
保姆級(jí)教程,用PyTorch搭一個(gè)神經(jīng)網(wǎng)絡(luò)
作為NumPy的替代品,可以利用GPU的性能進(jìn)行計(jì)算 作為一個(gè)高靈活性、速度快的深度學(xué)習(xí)平臺(tái)
在PyTorch中搭建神經(jīng)網(wǎng)絡(luò)并使用真實(shí)的天氣信息預(yù)測(cè)明天是否會(huì)下雨。
預(yù)處理 CSV 文件并將數(shù)據(jù)轉(zhuǎn)換為張量 使用 PyTorch 構(gòu)建神經(jīng)網(wǎng)絡(luò)模型 使用損失函數(shù)和優(yōu)化器來訓(xùn)練模型 評(píng)估模型并了解分類不平衡的危害
寫在前面
在開始構(gòu)建神經(jīng)網(wǎng)絡(luò)之前,首先了解一下幾個(gè)重要概念。
torch.Tensor
一個(gè)多維數(shù)組,支持諸如backward()等的自動(dòng)求導(dǎo)操作,同時(shí)也保存了張量的梯度。nn.Module
神經(jīng)網(wǎng)絡(luò)模塊。是一種方便封裝參數(shù)的方式,具有將參數(shù)移動(dòng)到GPU、導(dǎo)出、加載等功能。nn.Parameter
張量的一種,當(dāng)它作為一個(gè)屬性分配給一個(gè)Module時(shí),它會(huì)被自動(dòng)注冊(cè)為一個(gè)參數(shù)。autograd.Function
實(shí)現(xiàn)了自動(dòng)求導(dǎo)前向和反向傳播的定義,每個(gè)Tensor至少創(chuàng)建一個(gè)Function節(jié)點(diǎn),該節(jié)點(diǎn)連接到創(chuàng)建Tensor的函數(shù)并對(duì)其歷史進(jìn)行編碼。

導(dǎo)入相關(guān)模塊

#?pip?install?torch
import?torch
import?os
import?numpy?as?np
import?pandas?as?pd
from?tqdm?import?tqdm
import?seaborn?as?sns
from?pylab?import?rcParams
import?matplotlib.pyplot?as?plt
from?matplotlib?import?rc
from?sklearn.model_selection?import?train_test_split
from?sklearn.metrics?import?confusion_matrix,?classification_report
from?torch?import?nn,?optim
import?torch.nn.functional?as?F
%matplotlib?inline
%config?InlineBackend.figure_format='retina'
sns.set(style='whitegrid',?palette='muted',?font_scale=1.2)
HAPPY_COLORS_PALETTE?=?["#01BEFE",?"#FFDD00",?"#FF7D00",?"#FF006D",?"#93D30C",?"#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize']?=?12,?6
RANDOM_SEED?=?42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)數(shù)據(jù)集
我們的數(shù)據(jù)集包含來自多個(gè)澳大利亞氣象站的每日天氣信息。本次目標(biāo)是要回答一個(gè)簡(jiǎn)單的問題:明天會(huì)下雨嗎?
數(shù)據(jù)集來自Kaggle[文末參考鏈接2],接下來先通過Pandas讀取導(dǎo)入數(shù)據(jù)集。
