
用 Keras+LSTM+CRF 的實(shí)踐命名實(shí)體識(shí)別NER

文本分詞、詞性標(biāo)注和命名實(shí)體識(shí)別都是自然語(yǔ)言處理領(lǐng)域里面很基礎(chǔ)的任務(wù),他們的精度決定了下游任務(wù)的精度,其實(shí)在這之前我并沒(méi)有真正意義上接觸過(guò)命名實(shí)體識(shí)別這項(xiàng)工作,雖然說(shuō)讀研期間斷斷續(xù)續(xù)也參與了這樣的項(xiàng)目,但是畢業(yè)之后始終覺(jué)得一知半解的感覺(jué),最近想重新?lián)炱饋?lái),以實(shí)踐為學(xué)習(xí)的主要手段來(lái)比較系統(tǒng)地對(duì)命名實(shí)體識(shí)別這類任務(wù)進(jìn)行理解、學(xué)習(xí)和實(shí)踐應(yīng)用。
當(dāng)今的各個(gè)應(yīng)用里面幾乎不會(huì)說(shuō)哪個(gè)任務(wù)會(huì)沒(méi)有深度學(xué)習(xí)的影子,很多子任務(wù)的發(fā)展歷程都是驚人的相似,最初大部分的研究和應(yīng)用都是集中在機(jī)器學(xué)習(xí)領(lǐng)域里面,之后隨著深度學(xué)習(xí)模型的發(fā)展,也被廣泛應(yīng)用起來(lái)了,命名實(shí)體識(shí)別這樣的序列標(biāo)注任務(wù)自然也是不例外的,早就有了基于LSTM+CRF的深度學(xué)習(xí)實(shí)體識(shí)別的相關(guān)研究了,只不過(guò)與我之前的方向不一致,所以一直沒(méi)有化太多的時(shí)間去關(guān)注過(guò)它,最近正好在學(xué)習(xí)NER,在之前的相關(guān)文章中已經(jīng)基于機(jī)器學(xué)習(xí)的方法實(shí)踐了簡(jiǎn)單的命名實(shí)體識(shí)別了,這里以深度學(xué)習(xí)模型為基礎(chǔ)來(lái)實(shí)現(xiàn)NER。
命名實(shí)體識(shí)別屬于序列標(biāo)注任務(wù),其實(shí)更像是分類任務(wù),NER是在一段文本中,將預(yù)先定義好的實(shí)體類型識(shí)別出來(lái)。
NER是一種序列標(biāo)注問(wèn)題,因此他們的數(shù)據(jù)標(biāo)注方式也遵照序列標(biāo)注問(wèn)題的方式,主要是BIO和BIOES兩種。這里直接介紹BIOES,明白了BIOES,BIO也就掌握了。
先列出來(lái)BIOES分別代表什么意思:
B,即Begin,表示開(kāi)始
I,即Intermediate,表示中間
E,即End,表示結(jié)尾
S,即Single,表示單個(gè)字符
O,即Other,表示其他,用于標(biāo)記無(wú)關(guān)字符
比如對(duì)于下面的一句話:
姚明去哈爾濱工業(yè)大學(xué)體育館打球了
標(biāo)注結(jié)果為:
姚明 去 哈爾濱工業(yè)大學(xué) 體育館 打球 了
B-PER E-PER O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG E-ORG B-LOC I-LOC E-LOC O O O
簡(jiǎn)單的溫習(xí)就到這里了,接下來(lái)進(jìn)入到本文的實(shí)踐部分,首先是數(shù)據(jù)集部分,數(shù)據(jù)集來(lái)源于網(wǎng)絡(luò)獲取,簡(jiǎn)單看下樣例數(shù)據(jù),如下所示:
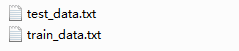
train_data部分樣例數(shù)據(jù)如下所示:
當(dāng) O
希 O
望 O
工 O
程 O
救 O
助 O
的 O
百 O
萬(wàn) O
兒 O
童 O
成 O
長(zhǎng) O
起 O
來(lái) O
, O
科 O
教 O
興 O
國(guó) O
蔚 O
然 O
成 O
風(fēng) O
時(shí) O
, O
今 O
天 O
有 O
收 O
藏 O
價(jià) O
值 O
的 O
書(shū) O
你 O
沒(méi) O
買 O
, O
明 O
日 O
就 O
叫 O
你 O
悔 O
不 O
當(dāng) O
初 O
!O
test_data部分樣例數(shù)據(jù)如下所示:
高 O
舉 O
愛(ài) O
國(guó) O
主 O
義 O
和 O
社 O
會(huì) O
主 O
義 O
兩 O
面 O
旗 O
幟 O
, O
團(tuán) O
結(jié) O
全 O
體 O
成 O
員 O
以 O
及 O
所 O
聯(lián) O
系 O
的 O
歸 O
僑 O
、 O
僑 O
眷 O
, O
發(fā) O
揚(yáng) O
愛(ài) O
國(guó) O
革 O
命 O
的 O
光 O
榮 O
傳 O
統(tǒng) O
, O
為 O
統(tǒng) O
一 O
祖 O
國(guó) O
、 O
振 O
興 O
中 B-LOC
華 I-LOC
而 O
努 O
力 O
奮 O
斗 O
;O
簡(jiǎn)單了解訓(xùn)練集數(shù)據(jù)和測(cè)試集數(shù)據(jù)結(jié)構(gòu)后就可以進(jìn)行后面的數(shù)據(jù)處理,主要的目的就是生成特征數(shù)據(jù),核心代碼實(shí)現(xiàn)如下所示:
with open('test_data.txt',encoding='utf-8') as f:
test_data_list=[one.strip().split('\t') for one in f.readlines() if one.strip()]
with open('train_data.txt',encoding='utf-8') as f:
train_data_list=[one.strip().split('\t') for one in f.readlines() if one.strip()]
char_list=[one[0] for one in test_data_list]+[one[0] for one in train_data_list]
label_list=[one[-1] for one in test_data_list]+[one[-1] for one in train_data_list]
print('char_list_length: ', len(char_list))
print('label_list_length: ', len(label_list))
print('char_num: ', len(list(set(char_list))))
print('label_num: ', len(list(set(label_list))))
char_count,label_count={},{}
#字符頻度統(tǒng)計(jì)
for one in char_list:
if one in char_count:
char_count[one]+=1
else:
char_count[one]=1
for one in label_list:
if one in label_count:
label_count[one]+=1
else:
label_count[one]=1
#按頻度降序排序
sorted_char=sorted(char_count.items(),key=lambda e:e[1],reverse=True)
sorted_label=sorted(label_count.items(),key=lambda e:e[1],reverse=True)
#字符-id映射關(guān)系構(gòu)建
char_map_dict={}
label_map_dict={}
for i in range(len(sorted_char)):
char_map_dict[sorted_char[i][0]]=i
char_map_dict[str(i)]=sorted_char[i][0]
for i in range(len(sorted_label)):
label_map_dict[sorted_label[i][0]]=i
label_map_dict[str(i)]=sorted_label[i][0]
#結(jié)果存儲(chǔ)
with open('charMap.json','w') as f:
f.write(json.dumps(char_map_dict))
with open('labelMap.json','w') as f:
f.write(json.dumps(label_map_dict))
代碼實(shí)現(xiàn)的很清晰,關(guān)鍵的部分也都有對(duì)應(yīng)的注釋內(nèi)容,這里就不多解釋了,核心的思想就是將字符或者是標(biāo)簽類別數(shù)據(jù)映射為對(duì)應(yīng)的index數(shù)據(jù),這里我沒(méi)有對(duì)頻度設(shè)置過(guò)濾閾值,有的實(shí)現(xiàn)里面會(huì)過(guò)濾掉只出現(xiàn)了1次的數(shù)據(jù),這個(gè)可以根據(jù)自己的需要進(jìn)行對(duì)應(yīng)的修改。
