
Hive文件存儲(chǔ)格式和Hive數(shù)據(jù)壓縮小總結(jié)
一、存儲(chǔ)格式行存儲(chǔ)和列存儲(chǔ)
行存儲(chǔ)可以理解為一條記錄存儲(chǔ)一行,通過(guò)條件能夠查詢一整行數(shù)據(jù)。
列存儲(chǔ),以字段聚集存儲(chǔ),可以理解為相同的字段存儲(chǔ)在一起。
二、Hive文件存儲(chǔ)格式
TEXTFILE
Hive數(shù)據(jù)表的默認(rèn)格式,存儲(chǔ)方式:行存儲(chǔ)。
可以使用Gzip壓縮算法,但壓縮后的文件不支持split。
在反序列化過(guò)程中,必須逐個(gè)字符判斷是不是分隔符和行結(jié)束符,因此反序列化開(kāi)銷(xiāo)會(huì)比SequenceFile高幾十倍。
SEQUENCEFILE
壓縮數(shù)據(jù)文件可以節(jié)省磁盤(pán)空間,但Hadoop中有些原生壓縮文件的缺點(diǎn)之一就是不支持分割。支持分割的文件可以并行的有多個(gè)mapper程序處理大數(shù)據(jù)文件,大多數(shù)文件不支持可分割是因?yàn)檫@些文件只能從頭開(kāi)始讀。Sequence File是可分割的文件格式,支持Hadoop的block級(jí)壓縮。
Hadoop API提供的一種二進(jìn)制文件,以key-value的形式序列化到文件中。存儲(chǔ)方式:行存儲(chǔ)。
sequencefile支持三種壓縮選擇:NONE,RECORD,BLOCK。Record壓縮率低,RECORD是默認(rèn)選項(xiàng),通常BLOCK會(huì)帶來(lái)較RECORD更好的壓縮性能。
優(yōu)勢(shì)是文件和hadoop api中的MapFile是相互兼容的
RCFILE
存儲(chǔ)方式:數(shù)據(jù)按行分塊,每塊按列存儲(chǔ)。結(jié)合了行存儲(chǔ)和列存儲(chǔ)的優(yōu)點(diǎn):
RCFile 保證同一行的數(shù)據(jù)位于同一節(jié)點(diǎn),因此元組重構(gòu)的開(kāi)銷(xiāo)很低
像列存儲(chǔ)一樣,RCFile 能夠利用列維度的數(shù)據(jù)壓縮,并且能跳過(guò)不必要的列讀取
數(shù)據(jù)追加:RCFile不支持任意方式的數(shù)據(jù)寫(xiě)操作,僅提供一種追加接口,這是因?yàn)榈讓拥?HDFS當(dāng)前僅僅支持?jǐn)?shù)據(jù)追加寫(xiě)文件尾部。
行組大小:行組變大有助于提高數(shù)據(jù)壓縮的效率,但是可能會(huì)損害數(shù)據(jù)的讀取性能,因?yàn)檫@樣增加了 Lazy 解壓性能的消耗。而且行組變大會(huì)占用更多的內(nèi)存,這會(huì)影響并發(fā)執(zhí)行的其他MR作業(yè)。考慮到存儲(chǔ)空間和查詢效率兩個(gè)方面,F(xiàn)acebook 選擇 4MB 作為默認(rèn)的行組大小,當(dāng)然也允許用戶自行選擇參數(shù)進(jìn)行配置。
ORCFILE
存儲(chǔ)方式:數(shù)據(jù)按行分塊,每塊按照列存儲(chǔ)。
壓縮快,快速列存取。效率比rcfile高,是rcfile的改良版本。
三、創(chuàng)建語(yǔ)句和壓縮
3.1 壓縮工具的對(duì)比:
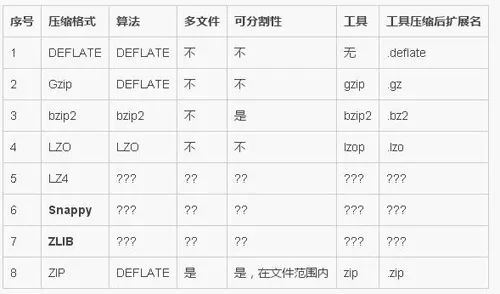
Hadoop編碼/解碼器方式,如下表所示

3.2、壓縮設(shè)置
HiveQL語(yǔ)句最終都將轉(zhuǎn)換成為hadoop中的MapReduce job,而MapReduce job可以有對(duì)處理的數(shù)據(jù)進(jìn)行壓縮。
Hive中間數(shù)據(jù)壓縮
hive.exec.compress.intermediate:默認(rèn)為false,設(shè)置true為激活中間數(shù)據(jù)壓縮功能,就是MapReduce的shuffle階段對(duì)mapper產(chǎn)生中間壓縮,在這個(gè)階段,優(yōu)先選擇一個(gè)低CPU開(kāi)銷(xiāo):
set hive.exec.compress.intermediate=true
set mapred.map.output.compression.codec= org.apache.hadoop.io.compress.SnappyCodec
set mapred.map.output.compression.codec=com.hadoop.compression.lzo.LzoCodec最終輸出結(jié)果壓縮
hive.exec.compress.output:用戶可以對(duì)最終生成的Hive表的數(shù)據(jù)通常也需要壓縮。該參數(shù)控制這一功能的激活與禁用,設(shè)置為true來(lái)聲明將結(jié)果文件進(jìn)行壓縮。