df?=?pd.read_csv('./data/weatherAUS.csv')
df.head()
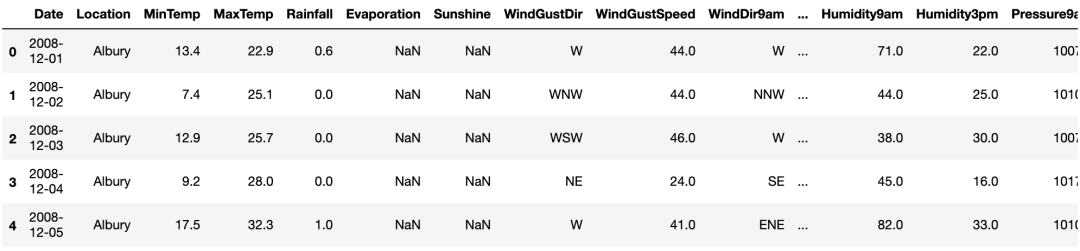
這里有很多特征列。也有很多NaN。下面來看看整體數(shù)據(jù)集大小。
df.shape
(145460, 23)
從數(shù)據(jù)集形狀看,這里數(shù)據(jù)還不少,超過14.5w條數(shù)據(jù)。
數(shù)據(jù)預(yù)處理
本節(jié)中,我們并不希望數(shù)據(jù)集和目標(biāo)問題有多復(fù)雜,嘗試將通過刪除大部分?jǐn)?shù)據(jù)來簡(jiǎn)化這個(gè)問題。這里只使用4個(gè)特征來預(yù)測(cè)明天是否會(huì)下雨。在你實(shí)際案例中,根據(jù)實(shí)際問題,特征數(shù)量可以比這多,也可以比這少,只要注意下面輸入數(shù)據(jù)維度即可。
cols?=?['Rainfall',?'Humidity3pm',?'Pressure9am',?'RainToday',?'RainTomorrow']
df?=?df[cols]
特征轉(zhuǎn)換
因?yàn)樯窠?jīng)網(wǎng)絡(luò)只能處理數(shù)字。所以我們將把文字的?yes 和 no?分別轉(zhuǎn)換為數(shù)字1 和 0。
df['RainToday'].replace({'No':?0,?'Yes':?1},?inplace?=?True)
df['RainTomorrow'].replace({'No':?0,?'Yes':?1},?inplace?=?True)
缺失值處理
刪除缺少值的行。也許會(huì)有更好的方法來處理這些缺失的行,但我們這里將簡(jiǎn)單地處理,直接刪除含有缺失值的行。
df?=?df.dropna(how='any')
df.head()
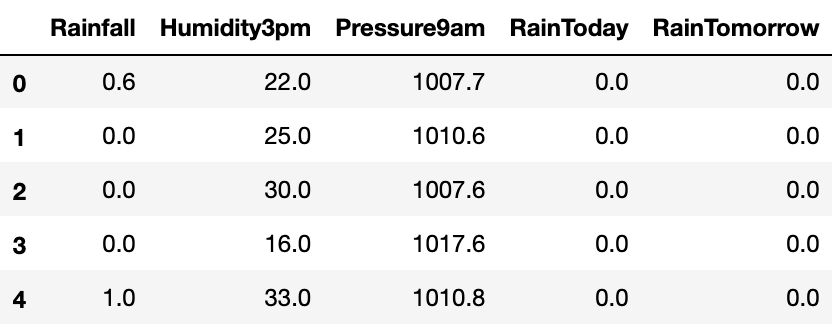
樣本不平衡處理
到目前為止,我們有了一個(gè)可以使用的數(shù)據(jù)集。這里我們需要回答的一個(gè)重要問題是 --?我們的數(shù)據(jù)集是否平衡??或者?明天到底會(huì)下多少次雨?
因此通過sns.countplot函數(shù)直接定性分析整個(gè)樣本集中是否下雨分別多少次,以此判斷正負(fù)樣本(是否有雨)是否平衡。
sns.countplot(df.RainTomorrow);
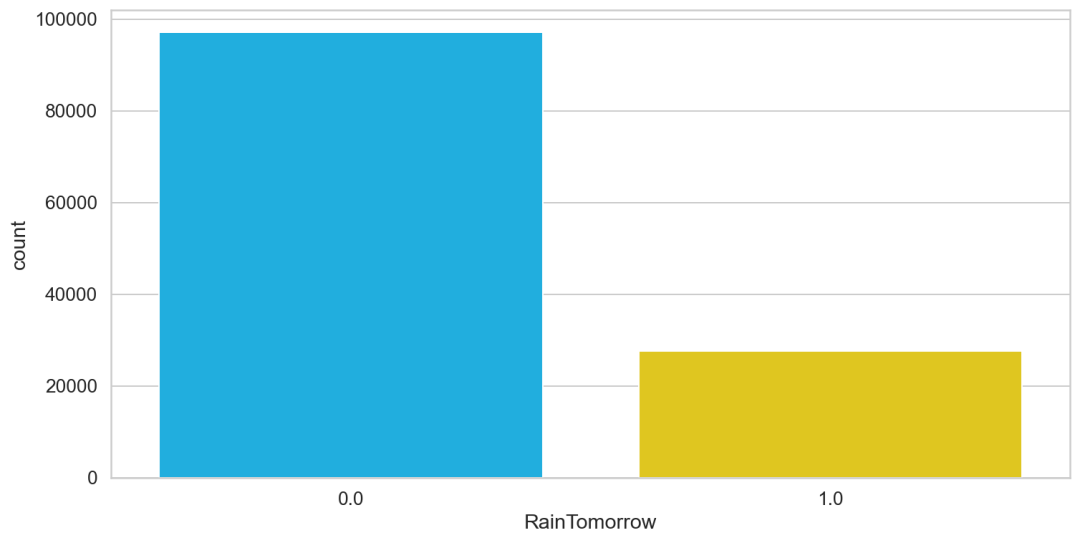
從結(jié)果看,下雨次數(shù)明顯比不下雨次數(shù)要少很多。再通過具體定量計(jì)算正負(fù)樣本數(shù)。
df.RainTomorrow.value_counts()?/?df.shape[0]
0.0 0.778762
1.0 0.221238
Name: RainTomorrow, dtype: float64
事情看起來不妙。約78%的數(shù)據(jù)點(diǎn)表示明天不會(huì)下雨。這意味著一個(gè)預(yù)測(cè)明天是否下雨的模型在78%的時(shí)間里是正確的。
如果想要解決此次樣本不平衡,以緩解其帶來的影響,可以參考云朵君先前文章機(jī)器學(xué)習(xí)中樣本不平衡,怎么辦?而這里,我們暫不做任何處理,但愿他對(duì)結(jié)果影響不大。
樣劃分訓(xùn)練集和測(cè)試集
數(shù)據(jù)預(yù)處理的最后一步是將數(shù)據(jù)分割為訓(xùn)練集和測(cè)試集。這一步大家應(yīng)該并不陌生,可以直接使用train_test_split()。
X?=?df[['Rainfall',?'Humidity3pm',?'RainToday',?'Pressure9am']]
y?=?df[['RainTomorrow']]
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?test_size=0.2,?random_state=RANDOM_SEED)
數(shù)據(jù)類型轉(zhuǎn)換
為了符合 PyTorch 所需求的數(shù)據(jù)類型。使用 python標(biāo)準(zhǔn)庫(kù)將數(shù)據(jù)加載到numpy數(shù)組里。然后將這個(gè)數(shù)組轉(zhuǎn)化成將全部數(shù)據(jù)轉(zhuǎn)換為張量(torch.Tensor)。
注意:Torch張量和NumPy數(shù)組將共享它們的底層內(nèi)存位置,因此當(dāng)一個(gè)改變時(shí),另外也會(huì)改變。
X_train.head()
PyTorch中也是非常方便,直接通過from_numpy直接轉(zhuǎn)換。
X_train?=?torch.from_numpy(X_train.to_numpy()).float()
y_train?=?torch.squeeze(torch.from_numpy(y_train.to_numpy()).float())
X_test?=?torch.from_numpy(X_test.to_numpy()).float()
y_test?=?torch.squeeze(torch.from_numpy(y_test.to_numpy()).float())
print(X_train.shape,?y_train.shape)
print(X_test.shape,?y_test.shape)
torch.Size([99751, 4]) torch.Size([99751])
torch.Size([24938, 4]) torch.Size([24938])
到目前為止,所有數(shù)據(jù)準(zhǔn)備工作已經(jīng)結(jié)束。
構(gòu)建神經(jīng)網(wǎng)絡(luò)
接下來我們將使用PyTorch建立一個(gè)簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò)(NN),嘗試預(yù)測(cè)明天是否會(huì)下雨。本次構(gòu)建的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)分為三個(gè)層,輸入層、輸出層和隱藏層。
輸入層:?我們的輸入包含四列數(shù)據(jù):"Rainfall, Humidity3pm, RainToday, Pressure9am"(降雨量,濕度下午3點(diǎn),今天下雨,壓力上午9點(diǎn))。將為此創(chuàng)建一個(gè)適當(dāng)?shù)妮斎雽印?/p>
輸出層:?輸出將是一個(gè)介于 0 和 1 之間的數(shù)字,代表模型認(rèn)為明天下雨的可能性。預(yù)測(cè)將由網(wǎng)絡(luò)的輸出層提供給我們。
隱藏層:?將在輸入層和輸出層之間添加兩個(gè)隱藏層。這些層的參數(shù)(神經(jīng)元)將決定最終輸出。所有層都將是全連接的,即全連接層。
一個(gè)神經(jīng)網(wǎng)絡(luò)的典型訓(xùn)練過程如下:
定義包含一些可學(xué)習(xí)參數(shù)(或者叫權(quán)重)的神經(jīng)網(wǎng)絡(luò) 在輸入數(shù)據(jù)集上迭代 通過網(wǎng)絡(luò)處理輸入 計(jì)算loss(輸出和正確答案的距離) 將梯度反向傳播給網(wǎng)絡(luò)的參數(shù) 更新網(wǎng)絡(luò)的權(quán)重,一般使用一個(gè)簡(jiǎn)單的規(guī)則: weight = weight - learning_rate * gradient
可以使用torch.nn包來構(gòu)建神經(jīng)網(wǎng)絡(luò)。即使用 PyTorch 構(gòu)建神經(jīng)網(wǎng)絡(luò)的一種簡(jiǎn)單方法是創(chuàng)建一個(gè)繼承自?torch.nn.Module?的類。
這里將nn.Module子類化(它本身是一個(gè)類并且能夠跟蹤狀態(tài))。在這種情況下,我們要?jiǎng)?chuàng)建一個(gè)類,該類包含前進(jìn)步驟的權(quán)重,偏差和方法。nn.Module具有許多我們將要使用的屬性和方法(例如.parameters()和.zero_grad())。
class?Net(nn.Module):
????def?__init__(self,?n_features):
????????super(Net,?self).__init__()
????????self.fc1?=?nn.Linear(n_features,?5)
????????self.fc2?=?nn.Linear(5,?3)
????????self.fc3?=?nn.Linear(3,?1)
????def?forward(self,?x):
????????x?=?F.relu(self.fc1(x))
????????x?=?F.relu(self.fc2(x))
????????return?torch.sigmoid(self.fc3(x))
我們只需要定義 forward 函數(shù),backward函數(shù)會(huì)在使用autograd時(shí)自動(dòng)定義,backward函數(shù)用來計(jì)算導(dǎo)數(shù)。我們可以在 forward 函數(shù)中使用任何針對(duì)張量的操作和計(jì)算。
可視化神經(jīng)元
這里的可視化神經(jīng)元主要基于https://github.com/Prodicode/ann-visualizer,完整神經(jīng)網(wǎng)絡(luò)可視化獲取方式:公眾號(hào)「機(jī)器學(xué)習(xí)研習(xí)院」消息框回復(fù) 【神經(jīng)網(wǎng)絡(luò)可視化】獲取。
net?=?Net(X_train.shape[1])
#?pip?install?graphviz
#?mac上安裝graphviz?需要用?brew?install?graphviz?
ann_viz(net,?view=True)

我們首先在構(gòu)造函數(shù)中創(chuàng)建模型的層。forward()方法是奇跡發(fā)生的地方。它接受輸入??并允許它流過每一層。
有一個(gè)相應(yīng)的由PyTorch定義到向后傳遞backward()方法,它允許模型從當(dāng)前發(fā)生的誤差中學(xué)習(xí),并修正模型參數(shù)。
激活函數(shù)
細(xì)心的讀者可能會(huì)注意到構(gòu)建的神經(jīng)網(wǎng)絡(luò)中調(diào)用?F.relu?和?torch.sigmoid?。這些是激活函數(shù),那我們?yōu)槭裁葱枰@些?
神經(jīng)網(wǎng)絡(luò)的一個(gè)很酷的特性是它們可以近似非線性函數(shù)。事實(shí)上,已經(jīng)證明它們可以逼近任何函數(shù)[3]。
不過,如果想通過堆疊線性層來逼近非線性函數(shù),此時(shí)就需要激活函數(shù)。激活函數(shù)可以讓神經(jīng)網(wǎng)絡(luò)擺脫線性世界并學(xué)習(xí)更多。通常將其應(yīng)用于某個(gè)層的輸出。
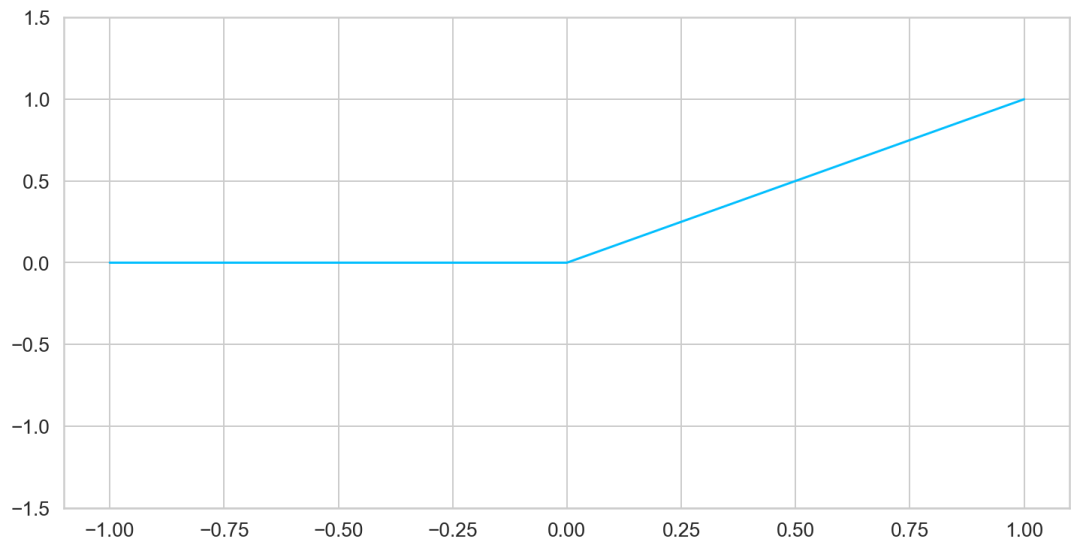
ReLU
從最廣泛使用的激活函數(shù)之一的 ReLU 定義開始:
該激活函數(shù)簡(jiǎn)單易行,其結(jié)果就是輸入值與零比較,得到的最大值。
從可視化結(jié)果看
ax?=?plt.gca()
plt.plot(
??np.linspace(-1,?1,?5),?
??F.relu(torch.linspace(-1,?1,?steps=5)).numpy()
)
ax.set_ylim([-1.5,?1.5]);
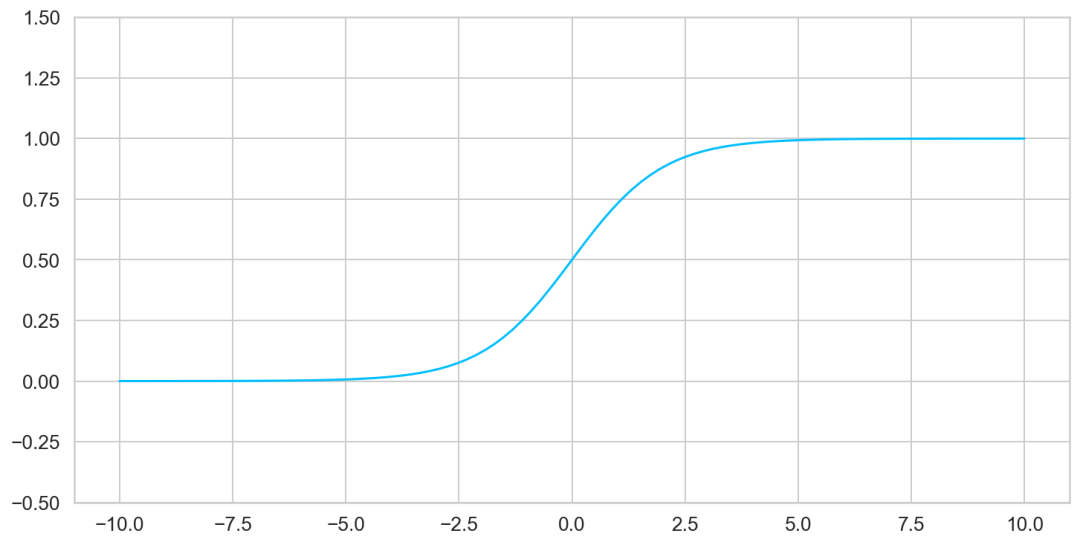
Sigmoid
它被定義為
當(dāng)需要進(jìn)行二元決策 / 分類(回答yes或no)時(shí),sigmoid?函數(shù)是很有用的。sigmoid 以一種超級(jí)的方式將輸入值壓縮在 0 和 1 之間。
從可視化結(jié)果看
ax?=?plt.gca()
plt.plot(
??np.linspace(-10,?10,?100),?
??torch.sigmoid(torch.linspace(-10,?10,?steps=100)).numpy()
)
ax.set_ylim([-0.5,?1.5]);
訓(xùn)練神經(jīng)網(wǎng)絡(luò)
目前為止,我們已經(jīng)看到了如何定義網(wǎng)絡(luò),接下來需要找到預(yù)測(cè)明天是否會(huì)下雨的參數(shù)。即需要找到該模型應(yīng)用于此次問題的最佳參數(shù)。而要想做到這點(diǎn),首先需要一些評(píng)價(jià)指標(biāo)來告訴我們,該模型目前做得有多好。
接下來需要計(jì)算損失,并更新網(wǎng)絡(luò)的權(quán)重。
損失函數(shù)
一個(gè)損失函數(shù)接受一對(duì)(output, target)作為輸入,計(jì)算一個(gè)值來估計(jì)網(wǎng)絡(luò)的輸出和目標(biāo)值相差多少。BCELoss[4]是一個(gè)損失函數(shù),其度量?jī)蓚€(gè)向量之間的差。
criterion?=?nn.BCELoss()
而在我們的例子中,這兩個(gè)向量即是我們的模型的預(yù)測(cè)和實(shí)際值。該損失函數(shù)的期望值由 sigmoid 函數(shù)輸出。該值越接近 0,模型效果越好。
但是我們?nèi)绾握业阶钚』瘬p失函數(shù)的參數(shù)呢?
優(yōu)化器
假設(shè)我們的神經(jīng)網(wǎng)絡(luò)的每個(gè)參數(shù)都是一個(gè)旋鈕。優(yōu)化器的工作是為每個(gè)旋鈕找到完美的位置,使損失接近0。
實(shí)戰(zhàn)中,模型可能包含數(shù)百萬甚至數(shù)十億個(gè)參數(shù)。有這么多旋鈕要轉(zhuǎn),如果有一個(gè)高效的優(yōu)化器可以快速找到解決方案,那就完美了。
而理想很豐滿,現(xiàn)實(shí)很骨感。深度學(xué)習(xí)中的優(yōu)化效果只能達(dá)到令人滿意的結(jié)果。在實(shí)踐中,可以提供可接受的準(zhǔn)確性的足夠好的參數(shù),就應(yīng)該心滿意足了。
在使用神經(jīng)網(wǎng)絡(luò)時(shí),PyTorch中提供了許多經(jīng)過良好調(diào)試過的優(yōu)化器,可能希望使用各種不同的更新規(guī)則,如SGD、Nesterov-SGD、Adam、RMSProp等。雖然你可以從這些優(yōu)化器中選擇,一般情況下,首選的還是Adam[5]。
optimizer?=?optim.Adam(net.parameters(),?lr=0.001)
一個(gè)模型的可學(xué)習(xí)參數(shù)可以通過net.parameters()。
自然地,優(yōu)化器需要輸入?yún)?shù)。第二個(gè)參數(shù)lr?是?learning rate?(學(xué)習(xí)率),這是要找到的最優(yōu)參數(shù)和到達(dá)最優(yōu)解的速度之間的權(quán)衡。而為此找到最優(yōu)解的方法或過程可能是黑魔法和大量的暴力“實(shí)驗(yàn)”。
在 GPU 上計(jì)算
在 GPU 上進(jìn)行大規(guī)模并行計(jì)算是現(xiàn)代深度學(xué)習(xí)的推動(dòng)因素之一。為此,您將需要配置 NVIDIA GPU。
如果你的設(shè)備上裝有GPU,PyTorch 中可以非常輕松地將所有計(jì)算傳輸?shù)?GPU。
我們首先檢查 CUDA 設(shè)備是否可用。然后,我們將所有訓(xùn)練和測(cè)試數(shù)據(jù)傳輸?shù)皆撛O(shè)備。最后移動(dòng)模型和損失函數(shù)。
張量可以使用.to方法移動(dòng)到任何設(shè)備(device)上。
device?=?torch.device("cuda:0"?if?torch.cuda.is_available()?else?"cpu")
X_train?=?X_train.to(device)
y_train?=?y_train.to(device)
X_test?=?X_test.to(device)
y_test?=?y_test.to(device)
net?=?net.to(device)
criterion?=?criterion.to(device)
尋找最優(yōu)參數(shù)
擁有損失函數(shù)固然很好,追蹤模型的準(zhǔn)確性是一件更容易理解的事情,而一般通過定義準(zhǔn)確性來做模型評(píng)價(jià)。
def?calculate_accuracy(y_true,?y_pred):
????predicted?=?y_pred.ge(.5).view(-1)
????return?(y_true?==?predicted).sum().float()?/?len(y_true)
我們定義一個(gè)預(yù)值,將連續(xù)概率值轉(zhuǎn)換為二分類值。即將每個(gè)低于 0.5 的值轉(zhuǎn)換為 0,高于0.5的值設(shè)置為 1。最后計(jì)算正確值的百分比。
所有的模塊都準(zhǔn)備好了,我們可以開始訓(xùn)練我們的模型了。
def?round_tensor(t,?decimal_places=3):
????return?round(t.item(),?decimal_places)
for?epoch?in?range(1000):????
????y_pred?=?net(X_train)
????y_pred?=?torch.squeeze(y_pred)
????train_loss?=?criterion(y_pred,?y_train)
????
????if?epoch?%?100?==?0:
????????train_acc?=?calculate_accuracy(y_train,?y_pred)
????????y_test_pred?=?net(X_test)
????????y_test_pred?=?torch.squeeze(y_test_pred)
????????test_loss?=?criterion(y_test_pred,?y_test)
????????test_acc?=?calculate_accuracy(y_test,?y_test_pred)
????????print(f'''epoch?{epoch}
??????????????Train?set?-?loss:?{round_tensor(train_loss)},?accuracy:?{round_tensor(train_acc)}
??????????????Test??set?-?loss:?{round_tensor(test_loss)},?accuracy:?{round_tensor(test_acc)}
??????????????''')
????
????optimizer.zero_grad()??#?清零梯度緩存
????train_loss.backward()?#?反向傳播誤差
????optimizer.step()??#?更新參數(shù)
epoch 0
Train set - loss: 0.94, accuracy: 0.779
Test set - loss: 0.94, accuracy: 0.778
epoch 100
Train set - loss: 0.466, accuracy: 0.78
Test set - loss: 0.466, accuracy: 0.779
...
epoch 900
Train set - loss: 0.41, accuracy: 0.833
Test set - loss: 0.408, accuracy: 0.834
在訓(xùn)練期間,我們向模型傳輸數(shù)據(jù)共計(jì)10,000次。每次測(cè)量損失時(shí),將誤差傳播到模型中,并要求優(yōu)化器找到更好的參數(shù)。
用?zero_grad()?方法清零所有參數(shù)的梯度緩存,然后進(jìn)行隨機(jī)梯度的反向傳播。如果忽略了這一步,梯度將會(huì)累積,導(dǎo)致模型不可用。
測(cè)試集上的準(zhǔn)確率為 83.4% 聽起來挺合理,但可能要讓你失望了,這樣的結(jié)果并不是很理想,接下來看看是如何不合理。
但首先我們需要學(xué)習(xí)如何保存和加載訓(xùn)練好的模型。
保存模型
訓(xùn)練一個(gè)好的模型可能需要很多時(shí)間。可能是幾周、幾個(gè)月甚至幾年。如果在訓(xùn)練過程了忘記保存,或不知道需要保存模型,這將會(huì)是非常痛苦的事情。因此這里需要確保我們知道如何保存寶貴的工作。其實(shí)保存很容易,但你不能忘記這件事。
MODEL_PATH?=?'model.pth'??#?后綴名為?.pth
torch.save(net,?MODEL_PATH)?#?直接使用torch.save()函數(shù)即可
當(dāng)然恢復(fù)模型也很容易,直接使用?torch.load()?函數(shù)即可。
net?=?torch.load(MODEL_PATH)評(píng)估
如果知道你的模型會(huì)犯什么樣的錯(cuò)誤不是很好嗎?當(dāng)然,這一點(diǎn)是非常難做到的。但是你可以通過一定的方法得到一個(gè)估計(jì)值。而僅使用準(zhǔn)確性來評(píng)估并不是一個(gè)好方法,尤其在樣本不平衡的二分類數(shù)據(jù)集上。仔細(xì)回想一下,我們的數(shù)據(jù)是一個(gè)很不平衡的數(shù)據(jù)集,其幾乎不包含明天會(huì)降雨樣本。
深入研究模型性能的一種方法是評(píng)估每個(gè)類的精確度和召回率。在我們的例子中,將是結(jié)果標(biāo)簽分別是?no rain?和?rain?。
classes?=?['No?rain',?'Raining']
y_pred?=?net(X_test)
y_pred?=?y_pred.ge(.5).view(-1).cpu()
y_test?=?y_test.cpu()
print(classification_report(y_test,?y_pred,?
????????????????????????????target_names=classes))
precision recall f1-score support
No rain 0.84 0.97 0.90 19413
Raining 0.76 0.37 0.50 5525
accuracy 0.83 24938
macro avg 0.80 0.67 0.70 24938
weighted avg 0.82 0.83 0.81 24938
精確度最大值為1,表明該模型只適用于識(shí)別相關(guān)的樣本。召回率最大值為1,表示模型可以在這個(gè)類的數(shù)據(jù)集中找到所有相關(guān)的示例。
可以看到模型在無雨類方面表現(xiàn)良好,因?yàn)闃颖局袩o雨類樣本數(shù)量較大。不幸的是,我們不能完全相信有雨類的預(yù)測(cè),因?yàn)闃颖静黄胶鈱?dǎo)致模型傾向于無雨類。
