
進擊的數(shù)據(jù)分析:像炒菜一樣做策略

頁")

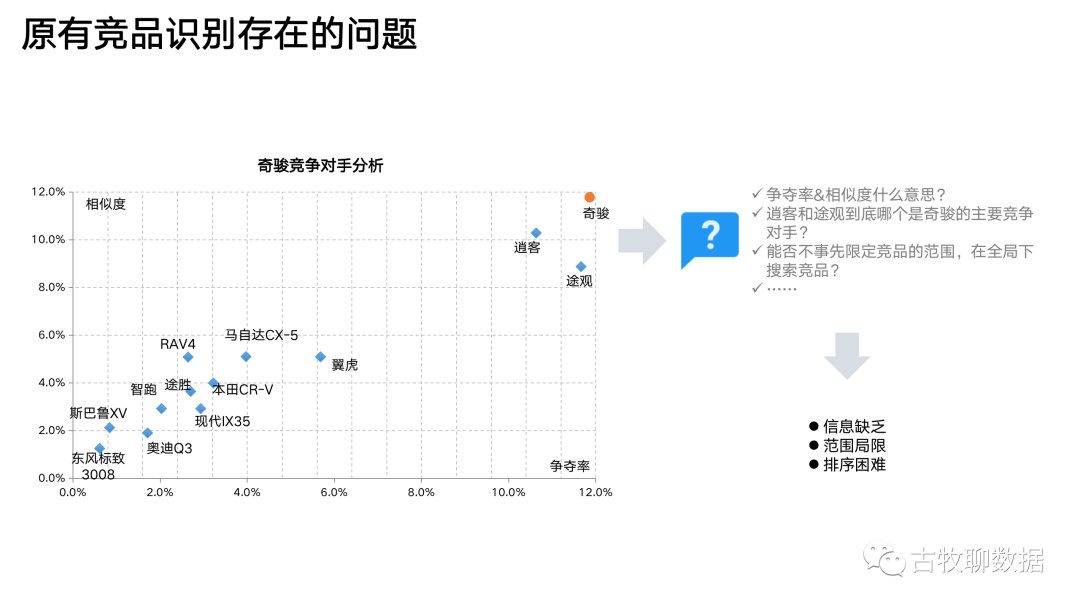
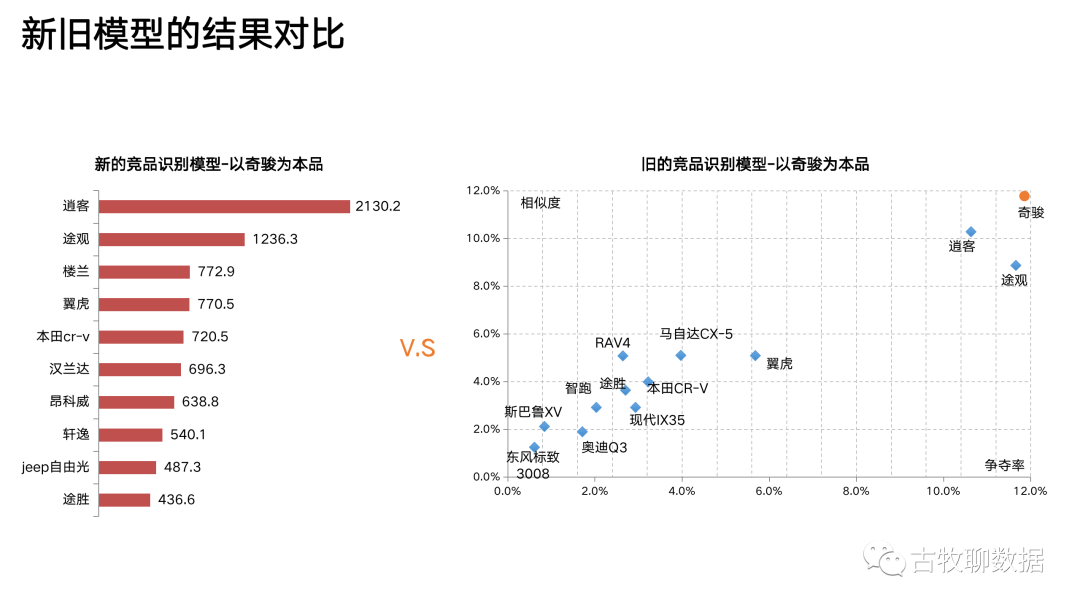
上面這個散點圖,是競品分析的傳統(tǒng)做法。以汽車行業(yè)舉例,右上角的那個奇駿就是廣告主爸爸的兒子——本品,剩下的那些都是競品,哪個離奇駿最近,哪個就是本品的最大競品。傳統(tǒng)做法從相似度和爭奪率這2個維度來拆解“競爭”這個概念,試圖量化點與點之間的距離。但有問題,因為相似度和爭奪率是這么計算的:
相似度:在一段時間內(nèi),既搜過本品也搜過競品的用戶,在搜過本品或搜過競品的總用戶中的比例(本品與競品的交集/本品與競品的并集)
爭奪率:在一段時間內(nèi),搜索過本品的用戶中,有多少人還搜索過某個競品(本品與競品的交集/本品)
問題1:如果我事先不輸入任何競品,這個方法就行不通(相似度和爭奪率的核心都是算交集,可你不告訴我跟誰交,我怎么算?)。相當(dāng)于它無法突破已知的經(jīng)驗范疇,而我們往往就是需要數(shù)據(jù)告知一些經(jīng)驗以外的東西
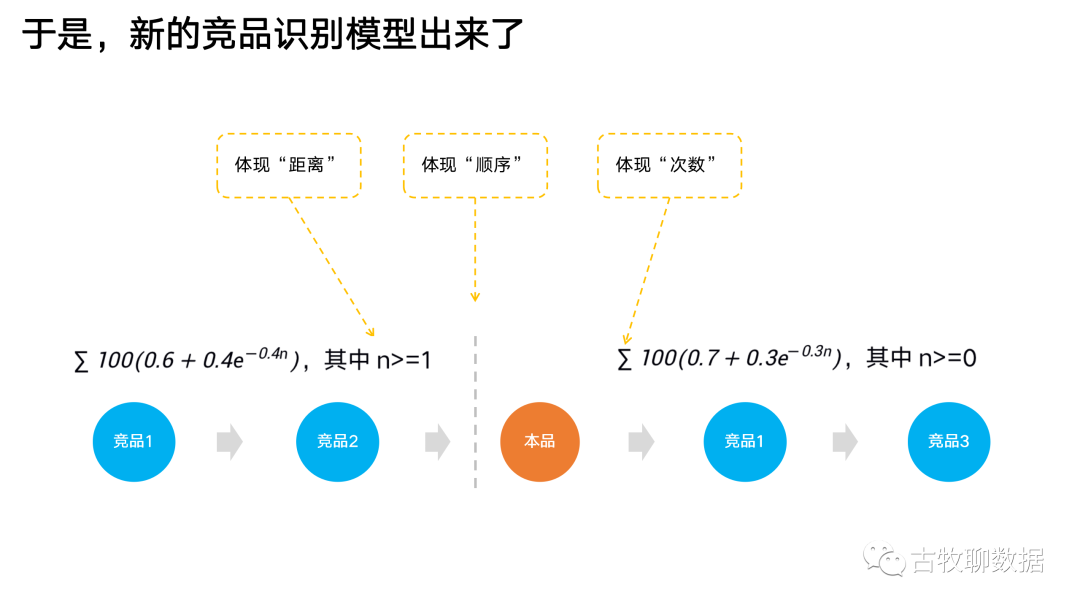
問題2:這個方法中,只應(yīng)用了“重合”這一個特征。然而用戶的搜索行為是一個連續(xù)的序列,是有前后順序(先搜A再搜B和先搜B再搜A,不一樣)、有次數(shù)多寡(搜了10次A和只搜了1次A,不一樣)、有距離遠(yuǎn)近的(剛搜完A就搜B,和搜完A之后又搜了CDE之再搜B,不一樣),這些信息在傳統(tǒng)方法中,都沒有體現(xiàn)出來
問題3:傳統(tǒng)方法下,誰是競品需要看圖說話。那么問題來了,就拿圖里的逍客和途觀來說,看上去跟奇駿都比較近,到底哪個才是最強勁的競爭對手?


? ??
評論
圖片
表情