
MySQL慢查詢:慢SQL定位、日志分析與優(yōu)化方案,真心不錯(cuò)!
點(diǎn)擊關(guān)注公眾號,Java干貨及時(shí)送達(dá)
來源:blog.csdn.net/qq_32828253/article/details/109526742
一個(gè)sql執(zhí)行很慢的就叫慢sql,一般來說sql語句執(zhí)行超過5s就能夠算是慢sql,需要進(jìn)行優(yōu)化了
為何要對慢SQL進(jìn)行治理
每一個(gè)SQL都需要消耗一定的I/O資源,SQL執(zhí)行的快慢直接決定了資源被占用時(shí)間的長短。假設(shè)業(yè)務(wù)要求每秒需要完成100條SQL的執(zhí)行,而其中10條SQL執(zhí)行時(shí)間長導(dǎo)致每秒只能完成90條SQL,所有新的SQL將進(jìn)入排隊(duì)等待,直接影響業(yè)務(wù)
治理的優(yōu)先級
master數(shù)據(jù)庫->slave數(shù)據(jù)庫:采用讀寫分離架構(gòu),讀在從庫slave上執(zhí)行,寫在主庫master上執(zhí)行。但由于從庫的數(shù)據(jù)都是在主庫復(fù)制過去的,主庫如果等待較多的情況,會加大從庫的復(fù)制延時(shí)
執(zhí)行SQL次數(shù)多的優(yōu)先治理
某張表被高并發(fā)集中訪問的優(yōu)先治理
MySQL執(zhí)行原理
為了更好的優(yōu)化慢SQL,我們來簡單了解下MySQL的執(zhí)行原理
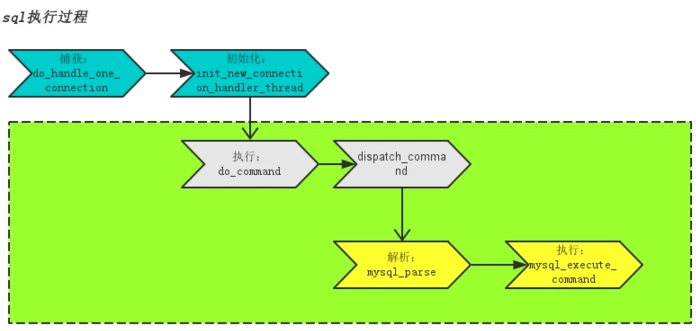
綠色部分為SQL實(shí)際執(zhí)行部分,主要分為兩步:
解析:詞法解析->語法解析->邏輯計(jì)劃->查詢優(yōu)化->物理執(zhí)行計(jì)劃,過程中會檢查緩存是否可用,如果沒有可用緩存則進(jìn)入下一步mysql_execute_command執(zhí)行
執(zhí)行:檢查用戶、表權(quán)限->表加上共享讀鎖->取數(shù)據(jù)到query_cache->取消共享讀鎖
如何發(fā)現(xiàn)慢查詢SQL
-- 修改慢查詢時(shí)間,只能當(dāng)前會話有效;set long_query_time=1; --- 啟用慢查詢 ,加上global,不然會報(bào)錯(cuò)的;set global slow_query_log='ON';---- 是否開啟慢查詢;show variables like "%slow%";---- 查詢慢查詢SQL狀況;show status like "%slow%"; ---- 慢查詢時(shí)間(默認(rèn)情況下MySQL認(rèn)位10秒以上才是慢查詢)show variables like "long_query_time"; --
除了sql的方式,我們也可以在配置文件(my.ini)中修改,加入配置時(shí)必須要在[mysqld]后面加入
-- 開啟日志;slow_query_log = on ---- 記錄日志的log文件(注意:window上必須寫絕對路徑)slow_query_log_file = D:/mysql5.5.16/data/show-slow.log---- 最長查詢的秒數(shù);long_query_time = 2 ---- 表示記錄沒有使用索引的查詢log-queries-not-using-indexes --
開啟慢查詢會帶來CPU損耗與日志記錄的IO開銷,所以建議間斷性的打開慢查詢?nèi)罩緛碛^察MySQL運(yùn)行狀態(tài)
慢查詢分析示例
假設(shè)我們有一條SQL
SELECT * FROM `emp` where ename like '%mQspyv%';執(zhí)行時(shí)間為1.163s,而我們設(shè)置的慢查詢時(shí)間為1s,這時(shí)我們可以打開慢查詢?nèi)罩具M(jìn)行日志分析:
# Time: 150530 15:30:58 -- -- 該查詢發(fā)生在2015-5-30 15:30:58# User@Host: root[root] @ localhost [127.0.0.1] -- --是誰,在什么主機(jī)上發(fā)生的查詢# Query_time: 1.134065 Lock_time: 0.000000 Rows_sent: 8 Rows_examined: 4000000 Query_time: --查詢總共用了多少時(shí)間,Lock_time: 在查詢時(shí)鎖定表的時(shí)間,Rows_sent: 返回多少rows數(shù)據(jù),Rows_examined: 表掃描了400W行數(shù)據(jù)才得到的結(jié)果;
如果我們的慢SQL很多,人工分析肯定分析不過來,這時(shí)候我們就需要借助一些分析工具,MySQL自帶了一個(gè)慢查詢分析工具mysqldumpslow,以下是常見使用示例
mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.logmysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.logmysqldumpslow -s t -t 10 -g “l(fā)eft join” /database/mysql/slow-logmysqldumpslow -s r -t 10 -g 'left join' /var/run/mysqld/mysqldslow.log
SQL語句常見優(yōu)化
只要簡單了解過MySQL內(nèi)部優(yōu)化機(jī)制,就很容易寫出高性能的SQL
1.不使用子查詢:
SELECT * FROM t1 WHERE id (SELECT id FROM t2 WHERE name='hechunyang');在MySQL5.5版本中,內(nèi)部執(zhí)行計(jì)劃器是先查外表再匹配內(nèi)表,如果外表數(shù)據(jù)量很大,查詢速度會非常慢
在MySQL5.6中,有對內(nèi)查詢做了優(yōu)化,優(yōu)化后SQL如下
SELECT t1.* FROM t1 JOIN t2 ON t1.id = t2.id;但也僅針對select語句有效,update、delete子查詢無效,所以生成環(huán)境不建議使用子查詢
2.避免函數(shù)索引
SELECT * FROM t WHERE YEAR(d) >= 2016;即使d字段有索引,也會全盤掃描,應(yīng)該優(yōu)化為:
SELECT * FROM t WHERE d >= '2016-01-01';3.使用IN替換OR
SELECT * FROM t WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30;非聚簇索引走了3次,使用IN之后只走一次:
SELECT * FROM t WHERE LOC_IN IN (10,20,30);4.LIKE雙百分號無法使用到索引
SELECT * FROM t WHERE name LIKE '%de%';應(yīng)優(yōu)化為右模糊
SELECT * FROM t WHERE name LIKE 'de%';5.增加LIMIT M,N 限制讀取的條數(shù)
6.避免數(shù)據(jù)類型不一致
SELECT * FROM t WHERE id = '19';應(yīng)優(yōu)化為
SELECT * FROM t WHERE id = 19;7.分組統(tǒng)計(jì)時(shí)可以禁止排序
SELECT goods_id,count(*) FROM t GROUP BY goods_id;默認(rèn)情況下MySQL會對所有GROUP BY co1,col2 …的字段進(jìn)行排序,我們可以對其使用ORDER BY NULL禁止排序,避免排序消耗資源
SELECT goods_id,count(*) FROM t GROUP BY goods_id ORDER BY NULL;8.去除不必要的ORDER BY語句
總結(jié)
總的來說,我們知道曼查詢的SQL后,優(yōu)化方案可以做如下嘗試:
SQL語句優(yōu)化,盡量精簡,去除非必要語句
索引優(yōu)化,讓所有SQL都能夠走索引
如果是表的瓶頸問題,則分表,單表數(shù)據(jù)量維持在1000W以內(nèi)
如果是單庫瓶頸問題,則分庫,讀寫分離
如果是物理機(jī)器性能問題,則分多個(gè)數(shù)據(jù)庫節(jié)點(diǎn)
????
往 期 推 薦
1、拖動文件就能觸發(fā)7-Zip安全漏洞,波及所有版本
3、一次 SQL 查詢優(yōu)化原理分析:900W+ 數(shù)據(jù),從 17s 到 300ms
點(diǎn)分享
點(diǎn)收藏
點(diǎn)點(diǎn)贊
點(diǎn)在看




