
【數(shù)據(jù)分析】近10年學(xué)術(shù)論文的數(shù)據(jù)分析!
本文使用arXiv公開的論文數(shù)據(jù)集,聚焦2008年-2020年計(jì)算機(jī)各個(gè)方向論文數(shù)據(jù),對其進(jìn)行了數(shù)據(jù)探索性分析和可視化分析,什么是2020年最火的方向,排名前五的又是哪些呢?一起來看看結(jié)論和數(shù)據(jù)分析過程。
本文目錄
一、 數(shù)據(jù)轉(zhuǎn)換
本文數(shù)據(jù)下載地址:https://tianchi.aliyun.com/competition/entrance/531866/information
從json中讀取數(shù)據(jù)
#?導(dǎo)入所需的package
import?seaborn?as?sns?#用于畫圖
from?bs4?import?BeautifulSoup?#用于爬取arxiv的數(shù)據(jù)
import?re?#用于正則表達(dá)式,匹配字符串的模式
import?requests?#用于網(wǎng)絡(luò)連接,發(fā)送網(wǎng)絡(luò)請求,使用域名獲取對應(yīng)信息
import?json?#讀取數(shù)據(jù),我們的數(shù)據(jù)為json格式的
import?pandas?as?pd?#數(shù)據(jù)處理,數(shù)據(jù)分析
import?matplotlib.pyplot?as?plt?#畫圖工具
def?readArxivFile(path,?columns=['id',?'submitter',?'authors',?'title',?'comments',?'journal-ref',?'doi','report-no',?'categories',?'license',?'abstract',?'versions','update_date',?'authors_parsed'],?count=None):
????data??=?[]
????with?open(path,?'r')?as?f:?
????????for?idx,?line?in?enumerate(f):?
????????????if?idx?==?count:
????????????????break
????????????????
????????????d?=?json.loads(line)
????????????d?=?{col?:?d[col]?for?col?in?columns}
????????????data.append(d)
????data?=?pd.DataFrame(data)
????return?data?1.1 讀取原始數(shù)據(jù)
data?=?readArxivFile('D:/Code/Github/data/arxiv-metadata-oai-snapshot.json',?['id',?'categories',?'authors','title','update_date'])
1.2?爬取論文類別數(shù)據(jù)
#爬取所有的類別
website_url?=?requests.get('https://arxiv.org/category_taxonomy').text?#獲取網(wǎng)頁的文本數(shù)據(jù)
soup?=?BeautifulSoup(website_url,'lxml')?#爬取數(shù)據(jù),這里使用lxml的解析器,加速
root?=?soup.find('div',{'id':'category_taxonomy_list'})?#找出?BeautifulSoup?對應(yīng)的標(biāo)簽入口
tags?=?root.find_all(["h2","h3","h4","p"],?recursive=True)?#讀取?tags
#初始化?str?和?list?變量
level_1_name?=?""
level_2_name?=?""
level_2_code?=?""
level_1_names?=?[]
level_2_codes?=?[]
level_2_names?=?[]
level_3_codes?=?[]
level_3_names?=?[]
level_3_notes?=?[]
#進(jìn)行
for?t?in?tags:
????if?t.name?==?"h2":
????????level_1_name?=?t.text????
????????level_2_code?=?t.text
????????level_2_name?=?t.text
????elif?t.name?==?"h3":
????????raw?=?t.text
????????level_2_code?=?re.sub(r"(.*)\((.*)\)",r"\2",raw)?#正則表達(dá)式:模式字符串:(.*)\((.*)\);被替換字符串"\2";被處理字符串:raw
????????level_2_name?=?re.sub(r"(.*)\((.*)\)",r"\1",raw)
????elif?t.name?==?"h4":
????????raw?=?t.text
????????level_3_code?=?re.sub(r"(.*)?\((.*)\)",r"\1",raw)
????????level_3_name?=?re.sub(r"(.*)?\((.*)\)",r"\2",raw)
????elif?t.name?==?"p":
????????notes?=?t.text
????????level_1_names.append(level_1_name)
????????level_2_names.append(level_2_name)
????????level_2_codes.append(level_2_code)
????????level_3_names.append(level_3_name)
????????level_3_codes.append(level_3_code)
????????level_3_notes.append(notes)
#根據(jù)以上信息生成dataframe格式的數(shù)據(jù)
df_taxonomy?=?pd.DataFrame({
????'group_name'?:?level_1_names,
????'archive_name'?:?level_2_names,
????'archive_id'?:?level_2_codes,
????'category_name'?:?level_3_names,
????'categories'?:?level_3_codes,
????'category_description':?level_3_notes
????
})
df_taxonomy.head()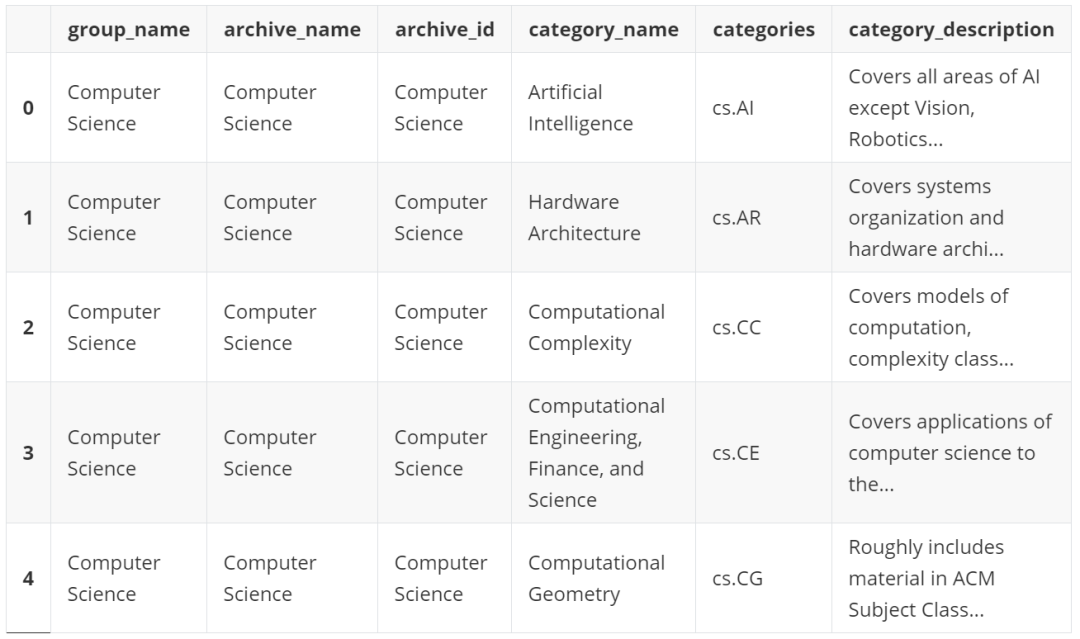
1.3?取data的子集進(jìn)行處理
抽取數(shù)據(jù)的5%進(jìn)行分析,否則數(shù)據(jù)量太大,處理時(shí)間太長。
#存儲轉(zhuǎn)換后的原始數(shù)據(jù)
data.to_csv('D:/Code/Github/data/data.csv',index?=?False)
df_taxonomy.to_csv('D:/Code/Github/data/categories.csv',index?=?False)
#對數(shù)據(jù)進(jìn)行抽樣
data?=?data.sample(frac=0.05,replace=False,random_state=1)
data.shape(89846, 5)
1.4?對catagories進(jìn)行處理
categories列中有很多,一篇論文同時(shí)屬于很多的類別,只取第一個(gè)類別,放棄其他類別。
print(data.categories.nunique())
data['categories']?=?data.categories.str.split('?',expand=True)[0]
data.categories.nunique()9488
172
1.5?數(shù)據(jù)連接
data_merge?=?data.merge(df_taxonomy,how='left',on='categories').sort_values(by?=?"update_date").drop_duplicates(['id','group_name'],keep?=?'first')
data_merge.shape(89847, 10)
發(fā)現(xiàn)比原始抽樣數(shù)據(jù)多了一行,經(jīng)查明,原來是多了一行空行,進(jìn)行刪除
data_merge.dropna(how='any',subset=['categories'],inplace=True)
data_merge.shape(89846, 10)
1.6?存儲轉(zhuǎn)換后的數(shù)據(jù),后面可以直接進(jìn)行讀取
data_merge.to_csv('D:/Code/Github/data/data_subset_merge.csv',index?=?False)二、 數(shù)據(jù)探索性分析
2.1?查看數(shù)據(jù)的缺失信息
可以看到group_name之后的部分列,都有缺失數(shù)據(jù)
data_merge.info()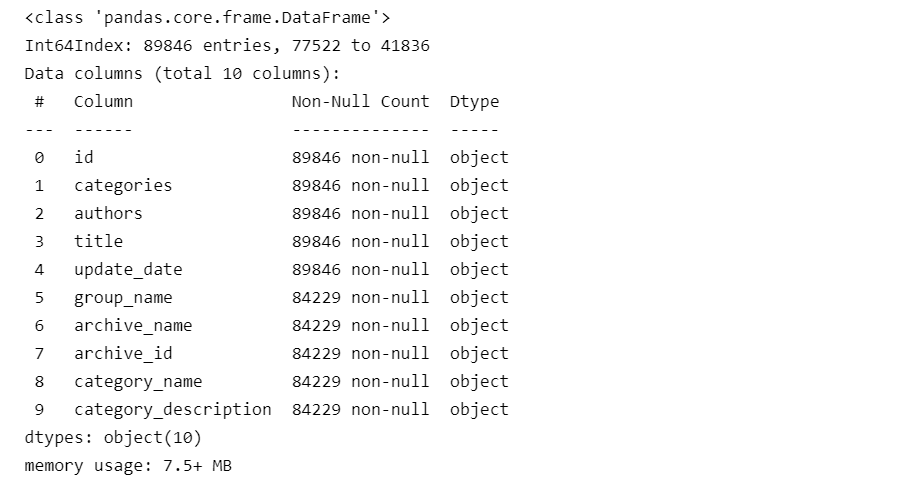
2.2?統(tǒng)計(jì)不同大類的論文數(shù)量
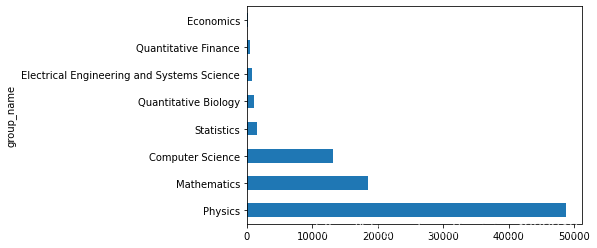
可以看到物理學(xué)領(lǐng)域的論文數(shù)量最多,數(shù)學(xué)和計(jì)算機(jī)科學(xué)的其次,其他領(lǐng)域的論文數(shù)量都相對較少 說明arxiv網(wǎng)站的論文大部分仍然集中在“物理學(xué),數(shù)學(xué),計(jì)算機(jī)科學(xué)”領(lǐng)域
data_merge.groupby('group_name')['id'].agg('count').sort_values(ascending?=?False).plot(kind?=?'barh')
2.3?按年度統(tǒng)計(jì)論文數(shù)量的變化
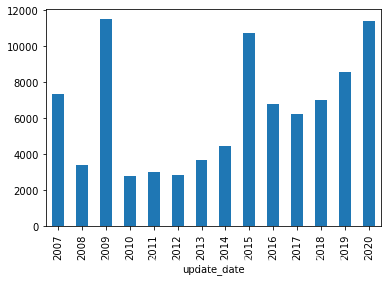
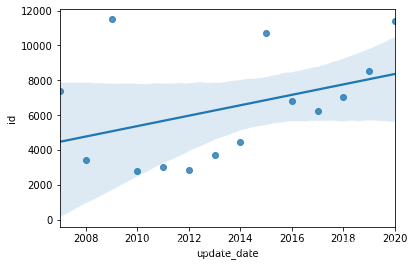
可以看到論文數(shù)量大體上呈現(xiàn)遞增的趨勢 2009年和2015年的數(shù)據(jù)偏高,有可能是抽樣的隨機(jī)因素,也有可能這兩年的論文數(shù)量本來就比較高
data_merge.groupby(pd.to_datetime(data_merge.update_date).dt.year)['id'].agg('count').plot(kind?=?'bar')
#繪制回歸圖
