
分庫(kù)分表常見(jiàn)概念解讀+Sharding-JDBC實(shí)戰(zhàn)
之前有不少剛?cè)肟?Java 的粉絲留言,想系統(tǒng)的學(xué)習(xí)一下分庫(kù)分表相關(guān)技術(shù),可我一直沒(méi)下定決心搞,眼下趕上公司項(xiàng)目在使用 sharding-jdbc ?對(duì)現(xiàn)有 MySQL 架構(gòu)做分庫(kù)分表的改造,所以借此機(jī)會(huì)出一系分庫(kù)分表落地實(shí)踐的文章,也算是自己對(duì)架構(gòu)學(xué)習(xí)的一個(gè)總結(jié)。
我在網(wǎng)上陸陸續(xù)續(xù)的也看了一些有關(guān)于分庫(kù)分表的文章,可發(fā)現(xiàn)網(wǎng)上同質(zhì)化的資料有點(diǎn)多,而且知識(shí)點(diǎn)又都比較零碎,還沒(méi)有詳細(xì)的實(shí)戰(zhàn)案例。為了更深入的學(xué)習(xí)下,我在某些平臺(tái)買了點(diǎn)付費(fèi)課程,看了幾節(jié)課發(fā)現(xiàn)有點(diǎn)經(jīng)驗(yàn)的人看還可以,但對(duì)于新手入門來(lái)說(shuō),其實(shí)學(xué)習(xí)難度還是蠻大的。
為了讓新手也能看得懂,有些知識(shí)點(diǎn)我可能會(huì)用更多的篇幅加以描述,希望大家不要嫌我啰嗦,等這分庫(kù)分表系列文章完結(jié)后,我會(huì)把它做成 PDF 文檔開(kāi)源出去,能幫一個(gè)算一個(gè)吧!如果發(fā)現(xiàn)文中有哪些錯(cuò)誤或不嚴(yán)謹(jǐn)之處,歡迎大家交流指正。
具體實(shí)踐分庫(kù)分表之前在啰嗦幾句,回頭復(fù)習(xí)下分庫(kù)分表的基礎(chǔ)概念。
什么是分庫(kù)分表
其實(shí) 分庫(kù) 和 分表 是兩個(gè)概念,只不過(guò)通常分庫(kù)與分表的操作會(huì)同時(shí)進(jìn)行,以至于我們習(xí)慣性的將它們合在一起叫做分庫(kù)分表。
分庫(kù)分表是為了解決由于庫(kù)、表數(shù)據(jù)量過(guò)大,而導(dǎo)致數(shù)據(jù)庫(kù)性能持續(xù)下降的問(wèn)題。按照一定的規(guī)則,將原本數(shù)據(jù)量大的數(shù)據(jù)庫(kù)拆分成多個(gè)單獨(dú)的數(shù)據(jù)庫(kù),將原本數(shù)據(jù)量大的表拆分成若干個(gè)數(shù)據(jù)表,使得單一的庫(kù)、表性能達(dá)到最優(yōu)的效果(響應(yīng)速度快),以此提升整體數(shù)據(jù)庫(kù)性能。
如何分庫(kù)分表
分庫(kù)分表的核心理念就是對(duì)數(shù)據(jù)進(jìn)行切分(Sharding),以及切分后如何對(duì)數(shù)據(jù)的快速定位與查詢結(jié)果整合。而分庫(kù)與分表都可以從:垂直(縱向)和 水平(橫向)兩種緯度進(jìn)行切分。
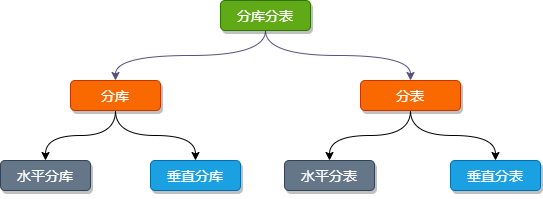
下邊我們就以訂單相關(guān)的業(yè)務(wù)舉例,看看如何做庫(kù)、表的 垂直 和 水平 切分。
垂直切分
垂直切分有 垂直 分庫(kù) 和 垂直分表。
1、垂直分庫(kù)
垂直分庫(kù)相對(duì)來(lái)說(shuō)是比較好理解的,核心理念就四個(gè)字:專庫(kù)專用。
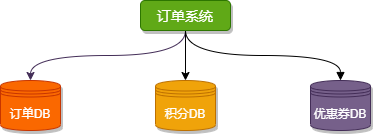
按業(yè)務(wù)類型對(duì)表進(jìn)行分類,像訂單、支付、優(yōu)惠券、積分等相應(yīng)的表放在對(duì)應(yīng)的數(shù)據(jù)庫(kù)中。開(kāi)發(fā)者不可以跨庫(kù)直連別的業(yè)務(wù)數(shù)據(jù)庫(kù),想要其他業(yè)務(wù)數(shù)據(jù),對(duì)應(yīng)業(yè)務(wù)方可以提供 API 接口,這就是微服務(wù)的初始形態(tài)。
垂直分庫(kù)很大程度上取決于業(yè)務(wù)的劃分,但有時(shí)候業(yè)務(wù)間的劃分并不是那么清晰,比如:訂單數(shù)據(jù)的拆分要考慮到與其他業(yè)務(wù)間的關(guān)聯(lián)關(guān)系,并不是說(shuō)直接把訂單相關(guān)的表放在一個(gè)庫(kù)里這么簡(jiǎn)單。
在一定程度上,垂直分庫(kù)似乎提升了一些數(shù)據(jù)庫(kù)性能,可實(shí)際上并沒(méi)有解決由于單表數(shù)據(jù)量過(guò)大導(dǎo)致的性能問(wèn)題,所以就需要配合水平切分方式來(lái)解決。
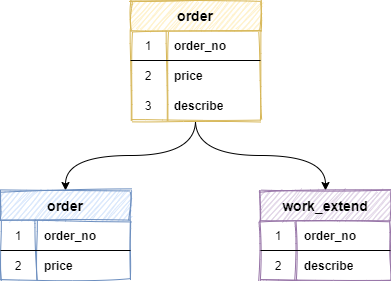
2、垂直分表
垂直分表是基于數(shù)據(jù)表的列(字段)為依據(jù)切分的,是一種大表拆小表的模式。
例如:一張 order 訂單表,將訂單金額、訂單編號(hào)等訪問(wèn)頻繁的字段,單獨(dú)拆成一張表,把 blob 類型這樣的大字段或訪問(wèn)不頻繁的字段,拆分出來(lái)創(chuàng)建一個(gè)單獨(dú)的擴(kuò)展表 work_extend ,這樣每張表只存儲(chǔ)原表的一部分字段,再將拆分出來(lái)的表分散到不同的庫(kù)中。
我們知道數(shù)據(jù)庫(kù)是以行為單位將數(shù)據(jù)加載到內(nèi)存中,這樣拆分以后核心表大多是訪問(wèn)頻率較高的字段,而且字段長(zhǎng)度也都較短,因而可以加載更多數(shù)據(jù)到內(nèi)存中,來(lái)增加查詢的命中率,減少磁盤IO,以此來(lái)提升數(shù)據(jù)庫(kù)性能。
垂直切分的優(yōu)點(diǎn):
業(yè)務(wù)間數(shù)據(jù)解耦,不同業(yè)務(wù)的數(shù)據(jù)進(jìn)行獨(dú)立的維護(hù)、監(jiān)控、擴(kuò)展。 在高并發(fā)場(chǎng)景下,一定程度上緩解了數(shù)據(jù)庫(kù)的壓力。
垂直切分的缺點(diǎn):
提升了開(kāi)發(fā)的復(fù)雜度,由于業(yè)務(wù)的隔離性,很多表無(wú)法直接訪問(wèn),必須通過(guò)接口方式聚合數(shù)據(jù)。 分布式事務(wù)管理難度增加。 數(shù)據(jù)庫(kù)還是存在單表數(shù)據(jù)量過(guò)大的問(wèn)題,并未根本上解決,需要配合水平切分。
水平切分
前邊說(shuō)了垂直切分還是會(huì)存在單庫(kù)、表數(shù)據(jù)量過(guò)大的問(wèn)題,當(dāng)我們的應(yīng)用已經(jīng)無(wú)法在細(xì)粒度的垂直切分時(shí), 依舊存在單庫(kù)讀寫、存儲(chǔ)性能瓶頸,這時(shí)就要配合水平切分一起了,水平切分能大幅提升數(shù)據(jù)庫(kù)性能。
1、水平分庫(kù)
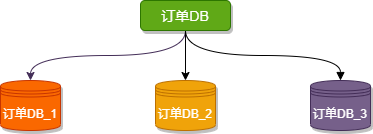
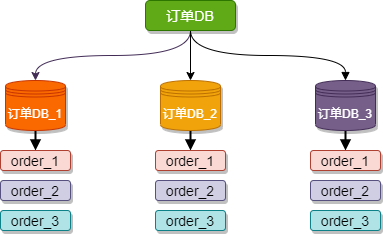
水平分庫(kù)是把同一個(gè)表按一定規(guī)則拆分到不同的數(shù)據(jù)庫(kù)中,每個(gè)庫(kù)可以位于不同的服務(wù)器上,以此實(shí)現(xiàn)水平擴(kuò)展,是一種常見(jiàn)的提升數(shù)據(jù)庫(kù)性能的方式。
這種方案往往能解決單庫(kù)存儲(chǔ)量及性能瓶頸問(wèn)題,但由于同一個(gè)表被分配在不同的數(shù)據(jù)庫(kù)中,數(shù)據(jù)的訪問(wèn)需要額外的路由工作,因此系統(tǒng)的復(fù)雜度也被提升了。
例如下圖,訂單DB_1、訂單DB_1、訂單DB_3 三個(gè)數(shù)據(jù)庫(kù)內(nèi)有完全相同的表 order,我們?cè)谠L問(wèn)某一筆訂單時(shí)可以通過(guò)對(duì)訂單的訂單編號(hào)取模的方式 訂單編號(hào) mod 3 (數(shù)據(jù)庫(kù)實(shí)例數(shù)) ,指定該訂單應(yīng)該在哪個(gè)數(shù)據(jù)庫(kù)中操作。
2、水平分表
水平分表是在同一個(gè)數(shù)據(jù)庫(kù)內(nèi),把一張大數(shù)據(jù)量的表按一定規(guī)則,切分成多個(gè)結(jié)構(gòu)完全相同表,而每個(gè)表只存原表的一部分?jǐn)?shù)據(jù)。
例如:一張 order 訂單表有 900萬(wàn)數(shù)據(jù),經(jīng)過(guò)水平拆分出來(lái)三個(gè)表,order_1、order_2、order_3,每張表存有數(shù)據(jù) 300萬(wàn),以此類推。
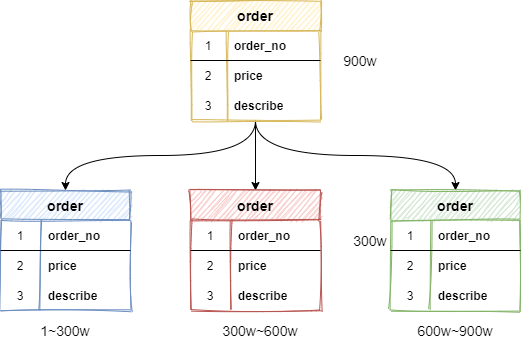
水平分表盡管拆分了表,但子表都還是在同一個(gè)數(shù)據(jù)庫(kù)實(shí)例中,只是解決了單一表數(shù)據(jù)量過(guò)大的問(wèn)題,并沒(méi)有將拆分后的表分散到不同的機(jī)器上,還在競(jìng)爭(zhēng)同一個(gè)物理機(jī)的CPU、內(nèi)存、網(wǎng)絡(luò)IO等。要想進(jìn)一步提升性能,就需要將拆分后的表分散到不同的數(shù)據(jù)庫(kù)中,達(dá)到分布式的效果。
水平切分的優(yōu)點(diǎn):
解決高并發(fā)時(shí)單庫(kù)數(shù)據(jù)量過(guò)大的問(wèn)題,提升系統(tǒng)穩(wěn)定性和負(fù)載能力。 業(yè)務(wù)系統(tǒng)改造的工作量不是很大。
水平切分的缺點(diǎn):
跨分片的事務(wù)一致性難以保證。 跨庫(kù)的join關(guān)聯(lián)查詢性能較差。 擴(kuò)容的難度和維護(hù)量較大,(拆分成幾千張子表想想都恐怖)。
一定規(guī)則是什么
我們上邊提到過(guò)很多次 一定規(guī)則 ,這個(gè)規(guī)則其實(shí)是一種路由算法,就是決定一條數(shù)據(jù)具體應(yīng)該存在哪個(gè)數(shù)據(jù)庫(kù)的哪張表里。
常見(jiàn)的有 取模算法 和 范圍限定算法
1、取模算法
按字段取模(對(duì)hash結(jié)果取余數(shù) (hash() mod N),N為數(shù)據(jù)庫(kù)實(shí)例數(shù)或子表數(shù)量)是最為常見(jiàn)的一種切分方式。
還拿 order 訂單表舉例,先對(duì)數(shù)據(jù)庫(kù)從 0 到 N-1進(jìn)行編號(hào),對(duì) order 訂單表中 work_no 訂單編號(hào)字段進(jìn)行取模,得到余數(shù) i,i=0存第一個(gè)庫(kù),i=1存第二個(gè)庫(kù),i=2存第三個(gè)庫(kù)....以此類推。
這樣同一筆訂單的數(shù)據(jù)都會(huì)存在同一個(gè)庫(kù)、表里,查詢時(shí)用相同的規(guī)則,用 work_no 訂單編號(hào)作為查詢條件,就能快速的定位到數(shù)據(jù)。
優(yōu)點(diǎn):
數(shù)據(jù)分片相對(duì)比較均勻,不易出現(xiàn)請(qǐng)求都打到一個(gè)庫(kù)上的情況。
缺點(diǎn):
這種算法存在一些問(wèn)題,當(dāng)某一臺(tái)機(jī)器宕機(jī),本應(yīng)該落在該數(shù)據(jù)庫(kù)的請(qǐng)求就無(wú)法得到正確的處理,這時(shí)宕掉的實(shí)例會(huì)被踢出集群,此時(shí)算法變成hash(userId) mod N-1,用戶信息可能就不再在同一個(gè)庫(kù)中了。
2、范圍限定算法
按照 時(shí)間區(qū)間 或 ID區(qū)間 來(lái)切分,比如:我們切分的是用戶表,可以定義每個(gè)庫(kù)的 User 表里只存10000條數(shù)據(jù),第一個(gè)庫(kù)只存 userId 從1 ~ 9999的數(shù)據(jù),第二個(gè)庫(kù)存 userId 為10000 ~ 20000,第三個(gè)庫(kù)存 userId 為 20001~ 30000......以此類推,按時(shí)間范圍也是同理。
優(yōu)點(diǎn):
單表數(shù)據(jù)量是可控的 水平擴(kuò)展簡(jiǎn)單只需增加節(jié)點(diǎn)即可,無(wú)需對(duì)其他分片的數(shù)據(jù)進(jìn)行遷移 能快速定位要查詢的數(shù)據(jù)在哪個(gè)庫(kù)
缺點(diǎn):
由于連續(xù)分片可能存在數(shù)據(jù)熱點(diǎn),比如按時(shí)間字段分片,可能某一段時(shí)間內(nèi)訂單驟增,可能會(huì)被頻繁的讀寫,而有些分片存儲(chǔ)的歷史數(shù)據(jù),則很少被查詢。
分庫(kù)分表的難點(diǎn)
1、分布式事務(wù)
由于表分布在不同庫(kù)中,不可避免會(huì)帶來(lái)跨庫(kù)事務(wù)問(wèn)題。一般可使用 "三階段提交 "和 "兩階段提交" 處理,但是這種方式性能較差,代碼開(kāi)發(fā)量也比較大。通常做法是做到最終一致性的方案,如果不苛求系統(tǒng)的實(shí)時(shí)一致性,只要在允許的時(shí)間段內(nèi)達(dá)到最終一致性即可,采用事務(wù)補(bǔ)償?shù)姆绞健?/p>
這里我應(yīng)用阿里的分布式事務(wù)框架Seata 來(lái)做分布式事務(wù)的管理,后邊會(huì)結(jié)合實(shí)際案例。
2、分頁(yè)、排序、跨庫(kù)聯(lián)合查詢
分頁(yè)、排序、聯(lián)合查詢是開(kāi)發(fā)中使用頻率非常高的功能,但在分庫(kù)分表后,這些看似普通的操作卻是讓人非常頭疼的問(wèn)題。將分散在不同庫(kù)中表的數(shù)據(jù)查詢出來(lái),再將所有結(jié)果進(jìn)行匯總整理后提供給用戶。
3、分布式主鍵
分庫(kù)分表后數(shù)據(jù)庫(kù)的自增主鍵意義就不大了,因?yàn)槲覀儾荒芤揽繂蝹€(gè)數(shù)據(jù)庫(kù)實(shí)例上的自增主鍵來(lái)實(shí)現(xiàn)不同數(shù)據(jù)庫(kù)之間的全局唯一主鍵,此時(shí)一個(gè)能夠生成全局唯一ID的系統(tǒng)是非常必要的,那么這個(gè)全局唯一ID就叫 分布式ID。
4、讀寫分離
不難發(fā)現(xiàn)大部分主流的關(guān)系型數(shù)據(jù)庫(kù)都提供了主從架構(gòu)的高可用方案,而我們需要實(shí)現(xiàn) 讀寫分離 + 分庫(kù)分表,讀庫(kù)與寫庫(kù)都要做分庫(kù)分表處理,后邊會(huì)有具體實(shí)戰(zhàn)案例。
5、數(shù)據(jù)脫敏
數(shù)據(jù)脫敏,是指對(duì)某些敏感信息通過(guò)脫敏規(guī)則進(jìn)行數(shù)據(jù)轉(zhuǎn)換,從而實(shí)現(xiàn)敏感隱私數(shù)據(jù)的可靠保護(hù),如身份證號(hào)、手機(jī)號(hào)、卡號(hào)、賬號(hào)密碼等個(gè)人信息,一般這些都需要進(jìn)行做脫敏處理。
分庫(kù)分表工具
我還是那句話,盡量不要自己造輪子,因?yàn)樽约涸斓妮喿涌赡懿荒敲磮A,業(yè)界已經(jīng)有了很多比較成熟的分庫(kù)分表中間件,我們根據(jù)自身的業(yè)務(wù)需求挑選,將更多的精力放在業(yè)務(wù)實(shí)現(xiàn)上。
sharding-jdbc(當(dāng)當(dāng))TSharding(蘑菇街)Atlas(奇虎360)Cobar(阿里巴巴)MyCAT(基于Cobar)Oceanus(58同城)Vitess(谷歌)
為什么選 Sharding-JDBC
sharding-jdbc 是一款輕量級(jí) Java 框架,以 jar 包形式提供服務(wù),是屬于客戶端產(chǎn)品不需要額外部署,它相當(dāng)于是個(gè)增強(qiáng)版的 JDBC 驅(qū)動(dòng);相比之下像 Mycat 這類需要單獨(dú)的部署服務(wù)的服務(wù)端產(chǎn)品,就稍顯復(fù)雜了。況且我想把更多精力放在實(shí)現(xiàn)業(yè)務(wù),不想做額外的運(yùn)維工作。
sharding-jdbc的兼容性也非常強(qiáng)大,適用于任何基于JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用的JDBC。完美兼容任何第三方的數(shù)據(jù)庫(kù)連接池,如: DBCP,C3P0,BoneCP,Druid,HikariCP等,幾乎對(duì)所有關(guān)系型數(shù)據(jù)庫(kù)都支持。
不難發(fā)現(xiàn)確實(shí)是比較強(qiáng)大的一款工具,而且它對(duì)項(xiàng)目的侵入性很小,幾乎不用做任何代碼層的修改,也無(wú)需修改 SQL 語(yǔ)句,只需配置待分庫(kù)分表的數(shù)據(jù)表即可。
Sharding-JDBC 簡(jiǎn)介
Sharding-JDBC 最早是當(dāng)當(dāng)網(wǎng)內(nèi)部使用的一款分庫(kù)分表框架,到2017年的時(shí)候才開(kāi)始對(duì)外開(kāi)源,這幾年在大量社區(qū)貢獻(xiàn)者的不斷迭代下,功能也逐漸完善,現(xiàn)已更名為 ShardingSphere,2020年4?16?正式成為 Apache 軟件基?會(huì)的頂級(jí)項(xiàng)?。
隨著版本的不斷更迭 ShardingSphere 的核心功能也變得多元化起來(lái)。從最開(kāi)始 Sharding-JDBC 1.0 版本只有數(shù)據(jù)分片,到 Sharding-JDBC 2.0 版本開(kāi)始支持?jǐn)?shù)據(jù)庫(kù)治理(注冊(cè)中心、配置中心等等),再到 Sharding-JDBC 3.0版本又加分布式事務(wù) (支持 Atomikos、Narayana、Bitronix、Seata),如今已經(jīng)迭代到了 Sharding-JDBC 4.0 版本。
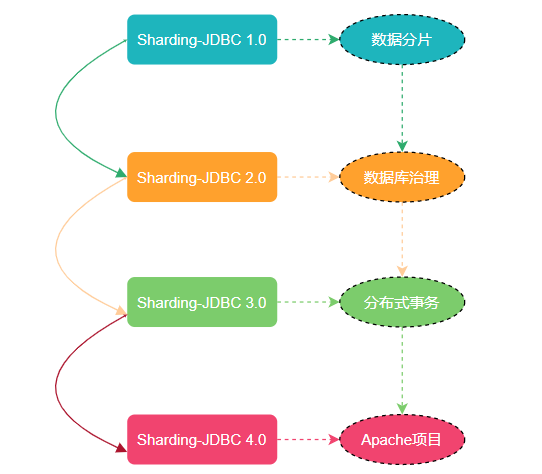
現(xiàn)在的 ShardingSphere 不單單是指某個(gè)框架而是一個(gè)生態(tài)圈,這個(gè)生態(tài)圈 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 這三款開(kāi)源的分布式數(shù)據(jù)庫(kù)中間件解決方案所構(gòu)成。
ShardingSphere 的前身就是 Sharding-JDBC,所以它是整個(gè)框架中最為經(jīng)典、成熟的組件,我們先從 Sharding-JDBC 框架入手學(xué)習(xí)分庫(kù)分表。
Sharding-JDBC核心概念
在開(kāi)始 Sharding-JDBC分庫(kù)分表具體實(shí)戰(zhàn)之前,我們有必要先了解分庫(kù)分表的一些核心概念。
