
服務(wù)鏈路追蹤怎么搞?好搞嗎?
關(guān)注我們,設(shè)為星標(biāo),每天7:30不見不散,架構(gòu)路上與您共享 回復(fù)"架構(gòu)師"獲取資源
微服務(wù)架構(gòu)是一個分布式架構(gòu),它按業(yè)務(wù)劃分服務(wù)單元,一個分布式系統(tǒng)往往有很多個服務(wù)單元。由于服務(wù)單元數(shù)量眾多,業(yè)務(wù)的復(fù)雜性,如果出現(xiàn)了錯誤和異常,很難去定位。主要體現(xiàn)在,一個請求可能需要調(diào)用很多個服務(wù),而內(nèi)部服務(wù)的調(diào)用復(fù)雜性,決定了問題難以定位。所以微服務(wù)架構(gòu)中,必須實(shí)現(xiàn)分布式鏈路追蹤,去跟進(jìn)一個請求到底有哪些服務(wù)參與,參與的順序又是怎樣的,從而達(dá)到每個請求的步驟清晰可見,出了問題,很快定位。
舉幾個例子:
1、在微服務(wù)系統(tǒng)中,一個來自用戶的請求,請求先達(dá)到前端A(如前端界面),然后通過遠(yuǎn)程調(diào)用,達(dá)到系統(tǒng)的中間件B、C(如負(fù)載均衡、網(wǎng)關(guān)等),最后達(dá)到后端服務(wù)D、E,后端經(jīng)過一系列的業(yè)務(wù)邏輯計(jì)算最后將數(shù)據(jù)返回給用戶。對于這樣一個請求,經(jīng)歷了這么多個服務(wù),怎么樣將它的請求過程的數(shù)據(jù)記錄下來呢?這就需要用到服務(wù)鏈路追蹤。
2、分析微服務(wù)系統(tǒng)在大壓力下的可用性和性能。
Zipkin可以結(jié)合壓力測試工具一起使用,分析系統(tǒng)在大壓力下的可用性和性能。
設(shè)想這么一種情況,如果你的微服務(wù)數(shù)量逐漸增大,服務(wù)間的依賴關(guān)系越來越復(fù)雜,怎么分析它們之間的調(diào)用關(guān)系及相互的影響?
spring boot對zipkin的自動配置可以使得所有RequestMapping匹配到的endpoints得到監(jiān)控,以及強(qiáng)化了RestTemplate,對其加了一層攔截器,使得由它發(fā)起的http請求也同樣被監(jiān)控。
Google開源的 Dapper鏈路追蹤組件,并在2010年發(fā)表了論文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,這篇文章是業(yè)內(nèi)實(shí)現(xiàn)鏈路追蹤的標(biāo)桿和理論基礎(chǔ),具有非常大的參考價(jià)值。
目前,鏈路追蹤組件有Google的Dapper,Twitter 的Zipkin,以及阿里的Eagleeye (鷹眼)等,它們都是非常優(yōu)秀的鏈路追蹤開源組件。
本文主要講述如何在Spring Cloud Sleuth中集成Zipkin。在Spring Cloud Sleuth中集成Zipkin非常的簡單,只需要引入相應(yīng)的依賴和做相關(guān)的配置即可。
一、簡介
Spring Cloud Sleuth 主要功能就是在分布式系統(tǒng)中提供追蹤解決方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相應(yīng)的依賴即可。
二、服務(wù)追蹤分析
微服務(wù)架構(gòu)上通過業(yè)務(wù)來劃分服務(wù)的,通過REST調(diào)用,對外暴露的一個接口,可能需要很多個服務(wù)協(xié)同才能完成這個接口功能,如果鏈路上任何一個服務(wù)出現(xiàn)問題或者網(wǎng)絡(luò)超時,都會形成導(dǎo)致接口調(diào)用失敗。隨著業(yè)務(wù)的不斷擴(kuò)張,服務(wù)之間互相調(diào)用會越來越復(fù)雜。

隨著服務(wù)的越來越多,對調(diào)用鏈的分析會越來越復(fù)雜。它們之間的調(diào)用關(guān)系也許如下:

三、術(shù)語
Spring Cloud Sleuth采用的是Google的開源項(xiàng)目Dapper的專業(yè)術(shù)語。
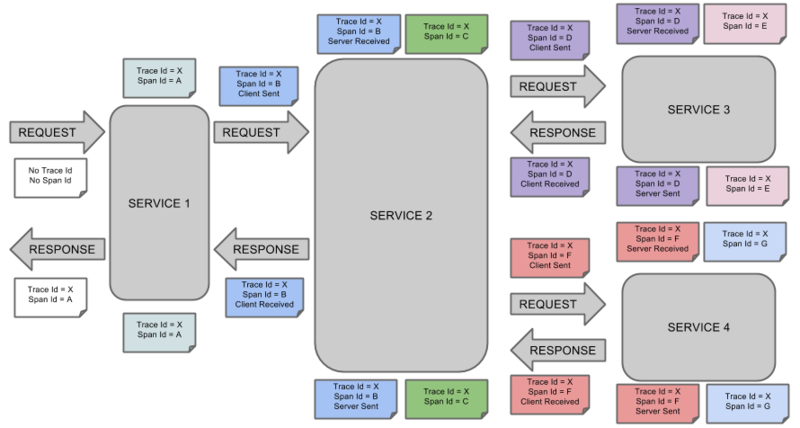
Span:基本工作單元,例如,在一個新建的span中發(fā)送一個RPC等同于發(fā)送一個回應(yīng)請求給RPC,span通過一個64位ID唯一標(biāo)識,trace以另一個64位ID表示,span還有其他數(shù)據(jù)信息,比如摘要、時間戳事件、關(guān)鍵值注釋(tags)、span的ID、以及進(jìn)度ID(通常是IP地址)
span在不斷的啟動和停止,同時記錄了時間信息,當(dāng)你創(chuàng)建了一個span,你必須在未來的某個時刻停止它。Trace:一系列spans組成的一個樹狀結(jié)構(gòu),例如,如果你正在跑一個分布式大數(shù)據(jù)工程,你可能需要創(chuàng)建一個trace。
Annotation:用來及時記錄一個事件的存在,一些核心annotations用來定義一個請求的開始和結(jié)束
cs - Client Sent -客戶端發(fā)起一個請求,這個annotion描述了這個span的開始
sr - Server Received -服務(wù)端獲得請求并準(zhǔn)備開始處理它,如果將其sr減去cs時間戳便可得到網(wǎng)絡(luò)延遲
ss - Server Sent -注解表明請求處理的完成(當(dāng)請求返回客戶端),如果ss減去sr時間戳便可得到服務(wù)端需要的處理請求時間
cr - Client Received -表明span的結(jié)束,客戶端成功接收到服務(wù)端的回復(fù),如果cr減去cs時間戳便可得到客戶端從服務(wù)端獲取回復(fù)的所有所需時間
將Span和Trace在一個系統(tǒng)中使用Zipkin注解的過程圖形化:
四、sleuth與Zipkin關(guān)系?
spring cloud提供了spring-cloud-sleuth-zipkin來方便集成zipkin實(shí)現(xiàn)(指的是Zipkin Client,而不是Zipkin服務(wù)器),該jar包可以通過spring-cloud-starter-zipkin依賴來引入。
五、Zipkin
Zipkin是什么
Zipkin分布式跟蹤系統(tǒng);它可以幫助收集時間數(shù)據(jù),解決在microservice架構(gòu)下的延遲問題;它管理這些數(shù)據(jù)的收集和查找;Zipkin的設(shè)計(jì)是基于谷歌的Google Dapper論文。
每個應(yīng)用程序向Zipkin報(bào)告定時數(shù)據(jù),Zipkin UI呈現(xiàn)了一個依賴圖表來展示多少跟蹤請求經(jīng)過了每個應(yīng)用程序;如果想解決延遲問題,可以過濾或者排序所有的跟蹤請求,并且可以查看每個跟蹤請求占總跟蹤時間的百分比。
為什么使用Zipkin
隨著業(yè)務(wù)越來越復(fù)雜,系統(tǒng)也隨之進(jìn)行各種拆分,特別是隨著微服務(wù)架構(gòu)和容器技術(shù)的興起,看似簡單的一個應(yīng)用,后臺可能有幾十個甚至幾百個服務(wù)在支撐;一個前端的請求可能需要多次的服務(wù)調(diào)用最后才能完成;當(dāng)請求變慢或者不可用時,我們無法得知是哪個后臺服務(wù)引起的,這時就需要解決如何快速定位服務(wù)故障點(diǎn),Zipkin分布式跟蹤系統(tǒng)就能很好的解決這樣的問題。
Zipkin原理
針對服務(wù)化應(yīng)用全鏈路追蹤的問題,Google發(fā)表了Dapper論文,介紹了他們?nèi)绾芜M(jìn)行服務(wù)追蹤分析。其基本思路是在服務(wù)調(diào)用的請求和響應(yīng)中加入ID,標(biāo)明上下游請求的關(guān)系。利用這些信息,可以可視化地分析服務(wù)調(diào)用鏈路和服務(wù)間的依賴關(guān)系。
對應(yīng)Dpper的開源實(shí)現(xiàn)是Zipkin,支持多種語言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多種不同的庫來支持
Spring Cloud Sleuth是對Zipkin的一個封裝,對于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server發(fā)送采集信息等全部自動完成。Spring Cloud Sleuth的概念圖見上圖。
Zipkin架構(gòu)
跟蹤器(Tracer)位于你的應(yīng)用程序中,并記錄發(fā)生的操作的時間和元數(shù)據(jù),提供了相應(yīng)的類庫,對用戶的使用來說是透明的,收集的跟蹤數(shù)據(jù)稱為Span;將數(shù)據(jù)發(fā)送到Zipkin的儀器化應(yīng)用程序中的組件稱為Reporter,Reporter通過幾種傳輸方式之一將追蹤數(shù)據(jù)發(fā)送到Zipkin收集器(collector),然后將跟蹤數(shù)據(jù)進(jìn)行存儲(storage),由API查詢存儲以向UI提供數(shù)據(jù)。
架構(gòu)圖如下: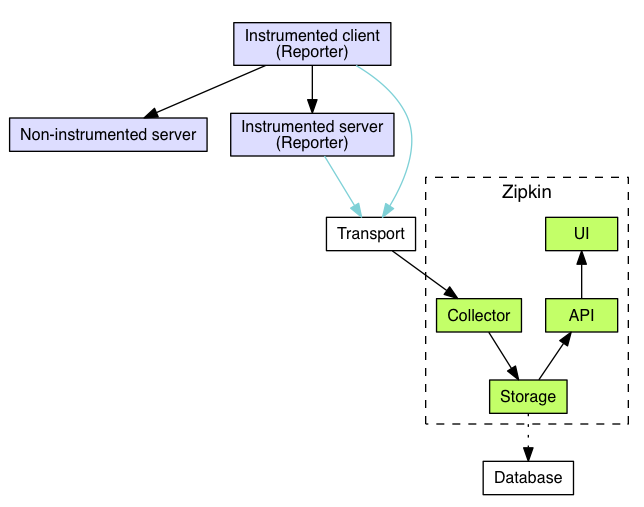
1.Trace
Zipkin使用Trace結(jié)構(gòu)表示對一次請求的跟蹤,一次請求可能由后臺的若干服務(wù)負(fù)責(zé)處理,每個服務(wù)的處理是一個Span,Span之間有依賴關(guān)系,Trace就是樹結(jié)構(gòu)的Span集合;
2.Span
