
Hive - ORC 文件存儲(chǔ)格式詳細(xì)解析
一、ORC File文件結(jié)構(gòu)
ORC的全稱是(Optimized Row Columnar),ORC文件格式是一種Hadoop生態(tài)圈中的列式存儲(chǔ)格式,它的產(chǎn)生早在2013年初,最初產(chǎn)生自Apache Hive,用于降低Hadoop數(shù)據(jù)存儲(chǔ)空間和加速Hive查詢速度。和Parquet類似,它并不是一個(gè)單純的列式存儲(chǔ)格式,仍然是首先根據(jù)行組分割整個(gè)表,在每一個(gè)行組內(nèi)進(jìn)行按列存儲(chǔ)。ORC文件是自描述的,它的元數(shù)據(jù)使用Protocol Buffers序列化,并且文件中的數(shù)據(jù)盡可能的壓縮以降低存儲(chǔ)空間的消耗,目前也被Spark SQL、Presto等查詢引擎支持,但是Impala對(duì)于ORC目前沒有支持,仍然使用Parquet作為主要的列式存儲(chǔ)格式。2015年ORC項(xiàng)目被Apache項(xiàng)目基金會(huì)提升為Apache頂級(jí)項(xiàng)目。ORC具有以下一些優(yōu)勢:
ORC是列式存儲(chǔ),有多種文件壓縮方式,并且有著很高的壓縮比。
文件是可切分(Split)的。因此,在Hive中使用ORC作為表的文件存儲(chǔ)格式,不僅節(jié)省HDFS存儲(chǔ)資源,查詢?nèi)蝿?wù)的輸入數(shù)據(jù)量減少,使用的MapTask也就減少了。
提供了多種索引,row group index、bloom filter index。
ORC可以支持復(fù)雜的數(shù)據(jù)結(jié)構(gòu)(比如Map等)
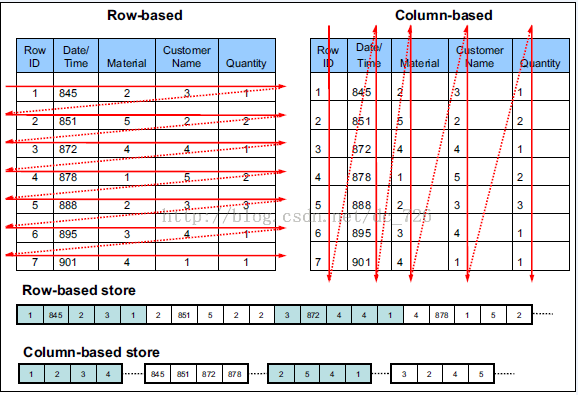
列式存儲(chǔ)
由于OLAP查詢的特點(diǎn),列式存儲(chǔ)可以提升其查詢性能,但是它是如何做到的呢?這就要從列式存儲(chǔ)的原理說起,從圖1中可以看到,相對(duì)于關(guān)系數(shù)據(jù)庫中通常使用的行式存儲(chǔ),在使用列式存儲(chǔ)時(shí)每一列的所有元素都是順序存儲(chǔ)的。由此特點(diǎn)可以給查詢帶來如下的優(yōu)化:
查詢的時(shí)候不需要掃描全部的數(shù)據(jù),而只需要讀取每次查詢涉及的列,這樣可以將I/O消耗降低N倍,另外可以保存每一列的統(tǒng)計(jì)信息(min、max、sum等),實(shí)現(xiàn)部分的謂詞下推。
由于每一列的成員都是同構(gòu)的,可以針對(duì)不同的數(shù)據(jù)類型使用更高效的數(shù)據(jù)壓縮算法,進(jìn)一步減小I/O。
由于每一列的成員的同構(gòu)性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的緩存失效。
關(guān)于Orc文件格式的官網(wǎng)介紹,見:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
需要注意的是,ORC在讀寫時(shí)候需要消耗額外的CPU資源來壓縮和解壓縮,當(dāng)然這部分的CPU消耗是非常少的。
數(shù)據(jù)模型
和Parquet不同,ORC原生是不支持嵌套數(shù)據(jù)格式的,而是通過對(duì)復(fù)雜數(shù)據(jù)類型特殊處理的方式實(shí)現(xiàn)嵌套格式的支持,例如對(duì)于如下的hive表:
CREATE TABLE `orcStructTable`(`name` string,`course` struct<course:string,score:int>,`score` map<string,int>,`work_locations` array<string>)
在ORC的結(jié)構(gòu)中包含了復(fù)雜類型列和原始類型,前者包括LIST、STRUCT、MAP和UNION類型,后者包括BOOLEAN、整數(shù)、浮點(diǎn)數(shù)、字符串類型等,其中STRUCT的孩子節(jié)點(diǎn)包括它的成員變量,可能有多個(gè)孩子節(jié)點(diǎn),MAP有兩個(gè)孩子節(jié)點(diǎn),分別為key和value,LIST包含一個(gè)孩子節(jié)點(diǎn),類型為該LIST的成員類型,UNION一般不怎么用得到。每一個(gè)Schema樹的根節(jié)點(diǎn)為一個(gè)Struct類型,所有的column按照樹的中序遍歷順序編號(hào)。
ORC只需要存儲(chǔ)schema樹中葉子節(jié)點(diǎn)的值,而中間的非葉子節(jié)點(diǎn)只是做一層代理,它們只需要負(fù)責(zé)孩子節(jié)點(diǎn)值得讀取,只有真正的葉子節(jié)點(diǎn)才會(huì)讀取數(shù)據(jù),然后交由父節(jié)點(diǎn)封裝成對(duì)應(yīng)的數(shù)據(jù)結(jié)構(gòu)返回。
文件結(jié)構(gòu)
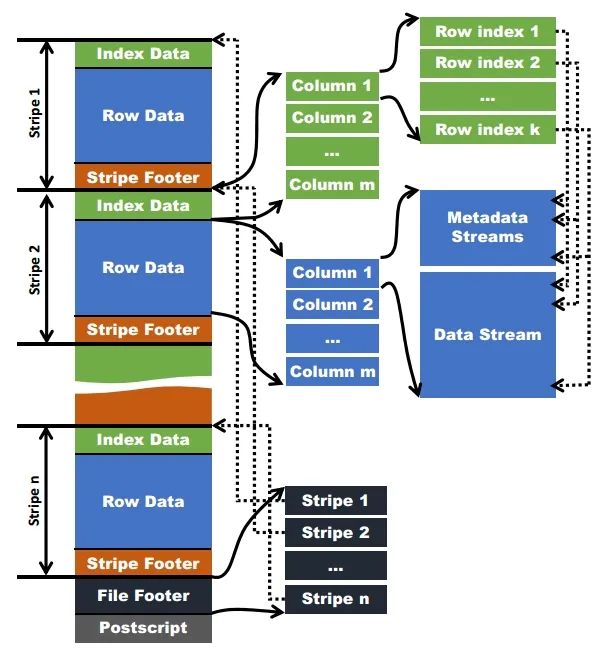
和Parquet類似,ORC文件也是以二進(jìn)制方式存儲(chǔ)的,所以是不可以直接讀取,ORC文件也是自解析的,它包含許多的元數(shù)據(jù),這些元數(shù)據(jù)都是同構(gòu)ProtoBuffer進(jìn)行序列化的。ORC的文件結(jié)構(gòu)如下圖,其中涉及到如下的概念:
ORC文件:保存在文件系統(tǒng)上的普通二進(jìn)制文件,一個(gè)ORC文件中可以包含多個(gè)stripe,每一個(gè)stripe包含多條記錄,這些記錄按照列進(jìn)行獨(dú)立存儲(chǔ),對(duì)應(yīng)到Parquet中的row group的概念。
文件級(jí)元數(shù)據(jù):包括文件的描述信息PostScript、文件meta信息(包括整個(gè)文件的統(tǒng)計(jì)信息)、所有stripe的信息和文件schema信息。
stripe:一組行形成一個(gè)stripe,每次讀取文件是以行組為單位的,一般為HDFS的塊大小,保存了每一列的索引和數(shù)據(jù)。
stripe元數(shù)據(jù):保存stripe的位置、每一個(gè)列的在該stripe的統(tǒng)計(jì)信息以及所有的stream類型和位置。
row group:索引的最小單位,一個(gè)stripe中包含多個(gè)row group,默認(rèn)為10000個(gè)值組成。
stream:一個(gè)stream表示文件中一段有效的數(shù)據(jù),包括索引和數(shù)據(jù)兩類。索引stream保存每一個(gè)row group的位置和統(tǒng)計(jì)信息,數(shù)據(jù)stream包括多種類型的數(shù)據(jù),具體需要哪幾種是由該列類型和編碼方式?jīng)Q定。
在ORC文件中保存了三個(gè)層級(jí)的統(tǒng)計(jì)信息,分別為文件級(jí)別、stripe級(jí)別和row group級(jí)別的,他們都可以用來根據(jù)Search ARGuments(謂詞下推條件)判斷是否可以跳過某些數(shù)據(jù),在統(tǒng)計(jì)信息中都包含成員數(shù)和是否有null值,并且對(duì)于不同類型的數(shù)據(jù)設(shè)置一些特定的統(tǒng)計(jì)信息。
