
任何網(wǎng)絡(luò)都能山寨!新型黑盒對(duì)抗攻擊可模擬未知網(wǎng)絡(luò)進(jìn)行攻擊 | CVPR 2021

來源:AI科技評(píng)論 本文約3500字,建議閱讀9分鐘
本文解讀對(duì)抗攻擊與元學(xué)習(xí)聯(lián)姻的兩篇典型的論文。
SimulatorAttack論文鏈接:
https://arxiv.org/abs/2009.00960
SimulatorAttack代碼鏈接:
https://github.com/machanic/SimulatorAttack
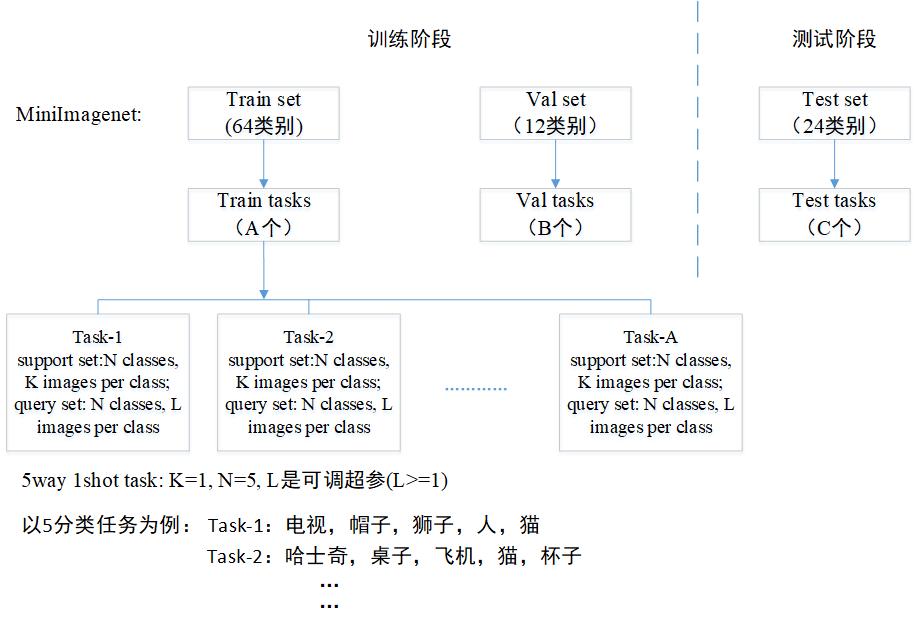
圖1 一個(gè)典型的元學(xué)習(xí)將數(shù)據(jù)切分成task訓(xùn)練,而每個(gè)task包含的5個(gè)分類不同,1-shot是指每個(gè)分類只有一個(gè)樣本。
 。而外部更新利用作為網(wǎng)絡(luò)參數(shù),輸入query set的數(shù)據(jù),計(jì)算一個(gè)對(duì)
。而外部更新利用作為網(wǎng)絡(luò)參數(shù),輸入query set的數(shù)據(jù),計(jì)算一個(gè)對(duì) ,而外部更新利用作為網(wǎng)絡(luò)參數(shù)去計(jì)算loss,這個(gè)loss最后用來計(jì)算元梯度來外部更新。
,而外部更新利用作為網(wǎng)絡(luò)參數(shù)去計(jì)算loss,這個(gè)loss最后用來計(jì)算元梯度來外部更新。3.1 模擬器的訓(xùn)練
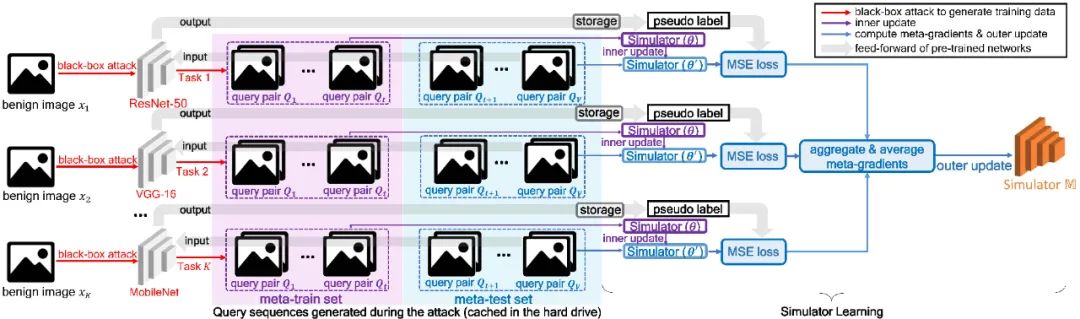 。然后,損失函數(shù)值
。然后,損失函數(shù)值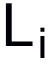 通過輸入第i個(gè)task的meta-test set到網(wǎng)絡(luò)而得到。之后,元梯度(meta-gradient)
通過輸入第i個(gè)task的meta-test set到網(wǎng)絡(luò)而得到。之后,元梯度(meta-gradient) 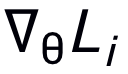 對(duì)
對(duì)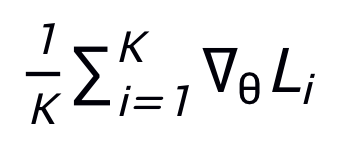 來更新模擬器(外部更新),由此模擬器可以學(xué)到泛化的模擬任意網(wǎng)絡(luò)的能力。
來更新模擬器(外部更新),由此模擬器可以學(xué)到泛化的模擬任意網(wǎng)絡(luò)的能力。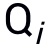 的兩個(gè)query
的兩個(gè)query 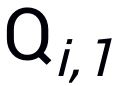 和
和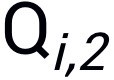 (由于Bandits攻擊使用有限差分法去估計(jì)梯度,因此每次迭代生成一個(gè)query pair)。模擬器和隨機(jī)選擇的分類網(wǎng)絡(luò)的logits輸出分別記為
(由于Bandits攻擊使用有限差分法去估計(jì)梯度,因此每次迭代生成一個(gè)query pair)。模擬器和隨機(jī)選擇的分類網(wǎng)絡(luò)的logits輸出分別記為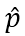 和
和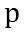 。如下MSE損失函數(shù)將使得模擬器的輸出和偽標(biāo)簽趨近于一致。
。如下MSE損失函數(shù)將使得模擬器的輸出和偽標(biāo)簽趨近于一致。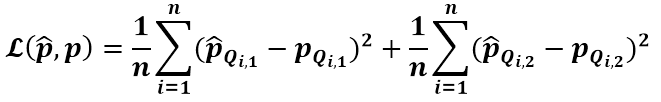
3.2 模擬器攻擊
 收集這些輸入和輸出。在warm-up之后的迭代中,每隔m次迭代才使用一次目標(biāo)模型,其余迭代一律輸入使用模擬器來輸出。因此目標(biāo)模型和模擬器的使用是輪流交替進(jìn)行的,這種方法一方面保證了大部分查詢壓力被轉(zhuǎn)移到模擬器中,另一方面保證了模擬器每隔m次迭代就得到機(jī)會(huì)fine-tune一次,這保證了后期的迭代中模擬器能“跟得上不斷演化的query的節(jié)奏,及時(shí)與目標(biāo)模型保持一致”。
