鏈接:https://zhuanlan.zhihu.com/p/354060133編輯:深度學(xué)習(xí)與計(jì)算機(jī)視覺本文約3300字,建議閱讀7分鐘
本文為你介紹基于深度學(xué)習(xí)的目標(biāo)檢測算法。
整體框架
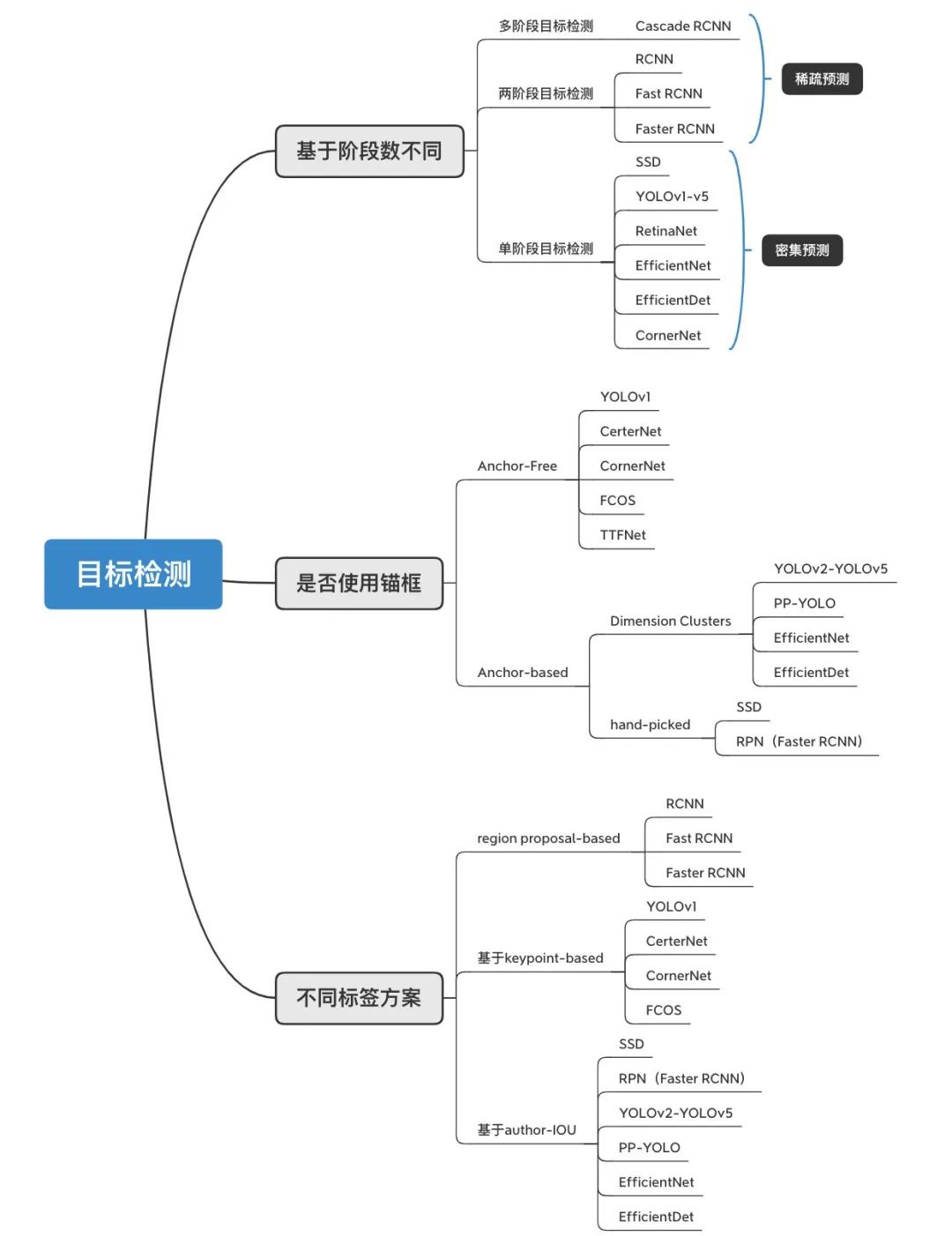 目標(biāo)檢測算法主要包括:【兩階段】目標(biāo)檢測算法、【多階段】目標(biāo)檢測算法、【單階段】目標(biāo)檢測算法。什么是兩階段目標(biāo)檢測算法,與單階段目標(biāo)檢測有什么區(qū)別?兩階段目標(biāo)檢測算法因需要進(jìn)行兩階段的處理:1)候選區(qū)域的獲取,2)候選區(qū)域分類和回歸,也稱為基于區(qū)域(Region-based)的方。與單階段目標(biāo)檢測算法的區(qū)別:通過聯(lián)合解碼同時(shí)獲取候選區(qū)域、類別。【兩階段】和【多階段】目標(biāo)檢測算法統(tǒng)稱級(jí)聯(lián)目標(biāo)檢測算法,【多階段】目標(biāo)檢測算法通過多次重復(fù)進(jìn)行步驟:1)候選區(qū)域的獲取,2)候選區(qū)域分類和回歸,反復(fù)修正候選區(qū)域。
目標(biāo)檢測算法主要包括:【兩階段】目標(biāo)檢測算法、【多階段】目標(biāo)檢測算法、【單階段】目標(biāo)檢測算法。什么是兩階段目標(biāo)檢測算法,與單階段目標(biāo)檢測有什么區(qū)別?兩階段目標(biāo)檢測算法因需要進(jìn)行兩階段的處理:1)候選區(qū)域的獲取,2)候選區(qū)域分類和回歸,也稱為基于區(qū)域(Region-based)的方。與單階段目標(biāo)檢測算法的區(qū)別:通過聯(lián)合解碼同時(shí)獲取候選區(qū)域、類別。【兩階段】和【多階段】目標(biāo)檢測算法統(tǒng)稱級(jí)聯(lián)目標(biāo)檢測算法,【多階段】目標(biāo)檢測算法通過多次重復(fù)進(jìn)行步驟:1)候選區(qū)域的獲取,2)候選區(qū)域分類和回歸,反復(fù)修正候選區(qū)域。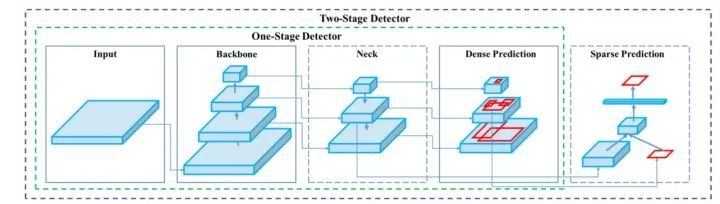
根據(jù)是否屬于錨框分為:
主要考慮問題
兩階段目標(biāo)檢測算法
RCNN
1、模型通過【選擇性搜索算法】獲取潛在的候選區(qū)域2、截取原圖每個(gè)候選區(qū)域并resize輸入到模型中進(jìn)行特征抽取3、使用SVM進(jìn)行分類,以及進(jìn)行bounding box 回歸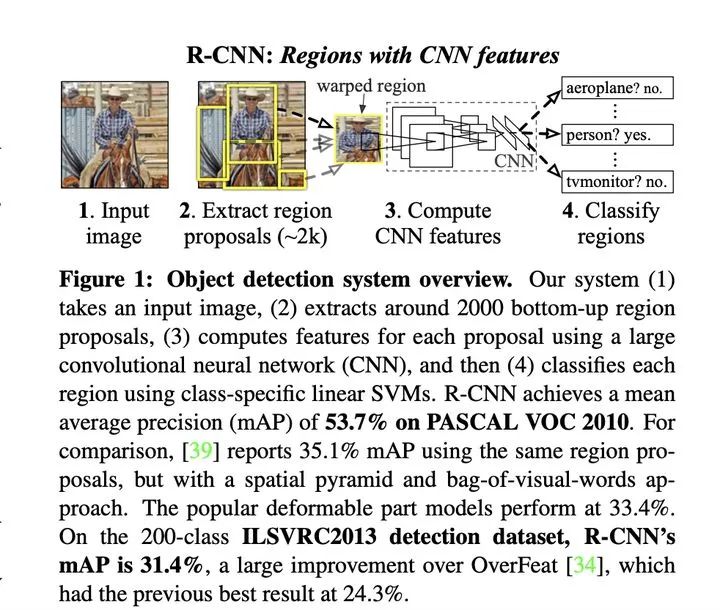
存在問題:
重復(fù)編碼:由于候選區(qū)域存在重疊,模型需要重復(fù)進(jìn)行重疊區(qū)域的特征圖提取,計(jì)算冗余。模型訓(xùn)練:由于特征抽取模型和區(qū)域的分類回歸模型分開訓(xùn)練,無法進(jìn)行端到端的模型訓(xùn)練,訓(xùn)練過程需要提取每個(gè)包含重疊區(qū)域的候選區(qū)域特征并保存用于分類和回歸訓(xùn)練。實(shí)時(shí)性差:重復(fù)編碼導(dǎo)致實(shí)時(shí)性不佳,【選擇性搜索算法】耗時(shí)嚴(yán)重。
Fast-RCNN
考慮到RCNN的缺點(diǎn),F(xiàn)ast-RCNN來了!1、模型依舊通過【選擇性搜索算法】獲取潛在的候選區(qū)域。2、將原圖通過特征抽取模型進(jìn)行一次的共享特征圖提取,避免了重復(fù)編碼。3、在特征圖中找到每一個(gè)候選區(qū)域?qū)?yīng)的區(qū)域并截取【區(qū)域特征圖】,ROI pooling層中將每個(gè)【區(qū)域特征圖】池化到統(tǒng)一大小。4、分別進(jìn)行softmax分類(使用softmax代替了RCNN里面的多個(gè)SVM分類器)和bbox回歸。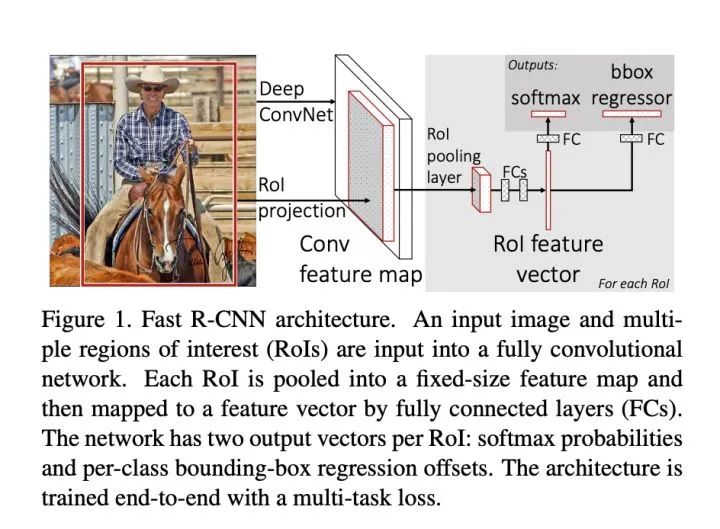
主要優(yōu)點(diǎn):
2、不需要存儲(chǔ)中間特征向量用于SVM分類和回歸模型訓(xùn)練。3、使用更高效的SPPnet特征提取網(wǎng)絡(luò)。存在問題:
實(shí)時(shí)性差:選擇性搜索獲取候選區(qū)域耗時(shí),主要通過貪婪算法合并低級(jí)特征超像素,單張圖片耗時(shí)接近2s,且無法使用GPU加速。Faster R-CNN
使用RPN網(wǎng)絡(luò)代替Fast RCNN使用的選擇性搜索進(jìn)行候選區(qū)域的提取,相當(dāng)于Faster R-CNN=RPN+Fast RCNN,且RPN和Fast RCNN共享卷積層。1、多尺度目標(biāo):通過RPN網(wǎng)絡(luò)候選區(qū)域,并使用不同大小和長寬比的anchors來解決多尺度問題。2、通過計(jì)算anchors與真實(shí)框的交并比IOU,并通過閾值建立正負(fù)樣本。3、樣本不平衡:每批次隨機(jī)采樣256個(gè)anchors進(jìn)行邊框回歸訓(xùn)練,并盡可能保證正負(fù)樣本數(shù)相同,避免負(fù)樣本過多導(dǎo)致的梯度統(tǒng)治問題。論文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks。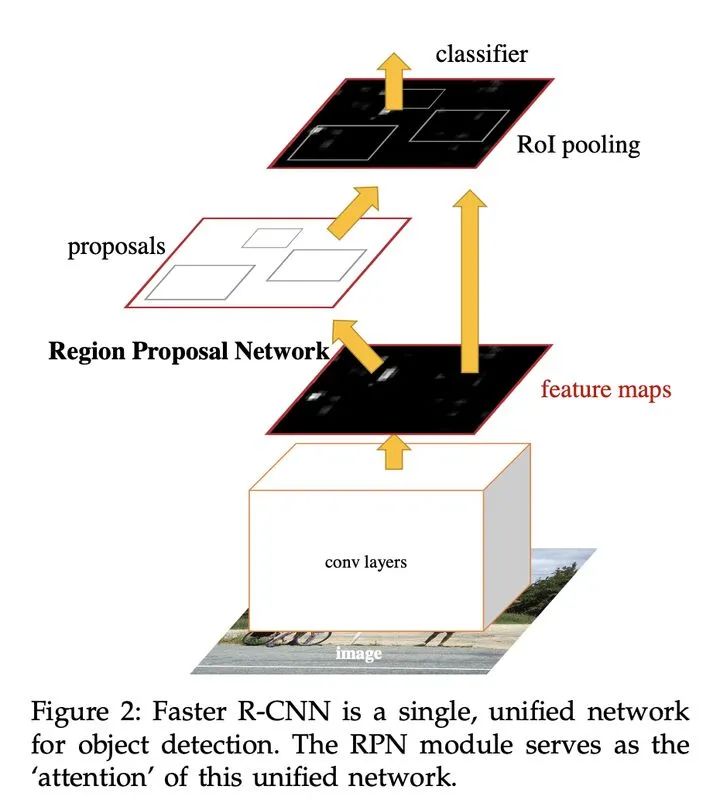
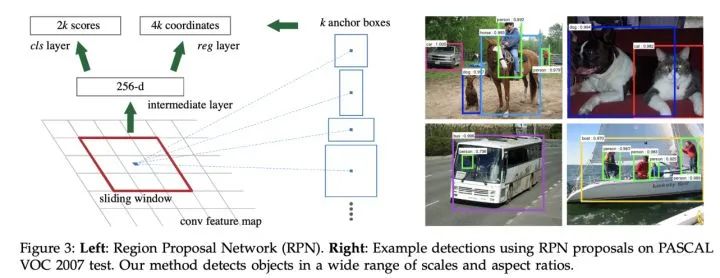
多階段目標(biāo)檢測算法
Cascade R-CNN
通過分析Faster RCNN在目標(biāo)候選區(qū)域的位置修正能力, 如下圖基于單個(gè)檢測器的可優(yōu)化性但優(yōu)化的程度有限,通過多次將預(yù)測區(qū)域作為候選區(qū)域進(jìn)行修正,使得輸出的預(yù)測區(qū)域與真實(shí)標(biāo)簽區(qū)域的IOU逐級(jí)遞增。
主要優(yōu)點(diǎn):
1、準(zhǔn)確性:碾壓各種單雙階段目標(biāo)檢測算法,采用RoIAlign取代RoIPooling。2、多尺度:通過FPN網(wǎng)絡(luò)集成多尺度特征圖,利用歸一化尺度偏差方法緩解不同尺度對(duì)Loss的影響程度。3、實(shí)時(shí)性:去除了Fater RCNN的全連接層,取而代之采用FCN網(wǎng)絡(luò),相比Fater RCNN,具有更少的模型參數(shù)和計(jì)算時(shí)間。
主要不足:
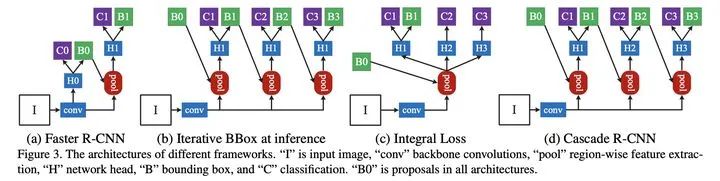
單階段目標(biāo)檢測算法
編碼方式
1、基于中心坐標(biāo)
方案1
通過計(jì)算IOU或者長寬比閾值篩選每個(gè)anchor位置對(duì)應(yīng)的target,可能過濾比較極端的target,但緩解目標(biāo)重疊情況下的編碼重疊問題。通過對(duì)應(yīng)anchor找到中心坐標(biāo)位置(x,y)。
方案2
通過iou最大值計(jì)算每個(gè)target對(duì)應(yīng)的anchor位置,保證每個(gè)target至少對(duì)應(yīng)一個(gè),目標(biāo)少的情況下但容易造成目標(biāo)稀疏編碼,通過對(duì)應(yīng)target找到中心坐標(biāo)位置(x,y),YOLOv5中通過中心坐標(biāo)結(jié)合四舍五入進(jìn)行多中心坐標(biāo)映射緩解目標(biāo)稀疏問題。同時(shí)利用方案1和方案2,保證每個(gè)target至少對(duì)應(yīng)一個(gè)anchor區(qū)域。
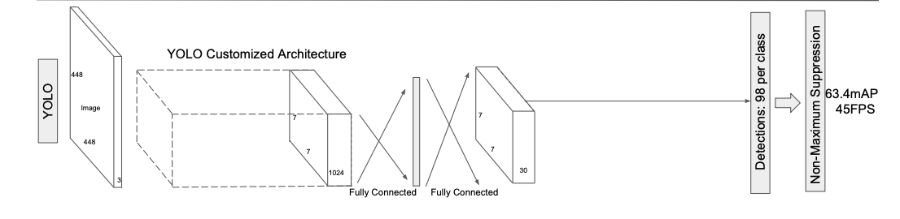
YOLOv1
雖然是單階段目標(biāo)檢測開山之作,但真正的鼻祖應(yīng)該是Faster RCNN的RPN。
主要優(yōu)點(diǎn):
2、采用全局特征進(jìn)行推理,由于利用全局上下文信息,相比于滑動(dòng)窗口和建議框方法,對(duì)背景的判斷更準(zhǔn)確。3、泛化性,訓(xùn)練好的模型在新的領(lǐng)域或者不期望的輸入情況下依然具有較好的效果。
主要不足:
1、準(zhǔn)確性:與Faster RCNN相比,correcct反映了YOLOv1準(zhǔn)確率較低,background反映了召回率較高,但總體性能F1較低,雖然loss采用長寬平方根進(jìn)行回歸,試圖降低大目標(biāo)對(duì)loss的主導(dǎo)地位,但小目標(biāo)的微小偏差對(duì)IOU的影響更嚴(yán)重,導(dǎo)致小目標(biāo)定位不準(zhǔn)。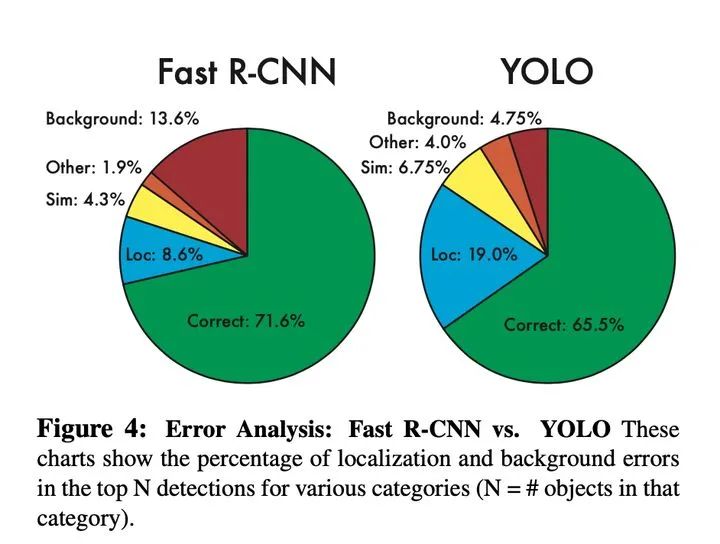 2、目標(biāo)重疊:雖然通過每個(gè)S*S的網(wǎng)格點(diǎn)設(shè)置了2個(gè)預(yù)測框用于回歸訓(xùn)練,但是每個(gè)網(wǎng)格點(diǎn)設(shè)置了一種類別,無法解決不同類別目標(biāo)重疊率較大,導(dǎo)致映射到相同網(wǎng)格點(diǎn)上的問題。3、多尺度:由于模型只是簡單使用下采樣獲得的粗糙特征,很難將其推廣到具有新的或不同尋常的寬高比或配置的對(duì)象。4、實(shí)時(shí)性:雖然與Faster RCNN相比,速度很快,但還可以更快,主要是由于v1中使用了全連接網(wǎng)絡(luò),不是全卷積網(wǎng)絡(luò)。=7x7x1024x4096+4096X7x7x30=2x10^8
2、目標(biāo)重疊:雖然通過每個(gè)S*S的網(wǎng)格點(diǎn)設(shè)置了2個(gè)預(yù)測框用于回歸訓(xùn)練,但是每個(gè)網(wǎng)格點(diǎn)設(shè)置了一種類別,無法解決不同類別目標(biāo)重疊率較大,導(dǎo)致映射到相同網(wǎng)格點(diǎn)上的問題。3、多尺度:由于模型只是簡單使用下采樣獲得的粗糙特征,很難將其推廣到具有新的或不同尋常的寬高比或配置的對(duì)象。4、實(shí)時(shí)性:雖然與Faster RCNN相比,速度很快,但還可以更快,主要是由于v1中使用了全連接網(wǎng)絡(luò),不是全卷積網(wǎng)絡(luò)。=7x7x1024x4096+4096X7x7x30=2x10^8
SSD
通過使用FCN全卷積神經(jīng)網(wǎng)絡(luò),并利用不同尺度的特征圖進(jìn)行目標(biāo)檢測,在速度和精度都得到了極大提升。主要優(yōu)點(diǎn)
1、實(shí)時(shí)性:相比YOlOv1更快,因?yàn)槿コ巳B接層。2、標(biāo)簽方案:通過預(yù)測類別置信度和相對(duì)固定尺度集合的先驗(yàn)框的偏差,能夠有效均衡不同尺度對(duì)loss的影響程度。3、多尺度:通過使用多個(gè)特征圖和對(duì)應(yīng)不同尺度的錨框進(jìn)行多尺度目標(biāo)預(yù)測。4、數(shù)據(jù)增強(qiáng):通過隨機(jī)裁剪的方式進(jìn)行數(shù)據(jù)增強(qiáng)提高模型的魯棒性。5、樣本不平衡:通過困難樣本挖掘,采用負(fù)樣本中置信度最高的先驗(yàn)框進(jìn)行訓(xùn)練,并設(shè)置正負(fù)樣本比例為1:3,使得模型訓(xùn)練收斂更快。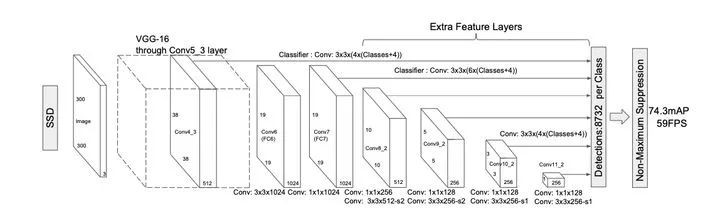
主要不足
1、通過人工先驗(yàn)設(shè)置的不同尺度的錨框無法適應(yīng)真實(shí)的目標(biāo)框的尺度分布。2、使用的多個(gè)特征圖由于高分辨率的特征圖不能有效地結(jié)合高層特征。
YOLOv2
針對(duì)YOLOv1在解決多尺度和實(shí)時(shí)性方面的不足,提出了YOLOv2。
主要優(yōu)點(diǎn):
1)Batch Normalization:使得性能極大提升;2)Higher Resolution Classifier:使預(yù)訓(xùn)練分類任務(wù)分辨率與目標(biāo)檢測的分辨率一致;3)Convolutional With Anchor Boxes:使用全卷積神經(jīng)網(wǎng)絡(luò)預(yù)測偏差,而非具體的坐標(biāo),模型更容易收斂;4)Dimension Clusters:通過聚類算法設(shè)置錨框的尺度,獲得更好的先驗(yàn)框,緩解了不同尺度對(duì)loss的影響變化;5)Fine-Grained Features:通過簡單相加融合了低層的圖像特征;6)Multi-Scale Training:通過使用全卷積網(wǎng)絡(luò)使得模型支持多種尺度圖像的輸入并輪流進(jìn)行訓(xùn)練。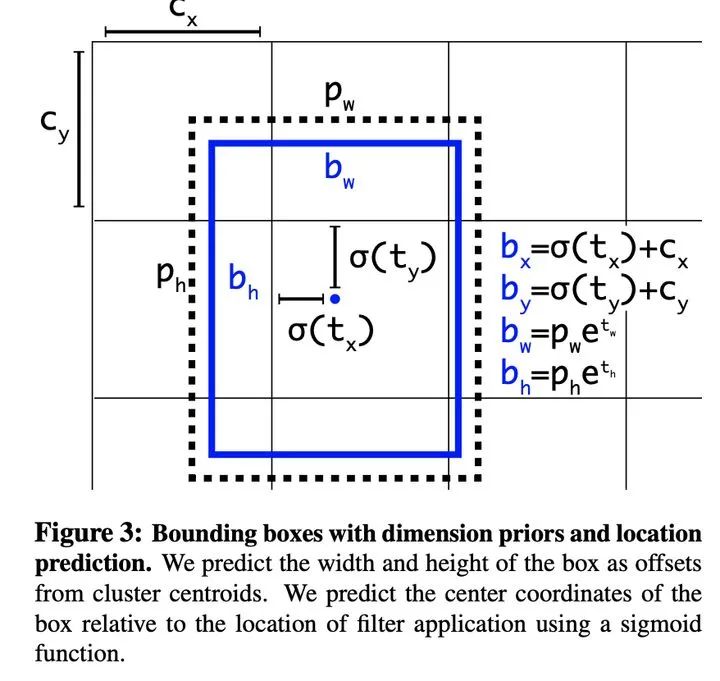 2、更快,構(gòu)建Darknet-19代替VGG-16作為backbone具有更好的性能。
2、更快,構(gòu)建Darknet-19代替VGG-16作為backbone具有更好的性能。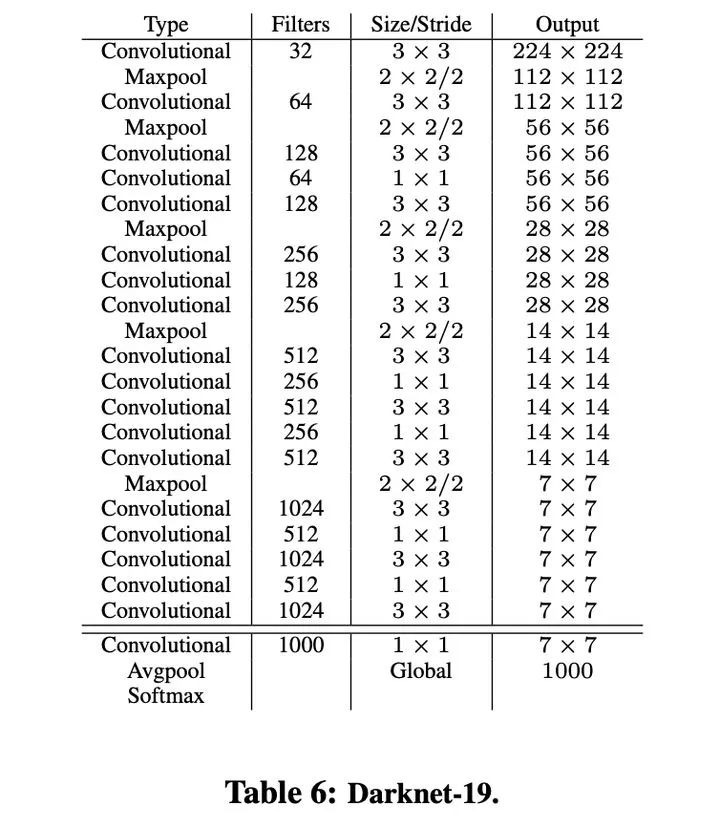
主要不足
1、多尺度:在模型維度只是簡單融合底層特征,在輸入維度進(jìn)行多尺度圖像分辨率的輸入訓(xùn)練,不能克服模型本身感受野導(dǎo)致的多尺度誤差。RetinaNet
論文:Focal Loss for Dense Object Detection主要優(yōu)點(diǎn)
1、多尺度:借鑒FPN網(wǎng)絡(luò)通過自下而上、自上而下的特征提取網(wǎng)絡(luò),并通過無代價(jià)的橫向連接構(gòu)建增強(qiáng)特征提取網(wǎng)絡(luò),利用不同尺度的特征圖檢測不同大小的目標(biāo),利用了底層高分率的特征圖有效的提高了模型對(duì)小尺度目標(biāo)的檢測精度。2、樣本不平衡:引入Focal Loss用于候選框的【類別預(yù)測】,克服正負(fù)樣本不平衡的影響及加大困難樣本的權(quán)重。
主要不足
1、實(shí)時(shí)性:網(wǎng)絡(luò)使用ResNet-101作為主干特征提取網(wǎng)絡(luò),檢測效率略微不足。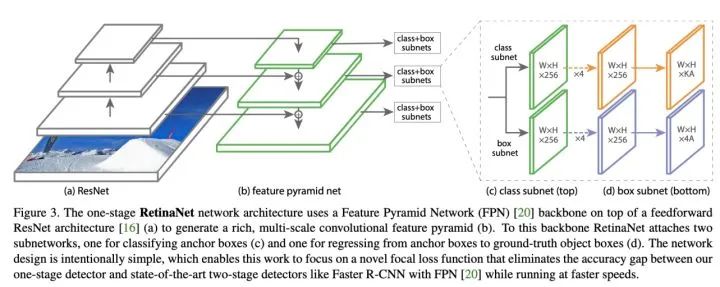
YOLOv3
論文:YOLOv3: An Incremental Improvement
主要優(yōu)點(diǎn)
1、實(shí)時(shí)性:相比RetinaNet,YOLOv3通過犧牲檢測精度,使用Darknet主干特征提取網(wǎng)絡(luò)而不是Resnet101,從而獲取更快的檢測速度。2、多尺度:相比于YOLOv1-v2,與RetinaNet采用相同的FPN網(wǎng)絡(luò)作為增強(qiáng)特征提取網(wǎng)絡(luò)得到更高的檢測精度。3、目標(biāo)重疊:通過使用邏輯回歸和二分類交叉熵?fù)p失函數(shù)進(jìn)行類別預(yù)測,將每個(gè)候選框進(jìn)行多標(biāo)簽分類,解決單個(gè)檢測框可能同時(shí)包含多個(gè)目標(biāo)的可能。
主要不足
1、準(zhǔn)確率:主要因?yàn)镈arknet的特征提取不夠強(qiáng),未進(jìn)行精細(xì)化結(jié)構(gòu)模型設(shè)計(jì)。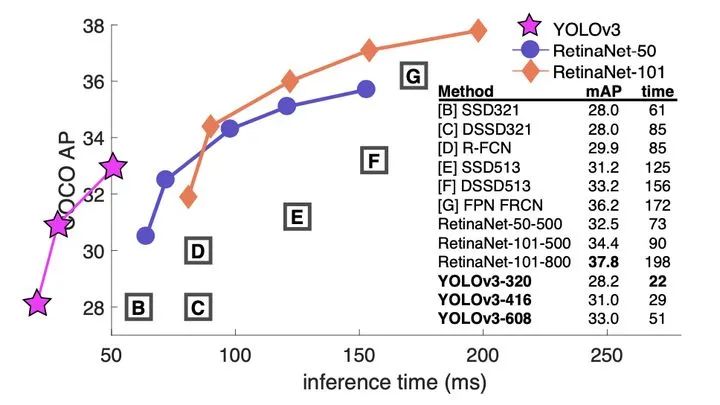
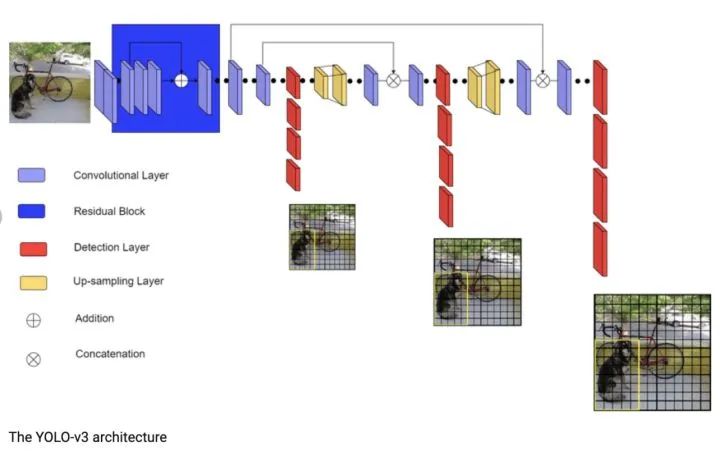
YOLOv4
論文:YOLOv4: Optimal Speed and Accuracy of Object Detection鑒于YOLOv3的缺點(diǎn),YOLOv5進(jìn)行了Darknet53主干特征提取網(wǎng)絡(luò)等一系列改進(jìn)。主要優(yōu)點(diǎn)
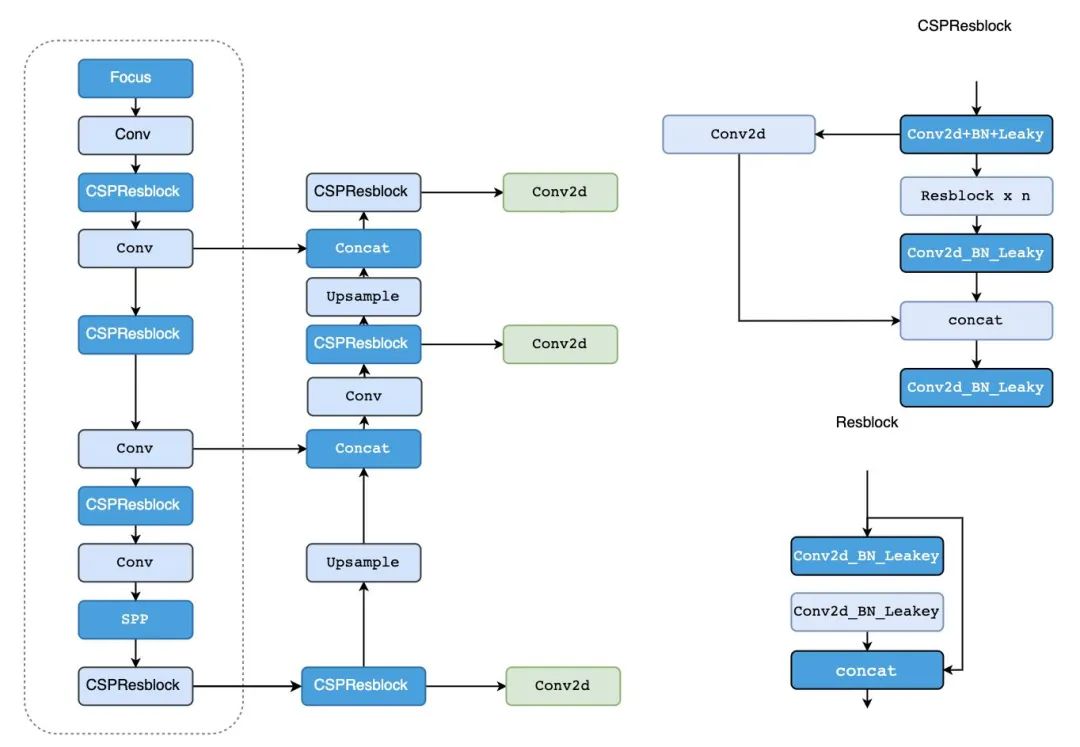
1、實(shí)時(shí)性:借鑒CSPNet網(wǎng)絡(luò)結(jié)構(gòu)將Darknet53改進(jìn)為CSPDarknet53使模型參數(shù)和計(jì)算時(shí)間更短。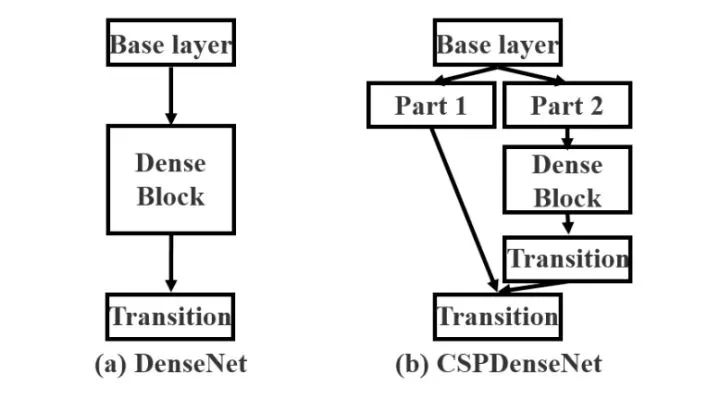 2、多尺度:頸部分別引入PAN和SPP網(wǎng)絡(luò)結(jié)構(gòu)作為增強(qiáng)特征提取網(wǎng)絡(luò),能夠有效多尺度特征,相比于引入FPN網(wǎng)絡(luò)準(zhǔn)確度更高。3、數(shù)據(jù)增強(qiáng):引入Mosaic數(shù)據(jù)增強(qiáng),在使用BN的時(shí)候可以有效降低batch_size的影響。4、模型訓(xùn)練,采用IOU:GIoU,DIoU,CIoU作為目標(biāo)框的回歸,與YOLOv3使用的平方差損失相比具有更高的檢測精度。
2、多尺度:頸部分別引入PAN和SPP網(wǎng)絡(luò)結(jié)構(gòu)作為增強(qiáng)特征提取網(wǎng)絡(luò),能夠有效多尺度特征,相比于引入FPN網(wǎng)絡(luò)準(zhǔn)確度更高。3、數(shù)據(jù)增強(qiáng):引入Mosaic數(shù)據(jù)增強(qiáng),在使用BN的時(shí)候可以有效降低batch_size的影響。4、模型訓(xùn)練,采用IOU:GIoU,DIoU,CIoU作為目標(biāo)框的回歸,與YOLOv3使用的平方差損失相比具有更高的檢測精度。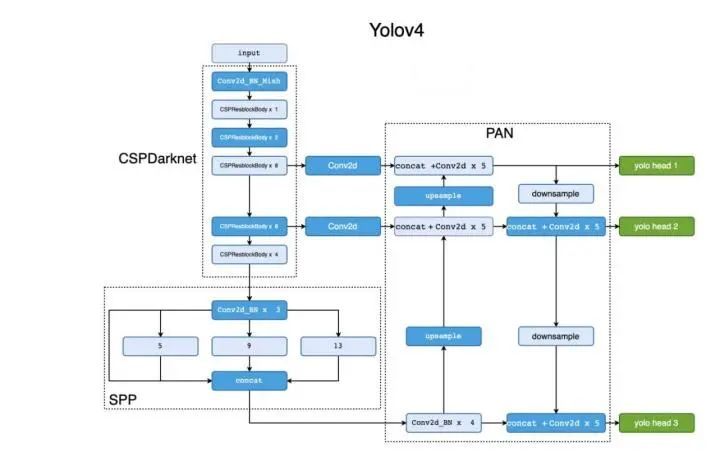
YOLOv5
為了進(jìn)一步提升YOLOv4的檢測速度,YOLOv5采用了更輕量的網(wǎng)絡(luò)結(jié)構(gòu)。
主要優(yōu)點(diǎn)
1、多尺度:使用FPN增強(qiáng)特征提取網(wǎng)絡(luò)代替PAN,使模型更簡單,速度更快。2、目標(biāo)重疊:使用四舍五入的方法進(jìn)行臨近位置查找,使目標(biāo)映射到周圍的多個(gè)中心網(wǎng)格點(diǎn)。
主要不足
1、通過長寬比篩選并過濾了大小和長寬比較極端的真實(shí)目標(biāo)框,而這些恰恰在真實(shí)檢測任務(wù)極為重要,和重點(diǎn)解決的檢測問題。