
[開放源代碼] 爬取微博用戶所有文章的爬蟲
? 點擊上方?月小水長?并?設為星標,第一時間接收干貨推送
在微博上發(fā)布的內容有的短文本+圖片(也就是微博),還有視頻,文章等形式,爬取用戶微博可以使用之前的源代碼文章:一個爬取用戶所有微博的爬蟲,還能斷網(wǎng)續(xù)爬那種
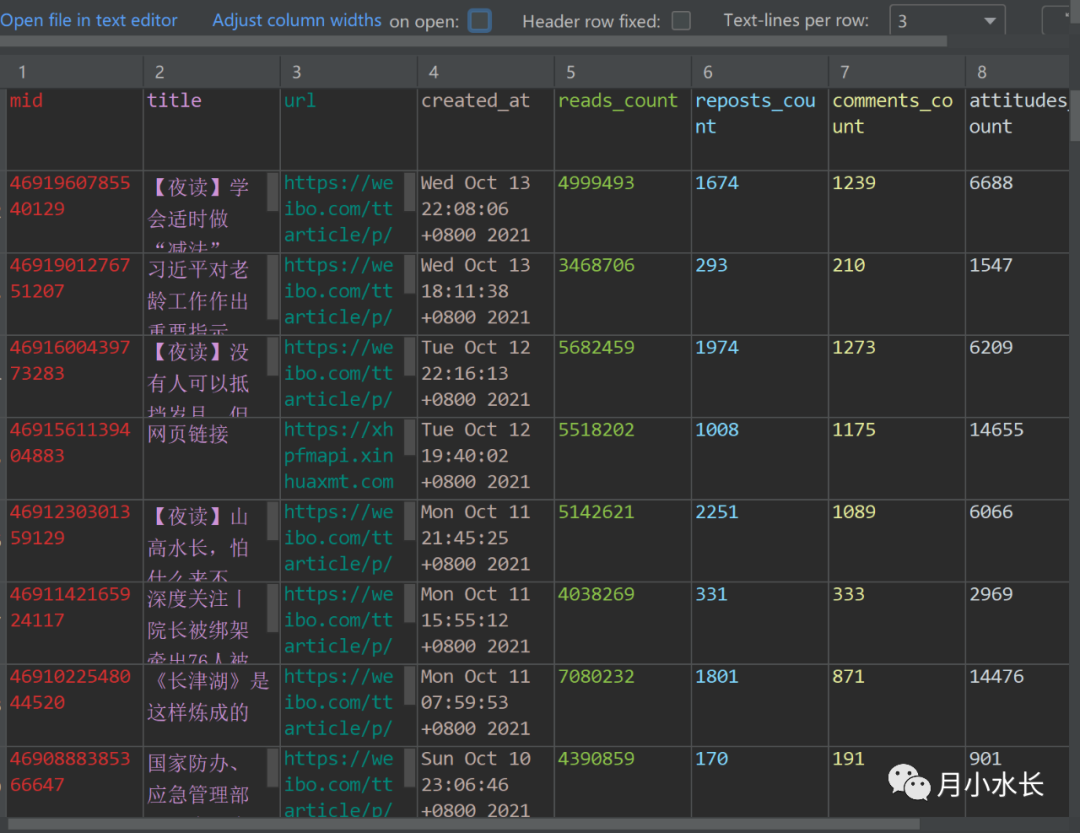
本次分享的是如何爬取用戶的所有文章。有文章標題,id,內容,發(fā)布時間,閱讀數(shù),評論數(shù),點贊數(shù),圖片鏈接等字段或信息,并開放源代碼。
下面以【共青團中央】微博為 target,抓取該賬號發(fā)布的所有文章,大部分都是深度好文,值得保存起來細細品讀。
https://weibo.com/u/3937348351?tabtype=articlehttps://weibo.com/ajax/statuses/mymblog在 Filter 框輸入 mymlog 就能過濾出此類請求,然后在請求上右鍵 ?Copy?as cURL(bash),方便自動轉換成爬蟲代碼,具體可以參見不寫一行,自動生成爬蟲代碼,自動生成的代碼如下
import requestsheaders = {'authority': 'weibo.com','sec-ch-ua': '"Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"','x-xsrf-token': 'M5-ZNBqYi4YtNkfZ8nh_Oz_0','traceparent': '00-348dc482c55e89d8cded23aaa7d56105-8f3e5ce7e78653bc-00','sec-ch-ua-mobile': '?0','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36','accept': 'application/json, text/plain, */*','x-requested-with': 'XMLHttpRequest','sec-ch-ua-platform': '"Windows"','sec-fetch-site': 'same-origin','sec-fetch-mode': 'cors','sec-fetch-dest': 'empty','referer': 'https://weibo.com/u/3937348351?tabtype=article','accept-language': 'zh-CN,zh;q=0.9,en-CN;q=0.8,en;q=0.7,es-MX;q=0.6,es;q=0.5',????'cookie':?'看不見我',}params = (('uid', '3937348351'),('page', '2'),('feature', '10'),)response?=?requests.get('https://weibo.com/ajax/statuses/mymblog',?headers=headers,?params=params)
我們第一步要做的事情是將 params 改成如下的字典形式
params = {'uid': '1516153080','page': '1','feature': '10',}
評論
圖片
表情