(1)file level
在ORC文件的末尾會(huì)記錄文件級(jí)別的統(tǒng)計(jì)信息,會(huì)記錄整個(gè)文件中columns的統(tǒng)計(jì)信息。這些信息主要用于查詢的優(yōu)化,也可以為一些簡單的聚合查詢比如max, min, sum輸出結(jié)果。
(2)stripe level
ORC文件會(huì)保存每個(gè)字段stripe級(jí)別的統(tǒng)計(jì)信息,ORC reader使用這些統(tǒng)計(jì)信息來確定對(duì)于一個(gè)查詢語句來說,需要讀入哪些stripe中的記錄。比如說某個(gè)stripe的字段max(a)=10,min(a)=3,那么當(dāng)where條件為a >10或者a <3時(shí),那么這個(gè)stripe中的所有記錄在查詢語句執(zhí)行時(shí)不會(huì)被讀入。
(3)row level
為了進(jìn)一步的避免讀入不必要的數(shù)據(jù),在邏輯上將一個(gè)column的index以一個(gè)給定的值(默認(rèn)為10000,可由參數(shù)配置)分割為多個(gè)index組。以10000條記錄為一個(gè)組,對(duì)數(shù)據(jù)進(jìn)行統(tǒng)計(jì)。Hive查詢引擎會(huì)將where條件中的約束傳遞給ORC reader,這些reader根據(jù)組級(jí)別的統(tǒng)計(jì)信息,過濾掉不必要的數(shù)據(jù)。如果該值設(shè)置的太小,就會(huì)保存更多的統(tǒng)計(jì)信息,用戶需要根據(jù)自己數(shù)據(jù)的特點(diǎn)權(quán)衡一個(gè)合理的值。
數(shù)據(jù)訪問
讀取ORC文件是從尾部開始的,第一次讀取16KB的大小,盡可能的將Postscript和Footer數(shù)據(jù)都讀入內(nèi)存。文件的最后一個(gè)字節(jié)保存著PostScript的長度,它的長度不會(huì)超過256字節(jié),PostScript中保存著整個(gè)文件的元數(shù)據(jù)信息,它包括文件的壓縮格式、文件內(nèi)部每一個(gè)壓縮塊的最大長度(每次分配內(nèi)存的大小)、Footer長度,以及一些版本信息。在Postscript和Footer之間存儲(chǔ)著整個(gè)文件的統(tǒng)計(jì)信息(上圖中未畫出),這部分的統(tǒng)計(jì)信息包括每一個(gè)stripe中每一列的信息,主要統(tǒng)計(jì)成員數(shù)、最大值、最小值、是否有空值等。
接下來讀取文件的Footer信息,它包含了每一個(gè)stripe的長度和偏移量,該文件的schema信息(將schema樹按照schema中的編號(hào)保存在數(shù)組中)、整個(gè)文件的統(tǒng)計(jì)信息以及每一個(gè)row group的行數(shù)。
處理stripe時(shí)首先從Footer中獲取每一個(gè)stripe的其實(shí)位置和長度、每一個(gè)stripe的Footer數(shù)據(jù)(元數(shù)據(jù),記錄了index和data的的長度),整個(gè)striper被分為index和data兩部分,stripe內(nèi)部是按照row group進(jìn)行分塊的(每一個(gè)row group中多少條記錄在文件的Footer中存儲(chǔ)),row group內(nèi)部按列存儲(chǔ)。每一個(gè)row group由多個(gè)stream保存數(shù)據(jù)和索引信息。每一個(gè)stream的數(shù)據(jù)會(huì)根據(jù)該列的類型使用特定的壓縮算法保存。在ORC中存在如下幾種stream類型:
PRESENT:每一個(gè)成員值在這個(gè)stream中保持一位(bit)用于標(biāo)示該值是否為NULL,通過它可以只記錄部位NULL的值
DATA:該列的中屬于當(dāng)前stripe的成員值。
LENGTH:每一個(gè)成員的長度,這個(gè)是針對(duì)string類型的列才有的。
DICTIONARY_DATA:對(duì)string類型數(shù)據(jù)編碼之后字典的內(nèi)容。
SECONDARY:存儲(chǔ)Decimal、timestamp類型的小數(shù)或者納秒數(shù)等。
ROW_INDEX:保存stripe中每一個(gè)row group的統(tǒng)計(jì)信息和每一個(gè)row group起始位置信息。
在初始化階段獲取全部的元數(shù)據(jù)之后,可以通過includes數(shù)組指定需要讀取的列編號(hào),它是一個(gè)boolean數(shù)組,如果不指定則讀取全部的列,還可以通過傳遞SearchArgument參數(shù)指定過濾條件,根據(jù)元數(shù)據(jù)首先讀取每一個(gè)stripe中的index信息,然后根據(jù)index中統(tǒng)計(jì)信息以及SearchArgument參數(shù)確定需要讀取的row group編號(hào),再根據(jù)includes數(shù)據(jù)決定需要從這些row group中讀取的列,通過這兩層的過濾需要讀取的數(shù)據(jù)只是整個(gè)stripe多個(gè)小段的區(qū)間,然后ORC會(huì)盡可能合并多個(gè)離散的區(qū)間盡可能的減少I/O次數(shù)。然后再根據(jù)index中保存的下一個(gè)row group的位置信息調(diào)至該stripe中第一個(gè)需要讀取的row group中。
ORC文件格式只支持讀取指定字段,還不支持只讀取特殊字段類型中的指定部分。
使用ORC文件格式時(shí),用戶可以使用HDFS的每一個(gè)block存儲(chǔ)ORC文件的一個(gè)stripe。對(duì)于一個(gè)ORC文件來說,stripe的大小一般需要設(shè)置得比HDFS的block小,如果不這樣的話,一個(gè)stripe就會(huì)分別在HDFS的多個(gè)block上,當(dāng)讀取這種數(shù)據(jù)時(shí)就會(huì)發(fā)生遠(yuǎn)程讀數(shù)據(jù)的行為。如果設(shè)置stripe的只保存在一個(gè)block上的話,如果當(dāng)前block上的剩余空間不足以存儲(chǔ)下一個(gè)strpie,ORC的writer接下來會(huì)將數(shù)據(jù)打散保存在block剩余的空間上,直到這個(gè)block存滿為止。這樣,下一個(gè)stripe又會(huì)從下一個(gè)block開始存儲(chǔ)。
由于ORC中使用了更加精確的索引信息,使得在讀取數(shù)據(jù)時(shí)可以指定從任意一行開始讀取,更細(xì)粒度的統(tǒng)計(jì)信息使得讀取ORC文件跳過整個(gè)row group,ORC默認(rèn)會(huì)對(duì)任何一塊數(shù)據(jù)和索引信息使用ZLIB壓縮,因此ORC文件占用的存儲(chǔ)空間也更小,這點(diǎn)在后面的測試對(duì)比中也有所印證。
文件壓縮
ORC文件使用兩級(jí)壓縮機(jī)制,首先將一個(gè)數(shù)據(jù)流使用流式編碼器進(jìn)行編碼,然后使用一個(gè)可選的壓縮器對(duì)數(shù)據(jù)流進(jìn)行進(jìn)一步壓縮。
