
精選30道MySQL數(shù)據(jù)庫面試題!
點(diǎn)擊“程序員面試吧”,選擇“星標(biāo)??”
點(diǎn)擊文末“閱讀原文”解鎖資料
數(shù)據(jù)庫分為關(guān)系型數(shù)據(jù)庫和非關(guān)系型數(shù)據(jù)庫,也就是我們常說的 SQL 和 NoSQL,這兩個(gè)方向的數(shù)據(jù)庫代表產(chǎn)品分別是MySQL 和 Redis ,這次我們主要以面試問答的形式,來學(xué)習(xí)下關(guān)系型數(shù)據(jù)庫 MySQL 基礎(chǔ)知識(shí)。
面試開始,準(zhǔn)備接受面試官靈魂拷問吧!
關(guān)系型數(shù)據(jù)庫
什么是關(guān)系型數(shù)據(jù)庫?
關(guān)系型數(shù)據(jù)庫,是指采用了關(guān)系模型來組織數(shù)據(jù)的數(shù)據(jù)庫,其以行和列的形式存儲(chǔ)數(shù)據(jù),以便于用戶理解,關(guān)系型數(shù)據(jù)庫這一系列的行和列被稱為表,一組表組成了數(shù)據(jù)庫。用戶通過查詢來檢索數(shù)據(jù)庫中的數(shù)據(jù),而查詢是一個(gè)用于限定數(shù)據(jù)庫中某些區(qū)域的執(zhí)行代碼。
簡單來說,關(guān)系模式就是二維表格模型。

關(guān)系型數(shù)據(jù)庫有什么優(yōu)勢?
關(guān)系型數(shù)據(jù)庫的優(yōu)勢:
易于理解
關(guān)系型二維表的結(jié)構(gòu)非常貼近現(xiàn)實(shí)世界,二維表格,容易理解。
支持復(fù)雜查詢 可以用 SQL 語句方便的在一個(gè)表以及多個(gè)表之間做非常復(fù)雜的數(shù)據(jù)查詢。
支持事務(wù) 可靠的處理事務(wù)并且保持事務(wù)的完整性,使得對于安全性能很高的數(shù)據(jù)訪問要求得以實(shí)現(xiàn)。
MySQL數(shù)據(jù)庫
什么是SQL
結(jié)構(gòu)化查詢語言 (Structured Query Language) 簡稱SQL,是一種特殊目的的編程語言,是一種數(shù)據(jù)庫查詢和程序設(shè)計(jì)語言程序設(shè)計(jì)語言,用于存取數(shù)據(jù)以及查詢、更新和管理關(guān)系數(shù)據(jù)庫系統(tǒng)。
什么是MySQL?
MySQL 是一個(gè)關(guān)系型數(shù)據(jù)庫管理系統(tǒng),MySQL 是最流行的關(guān)系型數(shù)據(jù)庫管理系統(tǒng)之一,常見的關(guān)系型數(shù)據(jù)庫還有 Oracle 、SQL Server、Access 等等。
MySQL在過去由于性能高、成本低、可靠性好,已經(jīng)成為最流行的開源數(shù)據(jù)庫,廣泛地應(yīng)用在 Internet 上的中小型網(wǎng)站中。

MySQL 和 MariaDB 傻傻分不清楚?
MySQL 最初由瑞典 MySQL AB 公司開發(fā),MySQL 的創(chuàng)始人是烏爾夫·米卡埃爾·維德紐斯,常用昵稱蒙提(Monty)。
在被甲骨文公司收購后,現(xiàn)在屬于甲骨文公司(Oracle) 旗下產(chǎn)品。Oracle 大幅調(diào)漲MySQL商業(yè)版的售價(jià),因此導(dǎo)致自由軟件社區(qū)們對于Oracle是否還會(huì)持續(xù)支持MySQL社區(qū)版有所隱憂。
MySQL 的創(chuàng)始人就是之前那個(gè)叫 Monty 的大佬以 MySQL為基礎(chǔ)成立分支計(jì)劃 MariaDB。
MariaDB打算保持與MySQL的高度兼容性,確保具有庫二進(jìn)制奇偶校驗(yàn)的直接替換功能,以及與MySQL API 應(yīng)用程序接口)和命令的精確匹配。而原先一些使用 MySQL 的開源軟件逐漸轉(zhuǎn)向 MariaDB 或其它的數(shù)據(jù)庫。
所以如果看到你公司用的是 MariaDB 不用懷疑,其實(shí)它骨子里還是 MySQL,學(xué)會(huì)了MySQL 也就會(huì)了 MariaDB。
一個(gè)彩蛋
MariaDB 是以 Monty 的小女兒Maria命名的,就像MySQL是以他另一個(gè)女兒 My 命名的一樣,兩款鼎鼎大名的數(shù)據(jù)庫分別用兩個(gè)女兒的名字命名,你大爺還是你大爺,老爺子牛批!

如何查看MySQL當(dāng)前版本號(hào)?
在系統(tǒng)命令行下:mysql -V
連接上MySQL命令行輸入:
> status;
Server: MySQL
Server version: 5.5.45
Protocol version: 10
或 select version();
+------------------------+
| version() |
+------------------------+
| 5.5.45-xxxxx |
+------------------------+
基礎(chǔ)數(shù)據(jù)類型
MySQL 有哪些數(shù)據(jù)類型?
MySQL 數(shù)據(jù)類型非常豐富,常用類型簡單介紹如下:
整數(shù)類型:BIT、BOOL、TINY INT、SMALL INT、MEDIUM INT、 INT、 BIG INT
浮點(diǎn)數(shù)類型:FLOAT、DOUBLE、DECIMAL
字符串類型:CHAR、VARCHAR、TINY TEXT、TEXT、MEDIUM TEXT、LONGTEXT、TINY BLOB、BLOB、MEDIUM BLOB、LONG BLOB
日期類型:Date、DateTime、TimeStamp、Time、Year
其他數(shù)據(jù)類型:BINARY、VARBINARY、ENUM、SET...
CHAR 和 VARCHAR的區(qū)別?
CHAR 是固定長度的字符類型,VARCHAR 則是可變長度的字符類型,下面討論基于在 MySQL5.0 以上版本中。
共同點(diǎn)
CHAR(M) 和 VARCHAR(M) 都表示該列能存儲(chǔ) M 個(gè)字符,注意不是字節(jié)!!
CHAR類型特點(diǎn)
CHAR 最多可以存儲(chǔ) 255 個(gè)字符 (注意不是字節(jié)),字符有不同的編碼集,比如 UTF8 編碼 (3字節(jié))、GBK 編碼 (2字節(jié)) 等。 對于 CHAR(M)如果實(shí)際存儲(chǔ)的數(shù)據(jù)長度小于M,則 MySQL 會(huì)自動(dòng)會(huì)在它的右邊用空格字符補(bǔ)足,但是在檢索操作中那些填補(bǔ)出來的空格字符會(huì)被去掉。
VARCHAR類型特點(diǎn)
VARCHAR 的最大長度為 65535 個(gè)字節(jié)。 VARCHAR 存儲(chǔ)的是實(shí)際的字符串加1或2個(gè)字節(jié)用來記錄字符串實(shí)際長度,字符串長度小于255字節(jié)用1字節(jié)記錄,超過255就需要2字節(jié)記錄。[^12 ]
VARCHAR(50) 能存放幾個(gè) UTF8 編碼的漢字?
存放的漢字個(gè)數(shù)與版本相關(guān)。
mysql 4.0以下版本,varchar(50) 指的是 50 字節(jié),如果存放 UTF8 格式編碼的漢字時(shí)(每個(gè)漢字3字節(jié)),只能存放16 個(gè)。
mysql 5.0以上版本,varchar(50) 指的是 50 字符,無論存放的是數(shù)字、字母還是 UTF8 編碼的漢字,都可以存放 50 個(gè)。
int(10) 和 bigint(10)能存儲(chǔ)的數(shù)據(jù)大小一樣嗎?
不一樣,具體原因如下:
int 能存儲(chǔ)四字節(jié)有符號(hào)整數(shù)。 bigint 能存儲(chǔ)八字節(jié)有符號(hào)整數(shù)。
所以能存儲(chǔ)的數(shù)據(jù)大小不一樣,其中的數(shù)字 10 代表的只是數(shù)據(jù)的顯示寬度。[^13]
顯示寬度指明Mysql最大可能顯示的數(shù)字個(gè)數(shù),數(shù)值的位數(shù)小于指定的寬度時(shí)數(shù)字左邊會(huì)用空格填充,空格不容易看出。 如果插入了大于顯示寬度的值,只要該值不超過該類型的取值范圍,數(shù)值依然可以插入且能夠顯示出來。 建表的時(shí)候指定 zerofill選項(xiàng),則不足顯示寬度的部分用0填充,如果是 1 會(huì)顯示成0000000001。如果沒指定顯示寬度, bigint 默認(rèn)寬度是 20 ,int默認(rèn)寬度 11。
存儲(chǔ)引擎相關(guān)
MySQL存儲(chǔ)引擎類型有哪些?
