
Python 機(jī)器學(xué)習(xí):超參數(shù)調(diào)優(yōu)

1.什么是超參數(shù)
RandomSearch GridSearch 貝葉斯優(yōu)化(Bayesian optimization)
2. GridSearchCV
import?pandas?as?pd
import?numpy?as?np
import?math
import?warnings
import?lightgbm?as?lgb
from?sklearn.model_selection?import?GridSearchCV
from?sklearn.model_selection?import?RandomizedSearchCV
lg?=?lgb.LGBMClassifier(silent=False)
param_dist?=?{"max_depth":?[2,?3,?4,?5,?7,?10],
??????????????"n_estimators":?[50,?100,?150,?200],
??????????????"min_child_samples":?[2,3,4,5,6]
?????????????}
grid_search?=?GridSearchCV(estimator=lg,?n_jobs=10,?param_grid=param_dist,?cv?=?5,?scoring='f1',?verbose=5)
grid_search.fit(X_train,?y)
grid_search.best_estimator_,?grid_search.best_score_
#?Fitting?5?folds?for?each?of?120?candidates,?totalling?600?fits
#?[Parallel(n_jobs=10)]:?Using?backend?LokyBackend?with?10?concurrent?workers.
#?[Parallel(n_jobs=10)]:?Done??52?tasks??????|?elapsed:????2.5s
#?[Parallel(n_jobs=10)]:?Done?142?tasks??????|?elapsed:????6.6s
#?[Parallel(n_jobs=10)]:?Done?268?tasks??????|?elapsed:???14.0s
#?[Parallel(n_jobs=10)]:?Done?430?tasks??????|?elapsed:???25.5s
#?[Parallel(n_jobs=10)]:?Done?600?out?of?600?|?elapsed:???40.6s?finished
#?(LGBMClassifier(max_depth=10,?min_child_samples=6,?n_estimators=200,
#?????????????????silent=False),?0.6359524127649383)
GridSearchCV搜索過程模型estimator:lgb.LGBMClassifier param_grid:模型的超參數(shù),上面例子給出了3個參數(shù),值得數(shù)量分別是6,4,5,組合起來的搜索空間是120個 cv:交叉驗(yàn)證的折數(shù)(上面例子5折交叉), 算法訓(xùn)練的次數(shù)總共為120*5=600 scoring:模型好壞的評價指標(biāo)分?jǐn)?shù),如F1值 搜索返回: 最好的模型 best_estimator_和最好的分?jǐn)?shù)
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
3. RandomSearchCV
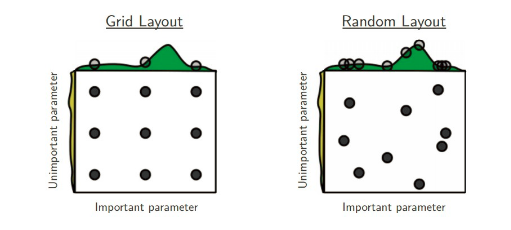
GridSearchCV一樣,RandomSearchCV也是在有限的超參數(shù)空間(人為重要的超參數(shù))中搜索最優(yōu)超參數(shù)。不一樣的地方在于搜索超參數(shù)的值不是固定,是在一定范圍內(nèi)隨機(jī)的值。不同超參數(shù)值的組合也是隨機(jī)的。值的隨機(jī)性可能會彌補(bǔ)GridSearchCV超參數(shù)值固定的有限組合,但也可能更壞。Better?than?grid?search?in?various?senses?but?still?expensive?to?guarantee?good?coverage
import?pandas?as?pd
import?numpy?as?np
import?math
import?warnings
import?lightgbm?as?lgb
from?scipy.stats?import?uniform
from?sklearn.model_selection?import?GridSearchCV
from?sklearn.model_selection?import?RandomizedSearchCV
lg?=?lgb.LGBMClassifier(silent=False)
param_dist?=?{"max_depth":?range(2,15,1),
??????????????"n_estimators":?range(50,200,4),
??????????????"min_child_samples":?[2,3,4,5,6],
?????????????}
random_search?=?RandomizedSearchCV(estimator=lg,?n_jobs=10,?param_distributions=param_dist,?n_iter=100,?cv?=?5,?scoring='f1',?verbose=5)
random_search.fit(X_train,?y)
random_search.best_estimator_,?random_search.best_score_
#?Fitting?5?folds?for?each?of?100?candidates,?totalling?500?fits
#?[Parallel(n_jobs=10)]:?Using?backend?LokyBackend?with?10?concurrent?workers.
#?[Parallel(n_jobs=10)]:?Done??52?tasks??????|?elapsed:????6.6s
#?[Parallel(n_jobs=10)]:?Done?142?tasks??????|?elapsed:???12.9s
#?[Parallel(n_jobs=10)]:?Done?268?tasks??????|?elapsed:???22.9s
#?[Parallel(n_jobs=10)]:?Done?430?tasks??????|?elapsed:???36.2s
#?[Parallel(n_jobs=10)]:?Done?500?out?of?500?|?elapsed:???42.0s?finished
#?(LGBMClassifier(max_depth=11,?min_child_samples=3,?n_estimators=198,
#?????????????????silent=False),?0.628180299445963)
GridSearchCV類似,不同之處如下:n_iter:隨機(jī)搜索值的數(shù)量 param_distributions:搜索值的范圍,除了list之外,也可以是某種分布如uniform均勻分布等
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html#sklearn.model_selection.RandomizedSearchCV
4. 貝葉斯優(yōu)化(Bayesian optimization)
GridSearchCV還是RandomSearchCV, 都是在調(diào)參者給定的有限范圍內(nèi)搜索全部或者部分參數(shù)的組合情況下模型的最佳表現(xiàn);可想而知最優(yōu)模型參數(shù)取決于先驗(yàn)的模型參數(shù)和有限范圍,某些情況下并一定是最優(yōu)的, 而且暴力搜索對于大的候選參數(shù)空間也是很耗時的。
Input:f是模型, M是高斯擬合函數(shù), X是參數(shù), S是參數(shù)選擇算法Acquisition Function 初始化高斯分布擬合的數(shù)據(jù)集D,為(x,y), x是超參數(shù),y是超參數(shù)的x的執(zhí)行結(jié)果(如精確率等) 迭代T次 每次迭代,用D數(shù)據(jù)集擬合高斯分布函數(shù) 根據(jù)擬合的函數(shù),根據(jù)Acquisition Function(如Expected improvement算法),在參數(shù)空間選擇一個比當(dāng)前最優(yōu)解更優(yōu)的參數(shù)xi 將參數(shù)xi代入模型f(訓(xùn)練一個模型),得出相應(yīng)的yi(新模型的精確率等) (xi,yi)重新加入擬合數(shù)據(jù)集D,再一次迭代
由此可知,貝葉斯優(yōu)化每次都利用上一次參數(shù)選擇。而GridSearchCV和RandomSearchCV每一次搜索都是獨(dú)立的。
到此,簡單介紹了貝葉斯優(yōu)化的理論知識。有很多第三方庫實(shí)現(xiàn)了貝葉斯優(yōu)化的實(shí)現(xiàn),如 advisor,bayesian-optimization,Scikit-Optimize和GPyOpt等。本文以GPyOpt和bayesian-optimization為例子。
pip?install?gpyopt
pip?install?bayesian-optimization
pip?install?scikit-optimize
gpyopt例子
import?GPy
import?GPyOpt
from?GPyOpt.methods?import?BayesianOptimization
from?sklearn.model_selection?import?train_test_split
from?sklearn.model_selection?import?cross_val_score
from?sklearn.datasets?import?load_iris
from?xgboost?import?XGBRegressor
import?numpy?as?np
?
?
iris?=?load_iris()
X?=?iris.data
y?=?iris.target
?
?
x_train,?x_test,?y_train,?y_test?=?train_test_split(X,y,test_size?=?0.3,random_state?=?14)
?
#?超參數(shù)搜索空間
bds?=?[{'name':?'learning_rate',?'type':?'continuous',?'domain':?(0,?1)},
????????{'name':?'gamma',?'type':?'continuous',?'domain':?(0,?5)},
????????{'name':?'max_depth',?'type':?'continuous',?'domain':?(1,?50)}]
?
?
#?Optimization?objective?模型F
def?cv_score(parameters):
????parameters?=?parameters[0]
????score?=?cross_val_score(
????????????????XGBRegressor(learning_rate=parameters[0],
??????????????????????????????gamma=int(parameters[1]),
??????????????????????????????max_depth=int(parameters[2])),?
????????????????X,?y,?scoring='neg_mean_squared_error').mean()
????score?=?np.array(score)
????return?score
?
#?acquisition就是選擇不同的Acquisition?Function
optimizer?=?GPyOpt.methods.BayesianOptimization(f?=?cv_score,????????????#?function?to?optimize???????
??????????????????????????????????????????domain?=?bds,?????????#?box-constraints?of?the?problem
??????????????????????????????????????????acquisition_type?='LCB',???????#?LCB?acquisition
??????????????????????????????????????????acquisition_weight?=?0.1)???#?Exploration?exploitation
?
?
x_best?=?optimizer.X[np.argmax(optimizer.Y)]
print("Best?parameters:?learning_rate="+str(x_best[0])+",gamma="+str(x_best[1])+",max_depth="+str(x_best[2]))
#?Best?parameters:?learning_rate=0.4272184438229706,gamma=1.4805727469635759,max_depth=41.8460390442754
bayesian-optimization例子
from?sklearn.datasets?import?make_classification
from?xgboost?import?XGBRegressor
from?sklearn.model_selection?import?cross_val_score
from?bayes_opt?import?BayesianOptimization
iris?=?load_iris()
X?=?iris.data
y?=?iris.target
?
?
x_train,?x_test,?y_train,?y_test?=?train_test_split(X,y,test_size?=?0.3,random_state?=?14)
bds?={'learning_rate':?(0,?1),
????????'gamma':?(0,?5),
????????'max_depth':?(1,?50)}
#?Optimization?objective?
def?cv_score(learning_rate,?gamma,??max_depth):
????score?=?cross_val_score(
????????????????XGBRegressor(learning_rate=learning_rate,
??????????????????????????????gamma=int(gamma),
??????????????????????????????max_depth=int(max_depth)),?
????????????????X,?y,?scoring='neg_mean_squared_error').mean()
????score?=?np.array(score)
????return?score
rf_bo?=?BayesianOptimization(
????????cv_score,
????????bds
????)
rf_bo.maximize()
rf_bo.max?
|???iter????|??target???|???gamma???|?learni...?|?max_depth?|
-------------------------------------------------------------
|??1????????|?-0.0907???|??0.7711???|??0.1819???|??20.33????|
|??2????????|?-0.1339???|??4.933????|??0.6599???|??8.972????|
|??3????????|?-0.07285??|??1.55?????|??0.8247???|??33.94????|
|??4????????|?-0.1359???|??4.009????|??0.3994???|??25.55????|
|??5????????|?-0.08773??|??1.666????|??0.9551???|??48.67????|
|??6????????|?-0.05654??|??0.0398???|??0.3707???|??1.221????|
|??7????????|?-0.08425??|??0.6883???|??0.2564???|??33.25????|
|??8????????|?-0.1113???|??3.071????|??0.8913???|??1.051????|
|??9????????|?-0.9167???|??0.0??????|??0.0??????|??2.701????|
|??10???????|?-0.05267??|??0.0538???|??0.1293???|??1.32?????|
|??11???????|?-0.08506??|??1.617????|??1.0??????|??32.68????|
|??12???????|?-0.09036??|??2.483????|??0.2906???|??33.21????|
|??13???????|?-0.08969??|??0.4662???|??0.3612???|??34.74????|
|??14???????|?-0.0723???|??1.295????|??0.2061???|??1.043????|
|??15???????|?-0.07531??|??1.903????|??0.1182???|??35.11????|
|??16???????|?-0.08494??|??2.977????|??1.0??????|??34.57????|
|??17???????|?-0.08506??|??1.231????|??1.0??????|??36.05????|
|??18???????|?-0.07023??|??2.81?????|??0.838????|??36.16????|
|??19???????|?-0.9167???|??1.94?????|??0.0??????|??36.99????|
|??20???????|?-0.09041??|??3.894????|??0.9442???|??35.52????|
|??21???????|?-0.1182???|??3.188????|??0.01882??|??35.14????|
|??22???????|?-0.08521??|??0.931????|??0.05693??|??31.66????|
|??23???????|?-0.1003???|??2.26?????|??0.07555??|??31.78????|
|??24???????|?-0.1018???|??0.08563??|??0.9838???|??32.22????|
|??25???????|?-0.1017???|??0.8288???|??0.9947???|??30.57????|
|??26???????|?-0.9167???|??1.943????|??0.0??????|??30.2?????|
|??27???????|?-0.08506??|??1.518????|??1.0??????|??35.04????|
|??28???????|?-0.08494??|??3.464????|??1.0??????|??32.36????|
|??29???????|?-0.1224???|??4.296????|??0.4472???|??33.47????|
|??30???????|?-0.1017???|??0.0??????|??1.0??????|??35.86????|
=============================================================
{'target':?-0.052665895082105285,
?'params':?{'gamma':?0.05379782654053811,
??'learning_rate':?0.1292986176550608,
??'max_depth':?1.3198257775801387}}
bayesian-optimization只支持最大化,如果score是越小越好,可以加一個負(fù)號轉(zhuǎn)化為最大值優(yōu)化。
5. 總結(jié)
GridSearchCV網(wǎng)格搜索,給定超參和取值范圍,遍歷所有組合得到最優(yōu)參數(shù)。首先你要給定一個先驗(yàn)的取值,不能取得太多,否則組合太多,耗時太長。可以啟發(fā)式的嘗試。 RandomSearchCV隨機(jī)搜索,搜索超參數(shù)的值不是固定,是在一定范圍內(nèi)隨機(jī)的值 貝葉斯優(yōu)化,采用高斯過程迭代式的尋找最優(yōu)參數(shù),每次迭代都是在上一次迭代基礎(chǔ)上擬合高斯函數(shù)上,尋找比上一次迭代更優(yōu)的參數(shù),推薦gpyopt庫
6. 參考資料
A Tutorial on Bayesian Optimization https://zhuanlan.zhihu.com/p/93683454 https://zhuanlan.zhihu.com/p/29779000 https://zhuanlan.zhihu.com/p/53826787
作者簡介:wedo實(shí)驗(yàn)君, 數(shù)據(jù)分析師;熱愛生活,熱愛寫作
贊 賞 作 者

更多閱讀
特別推薦

點(diǎn)擊下方閱讀原文加入社區(qū)會員
評論
圖片
表情