務(wù)是關(guān)于貨架的,英文名是:rack, rack 就是一個詞根,那我們就在所有的表、字段等用到的地方都叫 rack,不要叫成 別的什么。這就是詞根的作用,用來統(tǒng)一命名,表達同一個含義。
指標(biāo)體系中有很多“率”的指標(biāo),都可以拆解成 XXX+率,率可以叫 rate,那我 們所有的指標(biāo)都叫做 XXX+rate。
詞根:可以用來統(tǒng)一表名、字段名、主題域名等等。
舉例:以流程圖的方式來展示,更加直觀和易懂,本圖側(cè)重 dwm 層表的命名 規(guī)范,其余命名是類似的道理:
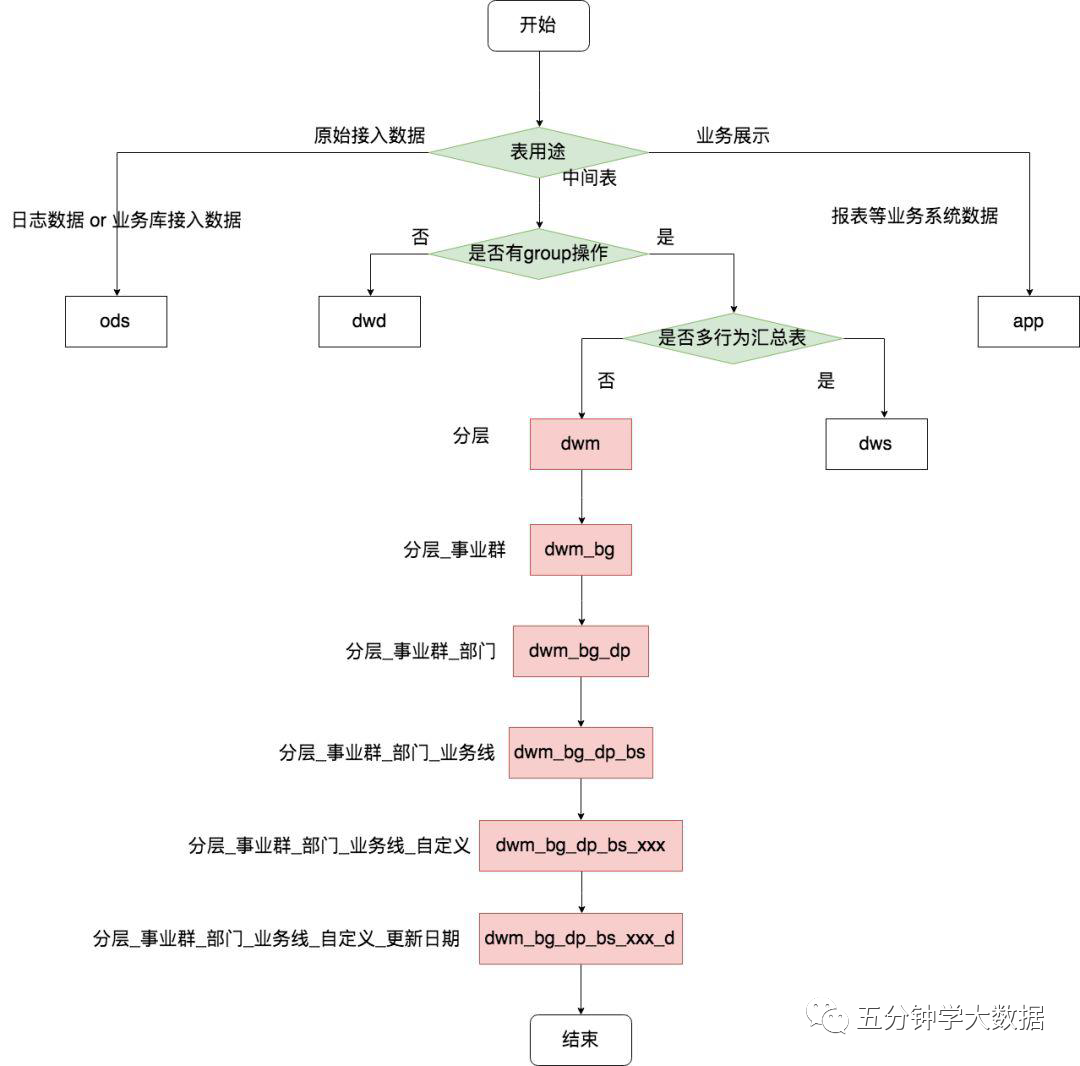
第一個判斷條件是該表的用途,是中間表、原始日志還是業(yè)務(wù)展示用的表 如果該表被判斷為中間表,就會走入下一個判斷條件:表是否有 group 操作 通過是否有 group 操作來判斷該表該劃分在 dwd 層還是 dwm 和 dws 層 如果不是 dwd 層,則需要判斷該表是否是多個行為的匯總表(即寬表) 最后再分別填上事業(yè)群、部門、業(yè)務(wù)線、自定義名稱和更新頻率等信息即可。
分層:表的使用范圍
事業(yè)群和部門:生產(chǎn)該表或者該數(shù)據(jù)的團隊
業(yè)務(wù)線:表明該數(shù)據(jù)是哪個產(chǎn)品或者業(yè)務(wù)線相關(guān)
主題域:分析問題的角度,對象實體
自定義:一般會盡可能多描述該表的信息,比如活躍表、留存表等
更新周期:比如說天級還是月級更新
數(shù)倉表的命名規(guī)范如下:
1. 數(shù)倉層次:
公用維度:dim
DM層:dm
ODS層:ods
DWD層:dwd
DWS層:dws
2. 周期/數(shù)據(jù)范圍:
日快照:d
增量:i
全量:f
周:w
拉鏈表:l
非分區(qū)全量表:a
2. 表命名規(guī)范
1) 常規(guī)表
常規(guī)表是我們需要固化的表,是正式使用的表,是目前一段時間內(nèi)需要去維護去 完善的表。
規(guī)范:分層前綴[dwd|dws|ads]_部門_業(yè)務(wù)域_主題域_XXX_更新周期|數(shù)據(jù)范圍
業(yè)務(wù)域、主題域我們都可以用詞根的方式枚舉清楚,不斷完善。
更新周期主要的是時間粒度、日、月、年、周等。
2) 中間表