一個(gè)column可能保存在一個(gè)或多個(gè)數(shù)據(jù)流中,可以將數(shù)據(jù)流劃分為以下四種類型:
? Byte Stream
字節(jié)流保存一系列的字節(jié)數(shù)據(jù),不對(duì)數(shù)據(jù)進(jìn)行編碼。
? Run Length Byte Stream
字節(jié)長度字節(jié)流保存一系列的字節(jié)數(shù)據(jù),對(duì)于相同的字節(jié),保存這個(gè)重復(fù)值以及該值在字節(jié)流中出現(xiàn)的位置。
? Integer Stream
整形數(shù)據(jù)流保存一系列整形數(shù)據(jù)。可以對(duì)數(shù)據(jù)量進(jìn)行字節(jié)長度編碼以及delta編碼。具體使用哪種編碼方式需要根據(jù)整形流中的子序列模式來確定。
? Bit Field Stream
比特流主要用來保存boolean值組成的序列,一個(gè)字節(jié)代表一個(gè)boolean值,在比特流的底層是用Run Length Byte Stream來實(shí)現(xiàn)的。
接下來會(huì)以Integer和String類型的字段舉例來說明。
(1)Integer
對(duì)于一個(gè)整形字段,會(huì)同時(shí)使用一個(gè)比特流和整形流。比特流用于標(biāo)識(shí)某個(gè)值是否為null,整形流用于保存該整形字段非空記錄的整數(shù)值。
(2)String
對(duì)于一個(gè)String類型字段,ORC writer在開始時(shí)會(huì)檢查該字段值中不同的內(nèi)容數(shù)占非空記錄總數(shù)的百分比不超過0.8的話,就使用字典編碼,字段值會(huì)保存在一個(gè)比特流,一個(gè)字節(jié)流及兩個(gè)整形流中。比特流也是用于標(biāo)識(shí)null值的,字節(jié)流用于存儲(chǔ)字典值,一個(gè)整形流用于存儲(chǔ)字典中每個(gè)詞條的長度,另一個(gè)整形流用于記錄字段值。
如果不能用字典編碼,ORC writer會(huì)知道這個(gè)字段的重復(fù)值太少,用字典編碼效率不高,ORC writer會(huì)使用一個(gè)字節(jié)流保存String字段的值,然后用一個(gè)整形流來保存每個(gè)字段的字節(jié)長度。
在ORC文件中,在各種數(shù)據(jù)流的底層,用戶可以自選ZLIB, Snappy和LZO壓縮方式對(duì)數(shù)據(jù)流進(jìn)行壓縮。編碼器一般會(huì)將一個(gè)數(shù)據(jù)流壓縮成一個(gè)個(gè)小的壓縮單元,在目前的實(shí)現(xiàn)中,壓縮單元的默認(rèn)大小是256KB。
二、Hive+ORC建立數(shù)據(jù)倉庫
在建Hive表的時(shí)候我們就應(yīng)該指定文件的存儲(chǔ)格式。所以你可以在Hive QL語句里面指定用ORCFile這種文件格式,如下:
CREATE TABLE ... STORED AS ORC
ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
SET hive.default.fileformat=Orc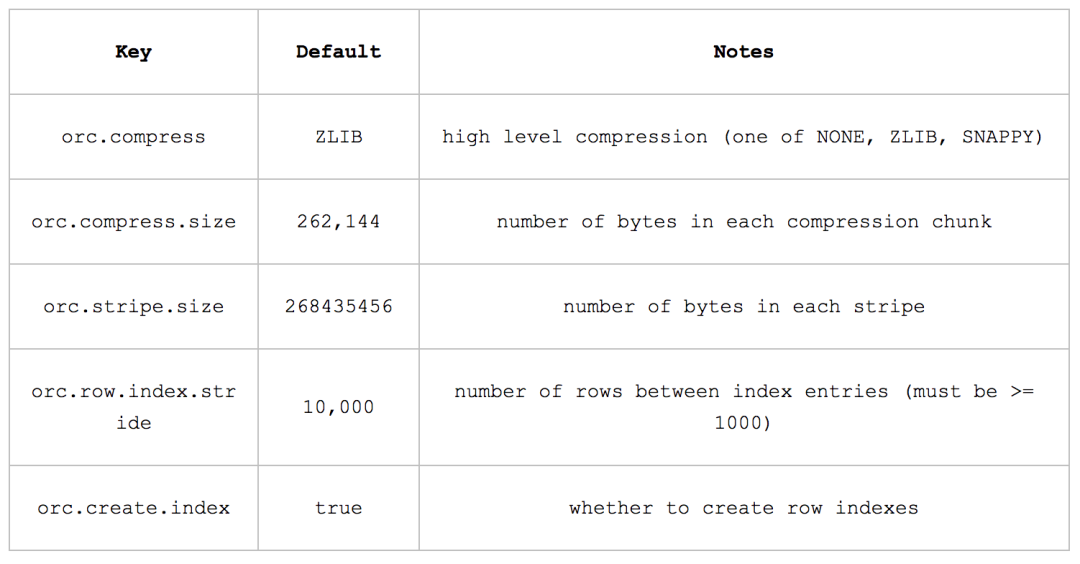
三、Java操作ORC
到https://orc.apache.org官網(wǎng)下載orc源碼包,然后編譯獲取orc-core-1.3.0.jar、orc-mapreduce-1.3.0.jar、orc-tools-1.3.0.jar,將其加入項(xiàng)目中
