
微服務(wù)架構(gòu)如何避免大規(guī)模故障?
點(diǎn)擊關(guān)注公眾號(hào),Java干貨及時(shí)送達(dá)
微服務(wù)架構(gòu)通過一種良好的服務(wù)邊界劃分,能夠有效地進(jìn)行故障隔離。但就像其他分布式系統(tǒng)一樣,在網(wǎng)絡(luò)、硬件或者應(yīng)用級(jí)別上容易出現(xiàn)問題的機(jī)率會(huì)更高。服務(wù)的依賴關(guān)系,導(dǎo)致在任何組件暫時(shí)不可用的情況下,就它們的消費(fèi)者而言都是可以接受的。為了能夠降低部分服務(wù)中斷所帶來的影響,我們需要構(gòu)建一個(gè)容錯(cuò)服務(wù),來優(yōu)雅地應(yīng)對(duì)特定類型的服務(wù)中斷。
本文基于一些在RisingStack的顧問咨詢與開發(fā)經(jīng)驗(yàn),介紹了如何運(yùn)用一些最常用的技術(shù)和架構(gòu)模型,去構(gòu)建與維護(hù)一個(gè)高可用的微服務(wù)系統(tǒng)。
如果你不熟悉本文中的模式,并不意味著你做錯(cuò)了什么。畢竟構(gòu)建一個(gè)高可用的系統(tǒng)需要很多額外的付出。
*微服務(wù)架構(gòu)的風(fēng)險(xiǎn) The Risk of the Microservices Architecture
微服務(wù)的架構(gòu)將應(yīng)用的邏輯移動(dòng)到一個(gè)服務(wù)里面,服務(wù)之間通過網(wǎng)絡(luò)層進(jìn)行通信交互。通過網(wǎng)絡(luò)通信交互的方式取代了內(nèi)存的調(diào)用,同時(shí)需要多個(gè)物理和邏輯組件之間的相互協(xié)作,給系統(tǒng)帶來了額外的延遲性與復(fù)雜性。分布式系統(tǒng)復(fù)雜性的增加,導(dǎo)致了特定網(wǎng)絡(luò)故障的可能性變得更大。
微服務(wù)允許你實(shí)現(xiàn)優(yōu)雅的服務(wù)降級(jí),因?yàn)榻M件可以被單獨(dú)的設(shè)置為失敗。
團(tuán)隊(duì)可以獨(dú)立地設(shè)計(jì)、開發(fā)與部署他們的服務(wù),是微服務(wù)的最大優(yōu)點(diǎn)之一。他們完全擁有整個(gè)服務(wù)的生命周期,這也意味著團(tuán)隊(duì)無法控制他們的服務(wù)依賴,因?yàn)檫@些服務(wù)更有可能是不同的團(tuán)隊(duì)在管理。我們需要記住,提供者的服務(wù)由于發(fā)布中斷、配置等等其他的改變而暫時(shí)不可用,他們是由別人控制,并且組件之間獨(dú)立活動(dòng)。
*優(yōu)雅的服務(wù)降級(jí) Graceful Service Degradation
微服務(wù)最佳優(yōu)勢(shì)之一,當(dāng)某個(gè)組件單獨(dú)失敗時(shí),你可以實(shí)現(xiàn)優(yōu)雅的服務(wù)降級(jí),進(jìn)行故障隔離。例如,一個(gè)照片共享的應(yīng)用,由于中斷,用戶可能無法上傳新的照片,但他們?nèi)匀豢梢詾g覽、編輯和分享他們現(xiàn)有的照片。
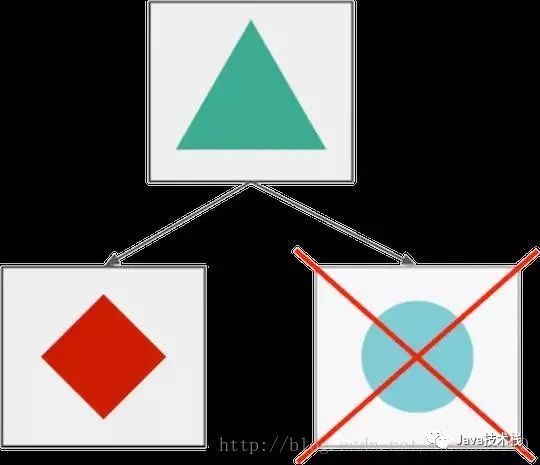
在大多數(shù)情況下,在一個(gè)分布式系統(tǒng)中,應(yīng)用程序之間互相依賴,實(shí)現(xiàn)一種優(yōu)雅的服務(wù)降級(jí),這是很困難的,你需要采取多種故障切換邏輯(其中一些會(huì)在本文后面進(jìn)行討論),應(yīng)對(duì)臨時(shí)的故障與中斷。
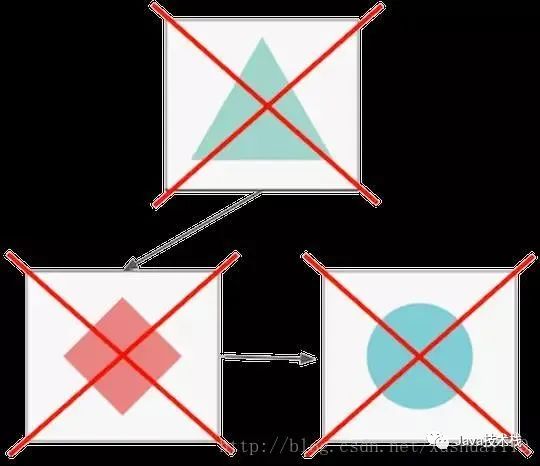
*變更管理 Change management
谷歌網(wǎng)站的可靠性團(tuán)隊(duì)(SRE)發(fā)現(xiàn),大約70%的中斷是由一個(gè)實(shí)時(shí)系統(tǒng)的改變而引起。當(dāng)你在服務(wù)中更改某些內(nèi)容時(shí)——你部署了新版本的代碼或更改了一些配置——總會(huì)導(dǎo)致更高的失敗機(jī)率或者引入一個(gè)新的bug。
在微服務(wù)架構(gòu)中,服務(wù)之間彼此依賴。這就是為什么你應(yīng)該盡量減少失敗,并限制它們的負(fù)面影響。如果要處理來自變更的問題,你可以使用變更管理策略和自動(dòng)升級(jí)。
例如,當(dāng)需要部署新代碼或者更改某些配置時(shí),你應(yīng)該逐漸地將這些更改應(yīng)用于實(shí)例的子集,監(jiān)控它們,甚至當(dāng)你看到關(guān)鍵指標(biāo)有負(fù)面影響時(shí),它們會(huì)自動(dòng)回滾恢復(fù)。
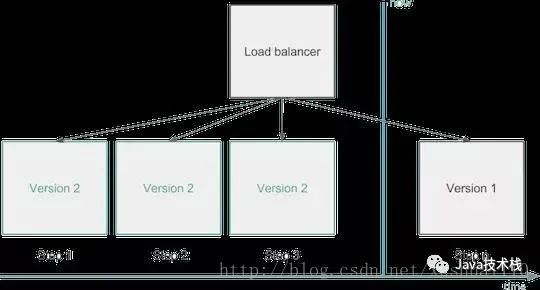
另一個(gè)解決方案,就是運(yùn)行兩個(gè)生產(chǎn)環(huán)境。只部署其中一個(gè),并且在驗(yàn)證新版本的運(yùn)行符合預(yù)期之后,才會(huì)將負(fù)載均衡指向新版本。這被稱為藍(lán)綠色部署,或紅黑色部署。
恢復(fù)代碼不是一件壞事情。你不應(yīng)該把壞的代碼留在生產(chǎn)中,然后再思考哪里出了問題。必要的時(shí)候,總是要恢復(fù)你的改變(回滾),越快越好。
*健康檢查與負(fù)載均衡 Health-check and Load Balancing
實(shí)例會(huì)因?yàn)槭 ⒉渴鸹蜃詣?dòng)伸縮,而不斷地啟動(dòng)、重新啟動(dòng)和停止。這會(huì)導(dǎo)致服務(wù)暫時(shí)或永久不可用。為了避免問題,你的負(fù)載均衡應(yīng)該跳過不健康的實(shí)例,因?yàn)樗鼈儾荒軡M足你的用戶或子系統(tǒng)的需要。
應(yīng)用實(shí)例健康可以通過外部觀察來決策。你可以反復(fù)調(diào)用 GET /health 請(qǐng)求埋點(diǎn)或自身報(bào)告。現(xiàn)代服務(wù)發(fā)現(xiàn)解決方案,將不斷從實(shí)例中收集健康信息,并配置負(fù)載均衡以保證健康的組件路由流量。
*自愈 Self-healing
自我修復(fù)可以幫助恢復(fù)應(yīng)用程序。我們談?wù)摰淖杂侵笐?yīng)用程序可以做一些必要的步驟來恢復(fù)崩潰狀態(tài)。在大多數(shù)情況下,這樣的操作是經(jīng)由一個(gè)外部系統(tǒng)來實(shí)現(xiàn)的,它會(huì)監(jiān)控實(shí)例的健康,并在它們較長時(shí)間處于錯(cuò)誤狀態(tài)的情況下,重新啟動(dòng)應(yīng)用程序。自愈是非常有用的,但是在某些情況下,不斷地重啟應(yīng)用程序會(huì)引起麻煩。由于負(fù)載過高或者數(shù)據(jù)庫連接超時(shí),你的應(yīng)用程序不停的重啟,會(huì)導(dǎo)致無法提供一個(gè)正確的健康狀態(tài)。
實(shí)現(xiàn)一種為微妙的情況而準(zhǔn)備的高級(jí)自我修復(fù)解決方案,可能會(huì)很棘手,比如數(shù)據(jù)庫連接丟失。在這種情況下,你需要為應(yīng)用程序添加額外的邏輯來處理一些極端情況,并讓外部系統(tǒng)知道不需要立即重啟實(shí)例。
*故障切換緩存 Failover Caching
服務(wù)通常會(huì)因?yàn)榫W(wǎng)絡(luò)問題和系統(tǒng)的變更而失敗。由于自愈和先進(jìn)的負(fù)載均衡,大多數(shù)中斷只是暫時(shí)的,然而我們還應(yīng)該找到一個(gè)解決方案,讓我們的服務(wù)在這些故障中能夠正常工作。這就是故障切換緩存,它可以幫助應(yīng)用程序提供一些必要的數(shù)據(jù)。
故障切換緩存一般使用兩個(gè)不同的過期時(shí)間。設(shè)置一個(gè)較短的時(shí)間,顯示在正常情況下可以使用多長時(shí)間的緩存;設(shè)置另一個(gè)較長的時(shí)間,顯示在發(fā)生故障期間,可供使用緩存數(shù)據(jù)的時(shí)間會(huì)有多久。
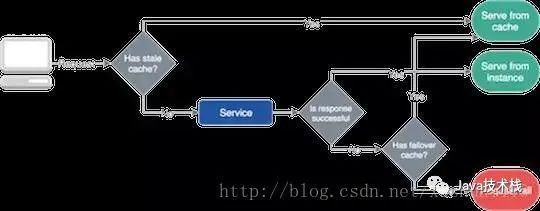
很重要的一點(diǎn)是,只有當(dāng)過時(shí)的數(shù)據(jù)比什么都不做要好的情況出現(xiàn)時(shí),才可運(yùn)行故障切換緩。
可以通過使用HTTP中的標(biāo)準(zhǔn)響應(yīng)頭(response header)來設(shè)置緩存和故障轉(zhuǎn)移緩存。另外,HTTP 系列面試題和答案全部整理好了,微信搜索Java技術(shù)棧,在后臺(tái)發(fā)送:面試,可以在線閱讀。
例如,通過設(shè)定 header 參數(shù) max-age 來指定一個(gè)資源被刷新時(shí)最大時(shí)間;也可以通過設(shè)定 header 參數(shù) stale-if-error 來決定,在服務(wù)失敗的情況下,需要多長時(shí)間從緩存獲取數(shù)據(jù)。
現(xiàn)代的CDN和負(fù)載均衡器提供了各種緩存和故障切換的方式,你也可以為公司建立一個(gè)包含了統(tǒng)一的可靠性解決方案的共享標(biāo)準(zhǔn)庫。
*重試機(jī)制 Retry Logic
在某些特定的場(chǎng)景下,我們可能無法緩存數(shù)據(jù),或者我們想對(duì)其做出一些更改,但是我們的操作最終還是會(huì)失敗。在這些情況下,我們可以重新嘗試我們的操作,因?yàn)槲覀兛梢灶A(yù)計(jì)資源在一段時(shí)間后會(huì)恢復(fù),或者我們的負(fù)載均衡將我們的請(qǐng)求轉(zhuǎn)發(fā)到一個(gè)健康的實(shí)例。
在應(yīng)用程序和客戶端添加重試邏輯需保持謹(jǐn)慎,因?yàn)榇罅康闹卦嚂?huì)讓事情變得更糟,甚至?xí)柚箲?yīng)用程序的恢復(fù)。
在分布式系統(tǒng)中,微服務(wù)系統(tǒng)重試會(huì)觸發(fā)多個(gè)其他的請(qǐng)求或重試,引起一個(gè)級(jí)聯(lián)效應(yīng)。為了盡量減少重試帶來的影響,你應(yīng)該最大限度限制它們的發(fā)生次數(shù),并使用指數(shù)補(bǔ)償算法來持續(xù)增加重試之間的延遲。
重試由客戶端(瀏覽器,其他微服務(wù)等)發(fā)起,客戶端不知道這個(gè)操作是在處理請(qǐng)求之前失敗還是之后失敗的,你應(yīng)該準(zhǔn)備好應(yīng)用程序來處理冪等性(idempotency)。例如,當(dāng)操作重試購買時(shí),不應(yīng)該對(duì)用戶進(jìn)行重復(fù)扣費(fèi)。對(duì)于每個(gè)事務(wù),使用唯一的 冪等令牌(idempotency-key ),可以幫助處理重試。
*限流與降級(jí) Rate Limiters and Load Shedders
限流是指在一個(gè)時(shí)間段內(nèi),特定的用戶或應(yīng)用程序可以接收或處理多少請(qǐng)求的技術(shù)。例如,有了限流,你就可以找出引起流量高峰的用戶和微服務(wù),或者可以確保應(yīng)用不會(huì)在負(fù)載過高情況下,發(fā)生自動(dòng)擴(kuò)容都不能拯救。
你還可以限制業(yè)務(wù)優(yōu)先級(jí)較低的流量,以便為核心業(yè)務(wù)提供足夠的資源。
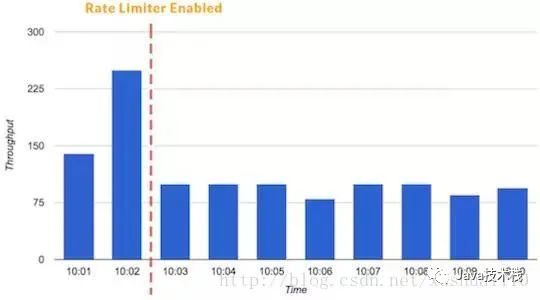
另外一種類型的限速器稱為并發(fā)請(qǐng)求限制。當(dāng)有一些昂貴的端點(diǎn)不應(yīng)該超過指定的調(diào)用次數(shù),但你仍然希望提供流量服務(wù)時(shí),選擇這樣的操作是很有用的。
快速降級(jí)可以確保總是有足夠的可用資源去服務(wù)關(guān)鍵的事務(wù)。它為高優(yōu)先級(jí)請(qǐng)求保留一些資源,并且不允許低優(yōu)先級(jí)事務(wù)使用所有的資源。降級(jí)與否是根據(jù)系統(tǒng)的整個(gè)狀態(tài)進(jìn)行判斷的,而不是基于單個(gè)用戶的請(qǐng)求桶大小。服務(wù)降級(jí)用于幫助恢復(fù)系統(tǒng),當(dāng)發(fā)生一些事故時(shí),它們可以保證核心功能仍然繼續(xù)工作。
如需獲取更多有關(guān)限流與降級(jí)的信息,推薦前往https://stripe.com/blog/rate-limiters,閱讀Stripe的文章。另外,微服務(wù)系列面試題和答案全部整理好了,微信搜索Java技術(shù)棧,在后臺(tái)發(fā)送:面試,可以在線閱讀。
*快速且獨(dú)立地失敗 Fail Fast and Independently
在微服務(wù)體系結(jié)構(gòu)中,我們希望我們的服務(wù)能夠快速、獨(dú)立地失敗。為了在服務(wù)級(jí)別上隔離問題,我們可以采用艙壁模式(bulkhead pattern)。你稍后可以在這篇文章中讀到更多關(guān)于艙壁的信息。