中間表一般出現(xiàn)在 Job 中,是 Job 中臨時存儲的中間數(shù)據(jù)的表,中間表的作 用域只限于當(dāng)前 Job 執(zhí)行過程中,Job 一旦執(zhí)行完成,該中間表的使命就完 成了,是可以刪除的(按照自己公司的場景自由選擇,以前公司會保留幾天 的中間表數(shù)據(jù),用來排查問題)。
規(guī)范:mid_table_name_[0~9|dim]
table_name 是我們?nèi)蝿?wù)中目標(biāo)表的名字,通常來說一個任務(wù)只有一個目標(biāo)表。這里加上表名,是為了防止自由發(fā)揮的時候表名沖突,而末尾大家可以選擇自由發(fā)揮,起一些有意義的名字,或者簡單粗暴,使用數(shù)字代替,各有優(yōu)劣吧,謹慎選擇。
通常會遇到需要補全維度的表,這里使用 dim 結(jié)尾。
如果要保留歷史的中間表,可以加上日期或者時間戳。
3) 臨時表
臨時表是臨時測試的表,是臨時使用一次的表,就是暫時保存下數(shù)據(jù)看看,后續(xù)一般不再使用的表,是可以隨時刪除的表。
規(guī)范:tmp_xxx
只要加上 tmp 開頭即可,其他名字隨意,注意 tmp 開頭的表不要用來實際使用,只是測試驗證而已。
4) 維度表
維度表是基于底層數(shù)據(jù),抽象出來的描述類的表。維度表可以自動從底層表抽象出來,也可以手工來維護。
規(guī)范:dim_xxx
維度表,統(tǒng)一以 dim 開頭,后面加上,對該指標(biāo)的描述。
5) 手工表
手工表是手工維護的表,手工初始化一次之后,一般不會自動改變,后面變更,也是手工來維護。
一般來說,手工的數(shù)據(jù)粒度是偏細的,所以暫時統(tǒng)一放在 dwd 層,后面如果有目標(biāo)值或者其他類型手工數(shù)據(jù),再根據(jù)實際情況分層。
規(guī)范:dwd_業(yè)務(wù)域_manual_xxx
手工表,增加特殊的主題域,manual,表示手工維護表。
3. 指標(biāo)命名規(guī)范
1) 公共規(guī)則
所有單詞小寫
單詞之間下劃線分割(反例:appName 或 AppName)
可讀性優(yōu)于長度 (詞根,避免出現(xiàn)同一個指標(biāo),命名一致性)
禁止使用 sql 關(guān)鍵字,如字段名與關(guān)鍵字沖突時 +col
數(shù)量字段后綴 _cnt 等標(biāo)識...
金額字段后綴 _price 標(biāo)識
天分區(qū)使用字段 dt,格式統(tǒng)一(yyyymmdd 或 yyyy-mm-dd)
小時分區(qū)使用字段 hh,范圍(00-23)
分鐘分區(qū)使用字段 mi,范圍(00-59)
布爾類型標(biāo)識:is_{業(yè)務(wù)},不允許出現(xiàn)空值
2) 指標(biāo)命名規(guī)范
結(jié)合指標(biāo)的特性以及詞根管理規(guī)范,將指標(biāo)進行結(jié)構(gòu)化處理。
基礎(chǔ)指標(biāo)詞根,即所有指標(biāo)必須包含以下基礎(chǔ)詞根:
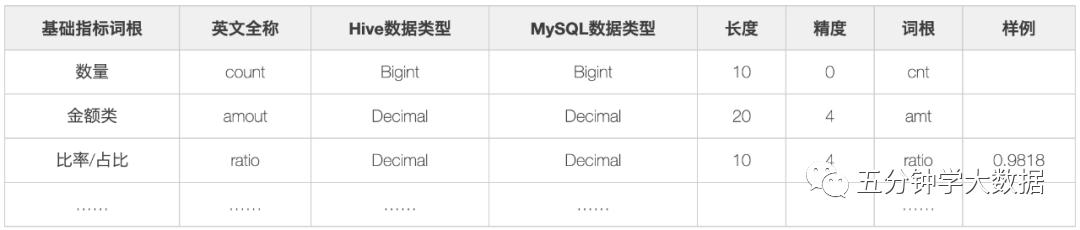
業(yè)務(wù)修飾詞,用于描述業(yè)務(wù)場景的詞匯,例如trade-交易。
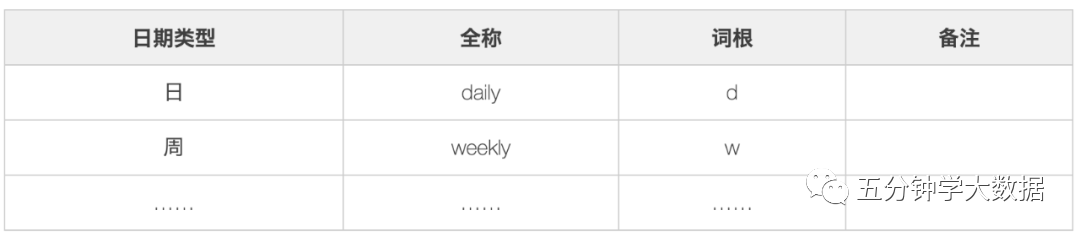
3.日期修飾詞,用于修飾業(yè)務(wù)發(fā)生的時間區(qū)間。
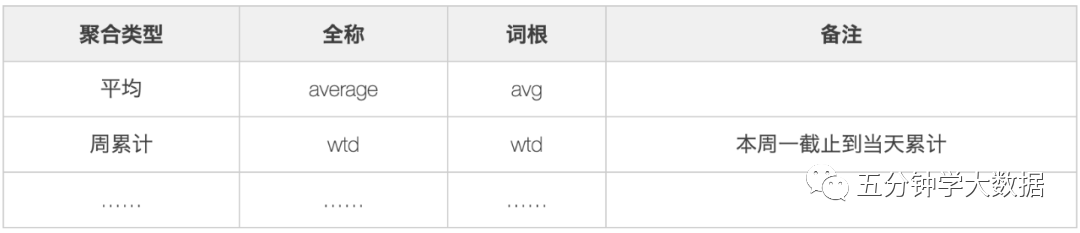
4.聚合修飾詞,對結(jié)果進行聚集操作。
5.基礎(chǔ)指標(biāo),單一的業(yè)務(wù)修飾詞+基礎(chǔ)指標(biāo)詞根構(gòu)建基礎(chǔ)指標(biāo) ,例如:交易金額-trade_amt。
6.派生指標(biāo),多修飾詞+基礎(chǔ)指標(biāo)詞根構(gòu)建派生指標(biāo)。派生指標(biāo)繼承基礎(chǔ)指標(biāo)的特性,例如:安裝門店數(shù)量-install_poi_cnt。
7.普通指標(biāo)命名規(guī)范,與字段命名規(guī)范一致,由詞匯轉(zhuǎn)換即可以。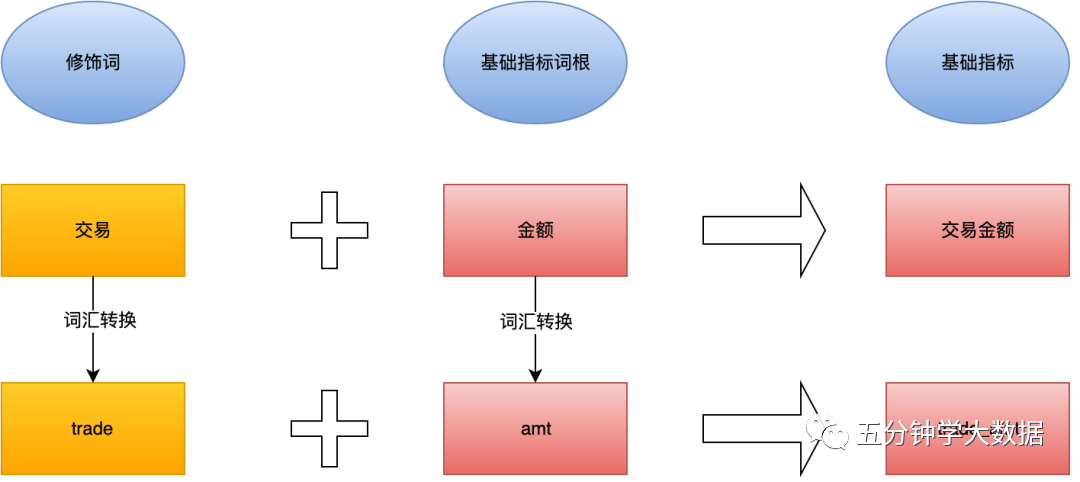
參考
本文檔規(guī)范依據(jù)來源參考: