
Hive參數(shù)與性能企業(yè)級調(diào)優(yōu)(建議收藏)
Hive作為大數(shù)據(jù)平臺舉足輕重的框架,以其穩(wěn)定性和簡單易用性也成為當(dāng)前構(gòu)建企業(yè)級數(shù)據(jù)倉庫時(shí)使用最多的框架之一。
但是如果我們只局限于會(huì)使用Hive,而不考慮性能問題,就難搭建出一個(gè)完美的數(shù)倉,所以Hive性能調(diào)優(yōu)是我們大數(shù)據(jù)從業(yè)者必須掌握的技能。本文將給大家講解Hive性能調(diào)優(yōu)的一些方法及技巧。
Hive性能調(diào)優(yōu)的方式
為什么都說性能優(yōu)化這項(xiàng)工作是比較難的,因?yàn)橐豁?xiàng)技術(shù)的優(yōu)化,必然是一項(xiàng)綜合性的工作,它是多門技術(shù)的結(jié)合。我們?nèi)绻痪窒抻谝环N技術(shù),那么肯定做不好優(yōu)化的。
下面將從多個(gè)完全不同的角度來介紹Hive優(yōu)化的多樣性,我們先來一起感受下。
1. SQL語句優(yōu)化
SQL語句優(yōu)化涉及到的內(nèi)容太多,因篇幅有限,不能一一介紹到,所以就拿幾個(gè)典型舉例,讓大家學(xué)到這種思想,以后遇到類似調(diào)優(yōu)問題可以往這幾個(gè)方面多思考下。
1. union all
insert?into?table?stu?partition(tp)?
select?s_age,max(s_birth)?stat,'max'?tp?
from?stu_ori
group?by?s_age
union?all
insert?into?table?stu?partition(tp)?
select?s_age,min(s_birth)?stat,'min'?tp?
from?stu_ori
group?by?s_age;
我們簡單分析上面的SQl語句,就是將每個(gè)年齡的最大和最小的生日獲取出來放到同一張表中,union all 前后的兩個(gè)語句都是對同一張表按照s_age進(jìn)行分組,然后分別取最大值和最小值。對同一張表相同的字段進(jìn)行兩次分組,這造成了極大浪費(fèi),我們能不能改造下呢,當(dāng)然是可以的,為大家介紹一個(gè)語法:from ... insert into ... ,這個(gè)語法將from前置,作用就是使用一張表,可以進(jìn)行多次插入操作:
--開啟動(dòng)態(tài)分區(qū)?
set?hive.exec.dynamic.partition=true;?
set?hive.exec.dynamic.partition.mode=nonstrict;?
from?stu_ori?
insert?into?table?stu?partition(tp)?
select?s_age,max(s_birth)?stat,'max'?tp?
group?by?s_age
insert?into?table?stu?partition(tp)?
select?s_age,min(s_birth)?stat,'min'?tp?
group?by?s_age;
上面的SQL就可以對stu_ori表的s_age字段分組一次而進(jìn)行兩次不同的插入操作。
這個(gè)例子告訴我們一定要多了解SQL語句,如果我們不知道這種語法,一定不會(huì)想到這種方式的。
2. distinct
先看一個(gè)SQL,去重計(jì)數(shù):
select?count(1)?
from(?
??select?s_age?
??from?stu?
??group?by?s_age?
)?b;
這是簡單統(tǒng)計(jì)年齡的枚舉值個(gè)數(shù),為什么不用distinct?
select?count(distinct?s_age)?
from?stu;
有人說因?yàn)樵跀?shù)據(jù)量特別大的情況下使用第一種方式能夠有效避免Reduce端的數(shù)據(jù)傾斜,但是事實(shí)如此嗎?
我們先不管數(shù)據(jù)量特別大這個(gè)問題,就當(dāng)前的業(yè)務(wù)和環(huán)境下使用distinct一定會(huì)比上面那種子查詢的方式效率高。原因有以下幾點(diǎn):
上面進(jìn)行去重的字段是年齡字段,要知道年齡的枚舉值是非常有限的,就算計(jì)算1歲到100歲之間的年齡,s_age的最大枚舉值才是100,如果轉(zhuǎn)化成MapReduce來解釋的話,在Map階段,每個(gè)Map會(huì)對s_age去重。由于s_age枚舉值有限,因而每個(gè)Map得到的s_age也有限,最終得到reduce的數(shù)據(jù)量也就是map數(shù)量*s_age枚舉值的個(gè)數(shù)。
distinct的命令會(huì)在內(nèi)存中構(gòu)建一個(gè)hashtable,查找去重的時(shí)間復(fù)雜度是O(1);group by在不同版本間變動(dòng)比較大,有的版本會(huì)用構(gòu)建hashtable的形式去重,有的版本會(huì)通過排序的方式, 排序最優(yōu)時(shí)間復(fù)雜度無法到O(1)。另外,第一種方式(group by)去重會(huì)轉(zhuǎn)化為兩個(gè)任務(wù),會(huì)消耗更多的磁盤網(wǎng)絡(luò)I/O資源。
最新的Hive 3.0中新增了 count(distinct ) 優(yōu)化,通過配置
hive.optimize.countdistinct,即使真的出現(xiàn)數(shù)據(jù)傾斜也可以自動(dòng)優(yōu)化,自動(dòng)改變SQL執(zhí)行的邏輯。第二種方式(distinct)比第一種方式(group by)代碼簡潔,表達(dá)的意思簡單明了,如果沒有特殊的問題,代碼簡潔就是優(yōu)!
這個(gè)例子告訴我們,有時(shí)候我們不要過度優(yōu)化,調(diào)優(yōu)講究適時(shí)調(diào)優(yōu),過早進(jìn)行調(diào)優(yōu)有可能做的是無用功甚至產(chǎn)生負(fù)效應(yīng),在調(diào)優(yōu)上投入的工作成本和回報(bào)不成正比。調(diào)優(yōu)需要遵循一定的原則。
2. 數(shù)據(jù)格式優(yōu)化
Hive提供了多種數(shù)據(jù)存儲組織格式,不同格式對程序的運(yùn)行效率也會(huì)有極大的影響。
Hive提供的格式有TEXT、SequenceFile、RCFile、ORC和Parquet等。
SequenceFile是一個(gè)二進(jìn)制key/value對結(jié)構(gòu)的平面文件,在早期的Hadoop平臺上被廣泛用于MapReduce輸出/輸出格式,以及作為數(shù)據(jù)存儲格式。
Parquet是一種列式數(shù)據(jù)存儲格式,可以兼容多種計(jì)算引擎,如MapRedcue和Spark等,對多層嵌套的數(shù)據(jù)結(jié)構(gòu)提供了良好的性能支持,是目前Hive生產(chǎn)環(huán)境中數(shù)據(jù)存儲的主流選擇之一。
ORC優(yōu)化是對RCFile的一種優(yōu)化,它提供了一種高效的方式來存儲Hive數(shù)據(jù),同時(shí)也能夠提高Hive的讀取、寫入和處理數(shù)據(jù)的性能,能夠兼容多種計(jì)算引擎。事實(shí)上,在實(shí)際的生產(chǎn)環(huán)境中,ORC已經(jīng)成為了Hive在數(shù)據(jù)存儲上的主流選擇之一。
我們使用同樣數(shù)據(jù)及SQL語句,只是數(shù)據(jù)存儲格式不同,得到如下執(zhí)行時(shí)長:
| 數(shù)據(jù)格式 | CPU時(shí)間 | 用戶等待耗時(shí) |
|---|---|---|
| TextFile | 33分 | 171秒 |
| SequenceFile | 38分 | 162秒 |
| Parquet | 2分22秒 | 50秒 |
| ORC | 1分52秒 | 56秒 |
注:CPU時(shí)間:表示運(yùn)行程序所占用服務(wù)器CPU資源的時(shí)間。
用戶等待耗時(shí):記錄的是用戶從提交作業(yè)到返回結(jié)果期間用戶等待的所有時(shí)間。
查詢TextFile類型的數(shù)據(jù)表CPU耗時(shí)33分鐘, 查詢ORC類型的表耗時(shí)1分52秒,時(shí)間得以極大縮短,可見不同的數(shù)據(jù)存儲格式也能給HiveSQL性能帶來極大的影響。
3. 小文件過多優(yōu)化
小文件如果過多,對 hive 來說,在進(jìn)行查詢時(shí),每個(gè)小文件都會(huì)當(dāng)成一個(gè)塊,啟動(dòng)一個(gè)Map任務(wù)來完成,而一個(gè)Map任務(wù)啟動(dòng)和初始化的時(shí)間遠(yuǎn)遠(yuǎn)大于邏輯處理的時(shí)間,就會(huì)造成很大的資源浪費(fèi)。而且,同時(shí)可執(zhí)行的Map數(shù)量是受限的。
所以我們有必要對小文件過多進(jìn)行優(yōu)化,關(guān)于小文件過多的解決的辦法,我之前專門寫了一篇文章講解,具體可查看:
4. 并行執(zhí)行優(yōu)化
Hive會(huì)將一個(gè)查詢轉(zhuǎn)化成一個(gè)或者多個(gè)階段。這樣的階段可以是MapReduce階段、抽樣階段、合并階段、limit階段。或者Hive執(zhí)行過程中可能需要的其他階段。默認(rèn)情況下,Hive一次只會(huì)執(zhí)行一個(gè)階段。不過,某個(gè)特定的job可能包含眾多的階段,而這些階段可能并非完全互相依賴的,也就是說有些階段是可以并行執(zhí)行的,這樣可能使得整個(gè)job的執(zhí)行時(shí)間縮短。如果有更多的階段可以并行執(zhí)行,那么job可能就越快完成。
通過設(shè)置參數(shù)hive.exec.parallel值為true,就可以開啟并發(fā)執(zhí)行。在共享集群中,需要注意下,如果job中并行階段增多,那么集群利用率就會(huì)增加。
set?hive.exec.parallel=true;?//打開任務(wù)并行執(zhí)行
set?hive.exec.parallel.thread.number=16;?//同一個(gè)sql允許最大并行度,默認(rèn)為8。
當(dāng)然得是在系統(tǒng)資源比較空閑的時(shí)候才有優(yōu)勢,否則沒資源,并行也起不來。
5. 數(shù)據(jù)傾斜優(yōu)化
數(shù)據(jù)傾斜的原理都知道,就是某一個(gè)或幾個(gè)key占據(jù)了整個(gè)數(shù)據(jù)的90%,這樣整個(gè)任務(wù)的效率都會(huì)被這個(gè)key的處理拖慢,同時(shí)也可能會(huì)因?yàn)橄嗤膋ey會(huì)聚合到一起造成內(nèi)存溢出。
Hive的數(shù)據(jù)傾斜一般的處理方案:
常見的做法,通過參數(shù)調(diào)優(yōu):
set?hive.map.aggr=true;??
set?hive.groupby.skewindata?=?ture;
當(dāng)選項(xiàng)設(shè)定為true時(shí),生成的查詢計(jì)劃有兩個(gè)MapReduce任務(wù)。
在第一個(gè)MapReduce中,map的輸出結(jié)果集合會(huì)隨機(jī)分布到reduce中,每個(gè)reduce做部分聚合操作,并輸出結(jié)果。
這樣處理的結(jié)果是,相同的Group By Key有可能分發(fā)到不同的reduce中,從而達(dá)到負(fù)載均衡的目的;
第二個(gè)MapReduce任務(wù)再根據(jù)預(yù)處理的數(shù)據(jù)結(jié)果按照Group By Key分布到reduce中(這個(gè)過程可以保證相同的Group By Key分布到同一個(gè)reduce中),最后完成最終的聚合操作。
但是這個(gè)處理方案對于我們來說是個(gè)黑盒,無法把控。
那么在日常需求的情況下如何處理這種數(shù)據(jù)傾斜的情況呢:
sample采樣,獲取哪些集中的key;
將集中的key按照一定規(guī)則添加隨機(jī)數(shù);
進(jìn)行join,由于打散了,所以數(shù)據(jù)傾斜避免了;
在處理結(jié)果中對之前的添加的隨機(jī)數(shù)進(jìn)行切分,變成原始的數(shù)據(jù)。
例:如發(fā)現(xiàn)有90%的key都是null,數(shù)據(jù)量一旦過大必然出現(xiàn)數(shù)據(jù)傾斜,可采用如下方式:
SELECT?*
FROM?a
?LEFT?JOIN?b?ON?CASE?
???WHEN?a.user_id?IS?NULL?THEN?concat('hive_',?rand())
???ELSE?a.user_id
??END?=?b.user_id;
注意:給null值隨機(jī)賦的值不要與表中已有的值重復(fù),不然會(huì)導(dǎo)致結(jié)果錯(cuò)誤。
6. Limit 限制調(diào)整優(yōu)化
一般情況下,Limit語句還是需要執(zhí)行整個(gè)查詢語句,然后再返回部分結(jié)果。
有一個(gè)配置屬性可以開啟,避免這種情況:對數(shù)據(jù)源進(jìn)行抽樣。
hive.limit.optimize.enable=true -- 開啟對數(shù)據(jù)源進(jìn)行采樣的功能
hive.limit.row.max.size -- 設(shè)置最小的采樣容量
hive.limit.optimize.limit.file -- 設(shè)置最大的采樣樣本數(shù)
缺點(diǎn):有可能部分?jǐn)?shù)據(jù)永遠(yuǎn)不會(huì)被處理到
7. JOIN優(yōu)化
1. 使用相同的連接鍵
當(dāng)對3個(gè)或者更多個(gè)表進(jìn)行join連接時(shí),如果每個(gè)on子句都使用相同的連接鍵的話,那么只會(huì)產(chǎn)生一個(gè)MapReduce job。
2. 盡量盡早地過濾數(shù)據(jù)
減少每個(gè)階段的數(shù)據(jù)量,對于分區(qū)表要加分區(qū),同時(shí)只選擇需要使用到的字段。
3. 盡量原子化操作
盡量避免一個(gè)SQL包含復(fù)雜邏輯,可以使用中間表來完成復(fù)雜的邏輯。
8. 謂詞下推優(yōu)化
Hive中的 Predicate Pushdown 簡稱謂詞下推,簡而言之,就是在不影響結(jié)果的情況下,盡量將過濾條件下推到j(luò)oin之前進(jìn)行。謂詞下推后,過濾條件在map端執(zhí)行,減少了map端的輸出,降低了數(shù)據(jù)在集群上傳輸?shù)牧浚?jié)約了集群的資源,也提升了任務(wù)的性能。
我們看下面這個(gè)語句:
select?s1.key,?s2.key?
from?s1?left?join?s2?
on?s1.key?>?'2';
上面是一個(gè)Left Join語句,s1是左表,稱為保留行表,s2是右表。
問:on條件的s1.key > '2' 是在join之前執(zhí)行還是之后?也就是會(huì)不會(huì)進(jìn)行謂詞下推?
答:不會(huì)進(jìn)行謂詞下推,因?yàn)閟1是保留行表,過濾條件會(huì)在join之后執(zhí)行。
而下面這個(gè)語句:
select?s1.key,?s2.key?
from?s1?left?join?s2?
on?s2.key?>?'2';
s2表不是保留行,所以s2.key>2條件可以下推到s2表中,也就是join之前執(zhí)行。
再看下面這個(gè)語句:
select?s1.key,?s2.key?
from?s1?left?join?s2?
where?s1.key?>?'2';
右表s2為NULL補(bǔ)充表。
s1不是NULL補(bǔ)充表,所以s1.key>2可以進(jìn)行謂詞下推。
而下面語句:
select?s1.key,?s2.key?
from?s1?left?join?s2?
where?s2.key?>?'2';
由于s2為NULL補(bǔ)充表,所以s2.key>2過濾條件不能下推。
那么謂詞下推的規(guī)則是什么,到底什么時(shí)候會(huì)進(jìn)行下推,什么時(shí)候不會(huì)下推,總結(jié)了下面的一張表,建議收藏保存:
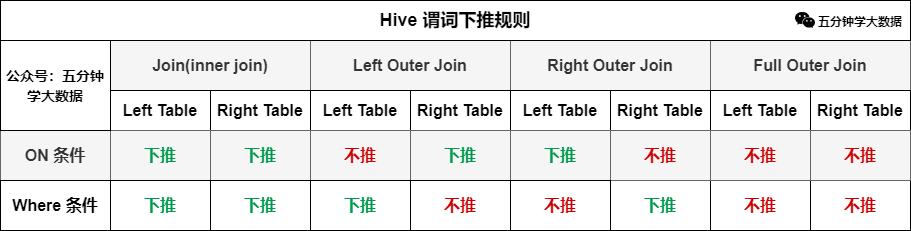
案例:
select?a.*??
from?a??
left?join?b?on??a.uid?=?b.uid??
where?a.ds='2020-08-10'??
and?b.ds='2020-08-10'
上面這個(gè)SQL主要犯了兩個(gè)錯(cuò)誤:
右表(上方b表)的where條件寫在join后面,會(huì)導(dǎo)致先全表關(guān)聯(lián)在過濾分區(qū)。
注:雖然a表的where條件也寫在join后面,但是a表會(huì)進(jìn)行謂詞下推,也就是先執(zhí)行where條件,再執(zhí)行join,但是b表不會(huì)進(jìn)行謂詞下推!
on的條件沒有過濾null值的情況,如果兩個(gè)數(shù)據(jù)表存在大批量null值的情況,會(huì)造成數(shù)據(jù)傾斜。
最后
代碼優(yōu)化原則:
理透需求原則,這是優(yōu)化的根本; 把握數(shù)據(jù)全鏈路原則,這是優(yōu)化的脈絡(luò); 堅(jiān)持代碼的簡潔原則,這讓優(yōu)化更加簡單; 沒有瓶頸時(shí)談?wù)搩?yōu)化,這是自尋煩惱。