
綜述:目標(biāo)檢測二十年

極市導(dǎo)讀
?以2014年為分水嶺,作者將過去二十年的目標(biāo)檢測發(fā)展進(jìn)程分為兩個階段:2014年之前的傳統(tǒng)目標(biāo)檢測,以及之后基于深度學(xué)習(xí)的目標(biāo)檢測。接下來,文章列舉了二十年來目標(biāo)檢測領(lǐng)域的關(guān)鍵技術(shù),思路非常清晰。
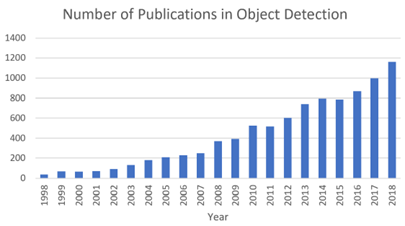
過去二十年中與 “ 目標(biāo)檢測 ” 相關(guān)的出版物數(shù)量的增長
二十年
在計算機(jī)視覺領(lǐng)域中有幾個基本的任務(wù):圖像分類[3]、目標(biāo)檢測[4]、實例分割[5]及語義分割[6],其中目標(biāo)檢測作為計算機(jī)視覺中最基本的任務(wù)在近年來引起了廣泛關(guān)注。某種意義上,它在過去二十年內(nèi)的發(fā)展也是計算機(jī)視覺發(fā)展史的縮影。如果我們將今天基于深度學(xué)習(xí)的目標(biāo)檢測技術(shù)比作一場“熱兵器革命”,那么回顧20年前的技術(shù)時即可窺探“冷兵器”時代的智慧。
目標(biāo)檢測是一項計算機(jī)視覺任務(wù)。正如視覺對于人的作用一樣,目標(biāo)檢測旨在解決計算機(jī)視覺應(yīng)用中兩個最基本的問題:1. 該物體是什么?2. 該物體在哪里?當(dāng)然,聰明的人可能會立即想到第三個問題:“該物體在干什么?”這即是更進(jìn)一步的邏輯及認(rèn)知推理,這一點在近年來的目標(biāo)檢測技術(shù)中也越來越被重視。不管怎樣,作為計算機(jī)視覺的基本任務(wù),它也是其他計算機(jī)視覺任務(wù)的主要成分,如實例分割、圖像字幕、目標(biāo)跟蹤等。
從應(yīng)用的角度來看,目標(biāo)檢測可以被分為兩個研究主題:“ 通用目標(biāo)檢測(General Object Detection) ” 及 “檢測應(yīng)用(Detection Applications)” ,前者旨在探索在統(tǒng)一的框架下檢測不同類型物體的方法,以模擬人類的視覺和認(rèn)知;后者是指特定應(yīng)用場景下的檢測,如行人檢測、人臉檢測、文本檢測等。
近年來,隨著深度學(xué)習(xí)技術(shù)[7]的快速發(fā)展,為目標(biāo)檢測注入了新鮮血液,取得了顯著的突破,也將其推向了一個前所未有的研究熱點。目前,目標(biāo)檢測已廣泛應(yīng)用于自動駕駛、機(jī)器人視覺、視頻監(jiān)控等領(lǐng)域。
二十年間的發(fā)展
如下圖所示,以2014年為分水嶺,目標(biāo)檢測在過去的二十年中可大致分為兩個時期:2014年前的“傳統(tǒng)目標(biāo)檢測期”及之后的“基于深度學(xué)習(xí)的目標(biāo)檢測期”。接下來我們詳細(xì)談?wù)搩蓚€時期的發(fā)展。
?
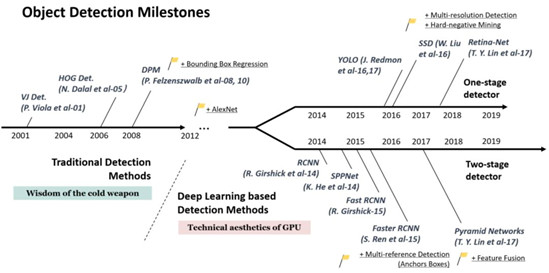
1、傳統(tǒng)檢測?
早期的目標(biāo)檢測算法大多是基于手工特征構(gòu)建的。由于當(dāng)時缺乏有效的圖像表示,人們別無選擇,只能設(shè)計復(fù)雜的特征表示及各種加速技術(shù)對有限的計算資源物盡其用。
(1) Viola Jones檢測器
18年前,P. Viola和M. Jones在沒有任何約束(如膚色分割)的情況下首次實現(xiàn)了人臉的實時檢測[8][9]。他們所設(shè)計的檢測器在一臺配備700MHz Pentium III CPU的電腦上運行,在保持同等檢測精度的條件下的運算速度是其他算法的數(shù)十甚至數(shù)百倍。這種檢測算法以共同作者的名字命名為“Viola-Jones (VJ) 檢測器”以紀(jì)念他們的重大貢獻(xiàn)。
VJ檢測器采用最直接的檢測方法,即滑動窗口(slide window):查看一張圖像中所有可能的窗口尺寸和位置并判斷是否有窗口包含人臉。這一過程雖然聽上去簡單,但它背后所需的計算量遠(yuǎn)遠(yuǎn)超出了當(dāng)時計算機(jī)的算力。VJ檢測器結(jié)合了 “ 積分圖像 ”、“ 特征選擇 ” 和 “ 檢測級聯(lián) ” 三種重要技術(shù),大大提高了檢測速度。
1)積分圖像:這是一種計算方法,以加快盒濾波或卷積過程。與當(dāng)時的其他目標(biāo)檢測算法一樣[10],在VJ檢測器中使用Haar小波作為圖像的特征表示。積分圖像使得VJ檢測器中每個窗口的計算復(fù)雜度與其窗口大小無關(guān)。
2)特征選擇:作者沒有使用一組手動選擇的Haar基過濾器,而是使用Adaboost算法從一組巨大的隨機(jī)特征池 (大約18萬維) 中選擇一組對人臉檢測最有幫助的小特征。
3)檢測級聯(lián):在VJ檢測器中引入了一個多級檢測范例 ( 又稱“檢測級聯(lián)”,detection cascades ),通過減少對背景窗口的計算,而增加對人臉目標(biāo)的計算,從而減少了計算開銷。
(2) HOG 檢測器
方向梯度直方圖(HOG)特征描述器最初是由N. Dalal和B.Triggs在2005年提出的[11]。HOG對當(dāng)時的尺度不變特征變換(scale-invariant feature transform)和形狀語境(shape contexts)做出重要改進(jìn)。為了平衡特征不變性 ( 包括平移、尺度、光照等 ) 和非線性 ( 區(qū)分不同對象類別 ),HOG描述器被設(shè)計為在密集的均勻間隔單元網(wǎng)格(稱為一個“區(qū)塊”)上計算,并使用重疊局部對比度歸一化方法來提高精度。雖然HOG可以用來檢測各種對象類,但它的主要目標(biāo)是行人檢測問題。如若要檢測不同大小的對象,則要讓HOG檢測器在保持檢測窗口大小不變的情況下,對輸入圖像進(jìn)行多次重設(shè)尺寸(rescale)。這么多年來,HOG檢測器一直是許多目標(biāo)檢測器和各種計算機(jī)視覺應(yīng)用的重要基礎(chǔ)。
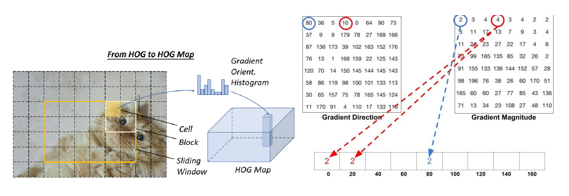
方向梯度直方圖(HOG),計算出每個像素朝四周的梯度方向和梯度強(qiáng)度,并統(tǒng)計形成梯度直方圖
(3) 基于可變形部件的模型(DPM)
DPM作為voco -07、-08、-09屆檢測挑戰(zhàn)賽的優(yōu)勝者,它曾是傳統(tǒng)目標(biāo)檢測方法的巔峰。DPM最初是由P. Felzenszwalb提出的[12],于2008年作為HOG檢測器的擴(kuò)展,之后R. Girshick進(jìn)行了各種改進(jìn)[13][14]。
DPM遵循“分而治之”的檢測思想,訓(xùn)練可以簡單地看作是學(xué)習(xí)一種正確的分解對象的方法,推理可以看作是對不同對象部件的檢測的集合。例如,檢測“汽車”的問題可以看作是檢測它的窗口、車身和車輪。工作的這一部分,也就是“star model”由P.Felzenszwalb等人完成。后來,R. Girshick進(jìn)一步將star model擴(kuò)展到 “ 混合模型 ”,以處理更顯著變化下的現(xiàn)實世界中的物體。
一個典型的DPM檢測器由一個根過濾器(root-filter)和一些零件濾波器(part-filters)組成。該方法不需要手動設(shè)定零件濾波器的配置(如尺寸和位置),而是在開發(fā)了一種弱監(jiān)督學(xué)習(xí)方法并使用到了DPM中,所有零件濾波器的配置都可以作為潛在變量自動學(xué)習(xí)。R. Girshick將這個過程進(jìn)一步表述為一個多實例學(xué)習(xí)的特殊案例,同時還應(yīng)用了“困難負(fù)樣本挖掘(hard-negative mining)”、“邊界框回歸”、“語境啟動”等重要技術(shù)以提高檢測精度。而為了加快檢測速度,Girshick開發(fā)了一種技術(shù),將檢測模型“ 編譯 ”成一個更快的模型,實現(xiàn)了級聯(lián)結(jié)構(gòu),在不犧牲任何精度的情況下實現(xiàn)了超過10倍的加速。
雖然今天的目標(biāo)探測器在檢測精度方面已經(jīng)遠(yuǎn)遠(yuǎn)超過了DPM,但仍然受到DPM的許多有價值的見解的影響,如混合模型、困難負(fù)樣本挖掘、邊界框回歸等。2010年,P. Felzenszwalb和R. Girshick被授予PASCAL VOC的 “終身成就獎”。
2、基于卷積神經(jīng)網(wǎng)絡(luò)的雙級檢測器
隨著手動選取特征技術(shù)的性能趨于飽和,目標(biāo)檢測在2010年之后達(dá)到了一個平穩(wěn)的發(fā)展期。2012年,卷積神經(jīng)網(wǎng)絡(luò)在世界范圍內(nèi)重新煥發(fā)生機(jī)[15]。由于深卷積網(wǎng)絡(luò)能夠?qū)W習(xí)圖像的魯棒性和高層次特征表示,一個自然而然的問題是:我們能否將其應(yīng)用到目標(biāo)檢測中?R. Girshick等人在2014年率先打破僵局,提出了具有CNN特征的區(qū)域(RCNN)用于目標(biāo)檢測[16]。從那時起,目標(biāo)檢測開始以前所未有的速度發(fā)展。在深度學(xué)習(xí)時代,目標(biāo)檢測可以分為兩類:“雙級檢測(two-stage detection)” 和 “單級檢測(one-stage detection)”,前者將檢測框定為一個“從粗到細(xì) ”的過程,而后者將其定義為“一步到位”。
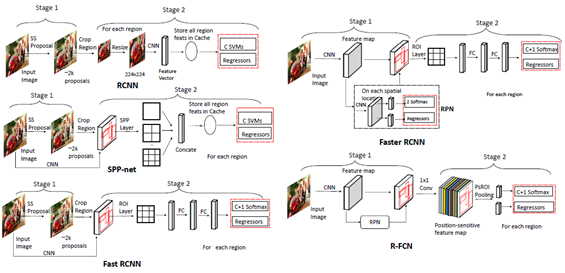
雙級檢測的發(fā)展及各類檢測器的結(jié)構(gòu)[2]
(1) RCNN
RCNN[17]的思路很簡單:它首先通過選擇性搜索來提取一組對象作為“提案(proposal)”并當(dāng)做對象的候選框。然后將每個提案重新調(diào)整成一個固定大小的圖像,再輸入到一個在ImageNet上訓(xùn)練得到的CNN模型(如AlexNet) 來提取特征。最后,利用線性SVM分類器對每個區(qū)域內(nèi)的目標(biāo)進(jìn)行預(yù)測,識別目標(biāo)類別。RCNN在VOC07測試集上有明顯的性能提升,平均精準(zhǔn)度 (mean Average Precision,mAP) 從33.7%(DPM-v5) 大幅提高到58.5%。
雖然RCNN已經(jīng)取得了很大的進(jìn)步,但它的缺點是顯而易見的:需要在大量重疊的提案上進(jìn)行冗余的特征計算 (一張圖片超過2000個框),導(dǎo)致檢測速度極慢(使用GPU時每張圖片耗時14秒)。同年晚些時候,有人提出了SPPNet并克服了這個問題。
(2) SPPNet
2014年,K. He等人提出了空間金字塔池化網(wǎng)絡(luò)( Spatial Pyramid Pooling Networks,SPPNet)[18]。以前的CNN模型需要固定大小的輸入,例如AlexNet需要224x224圖像。SPPNet的主要貢獻(xiàn)是引入了空間金字塔池化(SPP)層,它使CNN能夠生成固定長度的表示,而不需要重新調(diào)節(jié)有意義圖像的尺寸。利用SPPNet進(jìn)行目標(biāo)檢測時,只對整個圖像進(jìn)行一次特征映射計算,然后生成任意區(qū)域的定長表示以訓(xùn)練檢測器,避免了卷積特征的重復(fù)計算。SPPNet的速度是R-CNN的20多倍,并且沒有犧牲任何檢測精度(VOC07 mAP=59.2%)。
SPPNet雖然有效地提高了檢測速度,但仍然存在一些不足:第一,訓(xùn)練仍然是多階段的,第二,SPPNet只對其全連接層進(jìn)行微調(diào),而忽略了之前的所有層。而次年晚些時候出現(xiàn)Fast RCNN并解決了這些問題。
(3)?Fast RCNN
2015年,R. Girshick提出了Fast RCNN檢測器[19],這是對R-CNN和SPPNet的進(jìn)一步改進(jìn)。Fast RCNN使我們能夠在相同的網(wǎng)絡(luò)配置下同時訓(xùn)練檢測器和邊界框回歸器。在VOC07數(shù)據(jù)集上,F(xiàn)ast RCNN將mAP從58.5%( RCNN)提高到70.0%,檢測速度是R-CNN的200多倍。
雖然Fast-RCNN成功地融合了R-CNN和SPPNet的優(yōu)點,但其檢測速度仍然受到提案檢測的限制。然后,一個問題自然而然地出現(xiàn)了:“ 我們能用CNN模型生成對象提案嗎? ” 之后的Faster R-CNN解決了這個問題。
(4) Faster RCNN
2015年,S. Ren等人提出了Faster RCNN檢測器[20],在Fast RCNN之后不久。Faster RCNN 是第一個端到端的,也是第一個接近實時的深度學(xué)習(xí)檢測器(COCO [email protected]=42.7%,COCO mAP@[.5,.95]=21.9%, VOC07 mAP=73.2%,VOC12 mAP=70.4%)。Faster RCNN的主要貢獻(xiàn)是引入了區(qū)域提案網(wǎng)絡(luò) (RPN)從而允許幾乎所有的cost-free的區(qū)域提案。從RCNN到Faster RCNN,一個目標(biāo)檢測系統(tǒng)中的大部分獨立塊,如提案檢測、特征提取、邊界框回歸等,都已經(jīng)逐漸集成到一個統(tǒng)一的端到端學(xué)習(xí)框架中。
雖然Faster RCNN突破了Fast RCNN的速度瓶頸,但是在后續(xù)的檢測階段仍然存在計算冗余。后來提出了多種改進(jìn)方案,包括RFCN和 Light head RCNN。
(5) Feature Pyramid Networks(FPN)
2017年,T.-Y.Lin等人基于Faster RCNN提出了特征金字塔網(wǎng)絡(luò)(FPN)[21]。在FPN之前,大多數(shù)基于深度學(xué)習(xí)的檢測器只在網(wǎng)絡(luò)的頂層進(jìn)行檢測。雖然CNN較深層的特征有利于分類識別,但不利于對象的定位。為此,開發(fā)了具有橫向連接的自頂向下體系結(jié)構(gòu),用于在所有級別構(gòu)建高級語義。由于CNN通過它的正向傳播,自然形成了一個特征金字塔,F(xiàn)PN在檢測各種尺度的目標(biāo)方面顯示出了巨大的進(jìn)步。在基礎(chǔ)的Faster RCNN系統(tǒng)中使用FPN骨架可在無任何修飾的條件下在MS-COCO數(shù)據(jù)集上以單模型實現(xiàn)state-of-the-art 的效果(COCO [email protected]=59.1%,COCO mAP@[.5,.95]= 36.2%)。FPN現(xiàn)在已經(jīng)成為許多最新探測器的基本組成部分。
3、基于卷積神經(jīng)網(wǎng)絡(luò)的單級檢測器
?
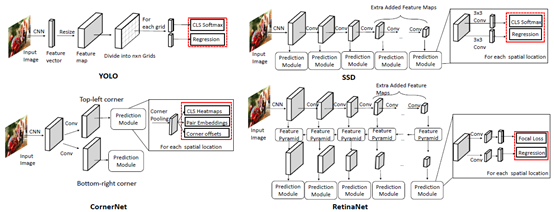
單階段檢測的發(fā)展及各類檢測器的結(jié)構(gòu)[2]
(1) You Only Look Once (YOLO)
YOLO由R. Joseph等人于2015年提出[22]。它是深度學(xué)習(xí)時代的第一個單級檢測器。YOLO非常快:YOLO的一個快速版本運行速度為155fps, VOC07 mAP=52.7%,而它的增強(qiáng)版本運行速度為45fps, VOC07 mAP=63.4%, VOC12 mAP=57.9%。YOLO是“ You Only Look Once ” 的縮寫。從它的名字可以看出,作者完全拋棄了之前的“提案檢測+驗證”的檢測范式。相反,它遵循一個完全不同的設(shè)計思路:將單個神經(jīng)網(wǎng)絡(luò)應(yīng)用于整個圖像。該網(wǎng)絡(luò)將圖像分割成多個區(qū)域,同時預(yù)測每個區(qū)域的邊界框和概率。后來R. Joseph在 YOLO 的基礎(chǔ)上進(jìn)行了一系列改進(jìn),其中包括以路徑聚合網(wǎng)絡(luò)(Path aggregation Network, PAN)取代FPN,定義新的損失函數(shù)等,陸續(xù)提出了其 v2、v3及v4版本(截止本文的2020年7月,Ultralytics發(fā)布了“YOLO v5”,但并沒有得到官方承認(rèn)),在保持高檢測速度的同時進(jìn)一步提高了檢測精度。??
必須指出的是,盡管與雙級探測器相比YOLO的探測速度有了很大的提高,但它的定位精度有所下降,特別是對于一些小目標(biāo)而言。YOLO的后續(xù)版本及在它之后提出的SSD更關(guān)注這個問題。
(2) Single Shot MultiBox Detector (SSD)
SSD由W. Liu等人于2015年提出[23]。這是深度學(xué)習(xí)時代的第二款單級探測器。SSD的主要貢獻(xiàn)是引入了多參考和多分辨率檢測技術(shù),這大大提高了單級檢測器的檢測精度,特別是對于一些小目標(biāo)。SSD在檢測速度和準(zhǔn)確度上都有優(yōu)勢(VOC07 mAP=76.8%,VOC12 mAP=74.9%, COCO [email protected]=46.5%,mAP@[.5,.95]=26.8%,快速版本運行速度為59fps) 。SSD與其他的檢測器的主要區(qū)別在于,前者在網(wǎng)絡(luò)的不同層檢測不同尺度的對象,而后者僅在其頂層運行檢測。
(3) RetinaNet
單級檢測器有速度快、結(jié)構(gòu)簡單的優(yōu)點,但在精度上多年來一直落后于雙級檢測器。T.-Y.Lin等人發(fā)現(xiàn)了背后的原因,并在2017年提出了RetinaNet[24]。他們的觀點為精度不高的原因是在密集探測器訓(xùn)練過程中極端的前景-背景階層不平衡(the extreme foreground-background class imbalance)現(xiàn)象。為此,他們在RetinaNet中引入了一個新的損失函數(shù) “ 焦點損失(focal loss)”,通過對標(biāo)準(zhǔn)交叉熵?fù)p失的重構(gòu),使檢測器在訓(xùn)練過程中更加關(guān)注難分類的樣本。焦損耗使得單級檢測器在保持很高的檢測速度的同時,可以達(dá)到與雙級檢測器相當(dāng)?shù)木取?COCO [email protected]=59.1%,mAP@[.5, .95]=39.1% )。
