
如何優(yōu)化BERT等預(yù)訓(xùn)練模型-Tricks總結(jié)
歷時幾個月的NLP中文預(yù)訓(xùn)練模型泛化能力挑戰(zhàn)賽【25】已經(jīng)圓滿結(jié)束,進(jìn)入決賽的各個隊伍都提供了很好的方案模型。
這次比賽是CLUE與阿里云平臺、樂言科技聯(lián)合發(fā)起的第一場針對中文預(yù)訓(xùn)練模型泛化能力的挑戰(zhàn)賽。
賽題以自然語言處理為背景,要求選手通過算法實現(xiàn)泛化能力強的中文預(yù)訓(xùn)練模型。通過這道賽題可以引導(dǎo)大家更好地理解預(yù)訓(xùn)練模型的運作機(jī)制,探索深層次的模型構(gòu)建和模型訓(xùn)練,而不僅僅是針對特定任務(wù)進(jìn)行簡單微調(diào)。
賽后,CLUE【26】就將各個選手的方案進(jìn)行總結(jié)歸攏,提取出各種對任務(wù)有效的 方案方法。大體上,各種優(yōu)化方法根據(jù)機(jī)器學(xué)習(xí)的三要素來劃分:模型、策略(loss)、算法(優(yōu)化方法),再加上前期的數(shù)據(jù),后期后處理跟其他正則化方法。
總的來說,對任務(wù)最有增益的還是大數(shù)據(jù)與大預(yù)訓(xùn)練模型,能夠提高4%左右的指標(biāo),其他的各種trick也都可以錦上添花,可以提高0.5-1%左右的指標(biāo)。下面我們就直接介紹各種方法。
數(shù)據(jù) 數(shù)據(jù)預(yù)處理 數(shù)據(jù)增廣 外部數(shù)據(jù) 模型 大力出奇跡 模型結(jié)構(gòu) loss label Smooting 優(yōu)化方法 學(xué)習(xí)率 對抗訓(xùn)練 EMA,SWA 正則化 word mixup dropout early stop 后處理 閾值優(yōu)化 其他 未起效方法 訓(xùn)練技巧 自知識蒸餾
數(shù)據(jù)
都說數(shù)據(jù)是模型的上限,可見數(shù)據(jù)對模型的重要性,其中數(shù)據(jù)的質(zhì)量與數(shù)量都對模型至關(guān)重要。
數(shù)據(jù)預(yù)處理
數(shù)據(jù)預(yù)處理,主要會刪除錯誤、冗余數(shù)據(jù),修改特殊表示,整理數(shù)據(jù)格式等等,從而提高數(shù)據(jù)的整體質(zhì)量,以此來提高模型的效果。在本次比賽中,數(shù)據(jù)相對比較干凈,相關(guān)處理比較少,就是簡單將emoj替換成相應(yīng)字符,以及將中文標(biāo)點替換成英文格式等操作,在選手的方案中,該方法與下面的數(shù)據(jù)增廣一起,可以提高模型0.2%左右的指標(biāo)。常用的數(shù)據(jù)預(yù)處理內(nèi)容參考【1】【2】。
數(shù)據(jù)增廣
數(shù)據(jù)增廣,就是通過修改樣本而不改變其標(biāo)簽的方式,提高了樣本的多樣性,在保持一定數(shù)據(jù)質(zhì)量的條件下,提高了數(shù)據(jù)的數(shù)量,從而提高了模型的魯棒性。最常用數(shù)據(jù)增廣的方式主要有:
EDA【3】:簡單數(shù)據(jù)增廣,通過隨機(jī)增刪字詞,替換隨機(jī)詞或近義詞,以及調(diào)整字詞順序來實現(xiàn)。 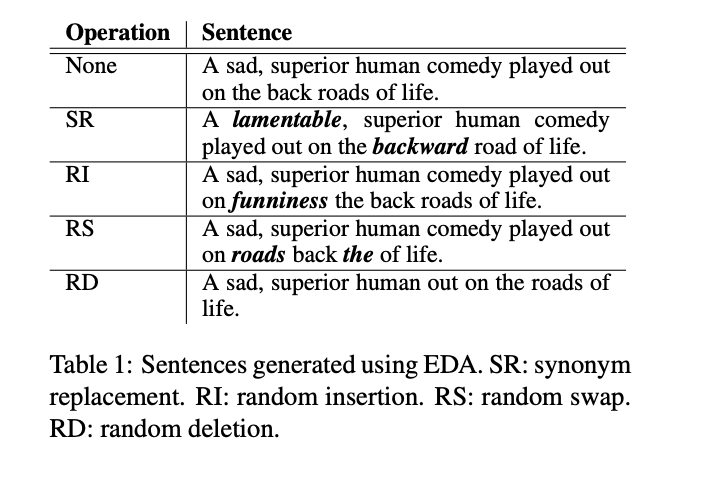
回譯【4】:將樣本翻譯成第二種語言,然后再翻譯回來,形成新樣本。 
比賽中,有選手使用EDA的方式進(jìn)行數(shù)據(jù)增廣,跟數(shù)據(jù)預(yù)處理一起,提高了0.2%左右的指標(biāo)。【5】中提供了很多數(shù)據(jù)增廣的方法,可用來快速生成大量訓(xùn)練數(shù)據(jù)。
外部數(shù)據(jù)
數(shù)據(jù)既然對模型的最終結(jié)果無比重要,那么就要通過各種方式來獲取數(shù)據(jù)。最直接的,通過人工標(biāo)注等方式獲取更多的數(shù)據(jù),但這種方法成本較高耗時也長,所以可以在網(wǎng)上尋找相似的公開帶標(biāo)簽數(shù)據(jù)集,如果缺少此類數(shù)據(jù),則可以獲取相似的無標(biāo)簽數(shù)據(jù),通過self-training的方式來訓(xùn)練模型;進(jìn)一步如無標(biāo)簽數(shù)據(jù)也難以獲得,則可以使用測試數(shù)據(jù)來做半監(jiān)督學(xué)習(xí)。比賽中,選手通過大量相似的帶標(biāo)簽數(shù)據(jù)以及大量無標(biāo)簽數(shù)據(jù)來做self-training【6】,整體提高1.5%左右的指標(biāo),也有選手使用測試數(shù)據(jù)做半監(jiān)督學(xué)習(xí),提高了0.8%左右。
模型
不同的任務(wù),不同的數(shù)據(jù),都可能需要不同的模型來處理。本次比賽是關(guān)于預(yù)訓(xùn)練的多任務(wù)學(xué)習(xí)(baseline模型結(jié)構(gòu)可參考【7】),所以選擇不同的預(yù)訓(xùn)練模型【8】,不同的多任務(wù)模型框架,改變細(xì)小的模型結(jié)構(gòu),都會對最終效果有影響。
大力出奇跡
本比賽中,對最終結(jié)果影響最大的,莫過于預(yù)訓(xùn)練模型的大小了,所謂大力出奇跡,越大的預(yù)訓(xùn)練模型,就包含了更多的信息,魯棒性也更好。從各位選手的結(jié)果來看,bert-large同等規(guī)模(24層的bert類模型)的模型比bert-base(12層的bert類模型)平均高4.5%左右,而bert-xlarge【9】(36層的bert類模型)規(guī)模的模型比bert-large要高3%左右。
模型結(jié)構(gòu)
本比賽是多任務(wù)學(xué)習(xí),并且需要使用單個預(yù)訓(xùn)練模型,所以baseline大都是硬共享模式。三個任務(wù)中有兩個是分類任務(wù)一個是匹配任務(wù)(也可以認(rèn)為分類任務(wù)),基礎(chǔ)的方法就是沿用最后一層cls或者pool層結(jié)果進(jìn)行分類。針對這些具體任務(wù),各個選手發(fā)揮主動能動性,使用了不同的網(wǎng)絡(luò)結(jié)構(gòu)來處理。
有選手使用bert最后4層的結(jié)果加上pooler層的結(jié)果來進(jìn)行下游任務(wù)學(xué)習(xí)【10】,得到了1%左右的收益; 有選手則將多任務(wù)模型結(jié)構(gòu)全部表示為共享形式,所有任務(wù)共享一種結(jié)構(gòu),只是對不同任務(wù)選擇獨立的query來獲取當(dāng)前任務(wù)的內(nèi)容【11】; 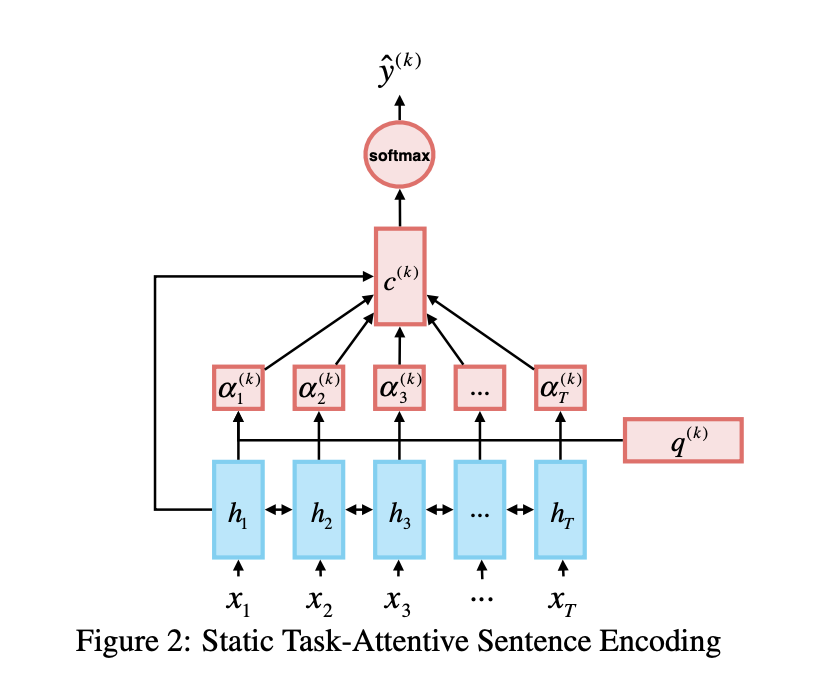
有選手則根據(jù)不同的任務(wù),選手lstm/transformer等結(jié)構(gòu)來學(xué)習(xí)下游任務(wù),提高了0.5%左右; 有選手并不使用cls的向量來學(xué)習(xí)下游任務(wù),而是用整個句子的平均池化結(jié)果來訓(xùn)練,這比cls的方法提高了0.5%左右; 有選手則是先對三個任務(wù)分別訓(xùn)練,然后將三個模型的參數(shù)進(jìn)行融合,再一起訓(xùn)練,該方法帶來了1%左右的提高; 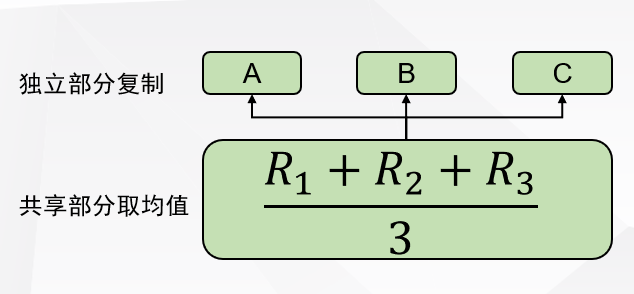
還有選手不把賽題看作是多任務(wù)學(xué)習(xí)問題,將各個任務(wù)混合在一起鋪平,進(jìn)行25分類訓(xùn)練,并在輸入時新增了task type的embedding以區(qū)分任務(wù)。 
LOSS
學(xué)習(xí)不同的任務(wù),需要不同的loss,比如分類任務(wù)通常使用交叉熵,預(yù)測問題通常使用均方誤差等等。loss函數(shù),可以體現(xiàn)任務(wù)標(biāo)簽的分布情況,樣本的比例,學(xué)到的信息大小與學(xué)習(xí)難度等等。所以一個更貼近數(shù)據(jù)情況的loss,能夠讓模型學(xué)習(xí)得更加魯棒。在本次比賽中,選手也更具具體情況選擇了不同的loss,但也并不是所有的策略都有效。比如像經(jīng)典的focal loss【12】,或者根據(jù)F1指標(biāo)修改的soft F1 loss【13】,或者是針對多任務(wù)學(xué)習(xí)的一些(動態(tài))權(quán)重loss等等,在本次比賽中并沒有起到明顯效果。而有選手則使用了label smoothing【14】的方式對標(biāo)簽進(jìn)行了平滑,提高了模型的魯棒行,最終與emb mixup【21】(在后續(xù)正則化講到)策略一起,將指標(biāo)提高了0.5%左右。
優(yōu)化方法
數(shù)據(jù)與模型都已經(jīng)準(zhǔn)備好,現(xiàn)在就需要學(xué)習(xí)模型,因為大部分神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)都不能找到最優(yōu)解,只能找到次優(yōu)解。從應(yīng)用的角度看,次優(yōu)解已經(jīng)可以使用,所以也沒有必要追求最優(yōu)解,但是通常情況下,次優(yōu)解越接近最優(yōu)解,應(yīng)用效果就越好,所有實際過程中,研究人員也通過各種方式,試圖獲取一個更好的次優(yōu)解。
學(xué)習(xí)率
當(dāng)前最主流的神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)方法是基于梯度下降的算法,如sgd,adma等。梯度下降方法中,學(xué)習(xí)率是個比較重要的超參數(shù)【15】,其控制著每次更新參數(shù)變化量的大小,不同的模型結(jié)構(gòu),不同的訓(xùn)練階段,甚至不同的參數(shù)層,都可以通過調(diào)整學(xué)習(xí)率來獲得更好的表現(xiàn)。大的學(xué)習(xí)率能夠讓模型學(xué)得更快,在一定程度上能讓參數(shù)跳過某些局部值,但也容易引起模型的不穩(wěn)定,容易過擬合等等;小的學(xué)習(xí)率可以讓模型學(xué)習(xí)得更穩(wěn)定,學(xué)習(xí)到一個較好的可行解,但也容易陷入局部值而不能跳出,且訓(xùn)練相對較慢。本次比賽中,有選手對bert之后的幾層選用不同的學(xué)習(xí)率【10】,但并沒有帶來明顯收益;而在使用較復(fù)雜的下游任務(wù)網(wǎng)絡(luò)模型的時候,通常的學(xué)習(xí)率并不能讓模型學(xué)習(xí)到有效信息,而更小的學(xué)習(xí)率則讓模型學(xué)到了有效信息。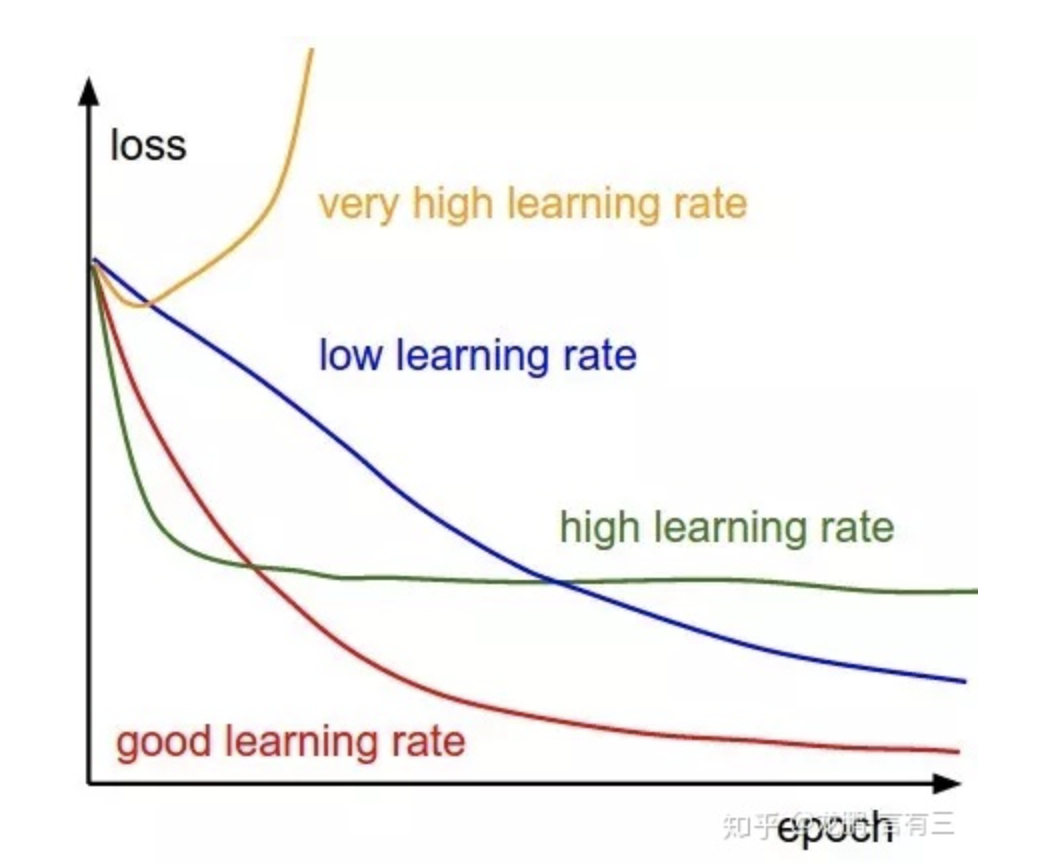
對抗訓(xùn)練
對抗訓(xùn)練【16】是提高神經(jīng)網(wǎng)絡(luò)魯棒性的利器,如下圖所示,減少了隨機(jī)干擾對模型結(jié)果的影響,其思想是,在訓(xùn)練過程中,通過對輸入進(jìn)行擾動,而使神經(jīng)網(wǎng)絡(luò)適應(yīng)這種改變,從而提高對對抗樣本的魯棒性。本次比賽中,選手也嘗試了不同的對抗訓(xùn)練方法,有選手通過FGM【17】對抗訓(xùn)練獲得了0.5%左右的提高,更有選手通過PDG【18】對抗訓(xùn)練提高了1.8%左右的成績。
訓(xùn)練手段
通常訓(xùn)練神經(jīng)網(wǎng)絡(luò)都是使用梯度下降之類的方法訓(xùn)練至收斂,不過因為一些隨機(jī)因素(隨機(jī)初始化、隨機(jī)訓(xùn)練樣本、不確定的學(xué)習(xí)率等等)甚至是梯度下降本身的因素,這樣的模型參數(shù)經(jīng)常會有較大的隨機(jī)性,所以一些研究人員通過參數(shù)平滑的方式,來降低模型參數(shù)的隨機(jī)性,以及提高模型的泛化能力。比賽中,有選手使用EMA【19】算法(滑動平均),降低了參數(shù)的隨機(jī)性,從而提高了模型準(zhǔn)確性;也有同學(xué)使用SWA【20】算法(隨機(jī)權(quán)重衰減),類似與集成模型的思想,將多個模型參數(shù)合并一起,從而提高模型的泛化能力,比賽中該方法提高了1%左右的成績。
正則化
過擬合一直是模型訓(xùn)練中的一大難題,正則化就是針對處理過擬合的一些手段。狹義的正則化主要是對模型做約束,如L1/L2正則,dropout等等;廣義的正則化則是一切能讓模型降低測試誤差的方法,如數(shù)據(jù)增廣、調(diào)整loss、early_stop甚至是調(diào)整模型結(jié)構(gòu)。從這個角度看,本文中的大部分內(nèi)容,都可以認(rèn)為是正則化手段。
word mixup
word mixup【21】可以認(rèn)為是一種數(shù)據(jù)增廣的方式,這種方法可以大量構(gòu)造虛擬樣本,其思路是隨機(jī)抽取兩個樣本,將兩個樣本的word embedding按比例混合作為新的樣本,新樣本的標(biāo)簽也是這兩個樣本的標(biāo)簽按比例的集合。比賽中,選手用該方法與label smoothing一起,將指標(biāo)提高了0.5%左右。
dropout
dropout【22】是常用的正則化手段之一,其主要思想是隨機(jī)丟棄一些計算單元或通道,從而讓各個計算單元或通道都能學(xué)到有效的信息,其思想也類似于bagging,減少了模型的方差。本次比賽中,選手使用dropout的方法,讓指標(biāo)提高了0.5%左右。
early stop
隨著模型的不斷訓(xùn)練,可能導(dǎo)致模型在訓(xùn)練數(shù)據(jù)集上過擬合,從而降低在測試集上的表現(xiàn),如下圖所示,隨著訓(xùn)練次數(shù)的增加,測試誤差先變小后變大。所以一個有效的early stop策略【23】,可以提高模型的泛化能力。本次比賽中,有效地利用early stop策略,可以提高1.8%左右的指標(biāo)。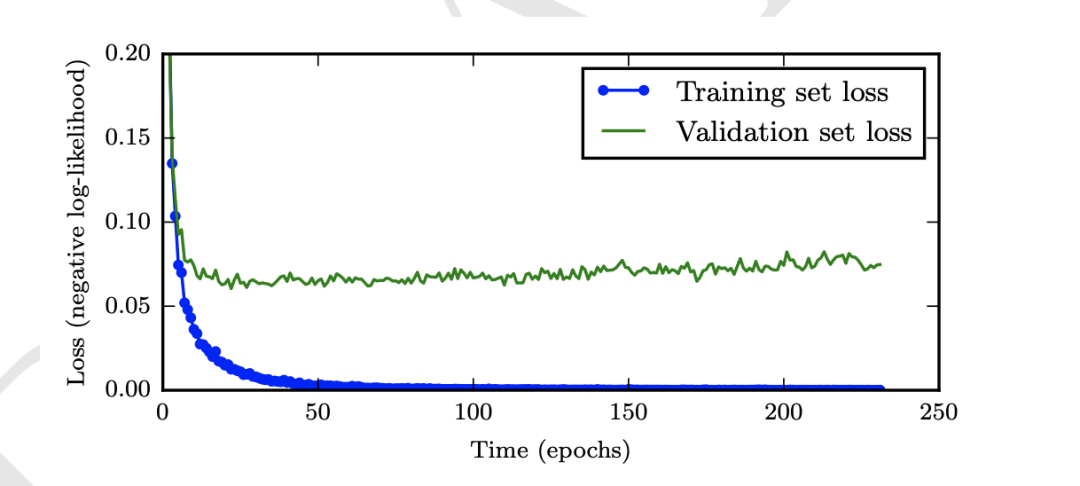
后處理
閾值優(yōu)化
數(shù)據(jù)準(zhǔn)備好了,模型也訓(xùn)練完成,模型的輸出結(jié)果到最終的結(jié)果還要一個轉(zhuǎn)換。對于通常的分類任務(wù),可能直接使用0.5作為閾值分類就好,但對于具體任務(wù)而言,不同的閾值可能對最終結(jié)果有不少的影響。本次比賽中,也有選手對最終模型的閾值做了優(yōu)化調(diào)整,且讓最終指標(biāo)提高了0.4%左右。
其他
未起效方法
比賽中,選手們也嘗試過其他很多方法,其中有不少也并沒有起到明顯作用,比如利用訓(xùn)練數(shù)據(jù)與預(yù)訓(xùn)練模型再做預(yù)訓(xùn)練,以及一些對loss的調(diào)整,比如focal loss、soft f1 loss、動態(tài)loss調(diào)整等等。
訓(xùn)練技巧
比賽中,大部分選手使用使用的大模型,36層的bert模型在顯存占用與訓(xùn)練速度上都堪憂。顯存的角度,模型太大,就導(dǎo)致batch size比較小,為此有選手使用了累計多步更新一次參數(shù)的方法;速度的角度,模型本身訓(xùn)練已經(jīng)比較慢,有很多tirck非常耗時,所以有選手就在訓(xùn)練初期使用原始模型訓(xùn)練,在一定輪次后,再加入trick繼續(xù)訓(xùn)練,從而提高了訓(xùn)練效率。
自知識蒸餾
自知識蒸餾【24】在很多任務(wù)上也能提高模型的的效果(本次比賽中,并沒有選手使用),因為其相對于原始的硬標(biāo)簽提供的信息,可以額外提供各個類別之間關(guān)系的信息。比如分類任務(wù)中,原始標(biāo)簽只會對某個樣本標(biāo)記為第一類/第二類,但自知識蒸餾可以把某個樣本標(biāo)記為80%的第一類20%的第二類,這樣就提供了更多的標(biāo)簽之間的信息。
參考
【1】如何對文本數(shù)據(jù)進(jìn)行預(yù)處理?:https://blog.csdn.net/weixin_36711901/article/details/79523698
【2】自然語言處理之?dāng)?shù)據(jù)預(yù)處理:https://bainingchao.github.io/2019/02/13/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E4%B9%8B%E6%95%B0%E6%8D%AE%E9%A2%84%E5%A4%84%E7%90%86/
【3】EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks:https://arxiv.org/pdf/1901.11196.pdf
【4】Unsupervised Data Augmentation for Consistency Training:https://arxiv.org/pdf/1904.12848.pdf
【5】A Visual Survey of Data Augmentation in NLP:https://amitness.com/2020/05/data-augmentation-for-nlp/
【6】Uncertainty-aware Self-training for Text Classification with Few Labels:https://arxiv.org/pdf/2006.15315.pdf
【7】Multi-Task Deep Neural Networks for Natural Language Understanding:https://arxiv.org/pdf/1901.11504.pdf
【8】NLP集大成之預(yù)訓(xùn)練模型綜述
【9】https://github.com/dbiir/UER-py
【10】NLP重鑄篇之BERT如何微調(diào)文本分類
【11】Same Representation, Different Attentions: Shareable Sentence Representation Learning from Multiple Tasks:https://arxiv.org/pdf/1804.08139v1.pdf
【12】Focal Loss for Dense Object Detection:https://arxiv.org/pdf/1708.02002.pdf
【13】The Unknown Benefits of using a Soft-F1 Loss in Classification Systems:https://towardsdatascience.com/the-unknown-benefits-of-using-a-soft-f1-loss-in-classification-systems-753902c0105d
【14】When Does Label Smoothing Help?:https://arxiv.org/pdf/1906.02629.pdf
【15】【AI不惑境】學(xué)習(xí)率和batchsize如何影響模型的性能?:https://zhuanlan.zhihu.com/p/64864995
【16】論文閱讀:對抗訓(xùn)練(adversarial training):https://zhuanlan.zhihu.com/p/104040055
【17】ADVERSARIAL TRAINING METHODS FOR SEMI-SUPERVISED TEXT CLASSIFICATION:https://arxiv.org/pdf/1605.07725.pdf
【18】Towards Deep Learning Models Resistant to Adversarial Attacks:https://arxiv.org/pdf/1706.06083.pdf
【19】機(jī)器學(xué)習(xí)模型性能提升技巧:指數(shù)加權(quán)平均(EMA):https://blog.csdn.net/mikelkl/article/details/85227053
【20】Averaging Weights Leads to Wider Optima and Better Generalization:https://arxiv.org/pdf/1803.05407.pdf
【21】Augmenting Data with Mixup for Sentence Classification: An Empirical Study:https://arxiv.org/pdf/1905.08941.pdf
【22】深度學(xué)習(xí)中Dropout原理解析:https://zhuanlan.zhihu.com/p/38200980
【23】Early Stopping | but when?:https://www.researchgate.net/publication/2874749_Early_Stopping_-_But_When
【24】Self-Knowledge Distillation: A Simple Way for Better Generalization:https://arxiv.org/pdf/2006.12000.pdf
【25】NLP中文預(yù)訓(xùn)練模型泛化能力挑戰(zhàn)賽:https://tianchi.aliyun.com/competition/entrance/531841/introduction
【26】中文語言理解測評基準(zhǔn)(CLUE):https://www.cluebenchmarks.com/index.html