
真實(shí)的產(chǎn)品案例:實(shí)現(xiàn)文檔邊緣檢測(cè)

向AI轉(zhuǎn)型的程序員都關(guān)注了這個(gè)號(hào)??????
機(jī)器學(xué)習(xí)AI算法工程?? 公眾號(hào):datayx
什么是邊緣檢測(cè)?
邊緣檢測(cè)是計(jì)算機(jī)視覺(jué)中一個(gè)非常古老的問(wèn)題,它涉及到檢測(cè)圖像中的邊緣來(lái)確定目標(biāo)的邊界,從而分離感興趣的目標(biāo)。最流行的邊緣檢測(cè)技術(shù)之一是Canny邊緣檢測(cè),它已經(jīng)成為大多數(shù)計(jì)算機(jī)視覺(jué)研究人員和實(shí)踐者的首選方法。讓我們快速看一下Canny邊緣檢測(cè)。
Canny邊緣檢測(cè)算法
1983年,John Canny在麻省理工學(xué)院發(fā)明了Canny邊緣檢測(cè)。它將邊緣檢測(cè)視為一個(gè)信號(hào)處理問(wèn)題。其核心思想是,如果你觀察圖像中每個(gè)像素的強(qiáng)度變化,它在邊緣的時(shí)候非常高。
在下面這張簡(jiǎn)單的圖片中,強(qiáng)度變化只發(fā)生在邊界上。所以,你可以很容易地通過(guò)觀察像素強(qiáng)度的變化來(lái)識(shí)別邊緣。

現(xiàn)在,看下這張圖片。強(qiáng)度不是恒定的,但強(qiáng)度的變化率在邊緣處最高。(微積分復(fù)習(xí):變化率可以用一階導(dǎo)數(shù)(梯度)來(lái)計(jì)算。)

Canny邊緣檢測(cè)器通過(guò)4步來(lái)識(shí)別邊緣:
去噪:因?yàn)檫@種方法依賴于強(qiáng)度的突然變化,如果圖像有很多隨機(jī)噪聲,那么會(huì)將噪聲作為邊緣。所以,使用5×5的高斯濾波器平滑你的圖像是一個(gè)非常好的主意。 梯度計(jì)算:下一步,我們計(jì)算圖像中每個(gè)像素的強(qiáng)度的梯度(強(qiáng)度變化率)。我們也計(jì)算梯度的方向。

非極大值抑制:現(xiàn)在,我們想刪除不是邊緣的像素(設(shè)置它們的值為0)。你可能會(huì)說(shuō),我們可以簡(jiǎn)單地選取梯度值最高的像素,這些就是我們的邊。然而,在真實(shí)的圖像中,梯度不是簡(jiǎn)單地在只一個(gè)像素處達(dá)到峰值,而是在臨近邊緣的像素處都非常高。因此我們?cè)谔荻确较蛏先?×3附近的局部最大值。

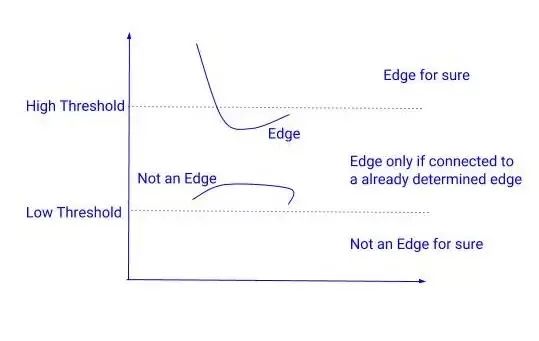
遲滯閾值化:在下一步中,我們需要決定一個(gè)梯度的閾值,低于這個(gè)閾值所有的像素都將被抑制(設(shè)置為0)。而Canny邊緣檢測(cè)器則采用遲滯閾值法。遲滯閾值法是一種非常簡(jiǎn)單而有效的方法。我們使用兩個(gè)閾值來(lái)代替只用一個(gè)閾值:
高閾值 = 選擇一個(gè)非常高的值,這樣任何梯度值高于這個(gè)值的像素都肯定是一個(gè)邊緣。
低閾值 = 選擇一個(gè)非常低的值,任何梯度值低于該值的像素絕對(duì)不是邊緣。
在這兩個(gè)閾值之間有梯度的像素會(huì)被檢查,如果它們和邊緣相連,就會(huì)留下,否則就會(huì)去掉。
Canny 邊緣檢測(cè)的問(wèn)題:
由于Canny邊緣檢測(cè)器只關(guān)注局部變化,沒(méi)有語(yǔ)義(理解圖像的內(nèi)容)理解,精度有限(很多時(shí)候是這樣)。
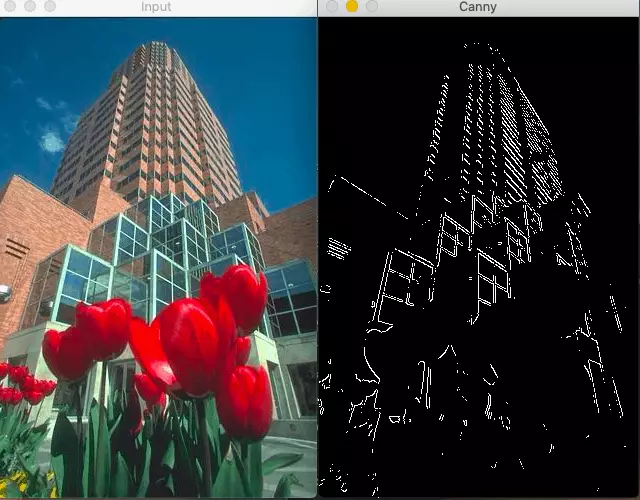
語(yǔ)義理解對(duì)于邊緣檢測(cè)是至關(guān)重要的,這就是為什么使用機(jī)器學(xué)習(xí)或深度學(xué)習(xí)的基于學(xué)習(xí)的檢測(cè)器比canny邊緣檢測(cè)器產(chǎn)生更好的結(jié)果。
OpenCV中基于深度學(xué)習(xí)的邊緣檢測(cè)
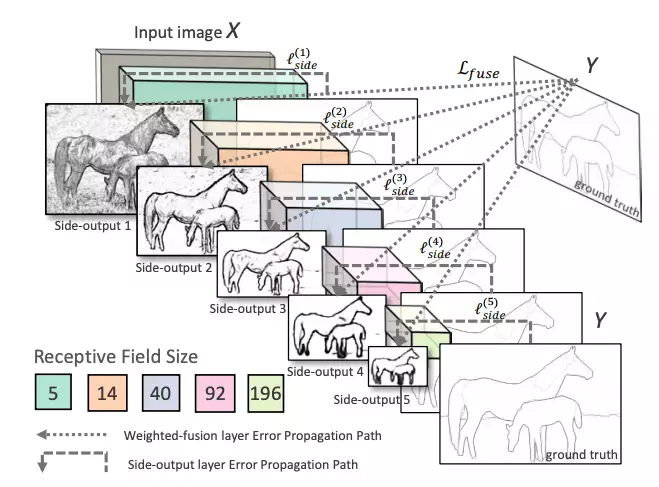
OpenCV在其全新的DNN模塊中集成了基于深度學(xué)習(xí)的邊緣檢測(cè)技術(shù)。你需要OpenCV 3.4.3或更高版本。這種技術(shù)被稱為整體嵌套邊緣檢測(cè)或HED,是一種基于學(xué)習(xí)的端到端邊緣檢測(cè)系統(tǒng),使用修剪過(guò)的類似vgg的卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行圖像到圖像的預(yù)測(cè)任務(wù)。
HED利用了中間層的輸出。之前的層的輸出稱為side output,將所有5個(gè)卷積層的輸出進(jìn)行融合,生成最終的預(yù)測(cè)。由于在每一層生成的特征圖大小不同,它可以有效地以不同的尺度查看圖像。
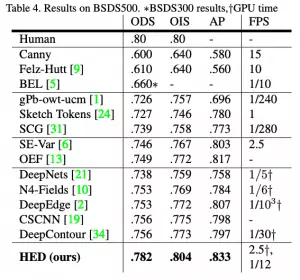
HED方法不僅比其他基于深度學(xué)習(xí)的方法更準(zhǔn)確,而且速度也比其他方法快得多。這就是為什么OpenCV決定將其集成到新的DNN模塊中。以下是這篇論文的結(jié)果:
在OpenCV中訓(xùn)練深度學(xué)習(xí)邊緣檢測(cè)的代碼
OpenCV使用的預(yù)訓(xùn)練模型已經(jīng)在Caffe框架中訓(xùn)練過(guò)了,可以這樣加載:
sh?download_pretrained.sh
網(wǎng)絡(luò)中有一個(gè)crop層,默認(rèn)是沒(méi)有實(shí)現(xiàn)的,所以我們需要自己實(shí)現(xiàn)一下。
class?CropLayer(object):
????def?__init__(self,?params,?blobs):
????????self.xstart?=?0
????????self.xend?=?0
????????self.ystart?=?0
????????self.yend?=?0
????#?Our?layer?receives?two?inputs.?We?need?to?crop?the?first?input?blob
????#?to?match?a?shape?of?the?second?one?(keeping?batch?size?and?number?of?channels)
????def?getMemoryShapes(self,?inputs):
????????inputShape,?targetShape?=?inputs[0],?inputs[1]
????????batchSize,?numChannels?=?inputShape[0],?inputShape[1]
????????height,?width?=?targetShape[2],?targetShape[3]
????????self.ystart?=?(inputShape[2]?-?targetShape[2])?//?2
????????self.xstart?=?(inputShape[3]?-?targetShape[3])?//?2
????????self.yend?=?self.ystart?+?height
????????self.xend?=?self.xstart?+?width
????????return?[[batchSize,?numChannels,?height,?width]]
????def?forward(self,?inputs):
????????return?[inputs[0][:,:,self.ystart:self.yend,self.xstart:self.xend]]
現(xiàn)在,我們可以重載這個(gè)類,只需用一行代碼注冊(cè)該層。
cv.dnn_registerLayer('Crop',?CropLayer)
現(xiàn)在,我們準(zhǔn)備構(gòu)建網(wǎng)絡(luò)圖并加載權(quán)重,這可以通過(guò)OpenCV的dnn.readNe函數(shù)。
net?=?cv.dnn.readNet(args.prototxt,?args.caffemodel)
現(xiàn)在,下一步是批量加載圖像,并通過(guò)網(wǎng)絡(luò)運(yùn)行它們。為此,我們使用cv2.dnn.blobFromImage方法。該方法從輸入圖像中創(chuàng)建四維blob。
blob?=?cv.dnn.blobFromImage(image,?scalefactor,?size,?mean,?swapRB,?crop)
其中:
image:是我們想要發(fā)送給神經(jīng)網(wǎng)絡(luò)進(jìn)行推理的輸入圖像。
scalefactor:圖像縮放常數(shù),很多時(shí)候我們需要把uint8的圖像除以255,這樣所有的像素都在0到1之間。默認(rèn)值是1.0,不縮放。
size:輸出圖像的空間大小。它將等于后續(xù)神經(jīng)網(wǎng)絡(luò)作為blobFromImage輸出所需的輸入大小。
swapRB:布爾值,表示我們是否想在3通道圖像中交換第一個(gè)和最后一個(gè)通道。OpenCV默認(rèn)圖像為BGR格式,但如果我們想將此順序轉(zhuǎn)換為RGB,我們可以將此標(biāo)志設(shè)置為True,這也是默認(rèn)值。
mean:為了進(jìn)行歸一化,有時(shí)我們計(jì)算訓(xùn)練數(shù)據(jù)集上的平均像素值,并在訓(xùn)練過(guò)程中從每幅圖像中減去它。如果我們?cè)谟?xùn)練中做均值減法,那么我們必須在推理中應(yīng)用它。這個(gè)平均值是一個(gè)對(duì)應(yīng)于R, G, B通道的元組。例如Imagenet數(shù)據(jù)集的均值是R=103.93, G=116.77, B=123.68。如果我們使用swapRB=False,那么這個(gè)順序?qū)⑹?B, G, R)。
crop:布爾標(biāo)志,表示我們是否想居中裁剪圖像。如果設(shè)置為True,則從中心裁剪輸入圖像時(shí),較小的尺寸等于相應(yīng)的尺寸,而其他尺寸等于或大于該尺寸。然而,如果我們將其設(shè)置為False,它將保留長(zhǎng)寬比,只是將其調(diào)整為固定尺寸大小。
在我們這個(gè)場(chǎng)景下:
inp?=?cv.dnn.blobFromImage(frame,?scalefactor=1.0,?size=(args.width,?args.height),?????????????????
???????????????????????????mean=(104.00698793,?116.66876762,?122.67891434),?swapRB=False,?????????????????
???????????????????????????crop=False)
現(xiàn)在,我們只需要調(diào)用一下前向方法。
net.setInput(inp)
out?=?net.forward()
out?=?out[0,?0]
out?=?cv.resize(out,?(frame.shape[1],?frame.shape[0]))
out?=?255?*?out
out?=?out.astype(np.uint8)
out=cv.cvtColor(out,cv.COLOR_GRAY2BGR)
con=np.concatenate((frame,out),axis=1)
cv.imshow(kWinName,con)
結(jié)果:
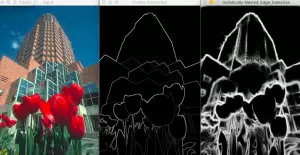

文中的代碼:https://github.com/sankit1/cv-tricks.com/tree/master/OpenCV/Edge_detection
本文不是神經(jīng)網(wǎng)絡(luò)或機(jī)器學(xué)習(xí)的入門教學(xué),而是通過(guò)一個(gè)真實(shí)的產(chǎn)品案例,展示了在手機(jī)客戶端上運(yùn)行一個(gè)神經(jīng)網(wǎng)絡(luò)的關(guān)鍵技術(shù)點(diǎn)
在卷積神經(jīng)網(wǎng)絡(luò)適用的領(lǐng)域里,已經(jīng)出現(xiàn)了一些很經(jīng)典的圖像分類網(wǎng)絡(luò),比如 VGG16/VGG19,Inception v1-v4 Net,ResNet 等,這些分類網(wǎng)絡(luò)通常又都可以作為其他算法中的基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu),尤其是 VGG 網(wǎng)絡(luò),被很多其他的算法借鑒,本文也會(huì)使用 VGG16 的基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu),但是不會(huì)對(duì) VGG 網(wǎng)絡(luò)做詳細(xì)的入門教學(xué)
雖然本文不是神經(jīng)網(wǎng)絡(luò)技術(shù)的入門教程,但是仍然會(huì)給出一系列的相關(guān)入門教程和技術(shù)文檔的鏈接,有助于進(jìn)一步理解本文的內(nèi)容
具體使用到的神經(jīng)網(wǎng)絡(luò)算法,只是本文的一個(gè)組成部分,除此之外,本文還介紹了如何裁剪 TensorFlow 靜態(tài)庫(kù)以便于在手機(jī)端運(yùn)行,如何準(zhǔn)備訓(xùn)練樣本圖片,以及訓(xùn)練神經(jīng)網(wǎng)絡(luò)時(shí)的各種技巧等等
?需求是什么
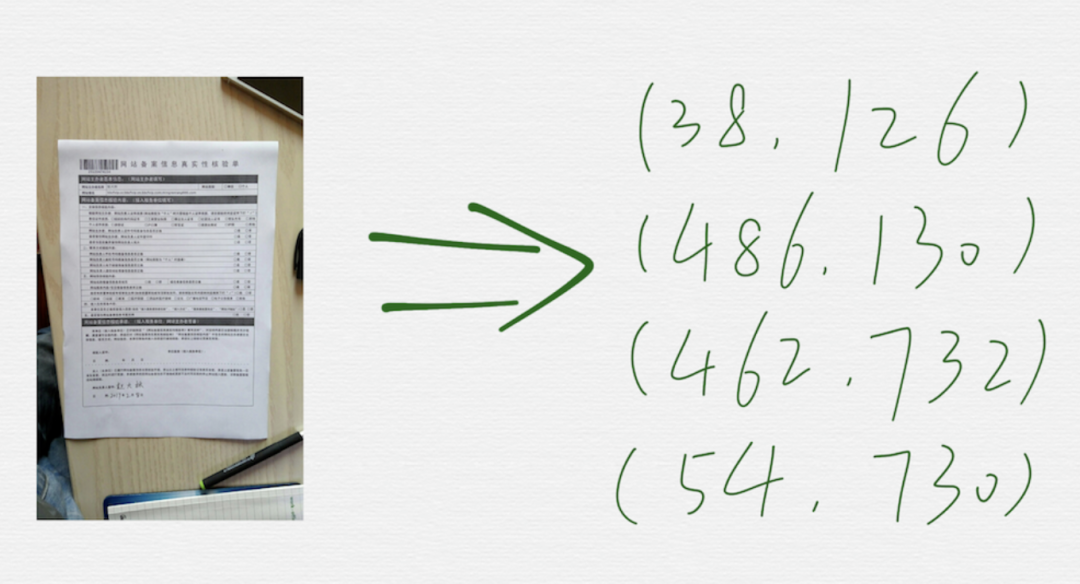
需求很容易描述清楚,如上圖,就是在一張圖里,把矩形形狀的文檔的四個(gè)頂點(diǎn)的坐標(biāo)找出來(lái)。
傳統(tǒng)技術(shù)方案的難度和局限性
canny 算法的檢測(cè)效果,依賴于幾個(gè)閾值參數(shù),這些閾值參數(shù)的選擇,通常都是人為設(shè)置的經(jīng)驗(yàn)值,在改進(jìn)的過(guò)程中,引入額外的步驟后,通常又會(huì)引入一些新的閾值參數(shù),同樣,也是依賴于調(diào)試結(jié)果設(shè)置的經(jīng)驗(yàn)值。整體來(lái)看,這些閾值參數(shù)的個(gè)數(shù),不能特別的多,因?yàn)橐坏┨嗔耍秃茈y依賴經(jīng)驗(yàn)值進(jìn)行設(shè)置,另外,雖然有這些閾值參數(shù),但是最終的參數(shù)只是一組或少數(shù)幾組固定的組合,所以算法的魯棒性又會(huì)打折扣,很容易遇到邊緣檢測(cè)效果不理想的場(chǎng)景
在邊緣圖上建立的數(shù)學(xué)模型很復(fù)雜,代碼實(shí)現(xiàn)難度大,而且也會(huì)遇到算法無(wú)能為力的場(chǎng)景
下面這張圖表,能夠很好的說(shuō)明上面列出的這兩個(gè)問(wèn)題:

這張圖表的第一列是輸入的 image,最后的三列(先不用看這張圖表的第二列),是用三組不同閾值參數(shù)調(diào)用 canny 函數(shù)和額外的函數(shù)后得到的輸出 image,可以看到,邊緣檢測(cè)的效果,并不總是很理想的,有些場(chǎng)景中,矩形的邊,出現(xiàn)了很嚴(yán)重的斷裂,有些邊,甚至被完全擦除掉了,而另一些場(chǎng)景中,又會(huì)檢測(cè)出很多干擾性質(zhì)的長(zhǎng)短邊。可想而知,想用一個(gè)數(shù)學(xué)模型,適應(yīng)這么不規(guī)則的邊緣圖,會(huì)是多么困難的一件事情。
?思考如何改善
在第一版的技術(shù)方案中,負(fù)責(zé)的同學(xué)花費(fèi)了大量的精力進(jìn)行各種調(diào)優(yōu),終于取得了還不錯(cuò)的效果,但是,就像前面描述的那樣,還是會(huì)遇到檢測(cè)不出來(lái)的場(chǎng)景。在第一版技術(shù)方案中,遇到這種情況的時(shí)候,采用的做法是針對(duì)這些不能檢測(cè)的場(chǎng)景,人工進(jìn)行分析和調(diào)試,調(diào)整已有的一組閾值參數(shù)和算法,可能還需要加入一些其他的算法流程(可能還會(huì)引入新的一些閾值參數(shù)),然后再整合到原有的代碼邏輯中。經(jīng)過(guò)若干輪這樣的調(diào)整后,我們發(fā)現(xiàn),已經(jīng)進(jìn)入一個(gè)瓶頸,按照這種手段,很難進(jìn)一步提高檢測(cè)效果了。
既然傳統(tǒng)的算法手段已經(jīng)到極限了,那不如試試機(jī)器學(xué)習(xí)/神經(jīng)網(wǎng)絡(luò)。
1 神經(jīng)網(wǎng)絡(luò)的輸入和輸出

按照這種思路,對(duì)于神經(jīng)網(wǎng)絡(luò)部分,現(xiàn)在的需求變成了上圖所示的樣子。
2 HED(Holistically-Nested Edge Detection) 網(wǎng)絡(luò)
邊緣檢測(cè)這種需求,在圖像處理領(lǐng)域里面,通常叫做 Edge Detection 或 Contour Detection,按照這個(gè)思路,找到了 Holistically-Nested Edge Detection 網(wǎng)絡(luò)模型。
HED 網(wǎng)絡(luò)模型是在 VGG16 網(wǎng)絡(luò)結(jié)構(gòu)的基礎(chǔ)上設(shè)計(jì)出來(lái)的,所以有必要先看看 VGG16。
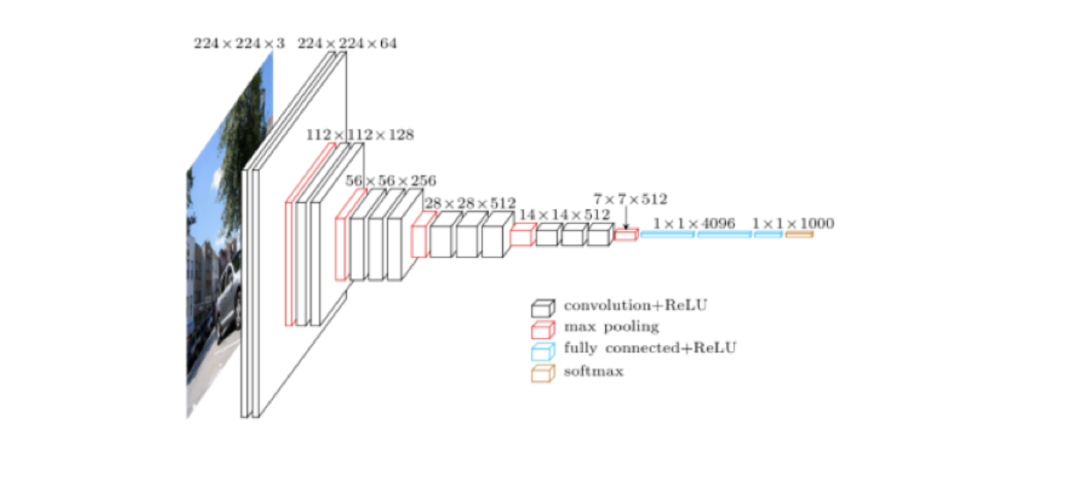
上圖是 VGG16 的原理圖,為了方便從 VGG16 過(guò)渡到 HED,我們先把 VGG16 變成下面這種示意圖:
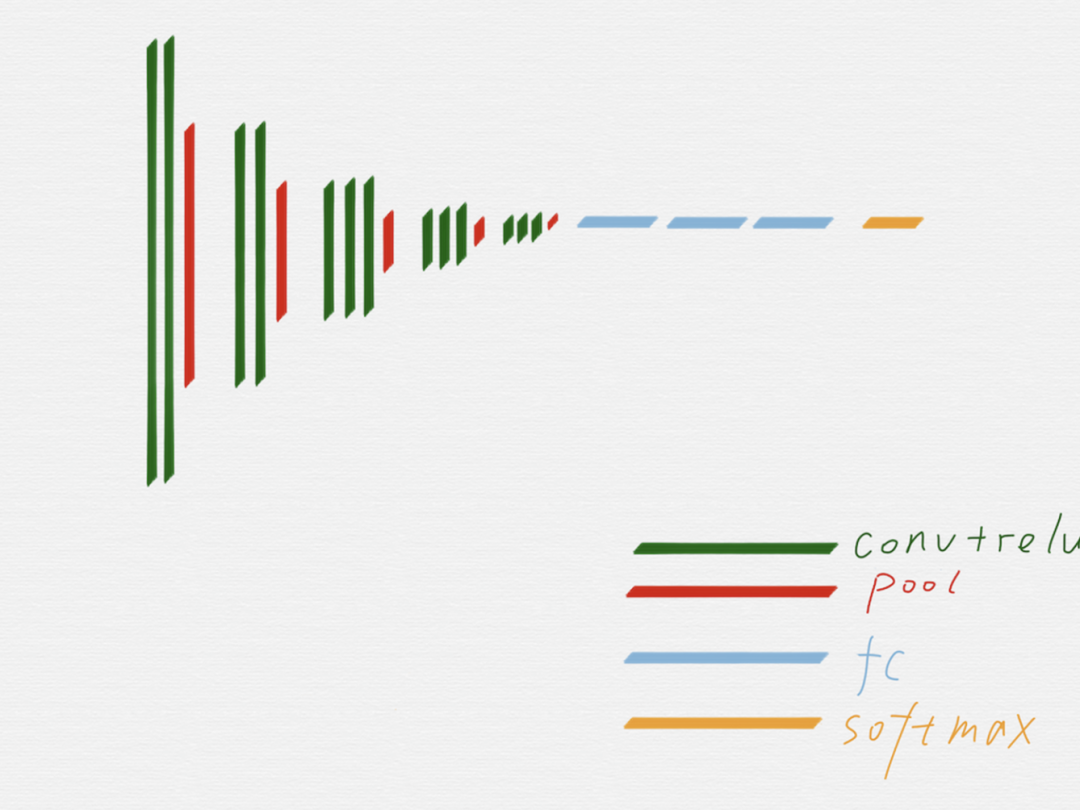
在上面這個(gè)示意圖里,用不同的顏色區(qū)分了 VGG16 的不同組成部分。
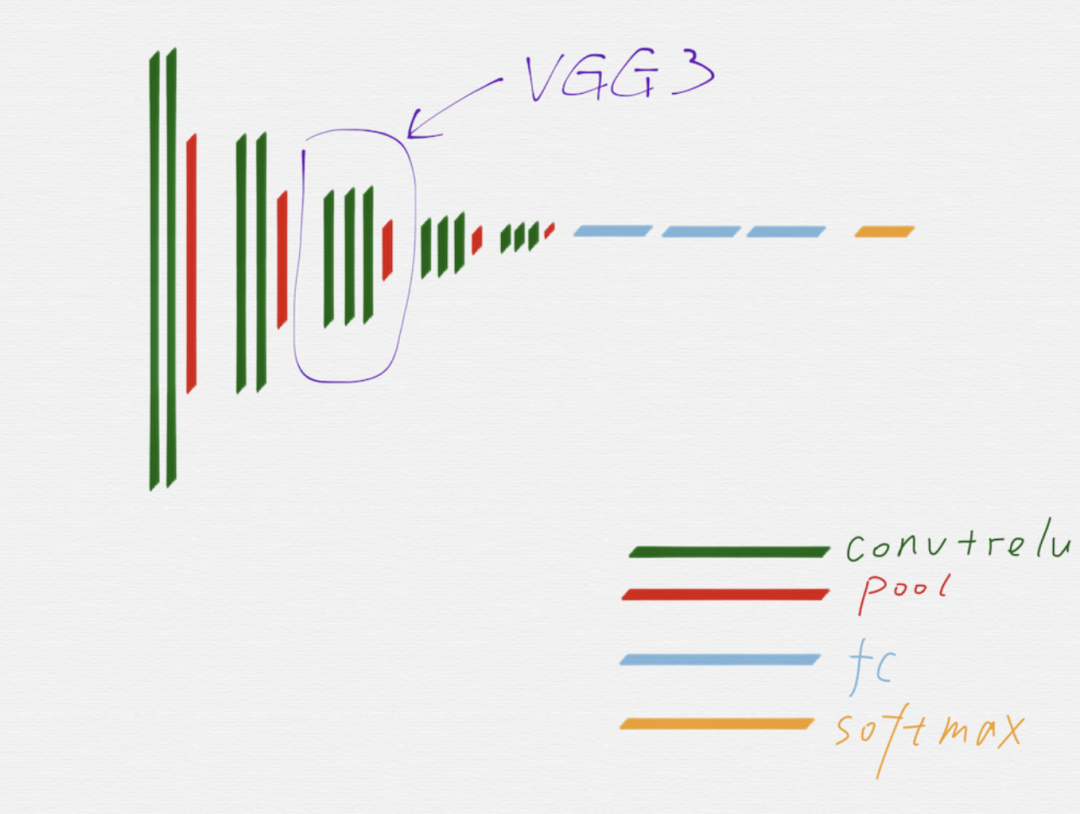
從示意圖上可以看到,綠色代表的卷積層和紅色代表的池化層,可以很明顯的劃分出五組,上圖用紫色線條框出來(lái)的就是其中的第三組。
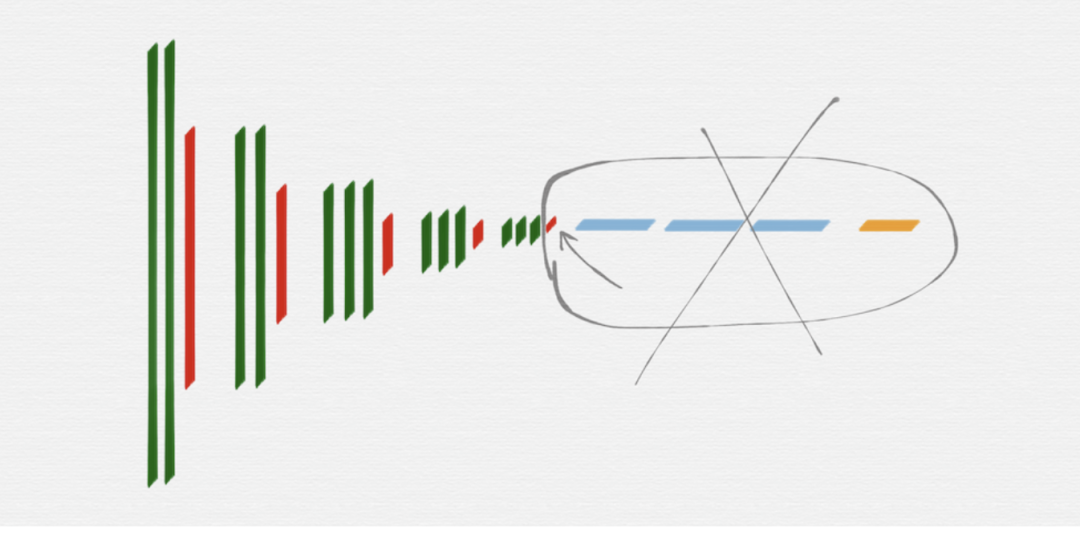
HED 網(wǎng)絡(luò)要使用的就是 VGG16 網(wǎng)絡(luò)里面的這五組,后面部分的 fully connected 層和 softmax 層,都是不需要的,另外,第五組的池化層(紅色)也是不需要的。

去掉不需要的部分后,就得到上圖這樣的網(wǎng)絡(luò)結(jié)構(gòu),因?yàn)橛谐鼗瘜拥淖饔茫瑥牡诙M開(kāi)始,每一組的輸入 image 的長(zhǎng)寬值,都是前一組的輸入 image 的長(zhǎng)寬值的一半。
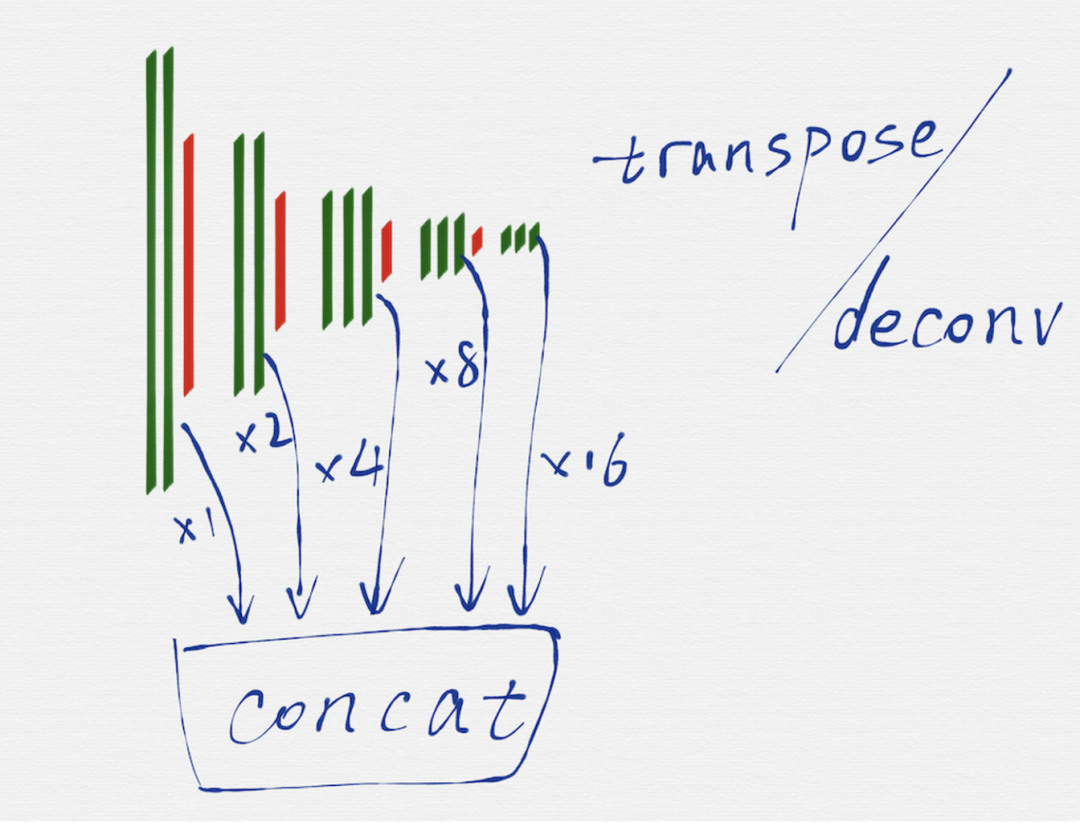
HED 網(wǎng)絡(luò)是一種多尺度多融合(multi-scale and multi-level feature learning)的網(wǎng)絡(luò)結(jié)構(gòu),所謂的多尺度,就是如上圖所示,把 VGG16 的每一組的最后一個(gè)卷積層(綠色部分)的輸出取出來(lái),因?yàn)槊恳唤M得到的 image 的長(zhǎng)寬尺寸是不一樣的,所以這里還需要用轉(zhuǎn)置卷積(transposed convolution)/反卷積(deconv)對(duì)每一組得到的 image 再做一遍運(yùn)算,從效果上看,相當(dāng)于把第二至五組得到的 image 的長(zhǎng)寬尺寸分別擴(kuò)大 2 至 16 倍,這樣在每個(gè)尺度(VGG16 的每一組就是一個(gè)尺度)上得到的 image,都是相同的大小了。

把每一個(gè)尺度上得到的相同大小的 image,再融合到一起,這樣就得到了最終的輸出 image,也就是具有邊緣檢測(cè)效果的 image。
基于 TensorFlow 編寫的 HED 網(wǎng)絡(luò)結(jié)構(gòu)代碼如下:



?訓(xùn)練網(wǎng)絡(luò)
1 cost 函數(shù)
論文給出的 HED 網(wǎng)絡(luò)是一個(gè)通用的邊緣檢測(cè)網(wǎng)絡(luò),按照論文的描述,每一個(gè)尺度上得到的 image,都需要參與 cost 的計(jì)算,這部分的代碼如下:
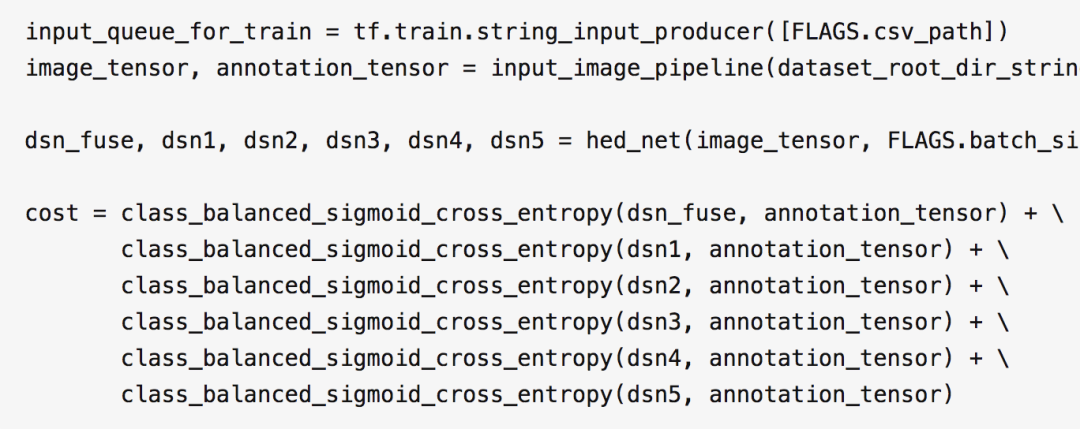
按照這種方式訓(xùn)練出來(lái)的網(wǎng)絡(luò),檢測(cè)到的邊緣線是有一點(diǎn)粗的,為了得到更細(xì)的邊緣線,通過(guò)多次試驗(yàn)找到了一種優(yōu)化方案,代碼如下:

也就是不再讓每個(gè)尺度上得到的 image 都參與 cost 的計(jì)算,只使用融合后得到的最終 image 來(lái)進(jìn)行計(jì)算。
兩種 cost 函數(shù)的效果對(duì)比如下圖所示,右側(cè)是優(yōu)化過(guò)后的效果:

另外還有一點(diǎn),按照 HED 論文里的要求,計(jì)算 cost 的時(shí)候,不能使用常見(jiàn)的方差 cost,而應(yīng)該使用 cost-sensitive loss function,代碼如下:
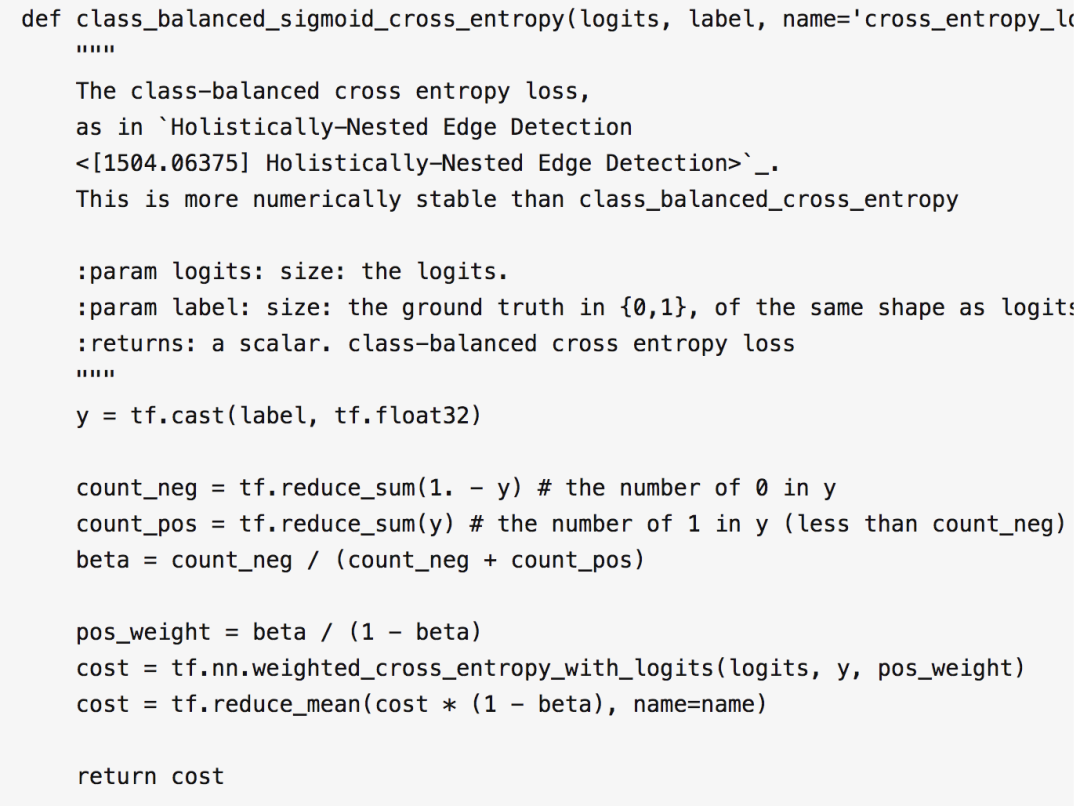
2 轉(zhuǎn)置卷積層的雙線性初始化
在嘗試 FCN 網(wǎng)絡(luò)的時(shí)候,就被這個(gè)問(wèn)題卡住過(guò)很長(zhǎng)一段時(shí)間,按照 FCN 的要求,在使用轉(zhuǎn)置卷積(transposed convolution)/反卷積(deconv)的時(shí)候,要把卷積核的值初始化成雙線性放大矩陣(bilinear upsampling kernel),而不是常用的正態(tài)分布隨機(jī)初始化,同時(shí)還要使用很小的學(xué)習(xí)率,這樣才更容易讓模型收斂。
HED 的論文中,并沒(méi)有明確的要求也要采用這種方式初始化轉(zhuǎn)置卷積層,但是,在訓(xùn)練過(guò)程中發(fā)現(xiàn),采用這種方式進(jìn)行初始化,模型才更容易收斂。
這部分的代碼如下:

3 訓(xùn)練過(guò)程冷啟動(dòng)
HED 網(wǎng)絡(luò)不像 VGG 網(wǎng)絡(luò)那樣很容易就進(jìn)入收斂狀態(tài),也不太容易進(jìn)入期望的理想狀態(tài),主要是兩方面的原因:
前面提到的轉(zhuǎn)置卷積層的雙線性初始化,就是一個(gè)重要因素,因?yàn)樵?4 個(gè)尺度上,都需要反卷積,如果反卷積層不能收斂,那整個(gè) HED 都不會(huì)進(jìn)入期望的理想狀態(tài)
另外一個(gè)原因,是由 HED 的多尺度引起的,既然是多尺度了,那每個(gè)尺度上得到的 image 都應(yīng)該對(duì)模型的最終輸出 image 產(chǎn)生貢獻(xiàn),在訓(xùn)練的過(guò)程中發(fā)現(xiàn),如果輸入 image 的尺寸是 224224,還是很容易就訓(xùn)練成功的,但是當(dāng)把輸入 image 的尺寸調(diào)整為 256256 后,很容易出現(xiàn)一種狀況,就是 5 個(gè)尺度上得到的 image,會(huì)有 1 ~ 2 個(gè) image 是無(wú)效的(全部是黑色)
為了解決這里遇到的問(wèn)題,采用的辦法就是先使用少量樣本圖片(比如 2000 張)訓(xùn)練網(wǎng)絡(luò),在很短的訓(xùn)練時(shí)間(比如迭代 1000 次)內(nèi),如果 HED 網(wǎng)絡(luò)不能表現(xiàn)出收斂的趨勢(shì),或者不能達(dá)到 5 個(gè)尺度的 image 全部有效的狀態(tài),那就直接放棄這輪的訓(xùn)練結(jié)果,重新開(kāi)啟下一輪訓(xùn)練,直到滿意為止,然后才使用完整的訓(xùn)練樣本集合繼續(xù)訓(xùn)練網(wǎng)絡(luò)。
訓(xùn)練數(shù)據(jù)集(大量合成數(shù)據(jù) + 少量真實(shí)數(shù)據(jù))
HED 論文里使用的訓(xùn)練數(shù)據(jù)集,是針對(duì)通用的邊緣檢測(cè)目的的,什么形狀的邊緣都有,比如下面這種:

用這份數(shù)據(jù)訓(xùn)練出來(lái)的模型,在做文檔掃描的時(shí)候,檢測(cè)出來(lái)的邊緣效果并不理想,而且這份訓(xùn)練數(shù)據(jù)集的樣本數(shù)量也很小,只有一百多張圖片(因?yàn)檫@種圖片的人工標(biāo)注成本太高了),這也會(huì)影響模型的質(zhì)量。
現(xiàn)在的需求里,要檢測(cè)的是具有一定透視和旋轉(zhuǎn)變換效果的矩形區(qū)域,所以可以大膽的猜測(cè),如果準(zhǔn)備一批針對(duì)性更強(qiáng)的訓(xùn)練樣本,應(yīng)該是可以得到更好的邊緣檢測(cè)效果的。
借助第一版技術(shù)方案收集回來(lái)的真實(shí)場(chǎng)景圖片,我們開(kāi)發(fā)了一套簡(jiǎn)單的標(biāo)注工具,人工標(biāo)注了 1200 張圖片(標(biāo)注這 1200 張圖片的時(shí)間成本也很高),但是這 1200 多張圖片仍然有很多問(wèn)題,比如對(duì)于神經(jīng)網(wǎng)絡(luò)來(lái)說(shuō),1200 個(gè)訓(xùn)練樣本其實(shí)還是不夠的,另外,這些圖片覆蓋的場(chǎng)景其實(shí)也比較少,有些圖片的相似度比較高,這樣的數(shù)據(jù)放到神經(jīng)網(wǎng)絡(luò)里訓(xùn)練,泛化的效果并不好。
所以,還采用技術(shù)手段,合成了80000多張訓(xùn)練樣本圖片。

如上圖所示,一張背景圖和一張前景圖,可以合成出一對(duì)訓(xùn)練樣本數(shù)據(jù)。在合成圖片的過(guò)程中,用到了下面這些技術(shù)和技巧:
在前景圖上添加旋轉(zhuǎn)、平移、透視變換
對(duì)背景圖進(jìn)行了隨機(jī)的裁剪
通過(guò)試驗(yàn)對(duì)比,生成合適寬度的邊緣線
OpenCV 不支持透明圖層之間的旋轉(zhuǎn)和透視變換操作,只能使用最低精度的插值算法,為了改善這一點(diǎn),后續(xù)改成了使用 iOS 模擬器,通過(guò) CALayer 上的操作來(lái)合成圖片
在不斷改進(jìn)訓(xùn)練樣本的過(guò)程中,還根據(jù)真實(shí)樣本圖片的統(tǒng)計(jì)情況和各種途徑的反饋信息,刻意模擬了一些更復(fù)雜的樣本場(chǎng)景,比如凌亂的背景環(huán)境、直線邊緣干擾等等
經(jīng)過(guò)不斷的調(diào)整和優(yōu)化,最終才訓(xùn)練出一個(gè)滿意的模型,可以再次通過(guò)下面這張圖表中的第二列看一下神經(jīng)網(wǎng)絡(luò)模型的邊緣檢測(cè)效果:
雖然用神經(jīng)網(wǎng)絡(luò)技術(shù),已經(jīng)得到了一個(gè)比 canny 算法更好的邊緣檢測(cè)效果,但是,神經(jīng)網(wǎng)絡(luò)也并不是萬(wàn)能的,干擾是仍然存在的,所以,第二個(gè)步驟中的數(shù)學(xué)模型算法,仍然是需要的,只不過(guò)因?yàn)榈谝粋€(gè)步驟中的邊緣檢測(cè)有了大幅度改善,所以第二個(gè)步驟中的算法,得到了適當(dāng)?shù)暮?jiǎn)化,而且算法整體的適應(yīng)性也更強(qiáng)了。
這部分的算法如下圖所示:
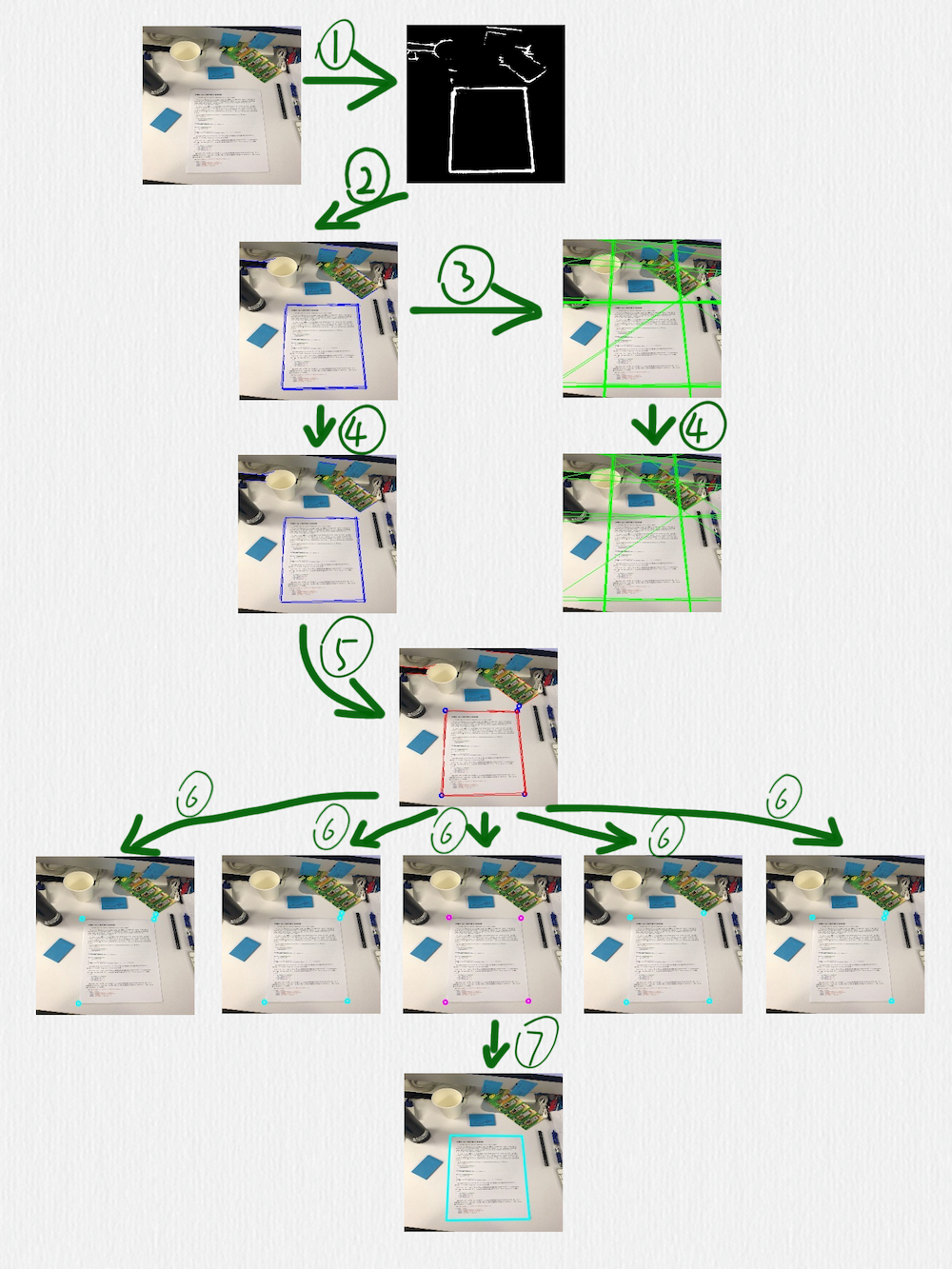
按照編號(hào)順序,幾個(gè)關(guān)鍵步驟做了下面這些事情:
用 HED 網(wǎng)絡(luò)檢測(cè)邊緣,可以看到,這里得到的邊緣線還是存在一些干擾的
在前一步得到的圖像上,使用 HoughLinesP 函數(shù)檢測(cè)線段(藍(lán)色線段)
把前一步得到的線段延長(zhǎng)成直線(綠色直線)
在第二步中檢測(cè)到的線段,有一些是很接近的,或者有些短線段是可以連接成一條更長(zhǎng)的線段的,所以可以采用一些策略把它們合并到一起,這個(gè)時(shí)候,就要借助第三步中得到的直線。定義一種策略判斷兩條直線是否相等,當(dāng)遇到相等的兩條直線時(shí),把這兩條直線各自對(duì)應(yīng)的線段再合并或連接成一條線段。這一步完成后,后面的步驟就只需要藍(lán)色的線段而不需要綠色的直線了
根據(jù)第四步得到的線段,計(jì)算它們之間的交叉點(diǎn),臨近的交叉點(diǎn)也可以合并,同時(shí),把每一個(gè)交叉點(diǎn)和產(chǎn)生這個(gè)交叉點(diǎn)的線段也要關(guān)聯(lián)在一起(每一個(gè)藍(lán)色的點(diǎn),都有一組紅色的線段和它關(guān)聯(lián))
對(duì)于第五步得到的所有交叉點(diǎn),每次取出其中的 4 個(gè),判斷這 4 個(gè)點(diǎn)組成的四邊形是否是一個(gè)合理的矩形(有透視變換效果的矩形),除了常規(guī)的判斷策略,比如角度、邊長(zhǎng)的比值之外,還有一個(gè)判斷條件就是每條邊是否可以和第五步中得到的對(duì)應(yīng)的點(diǎn)的關(guān)聯(lián)線段重合,如果不能重合,則這個(gè)四邊形就不太可能是我們期望檢測(cè)出來(lái)的矩形
經(jīng)過(guò)第六步的過(guò)濾后,如果得到了多個(gè)四邊形,可以再使用一個(gè)簡(jiǎn)單的過(guò)濾策略,比如排序找出周長(zhǎng)或面積最大的矩形
對(duì)于上面這個(gè)例子,第一版技術(shù)方案中檢測(cè)出來(lái)的邊緣線如下圖所示:

有興趣的讀者也可以考慮一下,在這種邊緣圖中,如何設(shè)計(jì)算法才能找出我們期望的那個(gè)矩形。
原文?https://blog.csdn.net/Tencent_Bugly/article/details/72828569
機(jī)器學(xué)習(xí)算法AI大數(shù)據(jù)技術(shù)
?搜索公眾號(hào)添加:?datanlp
長(zhǎng)按圖片,識(shí)別二維碼
閱讀過(guò)本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實(shí)戰(zhàn)
基于40萬(wàn)表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測(cè)
《基于深度學(xué)習(xí)的自然語(yǔ)言處理》中/英PDF
Deep Learning 中文版初版-周志華團(tuán)隊(duì)
【全套視頻課】最全的目標(biāo)檢測(cè)算法系列講解,通俗易懂!
《美團(tuán)機(jī)器學(xué)習(xí)實(shí)踐》_美團(tuán)算法團(tuán)隊(duì).pdf
《深度學(xué)習(xí)入門:基于Python的理論與實(shí)現(xiàn)》高清中文PDF+源碼
《深度學(xué)習(xí):基于Keras的Python實(shí)踐》PDF和代碼
python就業(yè)班學(xué)習(xí)視頻,從入門到實(shí)戰(zhàn)項(xiàng)目
2019最新《PyTorch自然語(yǔ)言處理》英、中文版PDF+源碼
《21個(gè)項(xiàng)目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實(shí)踐詳解》完整版PDF+附書(shū)代碼
《深度學(xué)習(xí)之pytorch》pdf+附書(shū)源碼
PyTorch深度學(xué)習(xí)快速實(shí)戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評(píng)分8.1,《機(jī)器學(xué)習(xí)實(shí)戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識(shí)圖譜項(xiàng)目實(shí)戰(zhàn)視頻(全23課)
李沐大神開(kāi)源《動(dòng)手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計(jì)學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
將機(jī)器學(xué)習(xí)模型部署為REST API
FashionAI服裝屬性標(biāo)簽圖像識(shí)別Top1-5方案分享
重要開(kāi)源!CNN-RNN-CTC 實(shí)現(xiàn)手寫漢字識(shí)別
同樣是機(jī)器學(xué)習(xí)算法工程師,你的面試為什么過(guò)不了?
前海征信大數(shù)據(jù)算法:風(fēng)險(xiǎn)概率預(yù)測(cè)
【Keras】完整實(shí)現(xiàn)‘交通標(biāo)志’分類、‘票據(jù)’分類兩個(gè)項(xiàng)目,讓你掌握深度學(xué)習(xí)圖像分類
VGG16遷移學(xué)習(xí),實(shí)現(xiàn)醫(yī)學(xué)圖像識(shí)別分類工程項(xiàng)目
特征工程(二) :文本數(shù)據(jù)的展開(kāi)、過(guò)濾和分塊
如何利用全新的決策樹(shù)集成級(jí)聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
全球AI挑戰(zhàn)-場(chǎng)景分類的比賽源碼(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識(shí)別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競(jìng)賽華人第1名團(tuán)隊(duì)-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、數(shù)據(jù)分析、python
?搜索公眾號(hào)添加:?datayx??