可以通過查看一個(gè)簡(jiǎn)單的混淆矩陣來評(píng)估二分類效果。
cm?=?confusion_matrix(y_test,?y_pred)
df_cm?=?pd.DataFrame(cm,?index=classes,?columns=classes)
hmap?=?sns.heatmap(df_cm,?annot=True,?fmt="d")
hmap.yaxis.set_ticklabels(hmap.yaxis.get_ticklabels(),?rotation=0,?ha='right')
hmap.xaxis.set_ticklabels(hmap.xaxis.get_ticklabels(),?rotation=30,?ha='right')
plt.ylabel('True?label')
plt.xlabel('Predicted?label');
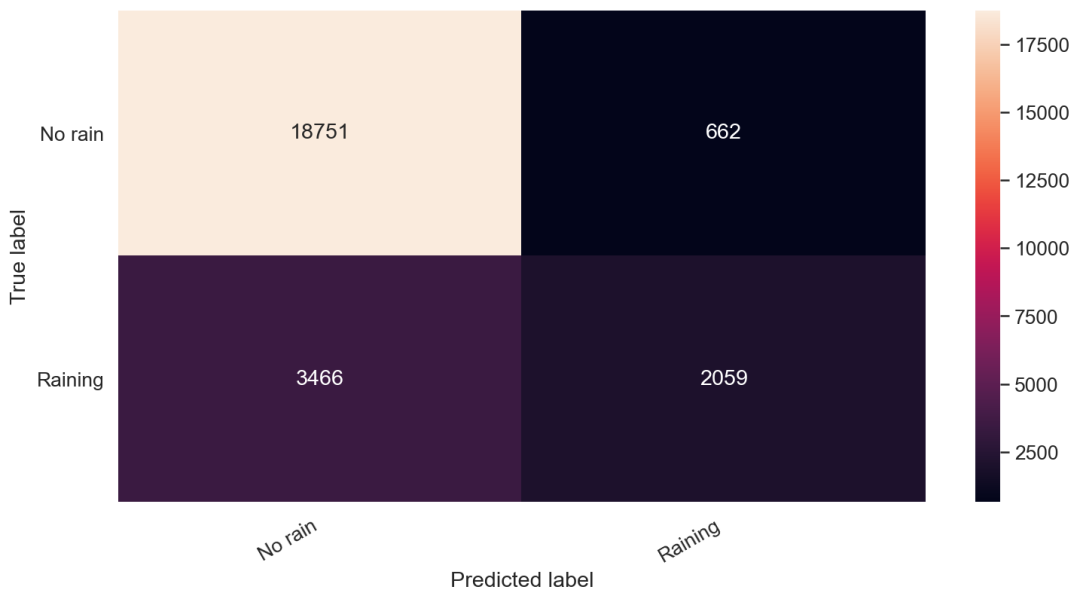
你可以清楚地看到,當(dāng)我們的模型預(yù)測(cè)要下雨時(shí),我們應(yīng)該抱有懷疑的態(tài)度。
模型預(yù)測(cè)
使用一些假設(shè)的例子上測(cè)試下模型。
def?will_it_rain(rainfall,?humidity,?rain_today,?pressure):
????t?=?torch.as_tensor([rainfall,?humidity,?rain_today,?pressure])?\
??????.float()?\
??????.to(device)
????output?=?net(t)
????return?output.ge(0.5).item()
這個(gè)函數(shù)將根據(jù)模型預(yù)測(cè)返回一個(gè)布爾值。讓我們?cè)囋嚳矗?/p>
will_it_rain(rainfall=10,?humidity=10,?
?????????????rain_today=True,?pressure=2)
>>>?True
will_it_rain(rainfall=0,?humidity=1,?
?????????????rain_today=False,?pressure=100)
>>>?False
根據(jù)一些參數(shù)得到了兩種不同的返回值。到這里為止,模型已準(zhǔn)備好部署來,但實(shí)際情況下,請(qǐng)不要匆忙部署,因?yàn)樵撃P筒⒉皇且粋€(gè)最佳的狀態(tài),只是用來掩飾如何使用PyTorch搭建模型!
寫在最后
如果你看到這里,將給你點(diǎn)個(gè)贊!因?yàn)槟悻F(xiàn)在成功搭建了一個(gè)可以預(yù)測(cè)天氣的神經(jīng)網(wǎng)絡(luò)深度學(xué)習(xí)模型。雖然此次用PyTorch搭建的深度學(xué)習(xí)模型是一個(gè)入門級(jí)別的模型,但其他更加復(fù)雜的神經(jīng)網(wǎng)絡(luò)模型的核心步驟與此類似。
說實(shí)話,構(gòu)建性能良好的模型真的很難,但在多次搭建模型過程中,你會(huì)不斷學(xué)到一些技巧,并能夠不斷進(jìn)步,這將會(huì)幫助你以后做的更好。
參考資料
參考原文:?https://curiousily.com/posts/build-your-first-neural-network-with-pytorch/
[2]?Kaggle:?https://www.kaggle.com/jsphyg/weather-dataset-rattle-package
[3]?已經(jīng)證明它們可以逼近任何函數(shù):?https://en.wikipedia.org/wiki/Universal_approximation_theorem
[4]?BCELoss:?https://pytorch.org/docs/stable/nn.html#bceloss
[5]?Adam:?https://pytorch.org/docs/stable/optim.html#torch.optim.Adam