分片
一般我們?cè)谔岬椒謳?kù)分表的時(shí)候,大多是以水平切分模式(水平分庫(kù)、分表)為基礎(chǔ)來(lái)說(shuō)的,數(shù)據(jù)分片將原本一張數(shù)據(jù)量較大的表 t_order 拆分生成數(shù)個(gè)表結(jié)構(gòu)完全一致的小數(shù)據(jù)量表 t_order_0、t_order_1、···、t_order_n,每張表只存儲(chǔ)原大表中的一部分?jǐn)?shù)據(jù),當(dāng)執(zhí)行一條SQL時(shí)會(huì)通過(guò) 分庫(kù)策略、分片策略 將數(shù)據(jù)分散到不同的數(shù)據(jù)庫(kù)、表內(nèi)。
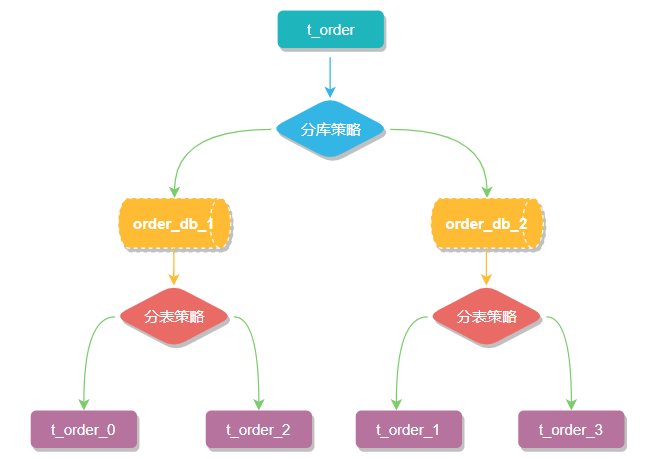
數(shù)據(jù)節(jié)點(diǎn)
數(shù)據(jù)節(jié)點(diǎn)是分庫(kù)分表中一個(gè)不可再分的最小數(shù)據(jù)單元(表),它由數(shù)據(jù)源名稱和數(shù)據(jù)表組成,例如上圖中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一個(gè)數(shù)據(jù)節(jié)點(diǎn)。
邏輯表
邏輯表是指一組具有相同邏輯和數(shù)據(jù)結(jié)構(gòu)表的總稱。比如我們將訂單表t_order 拆分成 t_order_0 ··· ?t_order_9 等 10張表。此時(shí)我們會(huì)發(fā)現(xiàn)分庫(kù)分表以后數(shù)據(jù)庫(kù)中已不在有 t_order 這張表,取而代之的是 t_order_n,但我們?cè)诖a中寫 SQL 依然按 t_order 來(lái)寫。此時(shí) t_order 就是這些拆分表的邏輯表。
真實(shí)表
真實(shí)表也就是上邊提到的 t_order_n 數(shù)據(jù)庫(kù)中真實(shí)存在的物理表。
分片鍵
用于分片的數(shù)據(jù)庫(kù)字段。我們將 t_order 表分片以后,當(dāng)執(zhí)行一條SQL時(shí),通過(guò)對(duì)字段 order_id 取模的方式來(lái)決定,這條數(shù)據(jù)該在哪個(gè)數(shù)據(jù)庫(kù)中的哪個(gè)表中執(zhí)行,此時(shí) order_id 字段就是 t_order 表的分片健。
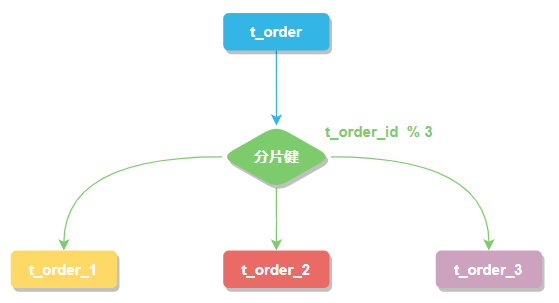
這樣以來(lái)同一個(gè)訂單的相關(guān)數(shù)據(jù)就會(huì)存在同一個(gè)數(shù)據(jù)庫(kù)表中,大幅提升數(shù)據(jù)檢索的性能,不僅如此 sharding-jdbc 還支持根據(jù)多個(gè)字段作為分片健進(jìn)行分片。
分片算法
上邊我們提到可以用分片健取模的規(guī)則分片,但這只是比較簡(jiǎn)單的一種,在實(shí)際開(kāi)發(fā)中我們還希望用 >=、<=、>、<、BETWEEN 和 IN 等條件作為分片規(guī)則,自定義分片邏輯,這時(shí)就需要用到分片策略與分片算法。
從執(zhí)行 SQL 的角度來(lái)看,分庫(kù)分表可以看作是一種路由機(jī)制,把 SQL 語(yǔ)句路由到我們期望的數(shù)據(jù)庫(kù)或數(shù)據(jù)表中并獲取數(shù)據(jù),分片算法可以理解成一種路由規(guī)則。
咱們先捋一下它們之間的關(guān)系,分片策略只是抽象出的概念,它是由分片算法和分片健組合而成,分片算法做具體的數(shù)據(jù)分片邏輯。
分庫(kù)、分表的分片策略配置是相對(duì)獨(dú)立的,可以各自使用不同的策略與算法,每種策略中可以是多個(gè)分片算法的組合,每個(gè)分片算法可以對(duì)多個(gè)分片健做邏輯判斷。
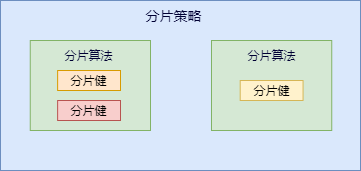
注意:sharding-jdbc 并沒(méi)有直接提供分片算法的實(shí)現(xiàn),需要開(kāi)發(fā)者根據(jù)業(yè)務(wù)自行實(shí)現(xiàn)。
sharding-jdbc 提供了4種分片算法:
1、精確分片算法
精確分片算法(PreciseShardingAlgorithm)用于單個(gè)字段作為分片鍵,SQL中有 = 與 IN 等條件的分片,需要在標(biāo)準(zhǔn)分片策略(StandardShardingStrategy )下使用。
2、范圍分片算法
范圍分片算法(RangeShardingAlgorithm)用于單個(gè)字段作為分片鍵,SQL中有 BETWEEN AND、>、<、>=、<= ?等條件的分片,需要在標(biāo)準(zhǔn)分片策略(StandardShardingStrategy )下使用。
3、復(fù)合分片算法
復(fù)合分片算法(ComplexKeysShardingAlgorithm)用于多個(gè)字段作為分片鍵的分片操作,同時(shí)獲取到多個(gè)分片健的值,根據(jù)多個(gè)字段處理業(yè)務(wù)邏輯。需要在復(fù)合分片策略(ComplexShardingStrategy )下使用。
4、Hint分片算法
Hint分片算法(HintShardingAlgorithm)稍有不同,上邊的算法中我們都是解析SQL 語(yǔ)句提取分片鍵,并設(shè)置分片策略進(jìn)行分片。但有些時(shí)候我們并沒(méi)有使用任何的分片鍵和分片策略,可還想將 SQL 路由到目標(biāo)數(shù)據(jù)庫(kù)和表,就需要通過(guò)手動(dòng)干預(yù)指定SQL的目標(biāo)數(shù)據(jù)庫(kù)和表信息,這也叫強(qiáng)制路由。
分片策略
上邊講分片算法的時(shí)候已經(jīng)說(shuō)過(guò),分片策略是一種抽象的概念,實(shí)際分片操作的是由分片算法和分片健來(lái)完成的。
1、標(biāo)準(zhǔn)分片策略
標(biāo)準(zhǔn)分片策略適用于單分片鍵,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 兩個(gè)分片算法。
其中 PreciseShardingAlgorithm 是必選的,用于處理 = 和 IN 的分片。RangeShardingAlgorithm 是可選的,用于處理BETWEEN AND, >, <,>=,<= 條件分片,如果不配置RangeShardingAlgorithm,SQL中的條件等將按照全庫(kù)路由處理。
2、復(fù)合分片策略
復(fù)合分片策略,同樣支持對(duì) SQL語(yǔ)句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片鍵,具體分配片細(xì)節(jié)完全由應(yīng)用開(kāi)發(fā)者實(shí)現(xiàn)。
3、行表達(dá)式分片策略
行表達(dá)式分片策略,支持對(duì) SQL語(yǔ)句中的 = 和 IN 的分片操作,但只支持單分片鍵。這種策略通常用于簡(jiǎn)單的分片,不需要自定義分片算法,可以直接在配置文件中接著寫規(guī)則。
t_order_$->{t_order_id % 4} 代表 t_order 對(duì)其字段 t_order_id取模,拆分成4張表,而表名分別是t_order_0 到 t_order_3。
4、Hint分片策略
Hint分片策略,對(duì)應(yīng)上邊的Hint分片算法,通過(guò)指定分片健而非從 SQL中提取分片健的方式進(jìn)行分片的策略。
分布式主鍵
數(shù)據(jù)分?后,不同數(shù)據(jù)節(jié)點(diǎn)?成全局唯?主鍵是?常棘?的問(wèn)題,同?個(gè)邏輯表(t_order)內(nèi)的不同真實(shí)表(t_order_n)之間的?增鍵由于?法互相感知而產(chǎn)?重復(fù)主鍵。
盡管可通過(guò)設(shè)置?增主鍵 初始值 和 步? 的?式避免ID碰撞,但這樣會(huì)使維護(hù)成本加大,乏完整性和可擴(kuò)展性。如果后去需要增加分片表的數(shù)量,要逐一修改分片表的步長(zhǎng),運(yùn)維成本非常高,所以不建議這種方式。
實(shí)現(xiàn)分布式主鍵?成器的方式很多,可以參考我之前寫的《9種分布式ID生成方式》。
為了讓上手更加簡(jiǎn)單,ApacheShardingSphere 內(nèi)置了UUID、SNOWFLAKE 兩種分布式主鍵?成器,默認(rèn)使?雪花算法(snowflake)?成64bit的?整型數(shù)據(jù)。不僅如此它還抽離出分布式主鍵?成器的接口,?便我們實(shí)現(xiàn)?定義的?增主鍵?成算法。
廣播表
廣播表:存在于所有的分片數(shù)據(jù)源中的表,表結(jié)構(gòu)和表中的數(shù)據(jù)在每個(gè)數(shù)據(jù)庫(kù)中均完全一致。一般是為字典表或者配置表 t_config,某個(gè)表一旦被配置為廣播表,只要修改某個(gè)數(shù)據(jù)庫(kù)的廣播表,所有數(shù)據(jù)源中廣播表的數(shù)據(jù)都會(huì)跟著同步。
綁定表
綁定表:那些分片規(guī)則一致的主表和子表。比如:t_order 訂單表和 t_order_item 訂單服務(wù)項(xiàng)目表,都是按 order_id 字段分片,因此兩張表互為綁定表關(guān)系。
那綁定表存在的意義是啥呢?
通常在我們的業(yè)務(wù)中都會(huì)使用 t_order 和 t_order_item 等表進(jìn)行多表聯(lián)合查詢,但由于分庫(kù)分表以后這些表被拆分成N多個(gè)子表。如果不配置綁定表關(guān)系,會(huì)出現(xiàn)笛卡爾積關(guān)聯(lián)查詢,將產(chǎn)生如下四條SQL。
SELECT?*?FROM?t_order_0?o?JOIN?t_order_item_0?i?ON?o.order_id=i.order_id?
SELECT?*?FROM?t_order_0?o?JOIN?t_order_item_1?i?ON?o.order_id=i.order_id?
SELECT?*?FROM?t_order_1?o?JOIN?t_order_item_0?i?ON?o.order_id=i.order_id?
SELECT?*?FROM?t_order_1?o?JOIN?t_order_item_1?i?ON?o.order_id=i.order_id?
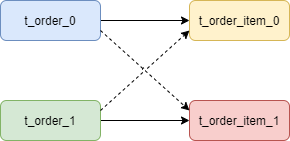
而配置綁定表關(guān)系后再進(jìn)行關(guān)聯(lián)查詢時(shí),只要對(duì)應(yīng)表分片規(guī)則一致產(chǎn)生的數(shù)據(jù)就會(huì)落到同一個(gè)庫(kù)中,那么只需 t_order_0 和 t_order_item_0 表關(guān)聯(lián)即可。
SELECT?*?FROM?t_order_0?o?JOIN?t_order_item_0?i?ON?o.order_id=i.order_id?
SELECT?*?FROM?t_order_1?o?JOIN?t_order_item_1?i?ON?o.order_id=i.order_id?
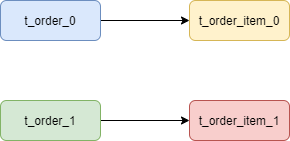
注意:在關(guān)聯(lián)查詢時(shí)
t_order它作為整個(gè)聯(lián)合查詢的主表。所有相關(guān)的路由計(jì)算都只使用主表的策略,t_order_item表的分片相關(guān)的計(jì)算也會(huì)使用t_order的條件,所以要保證綁定表之間的分片鍵要完全相同。
Sharding-JDBC和JDBC的貓膩
從名字上不難看出,Sharding-JDBC 和 JDBC有很大關(guān)系,我們知道 JDBC 是一種 Java 語(yǔ)言訪問(wèn)關(guān)系型數(shù)據(jù)庫(kù)的規(guī)范,其設(shè)計(jì)初衷就是要提供一套用于各種數(shù)據(jù)庫(kù)的統(tǒng)一標(biāo)準(zhǔn),不同廠家共同遵守這套標(biāo)準(zhǔn),并提供各自的實(shí)現(xiàn)方案供應(yīng)用程序調(diào)用。
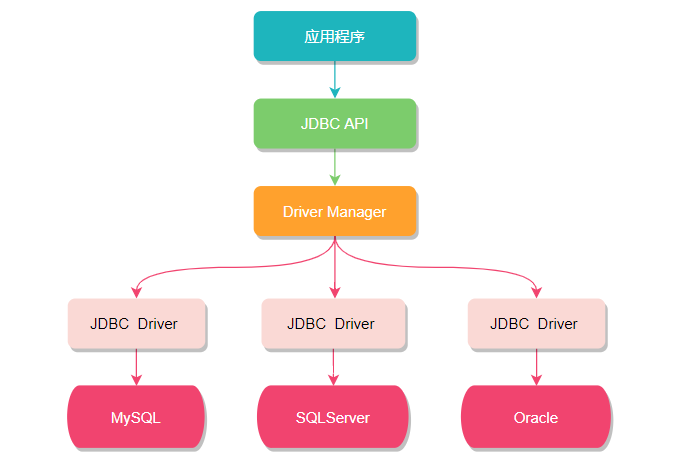
但其實(shí)對(duì)于開(kāi)發(fā)人員而言,我們只關(guān)心如何調(diào)用 JDBC API 來(lái)訪問(wèn)數(shù)據(jù)庫(kù),只要正確使用 DataSource、Connection、Statement 、ResultSet 等 API 接口,直接操作數(shù)據(jù)庫(kù)即可。所以如果想在 JDBC 層面實(shí)現(xiàn)數(shù)據(jù)分片就必須對(duì)現(xiàn)有的 API 進(jìn)行功能拓展,而 Sharding-JDBC 正是基于這種思想,重寫了 JDBC 規(guī)范并完全兼容了 JDBC 規(guī)范。
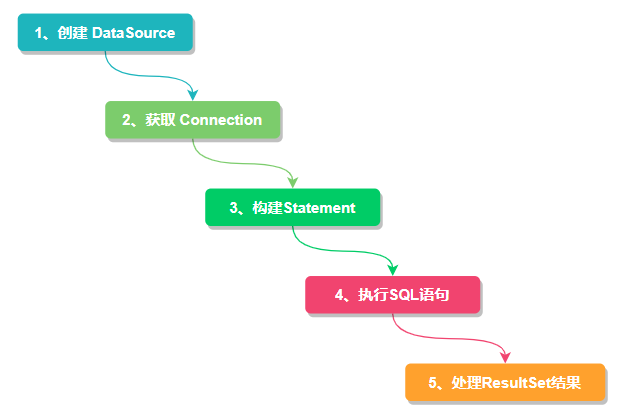
對(duì)原有的 DataSource、Connection 等接口擴(kuò)展成 ShardingDataSource、ShardingConnection,而對(duì)外暴露的分片操作接口與 JDBC 規(guī)范中所提供的接口完全一致,只要你熟悉 JDBC 就可以輕松應(yīng)用 Sharding-JDBC 來(lái)實(shí)現(xiàn)分庫(kù)分表。
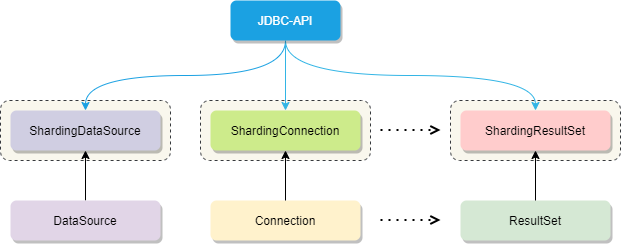
因此它適用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate,Mybatis,Spring JDBC Template 或直接使用的 JDBC。完美兼容任何第三方的數(shù)據(jù)庫(kù)連接池,如:DBCP, C3P0, BoneCP,Druid, HikariCP 等,幾乎對(duì)主流關(guān)系型數(shù)據(jù)庫(kù)都支持。
那 Sharding-JDBC 又是如何拓展這些接口的呢?想知道答案我們就的從源碼入手了,下邊我們以 JDBC API ?中的 DataSource 為例看看它是如何被重寫擴(kuò)展的。
數(shù)據(jù)源 DataSource 接口的核心作用就是獲取數(shù)據(jù)庫(kù)連接對(duì)象 Connection,我們看其內(nèi)部提供了兩個(gè)獲取數(shù)據(jù)庫(kù)連接的方法 ,并且繼承了 CommonDataSource 和 Wrapper 兩個(gè)接口。
public?interface?DataSource??extends?CommonDataSource,?Wrapper?{
??/**
???*?Attempts?to?establish?a?connection?with?the?data?source?that
???*?this?{@code?DataSource}?object?represents.
???*?@return??a?connection?to?the?data?source
???*/
??Connection?getConnection()?throws?SQLException;
??/**
???*?Attempts?to?establish?a?connection?with?the?data?source?that
???*?this?{@code?DataSource}?object?represents.
???*?@param?username?the?database?user?on?whose?behalf?the?connection?is
???*??being?made
???*?@param?password?the?user's?password
???*/
??Connection?getConnection(String?username,?String?password)
????throws?SQLException;
}
其中 CommonDataSource 是定義數(shù)據(jù)源的根接口這很好理解,而 Wrapper 接口則是拓展 JDBC 分片功能的關(guān)鍵。
由于數(shù)據(jù)庫(kù)廠商的不同,他們可能會(huì)各自提供一些超越標(biāo)準(zhǔn) JDBC API 的擴(kuò)展功能,但這些功能非 JDBC 標(biāo)準(zhǔn)并不能直接使用,而 Wrapper 接口的作用就是把一個(gè)由第三方供應(yīng)商提供的、非 JDBC 標(biāo)準(zhǔn)的接口包裝成標(biāo)準(zhǔn)接口,也就是適配器模式。
既然講到了適配器模式就多啰嗦幾句,也方便后邊的理解。
適配器模式個(gè)種比較常用的設(shè)計(jì)模式,它的作用是將某個(gè)類的接口轉(zhuǎn)換成客戶端期望的另一個(gè)接口,使原本因接口不匹配(或者不兼容)而無(wú)法在一起工作的兩個(gè)類能夠在一起工作。
比如用耳機(jī)聽(tīng)音樂(lè),我有個(gè)圓頭的耳機(jī),可手機(jī)插孔卻是扁口的,如果我想要使用耳機(jī)聽(tīng)音樂(lè)就必須借助一個(gè)轉(zhuǎn)接頭才可以,這個(gè)轉(zhuǎn)接頭就起到了適配作用。舉個(gè)栗子:假如我們 Target 接口中有 hello() 和 word() 兩個(gè)方法。
public?interface?Target?{
????void?hello();
????void?world();
}
可由于接口版本迭代Target 接口的 word() 方法可能會(huì)被廢棄掉或不被支持,Adaptee ?類的 greet()方法將代替hello() 方法。
public?class?Adaptee?{
????public?void?greet(){
????}
????public?void?world(){
????}
}
但此時(shí)舊版本仍然有大量 word() 方法被使用中,解決此事最好的辦法就是創(chuàng)建一個(gè)適配器Adapter,這樣就適配了 Target 類,解決了接口升級(jí)帶來(lái)的兼容性問(wèn)題。
public?class?Adapter?extends?Adaptee?implements?Target?{
????@Override
????public?void?world()?{
????????
????}
????@Override
????public?void?hello()?{
????????super.greet();
????}
????@Override
????public?void?greet()?{
????????
????}
}
而 Sharding-JDBC 提供的正是非 JDBC 標(biāo)準(zhǔn)的接口,所以它也提供了類似的實(shí)現(xiàn)方案,也使用到了 Wrapper 接口做數(shù)據(jù)分片功能的適配。除了 DataSource 之外,Connection、Statement、ResultSet 等核心對(duì)象也都繼承了這個(gè)接口。
下面我們通過(guò) ShardingDataSource ?類源碼簡(jiǎn)單看下實(shí)現(xiàn)過(guò)程,下圖是繼承關(guān)系流程圖。
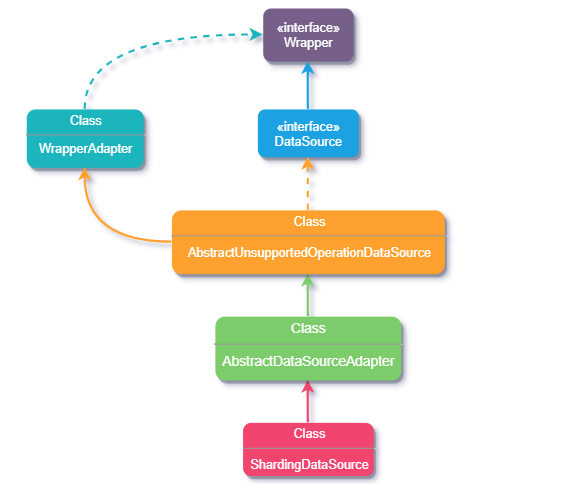
ShardingDataSource ?類它在原 DataSource 基礎(chǔ)上做了功能拓展,初始化時(shí)注冊(cè)了分片SQL路由包裝器、SQL重寫上下文和結(jié)果集處理引擎,還對(duì)數(shù)據(jù)源類型做了校驗(yàn),因?yàn)樗瑫r(shí)支持多個(gè)不同類型的數(shù)據(jù)源。到這好像也沒(méi)看出如何適配,那接著向上看 ShardingDataSource 的繼承類 ?AbstractDataSourceAdapter 。
@Getter
public?class?ShardingDataSource?extends?AbstractDataSourceAdapter?{
????
????private?final?ShardingRuntimeContext?runtimeContext;
????/**
?????*?注冊(cè)路由、SQl重寫上下文、結(jié)果集處理引擎
?????*/
????static?{
????????NewInstanceServiceLoader.register(RouteDecorator.class);
????????NewInstanceServiceLoader.register(SQLRewriteContextDecorator.class);
????????NewInstanceServiceLoader.register(ResultProcessEngine.class);
????}
????/**
?????*?初始化時(shí)校驗(yàn)數(shù)據(jù)源類型?并根據(jù)數(shù)據(jù)源?map、分片規(guī)則、數(shù)據(jù)庫(kù)類型得到一個(gè)分片上下文,用來(lái)獲取數(shù)據(jù)庫(kù)連接
?????*/
????public?ShardingDataSource(final?Map?dataSourceMap,?final?ShardingRule?shardingRule,?final?Properties?props) ?throws?SQLException?{
????????super(dataSourceMap);
????????checkDataSourceType(dataSourceMap);
????????runtimeContext?=?new?ShardingRuntimeContext(dataSourceMap,?shardingRule,?props,?getDatabaseType());
????}
????private?void?checkDataSourceType(final?Map?dataSourceMap) ?{
????????for?(DataSource?each?:?dataSourceMap.values())?{
????????????Preconditions.checkArgument(!(each?instanceof?MasterSlaveDataSource),?"Initialized?data?sources?can?not?be?master-slave?data?sources.");
????????}
????}
????/**
?????*?數(shù)據(jù)庫(kù)連接
?????*/
????@Override
????public?final?ShardingConnection?getConnection()?{
????????return?new?ShardingConnection(getDataSourceMap(),?runtimeContext,?TransactionTypeHolder.get());
????}
}
AbstractDataSourceAdapter 抽象類內(nèi)部主要獲取不同類型的數(shù)據(jù)源對(duì)應(yīng)的數(shù)據(jù)庫(kù)連接對(duì)象,實(shí)現(xiàn) AutoCloseable 接口是為在使用完資源后可以自動(dòng)將這些資源關(guān)閉(調(diào)用 close方法),那再看看繼承類 AbstractUnsupportedOperationDataSource 。
@Getter
public?abstract?class?AbstractDataSourceAdapter?extends?AbstractUnsupportedOperationDataSource?implements?AutoCloseable?{
????
????private?final?Map?dataSourceMap;
????
????private?final?DatabaseType?databaseType;
????
????public?AbstractDataSourceAdapter(final?Map?dataSourceMap) ?throws?SQLException?{
????????this.dataSourceMap?=?dataSourceMap;
????????databaseType?=?createDatabaseType();
????}
????
????public?AbstractDataSourceAdapter(final?DataSource?dataSource)?throws?SQLException?{
????????dataSourceMap?=?new?HashMap<>(1,?1);
????????dataSourceMap.put("unique",?dataSource);
????????databaseType?=?createDatabaseType();
????}
????
????private?DatabaseType?createDatabaseType()?throws?SQLException?{
????????DatabaseType?result?=?null;
????????for?(DataSource?each?:?dataSourceMap.values())?{
????????????DatabaseType?databaseType?=?createDatabaseType(each);
????????????Preconditions.checkState(null?==?result?||?result?==?databaseType,?String.format("Database?type?inconsistent?with?'%s'?and?'%s'",?result,?databaseType));
????????????result?=?databaseType;
????????}
????????return?result;
????}
????
????/**
?????*?不同數(shù)據(jù)源類型獲取數(shù)據(jù)庫(kù)連接
?????*/
????private?DatabaseType?createDatabaseType(final?DataSource?dataSource)?throws?SQLException?{
????????if?(dataSource?instanceof?AbstractDataSourceAdapter)?{
????????????return?((AbstractDataSourceAdapter)?dataSource).databaseType;
????????}
????????try?(Connection?connection?=?dataSource.getConnection())?{
????????????return?DatabaseTypes.getDatabaseTypeByURL(connection.getMetaData().getURL());
????????}
????}
????
????@Override
????public?final?Connection?getConnection(final?String?username,?final?String?password)?throws?SQLException?{
????????return?getConnection();
????}
????
????@Override
????public?final?void?close()?throws?Exception?{
????????close(dataSourceMap.keySet());
????}
}
AbstractUnsupportedOperationDataSource 實(shí)現(xiàn)DataSource 接口并繼承了 WrapperAdapter 類,它內(nèi)部并沒(méi)有什么具體方法只起到橋接的作用,但看著是不是和我們前邊講適配器模式的例子方式有點(diǎn)相似。
public?abstract?class?AbstractUnsupportedOperationDataSource?extends?WrapperAdapter?implements?DataSource?{
????
????@Override
????public?final?int?getLoginTimeout()?throws?SQLException?{
????????throw?new?SQLFeatureNotSupportedException("unsupported?getLoginTimeout()");
????}
????
????@Override
????public?final?void?setLoginTimeout(final?int?seconds)?throws?SQLException?{
????????throw?new?SQLFeatureNotSupportedException("unsupported?setLoginTimeout(int?seconds)");
????}
}
WrapperAdapter 是一個(gè)包裝器的適配類,實(shí)現(xiàn)了 JDBC 中的 Wrapper 接口,其中有兩個(gè)核心方法 recordMethodInvocation 用于添加需要執(zhí)行的方法和參數(shù),而 replayMethodsInvocation 則將添加的這些方法和參數(shù)通過(guò)反射執(zhí)行。仔細(xì)看不難發(fā)現(xiàn)兩個(gè)方法中都用到了 JdbcMethodInvocation類。
public?abstract?class?WrapperAdapter?implements?Wrapper?{
????
????private?final?Collection?jdbcMethodInvocations?=?new?ArrayList<>();
?
????/**
?????*?添加要執(zhí)行的方法
?????*/
????@SneakyThrows
????public?final?void?recordMethodInvocation(final?Class?targetClass,?final?String?methodName,?final?Class[]?argumentTypes,?final?Object[]?arguments)?{
????????jdbcMethodInvocations.add(new?JdbcMethodInvocation(targetClass.getMethod(methodName,?argumentTypes),?arguments));
????}
????
????/**
?????*?通過(guò)反射執(zhí)行?上邊添加的方法
?????*/
????public?final?void?replayMethodsInvocation(final?Object?target)?{
????????for?(JdbcMethodInvocation?each?:?jdbcMethodInvocations)?{
????????????each.invoke(target);
????????}
????}
}
JdbcMethodInvocation 類主要應(yīng)用反射通過(guò)傳入的 method 方法和 arguments 參數(shù)執(zhí)行對(duì)應(yīng)的方法,這樣就可以通過(guò) JDBC API 調(diào)用非 JDBC 方法了。
@RequiredArgsConstructor
public?class?JdbcMethodInvocation?{
????
????@Getter
????private?final?Method?method;
????
????@Getter
????private?final?Object[]?arguments;
????
????/**
?????*?Invoke?JDBC?method.
?????*?
?????*?@param?target?target?object
?????*/
????@SneakyThrows
????public?void?invoke(final?Object?target)?{
????????method.invoke(target,?arguments);
????}
}
那 Sharding-JDBC 拓展 JDBC API 接口后,在新增的分片功能里又做了哪些事情呢?
一張表經(jīng)過(guò)分庫(kù)分表后被拆分成多個(gè)子表,并分散到不同的數(shù)據(jù)庫(kù)中,在不修改原業(yè)務(wù) SQL 的前提下,Sharding-JDBC 就必須對(duì) SQL進(jìn)行一些改造才能正常執(zhí)行。
大致的執(zhí)行流程:SQL 解析 -> 執(zhí)?器優(yōu)化 -> SQL 路由 -> SQL 改寫 -> SQL 執(zhí)? -> 結(jié)果歸并 六步組成,一起瞅瞅每個(gè)步驟做了點(diǎn)什么。
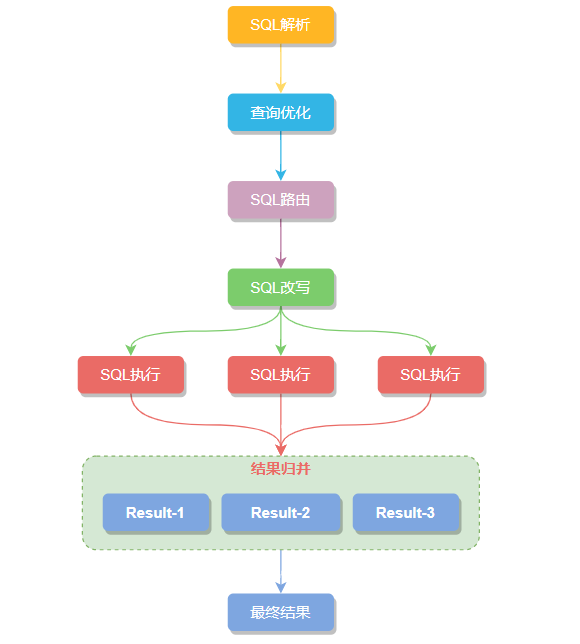
SQL 解析
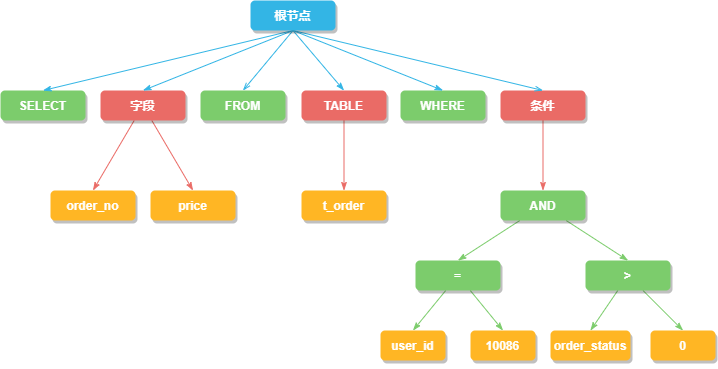
SQL解析過(guò)程分為詞法解析和語(yǔ)法解析兩步,比如下邊這條查詢用戶訂單的SQL,先用詞法解析將SQL拆解成不可再分的原子單元。在根據(jù)不同數(shù)據(jù)庫(kù)方言所提供的字典,將這些單元?dú)w類為關(guān)鍵字,表達(dá)式,變量或者操作符等類型。
SELECT?order_no,price?FROM?t_order_?where?user_id?=?10086?and?order_status?>?0
接著語(yǔ)法解析會(huì)將拆分后的SQL轉(zhuǎn)換為抽象語(yǔ)法樹(shù),通過(guò)對(duì)抽象語(yǔ)法樹(shù)遍歷,提煉出分片所需的上下文,上下文包含查詢字段信息(Field)、表信息(Table)、查詢條件(Condition)、排序信息(Order By)、分組信息(Group By)以及分頁(yè)信息(Limit)等,并標(biāo)記出 SQL中有可能需要改寫的位置。
執(zhí)?器優(yōu)化
執(zhí)?器優(yōu)化對(duì)SQL分片條件進(jìn)行優(yōu)化,處理像關(guān)鍵字 OR這種影響性能的壞味道。
SQL 路由
SQL 路由通過(guò)解析分片上下文,匹配到用戶配置的分片策略,并生成路由路徑。簡(jiǎn)單點(diǎn)理解就是可以根據(jù)我們配置的分片策略計(jì)算出 SQL該在哪個(gè)庫(kù)的哪個(gè)表中執(zhí)行,而SQL路由又根據(jù)有無(wú)分片健區(qū)分出 分片路由 和 廣播路由。
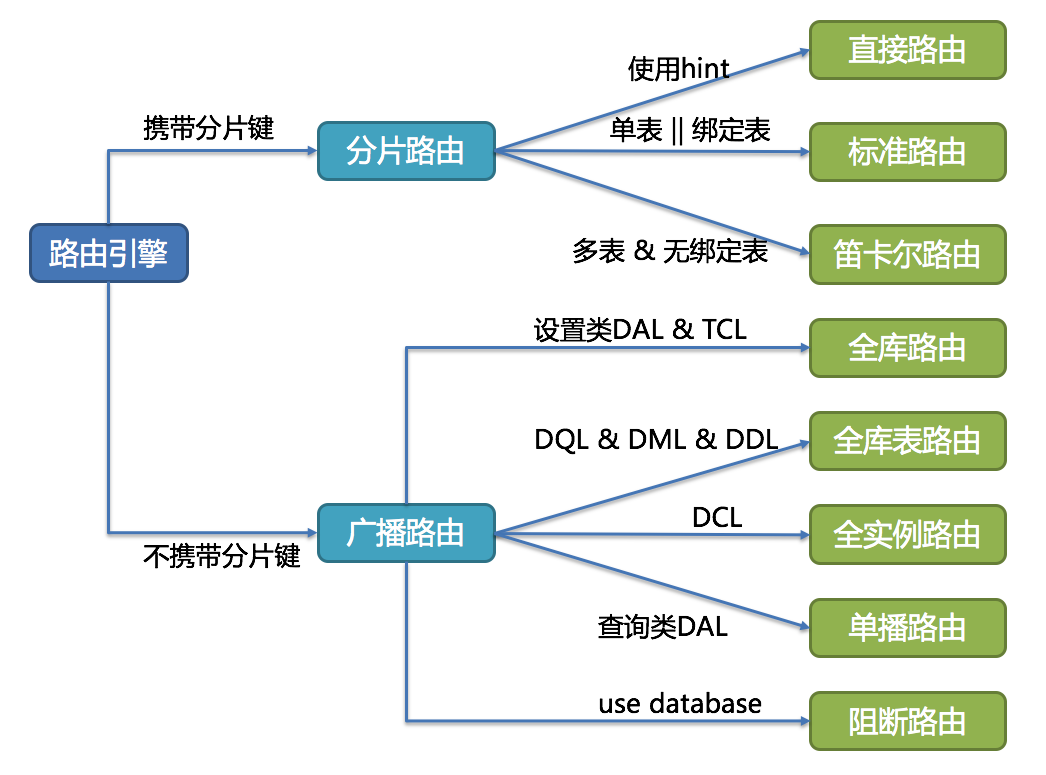
有分?鍵的路由叫分片路由,細(xì)分為直接路由、標(biāo)準(zhǔn)路由和笛卡爾積路由這3種類型。
標(biāo)準(zhǔn)路由
標(biāo)準(zhǔn)路由是最推薦也是最為常?的分??式,它的適?范圍是不包含關(guān)聯(lián)查詢或僅包含綁定表之間關(guān)聯(lián)查詢的SQL。
當(dāng) SQL分片健的運(yùn)算符為 = 時(shí),路由結(jié)果將落?單庫(kù)(表),當(dāng)分?運(yùn)算符是BETWEEN 或IN 等范圍時(shí),路由結(jié)果則不?定落?唯?的庫(kù)(表),因此?條邏輯SQL最終可能被拆分為多條?于執(zhí)?的真實(shí)SQL。
SELECT?*?FROM?t_order??where?t_order_id?in?(1,2)
SQL路由處理后
SELECT?*?FROM?t_order_0??where?t_order_id?in?(1,2)
SELECT?*?FROM?t_order_1??where?t_order_id?in?(1,2)
直接路由
直接路由是通過(guò)使用 HintAPI 直接將 SQL路由到指定?庫(kù)表的一種分?方式,而且直接路由可以?于分?鍵不在SQL中的場(chǎng)景,還可以執(zhí)?包括?查詢、?定義函數(shù)等復(fù)雜情況的任意SQL。
比如根據(jù) t_order_id 字段為條件查詢訂單,此時(shí)希望在不修改SQL的前提下,加上 user_id作為分片條件就可以使用直接路由。
笛卡爾積路由
笛卡爾路由是由?綁定表之間的關(guān)聯(lián)查詢產(chǎn)生的,查詢性能較低盡量避免走此路由模式。
無(wú)分?鍵的路由又叫做廣播路由,可以劃分為全庫(kù)表路由、全庫(kù)路由、 全實(shí)例路由、單播路由和阻斷路由這 5種類型。
全庫(kù)表路由
全庫(kù)表路由針對(duì)的是數(shù)據(jù)庫(kù) DQL和 DML,以及 DDL等操作,當(dāng)我們執(zhí)行一條邏輯表 t_order SQL時(shí),在所有分片庫(kù)中對(duì)應(yīng)的真實(shí)表 t_order_0 ··· ?t_order_n 內(nèi)逐一執(zhí)行。
全庫(kù)路由
全庫(kù)路由主要是對(duì)數(shù)據(jù)庫(kù)層面的操作,比如數(shù)據(jù)庫(kù) SET 類型的數(shù)據(jù)庫(kù)管理命令,以及 TCL 這樣的事務(wù)控制語(yǔ)句。
對(duì)邏輯庫(kù)設(shè)置 autocommit 屬性后,所有對(duì)應(yīng)的真實(shí)庫(kù)中都執(zhí)行該命令。
SET?autocommit=0;
復(fù)制代碼
全實(shí)例路由
全實(shí)例路由是針對(duì)數(shù)據(jù)庫(kù)實(shí)例的 DCL 操作(設(shè)置或更改數(shù)據(jù)庫(kù)用戶或角色權(quán)限),比如:創(chuàng)建一個(gè)用戶 order ,這個(gè)命令將在所有的真實(shí)庫(kù)實(shí)例中執(zhí)行,以此確保 order 用戶可以正常訪問(wèn)每一個(gè)數(shù)據(jù)庫(kù)實(shí)例。
CREATE?USER?order@127.0.0.1?identified?BY?'程序員內(nèi)點(diǎn)事';
單播路由
單播路由用來(lái)獲取某一真實(shí)表信息,比如獲得表的描述信息:
DESCRIBE?t_order;?
t_order 的真實(shí)表是 t_order_0 ···· t_order_n,他們的描述結(jié)構(gòu)相完全同,我們只需在任意的真實(shí)表執(zhí)行一次就可以。
阻斷路由
?來(lái)屏蔽SQL對(duì)數(shù)據(jù)庫(kù)的操作,例如:
USE?order_db;
這個(gè)命令不會(huì)在真實(shí)數(shù)據(jù)庫(kù)中執(zhí)?,因?yàn)?ShardingSphere 采?的是邏輯 Schema(數(shù)據(jù)庫(kù)的組織和結(jié)構(gòu)) ?式,所以無(wú)需將切換數(shù)據(jù)庫(kù)的命令發(fā)送?真實(shí)數(shù)據(jù)庫(kù)中。
SQL 改寫
將基于邏輯表開(kāi)發(fā)的SQL改寫成可以在真實(shí)數(shù)據(jù)庫(kù)中可以正確執(zhí)行的語(yǔ)句。比如查詢 t_order 訂單表,我們實(shí)際開(kāi)發(fā)中 SQL是按邏輯表 t_order 寫的。
SELECT?*?FROM?t_order
但分庫(kù)分表以后真實(shí)數(shù)據(jù)庫(kù)中 t_order 表就不存在了,而是被拆分成多個(gè)子表 t_order_n 分散在不同的數(shù)據(jù)庫(kù)內(nèi),還按原SQL執(zhí)行顯然是行不通的,這時(shí)需要將分表配置中的邏輯表名稱改寫為路由之后所獲取的真實(shí)表名稱。
SELECT?*?FROM?t_order_n
SQL執(zhí)?
將路由和改寫后的真實(shí) SQL 安全且高效發(fā)送到底層數(shù)據(jù)源執(zhí)行。但這個(gè)過(guò)程并不是簡(jiǎn)單的將 SQL 通過(guò)JDBC 直接發(fā)送至數(shù)據(jù)源執(zhí)行,而是平衡數(shù)據(jù)源連接創(chuàng)建以及內(nèi)存占用所產(chǎn)生的消耗,它會(huì)自動(dòng)化的平衡資源控制與執(zhí)行效率。
結(jié)果歸并
將從各個(gè)數(shù)據(jù)節(jié)點(diǎn)獲取的多數(shù)據(jù)結(jié)果集,合并成一個(gè)大的結(jié)果集并正確的返回至請(qǐng)求客戶端,稱為結(jié)果歸并。而我們SQL中的排序、分組、分頁(yè)和聚合等語(yǔ)法,均是在歸并后的結(jié)果集上進(jìn)行操作的。
Sharding-JDBC快速實(shí)踐
下面我們結(jié)合 Springboot + mybatisplus 快速搭建一個(gè)分庫(kù)分表案例。
1、準(zhǔn)備工作
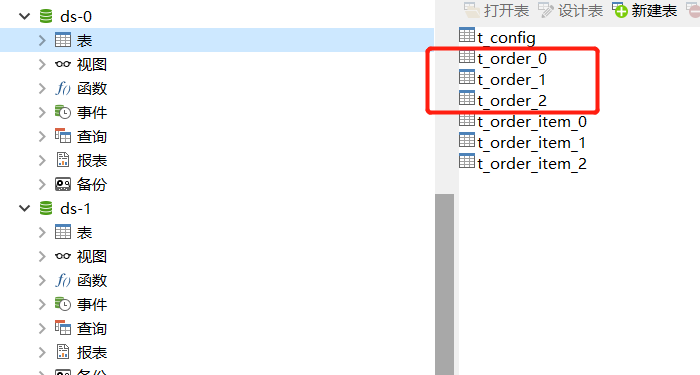
先做準(zhǔn)備工作,創(chuàng)建兩個(gè)數(shù)據(jù)庫(kù) ds-0、ds-1,兩個(gè)庫(kù)中分別建表 t_order_0、t_order_1、t_order_2 、t_order_item_0、t_order_item_1、t_order_item_2,t_config,方便后邊驗(yàn)證廣播表、綁定表的場(chǎng)景。
表結(jié)構(gòu)如下:
t_order_0 訂單表
CREATE?TABLE?`t_order_0`?(
??`order_id`?bigint(200)?NOT?NULL,
??`order_no`?varchar(100)?DEFAULT?NULL,
??`create_name`?varchar(50)?DEFAULT?NULL,
??`price`?decimal(10,2)?DEFAULT?NULL,
??PRIMARY?KEY?(`order_id`)
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8?ROW_FORMAT=DYNAMIC;
t_order_0 與 t_order_item_0 ?互為關(guān)聯(lián)表
CREATE?TABLE?`t_order_item_0`?(
??`item_id`?bigint(100)?NOT?NULL,
??`order_no`?varchar(200)?NOT?NULL,
??`item_name`?varchar(50)?DEFAULT?NULL,
??`price`?decimal(10,2)?DEFAULT?NULL,
??PRIMARY?KEY?(`item_id`)
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8?ROW_FORMAT=DYNAMIC;
廣播表 t_config
CREATE?TABLE?`t_config`?(
??`id`?bigint(30)?NOT?NULL,
??`remark`?varchar(50)?CHARACTER?SET?utf8?DEFAULT?NULL,
??`create_time`?timestamp?NOT?NULL?DEFAULT?CURRENT_TIMESTAMP,
??`last_modify_time`?timestamp?NOT?NULL?DEFAULT?CURRENT_TIMESTAMP?ON?UPDATE?CURRENT_TIMESTAMP,
??PRIMARY?KEY?(`id`)
)?ENGINE=InnoDB?DEFAULT?CHARSET=latin1;
ShardingSphere 提供了4種分片配置方式:
Java 代碼配置 Yaml 、properties 配置 Spring 命名空間配置 Spring Boot配置
為讓代碼看上去更簡(jiǎn)潔和直觀,后邊統(tǒng)一使用 properties 配置的方式,引入 shardingsphere 對(duì)應(yīng)的 sharding-jdbc-spring-boot-starter 和 sharding-core-common 包,版本統(tǒng)一用的 4.0.0-RC1。
2、分片配置
<dependency>
?<groupId>org.apache.shardingspheregroupId>
?<artifactId>sharding-jdbc-spring-boot-starterartifactId>
?<version>4.0.0-RC1version>
dependency>
<dependency>
?<groupId>org.apache.shardingspheregroupId>
?<artifactId>sharding-core-commonartifactId>
?<version>4.0.0-RC1version>
dependency>
準(zhǔn)備工作做完( mybatis 搭建就不贅述了),接下來(lái)我們逐一解讀分片配置信息。
我們首先定義兩個(gè)數(shù)據(jù)源 ds-0、ds-1,并分別加上數(shù)據(jù)源的基礎(chǔ)信息。
# 定義兩個(gè)全局?jǐn)?shù)據(jù)源
spring.shardingsphere.datasource.names=ds-0,ds-1
# 配置數(shù)據(jù)源 ds-0
spring.shardingsphere.datasource.ds-0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-0.driverClassName=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-0.url=jdbc:mysql://127.0.0.1:3306/ds-0?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=root
# 配置數(shù)據(jù)源 ds-1
spring.shardingsphere.datasource.ds-1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-1.driverClassName=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-1.url=jdbc:mysql://127.0.0.1:3306/ds-1?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
spring.shardingsphere.datasource.ds-1.username=root
spring.shardingsphere.datasource.ds-1.password=root
配置完數(shù)據(jù)源接下來(lái)為表添加分庫(kù)和分表策略,使用 sharding-jdbc 做分庫(kù)分表需要我們?yōu)槊恳粋€(gè)表單獨(dú)設(shè)置分片規(guī)則。
# 配置分片表 t_order
# 指定真實(shí)數(shù)據(jù)節(jié)點(diǎn)
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..2}