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.hive.ql.exec.vector.LongColumnVector;import org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch;import org.apache.orc.CompressionKind;import org.apache.orc.OrcFile;import org.apache.orc.TypeDescription;import org.apache.orc.Writer;public class TestORCWriter {public static void main(String[] args) throws Exception {Path testFilePath = new Path("/tmp/test.orc");Configuration conf = new Configuration();TypeDescription schema = TypeDescription.fromString("struct<field1:int,field2:int,field3:int>");Writer writer = OrcFile.createWriter(testFilePath, OrcFile.writerOptions(conf).setSchema(schema).compress(CompressionKind.SNAPPY));VectorizedRowBatch batch = schema.createRowBatch();LongColumnVector first = (LongColumnVector) batch.cols[0];LongColumnVector second = (LongColumnVector) batch.cols[1];LongColumnVector third = (LongColumnVector) batch.cols[2];final int BATCH_SIZE = batch.getMaxSize();// add 1500 rows to filefor (int r = 0; r < 15000000; ++r) {int row = batch.size++;first.vector[row] = r;second.vector[row] = r * 3;third.vector[row] = r * 6;if (row == BATCH_SIZE - 1) {writer.addRowBatch(batch);batch.reset();}}if (batch.size != 0) {writer.addRowBatch(batch);batch.reset();}writer.close();}}
大多情況下,還是建議在Hive中將文本文件轉(zhuǎn)成ORC格式,這種用JAVA在本地生成ORC文件,屬于特殊需求場景。
參考:
http://lxw1234.com/archives/2016/04/630.htm
https://www.iteblog.com/archives/1014.html
http://blog.csdn.net/dabokele/article/details/51542327
http://blog.csdn.net/dabokele/article/details/51813322
http://blog.csdn.net/nysyxxg/article/details/52241848
http://blog.csdn.net/yu616568/article/details/51868447