mapred.output.compression.codec:將hive.exec.compress.output參數(shù)設(shè)置成true后,然后選擇一個(gè)合適的編解碼器,如選擇SnappyCodec。設(shè)置如下(兩種壓縮的編寫(xiě)方式是一樣的):
set hive.exec.compress.output=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
或者
或者
set mapred.output.compress=true
set mapred.output.compression.codec=org.apache.hadoop.io.compress.LzopCodec3.3、 四種格式的存儲(chǔ)和壓縮設(shè)置(客戶端設(shè)置壓縮格式)
TEXTFILE
create table if not exists textfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as textfile;
插入數(shù)據(jù)操作:
set hive.exec.compress.output=true; //輸出結(jié)果壓縮開(kāi)啟
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; //壓縮和解壓縮編碼類(lèi)列表,用逗號(hào)分隔,將所用到解壓和壓縮碼設(shè)置其中
insert overwrite table textfile_table select * from testfile_table;SEQUENCEFILE
create table if not exists seqfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as sequencefile;
插入數(shù)據(jù)操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
SET mapred.output.compression.type=BLOCK;
insert overwrite table seqfile_table select * from testfile_table;RCFILE
create table if not exists rcfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as rcfile;
插入數(shù)據(jù)操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from testfile_table;ORCFILE
create table if not exists orcfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as orc;
插入數(shù)據(jù)操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table orcfile_table select * from testfile_table;總結(jié):
TextFile默認(rèn)格式,加載速度最快,可以采用Gzip進(jìn)行壓縮,壓縮后的文件無(wú)法split,無(wú)法并行處理了。
SequenceFile壓縮率最低,查詢速度一般,將數(shù)據(jù)存放到sequenceFile格式的hive表中,這時(shí)數(shù)據(jù)就會(huì)壓縮存儲(chǔ)。三種壓縮格式NONE,RECORD,BLOCK。是可分割的文件格式.
RCfile壓縮率最高,查詢速度最快,數(shù)據(jù)加載最慢。
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存儲(chǔ)方式,數(shù)據(jù)加載時(shí)性能消耗較大,但是具有較好的壓縮比和查詢響應(yīng)。數(shù)據(jù)倉(cāng)庫(kù)的特點(diǎn)是一次寫(xiě)入、多次讀取,因此,整體來(lái)看,RCFILE相比其余兩種格式具有較明顯的優(yōu)勢(shì)。
在hive中使用壓縮需要靈活的方式,如果是數(shù)據(jù)源的話,采用RCFile+bz或RCFile+gz的方式,這樣可以很大程度上節(jié)省磁盤(pán)空間;而在計(jì)算的過(guò)程中,為了不影響執(zhí)行的速度,可以浪費(fèi)一點(diǎn)磁盤(pán)空間,建議采用RCFile+snappy的方式,這樣可以整體提升hive的執(zhí)行速度。至于lzo的方式,也可以在計(jì)算過(guò)程中使用,只不過(guò)綜合考慮(速度和壓縮比)還是考慮snappy適宜。