
通俗講解強(qiáng)化學(xué)習(xí)!
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá) 
知乎 | https://www.zhihu.com/people/xu-xiu-jian-33
前言:強(qiáng)化學(xué)習(xí)這個(gè)概念是2017年Alpha Go戰(zhàn)勝了當(dāng)時(shí)世界排名第一的柯潔而被大眾知道,后面隨著強(qiáng)化學(xué)習(xí)在各大游戲比如王者榮耀中被應(yīng)用,而被越來(lái)越多人熟知。王者榮耀AI團(tuán)隊(duì),甚至在頂級(jí)期刊AAAI上發(fā)表過(guò)強(qiáng)化學(xué)習(xí)在王者榮耀中應(yīng)用的論文。那么強(qiáng)化學(xué)習(xí)到底是什么,如何應(yīng)用?下面和大家分享我對(duì)強(qiáng)化學(xué)習(xí)的整個(gè)過(guò)程,以及強(qiáng)化學(xué)習(xí)目前在工業(yè)界是如何應(yīng)用的,歡迎溝通交流。

1 簡(jiǎn)介強(qiáng)化學(xué)習(xí)
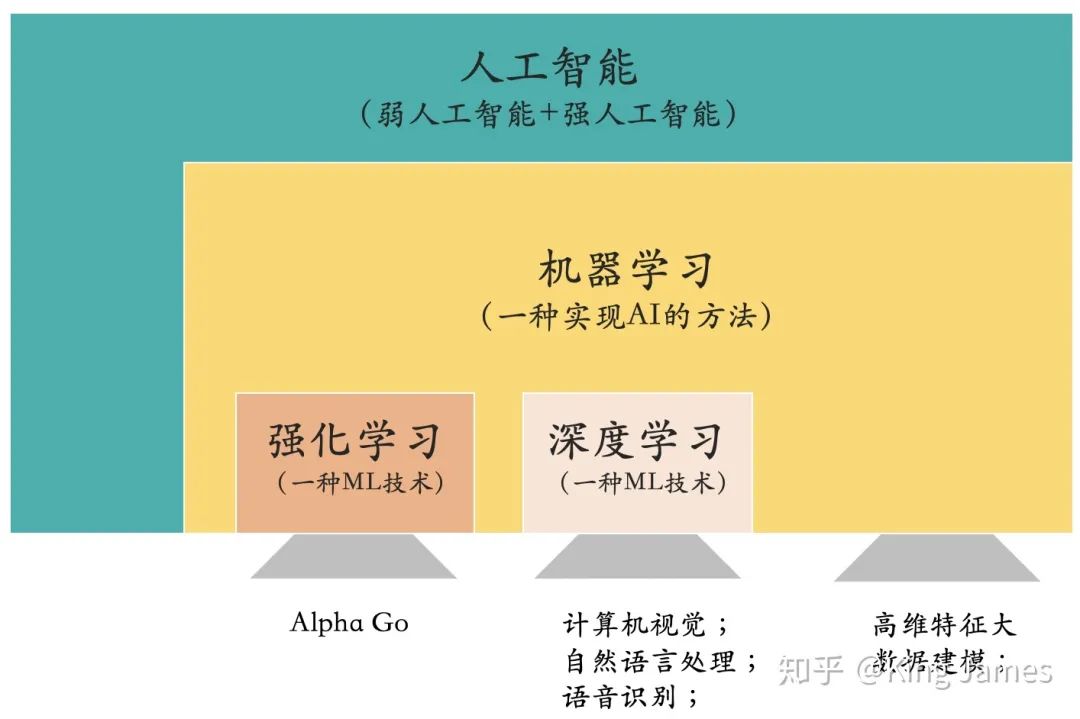
強(qiáng)化學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)分支。
1.1 什么是強(qiáng)化學(xué)習(xí)

強(qiáng)化學(xué)習(xí)是一種機(jī)器學(xué)習(xí)的學(xué)習(xí)方式(四種主要的機(jī)器學(xué)習(xí)方式解釋見上圖)。

上圖沒有提到深度學(xué)習(xí),是因?yàn)閺膶W(xué)習(xí)方式層面上來(lái)說(shuō),深度學(xué)習(xí)屬于上述四種方式的子集。而強(qiáng)化學(xué)習(xí)是獨(dú)立存在的,所以上圖單獨(dú)列出強(qiáng)化學(xué)習(xí),而沒有列出深度學(xué)習(xí)。
強(qiáng)化學(xué)習(xí)和其他三種學(xué)習(xí)方式主要不同點(diǎn)在于:強(qiáng)化學(xué)習(xí)訓(xùn)練時(shí),需要環(huán)境給予反饋,以及對(duì)應(yīng)具體的反饋值。它不是一個(gè)分類的任務(wù),不是金融反欺詐場(chǎng)景中如何分辨欺詐客戶和正常客戶。強(qiáng)化學(xué)習(xí)主要是指導(dǎo)訓(xùn)練對(duì)象每一步如何決策,采用什么樣的行動(dòng)可以完成特定的目的或者使收益最大化。
比如AlphaGo下圍棋,AlphaGo就是強(qiáng)化學(xué)習(xí)的訓(xùn)練對(duì)象,AlphaGo走的每一步不存在對(duì)錯(cuò)之分,但是存在“好壞”之分。當(dāng)前這個(gè)棋面下,下的“好”,這是一步好棋。下的“壞”,這是一步臭棋。強(qiáng)化學(xué)習(xí)的訓(xùn)練基礎(chǔ)在于AlphaGo的每一步行動(dòng)環(huán)境都能給予明確的反饋,是“好”是“壞”?“好”“壞”具體是多少,可以量化。強(qiáng)化學(xué)習(xí)在AlphaGo這個(gè)場(chǎng)景中最終訓(xùn)練目的就是讓棋子占領(lǐng)棋面上更多的區(qū)域,贏得最后的勝利。
打一個(gè)不是很恰當(dāng)?shù)谋扔鳎悬c(diǎn)像馬戲團(tuán)訓(xùn)猴一樣。
馴獸師敲鑼,訓(xùn)練猴站立敬禮,猴是我們的訓(xùn)練對(duì)象。如果猴完成了站立敬禮的動(dòng)作,就會(huì)獲得一定的食物獎(jiǎng)勵(lì),如果沒有完成或者完成的不對(duì),就沒有食物獎(jiǎng)勵(lì)甚至是鞭子抽打。時(shí)間久了,每當(dāng)馴獸師敲鑼,猴子自然而然地就知道要站立敬禮,因?yàn)檫@個(gè)動(dòng)作是當(dāng)前環(huán)境下獲得收益最大的動(dòng)作,其他動(dòng)作就不會(huì)有食物,甚至還要被鞭子抽打。(https://bbs.hupu.com/36347293.html 這里有一篇耍猴的報(bào)道,有強(qiáng)化學(xué)習(xí)的味道)
強(qiáng)化學(xué)習(xí)的靈感來(lái)源于心理學(xué)里的行為主義理論:
-
一切學(xué)習(xí)都是通過(guò)條件作用,在刺激和反應(yīng)之間建立直接聯(lián)結(jié)的過(guò)程。 -
強(qiáng)化在刺激一反應(yīng)之間的建立過(guò)程中起著重要的作用。在刺激一反應(yīng)聯(lián)結(jié)中,個(gè)體學(xué)到的是習(xí)慣,而習(xí)慣是反復(fù)練習(xí)與強(qiáng)化的結(jié)果。 -
習(xí)慣一旦形成,只要原來(lái)的或類似的刺激情境出現(xiàn),習(xí)得的習(xí)慣性反應(yīng)就會(huì)自動(dòng)出現(xiàn)。
那基于上述理論,強(qiáng)化學(xué)習(xí)就是訓(xùn)練對(duì)象如何在環(huán)境給予的獎(jiǎng)勵(lì)或懲罰的刺激下,逐步形成對(duì)刺激的預(yù)期,產(chǎn)生能獲得最大利益的習(xí)慣性行為。
1.2 強(qiáng)化學(xué)習(xí)的主要特點(diǎn)
-
試錯(cuò)學(xué)習(xí): 強(qiáng)化學(xué)習(xí)需要訓(xùn)練對(duì)象不停地和環(huán)境進(jìn)行交互,通過(guò)試錯(cuò)的方式去總結(jié)出每一步的最佳行為決策,整個(gè)過(guò)程沒有任何的指導(dǎo),只有冰冷的反饋。所有的學(xué)習(xí)基于環(huán)境反饋,訓(xùn)練對(duì)象去調(diào)整自己的行為決策。 -
延遲反饋: 強(qiáng)化學(xué)習(xí)訓(xùn)練過(guò)程中,訓(xùn)練對(duì)象的“試錯(cuò)”行為獲得環(huán)境的反饋,有時(shí)候可能需要等到整個(gè)訓(xùn)練結(jié)束以后才會(huì)得到一個(gè)反饋,比如Game Over或者是Win。當(dāng)然這種情況,我們?cè)谟?xùn)練時(shí)候一般都是進(jìn)行拆解的,盡量將反饋分解到每一步。 -
時(shí)間是強(qiáng)化學(xué)習(xí)的一個(gè)重要因素:強(qiáng)化學(xué)習(xí)的一系列環(huán)境狀態(tài)的變化和環(huán)境反饋等都是和時(shí)間強(qiáng)掛鉤,整個(gè)強(qiáng)化學(xué)習(xí)的訓(xùn)練過(guò)程是一個(gè)隨著時(shí)間變化,而狀態(tài)&反饋也在不停變化的,所以時(shí)間是強(qiáng)化學(xué)習(xí)的一個(gè)重要因素。 -
當(dāng)前的行為影響后續(xù)接收到的數(shù)據(jù):為什么單獨(dú)把該特點(diǎn)提出來(lái),也是為了和監(jiān)督學(xué)習(xí)&半監(jiān)督學(xué)習(xí)進(jìn)行區(qū)分。在監(jiān)督學(xué)習(xí)&半監(jiān)督學(xué)習(xí)中,每條訓(xùn)練數(shù)據(jù)都是獨(dú)立的,相互之間沒有任何關(guān)聯(lián)。但是強(qiáng)化學(xué)習(xí)中并不是這樣,當(dāng)前狀態(tài)以及采取的行動(dòng),將會(huì)影響下一步接收到的狀態(tài)。數(shù)據(jù)與數(shù)據(jù)之間存在一定的關(guān)聯(lián)性。
2 詳解強(qiáng)化學(xué)習(xí)
下面我們對(duì)強(qiáng)化學(xué)習(xí)進(jìn)行詳細(xì)的介紹:
2.1 基本組成部分
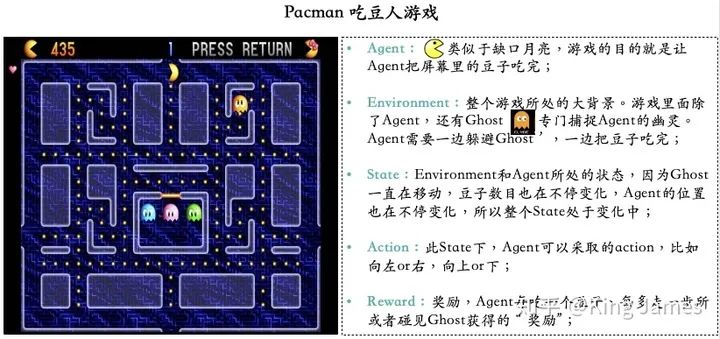
本文使用一個(gè)小游戲叫做Pacman(吃豆人)的游戲介紹強(qiáng)化學(xué)習(xí)(Reinforcement Learning)的基本組成部分。游戲目標(biāo)很簡(jiǎn)單,就是Agent要把屏幕里面所有的豆子全部吃完,同時(shí)又不能被幽靈碰到,被幽靈碰到則游戲結(jié)束,幽靈也是在不停移動(dòng)的。Agent每走一步、每吃一個(gè)豆子或者被幽靈碰到,屏幕左上方這分?jǐn)?shù)都會(huì)發(fā)生變化,圖例中當(dāng)前分?jǐn)?shù)是435分。這款小游戲,也是加州大學(xué)伯克利分校在上強(qiáng)化學(xué)習(xí)這門課程時(shí)使用的cousrwork。后續(xù)文章也會(huì)使用這個(gè)小游戲進(jìn)行強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)講解。
-
Agent(智能體): 強(qiáng)化學(xué)習(xí)訓(xùn)練的主體就是Agent,有時(shí)候翻譯為“代理”,這里統(tǒng)稱為“智能體”。Pacman中就是這個(gè)張開大嘴的黃色扇形移動(dòng)體。 -
Environment(環(huán)境): 整個(gè)游戲的大背景就是環(huán)境;Pacman中Agent、Ghost、豆子以及里面各個(gè)隔離板塊組成了整個(gè)環(huán)境。 -
State(狀態(tài)): 當(dāng)前 Environment和Agent所處的狀態(tài),因?yàn)镚host一直在移動(dòng),豆子數(shù)目也在不停變化,Agent的位置也在不停變化,所以整個(gè)State處于變化中;這里特別強(qiáng)調(diào)一點(diǎn),State包含了Agent和Environment的狀態(tài)。 -
Action(行動(dòng)): 基于當(dāng)前的State,Agent可以采取哪些action,比如向左or右,向上or下;Action是和State強(qiáng)掛鉤的,比如上圖中很多位置都是有隔板的,很明顯Agent在此State下是不能往左或者往右的,只能上下; -
Reward(獎(jiǎng)勵(lì)): Agent在當(dāng)前State下,采取了某個(gè)特定的action后,會(huì)獲得環(huán)境的一定反饋就是Reward。這里面用Reward進(jìn)行統(tǒng)稱,雖然Reward翻譯成中文是“獎(jiǎng)勵(lì)”的意思,但其實(shí)強(qiáng)化學(xué)習(xí)中Reward只是代表環(huán)境給予的“反饋”,可能是獎(jiǎng)勵(lì)也可能是懲罰。比如Pacman游戲中,Agent碰見了Ghost那環(huán)境給予的就是懲罰。
以上是強(qiáng)化學(xué)習(xí)的五個(gè)基本組成部分。
2.2 強(qiáng)化學(xué)習(xí)訓(xùn)練過(guò)程
下面我們需要介紹一下強(qiáng)化學(xué)習(xí)的訓(xùn)練過(guò)程。整個(gè)訓(xùn)練過(guò)程都基于一個(gè)前提,我們認(rèn)為整個(gè)過(guò)程都是符合馬爾可夫決策過(guò)程的。
-
馬爾可夫決策過(guò)程(Markov Decision Process)
Markov是一個(gè)俄國(guó)的數(shù)學(xué)家,為了紀(jì)念他在馬爾可夫鏈所做的研究,所以以他命名了“Markov Decision Process”,以下用MDP代替。
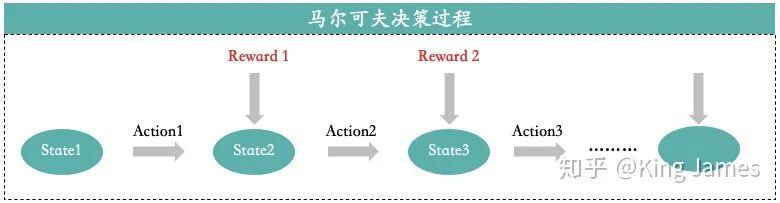
MDP核心思想就是下一步的State只和當(dāng)前的狀態(tài)State以及當(dāng)前狀態(tài)將要采取的Action有關(guān),只回溯一步。比如上圖State3只和State2以及Action2有關(guān),和State1以及Action1無(wú)關(guān)。我們已知當(dāng)前的State和將要采取的Action,就可以推出下一步的State是什么,而不需要繼續(xù)回溯上上步的State以及Action是什么,再結(jié)合當(dāng)前的(State,Action)才能得出下一步State。實(shí)際應(yīng)用中基本場(chǎng)景都是馬爾可夫決策過(guò)程,比如AlphaGo下圍棋,當(dāng)前棋面是什么,當(dāng)前棋子準(zhǔn)備落在哪里,我們就可以清晰地知道下一步的棋面是什么了。
為什么我們要先定義好整個(gè)訓(xùn)練過(guò)程符合MDP了,因?yàn)橹挥蟹螹DP,我們才方便根據(jù)當(dāng)前的State,以及要采取的Action,推理出下一步的State。方便在訓(xùn)練過(guò)程中清晰地推理出每一步的State變更,如果在訓(xùn)練過(guò)程中我們連每一步的State變化都推理不出,那么也無(wú)從訓(xùn)練。
接下來(lái)我們使用強(qiáng)化學(xué)習(xí)來(lái)指導(dǎo)Agent如何行動(dòng)了。
2.3 強(qiáng)化學(xué)習(xí)算法歸類
我們選擇什么樣的算法來(lái)指導(dǎo)Agent行動(dòng)?本身強(qiáng)化學(xué)習(xí)算法有很多種,關(guān)于強(qiáng)化學(xué)習(xí)算法如何分類,有很多種分類方式,這里我選擇三種比較常見的分類方式。
( 1 ) - Value Based -
強(qiáng)調(diào)一點(diǎn)這里面的Value值,在強(qiáng)化學(xué)習(xí)訓(xùn)練開始時(shí)都是不知道的,我們一般都是設(shè)置為0。然后讓Agent不斷去嘗試各類Action,不斷與環(huán)境交互,不斷獲得Reward,然后根據(jù)我們計(jì)算Value的公式,不停地去更新Value,最終在訓(xùn)練N多輪以后,Value值會(huì)趨于一個(gè)穩(wěn)定的數(shù)字,才能得出具體的State下,采取特定Action,對(duì)應(yīng)的Value是多少
( 2 ) - Policy Based -
Policy Based策略就是對(duì)Value Based的一個(gè)補(bǔ)充,
( 3 ) - Actor-Critic -
AC分類就是將Value-Based和Policy-Based結(jié)合在一起,里面的算法結(jié)合了2.3.1和2.3.2。
上述就是三大類常見的強(qiáng)化學(xué)習(xí)算法,而在Pacman這個(gè)游戲中,我們就可以使用Value-Based算法來(lái)訓(xùn)練。因?yàn)槊總€(gè)State下最終對(duì)應(yīng)的最優(yōu)Action是比較固定的,同時(shí)Reward函數(shù)也容易設(shè)定。
( 4 ) - 其他分類 -
上述三種分類是常見的分類方法,有時(shí)候我們還會(huì)通過(guò)其他角度進(jìn)行分類,以下分類方法和上述的分類存在一定的重疊:
根據(jù)是否學(xué)習(xí)出環(huán)境Model分類:Model-based指的是,agent已經(jīng)學(xué)習(xí)出整個(gè)環(huán)境是如何運(yùn)行的,當(dāng)agent已知任何狀態(tài)下執(zhí)行任何動(dòng)作獲得的回報(bào)和到達(dá)的下一個(gè)狀態(tài)都可以通過(guò)模型得出時(shí),此時(shí)總的問題就變成了一個(gè)動(dòng)態(tài)規(guī)劃的問題,直接利用貪心算法即可了。這種采取對(duì)環(huán)境進(jìn)行建模的強(qiáng)化學(xué)習(xí)方法就是Model-based方法。
而Model-free指的是,有時(shí)候并不需要對(duì)環(huán)境進(jìn)行建模也能找到最優(yōu)的策略。雖然我們無(wú)法知道確切的環(huán)境回報(bào),但我們可以對(duì)它進(jìn)行估計(jì)。Q-learning中的Q(s,a)就是對(duì)在狀態(tài)s下,執(zhí)行動(dòng)作a后獲得的未來(lái)收益總和進(jìn)行的估計(jì),經(jīng)過(guò)很多輪訓(xùn)練后,Q(s,a)的估計(jì)值會(huì)越來(lái)越準(zhǔn),這時(shí)候同樣利用貪心算法來(lái)決定agent在某個(gè)具體狀態(tài)下采取什么行動(dòng)。
如何判斷該強(qiáng)化學(xué)習(xí)算法是Model-based or Model-free, 我們是否在agent在狀態(tài)s下執(zhí)行它的動(dòng)作a之前,就已經(jīng)可以準(zhǔn)確對(duì)下一步的狀態(tài)和回報(bào)做出預(yù)測(cè),如果可以,那么就是Model-based,如果不能,即為Model-free。
2.4 EE(Explore & Exploit)
2.3里面介紹了各種強(qiáng)化學(xué)習(xí)算法:Value-Based、Policy-Based、Actor-Critic。但實(shí)際我們?cè)谶M(jìn)行強(qiáng)化學(xué)習(xí)訓(xùn)練過(guò)程中,會(huì)遇到一個(gè)“EE”問題。這里的Double E不是“Electronic Engineering”,而是“Explore & Exploit”,“探索&利用”。
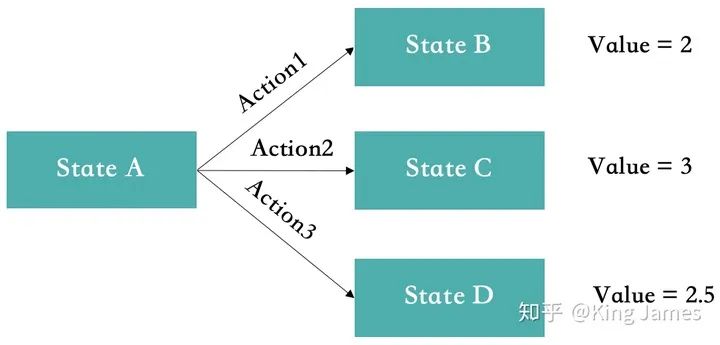
比如在Value-Based中,如下圖StateA的狀態(tài)下,最開始Action1&2&3對(duì)應(yīng)的Value都是0,因?yàn)橛?xùn)練前我們根本不知道,初始值均為0。如果第一次隨機(jī)選擇了Action1,這時(shí)候StateA轉(zhuǎn)化為了StateB,得到了Value=2,系統(tǒng)記錄在StateA下選擇Action1對(duì)應(yīng)的Value=2。如果下一次Agent又一次回到了StateA,此時(shí)如果我們選擇可以返回最大Value的action,那么一定還是選擇Action1。因?yàn)榇藭r(shí)StateA下Action2&3對(duì)應(yīng)的Value仍然為0。Agent根本沒有嘗試過(guò)Action2&3會(huì)帶來(lái)怎樣的Value。
