
【數(shù)據(jù)分析】Python數(shù)據(jù)分析指南(全)
前言
數(shù)據(jù)分析是通過明確分析目的,梳理并確定分析邏輯,針對性的收集、整理數(shù)據(jù),并采用統(tǒng)計、挖掘技術(shù)分析,提取有用信息和展示結(jié)論的過程,是數(shù)據(jù)科學(xué)領(lǐng)域的核心技能。
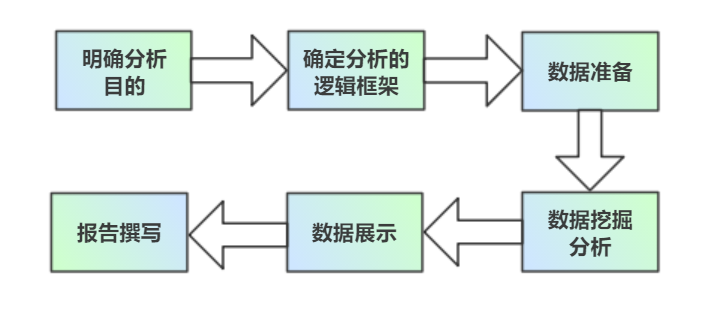
本文從數(shù)據(jù)分析常用邏輯框架及技術(shù)方法出發(fā),結(jié)合python項目實戰(zhàn)全面解讀數(shù)據(jù)分析,可以系統(tǒng)掌握數(shù)據(jù)分析的框架套路,快速上手?jǐn)?shù)據(jù)分析。
一、 數(shù)據(jù)分析的邏輯 --構(gòu)建系統(tǒng)的分析維度及指標(biāo)
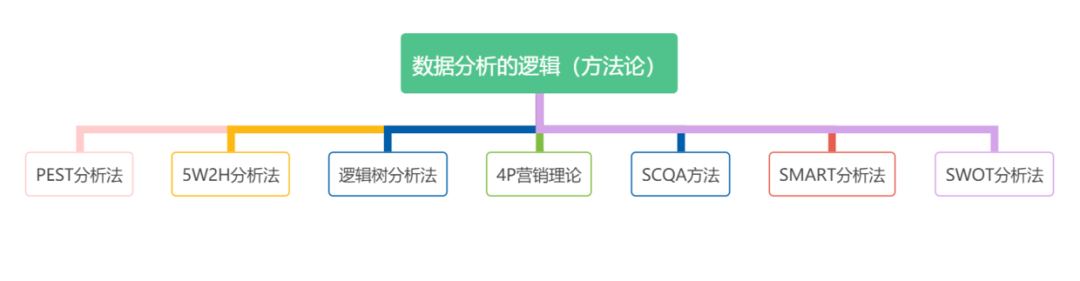
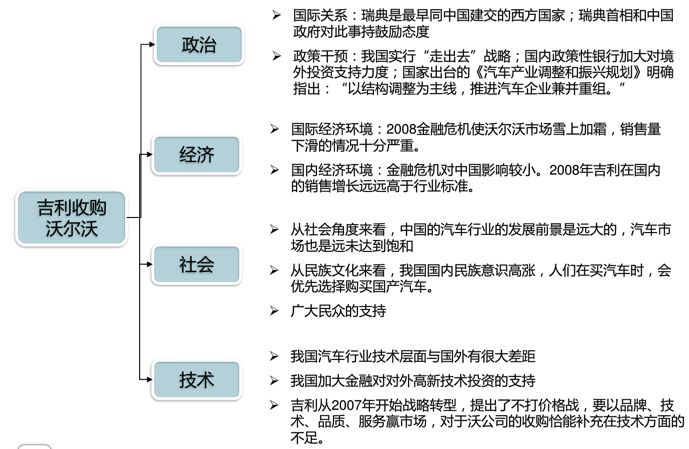
1.1 PEST分析法
PEST分析是指宏觀環(huán)境的分析,宏觀環(huán)境是指影響一切行業(yè)或企業(yè)的各種宏觀力量。P是政治(Politics),E是經(jīng)濟(Economy),S是社會(Society),T是技術(shù)(Technology)。通常是戰(zhàn)略咨詢顧問用來幫助企業(yè)檢閱其外部宏觀環(huán)境的一種方法,以吉利收購沃爾沃為例:
1.2 5W2H分析法
5W2H分析法又稱七何分析法,包括:Why、What、Where、When、Who、How、How much 。主要用于用戶行為分析、業(yè)務(wù)問題專題分析、營銷活動等,是一個方便又實用的工具。

1.3 邏輯樹分析法

邏輯樹是分析問題最常用的工具之一,它是將問題的所有子問題分層羅列,從最高層開始,并逐步向下擴展。使用邏輯樹分析的主要優(yōu)點是保證解決問題的過程的完整性,且方便將工作細(xì)分為便于操作的任務(wù),確定各部分的優(yōu)先順序,明確地把責(zé)任落實到個人。
1.4 4P營銷理論
4P即產(chǎn)品(Product)、價格(Price)、渠道(Place)、促銷(Promotion),在營銷領(lǐng)域,這種以市場為導(dǎo)向的營銷組合理論,被企業(yè)應(yīng)用最普遍。通過將四者的結(jié)合、協(xié)調(diào)發(fā)展,從而提高企業(yè)的市場份額,達(dá)到最終獲利的目的。
4P營銷理論適用于分析企業(yè)的經(jīng)營狀況,可視為企業(yè)內(nèi)部環(huán)境,PEST分析的是企業(yè)在外部面對的環(huán)境。

1.5 SCQA分析法
SCQA分析是一個“結(jié)構(gòu)化表達(dá)”工具,即S(Situation)情景、C(Complication)沖突、Q(Question)疑問、A(Answer)回答。
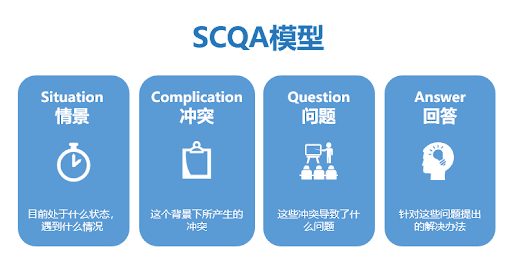
整個結(jié)構(gòu)是通過描述當(dāng)事者的現(xiàn)實狀態(tài),然后帶出沖突和核心問題,通過結(jié)構(gòu)化分析以提供更為明智的解決方案。以校園招聘SCQA分析為例:

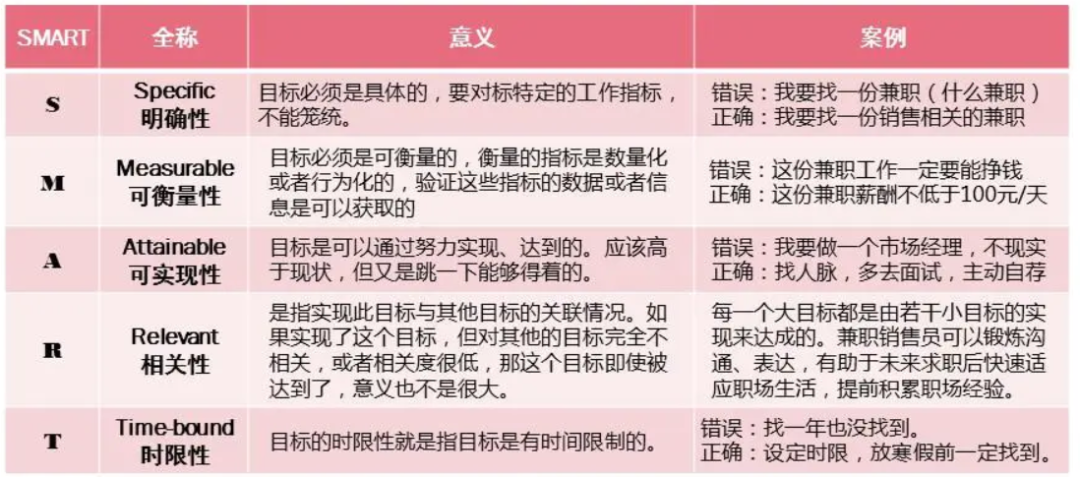
1.6 SMART分析法
SMART法是一種目標(biāo)管理方法,即對目標(biāo)的S(Specific)明確性,M(Measurable)可衡量性,A(Attainable)可實現(xiàn)性,R(Relevant)相關(guān)性,T(Time-based)時限性。
1.7 SWOT分析法
SWOT分析法也叫態(tài)勢分析法,S (Strengths)是優(yōu)勢、W (Weaknesses)是劣勢,O (Opportunities)是機會、T (Threats)是威脅或風(fēng)險。常用來確定企業(yè)自身的內(nèi)部優(yōu)勢、劣勢和外部的機會和威脅等,從而將公司的戰(zhàn)略與公司內(nèi)部與外部環(huán)境有機地結(jié)合起來。以HUAWEI 的SWOT分析為例:

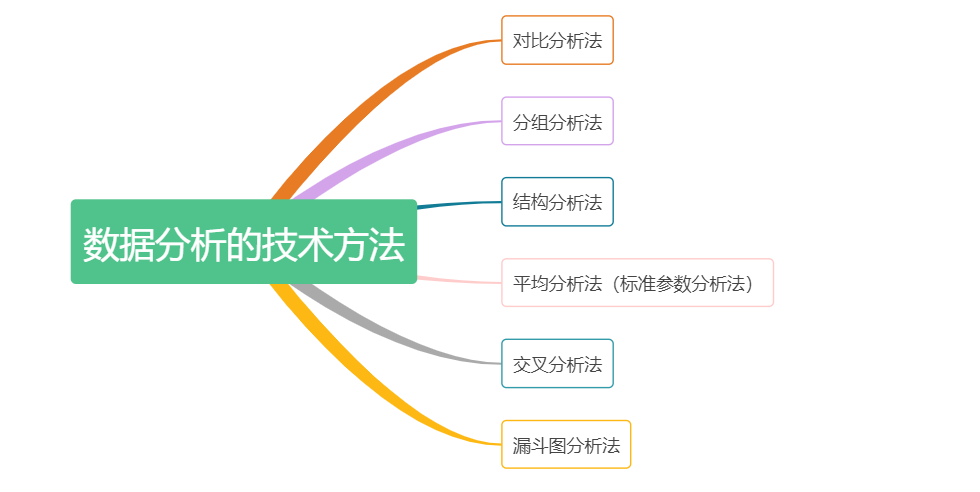
二、 數(shù)據(jù)分析的技術(shù)方法
數(shù)據(jù)分析的技術(shù)方法是指提取出關(guān)鍵指標(biāo)信息的具體方法,如對比分析、交叉分析、回歸預(yù)測分析等方法。
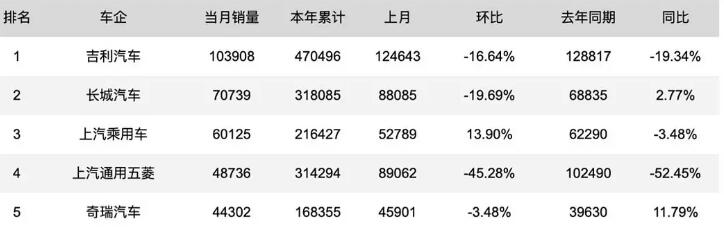
2.1 對比分析法
對比分析法是將兩個或兩個以上的數(shù)據(jù)進(jìn)行比較,分析差異,揭示發(fā)展變化情況和規(guī)律。
靜態(tài)比較:時間一致的前提下選取不同指標(biāo),如部門、城市、門店等,也叫橫向比較。 動態(tài)比較:指標(biāo)一致的前提下,針對不同時期的數(shù)據(jù)比較,也叫縱向比較。
舉例:各車企銷售表現(xiàn)
2.2 分組分析法
先經(jīng)過數(shù)據(jù)加工,對數(shù)據(jù)進(jìn)行數(shù)據(jù)分組,然后對分組的數(shù)據(jù)進(jìn)行分析。 分組的目的是為了便于對比,把總體中具有不同性質(zhì)的對象區(qū)分開,把性質(zhì)相同的對象合并在一起,保持各組內(nèi)對象屬性的一致性、組與組之間屬性的差異性,以便進(jìn)一步運用各種數(shù)據(jù)分析方法來解釋內(nèi)在的數(shù)量關(guān)系。
舉例:新書在各銷售渠道的銷量

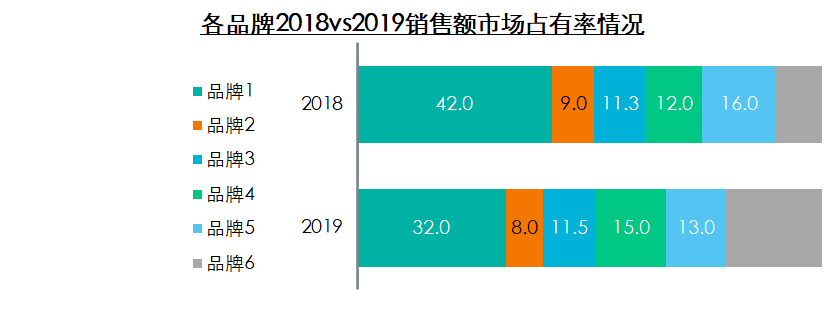
2.3 結(jié)構(gòu)分析法
結(jié)構(gòu)分析法又稱比重分析法,是在分組分析法的基礎(chǔ)上,計算總體內(nèi)各組成部分占總體的比重,進(jìn)而分析總體數(shù)據(jù)的內(nèi)部特征。
舉例:市場占有率是典型的結(jié)構(gòu)分析。
2.4 平均分析法(標(biāo)準(zhǔn)參數(shù)分析法)
運用計算平均數(shù)的方法來反映總體在一定的時間、地點條件下某一數(shù)量特征的一般水平。 平均指標(biāo)可用于同一現(xiàn)象在不同地區(qū)、不同部門或單位間的對比,還可用于同一現(xiàn)象在不同時間的對比。
舉例:季節(jié)性分析和價格分析時常會用到index指標(biāo)

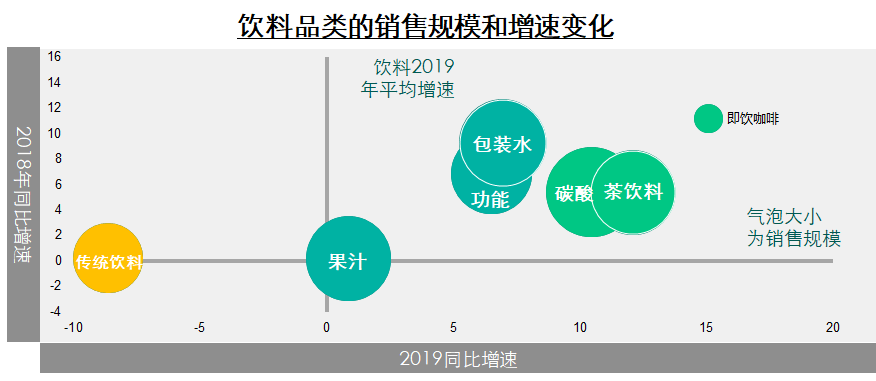
2.5 交叉分析法
通常用于分析兩個變量之間的關(guān)系,即同時將兩個有一定聯(lián)系的變量及其值交叉排列在一張表格內(nèi),使各變量值成為不同變量的交叉節(jié)點,形成交叉表。
舉例:常見的氣泡圖數(shù)據(jù)表格
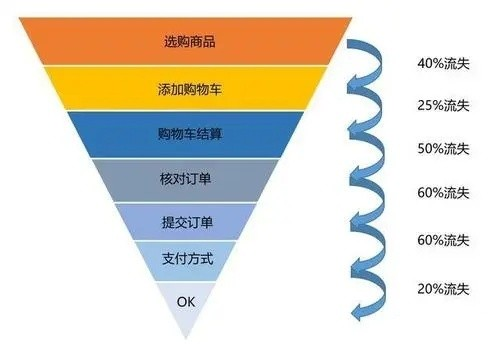
2.6 漏斗圖分析法
漏斗圖可以很好的反映網(wǎng)站各步奏轉(zhuǎn)化率,利用對比法對同一環(huán)節(jié)優(yōu)化前后的效果進(jìn)行對比分析來反映某個步奏轉(zhuǎn)化率的好壞。
舉例:商品流轉(zhuǎn)率表現(xiàn)圖
三、 數(shù)據(jù)分析的圖表展示
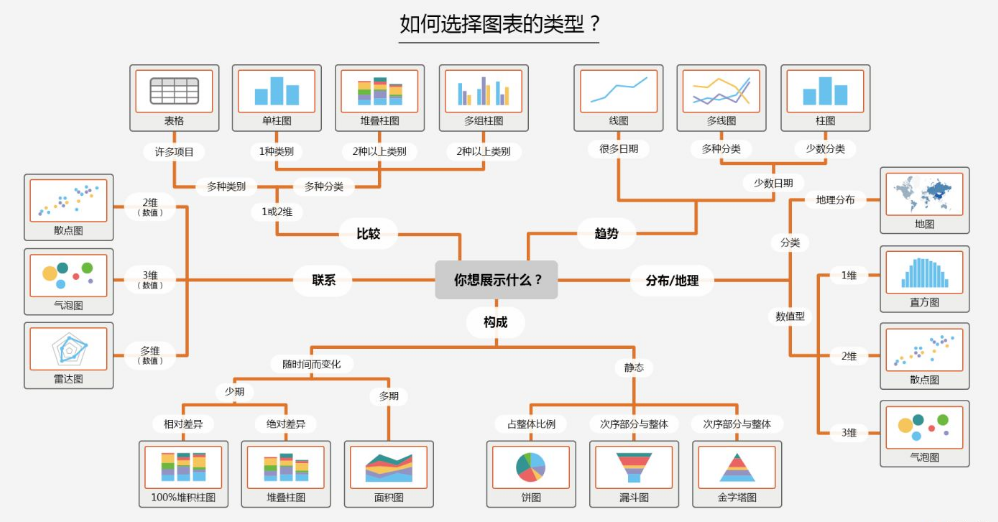
圖表展示可以幫助我們更好、更直觀地看懂?dāng)?shù)據(jù)信息。
圖表的選擇,不只是關(guān)注圖表的樣式,而關(guān)鍵在于關(guān)注數(shù)據(jù)情況及圖表展示的功能。可以通過數(shù)據(jù)展示的功能(構(gòu)成、比較、趨勢、分布及聯(lián)系)進(jìn)行圖表選擇,如下所示:
四、 項目實戰(zhàn) (python)
4.1 數(shù)據(jù)內(nèi)容
數(shù)據(jù)來源于kesci天貓真實成交訂單,主要是行為類數(shù)據(jù)。
a. 訂單編號:訂單編號
b. 總金額:訂單總金額
c. 買家實際支付金額:總金額 - 退款金額(在已付款的情況下);未付款的支付金額為0
d. 收貨地址:全國各個省份
e. 訂單創(chuàng)建時間:下單時間
f. 訂單付款時間:付款時間(如果未付款,顯示NaN)
g. 退款金額:付款后申請退款的金額。未付款的退款金額為0
4.2 天貓訂單分析過程
4.2.1 背景及分析目的
以天貓一個月內(nèi)的訂單數(shù)據(jù),觀察這個月的訂單量以及銷售額, 分析下單日期、收貨地址等因素對訂單量的影響以及訂單轉(zhuǎn)換情況,旨在提升用戶下單量和訂單轉(zhuǎn)換率,進(jìn)而提高用戶實際支付額。
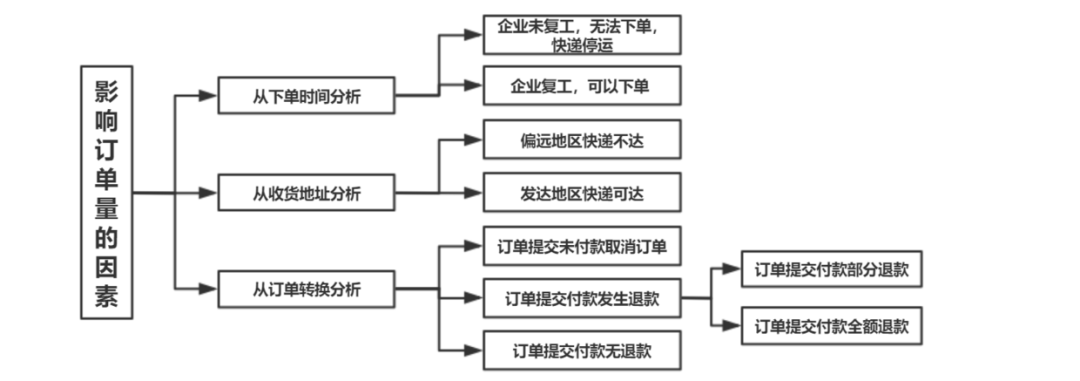
4.2.2 分析邏輯
本文結(jié)合訂單流程以邏輯樹方法分析訂單數(shù)目的影響因素,從以下幾個維度展開:
4.2.3 數(shù)據(jù)讀取及處理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
# 讀取數(shù)據(jù)
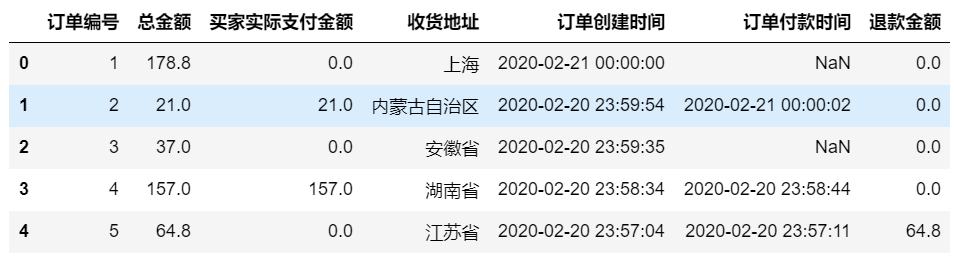
df = pd.read_csv('tmall_order_report.csv')
df.head()
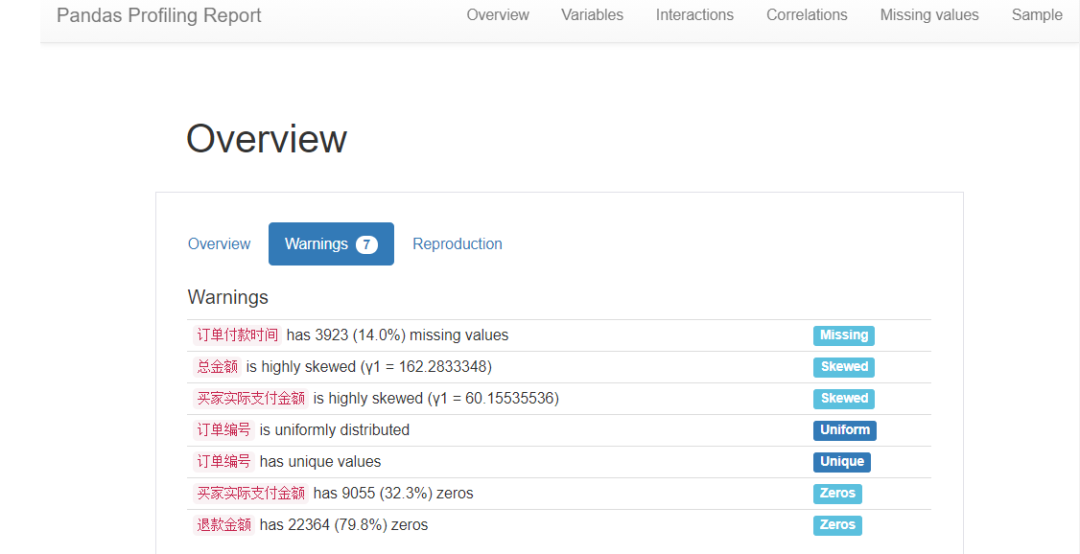
# 利用pandas_profiling一健生成數(shù)據(jù)情況(EDA)報告:數(shù)據(jù)描述、缺失、相關(guān)性等情況
import pandas_profiling as pp
report = pp.ProfileReport(df)
report
#規(guī)范字段名稱
df.columns
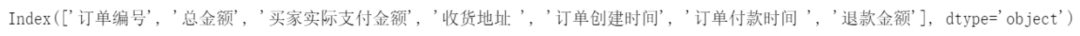
df=df.rename(columns={'收貨地址 ':'收貨地址','訂單付款時間 ':'訂單付款時間'})
df.columns
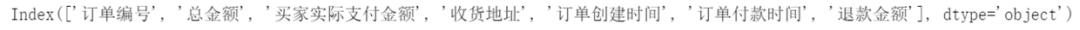
#查看數(shù)據(jù)基本信息
df.info()
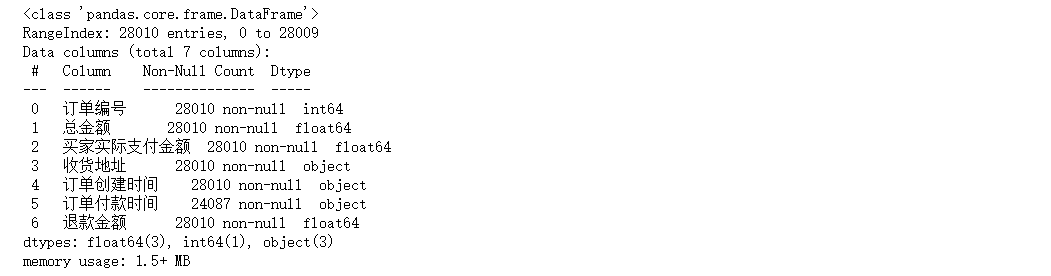
# 數(shù)據(jù)類型轉(zhuǎn)換
df['訂單創(chuàng)建時間']=pd.to_datetime(df.訂單創(chuàng)建時間)
df['訂單付款時間']=pd.to_datetime(df.訂單付款時間)
df.info()

# 數(shù)據(jù)重復(fù)值
df.duplicated().sum()
無
#數(shù)據(jù)缺失值
df.isnull().sum()

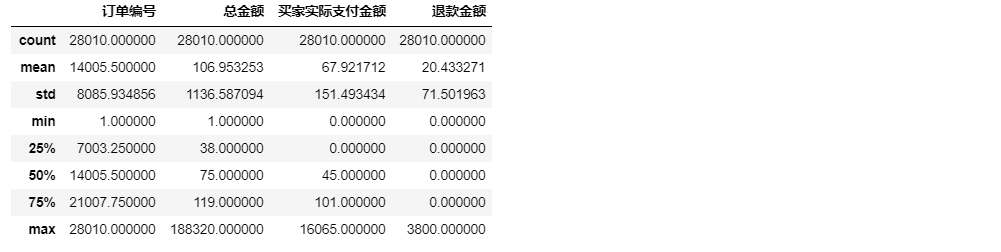
#數(shù)據(jù)集描述性信息
df.describe()
#篩選數(shù)據(jù)集
df_payed=df[df['訂單付款時間'].notnull()]#支付訂單數(shù)據(jù)集
df_trans=df_payed[df_payed['買家實際支付金額']!=0]#到款訂單數(shù)據(jù)集
df_trans_full=df_payed[df_payed['退款金額']==0]#全額到款訂單數(shù)據(jù)集
4.2.4 總體運營指標(biāo)分析
分析2月份成交訂單數(shù)的變化趨勢
import pyecharts.options as opts
#將訂單創(chuàng)建時間設(shè)為index
df_trans=df_trans.set_index('訂單創(chuàng)建時間')
#按天重新采樣
se_trans_month = df_trans.resample('D')['訂單編號'].count()
from pyecharts.charts import Line
#做出標(biāo)有具體數(shù)值的變化圖
name = '成交訂單數(shù)'
(
Line()
.add_xaxis(xaxis_data = list(se_trans_month.index.day.map(str)))
.add_yaxis(
series_name= name,
y_axis= se_trans_month,
)
.set_global_opts(
yaxis_opts = opts.AxisOpts(
splitline_opts = opts.SplitLineOpts(is_show = True)
)
)
.render_notebook()
)
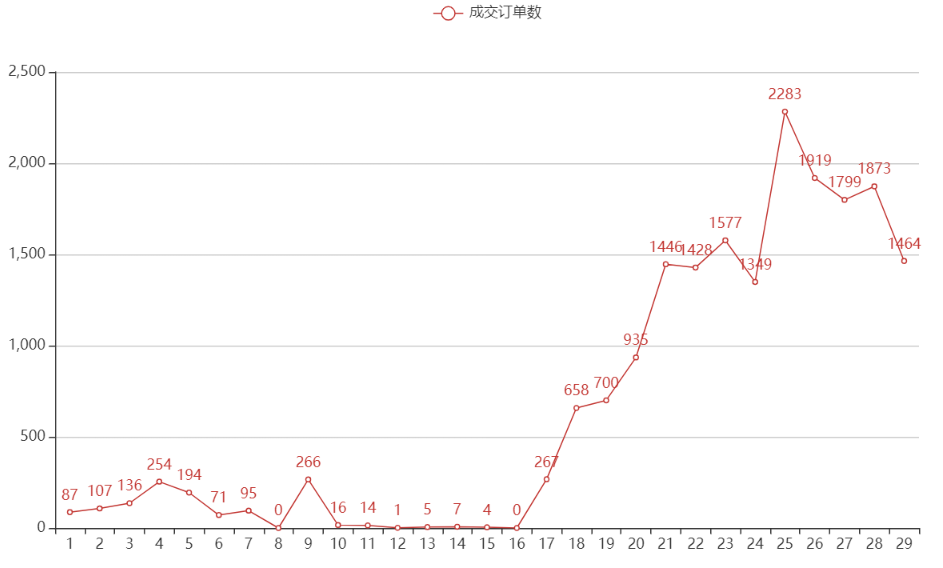
小結(jié) 1 :2月上半月,多數(shù)企業(yè)未復(fù)工,快遞也停運,暫時無法發(fā)貨,訂單數(shù)很少;2月下半月,隨著企業(yè)復(fù)工逐漸增多,訂單數(shù)開始上漲。
se_trans_map=df_trans.groupby('收貨地址')['收貨地址'].count().sort_values(ascending=False)
# 為了保持收貨地址和下面的地理分布圖使用的省份名稱一致,定義一個處理自治區(qū)的函數(shù)
def strip_region(iterable):
result = []
for i in iterable:
if i.endswith('自治區(qū)'):
if i == '內(nèi)蒙古自治區(qū)':
i = i[:3]
result.append(i)
else:
result.append(i[:2])
else:
result.append(i)
return result
# 處理自治區(qū)
se_trans_map.index = strip_region(se_trans_map.index)
# 去掉末位‘省’字
se_trans_map.index = se_trans_map.index.str.strip('省')
