
Python 疑難問題:[] 與 list() 哪個(gè)快?為什么快?快多少呢?

在日常使用 Python 時(shí),我們經(jīng)常需要?jiǎng)?chuàng)建一個(gè)列表,相信大家都很熟練了吧?
#?方法一:使用成對(duì)的方括號(hào)語法
list_a?=?[]
#?方法二:使用內(nèi)置的 list()
list_b?=?list()
上面的兩種寫法,你經(jīng)常使用哪一個(gè)呢?是否思考過它們的區(qū)別呢?
讓我們開門見山,直接拋出本文的問題吧:兩種創(chuàng)建列表的 [] 與 list() 寫法,哪一個(gè)更快呢,為什么它會(huì)更快呢?
注:為了簡化問題,我們以創(chuàng)建空列表為例進(jìn)行分析。關(guān)于列表的更多介紹與用法說明,可以查看這篇文章
1、 [] 是 list() 的三倍快
對(duì)于第一個(gè)問題,使用timeit模塊的 timeit() 函數(shù)就能簡單地測算出來:
>>>?import?timeit
>>>?timeit.timeit('[]',?number=10**7)
>>>?timeit.timeit('list()',?number=10**7)
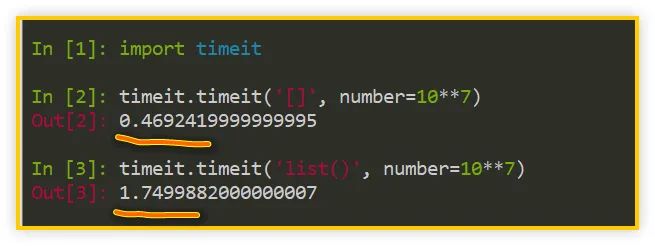
如上圖所示,在各自調(diào)用一千萬次的情況下,[] 創(chuàng)建方式只花費(fèi)了 0.47 秒,而 list() 創(chuàng)建方式要花費(fèi) 1.75 秒,所以,后者的耗時(shí)是前者的 3.7 倍!
這就回答了剛才的問題:創(chuàng)建空列表時(shí),[] 要比 list() 快不少。
注:timeit() 函數(shù)的效率跟運(yùn)行環(huán)境相關(guān),每次執(zhí)行結(jié)果會(huì)有微小差異。我在 Python3.8 版本實(shí)驗(yàn)了幾次,總體上 [] 速度是 list() 的 3 倍多一點(diǎn)。
2、list() 比 [] 執(zhí)行步驟多
那么,我們繼續(xù)來分析一下第二個(gè)問題:為什么 [] 會(huì)更快呢?
這一次我們可以使用dis模塊的 dis() 函數(shù),看看兩者執(zhí)行的字節(jié)碼有何差別:
>>>?from?dis?import?dis
>>>?dis("[]")
>>>?dis("list()")
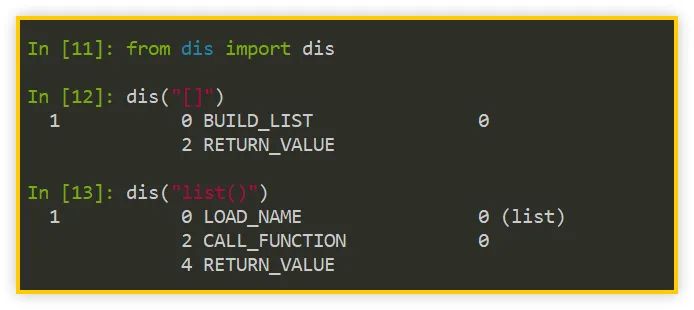
如上圖所示,[] 的字節(jié)碼有兩條指令(BUILD_LIST 與 RETURN_VALUE),而 list() 的字節(jié)碼有三條指令(LOAD_NAME、CALL_FUNCTION 與 RETURN_VALUE)。
這些指令意味著什么呢?該如何理解呢?
首先,對(duì)于 [],它是 Python 中的一組字面量(literal),像數(shù)字之類的字面量一樣,表示確切的固定值。
也就是說,Python 在解析到它時(shí),就知道它要表示一個(gè)列表,因此會(huì)直接調(diào)用解釋器中構(gòu)建列表的方法(對(duì)應(yīng)BUILD_LIST),來創(chuàng)建列表,所以是一步到位。
而對(duì)于 list(),“l(fā)ist”只是一個(gè)普通的名稱,并不是字面量,也就是說解釋器一開始并不認(rèn)識(shí)它。
因此,解釋器的第一步是要找到這個(gè)名稱(對(duì)應(yīng)LOAD_NAME)。它會(huì)按照一定的順序,在各個(gè)作用域中逐一查找(局部作用域--全局作用域--內(nèi)置作用域),直到找到為止,找不到則拋出NameError。
解釋器看到“l(fā)ist”之后是一對(duì)圓括號(hào),因此第二步是把這個(gè)名稱當(dāng)作可調(diào)用對(duì)象來調(diào)用,即把它當(dāng)成一個(gè)函數(shù)進(jìn)行調(diào)用(對(duì)應(yīng) CALL_FUNCTION)。
因此,list() 在創(chuàng)建列表時(shí),需要經(jīng)過名稱查找與函數(shù)調(diào)用兩個(gè)步驟,才能真正開始創(chuàng)建列表(注:CALL_FUNCTION 在底層還會(huì)有一些函數(shù)調(diào)用過程,才能走到跟 BUILD_LIST 相通的邏輯,此處我們忽略不計(jì))。
至此,我們就可以回答前面的問題了:因?yàn)?list() 涉及的執(zhí)行步驟更多,因此它比 [] 要慢一些。
3、list() 的速度提升
看完前兩個(gè)問題的解答過程,你也許覺得還不夠過癮,而且可能覺得就算知道了這個(gè)冷知識(shí),也不會(huì)有多大的幫助,似乎那微弱的提升顯得微不足道。
但是,我們Python貓出品的《Python為什么》系列一直秉承著孜孜不倦的求知精神,是不可能放著這個(gè)問題不去回答的。
而且,由于有發(fā)散性思考的習(xí)慣,我還想到了另外一個(gè)挺有意思的問題:list() 的速度能否提升呢?
我不久前寫過一篇文章正好討論到這個(gè)問題,也就是在剛剛發(fā)布的 Python 3.9.0 版本中,它給 list() 實(shí)現(xiàn)了更快的 vectorcall 協(xié)議,因此執(zhí)行速度會(huì)有一定的提升。
感興趣的同學(xué)可以去 Python 官網(wǎng)下載 3.9 版本。
根據(jù)我多輪的測試結(jié)果,在新版本中運(yùn)行 list() 一千萬次,耗時(shí)大概在 1 秒左右,也就是 [] 運(yùn)行耗時(shí)的 2 倍,相比于前面接近 4 倍的數(shù)據(jù),當(dāng)前版本總體上是提升了不少。
至此,我們已回答完一連串的疑問,如果你覺得有收獲,請(qǐng)點(diǎn)贊支持!歡迎大家關(guān)注后續(xù)更多精彩內(nèi)容。
送書活動(dòng)中獎(jiǎng)讀者,請(qǐng)通過微信公眾號(hào)菜單欄-關(guān)于添加個(gè)人微信。
相關(guān)閱讀: