
別再亂用 Prometheus 聯(lián)邦了,分享一個(gè) Prometheus 高可用新方案

作者 | 浪子燕青燕小乙
來源 | https://zhuanlan.zhihu.com/p/368868988
前言
我看到很多人會這樣使用聯(lián)邦:聯(lián)邦 prometheus 收集多個(gè)采集器的數(shù)據(jù)
實(shí)在看不下下去了,很多小白還在亂用
prometheus的聯(lián)邦其實(shí)很多人是想實(shí)現(xiàn) prometheus 數(shù)據(jù)的可用性,數(shù)據(jù)分片保存,有個(gè)統(tǒng)一的查詢地方(小白中的聯(lián)邦 prometheus)
而且引入 m3db 等支持集群的 tsdb 可能比較重
具體問題可以看我之前寫的文章 m3db 資源開銷,聚合降采樣,查詢限制等注意事項(xiàng)[1]
m3db-node oom 追蹤和內(nèi)存分配器代碼查看[2] 今天寫篇文章分析下聯(lián)邦的問題,并給出一個(gè)基于全部是 prometheus 的
multi_remote_read方案
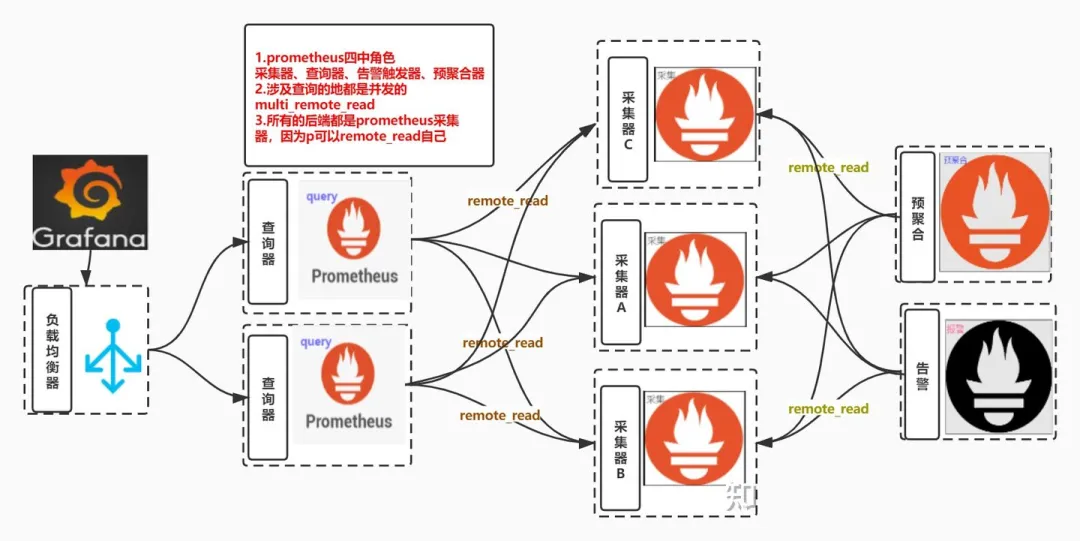
架構(gòu)圖
騰訊試點(diǎn)強(qiáng)制6點(diǎn)下班!標(biāo)志著反996、反內(nèi)卷的第一槍嗎?
聯(lián)邦問題
聯(lián)邦文檔地址[3]
聯(lián)邦使用樣例
本質(zhì)上就是采集級聯(lián) 說白了就是 a 從 b,c,d 那里再采集數(shù)據(jù)過來 可以搭配 match 指定只拉取某些指標(biāo) 下面就是官方文檔給出的樣例
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'
看上面的樣例配置怎么感覺是采集的配置呢
不用懷疑就是,下面看看代碼分析一下 從上述配置可以看到采集的 path 是 /federate
// web.go 的 federate Handler
router.Get("/federate", readyf(httputil.CompressionHandler{
Handler: http.HandlerFunc(h.federation),
}.ServeHTTP))
分析下聯(lián)邦函數(shù) 說白了就是讀取本地存儲數(shù)據(jù)處理
func (h *Handler) federation(w http.ResponseWriter, req *http.Request) {
// localstorage 的query
q, err := h.localStorage.Querier(req.Context(), mint, maxt)
defer q.Close()
// 最終發(fā)送的Vector 數(shù)組
vec := make(promql.Vector, 0, 8000)
hints := &storage.SelectHints{Start: mint, End: maxt}
var sets []storage.SeriesSet
set := storage.NewMergeSeriesSet(sets, storage.ChainedSeriesMerge)
// 遍歷存儲中的full series
for set.Next() {
s := set.At()
vec = append(vec, promql.Sample{
Metric: s.Labels(),
Point: promql.Point{T: t, V: v},
})
for _, s := range vec {
nameSeen := false
globalUsed := map[string]struct{}{}
protMetric := &dto.Metric{
Untyped: &dto.Untyped{},
}
// Encode方法根據(jù)請求類型編碼
if protMetricFam != nil {
if err := enc.Encode(protMetricFam); err != nil {
federationErrors.Inc()
level.Error(h.logger).Log("msg", "federation failed", "err", err)
return
}
}
}
protMetric.TimestampMs = proto.Int64(s.T)
protMetric.Untyped.Value = proto.Float64(s.V)
protMetricFam.Metric = append(protMetricFam.Metric, protMetric)
}
//
if protMetricFam != nil {
if err := enc.Encode(protMetricFam); err != nil {
federationErrors.Inc()
level.Error(h.logger).Log("msg", "federation failed", "err", err)
}
}
}
最終調(diào)用壓縮函數(shù)壓縮
type CompressionHandler struct {
Handler http.Handler
}
// ServeHTTP adds compression to the original http.Handler's ServeHTTP() method.
func (c CompressionHandler) ServeHTTP(writer http.ResponseWriter, req *http.Request) {
compWriter := newCompressedResponseWriter(writer, req)
c.Handler.ServeHTTP(compWriter, req)
compWriter.Close()
}
如果沒有過濾那么只是一股腦把分片的數(shù)據(jù)集中到了一起,沒意義。很多時(shí)候是因?yàn)閿?shù)據(jù)量太大了,分散在多個(gè)采集器的數(shù)據(jù)是不能被一個(gè)聯(lián)邦消化的。
正確使用聯(lián)邦的姿勢
使用 match 加過濾,將采集數(shù)據(jù)分位兩類
第一類需要再聚合的數(shù)據(jù),通過聯(lián)邦收集在一起
只收集中間件的數(shù)據(jù)的聯(lián)邦 只收集業(yè)務(wù)數(shù)據(jù)的聯(lián)邦 舉個(gè)例子 其余數(shù)據(jù)保留在采集器本地即可 這樣可以在各個(gè)聯(lián)邦上執(zhí)行
預(yù)聚合和alert,使得查詢速度提升
默認(rèn) prometheus 不支持降采樣
可以在聯(lián)邦配置 scrape_interval 的時(shí)候設(shè)置的大一點(diǎn)來達(dá)到 模擬降采樣的目的 真實(shí)的降采樣需要 agg 算法支持的,比如 5 分鐘的數(shù)據(jù)算平均值、最大值、最小值保留,而不是這種把采集間隔調(diào)大到 5 分鐘的隨機(jī)選點(diǎn)邏輯
正確實(shí)現(xiàn)統(tǒng)一查詢的姿勢
什么是 remote_read
簡單說就是 prometheus 意識到自己本地存儲不具備高可用性,所以通過支持第三方存儲來補(bǔ)足這點(diǎn)的手段 配置文檔地址[4]
讀寫都支持的存儲
AWS Timestream Azure Data Explorer Cortex CrateDB Google BigQuery Google Cloud Spanner InfluxDB[5] IRONdb M3DB[6] PostgreSQL/TimescaleDB QuasarDB Splunk Thanos TiKV
但是這個(gè)和我們今天聊的問題關(guān)聯(lián)在哪里?,往下看你就知道了
multi_remote_read
如果我們配置了多個(gè) remote_read 接口的話即可實(shí)現(xiàn) multi
remote_read:
- url: "http://172.20.70.205:9090/api/v1/read"
read_recent: true
- url: "http://172.20.70.215:9090/api/v1/read"
read_recent: true
上述配置代表并發(fā)查詢兩個(gè)后端存儲,并可以對查詢的結(jié)果進(jìn)行 merge
merge 有啥用:你們的查詢 promql 或者 alert 配置文件就無需關(guān)心數(shù)據(jù)到底存儲在哪個(gè)存儲里面 ,可以直接使用全局的聚合函數(shù)
prometheus 可以 remote_read prometheus 自己
感覺這個(gè)特點(diǎn)很多人不知道,以為 remoteread 必須配置第三方存儲如 m3db 等,其實(shí) p 也可以 remote_wirte 自己,只不過需要開啟 --enable-feature=remote-write-receiver
高可用方案
所以結(jié)合上述兩個(gè)特點(diǎn)就可以用多個(gè)采集的 prometheus + 多個(gè)無狀態(tài)的 prometheus query 實(shí)現(xiàn) prometheus 的高可用方案
監(jiān)控?cái)?shù)據(jù)存儲在多個(gè)采集器的本地,可以是機(jī)器上的 prometheus 也可以是 k8s 中的 prometheus statefulset prometheus query remote_read 填寫多個(gè) prometheus的/api/v1/read/地址
數(shù)據(jù)重復(fù)怎么辦
不用管,上面提到了 query 會做 merge,多個(gè)數(shù)據(jù)只會保留一份
可以利用這個(gè)特點(diǎn)模擬副本機(jī)制:
重要的采集 job 由兩個(gè)以上的采集 prometheus 采集 查詢的時(shí)候 merge 數(shù)據(jù) 可以避免其中一個(gè)掛掉時(shí)沒數(shù)據(jù)的問題
這種方案的缺點(diǎn)
并發(fā)查詢必須要等最慢的那個(gè)返回才返回,所以如果有個(gè)慢的節(jié)點(diǎn)會導(dǎo)致查詢速度下降,舉個(gè)例子:
有個(gè)美東的節(jié)點(diǎn),網(wǎng)絡(luò)基礎(chǔ)延遲是 1 秒,那么所有查詢無論返回多快都必須疊加 1 秒的延遲。
應(yīng)對重查詢時(shí)可能會把 query 打掛。
但也正是這個(gè)特點(diǎn),會很好的保護(hù)后端存儲分片,重查詢的基數(shù)分散給多個(gè)采集器了。
由于是無差別的并發(fā) query,也就是說所有的 query 都會打向所有的采集器,會導(dǎo)致一些采集器總是查詢不存在他這里的數(shù)據(jù)
那么一個(gè)關(guān)鍵性的問題就是,查詢不存在這個(gè) prometheus 的數(shù)據(jù)的資源開銷到底是多少?據(jù)我觀察,新版本速度還是很快的說明資源開銷不會在很深的地方才判斷出不屬于我的數(shù)據(jù)。
m3db 有布隆過濾器來防止這個(gè)問題。
如果想精確把 query 打向數(shù)據(jù)它的存儲分片可以參考我之前寫的 route 方案:開源項(xiàng)目 : prome-route:使用反向代理實(shí)現(xiàn) prometheus 分片[7]
主要哦,需要特征標(biāo)簽支持,并且數(shù)據(jù)天然就是分開的!!
忘了說了,這個(gè)方案還有個(gè)缺點(diǎn)就是重查詢沒控制好容易把你的采集器打掛了。
腳注
[1]m3db 資源開銷,聚合降采樣,查詢限制等注意事項(xiàng): https://zhuanlan.zhihu.com/p/359551116
[2]m3db-node oom 追蹤和內(nèi)存分配器代碼查看: https://zhuanlan.zhihu.com/p/183815841
[3]聯(lián)邦文檔地址: https://prometheus.io/docs/prometheus/latest/federation/
[4]配置文檔地址: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_read
[5]InfluxDB: https://docs.influxdata.com/influxdb/v1.8/supported_protocols/prometheus/
[6]M3DB: https://m3db.io/docs/integrations/prometheus/
[7]開源項(xiàng)目 : prome-route:使用反向代理實(shí)現(xiàn) prometheus 分片: https://zhuanlan.zhihu.com/p/231914857
往期推薦
關(guān)注我回復(fù)「加群」,加入Spring技術(shù)交流群