所以在強(qiáng)化學(xué)習(xí)訓(xùn)練的時(shí)候,一開始會(huì)讓Agent更偏向于探索Explore,并不是哪一個(gè)Action帶來(lái)的Value最大就執(zhí)行該Action,選擇Action時(shí)具有一定的隨機(jī)性,目的是為了覆蓋更多的Action,嘗試每一種可能性。等訓(xùn)練很多輪以后各種State下的各種Action基本嘗試完以后,我們這時(shí)候會(huì)大幅降低探索的比例,盡量讓Agent更偏向于利用Exploit,哪一個(gè)Action返回的Value最大,就選擇哪一個(gè)Action。
Explore&Exploit是一個(gè)在機(jī)器學(xué)習(xí)領(lǐng)域經(jīng)常遇到的問題,并不僅僅只是強(qiáng)化學(xué)習(xí)中會(huì)遇到,在推薦系統(tǒng)中也會(huì)遇到,比如用戶對(duì)某個(gè)商品 or 內(nèi)容感興趣,系統(tǒng)是否應(yīng)該一直為用戶推送,是不是也要適當(dāng)搭配隨機(jī)一些其他商品 or 內(nèi)容。
2.5 強(qiáng)化學(xué)習(xí)實(shí)際開展中的難點(diǎn)
我們實(shí)際在應(yīng)用強(qiáng)化學(xué)習(xí)去訓(xùn)練時(shí),經(jīng)常會(huì)遇到各類問題。雖然強(qiáng)化學(xué)習(xí)很強(qiáng)大,但是有時(shí)候很多問題很棘手無(wú)從下手。
03 強(qiáng)化學(xué)習(xí)的實(shí)際應(yīng)用
雖然強(qiáng)化學(xué)習(xí)目前還有各種各樣的棘手問題,但目前工業(yè)界也開始嘗試應(yīng)用強(qiáng)化學(xué)習(xí)到實(shí)際場(chǎng)景中了,除了AlphaGo還有哪些應(yīng)用了:
3.1 自動(dòng)駕駛
目前國(guó)內(nèi)百度在自動(dòng)駕駛領(lǐng)域中就使用了一定的強(qiáng)化學(xué)習(xí)算法,但是因?yàn)閺?qiáng)化學(xué)習(xí)需要和環(huán)境交互試錯(cuò),現(xiàn)實(shí)世界中這個(gè)成本太高,所以真實(shí)訓(xùn)練時(shí)都需要加入安全員進(jìn)行干預(yù),及時(shí)糾正Agent采取的錯(cuò)誤行為。
3.2 游戲
游戲可以說(shuō)是目前強(qiáng)化學(xué)習(xí)應(yīng)用最廣闊的,目前市場(chǎng)上的一些MOBA游戲基本都有了強(qiáng)化學(xué)習(xí)版的AI在里面,最出名的就是王者榮耀AI。游戲環(huán)境下可以隨便交互,隨便試錯(cuò),沒有任何真實(shí)成本。同時(shí)Reward也相對(duì)比較容易設(shè)置,存在明顯的獎(jiǎng)勵(lì)機(jī)制。
3.3 推薦系統(tǒng)
目前一些互聯(lián)網(wǎng)大廠也在推薦系統(tǒng)中嘗試加入強(qiáng)化學(xué)習(xí)來(lái)進(jìn)行推薦,比如百度&美團(tuán)。使用強(qiáng)化學(xué)習(xí)去提高推薦結(jié)果的多樣性,和傳統(tǒng)的協(xié)同過(guò)濾&CTR預(yù)估模型等進(jìn)行互補(bǔ)。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~