
零基礎(chǔ)讀懂Stable Diffusion
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá) 
極市導(dǎo)讀
一文搞懂Stable Diffusion是什么,怎么訓(xùn)練和使用,語(yǔ)義信息影響生成圖片的過(guò)程。
前幾個(gè)月AIGC可謂是大熱了一把,各種高質(zhì)量的生成圖片層出不窮,而其中最重要的開(kāi)源模型Stable Diffusion也受到了各種技術(shù)商業(yè)上的熱捧,以很快的速度不斷的向前迭代著。之前作為一個(gè)沒(méi)有相關(guān)知識(shí)基礎(chǔ)的小白,為了了解相關(guān)的技術(shù)知識(shí),找了很多文章看,最后還是發(fā)現(xiàn)Jay Alammar的這篇文章講的最為通俗易懂,于是決定簡(jiǎn)單翻譯一下,方便更多人從零開(kāi)始了解這項(xiàng)強(qiáng)大的技術(shù)。
由于原文篇幅較長(zhǎng),所以這里分為三部分進(jìn)行講解:
-
第一部分,主要講“是什么”的問(wèn)題,包括Stable Diffusion是什么,里面的各個(gè)模塊是什么 -
第二部分,主要講“怎么辦”的問(wèn)題,也就是Diffusion怎么訓(xùn)練以及怎么使用的問(wèn)題。 -
第三部分,主要講“如何控制”的問(wèn)題,具體闡述語(yǔ)義信息到底是怎么影響生成圖片的過(guò)程的。
接下來(lái)正式進(jìn)入第一部分的介紹,談?wù)凷table Diffusion是什么,以及里面的一些模塊是什么的問(wèn)題。
原文鏈接:The Illustrated Stable Diffusion 有能力和時(shí)間的小伙伴還是更推薦閱讀原文噢
作者:Jay Alammar
譯者:曾飛飛(知乎)
零基礎(chǔ)讀懂Stable Diffusion(I):怎么組成
AI圖像生成最近所展現(xiàn)出的潛力可謂是讓人大開(kāi)眼界,它能夠從一些簡(jiǎn)單的文字描述開(kāi)始,變魔法一般的變出高質(zhì)量的圖片。不用說(shuō),這已然深刻的拓寬了人類(lèi)創(chuàng)作藝術(shù)的方式。而其中,Stable Diffusion的公布算是一個(gè)里程碑事件了,它的開(kāi)源不僅僅意味著面向大眾群體公開(kāi)了一個(gè)極高質(zhì)量的模型,與此同時(shí)這個(gè)模型甚至能保持很快的運(yùn)行速度和較低的顯存需求,不可謂不厲害。
用過(guò)了Diffusion這個(gè)神奇的技術(shù)后,你可能會(huì)好奇它到底為什么能有如此好的效果,這里將給出一個(gè)盡量簡(jiǎn)單直白的解釋。
Stable Diffusion模型確實(shí)是多才多藝的,它可以出色的完成很多任務(wù),比如文生圖,圖生圖,特定角色的刻畫(huà),甚至超分或者Inpainting,但作為最基礎(chǔ)的一篇介紹,這里我們首先就著重講解最基礎(chǔ)的“文生圖”模塊,也就是txt2img部分。下圖是一個(gè)基本的文生圖展示,輸入是“天堂(paradise)、廣袤的(cosmic)、海灘(beach)”,可以看到最右邊的生成圖片很好的符合了輸入的要求,圖中不僅有藍(lán)天白云,廣闊的海灘也一望無(wú)際:

雖然本文暫時(shí)還沒(méi)講到圖生圖模塊(也就是所謂的img2img),但這個(gè)模塊的示意圖我們也暫時(shí)放一下,如下圖所示,這次的輸入從單純的“文字”變成了“圖片+文字”的形式,生成的結(jié)果是由原始圖片和文字提示詞共同決定的。這次輸入是"海盜船(pirate ship)"和上面img2img生成的圖片,最后輸出的結(jié)果也確實(shí)把輸入圖片的帆船變成了海盜船

現(xiàn)在,讓我們正式開(kāi)始了解這項(xiàng)技術(shù)背后的原理吧。
一、組成模塊
Stable Diffusion其實(shí)是個(gè)比較雜合的系統(tǒng),里面有著各種各樣的模型模塊。那首先映入眼簾的問(wèn)題是,怎么把人類(lèi)理解的文字轉(zhuǎn)換為機(jī)器理解的數(shù)學(xué)語(yǔ)言,畢竟計(jì)算機(jī)是不懂英文的嘛。這個(gè)時(shí)候就需要一個(gè)text understander幫忙轉(zhuǎn)化。在生成圖像前,下圖中藍(lán)藍(lán)的text understander先把文字轉(zhuǎn)換成某種計(jì)算機(jī)能理解的數(shù)學(xué)表示:

藍(lán)藍(lán)的text understander(也就是一個(gè)文字的encoder編碼器)把人類(lèi)語(yǔ)言轉(zhuǎn)換成計(jì)算機(jī)能理解的語(yǔ)義內(nèi)容
我們后續(xù)在第三篇中會(huì)講到這個(gè)text understander到底是怎么理解文字和怎么訓(xùn)練的,但現(xiàn)在暫時(shí)讓我略過(guò)這一部分內(nèi)容,我們只要知道這個(gè)text understander是個(gè)特別的Transformer語(yǔ)言模型就好了。它的輸入是人類(lèi)語(yǔ)言,輸出是一系列的向量,這些向量的語(yǔ)義對(duì)應(yīng)著我們輸入的文字。
那么現(xiàn)在,有了可以代表語(yǔ)義的向量(就比如下面的藍(lán)色3*5方格),我們就把這個(gè)語(yǔ)義向量交給真正的圖片生成器了,也即下圖中粉粉的Image Generator。

藍(lán)色方格的語(yǔ)義向量被輸入到粉色的圖片生成器中,正式開(kāi)始生成圖片
這個(gè)粉色的圖片生成器(Image Generator)可以分解成兩個(gè)子模塊來(lái)看
1,圖片信息生成器
這個(gè)下圖中粉色的模塊是Stable Diffusion的秘密武器,也是Stable Diffusion和其他diffusion模型最大的區(qū)別,很多性能上的提升就來(lái)源于此。
首先,最需要明確的一點(diǎn):圖片信息生成器不直接生成圖片,而是生成的較低維度的圖片信息,也就是所謂的隱空間信息(information of latent space)。這個(gè)隱空間信息在下面的流程圖中表現(xiàn)為那個(gè)粉色的4*3的方格,后續(xù)再將下圖中這個(gè)隱空間信息輸入到下圖中黃色的Decoder里,就可以成功生成圖片了。Stable Diffusion主要引用的論文“latent diffusion”中的latent也是來(lái)源于隱變量中的“隱”(latent)。
一般的diffusion模型都是直接生成圖片,并不會(huì)有先生成隱變量的過(guò)程,所以普通的diffusion在這一步上需要生成的信息更多,負(fù)荷也更大。因而之前的diffusion模型在速度上和資源利用上都比不過(guò)Stable Diffusion。那技術(shù)上來(lái)說(shuō),這個(gè)圖片隱變量到底是怎么生成的呢?這其實(shí)是由一個(gè)Unet和一個(gè)Schedule算法共同完成的。schedule算法控制生成的進(jìn)度,unet就具體去一步一步地執(zhí)行生成的過(guò)程。Stable Diffusion中,整個(gè)unet的生成迭代過(guò)程大概要重復(fù)50~100次,隱變量的質(zhì)量也在這個(gè)迭代的過(guò)程中不斷的變得更好。下圖中粉色的Image Information Creator左下角的循環(huán)標(biāo)志也正是象征著這個(gè)迭代的過(guò)程。
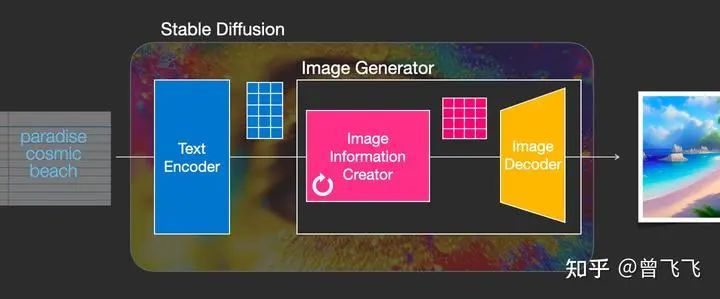
2,圖片解碼器
圖片解碼器也就是我們上面說(shuō)的decoder,它從圖片信息生成器(Image Information Creator)中接過(guò)圖片信息的隱變量,將其升維放大(upscale),還原成一張完整的圖片。圖片解碼器只在最后的階段起作用,也是我們真正能獲得一張圖片的最終過(guò)程。

上面粗略的聊了一下Stable Diffusion每個(gè)模塊的功能,下面我們來(lái)更具體的了解一下這個(gè)系統(tǒng)中輸入輸出的向量形狀,這樣的話(huà)對(duì)Stable Diffusion的工作原理應(yīng)該能有更直觀的認(rèn)識(shí):
-
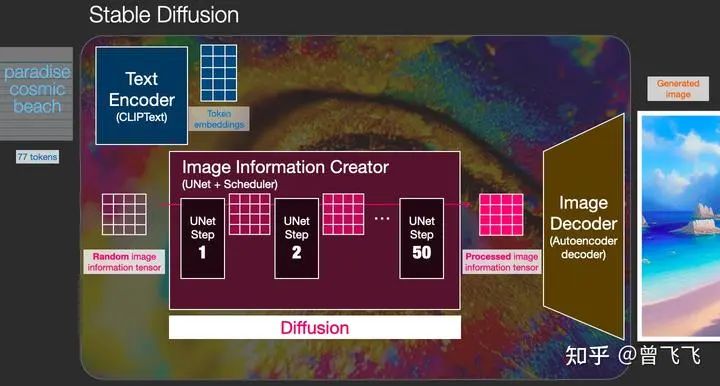
Text Encoder (藍(lán)色模塊) 功能:將人類(lèi)語(yǔ)言轉(zhuǎn)換成機(jī)器能理解的數(shù)學(xué)向量 輸入:人類(lèi)語(yǔ)言 輸出:語(yǔ)義向量(77,768) -
Image Information Creator (粉色模塊) 功能:結(jié)合語(yǔ)義向量,從純?cè)肼曢_(kāi)始逐步去除噪聲,生成圖片信息隱變量 輸入:噪聲隱變量(4,64,64)+語(yǔ)義向量(77,768) 輸出:去噪的隱變量(4,64,64) -
Image Decoder 功能:將圖片信息隱變量轉(zhuǎn)換為一張真正的圖片。輸入:去噪的隱變量(4,64,64) 輸出:一張真正的圖片(3,512,512)
大概流程中的向量形狀變化就是這樣,至于語(yǔ)義向量的形狀為什么是奇怪的(77,768)的形狀,我們后面講到Text Encoder里面的CLIP模型的時(shí)候還會(huì)講到,這里就暫且按下不表。
二、擴(kuò)散(Diffusion)到底是什么意思?
Diffusion模型,翻譯成中文也就是擴(kuò)散模型,那這個(gè)擴(kuò)散到底體現(xiàn)在什么地方呢?這就是我們這第二部分著重要描述的過(guò)程。首先我們先用random函數(shù)生成一個(gè)隱變量大小的純?cè)肼?/strong>【下圖中左下透明4*4】。而擴(kuò)散的過(guò)程發(fā)生在Image Information Creator中,有了初始的純?cè)肼?/strong>【下圖中左下透明4*4】+語(yǔ)義向量【下圖左上藍(lán)色3*5】后,unet會(huì)結(jié)合語(yǔ)義向量不斷的去除純?cè)肼曤[變量中的噪聲,重復(fù)50~100次左右就完全去除了噪聲,同時(shí)不斷的向隱變量中注入語(yǔ)義信息,我們就得到了一個(gè)有語(yǔ)義的隱變量【下圖粉色4*4】。別忘了我們還有一個(gè)scheduler,它就用來(lái)控制unet去噪的強(qiáng)度,以統(tǒng)籌整個(gè)去噪的過(guò)程。scheduler可以在去噪的不同階段中動(dòng)態(tài)地調(diào)整去噪強(qiáng)度,也可以在某些特殊的任務(wù)里,勻速地去除噪聲,這都取決于我們一開(kāi)始的設(shè)計(jì)。

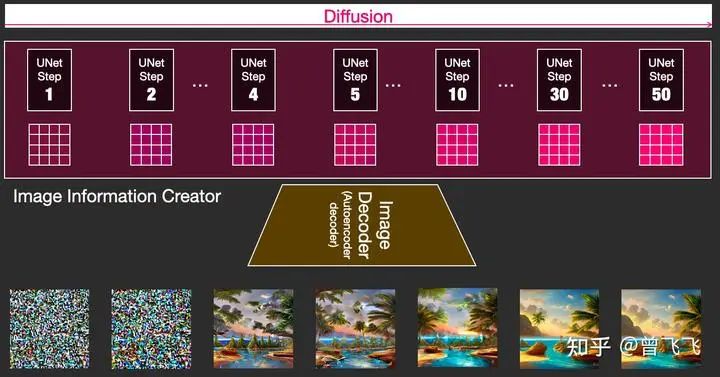
這個(gè)擴(kuò)散過(guò)程是一步一步迭代去噪的,每一步都向隱變量中注入語(yǔ)義信息,不斷重復(fù)直到去噪完成為止。為了有個(gè)直觀的認(rèn)識(shí),我們可以把初始的純?cè)肼暋鞠聢D左上透明4*4】和最后的去噪隱變量【下圖右上粉色4*4】都通過(guò)最后的Image Decoder,看看會(huì)出來(lái)什么樣的圖片。不出意料,純?cè)肼暠旧頉](méi)有任何有效信息,解碼出來(lái)的圖片也會(huì)是純?cè)肼暎缦聢D左側(cè)所示。而最后的去噪隱變量由于已經(jīng)耦合了語(yǔ)義信息,因此最后解碼出來(lái)的也是一張包含語(yǔ)義信息的有效圖片,如下圖右側(cè)圖片所示。

剛才我們也提到過(guò),擴(kuò)散過(guò)程是一個(gè)多次迭代的過(guò)程。每一步迭代的輸入都是一個(gè)隱變量,輸出也是一個(gè)隱變量,只不過(guò)輸出的這個(gè)隱變量噪聲更少,并且語(yǔ)義信息更多。下圖中4*4的隱變量不斷從透明變粉的過(guò)程就代表了這個(gè)迭代的過(guò)程,顏色越粉,迭代次數(shù)越多,噪聲也就越少。
這個(gè)時(shí)候我們?cè)偻低涤肐mage Decoder提前看一下每一步所對(duì)應(yīng)的圖片,就會(huì)看到我們想要的圖片一步一步地脫胎于噪聲的全過(guò)程:
這是一個(gè)神奇的過(guò)程,下面的視頻展示了迭代去噪的全過(guò)程,我們可以看一下視頻的展示:
三、總結(jié)
至此,我們已經(jīng)了解了Stable Diffusion是什么,以及其中的種種模塊是什么,甚至還簡(jiǎn)單的窺視了一下它的工作過(guò)程。至于為什么Diffusion如何訓(xùn)練、如何控制,鑒于篇幅原因,就容我放到后文中再去細(xì)講了。這里最后再簡(jiǎn)單做一下總結(jié):
-
第一部分介紹了一些Stable Diffusion中的主要模塊——包括一個(gè)Text Understander處理語(yǔ)義信息,一個(gè)Image Information Creator生成圖片的隱變量,一個(gè)Image Decoder利用隱變量生成真正的圖片。 -
其次還介紹了一下Diffusion生成圖片的流程——包括向量形狀在系統(tǒng)中經(jīng)歷的一系列變化,以及各個(gè)階段圖片隱變量解碼后的可視化。
零基礎(chǔ)讀懂Stable Diffusion(II):怎么訓(xùn)練
一,Diffusion怎么訓(xùn)練
Diffusion模型能夠生成高質(zhì)量圖片,其核心原因在于我們現(xiàn)在有著極其強(qiáng)大的計(jì)算機(jī)視覺(jué)模型。只要數(shù)據(jù)集夠大,我們強(qiáng)大的模型就能學(xué)習(xí)到任何復(fù)雜的操作。那具體diffusion里面讓unet學(xué)習(xí)了怎樣一個(gè)操作呢?簡(jiǎn)單來(lái)說(shuō),就是“去噪”。
那如何為去噪的任務(wù)設(shè)計(jì)數(shù)據(jù)集呢?很簡(jiǎn)單,我們只要向普通的照片里添加噪聲,不就有了加噪的圖片了嘛。假定我們現(xiàn)在有一張金字塔的圖片,我們用random函數(shù)生成從強(qiáng)到弱各個(gè)強(qiáng)度的噪聲,比如下圖中0~3共計(jì)4個(gè)強(qiáng)度的噪聲。現(xiàn)在我們選定個(gè)某個(gè)強(qiáng)度的噪聲,比如下圖中選了噪聲1,并且把這個(gè)噪聲添加到圖片里:

現(xiàn)在,我們就制作完成了訓(xùn)練集里面的一張圖片。按照這樣的操作,選一張圖片,再選一種強(qiáng)度的噪聲混合,我們還可以制作很多訓(xùn)練集。比如下面就選了圖書(shū)館的一張照片,混合了強(qiáng)度為2的噪聲,創(chuàng)造了一個(gè)更模糊一點(diǎn)的訓(xùn)練樣本:
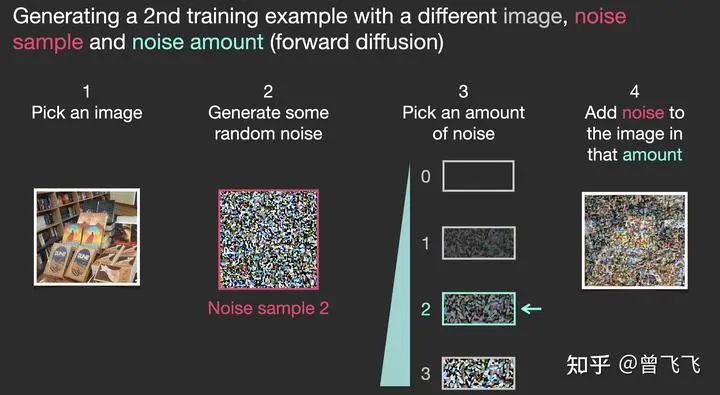
上面僅僅作為一個(gè)簡(jiǎn)單的例子,所以噪聲只設(shè)置了四個(gè)檔位。實(shí)際上我們可以更細(xì)膩地劃分噪聲的等級(jí),將其分為幾十個(gè)甚至上百個(gè)檔位,這樣就可以創(chuàng)建出成千上萬(wàn)個(gè)訓(xùn)練集。比如我們現(xiàn)在噪聲設(shè)置成100個(gè)檔位,下面就展示了利用不同的檔位結(jié)合不同的圖片創(chuàng)建6張訓(xùn)練集的過(guò)程:

這樣的話(huà),一組訓(xùn)練集包括了三樣?xùn)|西:噪聲強(qiáng)度(上圖數(shù)字),加噪后的圖片(上圖左列圖片),以及噪聲圖(上圖右列圖片)就可以了。訓(xùn)練的時(shí)候我們的unet只要在已知噪聲強(qiáng)度的條件下,學(xué)習(xí)如何從加噪后的圖片中計(jì)算出噪聲圖就可以了。注意,我們并不直接輸出無(wú)噪聲的原圖,而是讓unet去預(yù)測(cè)原圖上所加過(guò)的噪聲。當(dāng)需要生成圖片的時(shí)候,我們用加噪圖減掉噪聲就能恢復(fù)出原圖了。
具體的一個(gè)訓(xùn)練過(guò)程就如下圖所示,一共分四步走:
-
從訓(xùn)練集中選取一張加噪過(guò)的圖片和噪聲強(qiáng)度,比如下面的加噪街道圖和噪聲強(qiáng)度3。 -
輸入unet,讓unet預(yù)測(cè)噪聲圖,比如下圖的unet prediction。 -
計(jì)算和真正的噪聲圖之間的誤差 -
通過(guò)反向傳播更新unet的參數(shù)。
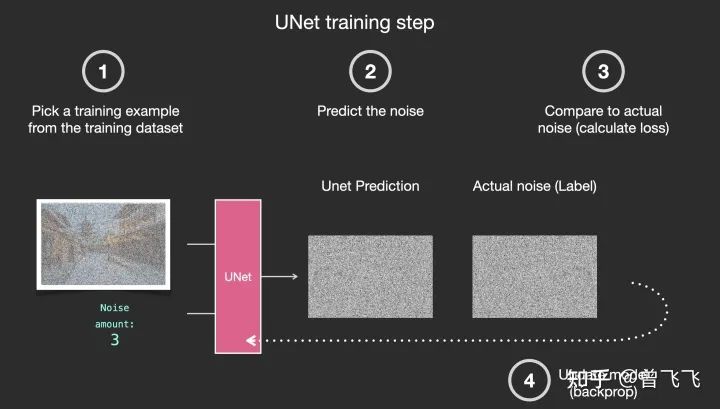
那完成訓(xùn)練后,我們?cè)撊绾紊蓤D片呢?
二,Diffusion怎么生成圖片
假設(shè)我們現(xiàn)在已經(jīng)按照上面的步驟訓(xùn)練好了一個(gè)unet,這就意味著它就可以成功從一個(gè)加噪的圖片中推斷出噪聲了。如下圖中,知道噪聲強(qiáng)度的情況下,給unet輸入一張有噪圖,unet就輸出有噪圖上面加過(guò)的噪聲:
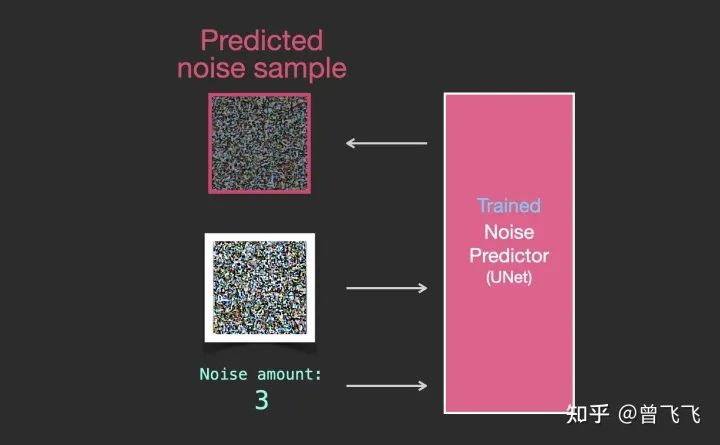
既然現(xiàn)在噪聲圖能夠被推斷出來(lái),我們只要把加噪后的圖片減去這個(gè)噪聲圖,就可以輕松得到一張略微去噪的圖片了:

重復(fù)這個(gè)過(guò)程,預(yù)測(cè)噪聲圖,再減去噪聲圖,進(jìn)行第二步去噪:
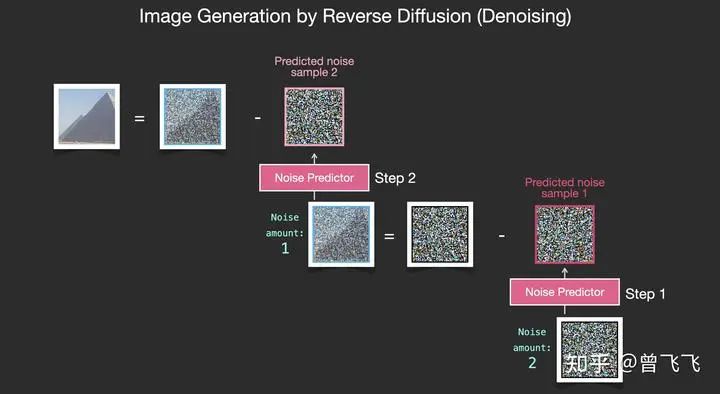
不斷地重復(fù)這個(gè)過(guò)程,不斷的去除一張?jiān)肼晥D片的噪聲,最終我們就可以得到一張很棒的圖片。這個(gè)圖片是接近訓(xùn)練集分布的,它和訓(xùn)練集保有相同的像素規(guī)律。比如你用一個(gè)藝術(shù)家數(shù)據(jù)集去訓(xùn)練,它就會(huì)遵循美學(xué)的顏色分布,你用真實(shí)世界的訓(xùn)練集去訓(xùn)練,它的結(jié)果就會(huì)盡量遵循真實(shí)世界的規(guī)律。現(xiàn)在,你已經(jīng)了解了Diffusion模型的基本規(guī)律了,這不僅僅適用于Stable Diffusion,也適用于OpenAI的Dall-E 2和Google的Imagen。
注意到上面這個(gè)過(guò)程中我們暫時(shí)還沒(méi)有引入文字和語(yǔ)義向量的控制。也就是說(shuō),如果單純的按照上面的流程走,我們可能能得到一些很炫酷的圖片,但我們沒(méi)有辦法去控制最后的結(jié)果到底是什么。那如何引入文字控制呢?這就要使用語(yǔ)言模型和Attention機(jī)制來(lái)引入語(yǔ)義啦。
三、總結(jié)
-
Diffusion's Training: 利用 “噪聲強(qiáng)度、噪聲圖、加噪后圖片”組成訓(xùn)練集,訓(xùn)練unet,使其學(xué)習(xí)如何從加噪后的圖片推斷出所加的噪聲。 -
Diffusion's Inference: 利用訓(xùn)練好的unet,從純?cè)肼曋幸徊揭徊饺ピ?/strong>,得到合理正常的圖片。
零基礎(chǔ)讀懂Stable Diffusion(III):怎么控制
第二部分中我們著重講述了如何訓(xùn)練Stable Diffusion中的unet,同時(shí),也了解了在訓(xùn)練好unet之后怎么使用它來(lái)去除噪聲以及生成圖片。然而,還有一個(gè)重要的地方我們尚未提及,那就是可控性。我們?nèi)绾斡谜Z(yǔ)言來(lái)控制最后生成的結(jié)果?答案也很簡(jiǎn)單——注意力機(jī)制。在第一部分中我們講到,一個(gè)unet除了要接收噪聲圖之外,還要接受我們用Text Encoder預(yù)先提取的語(yǔ)義信息。那這個(gè)語(yǔ)義信息怎么在生成圖片的過(guò)程中使用呢?我們直接使用注意力機(jī)制在unet內(nèi)層層耦合即可。下圖中每個(gè)黃色的小方塊都代表一次注意力機(jī)制的使用,而每次使用注意力機(jī)制,就發(fā)生了一次圖片信息和語(yǔ)義信息的耦合。每一個(gè)unet內(nèi)部,這樣的操作都會(huì)發(fā)生很多次很多次,直到最后一個(gè)unet為止,一直不斷重復(fù)這耦合的過(guò)程。
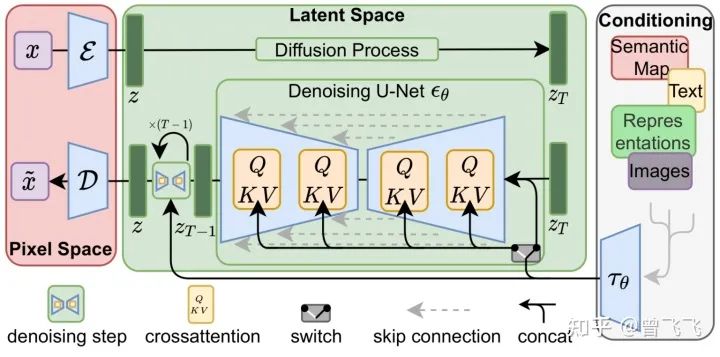
有人可能就要問(wèn)了,語(yǔ)義信息是語(yǔ)義信息,圖片信息是圖片信息,怎么能用attention耦合到一塊呢?計(jì)算機(jī)怎么把這兩種完全不同的信息聯(lián)系到一起的呢?這就要說(shuō)到我們這篇文章的主角——CLIP模型了。
一,CLIP模型介紹
自從2018年Bert發(fā)布以來(lái),Transformer的語(yǔ)言模型就成了主流。Stable Diffusion起初的版本便是用的基于GPT的CLIP模型,而最近的2.x版本換成了更新更好的OpenCLIP。語(yǔ)言模型的選擇直接決定了語(yǔ)義信息的優(yōu)良與否,而語(yǔ)義信息的好壞又會(huì)影響到最后圖片的多樣性和可控性。Google在Imagen論文中做過(guò)實(shí)驗(yàn),可以發(fā)現(xiàn)不同語(yǔ)言模型對(duì)生成結(jié)果的影響是相當(dāng)大的。

那像CLIP這樣的語(yǔ)言模型究竟是怎么訓(xùn)練出來(lái)的呢?它們是怎么樣做到結(jié)合人類(lèi)語(yǔ)言和計(jì)算機(jī)視覺(jué)的呢?接下來(lái)我們就來(lái)好好了解一下。
首先,要訓(xùn)練一個(gè)結(jié)合人類(lèi)語(yǔ)言和計(jì)算機(jī)視覺(jué)的模型,我們就必須有一個(gè)結(jié)合人類(lèi)語(yǔ)言和計(jì)算機(jī)視覺(jué)的數(shù)據(jù)集。CLIP就是在像下面這樣的數(shù)據(jù)集上訓(xùn)練的,只不過(guò)圖片數(shù)據(jù)達(dá)到了可怕的4億張而已。事實(shí)上,這些數(shù)據(jù)都是從網(wǎng)上爬取下來(lái)的,同時(shí)被爬取下來(lái)的還有它們的標(biāo)簽或者注釋。

CLIP模型包含一個(gè)圖片Encoder和一個(gè)文字Encoder。訓(xùn)練過(guò)程可以這么理解:我們先從訓(xùn)練集中隨機(jī)取出一張圖片和一段文字。注意,文字和圖片未必是匹配的,CLIP模型的任務(wù)就是預(yù)測(cè)圖文是否匹配,從而展開(kāi)訓(xùn)練。在隨機(jī)取出文字和圖片后,我們?cè)儆脠D片Encoder和文字Encoder分別壓縮成兩個(gè)embedding向量,稱(chēng)之為圖片embedding和文字embedding【下圖兩個(gè)藍(lán)色3*1向量】。

然后我們用余弦相似度來(lái)比較兩個(gè)embedding向量的相似性,以判斷我們隨機(jī)抽取的文字和圖片是否匹配。一開(kāi)始的時(shí)候,就算圖片和文字配對(duì)的很好,但由于我們的兩個(gè)Encoder剛剛初始化,參數(shù)都是混亂的,因此兩個(gè)embedding向量一定也是混亂的,計(jì)算出來(lái)的相似度往往會(huì)接近于0。這就會(huì)出現(xiàn)下圖這種狀況,明明圖文是一對(duì),他們的label是similar,但是余弦相似度算出來(lái)的prediction卻是not similar:
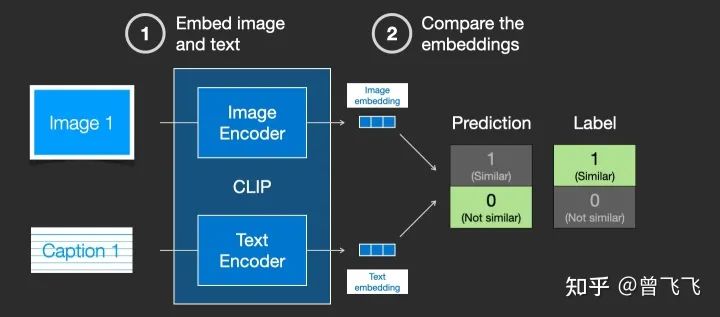
這個(gè)時(shí)候,標(biāo)簽(similar)和預(yù)測(cè)結(jié)果(not similar)不匹配,我們就根據(jù)這個(gè)結(jié)果去反向更新兩個(gè)Encoder的參數(shù):

不斷地重復(fù)這個(gè)反向傳播的過(guò)程,我們就能夠訓(xùn)練好兩個(gè)Encoder。對(duì)于配對(duì)的圖片和文字,這兩個(gè)Encoder最后就可以輸出相似的embedding向量,計(jì)算余弦相似度就可以得到接近1的結(jié)果。而對(duì)于不匹配的圖片和文字,這兩個(gè)Encoder就會(huì)輸出很不一樣的embedding向量,使得余弦相似度計(jì)算出來(lái)接近0. 這個(gè)時(shí)候,你給CLIP一張小狗的圖片,同時(shí)再給出文字描述:“小狗照片”,CLIP模型就會(huì)生成兩個(gè)相似的embedding向量,從而判斷出文字和圖片是匹配的。這個(gè)時(shí)候,計(jì)算機(jī)視覺(jué)和人類(lèi)語(yǔ)言這兩個(gè)原本不相干的信息就通過(guò)CLIP聯(lián)系到了一塊,二者就擁有了統(tǒng)一的數(shù)學(xué)表示了。你可以將文字通過(guò)一個(gè)Text Encoder轉(zhuǎn)換成圖片信息,也可以將文字通過(guò)Image Encoder轉(zhuǎn)換成語(yǔ)言信息,二者就能夠相互作用了。這也是Diffusion模型中可以通過(guò)文字生圖片的秘密所在。
值得注意的是,就像經(jīng)典的word2vec訓(xùn)練時(shí)一樣,訓(xùn)練CLIP時(shí)不僅僅要選擇匹配的圖文來(lái)訓(xùn)練,還要適當(dāng)選擇完全不匹配的圖文給機(jī)器識(shí)別,作為負(fù)樣本來(lái)平衡正樣本的數(shù)量。
二,給圖片注入語(yǔ)義
有了訓(xùn)練好的CLIP模型,我們就獲得了一個(gè)完美的工具,用來(lái)聯(lián)系語(yǔ)義信息和計(jì)算機(jī)視覺(jué)信息了。那如何利用CLIP模型呢?一個(gè)很直白的思路就是,對(duì)于一段描述文字,我們先用CLIP的Text Encoder去壓縮成embedding向量。在unet的去噪過(guò)程中,我們就不斷地用attention機(jī)制給去噪的過(guò)程注入這個(gè)embedding向量,就可以不斷注入語(yǔ)義信息了。
回憶一下,在第二部分中,我們介紹了沒(méi)有語(yǔ)義信息時(shí)unet的輸入輸出情況。大概就是下圖這個(gè)樣子,輸入是噪聲強(qiáng)度和加噪圖,輸出是加噪圖上所加的噪聲。
現(xiàn)在有了語(yǔ)義的embedding向量,稍作修改之后,我們就有了新的輸入輸出關(guān)系圖。語(yǔ)義embedding向量在下圖中表示為藍(lán)色3*5的方格:
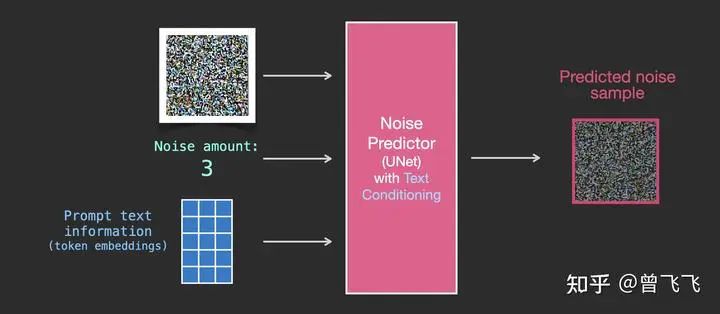
訓(xùn)練的數(shù)據(jù)集也添加了文字的數(shù)據(jù)對(duì),現(xiàn)在輸入變成了噪聲強(qiáng)度+加噪圖+文字:

要更清楚的知道語(yǔ)義向量是這么作用于這個(gè)過(guò)程中的,我們必須更深入的了解一下Unet里面是怎么工作的。
1,沒(méi)有文字時(shí)的Unet
首先,沒(méi)有文字的時(shí)候,unet宏觀的工作模式我們已經(jīng)很清楚了。unet的輸入是加噪圖和噪聲強(qiáng)度,輸出是加噪圖上所加的噪聲:

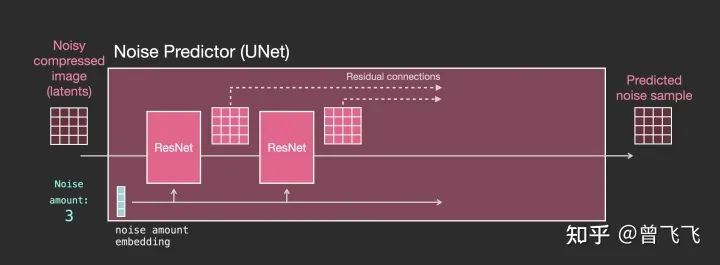
然后,當(dāng)我們要更細(xì)致的了解unet里面到底是什么樣的時(shí)候,就可以把上圖中代表unet的小粉塊放大來(lái)看。如下圖所示,整個(gè)unet內(nèi)部的流程特點(diǎn)如下
-
整個(gè)unet是由一系列Resnet構(gòu)成的。 -
每一層的輸入都是上一層的輸出。 -
一些輸出用residual connection直接跳躍到后面去,如下圖中的虛線,這種residual+skip的操作也是很經(jīng)典的unet思想。 -
噪聲強(qiáng)度被轉(zhuǎn)換成一個(gè)embedding向量,輸入到每一個(gè)子的Resnet里面。這也是噪聲強(qiáng)度能控制unet的底層原理所在。
2,有文字時(shí)的Unet
了解了沒(méi)有文字時(shí)的unet是怎么工作的之后,接下來(lái)我們就要加入文字的處理了。首先,還是看宏觀的輸入輸出,相比上面額外添加了文字embedding作為輸入【下圖藍(lán)色3*5】:

我們?cè)偌?xì)看一下粉色的unet模塊里到底發(fā)生了什么。如下圖所示,每個(gè)Resnet不再和相鄰的Resnet直接連接,而是在中間新增了Attention的模塊。CLIP Encoder得到的語(yǔ)義embedding就用這個(gè)Attention模塊來(lái)處理。
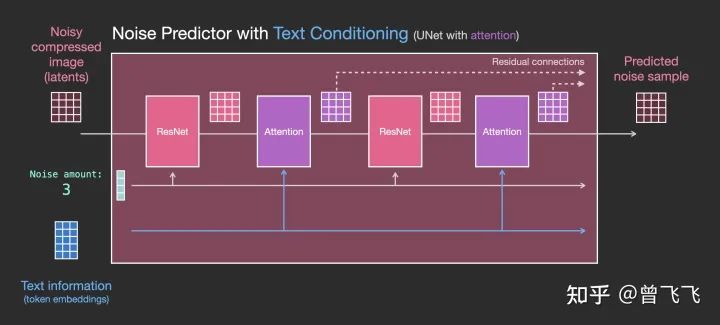
注意到,Resnet模塊并不直接以文字作為輸入,而是使用了Attention作為后處理模塊。現(xiàn)在Unet就可以通過(guò)這一方式成功利用CLIP的語(yǔ)義信息了。就此,我們也就能成功完成文生圖的任務(wù)。
三、總結(jié)
最后,再簡(jiǎn)單歸納一下第三部分的內(nèi)容,給我們的Stable Diffusion的理解系列畫(huà)上一個(gè)完美的句點(diǎn):
-
語(yǔ)義信息怎么來(lái)?——我們介紹了CLIP模型以及它的訓(xùn)練方式,主要運(yùn)用匹配的圖片對(duì)和不匹配的圖片對(duì)讓CLIP模型去判斷,通過(guò)判斷結(jié)果更新兩個(gè)Encoder的參數(shù)。 -
語(yǔ)義信息怎么用?——我們觀察了不用語(yǔ)義信息的Unet,并將其推廣到使用語(yǔ)義信息的Unet。具體來(lái)說(shuō),就是在內(nèi)部的每一個(gè)小小的Resnet后面加上一個(gè)Attention模塊處理語(yǔ)義信息。
如果你成功地看到了這里,那么首先要恭喜你看完了這共計(jì)一萬(wàn)字的大長(zhǎng)文。希望這篇文章能夠給你一個(gè)基本的直覺(jué),讓你明白Stable Diffusion是怎么工作的。事實(shí)上,還有很多其他的模塊或者是細(xì)節(jié),但是一旦你理解了這些基礎(chǔ)模塊的工作原理,那些附加的額外模塊相信你也可以輕松理解。
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。
下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車(chē)道線檢測(cè)、車(chē)輛計(jì)數(shù)、添加眼線、車(chē)牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。
下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講
在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~