我們還希望我們的組件快速失敗,因?yàn)槲覀儾幌氲却龎牡膶?shí)例超時(shí)。沒有什么比一個(gè)掛著的請(qǐng)求和一個(gè)沒有響應(yīng)的UI更令人失望的了。這樣不僅浪費(fèi)資源,而且還會(huì)對(duì)用戶體驗(yàn)造成影響。我們的服務(wù)是相互調(diào)用的,所以更應(yīng)該額外注意,在這些延遲結(jié)束之前,阻止掛起操作。
第一個(gè)想到的想法是在每個(gè)服務(wù)調(diào)用上運(yùn)用一個(gè)較好級(jí)別的超時(shí)時(shí)間。這種方法的問題在于,你不可能真正知道什么是一個(gè)好的超時(shí)時(shí)間值,因?yàn)樵谀承┣闆r下,網(wǎng)絡(luò)故障和其他問題只會(huì)影響到一兩個(gè)操作。在這種情況下,如果只有少數(shù)幾個(gè)請(qǐng)求超時(shí),你可能不想拒絕這些請(qǐng)求。
我們可以說,在微服務(wù)中使用超時(shí)來實(shí)現(xiàn)快速失敗的例子是一種反模式,你應(yīng)該避免它。你可以依賴于操作成功/失敗統(tǒng)計(jì)數(shù)據(jù)的斷路器(circuit-breaker)模式,而不是超時(shí)。
*艙壁 Bulkheads
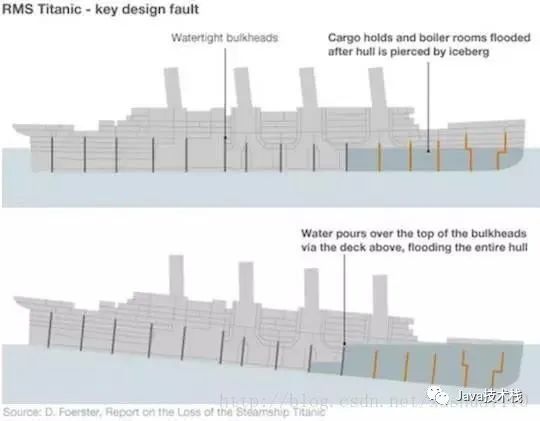
艙壁被用來將一艘船劃分成多個(gè)部分,這樣就可以在船體破裂的情況下對(duì)部分封閉。
隔離壁的概念可以應(yīng)用于軟件開發(fā)中,做到資源隔離。
通過采用艙壁模式,我們可以保護(hù)有限的資源不被耗盡。例如,如果我們有兩種操作,它們與相同的數(shù)據(jù)庫實(shí)例交互,我們的連接數(shù)量有限,那么我們可以使用兩個(gè)連接池,而不是共享連接池。由于此客戶端資源分離,當(dāng)發(fā)生超時(shí)或者過度使用連接池的操作,不會(huì)導(dǎo)致所有其他操作的關(guān)閉。
泰坦尼克號(hào)沉沒的主要原因之一,就是它的艙壁有一個(gè)設(shè)計(jì)上的失敗,水可以通過艙壁頂部上的甲板注入,淹沒整個(gè)船體。
*斷路器 Circuit Breakers
為了限制操作的持續(xù)時(shí)間,我們可以使用超時(shí)。超時(shí)可以防止掛起操作并保持系統(tǒng)響應(yīng)。然而,在微服務(wù)通信中使用靜態(tài)的、微調(diào)的超時(shí)是一種反模式,因?yàn)槲覀兲幵谝粋€(gè)高度動(dòng)態(tài)的環(huán)境中,幾乎不可能發(fā)現(xiàn)正確的時(shí)間限制,以確保在每個(gè)場(chǎng)景下都能很好地工作。
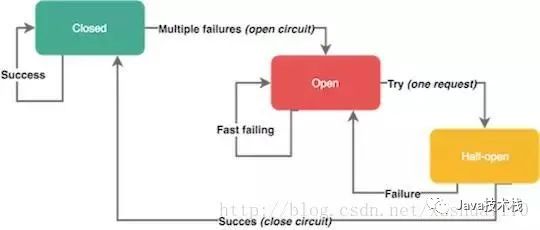
我們可以使用熔斷來處理錯(cuò)誤,而不是使用小的特定事務(wù)的靜態(tài)超時(shí)。斷路器是以真實(shí)世界電子元件命名的,因?yàn)樗鼈兊男袨槭窍嗤模ê唵蔚恼f,這種模式主要是參考電路熔斷,如果一條線路電壓過高,保險(xiǎn)絲會(huì)熔斷,防止火災(zāi))。你可以保護(hù)資源,幫助他們用斷路器恢復(fù)。它們?cè)诜植际较到y(tǒng)中非常有用,因?yàn)橹貜?fù)的失敗會(huì)導(dǎo)致滾雪球效應(yīng)(snowball effect),導(dǎo)致整個(gè)系統(tǒng)癱瘓。
當(dāng)一個(gè)特定類型的錯(cuò)誤在短時(shí)間內(nèi)多次出現(xiàn)時(shí),斷路器就會(huì)打開。斷路器的打開,阻止了進(jìn)一步的資源請(qǐng)求——就像真的阻止了電流的流動(dòng)。斷路器通常在一定時(shí)間后關(guān)閉,為基礎(chǔ)服務(wù)提供足夠的空間來恢復(fù)。
請(qǐng)記住,并非所有的錯(cuò)誤都應(yīng)該觸發(fā)斷路器。例如,你可能希望跳過客戶端問題,比如跳過 4xx 狀態(tài)碼響應(yīng)的請(qǐng)求,但不包括 5xx 服務(wù)器端錯(cuò)誤的請(qǐng)求。一些斷路器也可以有半開狀態(tài),在此狀態(tài)下,服務(wù)發(fā)送第一個(gè)請(qǐng)求檢測(cè)系統(tǒng)的可用性,同時(shí)讓其他請(qǐng)求失敗。如果第一個(gè)請(qǐng)求成功,它將斷路器恢復(fù)到一個(gè)關(guān)閉狀態(tài),并允許流量進(jìn)入。否則,它就會(huì)打開。
*測(cè)試失敗 Testing for Failures
你應(yīng)該不斷地測(cè)試你的系統(tǒng)以防止常見問題,以確保你的服務(wù)能夠承受住各種失敗。你應(yīng)該頻繁地測(cè)試失敗,讓你的團(tuán)隊(duì)為發(fā)生事故而做好準(zhǔn)備。
對(duì)于測(cè)試,你可以使用一個(gè)外部服務(wù)來標(biāo)識(shí)實(shí)例組,并隨機(jī)終止該組中的一個(gè)實(shí)例。有了這個(gè),你就可以為單個(gè)實(shí)例的失敗做準(zhǔn)備,你甚至可以關(guān)閉整個(gè)可用區(qū)來模擬云提供商的中斷。
最流行的測(cè)試解決方案之一是由Netflix提供的ChaosMonkey彈性工具。
*結(jié)尾
實(shí)現(xiàn)和運(yùn)行可靠的服務(wù)并不容易。這需要你付出很大的努力,也要花費(fèi)你的公司很多錢。
可靠性有很多的層次和方面,所以為你的團(tuán)隊(duì)找到最好的解決方案是很重要的。你應(yīng)該將可靠性作為業(yè)務(wù)決策過程中的一個(gè)因素,并為它分配足夠的預(yù)算和時(shí)間。
*主要收獲
動(dòng)態(tài)環(huán)境和分布式系統(tǒng)——比如微服務(wù)——會(huì)導(dǎo)致更大的失敗機(jī)率。 服務(wù)應(yīng)該單獨(dú)失敗,實(shí)現(xiàn)優(yōu)雅的降級(jí),用以改善用戶體驗(yàn)。 70%的中斷是由變更引起的,恢復(fù)代碼并不是件壞事。快速和獨(dú)立的失敗。團(tuán)隊(duì)無法控制他們服務(wù)的依賴。 架構(gòu)模式和技術(shù),如緩存、艙壁、限流、熔斷,有助于建立可靠的微服務(wù)。
原文:https://blog.risingstack.com/designing-microservices-architecture-for-failure/
譯文:https://blog.csdn.net/xushuai110/article/details/77726447







關(guān)注Java技術(shù)棧看更多干貨