import pyecharts.options as opts
from pyecharts.charts import Map
# 展示地理分布圖
name = '訂單數(shù)'
(
Map()
.add(
series_name = name,
data_pair= [list(i) for i in se_trans_map.items()])
.set_global_opts(visualmap_opts=opts.VisualMapOpts(
max_=max(se_trans_map)*0.6
)
)
.render_notebook()
)
用直觀的地圖來觀察成交訂單數(shù)的分布情況
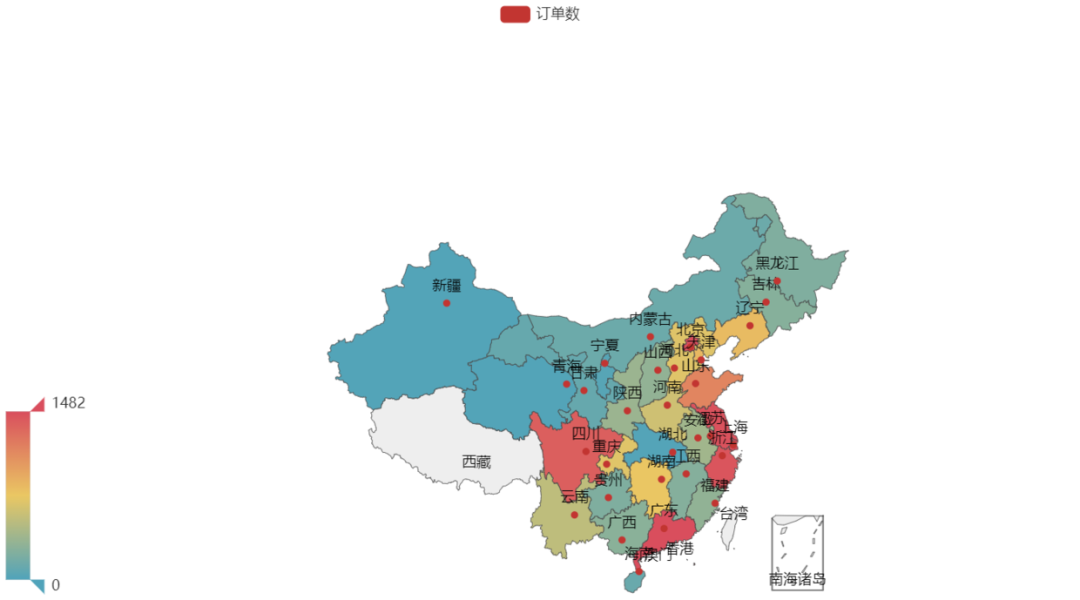
小結(jié) 2 :地區(qū)對訂單數(shù)量影響較大,一般較發(fā)達(dá)地區(qū)訂單數(shù)較大,邊遠(yuǎn)地區(qū)較小。這里可能需要具體分析每個地區(qū)的商品種類、消費群體以及優(yōu)惠政策,快遞等原因。可以根據(jù)原因進(jìn)一步提高其他地區(qū)的訂單數(shù)量和銷售金額。
4.2.5 銷售轉(zhuǎn)化指標(biāo)
訂單數(shù)以及訂單轉(zhuǎn)化率的呈現(xiàn)
dict_convs=dict() #字典
dict_convs['總訂單數(shù)']=len(df)
df_payed
dict_convs['訂單付款數(shù)']=len(df_payed.notnull())
df_trans=df[df['買家實際支付金額']!=0]
dict_convs['到款訂單數(shù)']=len(df_trans)
dict_convs['全額到款訂單數(shù)']=len(df_trans_full)
#字典轉(zhuǎn)為dataframe
df_convs = pd.Series(dict_convs,name = '訂單數(shù)').to_frame()
df_convs
#求總體轉(zhuǎn)換率,依次比上總訂單數(shù)
total_convs=df_convs['訂單數(shù)']/df_convs.loc['總訂單數(shù)','訂單數(shù)']*100
df_convs['總體轉(zhuǎn)化率']=total_convs.apply(lambda x:round(x,0))
df_convs
#求單一轉(zhuǎn)換率
single_convs=df_convs.訂單數(shù)/(df_convs.訂單數(shù).shift())*100
single_convs=single_convs.fillna(100)
df_convs['單一轉(zhuǎn)化率']=single_convs.apply(lambda x:round(x,0))
df_convs

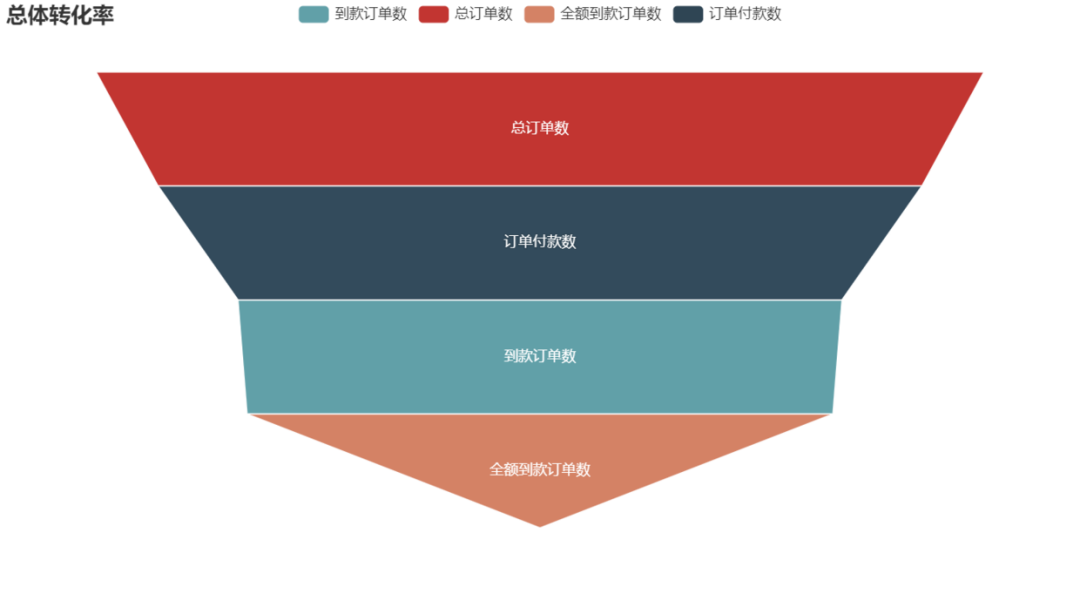
畫轉(zhuǎn)換率漏斗圖,直觀呈現(xiàn)訂單轉(zhuǎn)化情況
from pyecharts.charts import Funnel
from pyecharts import options as opts
name = '總體轉(zhuǎn)化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
name = '單一轉(zhuǎn)化率'
funnel = Funnel().add(
series_name = name,
data_pair = [ list(z) for z in zip(df_convs.index,df_convs[name]) ],
is_selected = True,
label_opts = opts.LabelOpts(position = 'inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = name),
# tooltip_opts = opts.TooltipOpts(formatter = '{a}<br\>{b}:{c}%'),
)
funnel.render_notebook()
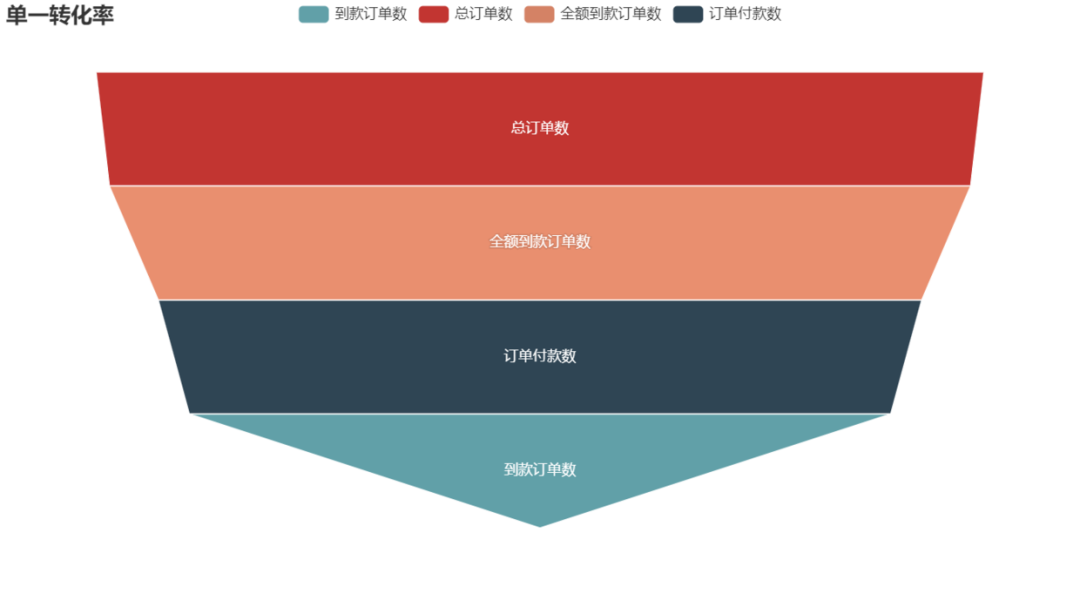
小結(jié) 3:從單一轉(zhuǎn)化率來看,支付訂單數(shù)-到款訂單數(shù)轉(zhuǎn)換率為79%,后續(xù)可以從退款率著手分析退款原因,提高轉(zhuǎn)換率。
文章首發(fā)于算法進(jìn)階,公眾號閱讀原文可訪問GitHub源碼
往期精彩回顧
本站qq群851320808,加入微信群請掃碼: