
Hive常用參數(shù)調(diào)優(yōu)十二板斧
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




1. limit限制調(diào)整
一般情況下,Limit語(yǔ)句還是需要執(zhí)行整個(gè)查詢語(yǔ)句,然后再返回部分結(jié)果。
有一個(gè)配置屬性可以開啟,避免這種情況---對(duì)數(shù)據(jù)源進(jìn)行抽樣。
hive.limit.optimize.enable=true --- 開啟對(duì)數(shù)據(jù)源進(jìn)行采樣的功能 hive.limit.row.max.size --- 設(shè)置最小的采樣容量 hive.limit.optimize.limit.file --- 設(shè)置最大的采樣樣本數(shù)
缺點(diǎn):有可能部分?jǐn)?shù)據(jù)永遠(yuǎn)不會(huì)被處理到
2. JOIN優(yōu)化
1)將大表放后頭
Hive假定查詢中最后的一個(gè)表是大表。它會(huì)將其它表緩存起來,然后掃描最后那個(gè)表。因此通常需要將小表放前面,或者標(biāo)記哪張表是大表:/*streamtable(table_name) */
2). 使用相同的連接鍵
當(dāng)對(duì)3個(gè)或者更多個(gè)表進(jìn)行join連接時(shí),如果每個(gè)on子句都使用相同的連接鍵的話,那么只會(huì)產(chǎn)生一個(gè)MapReduce job。
3). 盡量盡早地過濾數(shù)據(jù)
減少每個(gè)階段的數(shù)據(jù)量,對(duì)于分區(qū)表要加分區(qū),同時(shí)只選擇需要使用到的字段。
4). 盡量原子化操作
盡量避免一個(gè)SQL包含復(fù)雜邏輯,可以使用中間表來完成復(fù)雜的邏輯
3. 本地模式
有時(shí)hive的輸入數(shù)據(jù)量是非常小的。在這種情況下,為查詢出發(fā)執(zhí)行任務(wù)的時(shí)間消耗可能會(huì)比實(shí)際job的執(zhí)行時(shí)間要多的多。對(duì)于大多數(shù)這種情況,hive可以通過本地模式在單臺(tái)機(jī)器上處理所有的任務(wù)。對(duì)于小數(shù)據(jù)集,執(zhí)行時(shí)間會(huì)明顯被縮短
set hive.exec.mode.local.auto=true;
當(dāng)一個(gè)job滿足如下條件才能真正使用本地模式: - 1.job的輸入數(shù)據(jù)大小必須小于參數(shù):hive.exec.mode.local.auto.inputbytes.max(默認(rèn)128MB) - 2.job的map數(shù)必須小于參數(shù):hive.exec.mode.local.auto.tasks.max(默認(rèn)4) - 3.job的reduce數(shù)必須為0或者1
可用參數(shù)hive.mapred.local.mem(默認(rèn)0)控制child jvm使用的最大內(nèi)存數(shù)。
4.并行執(zhí)行
hive會(huì)將一個(gè)查詢轉(zhuǎn)化為一個(gè)或多個(gè)階段,包括:MapReduce階段、抽樣階段、合并階段、limit階段等。默認(rèn)情況下,一次只執(zhí)行一個(gè)階段。不過,如果某些階段不是互相依賴,是可以并行執(zhí)行的。
set hive.exec.parallel=true,可以開啟并發(fā)執(zhí)行。
set hive.exec.parallel.thread.number=16; //同一個(gè)sql允許最大并行度,默認(rèn)為8。
會(huì)比較耗系統(tǒng)資源。
5.strict模式
對(duì)分區(qū)表進(jìn)行查詢,在where子句中沒有加分區(qū)過濾的話,將禁止提交任務(wù)(默認(rèn):nonstrict)
set hive.mapred.mode=strict;
注:使用嚴(yán)格模式可以禁止3種類型的查詢:(1)對(duì)于分區(qū)表,不加分區(qū)字段過濾條件,不能執(zhí)行 (2)對(duì)于order by語(yǔ)句,必須使用limit語(yǔ)句 (3)限制笛卡爾積的查詢(join的時(shí)候不使用on,而使用where的)
6.調(diào)整mapper和reducer個(gè)數(shù)
Map階段優(yōu)化
map執(zhí)行時(shí)間:map任務(wù)啟動(dòng)和初始化的時(shí)間+邏輯處理的時(shí)間。
1.通常情況下,作業(yè)會(huì)通過input的目錄產(chǎn)生一個(gè)或者多個(gè)map任務(wù)。主要的決定因素有:input的文件總個(gè)數(shù),input的文件大小,集群設(shè)置的文件塊大小(目前為128M, 可在hive中通過set dfs.block.size;命令查看到,該參數(shù)不能自定義修改);
2.舉例:
a)假設(shè)input目錄下有1個(gè)文件a,大小為780M,那么hadoop會(huì)將該文件a分隔成7個(gè)塊(6個(gè)128m的塊和1個(gè)12m的塊),從而產(chǎn)生7個(gè)map數(shù) b)假設(shè)input目錄下有3個(gè)文件a,b,c,大小分別為10m,20m,130m,那么hadoop會(huì)分隔成4個(gè)塊(10m,20m,128m,2m),從而產(chǎn)生4個(gè)map數(shù) 即,如果文件大于塊大小(128m),那么會(huì)拆分,如果小于塊大小,則把該文件當(dāng)成一個(gè)塊。
3.是不是map數(shù)越多越好?
答案是否定的。如果一個(gè)任務(wù)有很多小文件(遠(yuǎn)遠(yuǎn)小于塊大小128m),則每個(gè)小文件也會(huì)被當(dāng)做一個(gè)塊,用一個(gè)map任務(wù)來完成,而一個(gè)map任務(wù)啟動(dòng)和初始化的時(shí)間遠(yuǎn)遠(yuǎn)大于邏輯處理的時(shí)間,就會(huì)造成很大的資源浪費(fèi)。而且,同時(shí)可執(zhí)行的map數(shù)是受限的。
4.是不是保證每個(gè)map處理接近128m的文件塊,就高枕無憂了?
答案也是不一定。比如有一個(gè)127m的文件,正常會(huì)用一個(gè)map去完成,但這個(gè)文件只有一個(gè)或者兩個(gè)小字段,卻有幾千萬(wàn)的記錄,如果map處理的邏輯比較復(fù)雜,用一個(gè)map任務(wù)去做,肯定也比較耗時(shí)。
針對(duì)上面的問題3和4,我們需要采取兩種方式來解決:即減少map數(shù)和增加map數(shù);如何合并小文件,減少map數(shù)?
假設(shè)一個(gè)SQL任務(wù):Select count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' 該任務(wù)的inputdir /group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 共有194個(gè)文件,其中很多是遠(yuǎn)遠(yuǎn)小于128m的小文件,總大小9G,正常執(zhí)行會(huì)用194個(gè)map任務(wù)。Map總共消耗的計(jì)算資源:SLOTS_MILLIS_MAPS= 623,020 通過以下方法來在map執(zhí)行前合并小文件,減少map數(shù):
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;再執(zhí)行上面的語(yǔ)句,用了74個(gè)map任務(wù),map消耗的計(jì)算資源:SLOTS_MILLIS_MAPS=333,500 對(duì)于這個(gè)簡(jiǎn)單SQL任務(wù),執(zhí)行時(shí)間上可能差不多,但節(jié)省了一半的計(jì)算資源。大概解釋一下,100000000表示100M
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
這個(gè)參數(shù)表示執(zhí)行前進(jìn)行小文件合并,前面三個(gè)參數(shù)確定合并文件塊的大小,大于文件塊大小128m的,按照128m來分隔,小于128m,大于100m的,按照100m來分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),進(jìn)行合并,最終生成了74個(gè)塊。
如何適當(dāng)?shù)脑黾觤ap數(shù)?當(dāng)input的文件都很大,任務(wù)邏輯復(fù)雜,map執(zhí)行非常慢的時(shí)候,可以考慮增加Map數(shù), 來使得每個(gè)map處理的數(shù)據(jù)量減少,從而提高任務(wù)的執(zhí)行效率。假設(shè)有這樣一個(gè)任務(wù):
Select data_desc,
count(1),
count(distinct id),
sum(case when …),
sum(case when ...),
sum(…)
from a group by data_desc如果表a只有一個(gè)文件,大小為120M,但包含幾千萬(wàn)的記錄,如果用1個(gè)map去完成這個(gè)任務(wù),肯定是比較耗時(shí)的,這種情況下,我們要考慮將這一個(gè)文件合理的拆分成多個(gè),這樣就可以用多個(gè)map任務(wù)去完成。
set mapred.reduce.tasks=10;
create table a_1 as
select * from a
distribute by rand(123);這樣會(huì)將a表的記錄,隨機(jī)的分散到包含10個(gè)文件的a_1表中,再用a_1代替上面sql中的a表,則會(huì)用10個(gè)map任務(wù)去完成。每個(gè)map任務(wù)處理大于12M(幾百萬(wàn)記錄)的數(shù)據(jù),效率肯定會(huì)好很多。
看上去,貌似這兩種有些矛盾,一個(gè)是要合并小文件,一個(gè)是要把大文件拆成小文件,這點(diǎn)正是重點(diǎn)需要關(guān)注的地方,根據(jù)實(shí)際情況,控制map數(shù)量需要遵循兩個(gè)原則:使大數(shù)據(jù)量利用合適的map數(shù);使單個(gè)map任務(wù)處理合適的數(shù)據(jù)量。
控制hive任務(wù)的reduce數(shù):
1.Hive自己如何確定reduce數(shù):
reduce個(gè)數(shù)的設(shè)定極大影響任務(wù)執(zhí)行效率,不指定reduce個(gè)數(shù)的情況下,Hive會(huì)猜測(cè)確定一個(gè)reduce個(gè)數(shù),基于以下兩個(gè)設(shè)定:hive.exec.reducers.bytes.per.reducer(每個(gè)reduce任務(wù)處理的數(shù)據(jù)量,默認(rèn)為1000^3=1G) hive.exec.reducers.max(每個(gè)任務(wù)最大的reduce數(shù),默認(rèn)為999)
計(jì)算reducer數(shù)的公式很簡(jiǎn)單N=min(參數(shù)2,總輸入數(shù)據(jù)量/參數(shù)1)
即,如果reduce的輸入(map的輸出)總大小不超過1G,那么只會(huì)有一個(gè)reduce任務(wù),如:
select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;
/group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04 總大小為9G多,
因此這句有10個(gè)reduce
2.調(diào)整reduce個(gè)數(shù)方法一:
調(diào)整hive.exec.reducers.bytes.per.reducer參數(shù)的值;set hive.exec.reducers.bytes.per.reducer=500000000; (500M) select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 這次有20個(gè)reduce
3.調(diào)整reduce個(gè)數(shù)方法二
set mapred.reduce.tasks = 15; select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt;這次有15個(gè)reduce
4.reduce個(gè)數(shù)并不是越多越好;
同map一樣,啟動(dòng)和初始化reduce也會(huì)消耗時(shí)間和資源;另外,有多少個(gè)reduce,就會(huì)有多少個(gè)輸出文件,如果生成了很多個(gè)小文件, 那么如果這些小文件作為下一個(gè)任務(wù)的輸入,則也會(huì)出現(xiàn)小文件過多的問題;
5.什么情況下只有一個(gè)reduce;
很多時(shí)候你會(huì)發(fā)現(xiàn)任務(wù)中不管數(shù)據(jù)量多大,不管你有沒有設(shè)置調(diào)整reduce個(gè)數(shù)的參數(shù),任務(wù)中一直都只有一個(gè)reduce任務(wù);其實(shí)只有一個(gè)reduce任務(wù)的情況,除了數(shù)據(jù)量小于hive.exec.reducers.bytes.per.reducer參數(shù)值的情況外,還有以下原因:
a)沒有g(shù)roup by的匯總,比如把select pt,count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04' group by pt; 寫成 select count(1) from popt_tbaccountcopy_mes where pt = '2012-07-04'; 這點(diǎn)非常常見,希望大家盡量改寫。
b)用了Order by
c)有笛卡爾積
通常這些情況下,除了找辦法來變通和避免,我們暫時(shí)沒有什么好的辦法,因?yàn)檫@些操作都是全局的,所以hadoop不得不用一個(gè)reduce去完成。同樣的,在設(shè)置reduce個(gè)數(shù)的時(shí)候也需要考慮這兩個(gè)原則:
使大數(shù)據(jù)量利用合適的reduce數(shù)
使單個(gè)reduce任務(wù)處理合適的數(shù)據(jù)量
Reduce階段優(yōu)化
調(diào)整方式:
set mapred.reduce.tasks=?
set hive.exec.reducers.bytes.per.reducer = ?
一般根據(jù)輸入文件的總大小,用它的estimation函數(shù)來自動(dòng)計(jì)算reduce的個(gè)數(shù):reduce個(gè)數(shù) = InputFileSize / bytes per reducer
7.JVM重用
用于避免小文件的場(chǎng)景或者task特別多的場(chǎng)景,這類場(chǎng)景大多數(shù)執(zhí)行時(shí)間都很短,因?yàn)閔ive調(diào)起mapreduce任務(wù),JVM的啟動(dòng)過程會(huì)造成很大的開銷,尤其是job有成千上萬(wàn)個(gè)task任務(wù)時(shí),JVM重用可以使得JVM實(shí)例在同一個(gè)job中重新使用N次
set mapred.job.reuse.jvm.num.tasks=10; --10為重用個(gè)數(shù)
8.動(dòng)態(tài)分區(qū)調(diào)整
動(dòng)態(tài)分區(qū)屬性:設(shè)置為true表示開啟動(dòng)態(tài)分區(qū)功能(默認(rèn)為false)
hive.exec.dynamic.partition=true;
動(dòng)態(tài)分區(qū)屬性:設(shè)置為nonstrict,表示允許所有分區(qū)都是動(dòng)態(tài)的(默認(rèn)為strict) 設(shè)置為strict,表示必須保證至少有一個(gè)分區(qū)是靜態(tài)的
hive.exec.dynamic.partition.mode=strict;
動(dòng)態(tài)分區(qū)屬性:每個(gè)mapper或reducer可以創(chuàng)建的最大動(dòng)態(tài)分區(qū)個(gè)數(shù)
hive.exec.max.dynamic.partitions.pernode=100;
動(dòng)態(tài)分區(qū)屬性:一個(gè)動(dòng)態(tài)分區(qū)創(chuàng)建語(yǔ)句可以創(chuàng)建的最大動(dòng)態(tài)分區(qū)個(gè)數(shù)
hive.exec.max.dynamic.partitions=1000;
動(dòng)態(tài)分區(qū)屬性:全局可以創(chuàng)建的最大文件個(gè)數(shù)
hive.exec.max.created.files=100000;
控制DataNode一次可以打開的文件個(gè)數(shù) 這個(gè)參數(shù)必須設(shè)置在DataNode的$HADOOP_HOME/conf/hdfs-site.xml文件中
dfs.datanode.max.xcievers
8192
9.推測(cè)執(zhí)行
目的:是通過加快獲取單個(gè)task的結(jié)果以及進(jìn)行偵測(cè)將執(zhí)行慢的TaskTracker加入到黑名單的方式來提高整體的任務(wù)執(zhí)行效率
(1)修改 $HADOOP_HOME/conf/mapred-site.xml文件
mapred.map.tasks.speculative.execution
true
mapred.reduce.tasks.speculative.execution
true
(2)修改hive配置
set hive.mapred.reduce.tasks.speculative.execution=true;
10.數(shù)據(jù)傾斜
表現(xiàn):任務(wù)進(jìn)度長(zhǎng)時(shí)間維持在99%(或100%),查看任務(wù)監(jiān)控頁(yè)面,發(fā)現(xiàn)只有少量(1個(gè)或幾個(gè))reduce子任務(wù)未完成。因?yàn)槠涮幚淼臄?shù)據(jù)量和其他reduce差異過大。單一reduce的記錄數(shù)與平均記錄數(shù)差異過大,通常可能達(dá)到3倍甚至更多。最長(zhǎng)時(shí)長(zhǎng)遠(yuǎn)大于平均時(shí)長(zhǎng)。
原因
1)、key分布不均勻
2)、業(yè)務(wù)數(shù)據(jù)本身的特性
3)、建表時(shí)考慮不周
4)、某些SQL語(yǔ)句本身就有數(shù)據(jù)傾斜
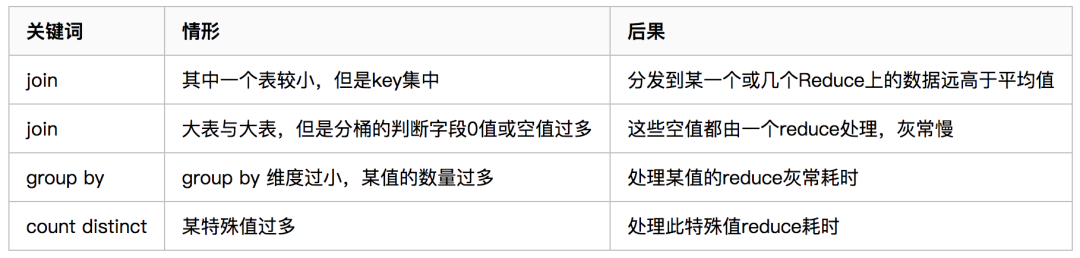
解決方案:參數(shù)調(diào)節(jié)
hive.map.aggr=true
11. 其他參數(shù)調(diào)優(yōu)
開啟CLI提示符前打印出當(dāng)前所在的數(shù)據(jù)庫(kù)名
set hive.cli.print.current.db=true;
讓CLI打印出字段名稱
hive.cli.print.header=true;
設(shè)置任務(wù)名稱,方便查找監(jiān)控
SET mapred.job.name=P_DWA_D_IA_S_USER_PROD;
決定是否可以在 Map 端進(jìn)行聚合操作
set hive.map.aggr=true;
有數(shù)據(jù)傾斜的時(shí)候進(jìn)行負(fù)載均衡
set hive.groupby.skewindata=true;
對(duì)于簡(jiǎn)單的不需要聚合的類似SELECT col from table LIMIT n語(yǔ)句,不需要起MapReduce job,直接通過Fetch task獲取數(shù)據(jù)
set hive.fetch.task.conversion=more;
12、小文件問題
小文件是如何產(chǎn)生的
1.動(dòng)態(tài)分區(qū)插入數(shù)據(jù),產(chǎn)生大量的小文件,從而導(dǎo)致map數(shù)量劇增。
2.reduce數(shù)量越多,小文件也越多(reduce的個(gè)數(shù)和輸出文件是對(duì)應(yīng)的)。
3.數(shù)據(jù)源本身就包含大量的小文件。
小文件問題的影響
1.從Hive的角度看,小文件會(huì)開很多map,一個(gè)map開一個(gè)JVM去執(zhí)行,所以這些任務(wù)的初始化,啟動(dòng),執(zhí)行會(huì)浪費(fèi)大量的資源,嚴(yán)重影響性能。
2.在HDFS中,每個(gè)小文件對(duì)象約占150byte,如果小文件過多會(huì)占用大量?jī)?nèi)存。這樣NameNode內(nèi)存容量嚴(yán)重制約了集群的擴(kuò)展。
小文件問題的解決方案
從小文件產(chǎn)生的途經(jīng)就可以從源頭上控制小文件數(shù)量,方法如下:
1.使用Sequencefile作為表存儲(chǔ)格式,不要用textfile,在一定程度上可以減少小文件
2.減少reduce的數(shù)量(可以使用參數(shù)進(jìn)行控制)
3.少用動(dòng)態(tài)分區(qū),用時(shí)記得按distribute by分區(qū)
對(duì)于已有的小文件,我們可以通過以下幾種方案解決:
1.使用hadoop archive命令把小文件進(jìn)行歸檔
2.重建表,建表時(shí)減少reduce數(shù)量
3.通過參數(shù)進(jìn)行調(diào)節(jié),設(shè)置map/reduce端的相關(guān)參數(shù),如下:
設(shè)置map輸入合并小文件的相關(guān)參數(shù):
//每個(gè)Map最大輸入大小(這個(gè)值決定了合并后文件的數(shù)量)
set mapred.max.split.size=256000000;
//一個(gè)節(jié)點(diǎn)上split的至少的大小(這個(gè)值決定了多個(gè)DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一個(gè)交換機(jī)下split的至少的大小(這個(gè)值決定了多個(gè)交換機(jī)上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//執(zhí)行Map前進(jìn)行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;設(shè)置map輸出和reduce輸出進(jìn)行合并的相關(guān)參數(shù):
//設(shè)置map端輸出進(jìn)行合并,默認(rèn)為true
set hive.merge.mapfiles = true
//設(shè)置reduce端輸出進(jìn)行合并,默認(rèn)為false
set hive.merge.mapredfiles = true
//設(shè)置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//當(dāng)輸出文件的平均大小小于該值時(shí),啟動(dòng)一個(gè)獨(dú)立的MapReduce任務(wù)進(jìn)行文件merge。
set hive.merge.smallfiles.avgsize=16000000設(shè)置如下參數(shù)取消一些限制(HIVE 0.7后沒有此限制):
hive.merge.mapfiles=false
默認(rèn)值:true 描述:是否合并Map的輸出文件,也就是把小文件合并成一個(gè)map
hive.merge.mapredfiles=false
默認(rèn)值:false 描述:是否合并Reduce的輸出文件,也就是在Map輸出階段做一次reduce操作,再輸出.
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
這個(gè)參數(shù)表示執(zhí)行前進(jìn)行小文件合并,
前面三個(gè)參數(shù)確定合并文件塊的大小,大于文件塊大小128m的,按照128m來分隔,小于128m,大于100m的,按照100m來分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),進(jìn)行合并,最終生成了74個(gè)塊。


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??