data_plot=data_merge.groupby(pd.to_datetime(data_merge.update_date).dt.year)['id'].agg('count').reset_index()
sns.regplot(data_plot.iloc[:,0],data_plot.iloc[:,1])
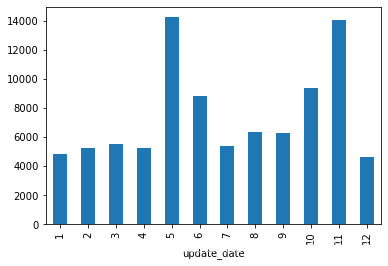
2.4 按月份統(tǒng)計(jì)論文發(fā)表數(shù)量
比較發(fā)現(xiàn)一年中5,6,10,11月份是論文出產(chǎn)最多的月份
data_merge.groupby(pd.to_datetime(data_merge.update_date).dt.month)['id'].agg('count').plot(kind?=?'bar')
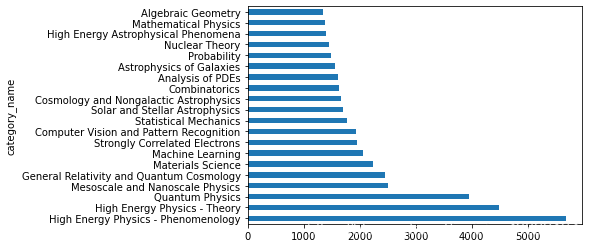
2.5 統(tǒng)計(jì)不同小類論文的數(shù)量
只繪制了前20種 高能物理,量子力學(xué)領(lǐng)域的論文數(shù)量最多
data_merge.groupby('category_name')['id'].agg('count').sort_values(ascending?=?False).head(20).plot(kind?=?'barh')
三、 使用BI軟件進(jìn)行數(shù)據(jù)可視化分析
3.1 不同年份計(jì)算機(jī)領(lǐng)域發(fā)表數(shù)量前五的領(lǐng)域