actual-data-nodes 屬性指定分片的真實(shí)數(shù)據(jù)節(jié)點(diǎn),$是一個(gè)占位符,{0..1}表示實(shí)際拆分的數(shù)據(jù)庫(kù)表數(shù)量。
ds-$->{0..1}.t_order_$->{0..2} ?表達(dá)式相當(dāng)于 6個(gè)數(shù)據(jù)節(jié)點(diǎn)
ds-0.t_order_0 ds-0.t_order_1 ds-0.t_order_2 ds-1.t_order_0 ds-1.t_order_1 ds-1.t_order_2
### 分庫(kù)策略
# 分庫(kù)分片健
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=order_id
# 分庫(kù)分片算法
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds-$->{order_id % 2}
為表設(shè)置分庫(kù)策略,上邊講了 sharding-jdbc 它提供了四種分片策略,為快速搭建我們先以最簡(jiǎn)單的行內(nèi)表達(dá)式分片策略來(lái)實(shí)現(xiàn),在下一篇會(huì)介紹四種分片策略的詳細(xì)用法和使用場(chǎng)景。
database-strategy.inline.sharding-column ?屬性中 database-strategy ?為分庫(kù)策略,inline ?為具體的分片策略,sharding-column ?代表分片健。
database-strategy.inline.algorithm-expression 是當(dāng)前策略下具體的分片算法,ds-$->{order_id % 2} 表達(dá)式意思是 對(duì) order_id字段進(jìn)行取模分庫(kù),2 代表分片庫(kù)的個(gè)數(shù),不同的策略對(duì)應(yīng)不同的算法,這里也可以是我們自定義的分片算法類。
# 分表策略
# 分表分片健
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
# 分表算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 3}
# 自增主鍵字段
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
# 自增主鍵ID 生成方案
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
分表策略 和 分庫(kù)策略 的配置比較相似,不同的是分表可以通過(guò) key-generator.column 和 key-generator.type 設(shè)置自增主鍵以及指定自增主鍵的生成方案,目前內(nèi)置了SNOWFLAKE 和 UUID 兩種方式,還能自定義的主鍵生成算法類,后續(xù)會(huì)詳細(xì)的講解。
# 綁定表關(guān)系
spring.shardingsphere.sharding.binding-tables= t_order,t_order_item
必須按相同分片健進(jìn)行分片的表才能互為成綁定表,在聯(lián)合查詢時(shí)就能避免出現(xiàn)笛卡爾積查詢。
# 配置廣播表
spring.shardingsphere.sharding.broadcast-tables=t_config
廣播表,開(kāi)啟 SQL解析日志,能清晰的看到 SQL分片解析的過(guò)程
# 是否開(kāi)啟 SQL解析日志
spring.shardingsphere.props.sql.show=true
3、驗(yàn)證分片
分片配置完以后我們無(wú)需在修改業(yè)務(wù)代碼了,直接執(zhí)行業(yè)務(wù)邏輯的增、刪、改、查即可,接下來(lái)驗(yàn)證一下分片的效果。
我們同時(shí)向 t_order、t_order_item 表插入 5條訂單記錄,并不給定主鍵 order_id ,item_id 字段值。
public?String?insertOrder()?{
???for?(int?i?=?0;?i?4;?i++)?{
???????TOrder?order?=?new?TOrder();
???????order.setOrderNo("A000"?+?i);
???????order.setCreateName("訂單?"?+?i);
???????order.setPrice(new?BigDecimal(""?+?i));
???????orderRepository.insert(order);
???????TOrderItem?orderItem?=?new?TOrderItem();
???????orderItem.setOrderId(order.getOrderId());
???????orderItem.setOrderNo("A000"?+?i);
???????orderItem.setItemName("服務(wù)項(xiàng)目"?+?i);
???????orderItem.setPrice(new?BigDecimal(""?+?i));
???????orderItemRepository.insert(orderItem);
???}
???return?"success";
}
看到訂單記錄被成功分散到了不同的庫(kù)表中, order_id 字段也自動(dòng)生成了主鍵ID,基礎(chǔ)的分片功能就完成了。
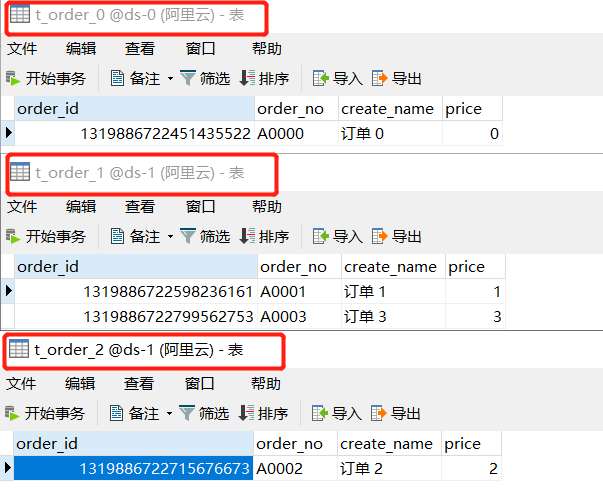
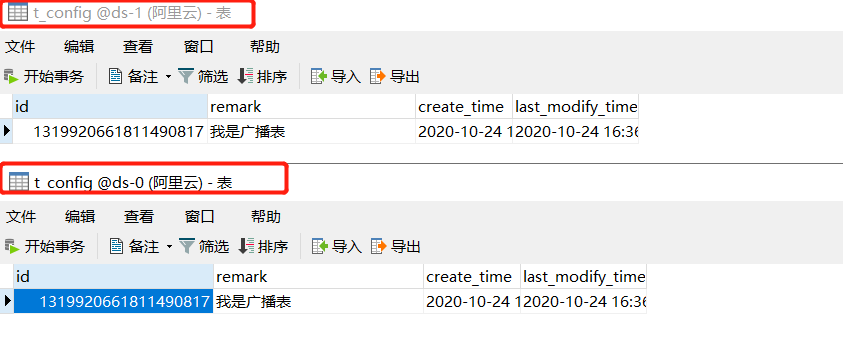
那向廣播表 t_config 中插入一條數(shù)據(jù)會(huì)是什么效果呢?
public?String?config()?{
????TConfig?tConfig?=?new?TConfig();
????tConfig.setRemark("我是廣播表");
????tConfig.setCreateTime(new?Date());
????tConfig.setLastModifyTime(new?Date());
????configRepository.insert(tConfig);
????return?"success";
}
發(fā)現(xiàn)所有庫(kù)中 t_config 表都執(zhí)行了這條SQL,廣播表和 MQ廣播訂閱的模式很相似,所有訂閱的客戶端都會(huì)收到同一條消息。
簡(jiǎn)單SQL操作驗(yàn)證沒(méi)問(wèn)通,接下來(lái)在試試復(fù)雜一點(diǎn)的聯(lián)合查詢,前邊我們已經(jīng)把 t_order 、t_order_item 表設(shè)為綁定表,直接聯(lián)表查詢執(zhí)行一下。
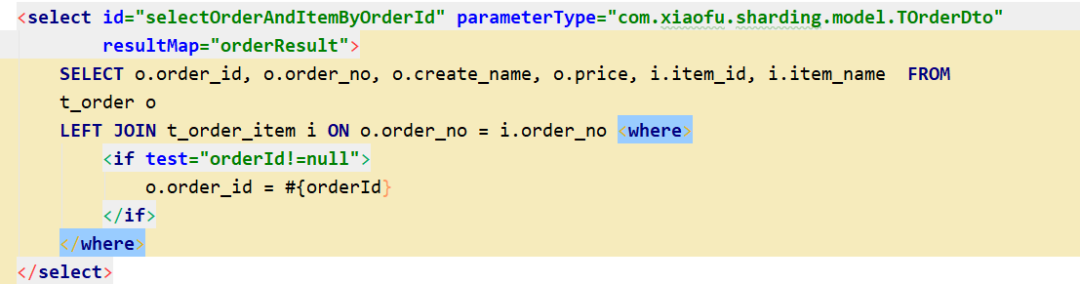
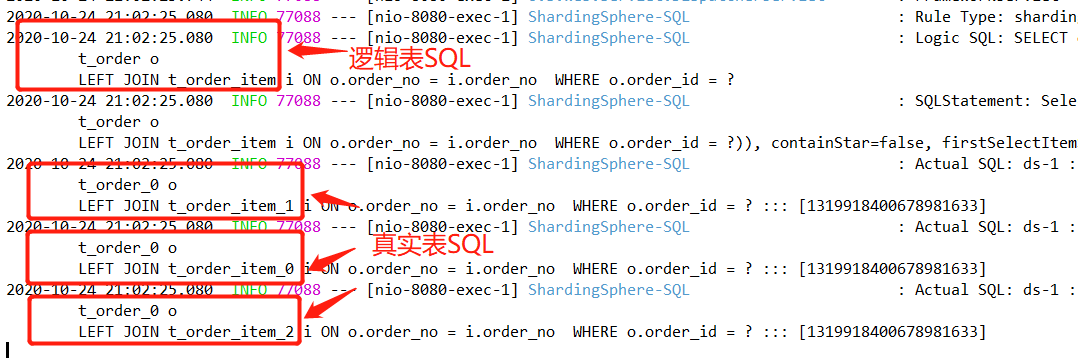
通過(guò)控制臺(tái)日志發(fā)現(xiàn),邏輯表SQL 經(jīng)過(guò)解析以后,只對(duì) ?t_order_0 和 t_order_item_0 表進(jìn)行了關(guān)聯(lián)產(chǎn)生一條SQL。

那如果不互為綁定表又會(huì)是什么情況呢?去掉 spring.shardingsphere.sharding.binding-tables試一下。
發(fā)現(xiàn)控制臺(tái)解析出了 3條真實(shí)表SQL,而去掉 order_id 作為查詢條件再次執(zhí)行后,結(jié)果解析出了 9條SQL,進(jìn)行了笛卡爾積查詢。所以相比之下綁定表的優(yōu)點(diǎn)就不言而喻了。
總結(jié)
這篇文章首先簡(jiǎn)單的回顧一下分庫(kù)分表的基礎(chǔ)知識(shí)。
然后對(duì)分庫(kù)分表中間件 sharding-jdbc 的基礎(chǔ)概念做了簡(jiǎn)單梳理,快速的搭建了一個(gè)分庫(kù)分表案例,但這只是實(shí)踐分庫(kù)分表的第一步,下一篇我們會(huì)詳細(xì)的介紹四種分片策略的具體用法和使用場(chǎng)景(必知必會(huì)),后邊將陸續(xù)講解自定義分布式主鍵、分布式數(shù)據(jù)庫(kù)事務(wù)、分布式服務(wù)治理,數(shù)據(jù)脫敏等。
案例
GitHub地址:https://github.com/chengxy-nds/Springboot-Notebook/tree/master/springboot-sharding-jdbc
后記
最近寫的一些干貨,每篇都很用心,歡迎各位小伙伴閱讀/點(diǎn)贊/分享:
我是Guide哥,Java后端開(kāi)發(fā),會(huì)一點(diǎn)前端知識(shí),喜歡烹飪,自由的少年。一個(gè)三觀比主角還正的技術(shù)人。我們下期再見(jiàn)!