每個服務(wù)的處理跟蹤是一個Span,可以理解為一個基本的工作單元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等,例如:
{
"traceId": "bd7a977555f6b982",
"name": "get-traces",
"id": "ebf33e1a81dc6f71",
"parentId": "bd7a977555f6b982",
"timestamp": 1458702548478000,
"duration": 354374,
"annotations": [
{
"endpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
},
"timestamp": 1458702548786000,
"value": "cs"
}
],
"binaryAnnotations": [
{
"key": "lc",
"value": "JDBCSpanStore",
"endpoint": {
"serviceName": "zipkin-query",
"ipv4": "192.168.1.2",
"port": 9411
}
}
]
}
traceId:標(biāo)記一次請求的跟蹤,相關(guān)的Spans都有相同的traceId;
id:span id;
name:span的名稱,一般是接口方法的名稱;
parentId:可選的id,當(dāng)前Span的父Span id,通過parentId來保證Span之間的依賴關(guān)系,如果沒有parentId,表示當(dāng)前Span為根Span;
timestamp:Span創(chuàng)建時的時間戳,使用的單位是微秒(而不是毫秒),所有時間戳都有錯誤,包括主機(jī)之間的時鐘偏差以及時間服務(wù)重新設(shè)置時鐘的可能性,出于這個原因,Span應(yīng)盡可能記錄其duration;
duration:持續(xù)時間使用的單位是微秒(而不是毫秒);
annotations:注釋用于及時記錄事件;有一組核心注釋用于定義RPC請求的開始和結(jié)束;
cs:Client Send,客戶端發(fā)起請求;
sr:Server Receive,服務(wù)器接受請求,開始處理;
ss:Server Send,服務(wù)器完成處理,給客戶端應(yīng)答;
cr:Client Receive,客戶端接受應(yīng)答從服務(wù)器;
binaryAnnotations:二進(jìn)制注釋,旨在提供有關(guān)RPC的額外信息。
3.Transport
收集的Spans必須從被追蹤的服務(wù)運(yùn)輸?shù)絑ipkin collector,有三個主要的傳輸方式:HTTP, Kafka和Scribe;
4.Components
有4個組件組成Zipkin:collector,storage,search,web UI
collector:一旦跟蹤數(shù)據(jù)到達(dá)Zipkin collector守護(hù)進(jìn)程,它將被驗(yàn)證,存儲和索引,以供Zipkin收集器查找;
storage:Zipkin最初數(shù)據(jù)存儲在Cassandra上,因?yàn)镃assandra是可擴(kuò)展的,具有靈活的模式,并在Twitter中大量使用;但是這個組件可插入,除了Cassandra之外,還支持ElasticSearch和MySQL; 存儲,zipkin默認(rèn)的存儲方式為in-memory,即不會進(jìn)行持久化操作。如果想進(jìn)行收集數(shù)據(jù)的持久化,可以存儲數(shù)據(jù)在Cassandra,因?yàn)镃assandra是可擴(kuò)展的,有一個靈活的模式,并且在Twitter中被大量使用,我們使這個組件可插入。除了Cassandra,我們原生支持ElasticSearch和MySQL。其他后端可能作為第三方擴(kuò)展提供。
search:一旦數(shù)據(jù)被存儲和索引,我們需要一種方法來提取它。查詢守護(hù)進(jìn)程提供了一個簡單的JSON API來查找和檢索跟蹤,主要給Web UI使用;
web UI:創(chuàng)建了一個GUI,為查看痕跡提供了一個很好的界面;Web UI提供了一種基于服務(wù),時間和注釋查看跟蹤的方法。
Zipkin下載和啟動
有三種安裝方法:
Zipkin的使用比較簡單,官網(wǎng)有說明幾種方式:
1、容器 Docker Zipkin項(xiàng)目能夠建立docker鏡像,提供腳本和docker-compose.yml來啟動預(yù)構(gòu)建的圖像。最快的開始是直接運(yùn)行最新鏡像:
docker run -d -p 9411:9411 openzipkin/zipkin
2、下載jar
如果你有java 8或更高版本,上手最快的方法是把新版本作為一個獨(dú)立的可執(zhí)行jar,Zipkin使用springboot來構(gòu)建的:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
3、下載源代碼運(yùn)行 Zipkin可以從源運(yùn)行,如果你正在開發(fā)新的功能。要實(shí)現(xiàn)這一點(diǎn),需要獲取Zipkin的源代碼并構(gòu)建它。
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
1、使用官網(wǎng)自己打包好的Jar運(yùn)行,Docker方式或下載源代碼自己打包Jar運(yùn)行(因?yàn)閦ipkin使用了springboot,內(nèi)置了服務(wù)器,所以可以直接使用jar運(yùn)行)。zipkin推薦使用docker方式運(yùn)行,我后面會專門寫一遍關(guān)于docker的運(yùn)行方式,而源碼運(yùn)行方式好處是有機(jī)會體驗(yàn)到最新的功能特性,但是可能也會帶來一些比較詭異的坑,所以不做講解,下面我直接是使用官網(wǎng)打包的jar運(yùn)行過程:
官方提供了三種方式來啟動,這里使用第二種方式來啟動;
wget -O zipkin.jar 'https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec'
java -jar zipkin.jar
首先下載zipkin.jar,我下載的是zipkin-server-2.10.2-exec.jar,然后直接使用-jar命令運(yùn)行,要求jdk8以上版本;
D:\workspace\zipkin>java -jar zipkin-server-2.10.2-exec.jar
********
** **
* *
** **
** **
** **
** **
********
****
****
**** ****
****** **** ***
****************************************************************************
******* **** ***
**** ****
**
**
***** ** ***** ** ** ** ** **
** ** ** * *** ** **** **
** ** ***** **** ** ** ***
****** ** ** ** ** ** ** **
:: Powered by Spring Boot :: (v2.0.3.RELEASE)
...
2018-07-20 14:59:08.635 INFO 17284 --- [ main] o.xnio : XNIO version 3.3.8.Final
2018-07-20 14:59:08.650 INFO 17284 --- [ main] o.x.nio : XNIO NIO Implementation Version 3.3.8.Final
2018-07-20 14:59:08.727 INFO 17284 --- [ main] o.s.b.w.e.u.UndertowServletWebServer : Undertow started on port(s) 9411 (http) with context path ''
2018-07-20 14:59:08.729 INFO 17284 --- [ main] z.s.ZipkinServer : Started ZipkinServer in 4.513 seconds (JVM running for 5.756)
2018-07-20 14:59:36.546 INFO 17284 --- [ XNIO-1 task-1] i.u.servlet : Initializing Spring FrameworkServlet 'dispatcherServlet'
2018-07-20 14:59:36.547 INFO 17284 --- [ XNIO-1 task-1] o.s.w.s.DispatcherServlet : FrameworkServlet 'dispatcherServlet': initialization started
2018-07-20 14:59:36.563 INFO 17284 --- [ XNIO-1 task-1] o.s.w.s.DispatcherServlet : FrameworkServlet 'dispatcherServlet': initialization completed in 15ms
(3) 查看運(yùn)行效果
通過上圖,我們發(fā)現(xiàn)zipkin使用springboot,并且啟動的端口為9411,然后我們通過瀏覽器訪問,效果如下:
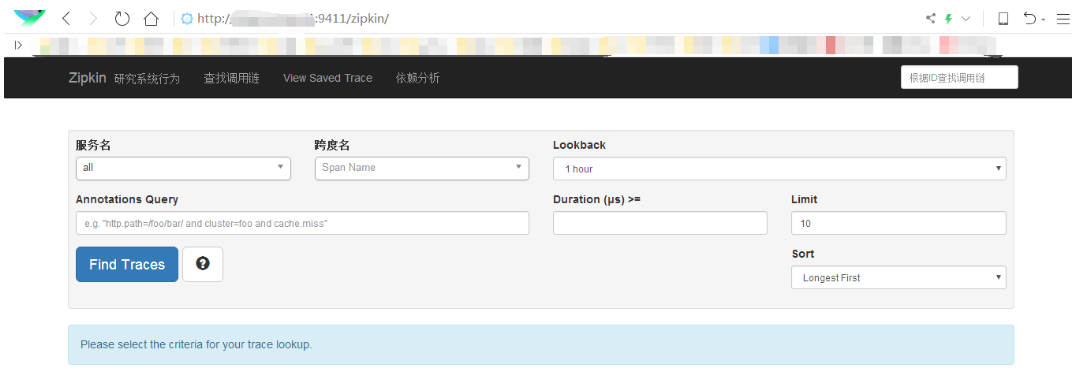
詳細(xì)參考:https://zipkin.io/pages/quick...