收集這些輸入和輸出。在warm-up之后的迭代中,每隔m次迭代才使用一次目標(biāo)模型,其余迭代一律輸入使用模擬器來輸出。因此目標(biāo)模型和模擬器的使用是輪流交替進(jìn)行的,這種方法一方面保證了大部分查詢壓力被轉(zhuǎn)移到模擬器中,另一方面保證了模擬器每隔m次迭代就得到機(jī)會(huì)fine-tune一次,這保證了后期的迭代中模擬器能“跟得上不斷演化的query的節(jié)奏,及時(shí)與目標(biāo)模型保持一致”。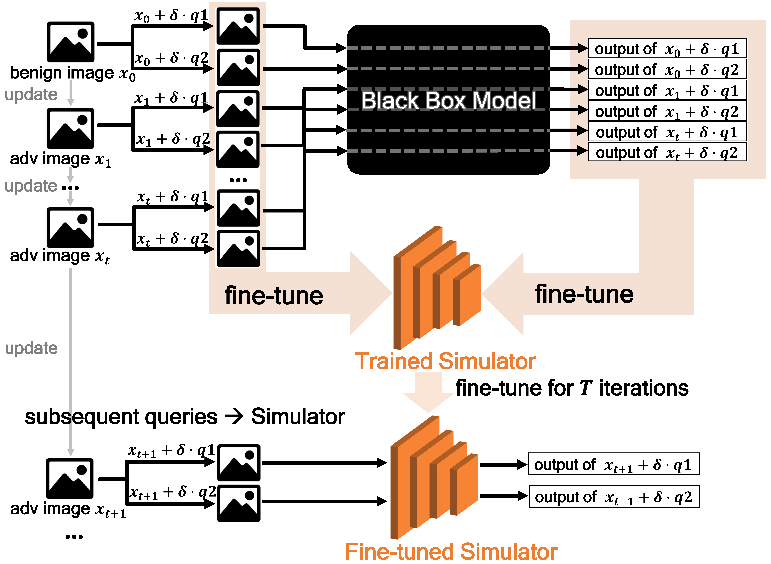
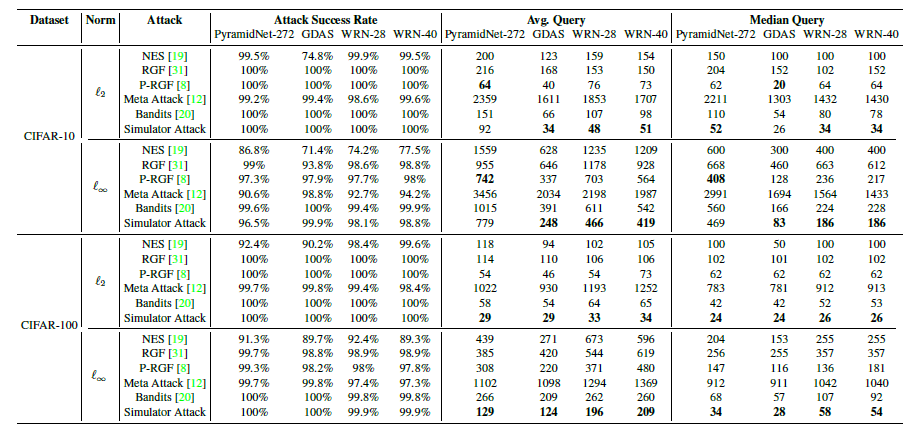
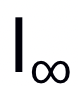 范數(shù)下的untargeted attack攻擊TinyImageNet的實(shí)驗(yàn)結(jié)果
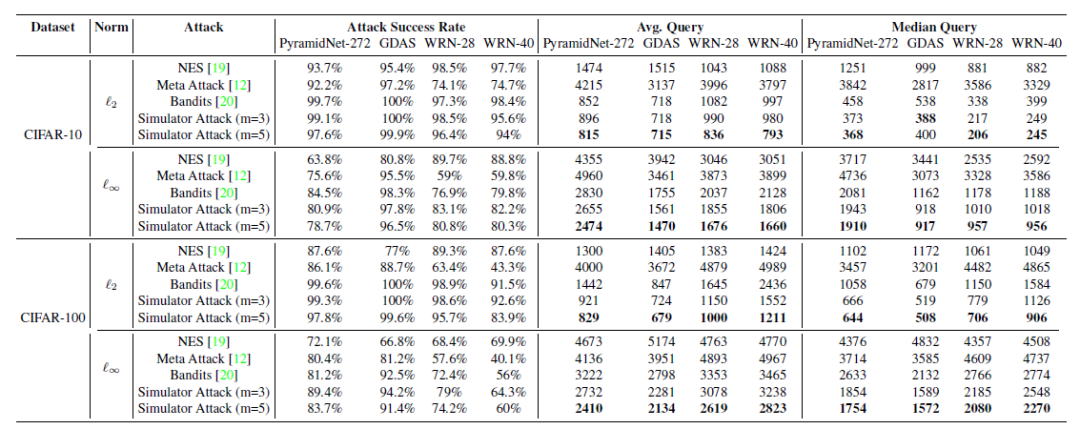
范數(shù)下的untargeted attack攻擊TinyImageNet的實(shí)驗(yàn)結(jié)果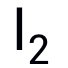 范數(shù)下的targeted attack攻擊TinyImageNet的實(shí)驗(yàn)結(jié)果
范數(shù)下的targeted attack攻擊TinyImageNet的實(shí)驗(yàn)結(jié)果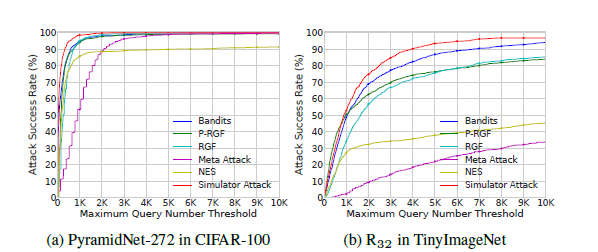
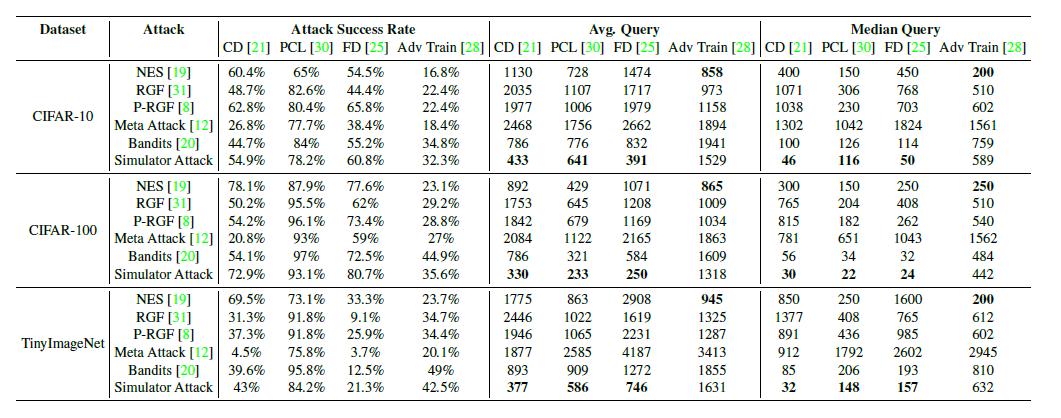 范數(shù)攻擊防御模型的結(jié)果,所有防御模型皆選擇ResNet-50 backbone
范數(shù)攻擊防御模型的結(jié)果,所有防御模型皆選擇ResNet-50 backbone評(píng)論
圖片
表情