
機(jī)器學(xué)習(xí) 4 個(gè)超參數(shù)搜索方法、代碼
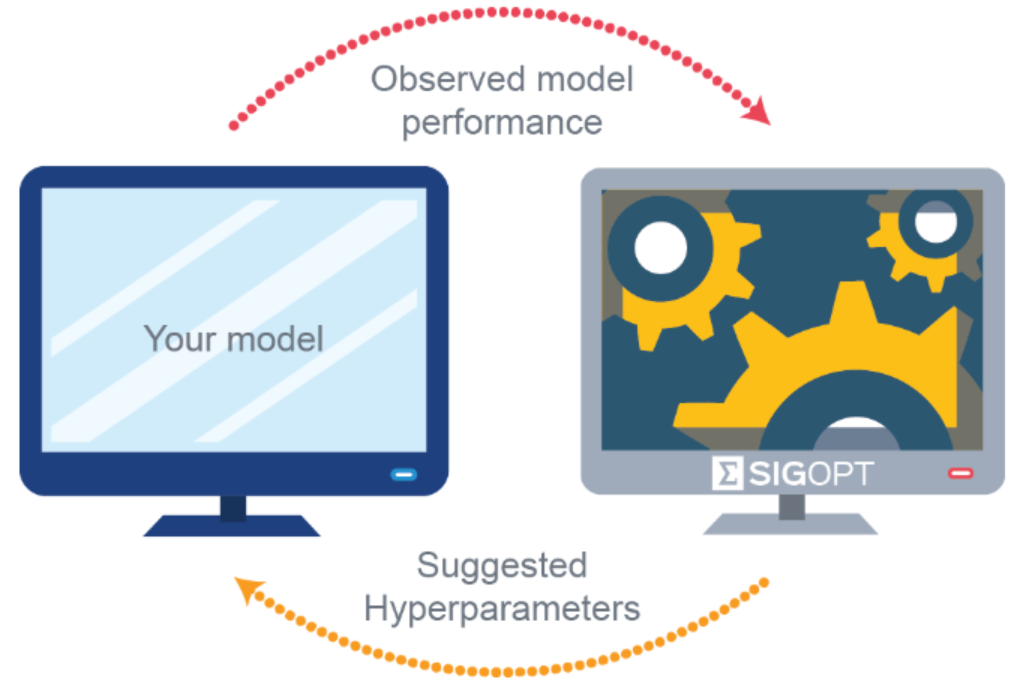
介紹
維基百科上說,“Hyperparameter optimization或tuning是為學(xué)習(xí)算法選擇一組最優(yōu)的hyperparameters的問題”。
超參數(shù)
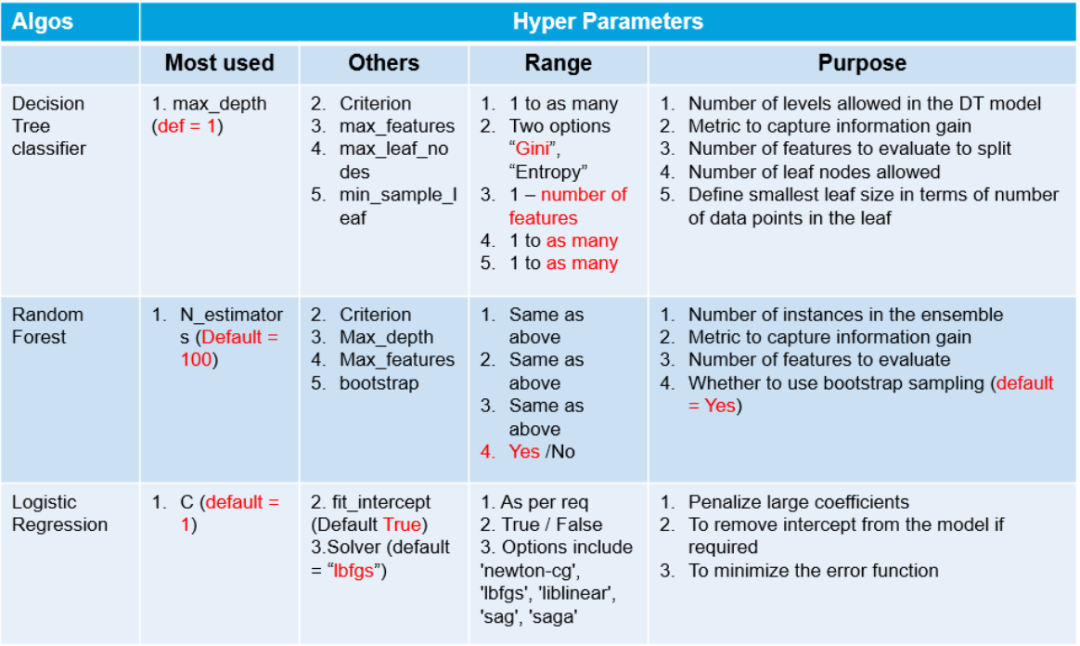
內(nèi)容
-
傳統(tǒng)的手工調(diào)參 -
網(wǎng)格搜索 -
隨機(jī)搜索 -
貝葉斯搜索
1. 傳統(tǒng)手工搜索
#importing required libraries
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold , cross_val_score
from sklearn.datasets import load_wine
wine = load_wine()
X = wine.data
y = wine.target
#splitting the data into train and test set
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3,random_state = 14)