可以看到計(jì)算機(jī)領(lǐng)域最火的領(lǐng)域一直在發(fā)生著變換,2014年-2016年都是信息理論方面的論文最多,而2017-2019是計(jì)算機(jī)視覺最火,到了2020年,機(jī)器學(xué)習(xí)則和計(jì)算機(jī)視覺并駕齊驅(qū)。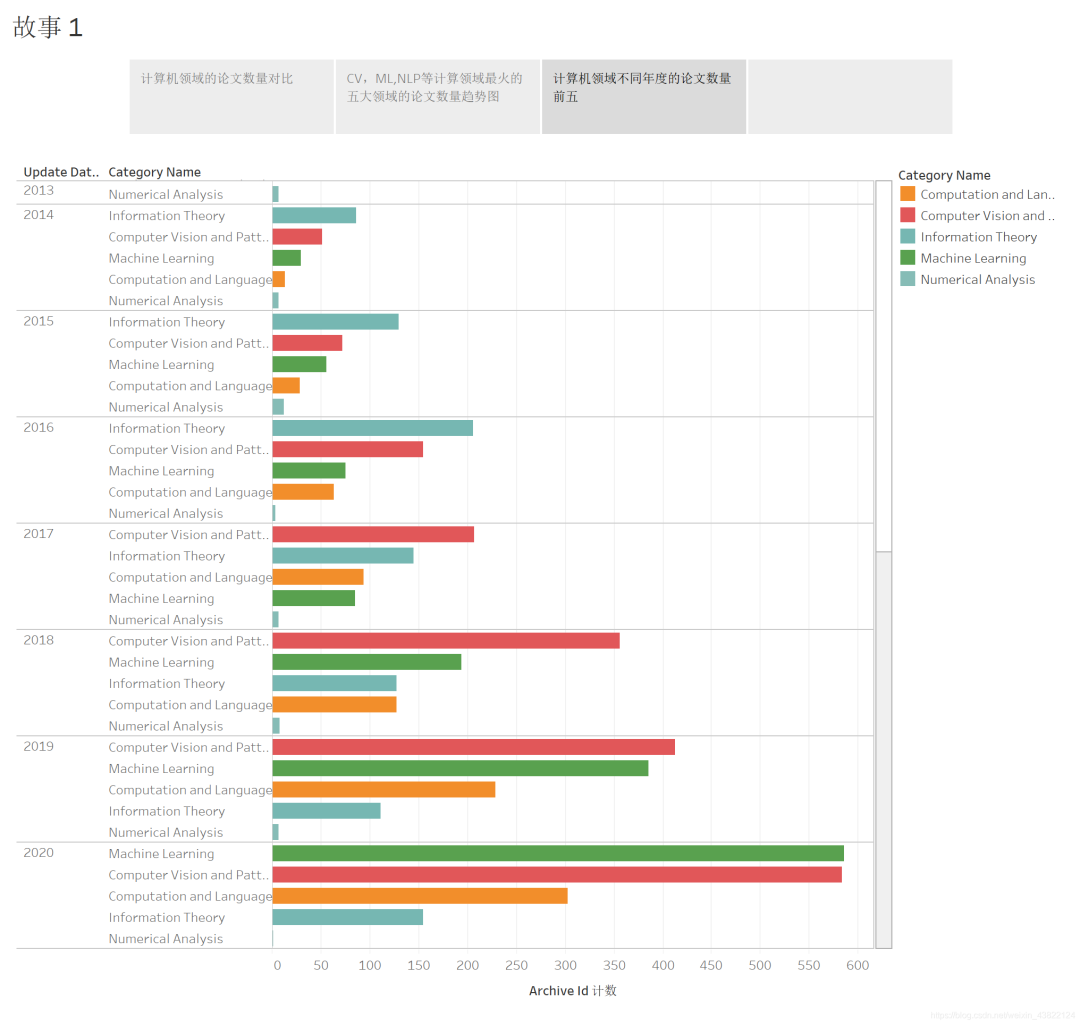
3.2 計(jì)算機(jī)領(lǐng)域論文數(shù)量對比
排名前五的是計(jì)算機(jī)視覺、機(jī)器學(xué)習(xí)、信息理論、自然語言處理、人工智能五個(gè)方面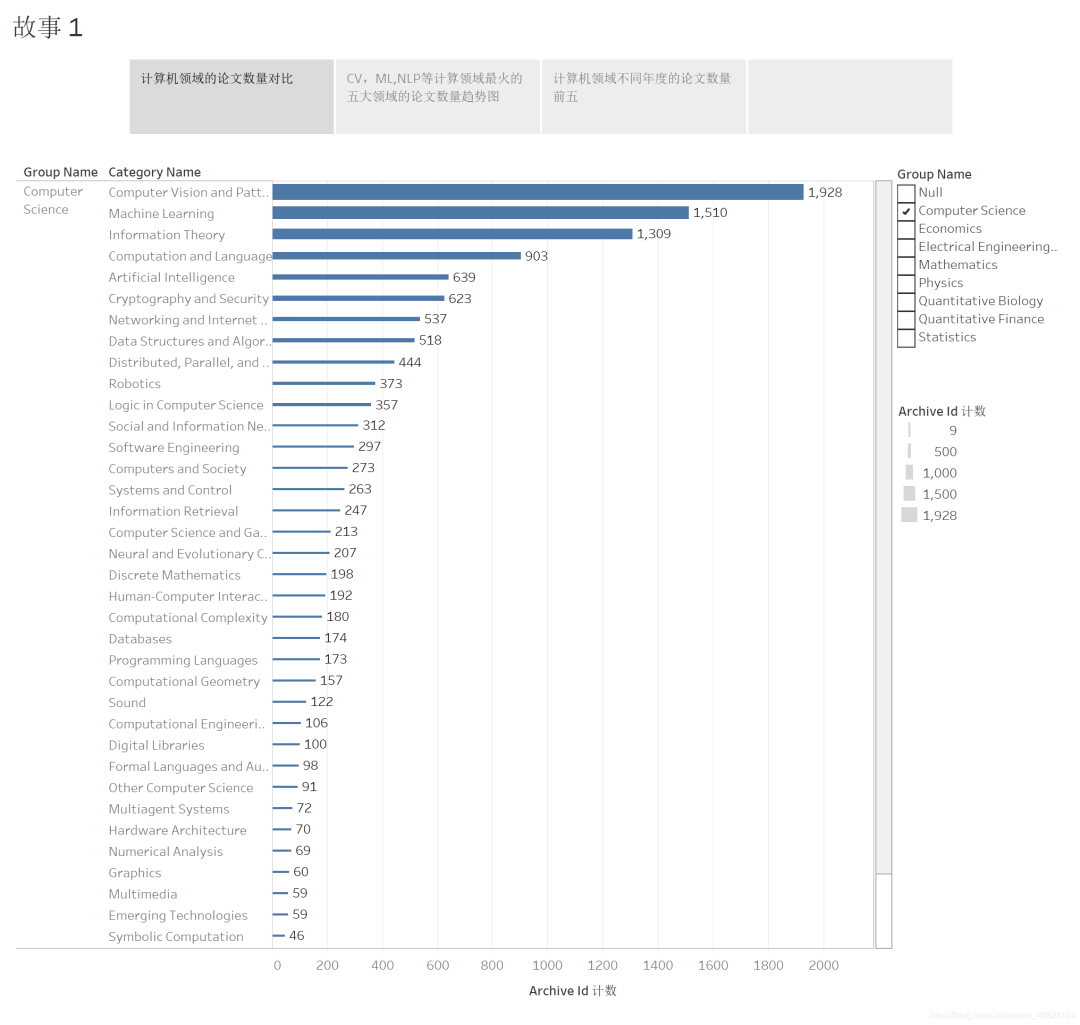
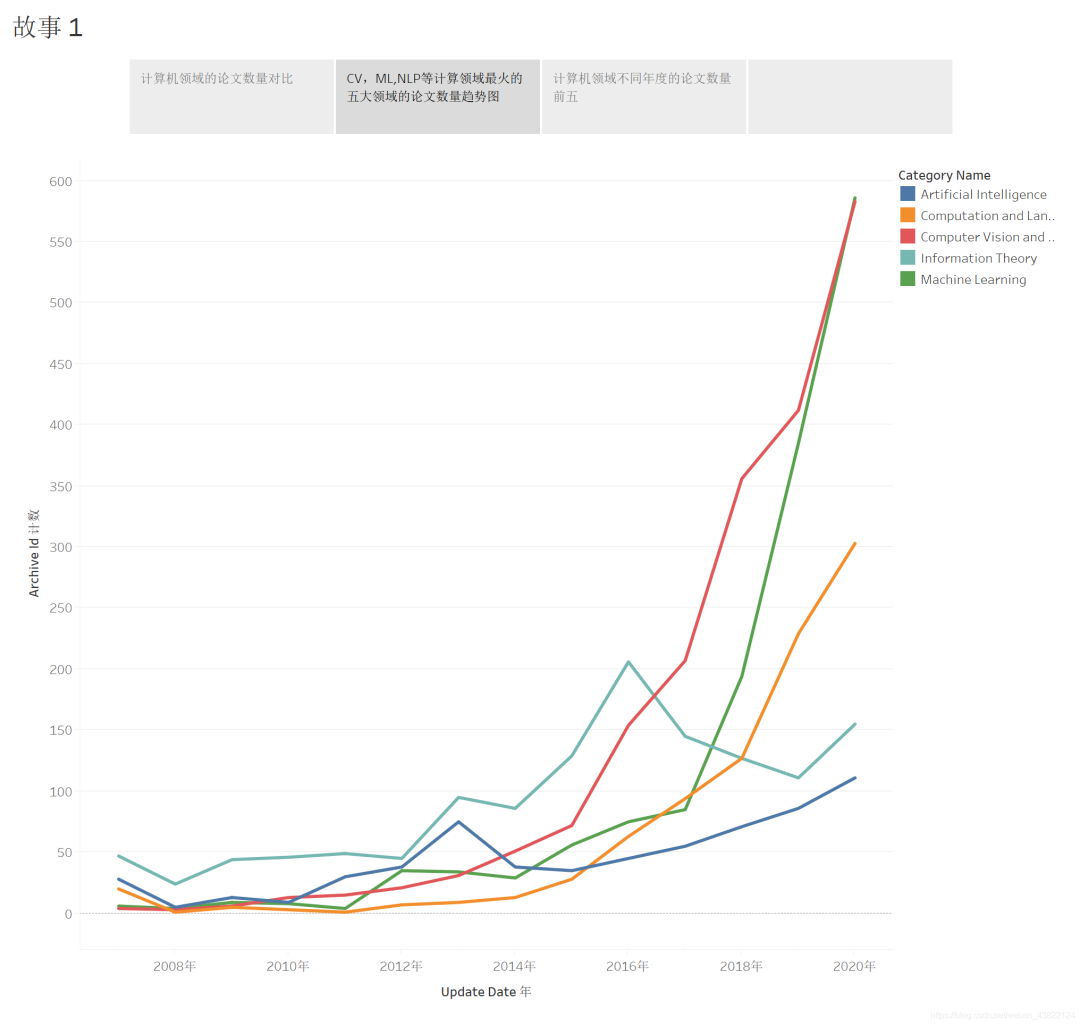
3.3 CV、ML等領(lǐng)域論文數(shù)量變化趨勢
可以看到論文的數(shù)量都呈現(xiàn)出上升的趨勢,但是2014年是一個(gè)節(jié)點(diǎn),2014年之后,計(jì)算機(jī)視覺和機(jī)器學(xué)習(xí)兩個(gè)領(lǐng)域的論文數(shù)量都開始了非常迅速的增長,這兩個(gè)方向依然是計(jì)算機(jī)領(lǐng)域目前論文中的最火的方向,至于今年比較熱的新方向,如可復(fù)現(xiàn)性、差分隱私、幾何深度學(xué)習(xí)、神經(jīng)形態(tài)計(jì)算、強(qiáng)化學(xué)習(xí)是否成為新增長點(diǎn),來一個(gè)預(yù)測吧。
往期精彩回顧
本站知識星球“黃博的機(jī)器學(xué)習(xí)圈子”(92416895)
本站qq群704220115。
加入微信群請掃碼: