Kafka生產(chǎn)者的使用和原理

本文將學(xué)習(xí)Kafka生產(chǎn)者的使用和原理,文中使用的kafka-clients版本號為2.6.0。下面進(jìn)入正文,先通過一個示例看下如何使用生產(chǎn)者API發(fā)送消息。
public?class?Producer?{
????
????public?static?void?main(String[]?args)?{
????????//?1.?配置參數(shù)
????????Properties?properties?=?new?Properties();
????????properties.put("bootstrap.servers",?"localhost:9092");
????????properties.put("key.serializer",
????????????????"org.apache.kafka.common.serialization.StringSerializer");
????????properties.put("value.serializer",
????????????????"org.apache.kafka.common.serialization.StringSerializer");
????????//?2.?根據(jù)參數(shù)創(chuàng)建KafkaProducer實例(生產(chǎn)者)
????????KafkaProducer?producer?=?new?KafkaProducer<>(properties);
????????//?3.?創(chuàng)建ProducerRecord實例(消息)
????????ProducerRecord?record?=?new?ProducerRecord<>("topic-demo",?"hello?kafka");
????????//?4.?發(fā)送消息
????????producer.send(record);
????????//?5.?關(guān)閉生產(chǎn)者示例
????????producer.close();
????}
????
}
首先創(chuàng)建一個Properties實例,設(shè)置了三個必填參數(shù):
bootstrap.servers:broker的地址清單;key.serializer:消息的鍵的序列化器;value.serializer:消息的值的序列化器。
由于broker希望接受的是字節(jié)數(shù)組,所以需要將消息中的鍵值序列化成字節(jié)數(shù)組。在設(shè)置好參數(shù)后,根據(jù)參數(shù)創(chuàng)建KafkaProducer實例,也就是用于發(fā)送消息的生產(chǎn)者,接著再創(chuàng)建準(zhǔn)備發(fā)送的消息ProducerRecord實例,然后使用KafkaProducer的send方法發(fā)送消息,最后再關(guān)閉生產(chǎn)者。
關(guān)于KafkaProducer,我們先記住兩點:
在創(chuàng)建實例的時候,需要指定配置; send方法可發(fā)送消息。
關(guān)于配置我們先只了解這三個必填參數(shù),下面我們看下send方法,關(guān)于發(fā)送消息的方式有三種:
發(fā)送并忘記(fire-and-forget)
在發(fā)送消息給Kafka時,不關(guān)心消息是否正常到達(dá),只負(fù)責(zé)成功發(fā)送,存在丟失消息的可能。上面給出的示例就是這種方式。
同步發(fā)送(sync)
send方法的返回值是一個Future對象,當(dāng)調(diào)用其get方法時將阻塞等待Kafka的響應(yīng)。如下:Future?recordMetadataFuture?=?producer.send(record);
RecordMetadata?recordMetadata?=?recordMetadataFuture.get();RecordMetadata對象中包含有消息的一些元數(shù)據(jù),如消息的主題、分區(qū)號、分區(qū)中的偏移量、時間戳等。異步發(fā)送(async)
在調(diào)用
send方法時,指定回調(diào)函數(shù),在Kafka返回響應(yīng)時,將調(diào)用該函數(shù)。如下:producer.send(record,?new?Callback()?{
????@Override
????public?void?onCompletion(RecordMetadata?recordMetadata,?Exception?e)?{
????????if?(e?!=?null)?{
????????????e.printStackTrace();
????????}?else?{
????????????System.out.println(recordMetadata.topic()?+?"-"
???????????????????????????????+?recordMetadata.partition()?+?":"?+?recordMetadata.offset());
????????}
????}
});onCompletion有兩個參數(shù),其類型分別是RecordMetadata和Exception。當(dāng)消息發(fā)送成功時,recordMetadata為非null,而e將為null。當(dāng)消息發(fā)送失敗時,則反之。
下面我們認(rèn)識下消息對象ProducerRecord,封裝了發(fā)送的消息,其定義如下:
public?class?ProducerRecord<K,?V>?{
????private?final?String?topic;??//?主題
????private?final?Integer?partition;??//?分區(qū)號
????private?final?Headers?headers;??//?消息頭部
????private?final?K?key;??//?鍵
????private?final?V?value;??//?值
????private?final?Long?timestamp;??//?時間戳
????//?...其他構(gòu)造方法和成員方法
}
其中主題和值為必填,其余非必填。例如當(dāng)給出了分區(qū)號,則相當(dāng)于指定了分區(qū),而當(dāng)未給出分區(qū)號時,若給出了鍵,則可用于計算分區(qū)號。關(guān)于消息頭部和時間戳,暫不講述。
在對生產(chǎn)者對象KafkaProducer和消息對象ProducerRecord有了認(rèn)識后,下面我們看下在使用生產(chǎn)者發(fā)送消息時,會使用到的組件有生產(chǎn)者攔截器、序列化器和分區(qū)器。其架構(gòu)(部分)如下:
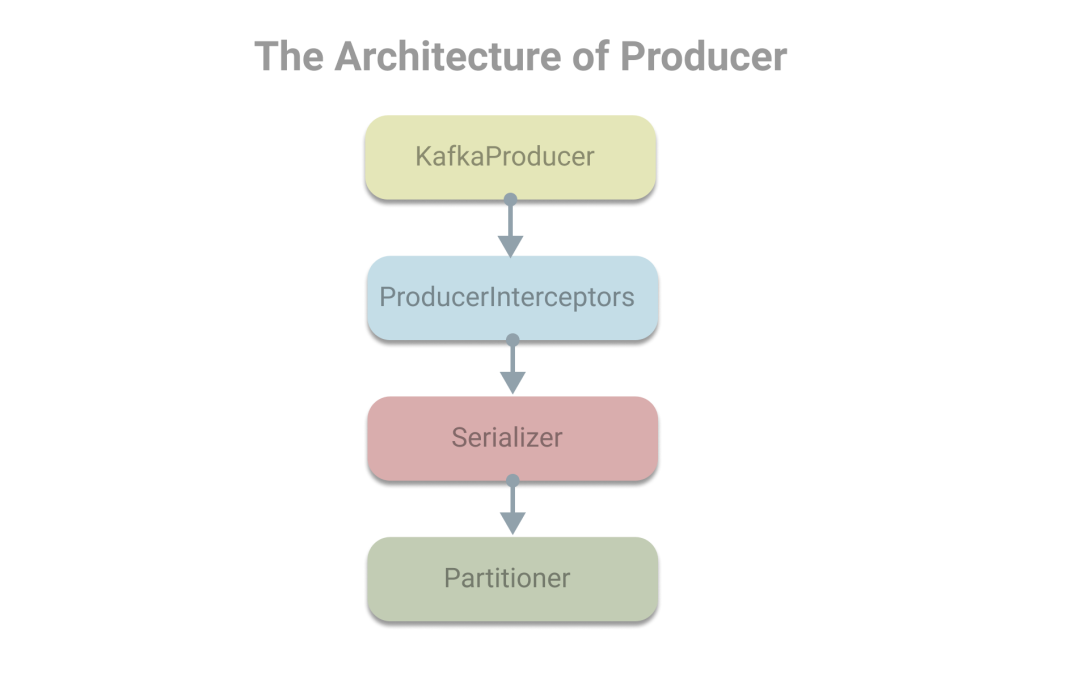
生產(chǎn)者攔截器: ProducerInterceptor接口,主要用于在消息發(fā)送前做一些準(zhǔn)備工作,比如對消息做過濾,或者修改消息內(nèi)容,也可以用于在發(fā)送回調(diào)邏輯前做一些定制化的需求,例如統(tǒng)計類工作。序列化器, Serializer接口,用于將數(shù)據(jù)轉(zhuǎn)換為字節(jié)數(shù)組。分區(qū)器, Partitioner接口,若未指定分區(qū)號,且提供key。
下面結(jié)合代碼來看下處理過程,加深印象。
public?Future?send(ProducerRecord?record,?Callback?callback) ? {
????//?攔截器,攔截消息進(jìn)行處理
????ProducerRecord?interceptedRecord?=?this.interceptors.onSend(record);
????return?doSend(interceptedRecord,?callback);
}
上面是KafkaProducer的send方法,首先會將消息傳給攔截器的onSend方法,然后進(jìn)入doSend方法。其中doSend方法較長,但內(nèi)容并不復(fù)雜,下面給出了主要步驟的注釋。
private?Future?doSend(ProducerRecord?record,?Callback?callback) ? {
????TopicPartition?tp?=?null;
????try?{
????????throwIfProducerClosed();
????????//?1.確認(rèn)數(shù)據(jù)發(fā)送到的topic的metadata可用
????????long?nowMs?=?time.milliseconds();
????????ClusterAndWaitTime?clusterAndWaitTime;
????????try?{
????????????clusterAndWaitTime?=?waitOnMetadata(record.topic(),?record.partition(),?nowMs,?maxBlockTimeMs);
????????}?catch?(KafkaException?e)?{
????????????if?(metadata.isClosed())
????????????????throw?new?KafkaException("Producer?closed?while?send?in?progress",?e);
????????????throw?e;
????????}
????????nowMs?+=?clusterAndWaitTime.waitedOnMetadataMs;
????????long?remainingWaitMs?=?Math.max(0,?maxBlockTimeMs?-?clusterAndWaitTime.waitedOnMetadataMs);
????????Cluster?cluster?=?clusterAndWaitTime.cluster;
????????//?2.序列化器,序列化消息的key和value
????????byte[]?serializedKey;
????????try?{
????????????serializedKey?=?keySerializer.serialize(record.topic(),?record.headers(),?record.key());
????????}?catch?(ClassCastException?cce)?{
????????????throw?new?SerializationException("Can't?convert?key?of?class?"?+?record.key().getClass().getName()?+
?????????????????????????????????????????????"?to?class?"?+?producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName()?+
?????????????????????????????????????????????"?specified?in?key.serializer",?cce);
????????}
????????byte[]?serializedValue;
????????try?{
????????????serializedValue?=?valueSerializer.serialize(record.topic(),?record.headers(),?record.value());
????????}?catch?(ClassCastException?cce)?{
????????????throw?new?SerializationException("Can't?convert?value?of?class?"?+?record.value().getClass().getName()?+
?????????????????????????????????????????????"?to?class?"?+?producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName()?+
?????????????????????????????????????????????"?specified?in?value.serializer",?cce);
????????}
????????//?3.分區(qū)器,獲取或計算分區(qū)號
????????int?partition?=?partition(record,?serializedKey,?serializedValue,?cluster);
????????tp?=?new?TopicPartition(record.topic(),?partition);
????????setReadOnly(record.headers());
????????Header[]?headers?=?record.headers().toArray();
????????int?serializedSize?=?AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
???????????????????????????????????????????????????????????????????????????compressionType,?serializedKey,?serializedValue,?headers);
????????ensureValidRecordSize(serializedSize);
????????long?timestamp?=?record.timestamp()?==?null???nowMs?:?record.timestamp();
????????if?(log.isTraceEnabled())?{
????????????log.trace("Attempting?to?append?record?{}?with?callback?{}?to?topic?{}?partition?{}",?record,?callback,?record.topic(),?partition);
????????}
????????Callback?interceptCallback?=?new?InterceptorCallback<>(callback,?this.interceptors,?tp);
????????if?(transactionManager?!=?null?&&?transactionManager.isTransactional())?{
????????????transactionManager.failIfNotReadyForSend();
????????}
????????//?4.消息累加器,緩存消息
????????RecordAccumulator.RecordAppendResult?result?=?accumulator.append(tp,?timestamp,?serializedKey,
?????????????????????????????????????????????????????????????????????????serializedValue,?headers,?interceptCallback,?remainingWaitMs,?true,?nowMs);
????????if?(result.abortForNewBatch)?{
????????????int?prevPartition?=?partition;
????????????partitioner.onNewBatch(record.topic(),?cluster,?prevPartition);
????????????partition?=?partition(record,?serializedKey,?serializedValue,?cluster);
????????????tp?=?new?TopicPartition(record.topic(),?partition);
????????????if?(log.isTraceEnabled())?{
????????????????log.trace("Retrying?append?due?to?new?batch?creation?for?topic?{}?partition?{}.?The?old?partition?was?{}",?record.topic(),?partition,?prevPartition);
????????????}
????????????//?producer?callback?will?make?sure?to?call?both?'callback'?and?interceptor?callback
????????????interceptCallback?=?new?InterceptorCallback<>(callback,?this.interceptors,?tp);
????????????result?=?accumulator.append(tp,?timestamp,?serializedKey,
????????????????????????????????????????serializedValue,?headers,?interceptCallback,?remainingWaitMs,?false,?nowMs);
????????}
????????if?(transactionManager?!=?null?&&?transactionManager.isTransactional())
????????????transactionManager.maybeAddPartitionToTransaction(tp);
????????//?5.如果batch滿了或者消息大小超過了batch的剩余空間需要創(chuàng)建新的batch
????????//?將喚醒sender線程發(fā)送消息
????????if?(result.batchIsFull?||?result.newBatchCreated)?{
????????????log.trace("Waking?up?the?sender?since?topic?{}?partition?{}?is?either?full?or?getting?a?new?batch",?record.topic(),?partition);
????????????this.sender.wakeup();
????????}
????????return?result.future;
????}?catch?(ApiException?e)?{
????????log.debug("Exception?occurred?during?message?send:",?e);
????????if?(callback?!=?null)
????????????callback.onCompletion(null,?e);
????????this.errors.record();
????????this.interceptors.onSendError(record,?tp,?e);
????????return?new?FutureFailure(e);
????}?catch?(InterruptedException?e)?{
????????this.errors.record();
????????this.interceptors.onSendError(record,?tp,?e);
????????throw?new?InterruptException(e);
????}?catch?(KafkaException?e)?{
????????this.errors.record();
????????this.interceptors.onSendError(record,?tp,?e);
????????throw?e;
????}?catch?(Exception?e)?{
????????this.interceptors.onSendError(record,?tp,?e);
????????throw?e;
????}
}
doSend方法主要分為5個步驟:
在發(fā)送數(shù)據(jù)前,先確認(rèn)數(shù)據(jù)發(fā)送的topic的metadata是可用的(partition的leader存在即為可用,如果開啟了權(quán)限控制,則還要求client具有相應(yīng)的權(quán)限); 序列化器,序列化消息的key和value; 分區(qū)器,獲取或計算分區(qū)號; 消息累加器,緩存消息; 在消息累加器中,消息會被放在一個batch中,用于批量發(fā)送,當(dāng)batch滿了或者消息大小超過了batch的剩余空間需要創(chuàng)建新的batch,則將喚醒sender線程發(fā)送消息。
關(guān)于meatadata本文將不深究,序列化器、分區(qū)器前文也給出了介紹。下面我們主要看下消息累加器。
消息累加器,其作用是用于緩存消息,以便批量發(fā)送消息。在RecordAccumulator中用一個ConcurrentMap的map變量保存消息。作為key的TopicPartition封裝了topic和分區(qū)號,而對應(yīng)的value為ProducerBatch的雙端隊列,也就是將發(fā)往同一個分區(qū)的消息緩存在ProducerBatch中。在發(fā)送消息時,Record會被追加在隊列的尾部,即加入到尾部的ProducerBatch中,如果ProducerBatch的空間不足或隊列為空,則將創(chuàng)建新的ProducerBatch,然后追加。當(dāng)ProducerBatch滿了或創(chuàng)建新的ProducerBatch時,將喚醒Sender線程從隊列的頭部獲取ProducerBatch進(jìn)行發(fā)送。
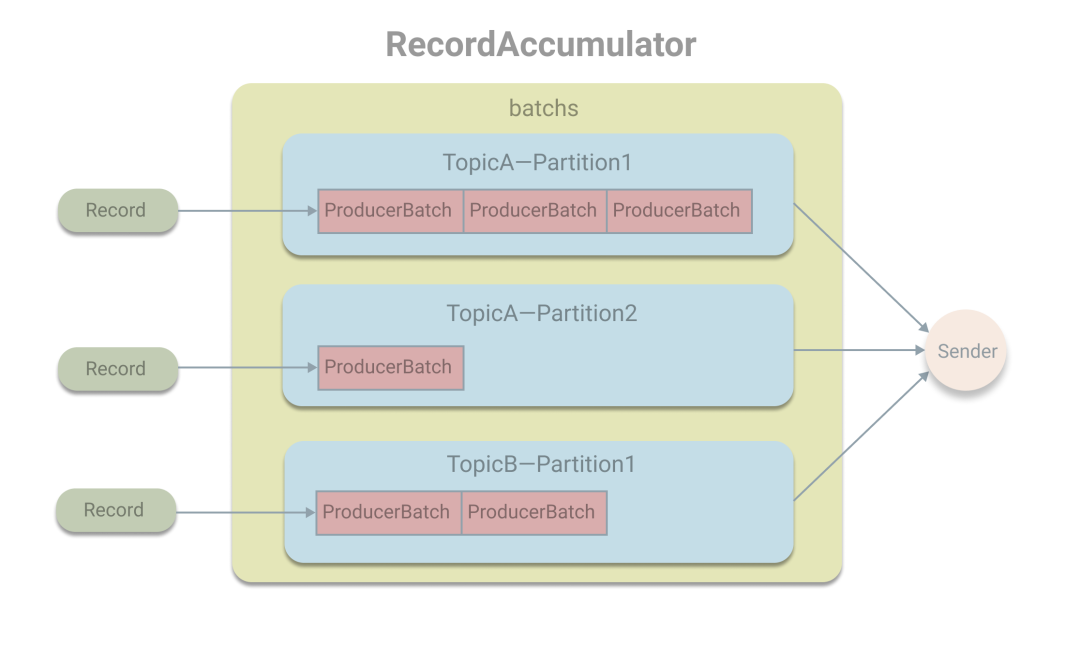
在Sender線程中會將待發(fā)送的ProducerBatch將轉(zhuǎn)換成ProducerBatch放在一個請求中發(fā)送。
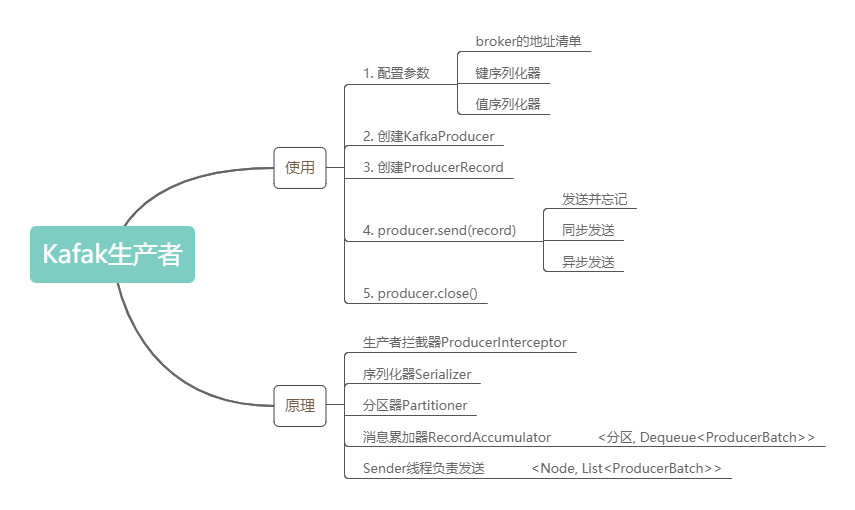
Kafak生產(chǎn)者的內(nèi)容就先了解到這,下面通過思維導(dǎo)圖對本文內(nèi)容做一個簡單的回顧:
參考
《深入理解Kafka核心設(shè)計與實踐原理》 《Kafka權(quán)威指南》 Kafka 源碼解析之 Producer 發(fā)送模型(一):?http://matt33.com/2017/06/25/kafka-producer-send-module/