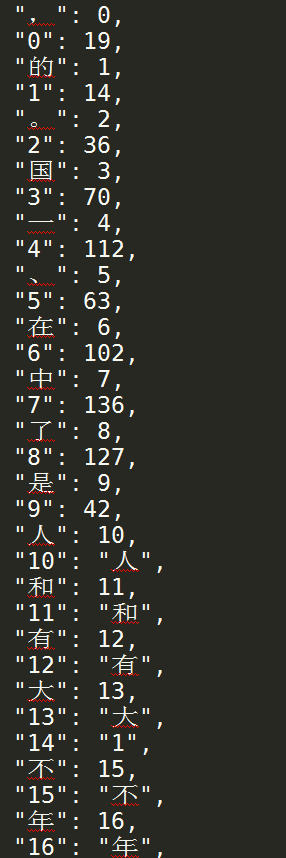
charMap數(shù)據(jù)樣例如下所示:
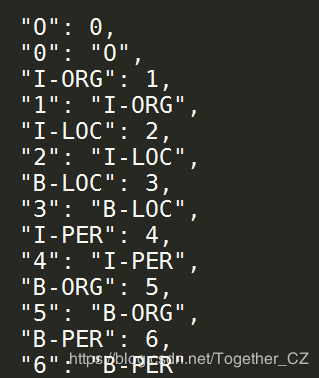
labelMap數(shù)據(jù)樣例如下所示:
在生成上述映射數(shù)據(jù)之后,就可以對(duì)原始的文本數(shù)據(jù)進(jìn)行轉(zhuǎn)化計(jì)算,進(jìn)而生成我們所需要的特征數(shù)據(jù)了,核心代碼實(shí)現(xiàn)如下所示:
X_train,y_train,X_test,y_test=[],[],[],[]
#訓(xùn)練數(shù)據(jù)集
for i in range(len(trainData)):
one_sample=[one.strip().split('\t') for one in trainData[i]]
char_list=[O[0] for O in one_sample]
label_list=[O[1] for O in one_sample]
char_vec=[char_map_dict[char_list[v]] for v in range(len(char_list))]
label_vec=[label_map_dict[label_list[l]] for l in range(len(label_list))]
X_train.append(char_vec)
y_train.append(label_vec)
#測(cè)試數(shù)據(jù)集
for i in range(len(testData)):
one_sample=[one.strip().split('\t') for one in testData[i]]
char_list=[O[0] for O in one_sample]
label_list=[O[1] for O in one_sample]
char_vec=[char_map_dict[char_list[v]] for v in range(len(char_list))]
label_vec=[label_map_dict[label_list[l]] for l in range(len(label_list))]
X_test.append(char_vec)
y_test.append(label_vec)
feature={}
feature['X_train'],feature['y_train']=X_train,y_train
feature['X_test'],feature['y_test']=X_test,y_test
#結(jié)果存儲(chǔ)
with open('feature.json','w') as f:
f.write(json.dumps(feature))
到這里我們已經(jīng)得到了我們所需要的特征數(shù)據(jù),且已經(jīng)劃分好了測(cè)試集數(shù)據(jù)和訓(xùn)練集數(shù)據(jù)。
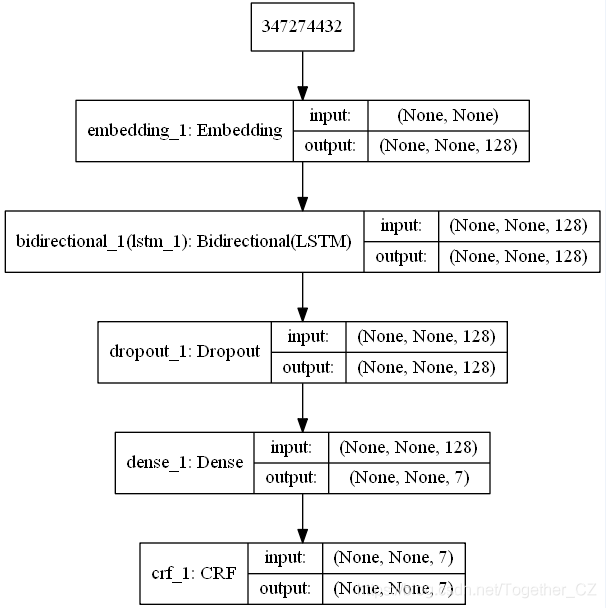
接下來(lái)就可以構(gòu)建模型了,這里為了簡(jiǎn)化實(shí)現(xiàn),我采用的是Keras框架,相比于原生態(tài)的Tensorflow框架來(lái)說(shuō),上手門(mén)檻更低,核心代碼實(shí)現(xiàn)如下所示:
#加載數(shù)據(jù)集
with open('feature.json') as f:
F=json.load(f)
X_train,X_test,y_train,y_test=F['X_train'],F['X_test'],F['y_train'],F['y_test']
#數(shù)據(jù)對(duì)齊操作
X_train = pad_sequences(X_train, maxlen=max_len, value=0)
y_train = pad_sequences(y_train, maxlen=max_len, value=-1)
y_train = np.expand_dims(y_train, 2)
X_test = pad_sequences(X_test, maxlen=max_len, value=0)
y_test = pad_sequences(y_test, maxlen=max_len, value=-1)
y_test = np.expand_dims(y_test, 2)
#模型初始化、訓(xùn)練
if not os.path.exists(saveDir):
os.makedirs(saveDir)
#模型初始化
model = Sequential()
model.add(Embedding(voc_size, 256, mask_zero=True))
model.add(Bidirectional(LSTM(128, return_sequences=True)))
model.add(Dropout(rate=0.5))
model.add(Dense(tag_size))
crf = CRF(tag_size, sparse_target=True)
model.add(crf)
model.summary()
model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
#訓(xùn)練擬合
history=model.fit(X_train,y_train,batch_size=100,epochs=500,validation_data=[X_test,y_test])
model.save(saveDir+'model.h5')
#模型結(jié)構(gòu)可視化
try:
plot_model(model,to_file=saveDir+"model_structure.png",show_shapes=True)
except Exception as e:
print('Exception: ', e)
#結(jié)果可視化
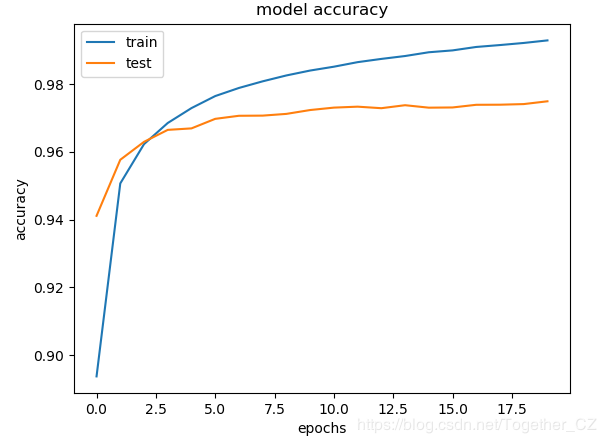
plt.clf()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epochs')
plt.legend(['train','test'], loc='upper left')
plt.savefig(saveDir+'train_validation_acc.png')
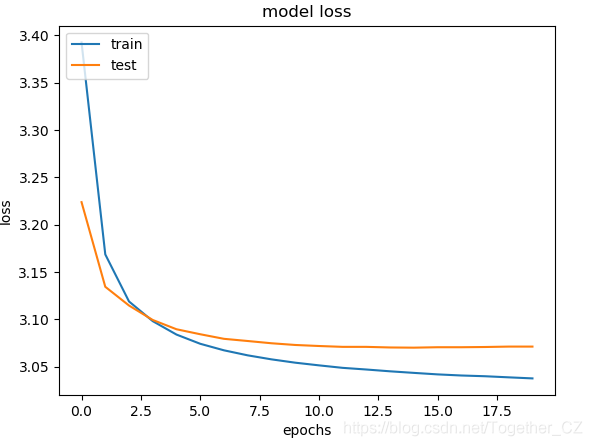
plt.clf()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig(saveDir+'train_validation_loss.png')
scores=model.evaluate(X_test,y_test,verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
model_json=model.to_json()
with open(saveDir+'structure.json','w') as f:
f.write(model_json)
model.save_weights(saveDir+'weight.h5')
print('===Finish====')


作者:沂水寒城,CSDN博客專家,個(gè)人研究方向:機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
贊 賞 作 者

Python中文社區(qū)作為一個(gè)去中心化的全球技術(shù)社區(qū),以成為全球20萬(wàn)Python中文開(kāi)發(fā)者的精神部落為愿景,目前覆蓋各大主流媒體和協(xié)作平臺(tái),與阿里、騰訊、百度、微軟、亞馬遜、開(kāi)源中國(guó)、CSDN等業(yè)界知名公司和技術(shù)社區(qū)建立了廣泛的聯(lián)系,擁有來(lái)自十多個(gè)國(guó)家和地區(qū)數(shù)萬(wàn)名登記會(huì)員,會(huì)員來(lái)自以工信部、清華大學(xué)、北京大學(xué)、北京郵電大學(xué)、中國(guó)人民銀行、中科院、中金、華為、BAT、谷歌、微軟等為代表的政府機(jī)關(guān)、科研單位、金融機(jī)構(gòu)以及海內(nèi)外知名公司,全平臺(tái)近20萬(wàn)開(kāi)發(fā)者關(guān)注。
長(zhǎng)按掃碼添加“Python小助手”
進(jìn)入 P Y 交 流 群
▼點(diǎn)擊成為社區(qū)會(huì)員 喜歡就點(diǎn)個(gè)在看吧