#declaring parameters grid
k_value = list(range(2,11))
algorithm = ['auto','ball_tree','kd_tree','brute']
scores = []
best_comb = []
kfold = KFold(n_splits=5)
#hyperparameter tunning
for algo in algorithm:
for k in k_value:
knn = KNeighborsClassifier(n_neighbors=k,algorithm=algo)
results = cross_val_score(knn,X_train,y_train,cv = kfold)
print(f'Score:{round(results.mean(),4)} with algo = {algo} , K = {k}')
scores.append(results.mean())
best_comb.append((k,algo))
best_param = best_comb[scores.index(max(scores))]
print(f'\nThe Best Score : {max(scores)}')
print(f"['algorithm': {best_param[1]} ,'n_neighbors': {best_param[0]}]")
-
沒辦法確保得到最佳的參數(shù)組合。 -
這是一個(gè)不斷試錯(cuò)的過程,所以,非常的耗時(shí)。
2. 網(wǎng)格搜索
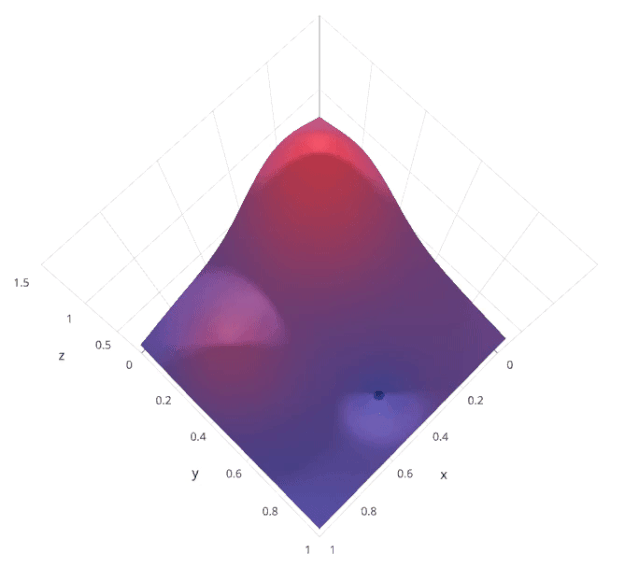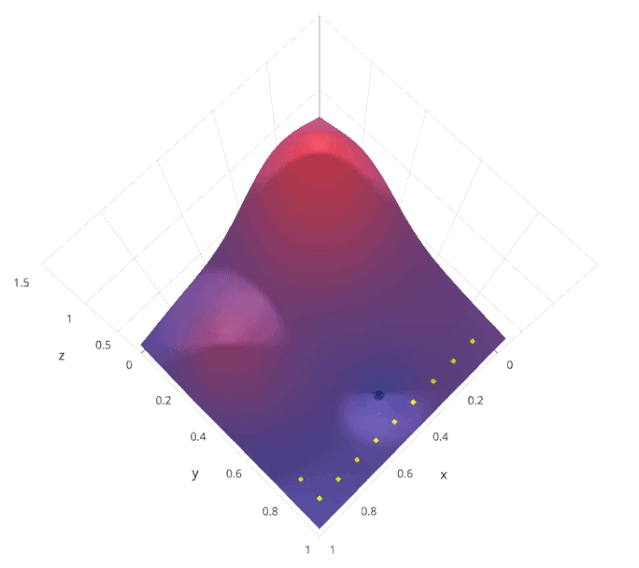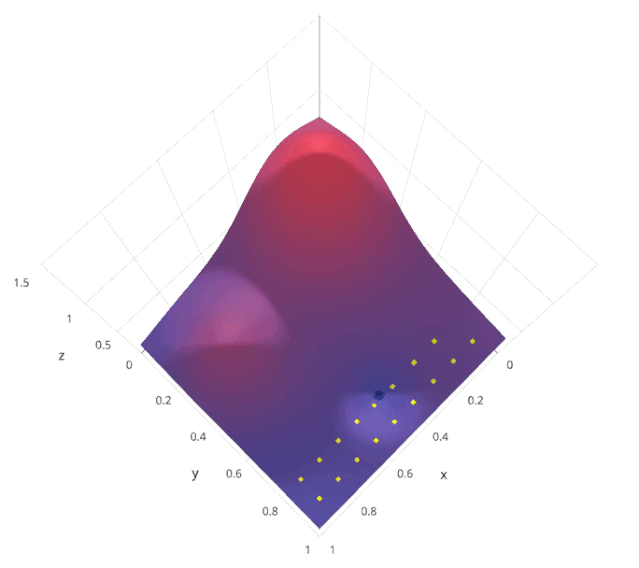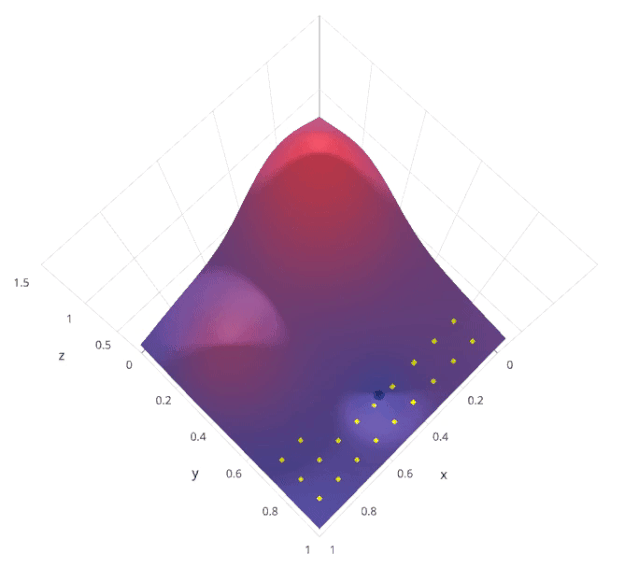
from sklearn.model_selection import GridSearchCV
knn = KNeighborsClassifier()
grid_param = { 'n_neighbors' : list(range(2,11)) ,
'algorithm' : ['auto','ball_tree','kd_tree','brute'] }
grid = GridSearchCV(knn,grid_param,cv = 5)
grid.fit(X_train,y_train)
#best parameter combination
grid.best_params_
#Score achieved with best parameter combination
grid.best_score_
#all combinations of hyperparameters
grid.cv_results_['params']
#average scores of cross-validation
grid.cv_results_['mean_test_score']
3. 隨機(jī)搜索
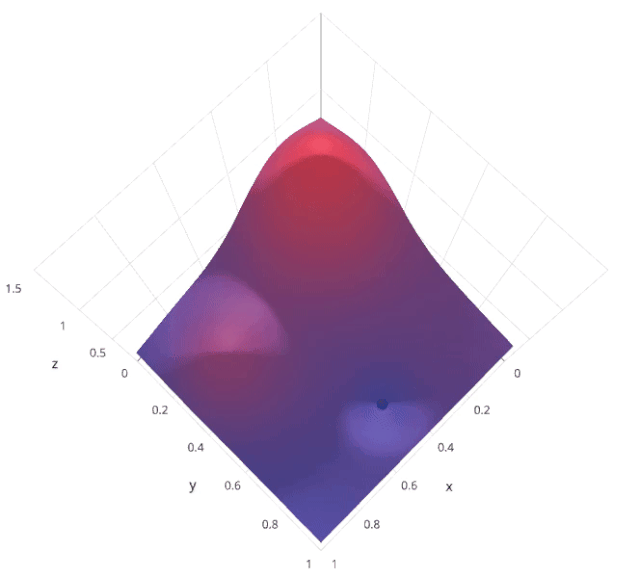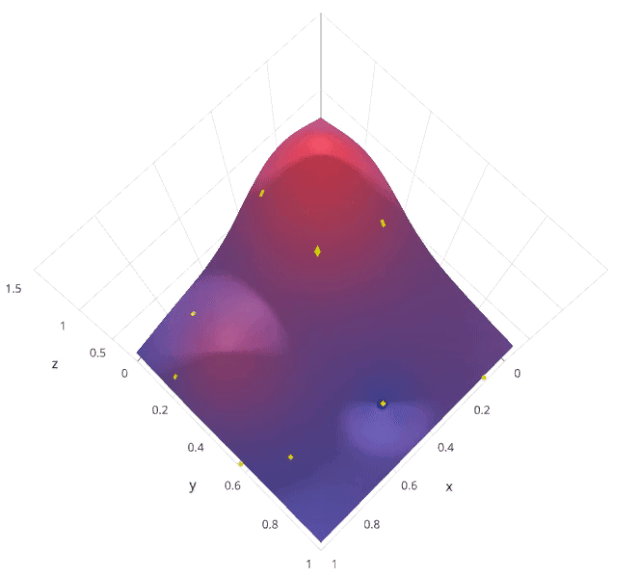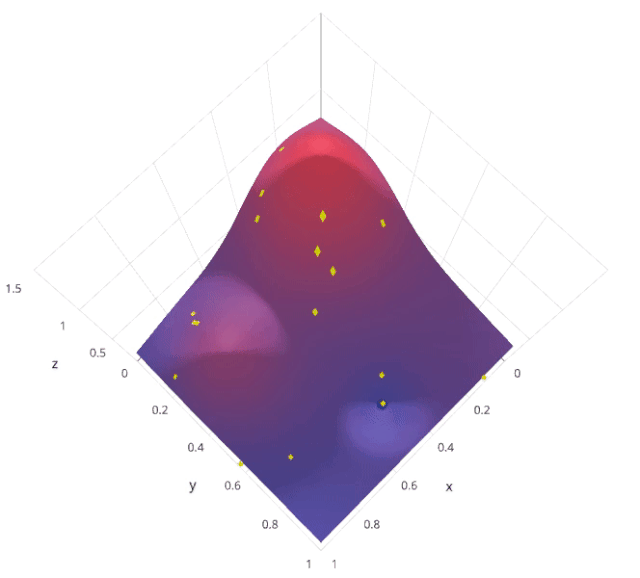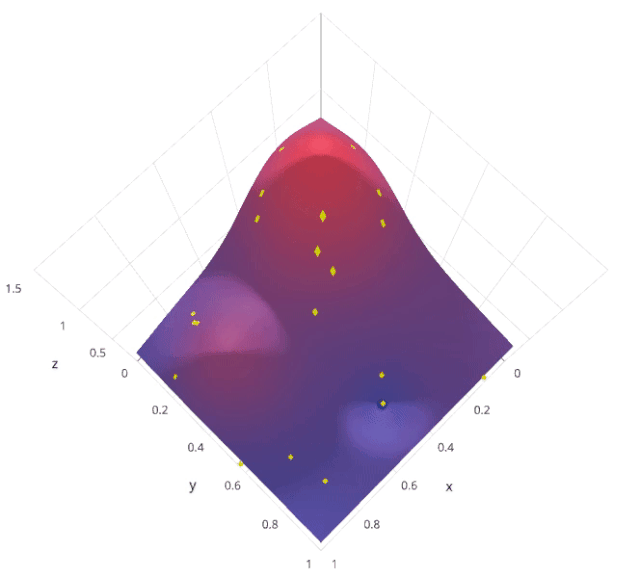
from sklearn.model_selection import RandomizedSearchCV
knn = KNeighborsClassifier()
grid_param = { 'n_neighbors' : list(range(2,11)) ,
'algorithm' : ['auto','ball_tree','kd_tree','brute'] }
rand_ser = RandomizedSearchCV(knn,grid_param,n_iter=10)
rand_ser.fit(X_train,y_train)
#best parameter combination
rand_ser.best_params_
#score achieved with best parameter combination
rand_ser.best_score_
#all combinations of hyperparameters
rand_ser.cv_results_['params']
#average scores of cross-validation
rand_ser.cv_results_['mean_test_score']
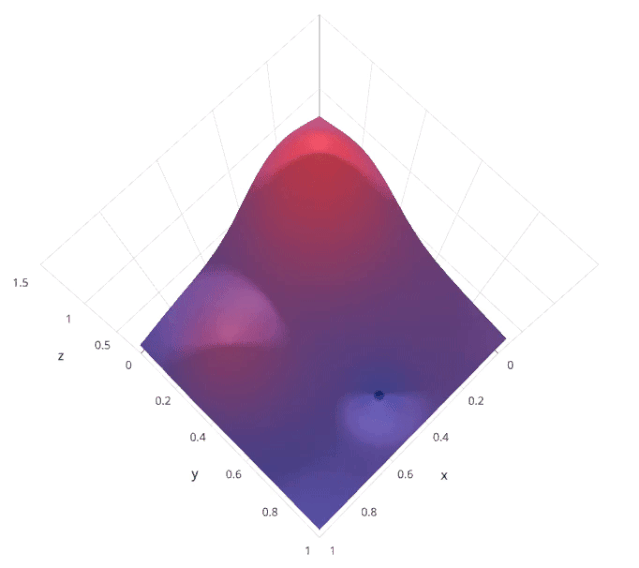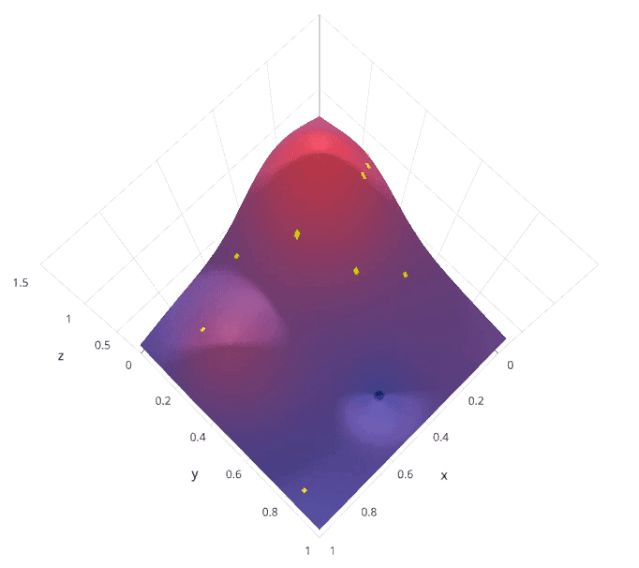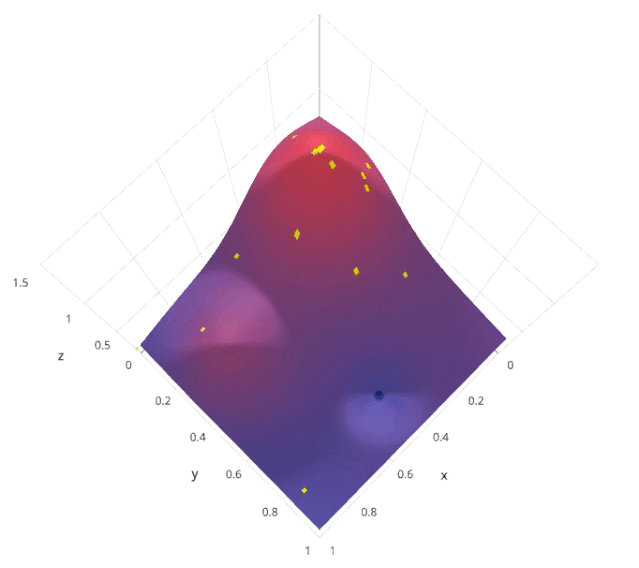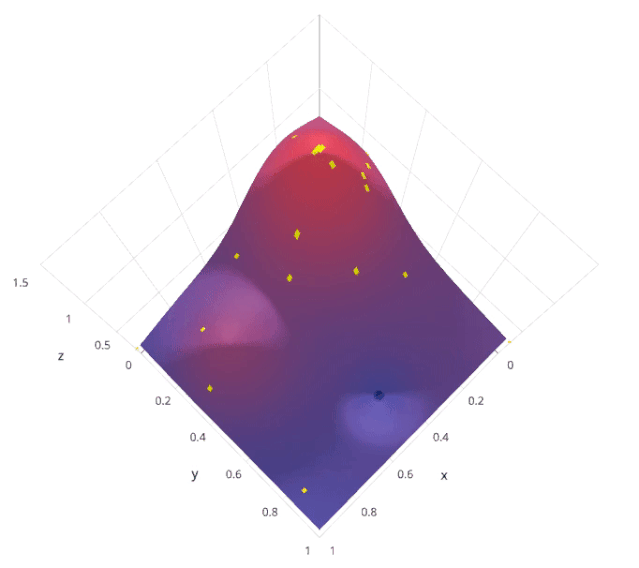
4. 貝葉斯搜索
使用先前評估的點(diǎn)X1*:n*,計(jì)算損失f的后驗(yàn)期望。
在新的點(diǎn)X的抽樣損失f,從而最大化f的期望的某些方法。該方法指定f域的哪些區(qū)域最適于抽樣。
安裝: pip install scikit-optimize
from skopt import BayesSearchCV
import warnings
warnings.filterwarnings("ignore")
# parameter ranges are specified by one of below
from skopt.space import Real, Categorical, Integer
knn = KNeighborsClassifier()
#defining hyper-parameter grid
grid_param = { 'n_neighbors' : list(range(2,11)) ,
'algorithm' : ['auto','ball_tree','kd_tree','brute'] }
#initializing Bayesian Search
Bayes = BayesSearchCV(knn , grid_param , n_iter=30 , random_state=14)
Bayes.fit(X_train,y_train)
#best parameter combination
Bayes.best_params_
#score achieved with best parameter combination
Bayes.best_score_
#all combinations of hyperparameters
Bayes.cv_results_['params']
#average scores of cross-validation
Bayes.cv_results_['mean_test_score']
安裝: pip install bayesian-optimization