
通俗講解集成學(xué)習(xí)算法!
作者:黃星源,Datawhale優(yōu)秀學(xué)習(xí)者
本文以圖文的形式對(duì)模型算法中的集成學(xué)習(xí),以及對(duì)集中學(xué)習(xí)在深度學(xué)習(xí)中的應(yīng)用進(jìn)行了詳細(xì)解讀。
數(shù)據(jù)及背景??
集成學(xué)習(xí)
選定樣本(包含正樣本和負(fù)樣本),將所有樣本分成訓(xùn)練樣本和測(cè)試樣本兩部分。 在訓(xùn)練樣本上執(zhí)行分類器算法,生成分類模型。 在測(cè)試樣本上執(zhí)行分類模型,生成預(yù)測(cè)結(jié)果。 根據(jù)預(yù)測(cè)結(jié)果,計(jì)算必要的評(píng)估指標(biāo),評(píng)估分類模型的性能。
構(gòu)造這個(gè)分類器不需要任何領(lǐng)域的知識(shí),也不需要任何的參數(shù)設(shè)置。因此它特別適合于探測(cè)式的知識(shí)發(fā)現(xiàn)。此外,這個(gè)分類器還可以處理高維數(shù)據(jù),而且采用的是類似于樹這種形式,也特別直觀和便于理解。因此,決策樹是許多商業(yè)規(guī)則歸納系統(tǒng)的基礎(chǔ)。
2. 樸素貝葉斯分類器
素貝葉斯分類器是假設(shè)數(shù)據(jù)樣本特征完全獨(dú)立,以貝葉斯定理為基礎(chǔ)的簡單概率分類器。
3. AdaBoost算法
AdaBoost算法的自適應(yīng)在于前一個(gè)分類器產(chǎn)生的錯(cuò)誤分類樣本會(huì)被用來訓(xùn)練下一個(gè)分類器,從而提升分類準(zhǔn)確率,但是對(duì)于噪聲樣本和異常樣本比較敏感。
4. 支持向量機(jī)
支持向量機(jī)是用過構(gòu)建一個(gè)或者多個(gè)高維的超平面來將樣本數(shù)據(jù)進(jìn)行劃分,超平面即為樣本之間的分類邊界。
5. K近鄰算法
基于k近鄰的K個(gè)樣本作為分析從而簡化計(jì)算提升效率,K近鄰算法分類器是基于距離計(jì)算的分類器。
集成學(xué)習(xí)有許多集成模型,例如自助法、自助聚合(Bagging)、隨機(jī)森林、提升法(Boosting)、 堆疊法(stacking) 以及許多其它的基礎(chǔ)集成學(xué)習(xí)模型。
我們可以用三種主要的旨在組合弱學(xué)習(xí)器的元算法:
自助聚合(Bagging),該方法通常考慮的是同質(zhì)弱學(xué)習(xí)器,相互獨(dú)立地并行學(xué)習(xí)這些弱學(xué)習(xí)器,并按照某種確定性的平均過程將它們組合起來。 提升法(Boosting),該方法通常考慮的也是同質(zhì)弱學(xué)習(xí)器。它以一種高度自適應(yīng)的方法順序地學(xué)習(xí)這些弱學(xué)習(xí)器(每個(gè)基礎(chǔ)模型都依賴于前面的模型),并按照某種確定性的策略將它們組合起來。 堆疊法(Stacking),該方法通常考慮的是異質(zhì)弱學(xué)習(xí)器,并行地學(xué)習(xí)它們,并通過訓(xùn)練一個(gè) 元模型 將它們組合起來,根據(jù)不同弱模型的預(yù)測(cè)結(jié)果輸出一個(gè)最終的預(yù)測(cè)結(jié)果。
非常粗略地說,我們可以說Bagging的重點(diǎn)在于獲得一個(gè)方差比其組成部分更小的集成模型,而Boosting和Stacking則將主要生成偏置比其組成部分更低的強(qiáng)模型(即使方差也可以被減小)。
1. 自助聚合(Bagging)
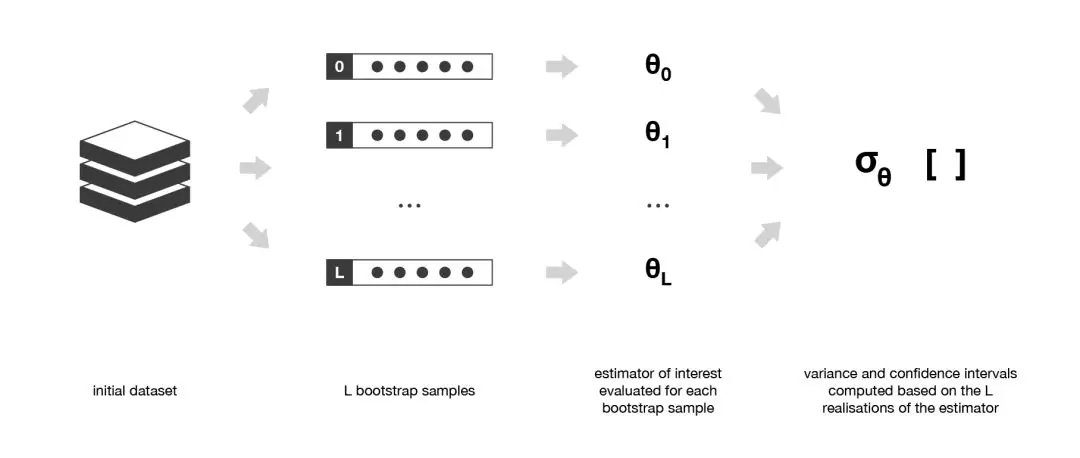
在并行化的方法 中,我們單獨(dú)擬合不同的學(xué)習(xí)器,因此可以同時(shí)訓(xùn)練它們。最著名的方法是自助聚合(Bagging),它的目標(biāo)是生成比單個(gè)模型更棒的集成模型。Bagging的方法實(shí)現(xiàn)。
自助法:這種統(tǒng)計(jì)技術(shù)先隨機(jī)抽取出作為替代的 B 個(gè)觀測(cè)值,然后根據(jù)一個(gè)規(guī)模為 N 的初始數(shù)據(jù)集生成大小為 B 的樣本(稱為自助樣本)。
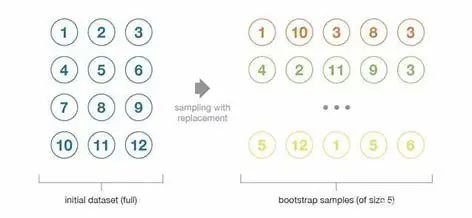
初始數(shù)據(jù)集的大小N應(yīng)該足夠大,以捕獲底層分布的大部分復(fù)雜性。這樣,從數(shù)據(jù)集中抽樣就是從真實(shí)分布中抽樣的良好近似(代表性)。 與自助樣本的大小B相比,數(shù)據(jù)集的規(guī)模N應(yīng)該足夠大,這樣樣本之間就不會(huì)有太大的相關(guān)性(獨(dú)立性)。注意,接下來我可能還會(huì)提到自助樣本的這些特性(代表性和獨(dú)立性),但讀者應(yīng)該始終牢記:這只是一種近似。
在大多數(shù)情況下,相較于實(shí)際可用的數(shù)據(jù)量來說,考慮真正獨(dú)立的樣本所需要的數(shù)據(jù)量可能太大了。然而,我們可以使用自助法生成一些自助樣本,它們可被視為最具代表性以及最具獨(dú)立性(幾乎是獨(dú)立同分布的樣本)的樣本。這些自助樣本使我們可以通過估計(jì)每個(gè)樣本的值,近似得到估計(jì)量的方差。
2. 提升法(Boosting)
簡而言之,這兩種元算法在順序化的過程中創(chuàng)建和聚合弱學(xué)習(xí)器的方式存在差異。自適應(yīng)提升算法會(huì)更新附加給每個(gè)訓(xùn)練數(shù)據(jù)集中觀測(cè)數(shù)據(jù)的權(quán)重,而梯度提升算法則會(huì)更新這些觀測(cè)數(shù)據(jù)的值。這里產(chǎn)生差異的主要原因是:兩種算法解決優(yōu)化問題(尋找最佳模型——弱學(xué)習(xí)器的加權(quán)和)的方式不同。
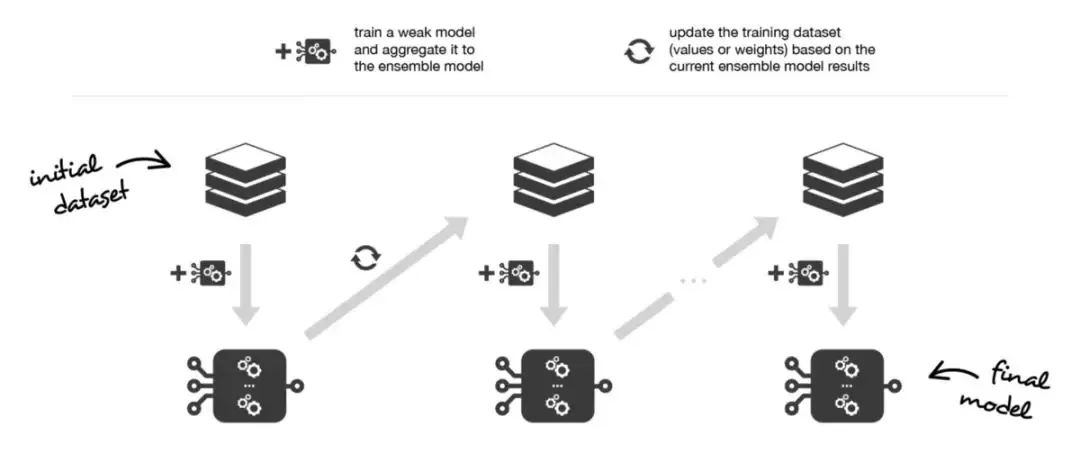
在自適應(yīng)adaboost中,我們將集成模型定義為L個(gè)弱學(xué)習(xí)器的加權(quán)和:
另外,我們將弱學(xué)習(xí)器逐個(gè)添加到當(dāng)前的集成模型中,在每次迭代中尋找可能的最佳組合(系數(shù)、弱學(xué)習(xí)器)。換句話說,我們循環(huán)地將 定義如下:
因此,假設(shè)我們面對(duì)的是一個(gè)二分類問題:數(shù)據(jù)集中有N個(gè)觀測(cè)數(shù)據(jù),我們想在給定一組弱模型的情況下使用adaboost算法。在算法的起始階段(序列中的第一個(gè)模型),所有的觀測(cè)數(shù)據(jù)都擁有相同的權(quán)重1/N。然后,我們將下面的步驟重復(fù)L次(作用于序列中的L個(gè)學(xué)習(xí)器):
用當(dāng)前觀測(cè)數(shù)據(jù)的權(quán)重?cái)M合可能的最佳弱模型 計(jì)算更新系數(shù)的值,更新系數(shù)是弱學(xué)習(xí)器的某種標(biāo)量化評(píng)估指標(biāo),它表示相對(duì)集成模型來說,該弱學(xué)習(xí)器的分量如何 通過添加新的弱學(xué)習(xí)器與其更新系數(shù)的乘積來更新強(qiáng)學(xué)習(xí)器計(jì)算新觀測(cè)數(shù)據(jù)的權(quán)重,該權(quán)重表示我們想在下一輪迭代中關(guān)注哪些觀測(cè)數(shù)據(jù)(聚和模型預(yù)測(cè)錯(cuò)誤的觀測(cè)數(shù)據(jù)的權(quán)重增加,而正確預(yù)測(cè)的觀測(cè)數(shù)據(jù)的權(quán)重減小)
重復(fù)這些步驟,我們順序地構(gòu)建出L個(gè)模型,并將它們聚合成一個(gè)簡單的線性組合,然后由表示每個(gè)學(xué)習(xí)器性能的系數(shù)加權(quán)。注意,初始adaboost算法有一些變體,比如LogitBoost(分類)或L2Boost(回歸),它們的差異主要取決于損失函數(shù)的選擇。
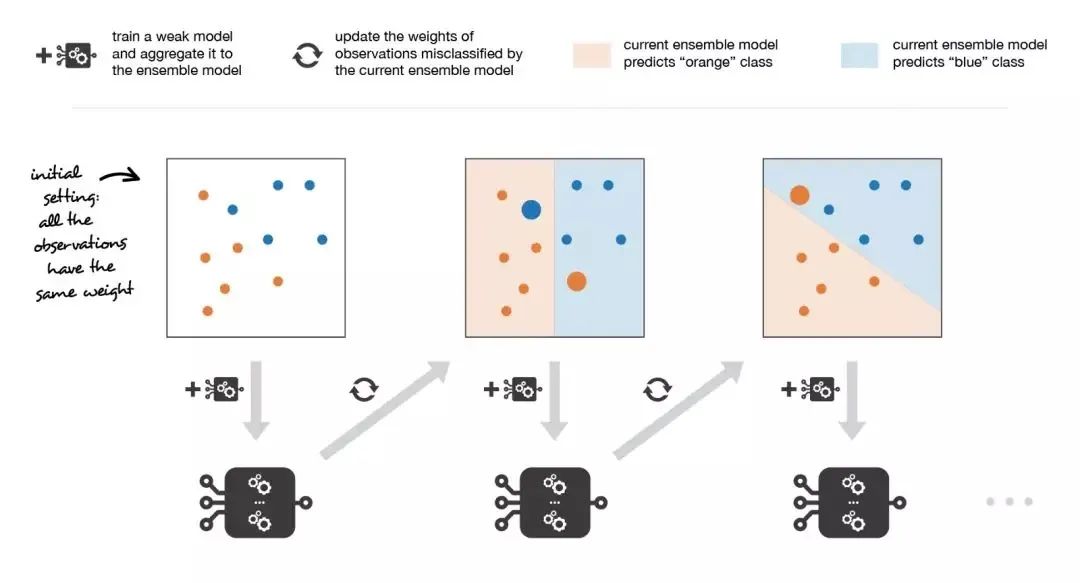
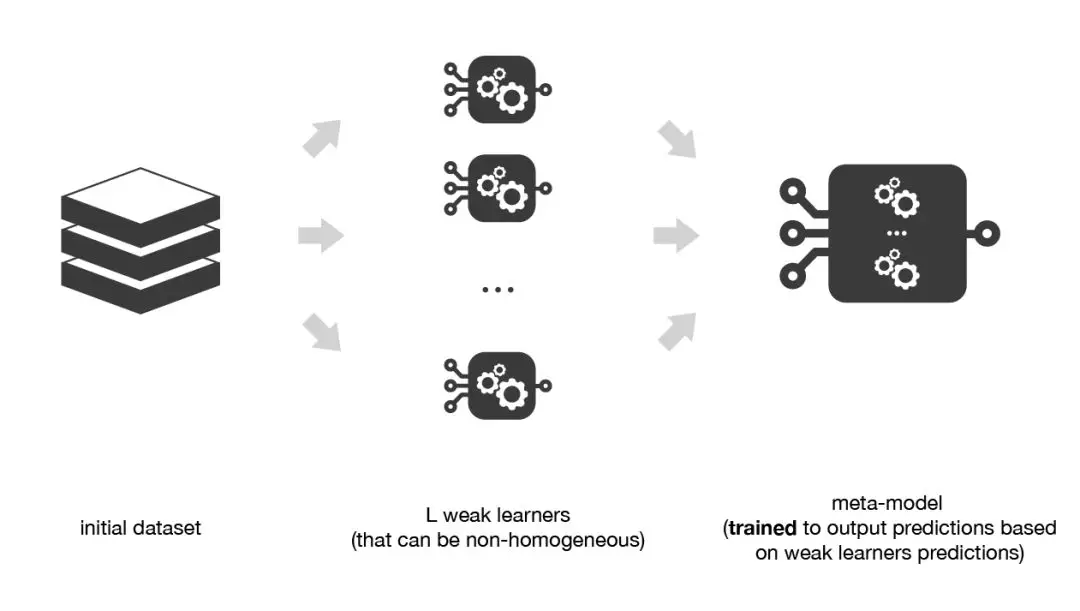
3. 堆疊法(Stacking)
將訓(xùn)練數(shù)據(jù)分為兩組 選擇 L 個(gè)弱學(xué)習(xí)器,用它們擬合第一組數(shù)據(jù) 使 L 個(gè)學(xué)習(xí)器中的每個(gè)學(xué)習(xí)器對(duì)第二組數(shù)據(jù)中的觀測(cè)數(shù)據(jù)進(jìn)行預(yù)測(cè) 在第二組數(shù)據(jù)上擬合元模型,使用弱學(xué)習(xí)器做出的預(yù)測(cè)作為輸入
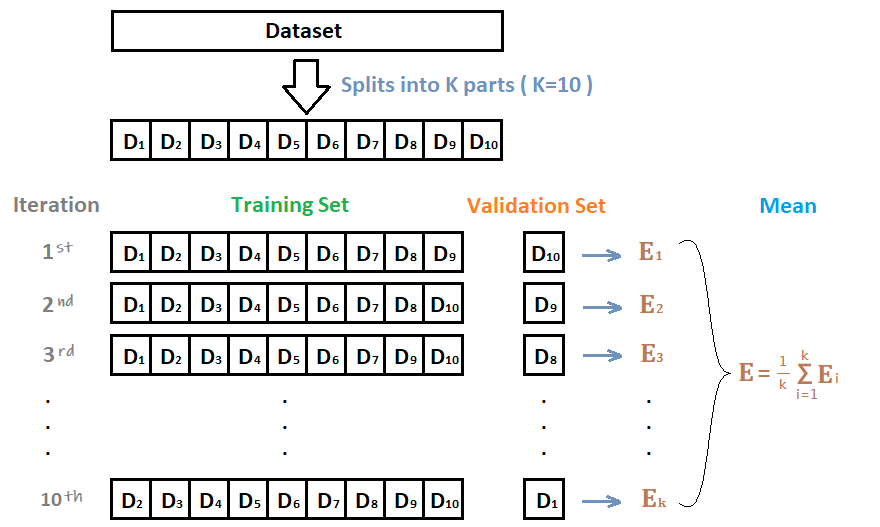
為了克服這種限制,我們可以使用某種k-折交叉訓(xùn)練方法(類似于 k-折交叉驗(yàn)證中的做法)。這樣所有的觀測(cè)數(shù)據(jù)都可以用來訓(xùn)練元模型:對(duì)于任意的觀測(cè)數(shù)據(jù),弱學(xué)習(xí)器的預(yù)測(cè)都是通過在k-1折數(shù)據(jù)(不包含已考慮的觀測(cè)數(shù)據(jù))上訓(xùn)練這些弱學(xué)習(xí)器的實(shí)例來完成的。換句話說,它會(huì)在k-1折數(shù)據(jù)上進(jìn)行訓(xùn)練,從而對(duì)剩下的一折數(shù)據(jù)進(jìn)行預(yù)測(cè)。迭代地重復(fù)這個(gè)過程,就可以得到對(duì)任何一折觀測(cè)數(shù)據(jù)的預(yù)測(cè)結(jié)果。這樣一來,我們就可以為數(shù)據(jù)集中的每個(gè)觀測(cè)數(shù)據(jù)生成相關(guān)的預(yù)測(cè),然后使用所有這些預(yù)測(cè)結(jié)果訓(xùn)練元模型。
十折交叉驗(yàn)證
那么在十個(gè)CNN模型可以使用如下方式進(jìn)行集成:
對(duì)預(yù)測(cè)的結(jié)果的概率值進(jìn)行平均,然后解碼為具體字符 對(duì)預(yù)測(cè)的字符進(jìn)行投票,得到最終字符
深度學(xué)習(xí)中的集成學(xué)習(xí)
丟棄法Dropout 測(cè)試集數(shù)據(jù)擴(kuò)增TTA Snapshot
1. 丟棄法Dropout
Dropout可以作為訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)的一種技巧。在每個(gè)訓(xùn)練批次中,通過隨機(jī)讓一部分的節(jié)點(diǎn)停止工作。同時(shí)在預(yù)測(cè)的過程中讓所有的節(jié)點(diǎn)都其作用。
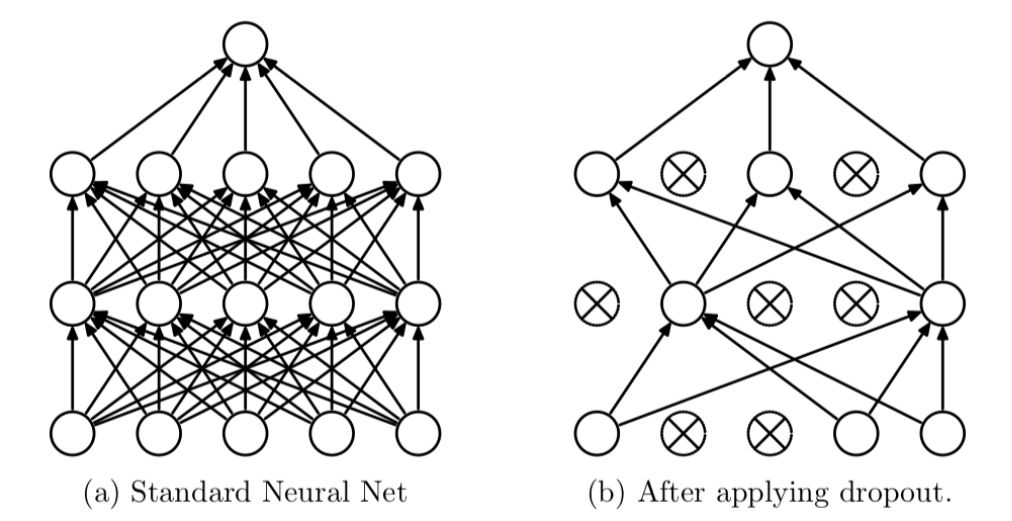
Dropout經(jīng)常出現(xiàn)在在先有的CNN網(wǎng)絡(luò)中,可以有效的緩解模型過擬合的情況,也可以在預(yù)測(cè)時(shí)增加模型的精度。加入Dropout后的網(wǎng)絡(luò)結(jié)構(gòu)如下:?
# 定義模型class SVHN_Model1(nn.Module):def __init__(self):super(SVHN_Model1, self).__init__()# CNN提取特征模塊self.cnn = nn.Sequential(nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),nn.ReLU(),nn.Dropout(0.25),nn.MaxPool2d(2),nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),nn.ReLU(),nn.Dropout(0.25),nn.MaxPool2d(2),)#self.fc1 = nn.Linear(32*3*7, 11)self.fc2 = nn.Linear(32*3*7, 11)self.fc3 = nn.Linear(32*3*7, 11)self.fc4 = nn.Linear(32*3*7, 11)self.fc5 = nn.Linear(32*3*7, 11)self.fc6 = nn.Linear(32*3*7, 11)def forward(self, img):feat = self.cnn(img)feat = feat.view(feat.shape[0], -1)c1 = self.fc1(feat)c2 = self.fc2(feat)c3 = self.fc3(feat)c4 = self.fc4(feat)c5 = self.fc5(feat)c6 = self.fc6(feat)????????return?c1,?c2,?c3,?c4,?c5,?c6
2. 測(cè)試集數(shù)據(jù)擴(kuò)增TTA

def predict(test_loader, model, tta=10):model.eval()test_pred_tta = None# TTA 次數(shù)for _ in range(tta):test_pred = []with torch.no_grad():for i, (input, target) in enumerate(test_loader):c0, c1, c2, c3, c4, c5 = model(data[0])output = np.concatenate([c0.data.numpy(), c1.data.numpy(),c2.data.numpy(), c3.data.numpy(),c4.data.numpy(), c5.data.numpy()], axis=1)test_pred.append(output)test_pred = np.vstack(test_pred)if test_pred_tta is None:test_pred_tta = test_predelse:test_pred_tta += test_predreturn test_pred_tta
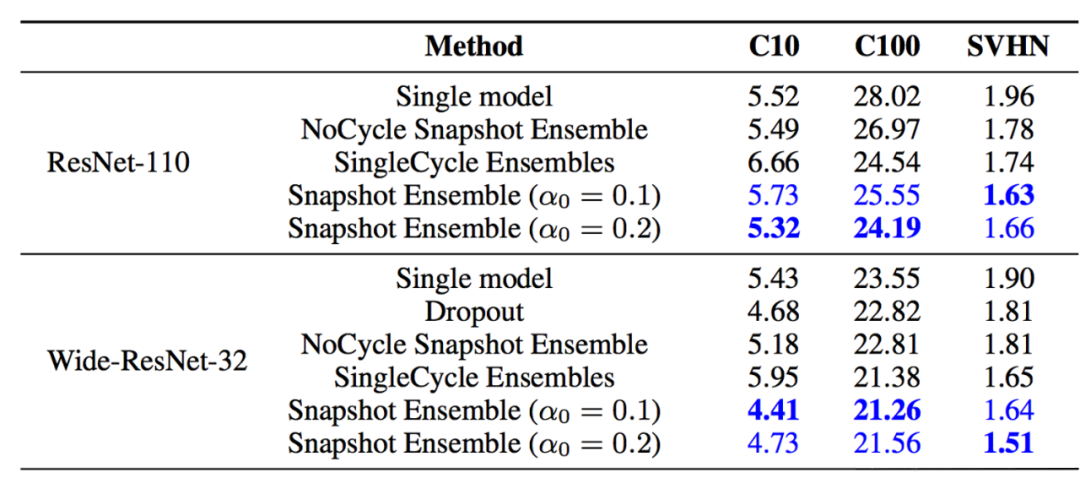
Snapshot
在論文Snapshot Ensembles中,作者提出使用cyclical learning rate進(jìn)行訓(xùn)練模型,并保存精度比較好的一些checkopint,最后將多個(gè)checkpoint進(jìn)行模型集成。
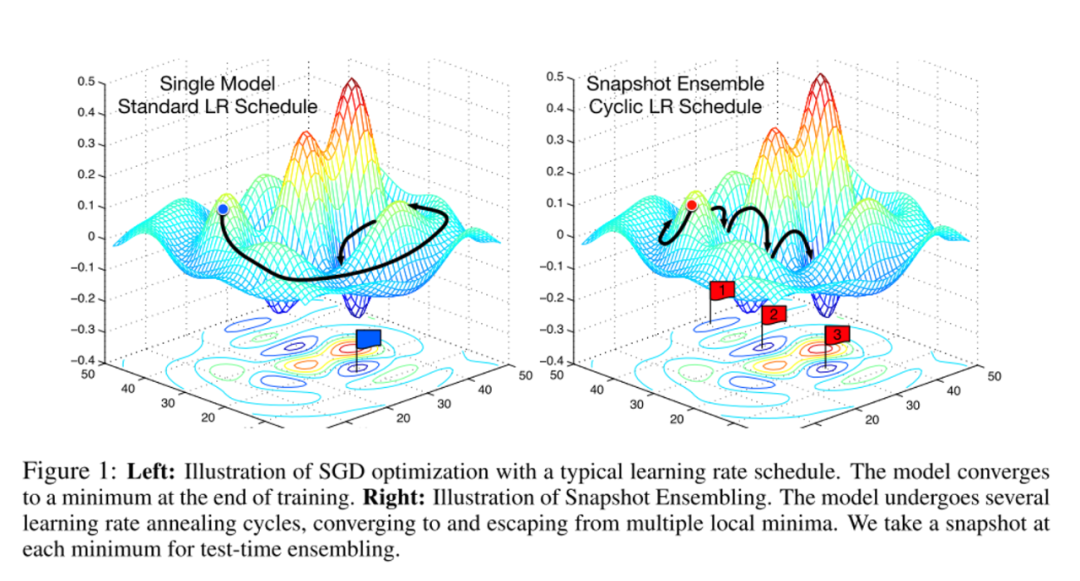
由于在cyclical learning rate中學(xué)習(xí)率的變化有周期性變大和減少的行為,因此CNN模型很有可能在跳出局部最優(yōu)進(jìn)入另一個(gè)局部最優(yōu)。在Snapshot論文中作者通過使用表明,此種方法可以在一定程度上提高模型精度,但需要更長的訓(xùn)練時(shí)間。
寫到最后
統(tǒng)計(jì)圖片中每個(gè)位置字符出現(xiàn)的頻率,使用規(guī)則修正結(jié)果; 單獨(dú)訓(xùn)練一個(gè)字符長度預(yù)測(cè)模型,用來預(yù)測(cè)圖片中字符個(gè)數(shù),并修正結(jié)果。