常用的存儲(chǔ)引擎有 InnoDB 存儲(chǔ)引擎和 MyISAM 存儲(chǔ)引擎,InnoDB 是 MySQL 的默認(rèn)事務(wù)引擎。
查看數(shù)據(jù)庫表當(dāng)前支持的引擎,可以用下面查詢語句查看 :
# 查詢結(jié)果表中的 Engine 字段指示存儲(chǔ)引擎類型。
show table status from 'your_db_name' where name='your_table_name';
InnoDB存儲(chǔ)引擎應(yīng)用場景是什么?
InnoDB 是 MySQL的默認(rèn)「事務(wù)引擎」,被設(shè)置用來處理大量短期(short-lived)事務(wù),短期事務(wù)大部分情況是正常提交的,很少會(huì)回滾。
InnoDB存儲(chǔ)引擎特性有哪些?
采用多版本并發(fā)控制(MVCC,MultiVersion Concurrency Control)來支持高并發(fā)。并且實(shí)現(xiàn)了四個(gè)標(biāo)準(zhǔn)的隔離級(jí)別,通過間隙鎖next-key locking策略防止幻讀的出現(xiàn)。
引擎的表基于聚簇索引建立,聚簇索引對主鍵查詢有很高的性能。不過它的二級(jí)索引secondary index非主鍵索引中必須包含主鍵列,所以如果主鍵列很大的話,其他的所有索引都會(huì)很大。因此,若表上的索引較多的話,主鍵應(yīng)當(dāng)盡可能的小。另外InnoDB的存儲(chǔ)格式是平臺(tái)獨(dú)立。
InnoDB做了很多優(yōu)化,比如:磁盤讀取數(shù)據(jù)方式采用的可預(yù)測性預(yù)讀、自動(dòng)在內(nèi)存中創(chuàng)建hash索引以加速讀操作的自適應(yīng)哈希索引(adaptive hash index),以及能夠加速插入操作的插入緩沖區(qū)(insert buffer)等。
InnoDB通過一些機(jī)制和工具支持真正的熱備份,MySQL 的其他存儲(chǔ)引擎不支持熱備份,要獲取一致性視圖需要停止對所有表的寫入,而在讀寫混合場景中,停止寫入可能也意味著停止讀取。
InnoDB 引擎的四大特性是什么?
插入緩沖(Insert buffer)
Insert Buffer 用于非聚集索引的插入和更新操作。先判斷插入的非聚集索引是否在緩存池中,如果在則直接插入,否則插入到 Insert Buffer 對象里。再以一定的頻率進(jìn)行 Insert Buffer 和輔助索引葉子節(jié)點(diǎn)的 merge 操作,將多次插入合并到一個(gè)操作中,提高對非聚集索引的插入性能。
二次寫 (Double write)
Double Write由兩部分組成,一部分是內(nèi)存中的double write buffer,大小為2MB,另一部分是物理磁盤上共享表空間連續(xù)的128個(gè)頁,大小也為 2MB。在對緩沖池的臟頁進(jìn)行刷新時(shí),并不直接寫磁盤,而是通過 memcpy 函數(shù)將臟頁先復(fù)制到內(nèi)存中的該區(qū)域,之后通過doublewrite buffer再分兩次,每次1MB順序地寫入共享表空間的物理磁盤上,然后馬上調(diào)用fsync函數(shù),同步磁盤,避免操作系統(tǒng)緩沖寫帶來的問題。
自適應(yīng)哈希索引 (Adaptive Hash Index)
InnoDB會(huì)根據(jù)訪問的頻率和模式,為熱點(diǎn)頁建立哈希索引,來提高查詢效率。索引通過緩存池的 B+ 樹頁構(gòu)造而來,因此建立速度很快,InnoDB存儲(chǔ)引擎會(huì)監(jiān)控對表上各個(gè)索引頁的查詢,如果觀察到建立哈希索引可以帶來速度上的提升,則建立哈希索引,所以叫做自適應(yīng)哈希索引。
緩存池
為了提高數(shù)據(jù)庫的性能,引入緩存池的概念,通過參數(shù) innodb_buffer_pool_size 可以設(shè)置緩存池的大小,參數(shù) innodb_buffer_pool_instances 可以設(shè)置緩存池的實(shí)例個(gè)數(shù)。緩存池主要用于存儲(chǔ)以下內(nèi)容:
緩沖池中緩存的數(shù)據(jù)頁類型有:索引頁、數(shù)據(jù)頁、undo頁、插入緩沖 (insert buffer)、自適應(yīng)哈希索引(adaptive hash index)、InnoDB存儲(chǔ)的鎖信息 (lock info)和數(shù)據(jù)字典信息 (data dictionary)。
MyISAM存儲(chǔ)引擎應(yīng)用場景有哪些?
MyISAM 是 MySQL 5.1 及之前的版本的默認(rèn)的存儲(chǔ)引擎。MyISAM 提供了大量的特性,包括全文索引、壓縮、空間函數(shù)(GIS)等,但MyISAM 不「支持事務(wù)和行級(jí)鎖」,對于只讀數(shù)據(jù),或者表比較小、可以容忍修復(fù)操作,依然可以使用它。
MyISAM存儲(chǔ)引擎特性有哪些?
MyISAM「不支持行級(jí)鎖而是對整張表加鎖」。讀取時(shí)會(huì)對需要讀到的所有表加共享鎖,寫入時(shí)則對表加排它鎖。但在表有讀取操作的同時(shí),也可以往表中插入新的記錄,這被稱為并發(fā)插入。
MyISAM 表可以手工或者自動(dòng)執(zhí)行檢查和修復(fù)操作。但是和事務(wù)恢復(fù)以及崩潰恢復(fù)不同,可能導(dǎo)致一些「數(shù)據(jù)丟失」,而且修復(fù)操作是非常慢的。
對于 MyISAM 表,即使是BLOB和TEXT等長字段,也可以基于其前 500 個(gè)字符創(chuàng)建索引,MyISAM 也支持「全文索引」,這是一種基于分詞創(chuàng)建的索引,可以支持復(fù)雜的查詢。
如果指定了DELAY_KEY_WRITE選項(xiàng),在每次修改執(zhí)行完成時(shí),不會(huì)立即將修改的索引數(shù)據(jù)寫入磁盤,而是會(huì)寫到內(nèi)存中的鍵緩沖區(qū),只有在清理鍵緩沖區(qū)或者關(guān)閉表的時(shí)候才會(huì)將對應(yīng)的索引塊寫入磁盤。這種方式可以極大的提升寫入性能,但是在數(shù)據(jù)庫或者主機(jī)崩潰時(shí)會(huì)造成「索引損壞」,需要執(zhí)行修復(fù)操作。
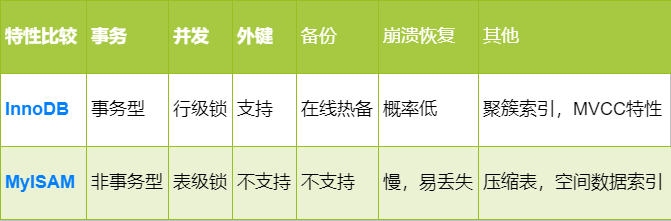
MyISAM 與 InnoDB 存儲(chǔ)引擎 5 大區(qū)別
InnoDB支持事物,而MyISAM不支持事物 InnoDB支持行級(jí)鎖,而MyISAM支持表級(jí)鎖 InnoDB支持MVCC, 而MyISAM不支持 InnoDB支持外鍵,而MyISAM不支持 InnoDB不支持全文索引,而MyISAM支持
一張表簡單羅列兩種引擎的主要區(qū)別,如下圖:
SELECT COUNT(*) 在哪個(gè)引擎執(zhí)行更快?
SELECT COUNT(*) 常用于統(tǒng)計(jì)表的總行數(shù),在 MyISAM 存儲(chǔ)引擎中執(zhí)行更快,前提是不能加有任何WHERE條件。
這是因?yàn)?MyISAM 對于表的行數(shù)做了優(yōu)化,內(nèi)部用一個(gè)變量存儲(chǔ)了表的行數(shù),如果查詢條件沒有 WHERE 條件則是查詢表中一共有多少條數(shù)據(jù),MyISAM 可以迅速返回結(jié)果,如果加 WHERE 條件就不行。
InnoDB 的表也有一個(gè)存儲(chǔ)了表行數(shù)的變量,但這個(gè)值是一個(gè)估計(jì)值,所以并沒有太大實(shí)際意義。
MySQL 基礎(chǔ)知識(shí)
說一下數(shù)據(jù)庫設(shè)計(jì)三范式是什么?
1范式:1NF是對屬性的原子性約束,要求屬性具有原子性,不可再分解;(只要是關(guān)系型數(shù)據(jù)庫都滿足1NF)
2范式:2NF是對記錄的惟一性約束,要求記錄有惟一標(biāo)識(shí),即實(shí)體的惟一性;
3范式:3NF是對字段冗余性的約束,即任何字段不能由其他字段派生出來,它要求字段沒有冗余。沒有冗余的數(shù)據(jù)庫設(shè)計(jì)可以做到
但是,沒有冗余的數(shù)據(jù)庫未必是最好的數(shù)據(jù)庫,有時(shí)為了提高運(yùn)行效率,就必須降低范式標(biāo)準(zhǔn),適當(dāng)保留冗余數(shù)據(jù),具體做法是:在概念數(shù)據(jù)模型設(shè)計(jì)時(shí)遵守第三范式,降低范式標(biāo)準(zhǔn)的工作放到物理數(shù)據(jù)模型設(shè)計(jì)時(shí)考慮,降低范式就是增加字段,允許冗余。
SQL 語句有哪些分類?
DDL:數(shù)據(jù)定義語言(create alter drop) DML:數(shù)據(jù)操作語句(insert update delete) DTL:數(shù)據(jù)事務(wù)語句(commit collback savapoint) DCL:數(shù)據(jù)控制語句(grant revoke)
數(shù)據(jù)庫刪除操作中的 delete、drop、 truncate 區(qū)別在哪?
當(dāng)不再需要該表時(shí)可以用 drop 來刪除表; 當(dāng)仍要保留該表,但要?jiǎng)h除所有記錄時(shí), 用 truncate來刪除表中記錄。 當(dāng)要?jiǎng)h除部分記錄時(shí)(一般來說有 WHERE 子句約束) 用 delete來刪除表中部分記錄。
什么是MySql視圖?
視圖是虛擬表,并不儲(chǔ)存數(shù)據(jù),只包含定義時(shí)的語句的動(dòng)態(tài)數(shù)據(jù)。
創(chuàng)建視圖語法:
CREATE
[OR REPLACE]
[ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
[DEFINER = user]
[SQL SECURITY { DEFINER | INVOKER }]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
參數(shù)說明:
OR REPLACE:如果視圖存在,則替換已有視圖。
ALGORITHM:視圖選擇算法,默認(rèn)算法是 UNDEFINED(未定義的)由 MySQL自動(dòng)選擇要使用的算法。
DEFINER:指定視圖創(chuàng)建者或定義者,如果不指定該選項(xiàng),則創(chuàng)建視圖的用戶就是定義者。
SQL SECURITY:SQL安全性,默認(rèn)為DEFINER。
select_statement:創(chuàng)建視圖的 SELECT語句,可以從基表或其他視圖中選擇數(shù)據(jù)。
WITH CHECK OPTION:表示視圖在更新時(shí)保證約束,默認(rèn)是 CASCADED。
使用 MySQL 視圖有何優(yōu)點(diǎn)?
操作簡單方便。視圖用戶完全不需要關(guān)心視圖對應(yīng)的表的結(jié)構(gòu)、關(guān)聯(lián)條件和篩選條件,對用戶來說已經(jīng)是過濾好的復(fù)合條件的結(jié)果集。
數(shù)據(jù)更加安全。視圖用戶只能訪問視圖中的結(jié)果集,通過視圖可以把對表的訪問權(quán)限限制在某些行和列上面。
數(shù)據(jù)隔離。屏蔽了源表結(jié)構(gòu)變化對用戶帶來的影響,源表結(jié)構(gòu)變化視圖結(jié)構(gòu)不變。^1
MySql服務(wù)默認(rèn)端口號(hào)是多少 ?
默認(rèn)端口是 3306
查看端口命令:> show variables like 'port';
用 DISTINCT 過濾 多列的規(guī)則?
DISTINCT 用于對選擇的數(shù)據(jù)去重,單列用法容易理解。比如有如下數(shù)據(jù)表 tamb:
name number
Tencent 1
Alibaba 2
Bytedance 3
Meituan 3
查詢語句:SELECT DISTINCT name FROM table tamb 結(jié)果如下:
name
Tencent
Alibaba
Bytedance
Meituan
如果要求按 number 列去重同時(shí)顯示 name ,你可能會(huì)寫出查詢語句:
SELECT DISTINCT number, name FROM table tamb
多參數(shù) DISTINCT 去重規(guī)則是:把 DISTINCT 之后的所有參數(shù)當(dāng)做一個(gè)過濾條件,也就是說會(huì)對 (number, name)整體去重處理,只有當(dāng)這個(gè)組合不同才會(huì)去重,結(jié)果如下:
number name
1 Tencent
2 Alibaba
3 Bytedance
3 Meituan
從結(jié)果來看好像并沒有達(dá)到我們想要的去重的效果,那要怎么實(shí)現(xiàn)「按 number 列去重同時(shí)顯示 name」呢?可以用 Group By 語句:
SELECT number, name FROM table tamb GROUP BY number 輸出如下,正是我們想要的效果:
number name
1 Tencent
2 Alibaba
3 Bytedance
什么是存儲(chǔ)過程?
一條或多條sql語句集合,有以下一些特點(diǎn):
存儲(chǔ)過程能實(shí)現(xiàn)較快的執(zhí)行速度。 存儲(chǔ)過程可以用流程控制語句編寫,有很強(qiáng)的靈活性,可以完成復(fù)雜的判斷和較復(fù)雜的運(yùn)算。 存儲(chǔ)過程可被作為一種安全機(jī)制來充分利用。 存儲(chǔ)過程能夠減少網(wǎng)絡(luò)流量
delimiter 分隔符
create procedure|proc proc_name()
begin
sql語句
end 分隔符
delimiter ; --還原分隔符,為了不影響后面的語句的使用
--默認(rèn)的分隔符是;但是為了能在整個(gè)存儲(chǔ)過程中重用,因此一般需要自定義分隔符(除\外)
show procedure status like ""; --查詢存儲(chǔ)過程,可以不適用like進(jìn)行過濾
drop procedure if exists;--刪除存儲(chǔ)過程
存儲(chǔ)過程和函數(shù)好像差不多,你說說他們有什么區(qū)別?
存儲(chǔ)過程和函數(shù)是事先經(jīng)過編譯并存儲(chǔ)在數(shù)據(jù)庫中的一段 SQL 語句的集合,調(diào)用存儲(chǔ)過程和函數(shù)可以簡化應(yīng)用開發(fā)人員的很多工作,減少數(shù)據(jù)在數(shù)據(jù)庫和應(yīng)用服務(wù)器之間的傳輸,對于提高數(shù)據(jù)處理的效率是有好處的。
相同點(diǎn)
存儲(chǔ)過程和函數(shù)都是為了可重復(fù)的執(zhí)行操作數(shù)據(jù)庫的 SQL 語句的集合。
存儲(chǔ)過程和函數(shù)都是一次編譯后緩存起來,下次使用就直接命中已經(jīng)編譯好的 sql 語句,減少網(wǎng)絡(luò)交互提高了效率。
不同點(diǎn)
標(biāo)識(shí)符不同,函數(shù)的標(biāo)識(shí)符是 function,存儲(chǔ)過程是 procedure。
函數(shù)返回單個(gè)值或者表對象,而存儲(chǔ)過程沒有返回值,但是可以通過OUT參數(shù)返回多個(gè)值。
函數(shù)限制比較多,比如不能用臨時(shí)表,只能用表變量,一些函數(shù)都不可用等,而存儲(chǔ)過程的限制相對就比較少。
一般來說,存儲(chǔ)過程實(shí)現(xiàn)的功能要復(fù)雜一點(diǎn),而函數(shù)的實(shí)現(xiàn)的功能針對性比較強(qiáng)
函數(shù)的參數(shù)只能是 IN 類型,存儲(chǔ)過程的參數(shù)可以是
IN OUT INOUT三種類型。存儲(chǔ)函數(shù)使用 select 調(diào)用,存儲(chǔ)過程需要使用 call 調(diào)用。
來源: 后端技術(shù)學(xué)堂-LemonCoder
![]()