數(shù)據(jù)分析方法和思維—RFM用戶分群

01
在運營場景中, 經(jīng)常需要對用戶進(jìn)行分層, 把整體的用戶分層不同的層次的用戶, 然后針對不同層次的用戶采取不同的運營策略, 也被稱作精細(xì)化運營。但是如何運用科學(xué)的方法對用戶進(jìn)行劃分呢。
經(jīng)常遇到的例子是這樣的,?比如針對抖音的打賞的用戶, 把這些用戶按照不同的價值度進(jìn)行劃分, 然后針對不同價值的用戶發(fā)放不同的優(yōu)惠套路, 比如充值多少優(yōu)惠多少
經(jīng)常產(chǎn)品就會按照單一的月付費次數(shù)規(guī)則去劃分, 比如如下, 我們就可以得到三種不同價值的用戶, 這種劃分的方法簡單來看是沒有大問題的, 但是對于數(shù)據(jù)分析師來說并不是科學(xué)的方法。
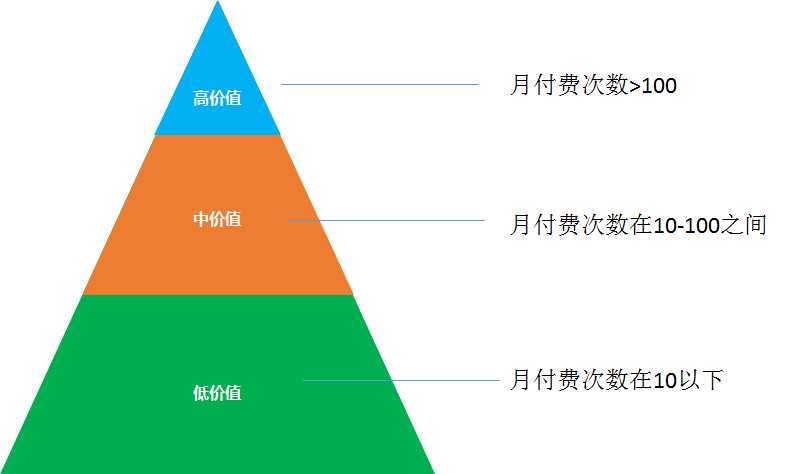
主要的缺點有兩個, 首先是只用單一的付費次數(shù)來衡量用戶的價值度, 沒有考慮用戶的付費金額, 一個用戶假如付費的次數(shù)很頻繁, 但付費的金額小, 那么他的價值度可能不如另外一個用戶付費次數(shù)小于他的 但付費金額比他高很多。
另外人為定的劃分的標(biāo)準(zhǔn)比如用付費次數(shù) 10, 100作為兩個劃分的臨界點, 沒有科學(xué)性, 很容易分出來的幾乎絕大多數(shù)都變成高價值的用戶, 這樣肯定是不合理的。
一般來說, 肯定是高價值的用戶的數(shù)量遠(yuǎn)遠(yuǎn)小于低價值的用戶, 但這種數(shù)量是跟我們劃分的標(biāo)準(zhǔn)緊密相關(guān)的, 不同的人定的劃分的數(shù)值標(biāo)準(zhǔn)是不一樣的, 那么定出來的高價值和低價值的差別就會較大, 所以我們需要去用一種科學(xué)的, 通用的劃分方法去做用戶分群。
而RFM作為用戶價值的劃分的經(jīng)典模型, 就可以解決這種分群的問題。
02
什么是RFM
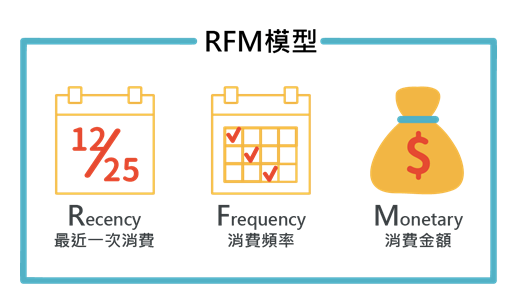
RFM 模型是利用 R, F, M 三個特征去對用戶進(jìn)行劃分的。
其中R是表示最后一次付費的日期距離現(xiàn)在的時間, 比如你在 12月20號給一個主播打賞過, 那么到現(xiàn)在的距離的天數(shù)是5 那么R就是5, R是用來刻畫用戶的忠誠度, 一般來說R越小, 代表用戶上一次剛剛才付費的, 這種用戶的忠誠度比較高。
F是表示一段時間的付費頻次,?也就是比如一個月付費了多少次, 這個是用來刻畫用戶付費行為的活躍度,?我們認(rèn)為用戶的付費行為頻次越高, 一定程度上代表他的價值度
M是表示一段時間的付費金額, 比如一個月付費了10000元, M=10000, M主要是用來刻畫用戶的土豪程度。
以上我們就從用戶的忠誠度, 活躍度, 土豪度三個方面去刻畫一個用戶的價值度。
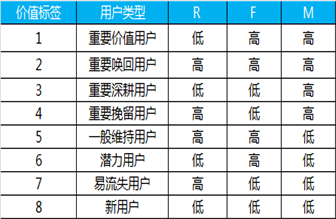
根據(jù)RFM的值, 我們就可以把用戶劃分為以下不同的類別:
重要價值用戶: R 低,?F?高, M 高, 這種用戶價值度非常高, 因為忠誠度高,?付費頻次高, 又很土豪
重要召回用戶: R 低,?F 低?M 高, 因為付費頻次低, 但金額高, 所以是重點召回用戶
重要發(fā)展用戶:?R 高, F 低, M 高 因為忠誠度不夠, 所以需要大力發(fā)展
重要挽留用戶: R 高?F 低?M高? 因為?忠誠度和活躍度都不夠 很容易流失 所以需要重點挽留
還有四種其他用戶就不一一列舉
03
RFM如何進(jìn)行用戶分群
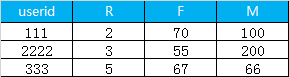
1.首先是利用sql 計算 每一個用戶的 R, F, M, 最終得到的數(shù)據(jù)格式如下
2.?讀取數(shù)據(jù)和查看數(shù)據(jù)
pay_data= pd.read_csv('d:/My Documents/Desktop/train_pay.csv')#?路徑名 'd:/My Documents/Desktop/train_pay.csv' 填寫你自己的即可pay_data.head() # 查看數(shù)據(jù)前面幾行
3. 選取我們要聚類的特征
pay_RFM = pay_data[['r_c','f_c','m_c']]4. 開始聚類, 因為我們用戶分群分的是八個類別, 所以k =8?
# 創(chuàng)建模型model_k = KMeans(n_clusters=8,random_state=1)#?模型訓(xùn)練model_k.fit(pay_RFM)#?聚類出來的類別賦值給新的變量?cluster_labelscluster_labels = model_k.labels_
5. 對聚類的結(jié)果中每一個類別計算 每個類別的數(shù)量?最小值 最大值 平均值等指標(biāo)
rfm_kmeans = pay_RFM.assign(class1=cluster_labels)num_agg = {'r_c':['mean', 'count','min','max'], 'f_c':['mean', 'count','min','max'],'m_c':['mean','sum','count','min','max']}rfm_kmeans.groupby('class1').agg(num_agg).round(2)
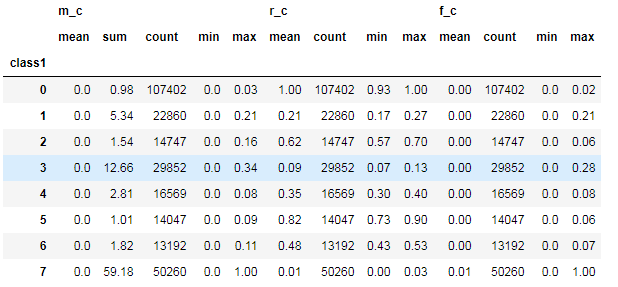
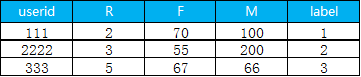
6.?把聚類出來的類別和用戶id 拼接在一起
pay_data.assign(class1=cluster_labels).to_csv('d:/My Documents/Desktop/result.csv',header=True, sep=',')下面就是最終結(jié)果,?label 表示用戶是屬于哪一個細(xì)分的類別
04
RFM模型的應(yīng)用
重要價值客戶:占比11.7%,處于正常水平,RFM都很大,對這部分優(yōu)質(zhì)客戶要特殊保護
重要喚回客戶:占比13.28%,交易金額和次數(shù)多,但最近無交易,需要運營/業(yè)務(wù)人員對其進(jìn)行喚回(可用紅包、獎勵、優(yōu)惠券等方式)
重要深耕客戶:占比16.12%,該類客戶占比最多,近期有交易且平均交易金額也多,交易頻次低,所以需要對其識別后進(jìn)行個性化推薦,增加用戶付費次數(shù),提高粘性
重要挽留客戶:占比9.02%,該類客戶占比最少,交易金額多于平均值,其付費能力較強,但最近無消費、消費頻率低,可能是我們的潛在客戶或易流失客戶,可以找到該部分用戶讓其給出反饋建議等
潛力客戶:占比11.11%,交易次數(shù)多近期也有消費,但整體消費金額低,可能是對價格較敏感或付費能力不足,可對該部分用戶進(jìn)行商品關(guān)聯(lián)推薦
新客戶:占比14.79%,最近有消費,交易頻率和金額也不高,可對該部分用戶增加關(guān)懷,推送優(yōu)惠信息,增加粘性
一般維持客戶:占比13.7%,累計單數(shù)高,近期無消費,交易金額不高,該部分客戶可能快要流失,可低成本營銷
流失客戶:占比10.28%,三項指標(biāo)均低于平均值,已經(jīng)流失,有可能不是目標(biāo)客戶,若經(jīng)費有限可忽略此類用戶
文章點贊超過100+
我將在個人視頻號直播(老表Max)
帶大家一起進(jìn)行項目實戰(zhàn)復(fù)現(xiàn)
掃碼即可加我微信
老表朋友圈經(jīng)常有贈書/紅包福利活動
學(xué)習(xí)更多: 整理了我開始分享學(xué)習(xí)筆記到現(xiàn)在超過250篇優(yōu)質(zhì)文章,涵蓋數(shù)據(jù)分析、爬蟲、機器學(xué)習(xí)等方面,別再說不知道該從哪開始,實戰(zhàn)哪里找了 “點贊”就是對博主最大的支持?