
高可用 Prometheus 的常見問題
點擊上方藍(lán)色“程序猿DD”,選擇“設(shè)為星標(biāo)”
回復(fù)“資源”獲取獨家整理的學(xué)習(xí)資料!

監(jiān)控系統(tǒng)的歷史悠久,是一個很成熟的方向,而 Prometheus 作為新生代的開源監(jiān)控系統(tǒng),慢慢成為了云原生體系的事實標(biāo)準(zhǔn),也證明了其設(shè)計很受歡迎。本文主要分享在 prometheus 實踐中遇到的一些問題和思考
幾點原則
監(jiān)控是基礎(chǔ)設(shè)施,目的是為了解決問題,不要只朝著大而全去做,尤其是不必要的指標(biāo)采集,浪費人力和存儲資源(To B 商業(yè)產(chǎn)品例外) 需要處理的告警才發(fā)出來,發(fā)出來的告警必須得到處理 簡單的架構(gòu)就是最好的架構(gòu),業(yè)務(wù)系統(tǒng)都掛了,監(jiān)控也不能掛,Google SRE 里面也說避免使用 magic 系統(tǒng),例如機器學(xué)習(xí)報警閾值、自動修復(fù)之類。這一點見仁見智吧,感覺很多公司都在搞智能 AI 運維
prometheus 的局限
prometheus 是基于 metric 的監(jiān)控,不適用于日志(logs)、事件(event)、調(diào)用鏈(tracing) prometheus 默認(rèn)是 pull 模型,合理規(guī)劃你的網(wǎng)絡(luò),盡量不用 pushgateway 轉(zhuǎn)發(fā) 對于集群化、水平擴展,官方和社區(qū)都沒有銀彈,合理選擇 federate、cortex、thanos 監(jiān)控系統(tǒng)一般 可用性>一致性,這個后面說 thanos 的時候會提到
合理選擇黃金指標(biāo)
我們應(yīng)該關(guān)注哪些指標(biāo)?Google 在“SRE Handbook”中提出了“四個黃金信號”:延遲、流量、錯誤數(shù)、飽和度。實際操作中可以使用 USE 或 RED 方法作為指導(dǎo),USE 用于資源,RED 用于服務(wù)
USE 方法:Utilization、Saturation、Errors RED 方法:Rate、Errors、Duration
對 USE 和 RED 的闡述可以參考容器監(jiān)控實踐—K8S 常用指標(biāo)分析[1]這篇文章
采集組件 all in one
prometheus 體系中 exporter 都是獨立的,每個組件各司其職,如機器資源用 node-exporter,gpu 有 NVIDIA exporter 等等,但是 exporter 越多,運維壓力越大,尤其是對 agent 做資源控制、版本升級。我們嘗試對一些 exporter 進(jìn)行組合,方案有二:
通過主進(jìn)程拉起 n 個 exporter 進(jìn)程,仍然可以跟著社區(qū)版本更新 用 telegraf 來支持各種類型的 input,n 合 1
另外,node-exporter 不支持進(jìn)程監(jiān)控,可以加一個 process-exporter,也可以用上邊提到的 telegraf。
k8s 1.16 中 cadvisor 的指標(biāo)兼容問題
在 k8s 1.16 版本,cadvisor 的指標(biāo)去掉了 pod_name 和 container_name 的 label,替換為了 pod 和 container。如果你之前用這兩個 label 做查詢或者 grafana 繪圖,得更改下 sql 了。因為我們一直支持多個 k8s 版本,就通過 relabel 配置繼續(xù)保留了原來的**_name
metric_relabel_configs:
-?source_labels:?[container]
??regex:?(.+)
??target_label:?container_name
??replacement:?$1
??action:?replace
-?source_labels:?[pod]
??regex:?(.+)
??target_label:?pod_name
??replacement:?$1
??action:?replace
注意要用 metric_relabel_configs,不是 relabel_configs,采集后做的 replace。
prometheus 集群內(nèi)與集群外部署
prometheus 如果部署在 k8s 集群內(nèi)采集是很方便的,用官方給的 yaml 就可以,但我們因為權(quán)限和網(wǎng)絡(luò)需要部署在集群外,二進(jìn)制運行,專門劃了幾臺高配服務(wù)器運行監(jiān)控組件。
以 pod 方式運行在集群內(nèi)是不需要證書的(in-cluster 模式),但集群外需要聲明 token 之類的證書,并替換address。例如:
kubernetes_sd_configs:
-?api_server:?https://xx:6443
??role:?node
??bearer_token_file:?token/xx.token
??tls_config:
????insecure_skip_verify:?true
relabel_configs:
-?separator:?;
??regex:?__meta_kubernetes_node_label_(.+)
??replacement:?$1
??action:?labelmap
-?separator:?;
??regex:?(.*)
??target_label:?__address__
??replacement:?xx:6443
??action:?replace
-?source_labels:?[__meta_kubernetes_node_name]
??separator:?;
??regex:?(.+)
??target_label:?__metrics_path__
??replacement:?/api/v1/nodes/${1}/proxy/metrics/cadvisor
??action:?replace
上面是通過默認(rèn)配置中通過 apiserver proxy 到 let,如果網(wǎng)絡(luò)能通,其實也可以直接把 kubelet 的 10255 作為 target,規(guī)模大的時候還減輕了 apiserver 的壓力,不過這種方式就要寫服務(wù)發(fā)現(xiàn)來更新 node 列表了。
gpu 指標(biāo)的獲取
nvidia-smi 可以查看機器上的 gpu 資源,而 cadvisor 其實暴露了 metric 來表示 容器使用 gpu 情況,
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果要更詳細(xì)的 gpu 數(shù)據(jù),可以安裝dcgm exporter[2],不過 k8s 1.13 才能支持
更改 prometheus 的顯示時區(qū)
prometheus 為避免時區(qū)混亂,在所有組件中專門使用 Unix time 和 UTC 進(jìn)行顯示。不支持在配置文件中設(shè)置時區(qū),也不能讀取本機/etc/timezone 時區(qū)。
其實這個限制是不影響使用的:
如果做可視化,grafana 是可以做時區(qū)轉(zhuǎn)換的 如果是調(diào)接口,拿到了數(shù)據(jù)中的時間戳,你想怎么處理都可以 如果因為 prometheus 自帶的 ui 不是本地時間,看著不舒服,?2.16 版本[3]的新版 webui 已經(jīng)引入了 local timezone 的選項。區(qū)別見下圖 如果你仍然想改 prometheus 代碼來適應(yīng)自己的時區(qū),可以參考這篇文章[4]
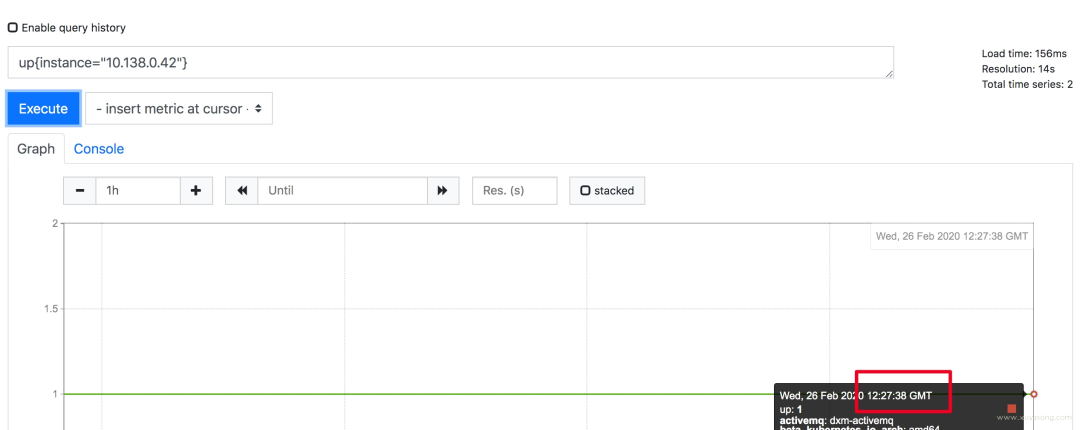
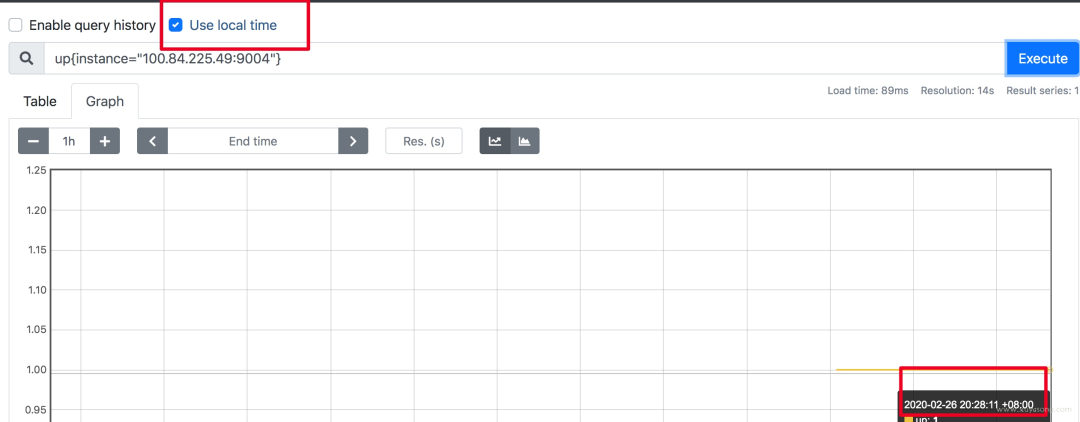
關(guān)于 timezone 的討論,可以看這個issue[5]
如何采集 lb 后面的 rs 的 metric
假如你有一個負(fù)載均衡 lb,但網(wǎng)絡(luò)上 prometheus 只能訪問到 lb 本身,訪問不到后面的 rs,應(yīng)該如何采集 rs 暴露的 metric?
rs 的服務(wù)加 sidecar proxy,或者本機增加 proxy 組件,保證 prometheus 能訪問到 lb 增加/ backend1 和/ backend2 請求轉(zhuǎn)發(fā)到兩個單獨的后端,再由 prometheus 訪問 lb 采集
版本
prometheus 當(dāng)前最新版本為 2.16,prometheus 還在不斷迭代,因此盡量用最新版,1.x 版本就不用考慮了。
2.16 版本上有一套實驗 UI,可以查看 TSDB 的狀態(tài),包括 top 10 的 label、metric
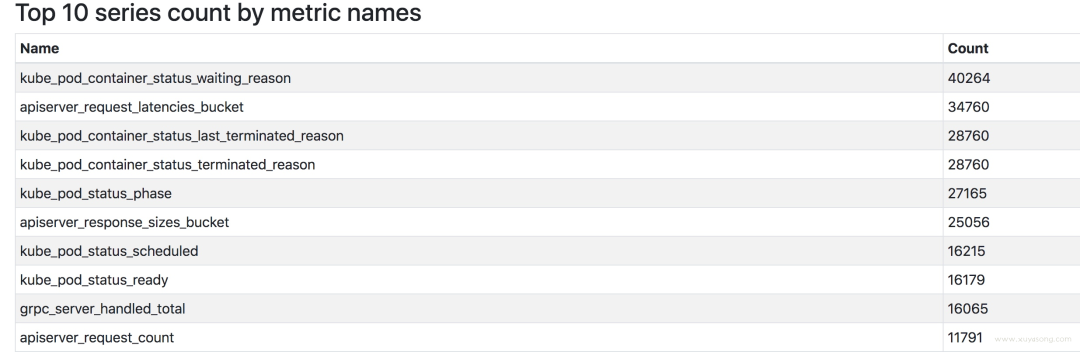
prometheus 大內(nèi)存問題
隨著規(guī)模變大,prometheus 需要的 cpu 和內(nèi)存都會升高,內(nèi)存一般先達(dá)到瓶頸,這個時候要么加內(nèi)存,要么集群分片減少單機指標(biāo)。這里我們先討論單機版 prometheus 的內(nèi)存問題
原因:
prometheus 的內(nèi)存消耗主要是因為每隔 2 小時做一個 block 數(shù)據(jù)落盤,落盤之前所有數(shù)據(jù)都在內(nèi)存里面,因此和采集量有關(guān)。 加載歷史數(shù)據(jù)時,是從磁盤到內(nèi)存的,查詢范圍越大,內(nèi)存越大。這里面有一定的優(yōu)化空間 一些不合理的查詢條件也會加大內(nèi)存,如 group、大范圍 rate
我的指標(biāo)需要多少內(nèi)存:
作者給了一個計算器,設(shè)置指標(biāo)量、采集間隔之類的,計算 prometheus 需要的理論內(nèi)存值:https://www.robustperception.io/how-much-ram-does-prometheus-2-x-need-for-cardinality-and-ingestion
以我們的一個 promserver 為例,本地只保留 2 小時數(shù)據(jù),95 萬 series,大概占用的內(nèi)存如下:

有什么優(yōu)化方案:
sample 數(shù)量超過了 200 萬,就不要單實例了,做下分片,然后通過 victoriametrics,thanos,trickster 等方案合并數(shù)據(jù) 評估哪些 metric 和 label 占用較多,去掉沒用的指標(biāo)。2.14 以上可以看?tsdb 狀態(tài)[6] 查詢時盡量避免大范圍查詢,注意時間范圍和 step 的比例,慎用 group 如果需要關(guān)聯(lián)查詢,先想想能不能通過 relabel 的方式給原始數(shù)據(jù)多加個 label,一條 sql 能查出來的何必用 join,時序數(shù)據(jù)庫不是關(guān)系數(shù)據(jù)庫。
prometheus 內(nèi)存占用分析:
通過 pprof 分析:https://www.robustperception.io/optimising-prometheus-2-6-0-memory-usage-with-pprof 1.x 版本的內(nèi)存:https://www.robustperception.io/how-much-ram-does-my-prometheus-need-for-ingestion
相關(guān) issue:
https://groups.google.com/forum/#!searchin/prometheus-users/memory%7Csort:date/prometheus-users/q4oiVGU6Bxo/uifpXVw3CwAJ https://github.com/prometheus/prometheus/issues/5723 https://github.com/prometheus/prometheus/issues/1881
prometheus 容量規(guī)劃
容量規(guī)劃除了上邊說的內(nèi)存,還有磁盤存儲規(guī)劃,這和你的 prometheus 的架構(gòu)方案有關(guān)
如果是單機 prometheus,計算本地磁盤使用量 如果是 remote-write,和已有的 tsdb 共用即可。 如果是 thanos 方案,本地磁盤可以忽略(2h),計算對象存儲的大小就行。
Prometheus 每 2 小時將已緩沖在內(nèi)存中的數(shù)據(jù)壓縮到磁盤上的塊中。包括 chunks, indexes, tombstones 和 metadata,這些占用了一部分存儲空間。一般情況下,Prometheus 中存儲的每一個樣本大概占用 1-2 字節(jié)大小(1.7byte)。可以通過 promql 來查看每個樣本平均占用多少空間:
rate(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
?rate(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890",?job="prometheus"}??1.252747585939941
如果大致估算本地磁盤大小,可以通過以下公式:
磁盤大小?=?保留時間?*?每秒獲取樣本數(shù)?*?樣本大小
保留時間(retention_time_seconds)和樣本大小(bytes_per_sample)不變的情況下,如果想減少本地磁盤的容量需求,只能通過減少每秒獲取樣本數(shù)(ingested_samples_per_second)的方式。
查看當(dāng)前每秒獲取的樣本數(shù):
rate(prometheus_tsdb_head_samples_appended_total[1h])
有兩種手段,一是減少時間序列的數(shù)量,二是增加采集樣本的時間間隔。考慮到 Prometheus 會對時間序列進(jìn)行壓縮,因此減少時間序列的數(shù)量效果更明顯.
舉例說明:
采集頻率 30s,機器數(shù)量 1000,metric 種類 6000,1000600026024 約 200 億,30G 左右磁盤 只采集需要的指標(biāo),如 match[], 或者統(tǒng)計下最常使用的指標(biāo),性能最差的指標(biāo)
以上磁盤容量并沒有把 WAL 文件算進(jìn)去,WAL 文件(raw data)Prometheus 官方文檔中說明至少會保存 3 個 write-ahead log files,每一個最大為 128M(實際運行發(fā)現(xiàn)數(shù)量會更多)
因為我們使用了 thanos 的方案,所以本地磁盤只保留 2h 熱數(shù)據(jù)。WAL 每 2 小時生成一份 block 文件,block 文件每 2 小時上傳對象存儲,本地磁盤基本沒有壓力。
關(guān)于 prometheus 存儲機制,可以看這篇[7]
對 apiserver 的 性能影響
如果你的 prometheus 使用了 kubernetes_sd_config 做服務(wù)發(fā)現(xiàn),請求一般會經(jīng)過集群的 apiserver,隨著規(guī)模的變大,需要評估下對 apiserver 性能的影響,尤其是 proxy 失敗的時候,會導(dǎo)致 cpu 升高。當(dāng)然了,如果單 k8s 集群規(guī)模太大,一般都是拆分集群,不過隨時監(jiān)測下 apiserver 的進(jìn)程變化還是有必要的。
在監(jiān)控 cadvisor、docker、kube-proxy 的 metric 時,我們一開始選擇從 apiserver proxy 到節(jié)點的對應(yīng)端口,統(tǒng)一設(shè)置比較方便,但后來還是改為了直接拉取節(jié)點,apiserver 僅做服務(wù)發(fā)現(xiàn)。
rate 的計算邏輯
prometheus 中的 counter 類型主要是為了 rate 而存在的,即計算速率,單純的 counter 計數(shù)意義不大,因為 counter 一旦重置,總計數(shù)就沒有意義了。
rate 會自動處理 counter 重置的問題,counter 一般都是一直變大的,例如一個 exporter 啟動,然后崩潰了。本來以每秒大約 10 的速率遞增,但僅運行了半個小時,則速率(x_total [1h])將返回大約每秒 5 的結(jié)果。另外,counter 的任何減少也會被視為 counter 重置。例如,如果時間序列的值為[5,10,4,6],則將其視為[5,10,14,16]。
rate 值很少是精確的。由于針對不同目標(biāo)的抓取發(fā)生在不同的時間,因此隨著時間的流逝會發(fā)生抖動,query_range 計算時很少會與抓取時間完美匹配,并且抓取有可能失敗。面對這樣的挑戰(zhàn),rate 的設(shè)計必須是健壯的。
rate 并非想要捕獲每個增量,因為有時候增量會丟失,例如實例在抓取間隔中掛掉。如果 counter 的變化速度很慢,例如每小時僅增加幾次,則可能會導(dǎo)致【假象】。比如出現(xiàn)一個 counter 時間序列,值為 100,rate 就不知道這些增量是現(xiàn)在的值,還是目標(biāo)已經(jīng)運行了好幾年并且才剛剛開始返回。
建議將 rate 計算的范圍向量的時間至少設(shè)為抓取間隔的四倍。這將確保即使抓取速度緩慢,且發(fā)生了一次抓取故障,您也始終可以使用兩個樣本。此類問題在實踐中經(jīng)常出現(xiàn),因此保持這種彈性非常重要。例如,對于 1 分鐘的抓取間隔,您可以使用 4 分鐘的 rate 計算,但是通常將其四舍五入為 5 分鐘。
如果 rate 的時間區(qū)間內(nèi)有數(shù)據(jù)缺失,他會基于趨勢進(jìn)行推測,比如:
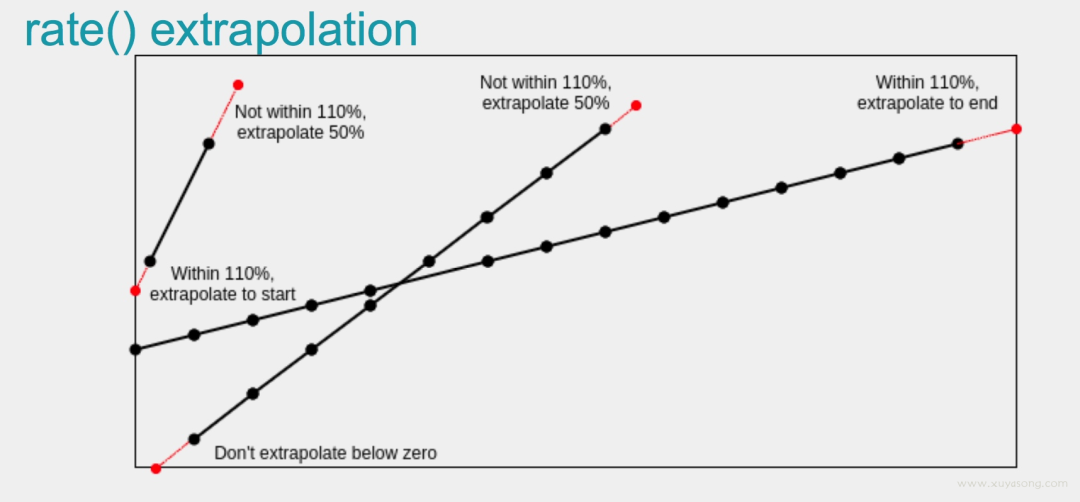
詳細(xì)的內(nèi)容可以看下這個視頻[8]
反直覺的 p95 統(tǒng)計
histogram_quantile 是 Prometheus 常用的一個函數(shù),比如經(jīng)常把某個服務(wù)的 P95 響應(yīng)時間來衡量服務(wù)質(zhì)量。不過它到底是什么意思很難解釋得清,特別是面向非技術(shù)的同學(xué),會遇到很多“靈魂拷問”。
我們常說 P95(p99,p90 都可以) 響應(yīng)延遲是 100ms,實際上是指對于收集到的所有響應(yīng)延遲,有 5% 的請求大于 100ms,95% 的請求小于 100ms。Prometheus 里面的 histogram_quantile 函數(shù)接收的是 0-1 之間的小數(shù),將這個小數(shù)乘以 100 就能很容易得到對應(yīng)的百分位數(shù),比如 0.95 就對應(yīng)著 P95,而且還可以高于百分位數(shù)的精度,比如 0.9999。
當(dāng)你用 histogram_quantile 畫出響應(yīng)時間的趨勢圖時,可能會被問:為什么 p95 大于或小于我的平均值?
正如中位數(shù)可能比平均數(shù)大也可能比平均數(shù)小,P99 比平均值小也是完全有可能的。通常情況下 P99 幾乎總是比平均值要大的,但是如果數(shù)據(jù)分布比較極端,最大的 1% 可能大得離譜從而拉高了平均值。一種可能的例子:
1,?1,?...?1,?901?//?共?100?條數(shù)據(jù),平均值=10,P99=1
服務(wù) X 由順序的 A,B 兩個步驟完成,其中 X 的 P99 耗時 100ms,A 過程 P99 耗時 50ms,那么推測 B 過程的 P99 耗時情況是?
直覺上來看,因為有 X=A+B,所以答案可能是 50ms,或者至少應(yīng)該要小于 50ms。實際上 B 是可以大于 50ms 的,只要 A 和 B 最大的 1% 不恰好遇到,B 完全可以有很大的 P99:
A?=?1,?1,?...?1,??1,??1,??50,??50?//?共?100?條數(shù)據(jù),P99=50
B?=?1,?1,?...?1,??1,??1,??99,??99?//?共?100?條數(shù)據(jù),P99=99
X?=?2,?2,?...?1,?51,?51,?100,?100?//?共?100?條數(shù)據(jù),P99=100
如果讓 A 過程最大的 1%?接近 100ms,我們也能構(gòu)造出 P99 很小的 B:
A?=?50,?50,?...?50,??50,??99?//?共?100?條數(shù)據(jù),P99=50
B?=??1,??1,?...??1,???1,??50?//?共?100?條數(shù)據(jù),P99=1
X?=?51,?51,?...?51,?100,?100?//?共?100?條數(shù)據(jù),P99=100
所以我們從題目唯一能確定的只有 B 的 P99 應(yīng)該不能超過 100ms,A 的 P99 耗時 50ms 這個條件其實沒啥用。
類似的疑問很多,因此對于 histogram_quantile 函數(shù),可能會產(chǎn)生反直覺的一些結(jié)果,最好的處理辦法是不斷試驗調(diào)整你的 bucket 的值,保證更多的請求時間落在更細(xì)致的區(qū)間內(nèi),這樣的請求時間才有統(tǒng)計意義。
慢查詢問題
promql 的基礎(chǔ)知識看這篇文章[9]
prometheus 提供了自定義的 promql 作為查詢語句,在 graph 上調(diào)試的時候,會告訴你這條 sql 的返回時間,如果太慢你就要注意了,可能是你的用法出現(xiàn)了問題。
評估 prometheus 的整體響應(yīng)時間,可以用這個默認(rèn)指標(biāo):
prometheus_engine_query_duration_seconds{}
一般情況下響應(yīng)過慢都是 promql 使用不當(dāng)導(dǎo)致,或者指標(biāo)規(guī)劃有問題,如:
大量使用 join 來組合指標(biāo)或者增加 label,如將 kube-state-metric 中的一些 meta label 和 node-exporter 中的節(jié)點屬性 label 加入到 cadvisor 容器 數(shù)據(jù)里,像統(tǒng)計 pod 內(nèi)存使用率并按照所屬節(jié)點的機器類型分類,或按照所屬 rs 歸類。 范圍查詢時,大的時間范圍,step 值卻很小,導(dǎo)致查詢到的數(shù)量量過大。 rate 會自動處理 counter 重置的問題,最好由 promql 完成,不要自己拿出來全部元數(shù)據(jù)在程序中自己做 rate 計算。 在使用 rate 時,range duration 要大于等于step[10],否則會丟失部分?jǐn)?shù)據(jù)[11] prometheus 是有基本預(yù)測功能的,如 deriv和predict_linear(更準(zhǔn)確)可以根據(jù)已有數(shù)據(jù)預(yù)測未來趨勢如果比較復(fù)雜且耗時的 sql,可以使用 record rule 減少指標(biāo)數(shù)量,并使查詢效率更高,但不要什么指標(biāo)都加 record,一半以上的 metric 其實不太會查詢到。同時 label 中的值不要加到 record rule 的 name 中。
高基數(shù)問題 Cardinality
高基數(shù)是數(shù)據(jù)庫避不開的一個話題,對于 mysql 這種 db 來講,基數(shù)是指特定列或字段中包含的唯一值的數(shù)量。基數(shù)越低,列中重復(fù)的元素越多。對于時序數(shù)據(jù)庫而言,就是 tags、label 這種標(biāo)簽值的數(shù)量多少。
比如 prometheus 中如果有一個指標(biāo)?http_request_count{method="get",path="/abc",originIP="1.1.1.1"}表示訪問量,method 表示請求方法,originIP 是客戶端 IP,method 的枚舉值是有限的,但 originIP 卻是無限的,加上其他 label 的排列組合就無窮大了,也沒有任何關(guān)聯(lián)特征,因此這種高基數(shù)不適合作為 metric 的 label,真要的提取 originIP,應(yīng)該用日志的方式,而不是 metric 監(jiān)控
時序數(shù)據(jù)庫會為這些 label 建立索引,以提高查詢性能,以便您可以快速找到與所有指定標(biāo)簽匹配的值。如果值的數(shù)量過多,索引是沒有意義的,尤其是做 p95 等計算的時候,要掃描大量 series 數(shù)據(jù)
官方文檔中對于 label 的建議
CAUTION:?Remember?that?every?unique?combination?of?key-value?label?pairs?represents?a?new?time?series,?which?can?dramatically?increase?the?amount?of?data?stored.?Do?not?use?labels?to?store?dimensions?with?high?cardinality?(many?different?label?values),?such?as?user?IDs,?email?addresses,?or?other?unbounded?sets?of?values.
如何查看當(dāng)前的 label 分布情況呢,可以使用 prometheus 提供的 tsdb 工具。可以使用命令行查看,也可以在 2.16 版本以上的 prometheus graph 查看
[work@xxx?bin]$?./tsdb?analyze?../data/prometheus/
Block?ID:?01E41588AJNGM31SPGHYA3XSXG
Duration:?2h0m0s
Series:?955372
Label?names:?301
Postings?(unique?label?pairs):?30757
Postings?entries?(total?label?pairs):?10842822
....
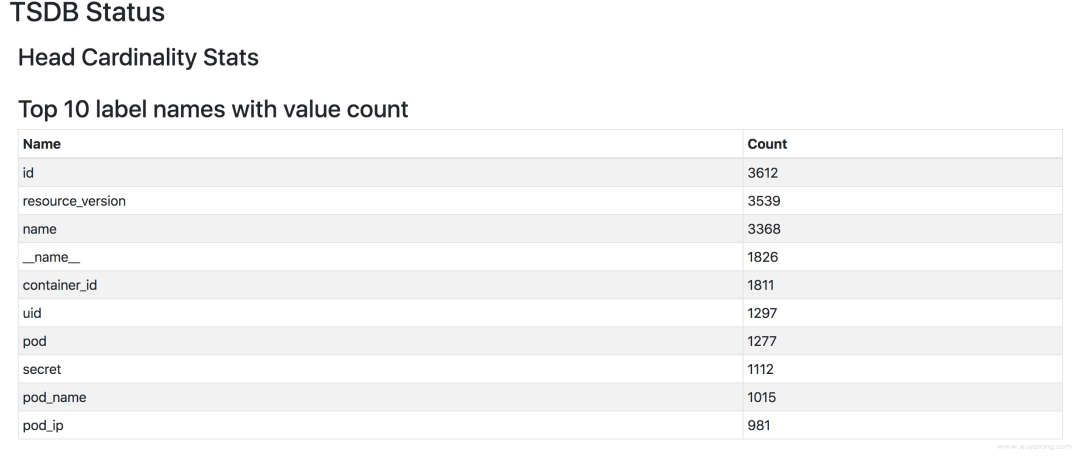

top10 高基數(shù)的 metric
Highest?cardinality?metric?names:
87176?apiserver_request_latencies_bucket
59968?apiserver_response_sizes_bucket
39862?apiserver_request_duration_seconds_bucket
37555?container_tasks_state
....
高基數(shù)的 label
Highest?cardinality?labels:
4271?resource_version
3670?id
3414?name
1857?container_id
1824?__name__
1297?uid
1276?pod
...
找到最大的 metric 或 job
top10 的 metric 數(shù)量:按 metric 名字分
topk(10,?count?by?(__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{}??62544
apiserver_response_sizes_bucket{}???44600
top10 的 metric 數(shù)量:按 job 名字分
topk(10,?count?by?(__name__,?job)({__name__=~".+"}))
{job="master-scrape"}?525667
{job="xxx-kubernetes-cadvisor"}??50817
{job="yyy-kubernetes-cadvisor"}???44261
k8s 組件性能指標(biāo)
除了基礎(chǔ)的 cadvisor 資源監(jiān)控,還應(yīng)該對核心組件的 metric 進(jìn)行采集,包括:
10250:kubelet 監(jiān)聽端口,包括/stats/summary、metrics、metrics/cadvisor。10250 為認(rèn)證端口,非認(rèn)證端口用 10255 10251:kube-scheduler 的 metric 端口,本地 127 訪問不需要認(rèn)證,如調(diào)度延遲, 10252:kube-controller 的 metric 端口,本地 127 訪問不需要認(rèn)證 6443: apiserver,需要證書認(rèn)證,直接 curl 命令為 curl --cacert /etc/kubernetes/pki/ca.pem --cert /etc/kubernetes/pki/admin.pem --key /etc/kubernetes/pki/admin-key.pem https://ip:6443/metrics -k2379: etcd 的 metric 端口,直接 curl 命令為: curl --cacert /etc/etcd/ssl/ca.pem --cert /etc/etcd/ssl/etcd.pem --key /etc/etcd/ssl/etcd-key.pem https://localhost:2379/metrics -k
docker 指標(biāo)暴露:
如果要開放 docker 進(jìn)程指標(biāo),需要開啟實驗特性,文件/etc/docker/daemon.json
{
??"metrics-addr"?:?"127.0.0.1:9323",
??"experimental"?:?true
}
kube-proxy 指標(biāo):
端口為 10249,默認(rèn) 127 開放,可以修改為 hostname 開放,--metrics-bind-address=機器 ip
示例圖: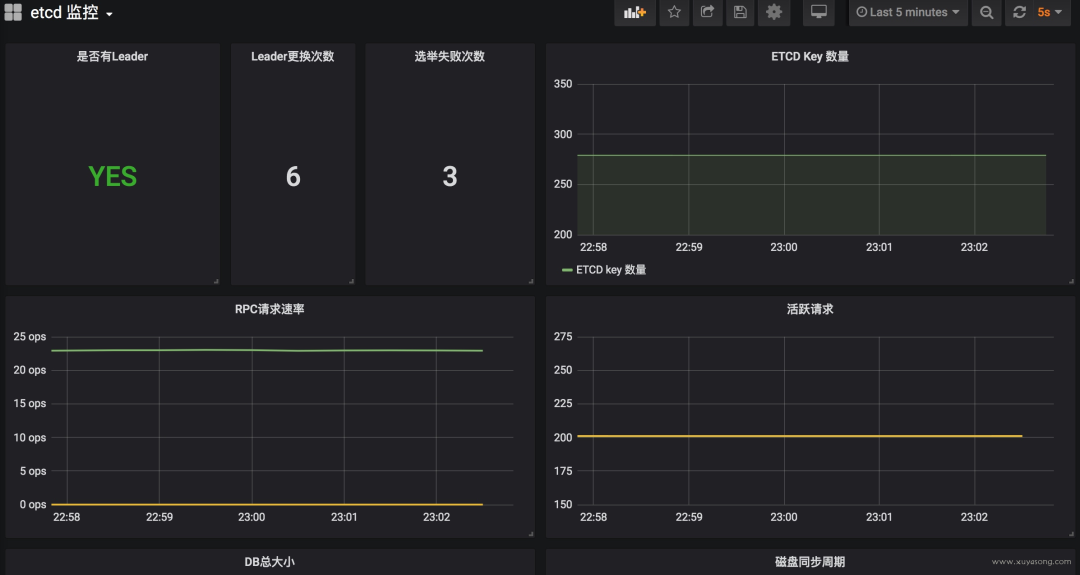
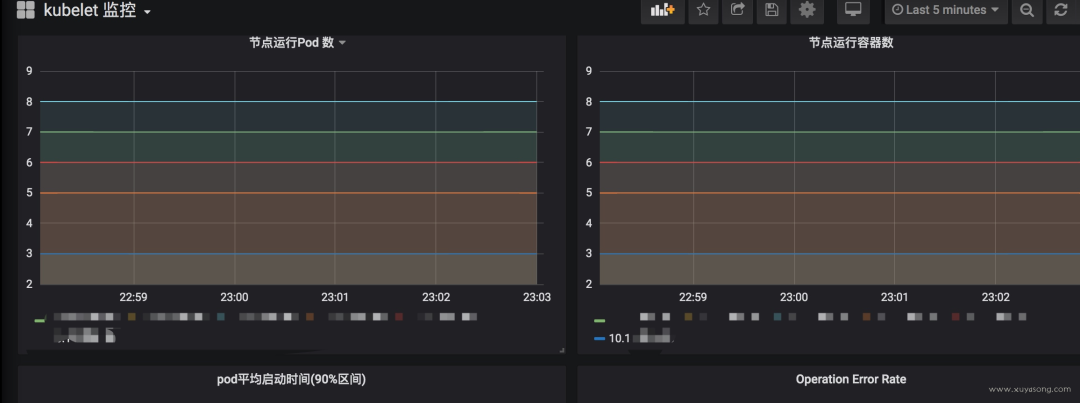
prometheus 重啟慢
prometheus 重啟的時候需要把 wal 中的內(nèi)容 load 到內(nèi)存里,保留時間越久、wal 文件越大,重啟的實際越長,這個是 prometheus 的機制,沒得辦法,因此能 reload 的,就不要重啟,重啟一定會導(dǎo)致短時間的不可用,而這個時候 prometheus 高可用就很重要了。
但 prometheus 也曾經(jīng)對啟動時間做過優(yōu)化,在 2.6 版本中對于 WAL 的 load 速度就做過速度的優(yōu)化,希望重啟的時間不超過?1 分鐘[12]
你的應(yīng)用應(yīng)該暴露多少指標(biāo)
當(dāng)你開發(fā)自己的服務(wù)的時候,你可能會把一些數(shù)據(jù)暴露 metric 出去,比如特定請求數(shù)、goroutine 數(shù)等,指標(biāo)數(shù)量多少合適呢?
雖然指標(biāo)數(shù)量和你的應(yīng)用規(guī)模相關(guān),但也有一些建議(Brian Brazil)[13],
比如簡單的服務(wù)如緩存等,類似 pushgateway,大約 120 個指標(biāo),prometheus 本身暴露了 700 左右的指標(biāo),如果你的應(yīng)用很大,也盡量不要超過 10000 個指標(biāo),需要合理控制你的 label。
relabel_configs 與 metric_relabel_configs
relabel_config 發(fā)生在采集之前,metric_relabel_configs 發(fā)生在采集之后,合理搭配可以滿足場景的配置
如
metric_relabel_configs:
??-?separator:?;
????regex:?instance
????replacement:?$1
????action:?labeldrop
-?source_labels:?[__meta_kubernetes_namespace,?__meta_kubernetes_endpoints_name,
??????__meta_kubernetes_service_annotation_prometheus_io_port]
????separator:?;
????regex:?(.+);(.+);(.*)
????target_label:?__metrics_path__
????replacement:?/api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
????action:?replace
Prometheus 的預(yù)測能力
場景 1:你的磁盤剩余空間一直在減少,并且降低的速度比較均勻,你希望知道大概多久之后達(dá)到閾值,并希望在某一個時刻報警出來。
場景 2:你的 pod 內(nèi)存使用率一直升高,你希望知道大概多久之后會到達(dá) limit 值,并在一定時刻報警出來,在被殺掉之前上去排查。
prometheus 的 deriv 和 predict_linear 方法可以滿足這類需求, promtheus 提供了基礎(chǔ)的預(yù)測能力,基于當(dāng)前的變化速度,推測一段時間后的值。
以 mem_free 為例,最近一小時的 free 值一直在下降。
mem_free僅為舉例,實際內(nèi)存可用以mem_available為準(zhǔn)
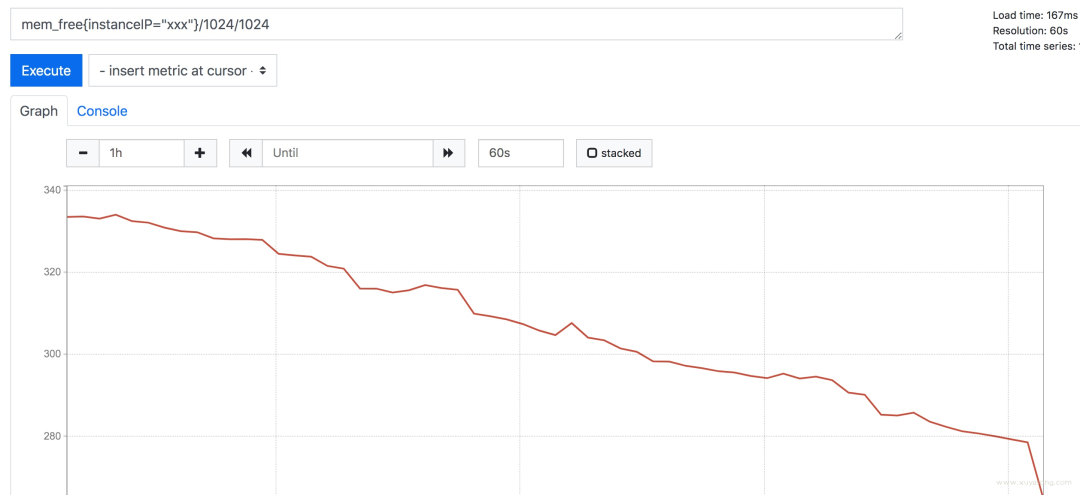
deriv 函數(shù)可以顯示指標(biāo)在一段時間的變化速度
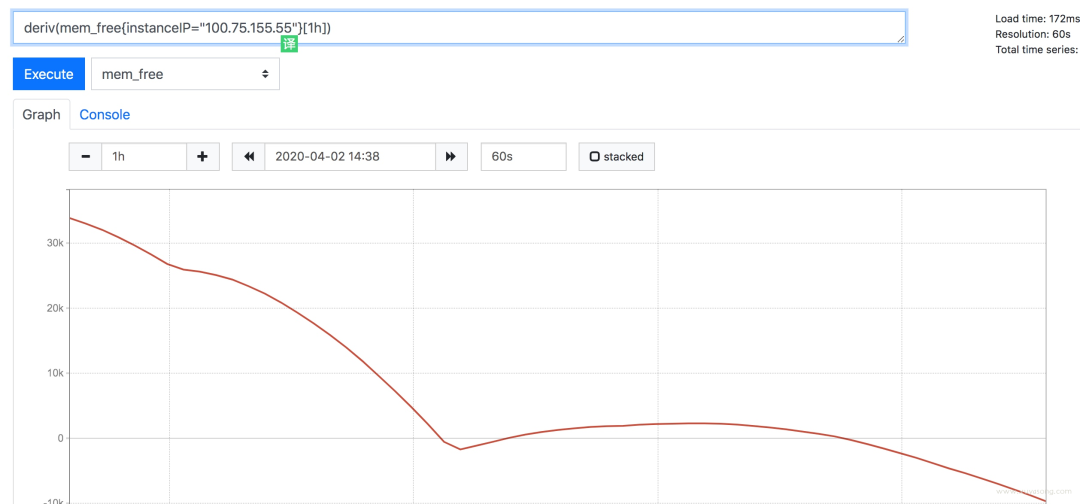
predict_linear 方法是預(yù)測基于這種速度,最后可以達(dá)到的值
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h],?2*3600)/1024/1024
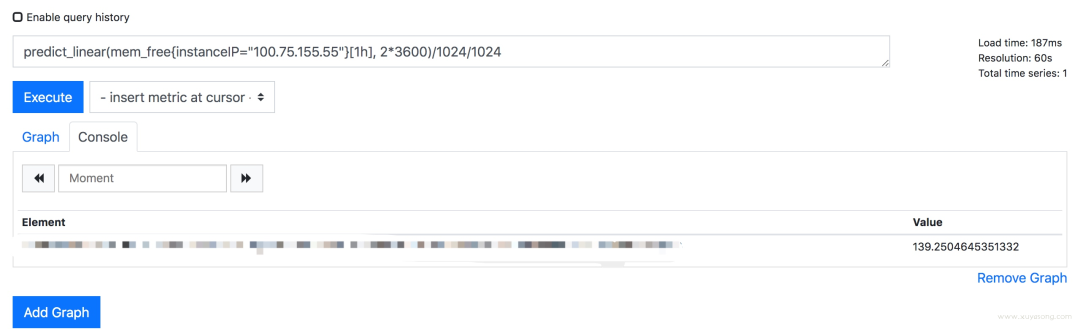
你可以基于設(shè)置合理的報警規(guī)則,如小于 10 時報警
rule:?predict_linear(mem_free{instanceIP="100.75.155.55"}[1h],?2*3600)/1024/1024?<10
predict_linear 與 deriv 的關(guān)系,含義上約等于,predict_linear 稍微準(zhǔn)確一些。
??deriv(mem_free{instanceIP="100.75.155.55"}[1h])?*?2?*?3600
+
??mem_free{instanceIP="100.75.155.55"}[1h]
如果你要基于 metric 做模型預(yù)測,可以參考下forecast-prometheus[14]
錯誤的高可用設(shè)計
有些人提出過這種類型的方案,想提高其擴展性和可用性。
應(yīng)用程序?qū)?metric 推到到消息隊列如 kafaka,然后經(jīng)過 exposer 消費中轉(zhuǎn),再被 prometheus 拉取。產(chǎn)生這種方案的原因一般是有歷史包袱、復(fù)用現(xiàn)有組件、想通過 mq 來提高擴展性。
這種方案有幾個問題:
增加了 queue 組件,多了一層依賴,如果 app 與 queue 之間連接失敗,難道要在 app 本地緩存監(jiān)控數(shù)據(jù)? 抓取時間可能會不同步,延遲的數(shù)據(jù)將會被標(biāo)記為陳舊數(shù)據(jù),當(dāng)然你可以通過添加時間戳來標(biāo)識,但就失去了對陳舊數(shù)據(jù)的處理邏輯[15] 擴展性問題:prometheus 適合大量小目標(biāo),而不是一個大目標(biāo),如果你把所有數(shù)據(jù)都放在了 exposer 中,那么 prometheus 的單個 job 拉取就會成為 cpu 瓶頸。這個和 pushgateway 有些類似,沒有特別必要的場景,都不是官方建議的方式。 缺少了服務(wù)發(fā)現(xiàn)和拉取控制,prom 只知道一個 exposer,不知道具體是哪些 target,不知道他們的 up 時間,無法使用 scrape_*等指標(biāo)做查詢,也無法用scrape_limit[16]做限制。
如果你的架構(gòu)和 prometheus 的設(shè)計理念相悖,可能要重新設(shè)計一下方案了,否則擴展性和可靠性反而會降低。
高可用方案
prometheus 高可用有幾種方案:
基本 HA:即兩套 prometheus 采集完全一樣的數(shù)據(jù),外邊掛負(fù)載均衡 HA + 遠(yuǎn)程存儲:除了基礎(chǔ)的多副本 prometheus,還通過 Remote write 寫入到遠(yuǎn)程存儲,解決存儲持久化問題 聯(lián)邦集群:即 federation,按照功能進(jìn)行分區(qū),不同的 shard 采集不同的數(shù)據(jù),由 Global 節(jié)點來統(tǒng)一存放,解決監(jiān)控數(shù)據(jù)規(guī)模的問題。 使用 thanos 或者 victoriametrics,來解決全局查詢、多副本數(shù)據(jù) join 問題。
就算使用官方建議的多副本 + 聯(lián)邦,仍然會遇到一些問題:
官方建議數(shù)據(jù)做Shard,然后通過federation來實現(xiàn)高可用,
但是邊緣節(jié)點和Global節(jié)點依然是單點,需要自行決定是否每一層都要使用雙節(jié)點重復(fù)采集進(jìn)行保活。
也就是仍然會有單機瓶頸。
另外部分敏感報警盡量不要通過global節(jié)點觸發(fā),畢竟從Shard節(jié)點到Global節(jié)點傳輸鏈路的穩(wěn)定性會影響數(shù)據(jù)到達(dá)的效率,進(jìn)而導(dǎo)致報警實效降低。
例如服務(wù)updown狀態(tài),API請求異常這類報警我們都放在shard節(jié)點進(jìn)行報警。
本質(zhì)原因是,prometheus 的本地存儲沒有數(shù)據(jù)同步能力,要在保證可用性的前提下,再保持?jǐn)?shù)據(jù)一致性是比較困難的,基礎(chǔ)的 HA proxy 滿足不了要求,比如:
集群的后端有 A 和 B 兩個實例,A 和 B 之間沒有數(shù)據(jù)同步。A 宕機一段時間,丟失了一部分?jǐn)?shù)據(jù),如果負(fù)載均衡正常輪詢,請求打到 A 上時,數(shù)據(jù)就會異常。 如果 A 和 B 的啟動時間不同,時鐘不同,那么采集同樣的數(shù)據(jù)時間戳也不同,就不是多副本同樣數(shù)據(jù)的概念了 就算用了遠(yuǎn)程存儲,A 和 B 不能推送到同一個 tsdb,如果每人推送自己的 tsdb,數(shù)據(jù)查詢走哪邊就是問題了。
因此解決方案是在存儲、查詢兩個角度上保證數(shù)據(jù)的一致:
存儲角度:如果使用 remote write 遠(yuǎn)程存儲, A 和 B 后面可以都加一個 adapter,adapter 做選主邏輯,只有一份數(shù)據(jù)能推送到 tsdb,這樣可以保證一個異常,另一個也能推送成功,數(shù)據(jù)不丟,同時遠(yuǎn)程存儲只有一份,是共享數(shù)據(jù)。方案可以參考這篇文章[17] 查詢角度:上邊的方案實現(xiàn)很復(fù)雜且有一定風(fēng)險,因此現(xiàn)在的大多數(shù)方案在查詢層面做文章,比如 thanos 或者 victoriametrics,仍然是兩份數(shù)據(jù),但是查詢時做數(shù)據(jù)去重和 join。只是 thanos 是通過 sidecar 把數(shù)據(jù)放在對象存儲,victoriametrics 是把數(shù)據(jù) remote write 到自己的 server 實例,但查詢層 thanos-query 和 victor 的 promxy 的邏輯基本一致。
我們采用了 thanos 來支持多地域監(jiān)控數(shù)據(jù),具體方案可以看這篇文章[18]
關(guān)于日志
k8s 中的日志一般指是容器標(biāo)準(zhǔn)輸出 + 容器內(nèi)日志,方案基本是采用 fluentd/fluent-bit/filebeat 等采集推送到 es,但還有一種是日志轉(zhuǎn) metric,如解析特定字符串出現(xiàn)次數(shù),nginx 日志得到 qps 指標(biāo) 等,這里可以采用 grok 或者 mtail,以 exporter 的形式提供 metric 給 prometheus
參考資料
容器監(jiān)控實踐—K8S 常用指標(biāo)分析:?http://www.xuyasong.com/?p=1717
[2]dcgm exporter:?https://github.com/NVIDIA/gpu-monitoring-tools/tree/master/exporters/prometheus-dcgm
[3]2.16 版本:?https://github.com/prometheus/prometheus/commit/d996ba20ec9c7f1808823a047ed9d5ce96be3d8f
[4]這篇文章:?https://zhangguanzhang.github.io/2019/09/05/prometheus-change-timezone/
[5]issue:?https://github.com/prometheus/prometheus/issues/500
[6]tsdb 狀態(tài):?https://www.google.com/url?q=https%3A%2F%2Fprometheus.io%2Fdocs%2Fprometheus%2Flatest%2Fquerying%2Fapi%2F%23tsdb-stats&sa=D&sntz=1&usg=AFQjCNFE5AzQxyhzt8SqQLHPUySZl3lNNw
[7]這篇:?http://www.xuyasong.com/?p=1601
[8]視頻:?https://www.youtube.com/watch?reload=9&v=67Ulrq6DxwA
[9]文章:?http://www.xuyasong.com/?p=1578
[10]step:?https://www.robustperception.io/step-and-query_range
[11]部分?jǐn)?shù)據(jù):?https://chanjarster.github.io/post/p8s-step-param/
[12]1 分鐘:?https://www.robustperception.io/optimising-startup-time-of-prometheus-2-6-0-with-pprof
[13]建議(Brian Brazil):?https://www.robustperception.io/how-many-metrics-should-an-application-return
[14]forecast-prometheus:?https://github.com/nfrumkin/forecast-prometheus
[15]處理邏輯:?https://www.robustperception.io/staleness-and-promql
[16]scrape_limit:?https://www.robustperception.io/using-sample_limit-to-avoid-overload
[17]這篇文章:?https://blog.timescale.com/blog/prometheus-ha-postgresql-8de68d19b6f5
[18]這篇文章:?http://www.xuyasong.com/?p=1925
原文鏈接:https://yasongxu.gitbook.io/container-monitor/yi-.-kai-yuan-fang-an/di-2-zhang-prometheus/prometheus-use
往期推薦
掃一掃,關(guān)注我
一起學(xué)習(xí),一起進(jìn)步
每周贈書,福利不斷
﹀
﹀
﹀
深度內(nèi)容
推薦加入
最近熱門內(nèi)容回顧? ?#技術(shù)人系列