六、入門示例
追蹤服務(wù)包含下面幾個服務(wù):
1、注冊中心 Eureka Server(可選的,只用于服務(wù)生產(chǎn)者和調(diào)用者注冊)
2、Zipkin服務(wù)器
3、服務(wù)的生產(chǎn)者及服務(wù)的調(diào)用者:
1)服務(wù)的生產(chǎn)者、調(diào)用者是相對的,兩者之間可以互相調(diào)用,即可以同時作為生產(chǎn)者和調(diào)用者,兩者都是Eureka Client;
2)兩者都要注冊到注冊中心上,這樣才可以相互可見,才能通過服務(wù)名來調(diào)用指定服務(wù),才能使用Feign或RestTemplate+Ribbon來達(dá)到負(fù)載均衡
3)兩者都要注冊到Zipkin服務(wù)器上,這樣Zipkin才能追蹤服務(wù)的調(diào)用鏈路
構(gòu)建工程
基本知識講解完畢,下面我們來實(shí)戰(zhàn),本文的案例主要有三個工程組成:一個server-zipkin,它的主要作用使用ZipkinServer 的功能,收集調(diào)用數(shù)據(jù),并展示;一個service-hi,對外暴露hi接口;一個service-miya,對外暴露miya接口;這兩個service可以相互調(diào)用;并且只有調(diào)用了,server-zipkin才會收集數(shù)據(jù)的,這就是為什么叫服務(wù)追蹤了。
一、Zipkin服務(wù)器
代碼地址(碼云):https://gitee.com/wudiyong/ZipkinServer.git
1、新建一個普通的Spring Boot項(xiàng)目,工程取名為server-zipkin,在其pom引入依賴:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.dxz.serverzipkin</groupId>
<artifactId>serverzipkin</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>server-zipkin</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version> <!--配合spring cloud版本 -->
<relativePath /> <!-- lookup parent from repository -->
</parent>
<properties>
<!--設(shè)置字符編碼及java版本 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--增加zipkin的依賴 -->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<!--用于測試的,本例可省略 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<!--依賴管理,用于管理spring-cloud的依賴 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-parent</artifactId>
<version>Brixton.SR3</version> <!--官網(wǎng)為Angel.SR4版本,但是我使用的時候總是報(bào)錯 -->
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<!--使用該插件打包 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2在其程序入口類, 加上注解@EnableZipkinServer,開啟ZipkinServer的功能:
package com.dxz.serverzipkin;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import zipkin.server.EnableZipkinServer;
@EnableZipkinServer
@SpringBootApplication
public class ServerZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ServerZipkinApplication.class, args);
}
}
3在配置文件application.yml指定,配置Zipkin服務(wù)端口、名稱等:
server.port=9411
spring.application.name=my-zipkin-server
啟動后打開http://localhost:9411/可以看到
如下圖,什么內(nèi)容都沒有,因?yàn)檫€沒有任何服務(wù)注冊到Zipkin,一旦有服務(wù)注冊到Zipkin便在Service Name下拉列表中可以看到服務(wù)名字,當(dāng)有服務(wù)被調(diào)用,則可以在Span Name中看到被調(diào)用的接口名字.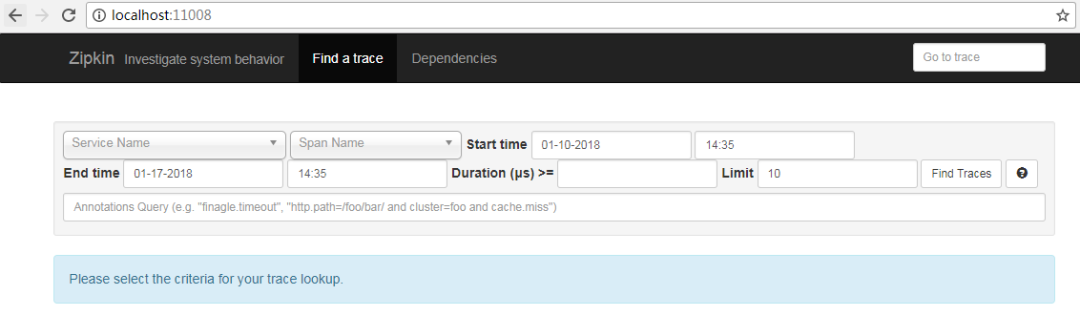
這里為了測試方便,我們可以將數(shù)據(jù)保存到內(nèi)存中,但是生產(chǎn)環(huán)境還是需要將數(shù)據(jù)持久化的,原生支持了很多產(chǎn)品,例如ES、數(shù)據(jù)庫等。二服務(wù)生成者調(diào)用者
這兩者配置是一樣的此處簡化,直接修改compute-server和feign-consumer兩個服務(wù),修改有兩點(diǎn):
1、pom增加
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
2、在其配置文件application.yml指定zipkin server的地址,頭通過配置“spring.zipkin.base-url”指定:
spring.zipkin.base-url=http://localhost:9411
至此,可以開始測試Zipkin追蹤服務(wù)了
三啟動工程,演示追蹤
啟動順序:注冊中心(可選)->配置中心(可選)->Zipkin服務(wù)器->服務(wù)生產(chǎn)者及調(diào)用者
我們可以嘗試調(diào)用生產(chǎn)者或調(diào)用者的接口,然后刷新Zipkin服務(wù)器頁面,可以看到如下結(jié)果:
依次啟動上面的三個工程,打開瀏覽器訪問:http://localhost:9411/,會出現(xiàn)以下界面:
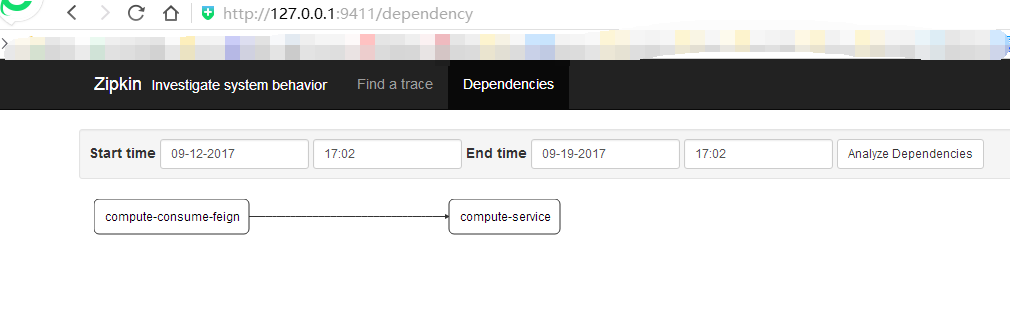
再打開http://localhost:9411/的界面,點(diǎn)擊Dependencies,可以發(fā)現(xiàn)服務(wù)的依賴關(guān)系:
點(diǎn)擊find traces,可以看到具體服務(wù)相互調(diào)用的數(shù)據(jù):
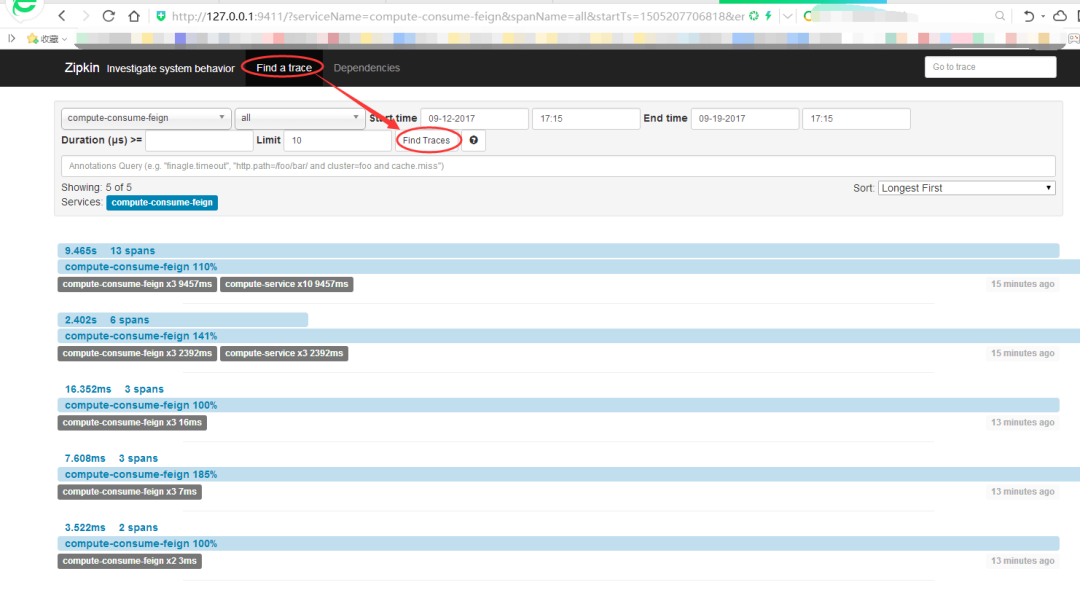
可以看到,調(diào)用消費(fèi)者(ribbon-consumer)耗時83ms,其中消費(fèi)者調(diào)用生產(chǎn)者占了5ms,占比6%。
在測試的過程中我們會發(fā)現(xiàn),有時候,程序剛剛啟動后,刷新幾次,并不能看到任何數(shù)據(jù),原因就是我們的spring-cloud-sleuth收集信息是有一定的比率的,默認(rèn)的采樣率是0.1,配置此值的方式在配置文件中增加spring.sleuth.sampler.percentage參數(shù)配置(如果不配置默認(rèn)0.1),如果我們調(diào)大此值為1,可以看到信息收集就更及時。但是當(dāng)這樣調(diào)整后,我們會發(fā)現(xiàn)我們的rest接口調(diào)用速度比0.1的情況下慢了很多,即使在0.1的采樣率下,我們多次刷新consumer的接口,會發(fā)現(xiàn)對同一個請求兩次耗時信息相差非常大,如果取消spring-cloud-sleuth后我們再測試,會發(fā)現(xiàn)并沒有這種情況,可以看到這種方式追蹤服務(wù)調(diào)用鏈路會給我們業(yè)務(wù)程序性能帶來一定的影響。
#sleuth采樣率,默認(rèn)為0.1,值越大收集越及時,但性能影響也越大
spring.sleuth.sampler.percentage=1
其實(shí),我們仔細(xì)想想也可以總結(jié)出這種方式的幾種缺陷:
缺陷1:zipkin客戶端向zipkin-server程序發(fā)送數(shù)據(jù)使用的是http的方式通信,每次發(fā)送的時候涉及到連接和發(fā)送過程。
缺陷2:當(dāng)我們的zipkin-server程序關(guān)閉或者重啟過程中,因?yàn)榭蛻舳耸占畔⒌陌l(fā)送采用http的方式會被丟失。
針對以上兩個明顯的缺陷,改進(jìn)的辦法是:
1、通信采用socket或者其他效率更高的通信方式。
2、客戶端數(shù)據(jù)的發(fā)送盡量減少業(yè)務(wù)線程的時間消耗,采用異步等方式發(fā)送收集信息。
3、客戶端與zipkin-server之間增加緩存類的中間件,例如redis、MQ等,在zipkin-server程序掛掉或重啟過程中,客戶端依舊可以正常的發(fā)送自己收集的信息。
相信采用以上三種方式會很大的提高我們的效率和可靠性。其實(shí)spring-cloud已經(jīng)為我們提供采用MQ或redis等其他的采用socket方式通信,利用消息中間件或數(shù)據(jù)庫緩存的實(shí)現(xiàn)方式。
spring-cloud-sleuth-zipkin-stream方式的實(shí)現(xiàn)請看下面內(nèi)容!
將HTTP通信改成MQ異步方式通信
springcloud官方按照傳輸方式分成了三種啟動服務(wù)端的方式:
Sleuth with Zipkin via HTTP,
Sleuth with Zipkin via Spring Cloud Stream,
Spring Cloud Sleuth Stream Zipkin Collector。
只需要添加相應(yīng)的依賴,之后配置相應(yīng)的注解,如@EnableZipkinStreamServer即可。具體配置參考官方文檔:
(http://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/1.2.1.RELEASE/#_adding_to_the_project)
1、加入依賴
要將http方式改為通過MQ通信,我們要將依賴的原來依賴的io.zipkin.java:zipkin-server換成spring-cloud-sleuth-zipkin-stream和spring-cloud-starter-stream-rabbit
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency> 2、在啟動類中開啟Stream通信功能
package com.zipkinServer.ZipkinServer;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
import zipkin.server.EnableZipkinServer;
/*
* @EnableZipkinServer、@EnableZipkinStreamServer兩者二選一
* 通過源碼可看到,@EnableZipkinStreamServer包含了@EnableZipkinServer,同時
* 還創(chuàng)建了一個rabbit-mq的消息隊(duì)列監(jiān)聽器,所以也支持原來的HTTP通信方式
*/
//@EnableZipkinServer//默認(rèn)采用HTTP通信方式啟動ZipkinServer
@EnableZipkinStreamServer//采用Stream通信方式啟動ZipkinServer,也支持HTTP通信方式
@SpringBootApplication
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
3、配置消息中間件rabbit mq地址等信息
#連接rabbitmq服務(wù)器配置
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
至此,ZipkinServer配置完成,下面是Zipkin客戶端的配置
1、將原來的spring-cloud-starter-zipkin替換為如下依賴即可
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2、此外,在配置文件中也加上連接MQ的配置
#連接rabbitmq服務(wù)器配置
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
至此全部配置完成,可以開始測試。
另外,由于要連接到rabbitmq服務(wù)器,所以,還要安裝及啟動rabbitmq服務(wù)器!
加了MQ之后,通信過程如下圖所示:

可以看到如下效果:
1)請求的耗時時間不會出現(xiàn)突然耗時特長的情況
2)當(dāng)ZipkinServer不可用時(比如關(guān)閉、網(wǎng)絡(luò)不通等),追蹤信息不會丟失,因?yàn)檫@些信息會保存在Rabbitmq服務(wù)器上,直到Zipkin服務(wù)器可用時,再從Rabbitmq中取出這段時間的信息
持久化到數(shù)據(jù)庫
Zipkin目前只支持mysql數(shù)據(jù)庫,ZipkinServer服務(wù)做如下修改,其它服務(wù)不需做任何修改
1、加入數(shù)據(jù)庫依賴
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
2、在application.properties中配置數(shù)據(jù)庫屬性
#zipkin數(shù)據(jù)保存到數(shù)據(jù)庫中需要進(jìn)行如下配置
#表示當(dāng)前程序不使用sleuth
spring.sleuth.enabled=false
#表示zipkin數(shù)據(jù)存儲方式是mysql
zipkin.storage.type=mysql
#數(shù)據(jù)庫腳本創(chuàng)建地址,當(dāng)有多個時可使用[x]表示集合第幾個元素,腳本可到官網(wǎng)下載,需要先手動到數(shù)據(jù)庫執(zhí)行
spring.datasource.schema[0]=classpath:/zipkin.sql
#spring boot數(shù)據(jù)源配置
spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.initialize=true
spring.datasource.continue-on-error=true
3、zipkin.sql
數(shù)據(jù)庫腳本文件放到resources目錄下,且需要先手動到數(shù)據(jù)庫執(zhí)行一次,內(nèi)容如下:
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
至此,ZipkinServer采用數(shù)據(jù)庫存儲配置完成。
測試時發(fā)現(xiàn),要用MQ異步方式通信的pom.xml配置及@EnableZipkinStreamServer注解才可以(@EnableZipkinServer貌似只能保存到內(nèi)存),否則啟動報(bào)錯,不明白為什么。
elasticsearch存儲
前面講了利用mq的方式發(fā)送數(shù)據(jù),存儲在mysql,實(shí)際生產(chǎn)過程中調(diào)用數(shù)據(jù)量非常的大,mysql存儲并不是很好的選擇,這時我們可以采用elasticsearch進(jìn)行存儲
配置過程也很簡單
1、mysql依賴改成elasticsearch依賴
<!-- 添加 spring-data-elasticsearch的依賴 -->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>1.24.0</version>
<optional>true</optional>
</dependency>
2、數(shù)據(jù)庫配置改成elasticsearch配置
#表示當(dāng)前程序不使用sleuth
spring.sleuth.enabled=false
#表示zipkin數(shù)據(jù)存儲方式是elasticsearch
zipkin.storage.StorageComponent = elasticsearch
zipkin.storage.type=elasticsearch
zipkin.storage.elasticsearch.cluster=elasticsearch-zipkin-cluster
zipkin.storage.elasticsearch.hosts=127.0.0.1:9300
# zipkin.storage.elasticsearch.pipeline=
zipkin.storage.elasticsearch.max-requests=64
zipkin.storage.elasticsearch.index=zipkin
zipkin.storage.elasticsearch.index-shards=5
zipkin.storage.elasticsearch.index-replicas=1
3、安裝elasticsearch
其它代碼完全不變
具體見:
http://www.cnblogs.com/shunyang/p/7011306.html
http://www.cnblogs.com/shunyang/p/7298005.html
https://segmentfault.com/a/1190000012342007
https://blog.csdn.net/meiliangdeng1990/article/details/54131384
文章來源:https://urlify.cn/r2mqee

到此文章就結(jié)束了。如果今天的文章對你在進(jìn)階架構(gòu)師的路上有新的啟發(fā)和進(jìn)步,歡迎轉(zhuǎn)發(fā)給更多人。歡迎加入架構(gòu)師社區(qū)技術(shù)交流群,眾多大咖帶你進(jìn)階架構(gòu)師,在后臺回復(fù)“加群”即可入群。
這些年小編給你分享過的干貨
1.SpringBoot物流管理項(xiàng)目,拿去學(xué)習(xí)吧(附源碼)
2.ERP系統(tǒng),自帶進(jìn)銷存+財(cái)務(wù)+生產(chǎn)功能,拿來即用(附源碼)
3.帶工作流的SpringBoot后臺管理項(xiàng)目快速開發(fā)(附源碼)
4.最好的OA系統(tǒng),拿來即用,非常方便(附源碼)
5.SpringBoot+Vue完整的外賣系統(tǒng),手機(jī)端和后臺管理,附源碼!
6.SpringBoot+Vue 可視化拖拽編輯的大屏項(xiàng)目(附源碼)

轉(zhuǎn)發(fā)在看就是最大的支持??