
解惑“高深”的Kafka時間輪原理
【摘要】 Kafka時間輪是Kafka實現(xiàn)高效的延時任務(wù)的基礎(chǔ),它模擬了現(xiàn)實生活中的鐘表對時間的表示方式,同時,時間輪的方式并不僅限于Kafka,它是一種通用的時間表示方式,本文主要介紹Kafka中的時間輪原理。
Kafka中存在一些定時任務(wù)(DelayedOperation),如DelayedFetch、DelayedProduce、DelayedHeartbeat等,在Kafka中,定時任務(wù)的添加、輪轉(zhuǎn)、執(zhí)行、消亡等是通過時間輪來實現(xiàn)的。(時間輪并不是Kafka獨有的設(shè)計,而是一種通用的實現(xiàn)方式,Netty中也有用到時間輪的方式)
1. 時間輪是什么
參考網(wǎng)上的兩張圖(摘自
https://blog.csdn.net/u013256816/article/details/80697456)
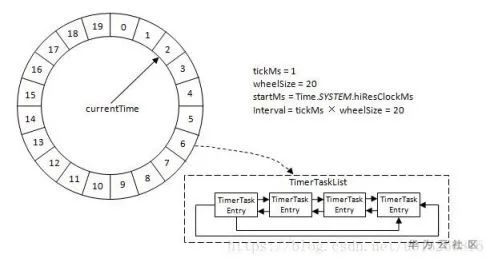

這兩張圖就比較清楚的說明了Kafka時間輪的結(jié)構(gòu)了:類似現(xiàn)實中的鐘表,由多個環(huán)形數(shù)組組成,每個環(huán)形數(shù)組包含20個時間單位,表示一個時間維度(一輪),如:第一層時間輪,數(shù)組中的每個元素代表1ms,一圈就是20ms,當延遲時間大于20ms時,就“進位”到第二層時間輪,第二層中,每“一格”表示20ms,依此類推…
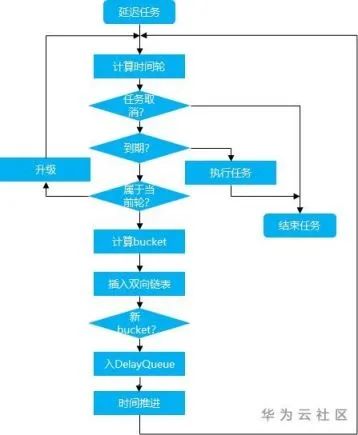
對于一個延遲任務(wù),大體包含三個過程:進入時間輪、降級和到期執(zhí)行。
進入時間輪
1. 根據(jù)延遲時間計算對應(yīng)的時間輪“層次”(如鐘表中的“小時級”還是“分鐘級”還是“秒級”,實際上是一個不斷“升級”的過程,直到找到合適的“層次”)
2. 計算在該輪中的位置,并插入該位置(每個bucket是一個雙向鏈表,可能包含多個延遲任務(wù),這也是時間輪提高效率的一大原因,后面會提到)
3. 若該bucket是首次插入,需要將該bucket加入DelayQueue中(DelayQueue的引入是為了解決“空推進”,后面會提到)
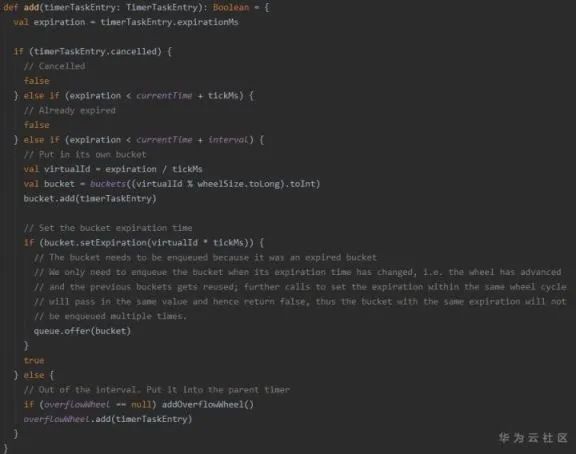
降級
1. 當時間“推進”到某個bucket時,說明該bucket中的任務(wù)在當前時間輪中的時間已經(jīng)走完,需要進行“降級”,即進入更小粒度的時間輪中,reinsert的過程和進入時間輪是類似的
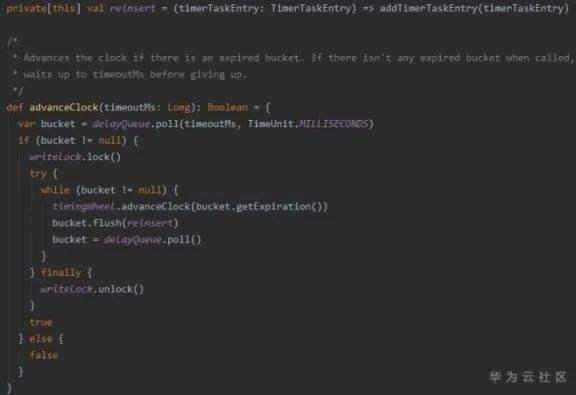
到期執(zhí)行
1. 在reinsert的過程中,若發(fā)現(xiàn)已經(jīng)到期,則執(zhí)行這些任務(wù)
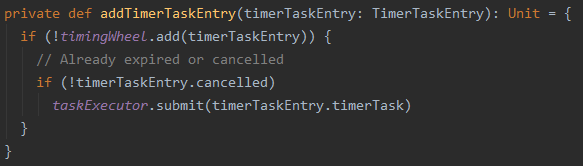
整體過程大致如下:
2. 時間的“推進”
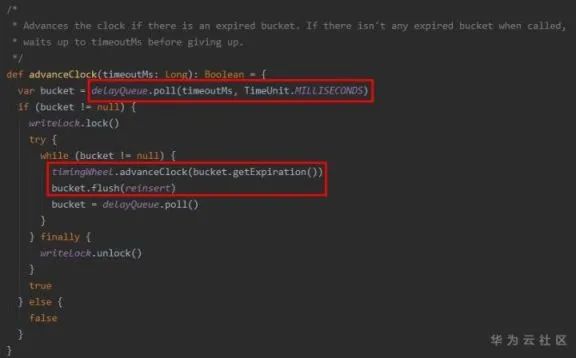
一種直觀的想法是,像現(xiàn)實中的鐘表一樣,“一格一格”地走,這樣就需要有一個線程一直不停的執(zhí)行,而大多數(shù)情況下,時間輪中的bucket大部分是空的,指針的“推進”就沒有實質(zhì)作用,因此,為了減少這種“空推進”,Kafka引入了DelayQueue,以bucket為單位入隊,每當有bucket到期,即queue.poll能拿到結(jié)果時,才進行時間的“推進”,減少了 ExpiredOperationReaper 線程空轉(zhuǎn)的開銷。
3. 為什么要用時間輪
用到延遲任務(wù)時,比較直接的想法是DelayQueue、ScheduledThreadPoolExecutor 這些,而時間輪相比之下,最大的優(yōu)勢是在時間復(fù)雜度上:
時間復(fù)雜度對比:
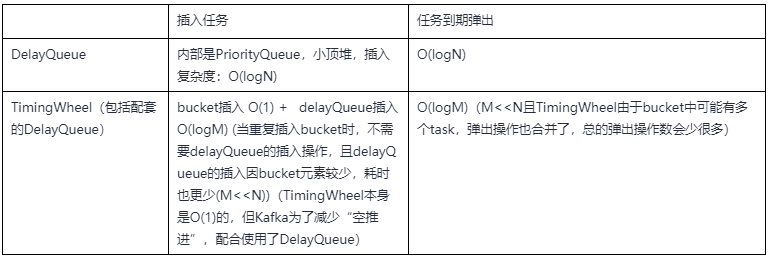
因此,理論上,當任務(wù)較多時,TimingWheel的時間性能優(yōu)勢會更明顯
總結(jié)一下Kafka時間輪性能高的幾個主要原因:
(1)時間輪的結(jié)構(gòu)+雙向列表bucket,使得插入操作可以達到O(1)的時間復(fù)雜度
(2)Bucket的設(shè)計讓多個任務(wù)“合并”,使得同一個bucket的多次插入只需要在delayQueue中入隊一次,同時減少了delayQueue中元素數(shù)量,堆的深度也減小,delayqueue的插入和彈出操作開銷也更小。