
【NLP】流水的NLP鐵打的NER:命名實(shí)體識(shí)別實(shí)踐與探索
作者:王岳王院長(zhǎng)
知乎:https://www.zhihu.com/people/wang-yue-40-21
github:?https://github.com/wavewangyue
編輯:yuquanle

前言
最近在做命名實(shí)體識(shí)別(Named Entity Recognition, NER)的工作,也就是序列標(biāo)注(Sequence Tagging),老 NLP task 了,就是從一段文本中抽取到找到任何你想要的東西,可能是某個(gè)字,某個(gè)詞,或者某個(gè)短語
為什么說流水的NLP鐵打的NER?NLP四大任務(wù)嘛,分類、生成、序列標(biāo)注、句子對(duì)標(biāo)注。分類任務(wù),面太廣了,萬物皆可分類,各種方法層出不窮;句子對(duì)標(biāo)注,經(jīng)常是體現(xiàn)人工智能(zhang)對(duì)人類語言理解能力的標(biāo)準(zhǔn)秤,孿生網(wǎng)絡(luò)、DSSM、ESIM 各種模型一年年也是秀的飛起;生成任務(wù),目前人工智障 NLP 能力的天花板,雖然經(jīng)常會(huì)處在說不出來人話的狀態(tài),但也不斷吸引 CopyNet、VAE、GAN 各類選手前來挑戰(zhàn);唯有序列標(biāo)注,數(shù)年如一日,不忘初心,原地踏步,到現(xiàn)在一提到 NER,還是會(huì)一下子只想到 LSTM-CRF,鐵打不動(dòng)的模型,沒得挑也不用挑,用就完事了,不用就是不給面子
雖然之前也做過 NER,但是想細(xì)致地捋一下,看一下自從有了 LSTM-CRF 之后,NER 在做些什么,順便記錄一下最近的工作,中間有些經(jīng)驗(yàn)和想法,有什么就記點(diǎn)什么
因?yàn)槟芰τ邢蓿€是跟之前一樣,就少講理論少放公式,多畫模型圖多放代碼,還是主要從工程實(shí)現(xiàn)角度記錄和分享下經(jīng)驗(yàn),也記錄一些個(gè)人探索過程。如果有新人苦于不知道怎么實(shí)現(xiàn)一個(gè) NER 模型,不知道 LSTM-CRF、BERT-CRF 怎么寫,看到代碼之后便可以原地起飛,從此打開新世界的大門;或者有老 NLPer 從我的某段探索過程里感覺還挺有意思的,那我就太開心了。就這樣
還是先放結(jié)論
命名實(shí)體識(shí)別雖然是一個(gè)歷史悠久的老任務(wù)了,但是自從2015年有人使用了BI-LSTM-CRF模型之后,這個(gè)模型和這個(gè)任務(wù)簡(jiǎn)直是郎才女貌,天造地設(shè),輪不到任何妖怪來反對(duì)。直到后來出現(xiàn)了BERT。在這里放兩個(gè)問題:
2015-2019年,BERT出現(xiàn)之前4年的時(shí)間,命名實(shí)體識(shí)別就只有 BI-LSTM-CRF 了嗎? 2019年BERT出現(xiàn)之后,命名實(shí)體識(shí)別就只有 BERT-CRF(或者 BERT-LSTM-CRF)了嗎?
經(jīng)過我不完善也不成熟的調(diào)研之后,好像的確是的,一個(gè)能打的都沒有
既然模型打不動(dòng)了,然后我找了找 ACL2020 做NER的論文,看看現(xiàn)在的NER還在做哪些事情,主要分幾個(gè)方面:
多特征:實(shí)體識(shí)別不是一個(gè)特別復(fù)雜的任務(wù),不需要太深入的模型,那么就是加特征,特征越多效果越好,所以字特征、詞特征、詞性特征、句法特征、KG表征等等的就一個(gè)個(gè)加吧,甚至有些中文 NER 任務(wù)里還加入了拼音特征、筆畫特征。。?心有多大,特征就有多多
多任務(wù):很多時(shí)候做 NER 的目的并不僅是為了 NER,而是服務(wù)于一個(gè)更大的目標(biāo),比如信息抽取、問答系統(tǒng)等等的,如果把整個(gè)大任務(wù)做一個(gè)端到端的模型,就需要做成一個(gè)多任務(wù)模型,把 NER 作為其中一個(gè)子任務(wù);另外,如果單純?yōu)榱?NER,本身也可以做成多任務(wù),比如實(shí)體類型多的時(shí)候,單獨(dú)用一個(gè)任務(wù)來識(shí)別實(shí)體,另一個(gè)用來判斷實(shí)體類型
時(shí)令大雜燴:把當(dāng)下比較流行的深度學(xué)習(xí)話題或方法跟NER結(jié)合一下,比如結(jié)合強(qiáng)化學(xué)習(xí)的NER、結(jié)合 few-shot learning 的NER、結(jié)合多模態(tài)信息的NER、結(jié)合跨語種學(xué)習(xí)的NER等等的,具體就不提了
所以沿著上述思路,就在一個(gè)中文NER任務(wù)上做一些實(shí)踐,寫一些模型。都列在下面了,首先是 LSTM-CRF 和 BERT-CRF,然后就是幾個(gè)多任務(wù)模型, Cascade 開頭的(因?yàn)閷?shí)體類型比較多,把NER拆成兩個(gè)任務(wù),一個(gè)用來識(shí)別實(shí)體,另一個(gè)用來判斷實(shí)體類型),后面的幾個(gè)模型里,WLF 指的是 Word Level Feature(即在原本字級(jí)別的序列標(biāo)注任務(wù)上加入詞級(jí)別的表征),WOL 指的是 Weight of Loss(即在loss函數(shù)方面通過設(shè)置權(quán)重來權(quán)衡Precision與Recall,以達(dá)到提高F1的目的),具體細(xì)節(jié)后面再講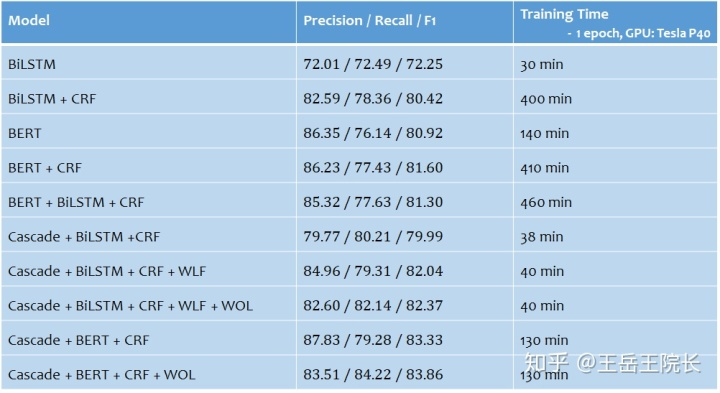
代碼:上述所有模型的代碼都在這里:https://github.com/wavewangyue/ner,帶 BERT 的可以自己去下載BERT_CHINESE預(yù)訓(xùn)練的 ckpt 模型,然后解壓到 bert_model 目錄下
環(huán)境:Python3, Tensorflow1.12
數(shù)據(jù):一個(gè)電商場(chǎng)景下商品標(biāo)題中的實(shí)體識(shí)別,因?yàn)槭枪ぷ髦械臄?shù)據(jù),并且通過遠(yuǎn)程監(jiān)督弱標(biāo)注的質(zhì)量也一般,完整數(shù)據(jù)就不放了。但是我 sample 了一些數(shù)據(jù)留在 git 里了,為了直接 git clone 完,代碼原地就能跑,方便你我他
ok 下面正經(jīng)開工
1. BI-LSTM+CRF
用純 HMM 或者 CRF 做 NER 的話就不講了,比較古老了。從 LSTM+CRF 開始講起,應(yīng)該是2015年被提出的模型[1],模型架構(gòu)在今天來看非常簡(jiǎn)單,直接上圖
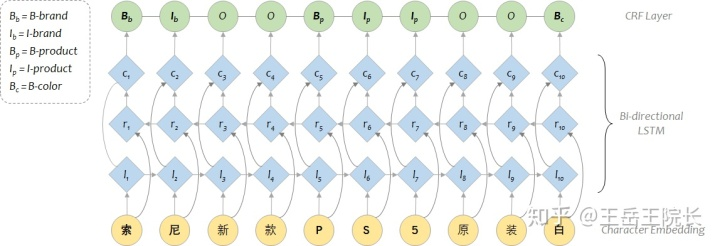
BI-LSTM 即 Bi-directional LSTM,也就是有兩個(gè) LSTM cell,一個(gè)從左往右跑得到第一層表征向量 l,一個(gè)從右往左跑得到第二層向量 r,然后兩層向量加一起得到第三層向量 c
如果不使用CRF的話,這里就可以直接接一層全連接與softmax,輸出結(jié)果了;如果用CRF的話,需要把 c 輸入到 CRF 層中,經(jīng)過 CRF 一通專業(yè)縝密的計(jì)算,它來決定最終的結(jié)果
這里說一下用于表示序列標(biāo)注結(jié)果的 BIO 標(biāo)記法。序列標(biāo)注里標(biāo)記法有很多,最主要的還是 BIO 與 BIOES 這兩種。B 就是標(biāo)記某個(gè)實(shí)體詞的開始,I 表示某個(gè)實(shí)體詞的中間,E 表示某個(gè)實(shí)體詞的結(jié)束,S 表示這個(gè)實(shí)體詞僅包含當(dāng)前這一個(gè)字。區(qū)別很簡(jiǎn)單,看圖就懂。一般實(shí)驗(yàn)效果上差別不大,有些時(shí)候用 BIOES 可能會(huì)有一內(nèi)內(nèi)的優(yōu)勢(shì)
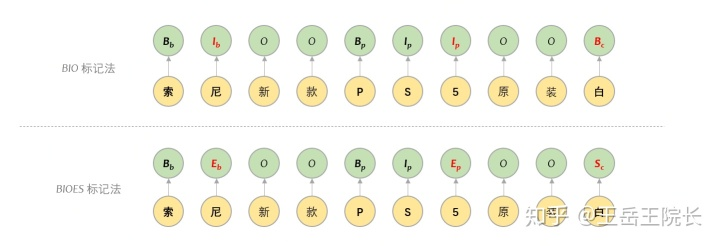
另外,如果在某些場(chǎng)景下不考慮實(shí)體類別(比如問答系統(tǒng)),那就直接完事了,但是很多場(chǎng)景下需要同時(shí)考慮實(shí)體類別(比如事件抽取中需要抽取主體客體地點(diǎn)機(jī)構(gòu)等等),那么就需要擴(kuò)展 BIO 的 tag 列表,給每個(gè)“實(shí)體類型”都分配一個(gè) B 與 I 的標(biāo)簽,例如用“B-brand”來代表“實(shí)體詞的開始,且實(shí)體類型為品牌”。當(dāng)實(shí)體類別過多時(shí),BIOES 的標(biāo)簽列表規(guī)模可能就爆炸了
「基于 Tensorflow 來實(shí)現(xiàn) LSTM+CRF 代碼也很簡(jiǎn)單,直接上」
self.inputs_seq?=?tf.placeholder(tf.int32,?[None,?None],?name="inputs_seq")?#?B?*?S
self.inputs_seq_len?=?tf.placeholder(tf.int32,?[None],?name="inputs_seq_len")?#?B
self.outputs_seq?=?tf.placeholder(tf.int32,?[None,?None],?name='outputs_seq')?#?B?*?S
with?tf.variable_scope('embedding_layer'):
????embedding_matrix?=?tf.get_variable("embedding_matrix",?[vocab_size_char,?embedding_dim],?dtype=tf.float32)
????embedded?=?tf.nn.embedding_lookup(embedding_matrix,?self.inputs_seq)?#?B?*?S?*?D
with?tf.variable_scope('encoder'):
????cell_fw?=?tf.nn.rnn_cell.LSTMCell(hidden_dim)
????cell_bw?=?tf.nn.rnn_cell.LSTMCell(hidden_dim)
????((rnn_fw_outputs,?rnn_bw_outputs),?(rnn_fw_final_state,?rnn_bw_final_state))?=?tf.nn.bidirectional_dynamic_rnn(
????????cell_fw=cell_fw,?
????????cell_bw=cell_bw,?
????????inputs=embedded,?
????????sequence_length=self.inputs_seq_len,
????????dtype=tf.float32
????)
????rnn_outputs?=?tf.add(rnn_fw_outputs,?rnn_bw_outputs)?#?B?*?S?*?D
with?tf.variable_scope('projection'):
????logits_seq?=?tf.layers.dense(rnn_outputs,?vocab_size_bio)?#?B?*?S?*?V
????probs_seq?=?tf.nn.softmax(logits_seq)?#?B?*?S?*?V
????if?not?use_crf:
????????preds_seq?=?tf.argmax(probs_seq,?axis=-1,?name="preds_seq")?#?B?*?S
????else:
????????log_likelihood,?transition_matrix?=?tf.contrib.crf.crf_log_likelihood(logits_seq,?self.outputs_seq,?self.inputs_seq_len)
????????preds_seq,?crf_scores?=?tf.contrib.crf.crf_decode(logits_seq,?transition_matrix,?self.inputs_seq_len)
????
with?tf.variable_scope('loss'):
????if?not?use_crf:?
????????loss?=?tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_seq,?labels=self.outputs_seq)?#?B?*?S
????????masks?=?tf.sequence_mask(self.inputs_seq_len,?dtype=tf.float32)?#?B?*?S
????????loss?=?tf.reduce_sum(loss?*?masks,?axis=-1)?/?tf.cast(self.inputs_seq_len,?tf.float32)?#?B
????else:
????????loss?=?-log_likelihood?/?tf.cast(self.inputs_seq_len,?tf.float32)?#?B
Tensorflow 里調(diào)用 CRF 非常方便,主要就 crf_log_likelihood 和 crf_decode 這兩個(gè)函數(shù),結(jié)果和 loss 就都給你算出來了。它要學(xué)習(xí)的參數(shù)也很簡(jiǎn)單,就是這個(gè) transition_matrix,形狀為 V*V,V 是輸出端 BIO 的詞表大小。但是有一個(gè)小小的缺點(diǎn),就是官方實(shí)現(xiàn)的 crf_log_likelihood 里某個(gè)未知的角落有個(gè) stack 操作,會(huì)悄悄地吃掉很多的內(nèi)存。如果 V 較大,內(nèi)存占用量會(huì)極高,訓(xùn)練時(shí)間極長(zhǎng)。比如我的實(shí)驗(yàn)里有 500 個(gè)實(shí)體類別,也就是 V=500*2+1=1001,訓(xùn)練 1epoch 的時(shí)間從 30min 暴增到 400min
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gradients_impl.py:112:?UserWarning:?Converting?sparse?IndexedSlices?to?a?dense?Tensor?of?unknown?shape.?This?may?consume?a?large?amount?of?memory.
??"Converting?sparse?IndexedSlices?to?a?dense?Tensor?of?unknown?shape.?"
不過好消息是,Tensorflow2.0 里,這個(gè)問題不再有了
壞消息是,Tensorflow2.0 直接把 tf.contrib.crf 移除了,目前還沒有官方實(shí)現(xiàn)的 CRF 接口

再說一下為什么要加 CRF。從開頭的 Leaderboard 里可以看到,BiLSTM 的 F1 Score 在72%,而 BiLSTM+CRF 達(dá)到 80%,提升明顯

那么為什么提升這么大呢?CRF 的原理,網(wǎng)上隨便搜就一大把,就不講了(因?yàn)榈拇_很難,我也沒太懂),但是從實(shí)驗(yàn)的角度可以簡(jiǎn)單說說,就是 LSTM 只能通過輸入判斷輸出,但是 CRF 可以通過學(xué)習(xí)轉(zhuǎn)移矩陣,看前后的輸出來判斷當(dāng)前的輸出。這樣就能學(xué)到一些規(guī)律(比如“O 后面不能直接接 I”“B-brand 后面不可能接 I-color”),這些規(guī)律在有時(shí)會(huì)起到至關(guān)重要的作用
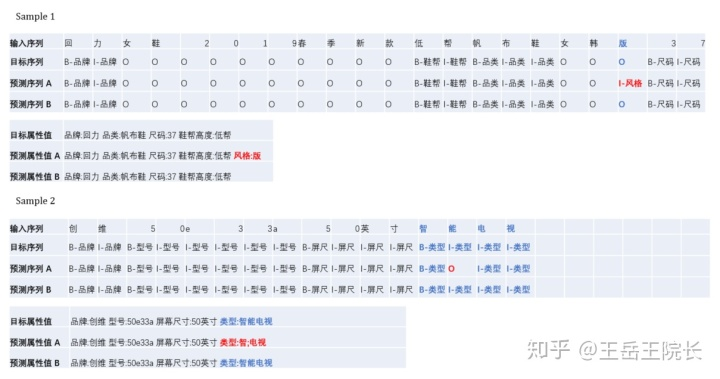
例如下面的例子,A 是沒加 CRF 的輸出結(jié)果,B 是加了 CRF 的輸出結(jié)果,一看就懂不細(xì)說了
2. BERT+CRF & BERT+LSTM+CRF
用 BERT 來做,結(jié)構(gòu)上跟上面是一樣的,只是把 LSTM 換成 BERT 就 ok 了,直接上代碼
首先把 BERT 這部分模型搭好,直接用 BERT 的官方代碼。這里我把序列長(zhǎng)度都標(biāo)成了“S+2”是為了提醒自己每條數(shù)據(jù)前后都加了“[CLS]”和“[SEP]”,出結(jié)果時(shí)需要處理掉
from?bert?import?modeling?as?bert_modeling
self.inputs_seq?=?tf.placeholder(shape=[None,?None],?dtype=tf.int32,?name="inputs_seq")?#?B?*?(S+2)
self.inputs_mask?=?tf.placeholder(shape=[None,?None],?dtype=tf.int32,?name="inputs_mask")?#?B?*?(S+2)
self.inputs_segment?=?tf.placeholder(shape=[None,?None],?dtype=tf.int32,?name="inputs_segment")?#?B?*?(S+2)
self.outputs_seq?=?tf.placeholder(shape=[None,?None],?dtype=tf.int32,?name='outputs_seq')?#?B?*?(S+2)
bert_config?=?bert_modeling.BertConfig.from_json_file("./bert_model/bert_config.json")
bert_model?=?bert_modeling.BertModel(
????config=bert_config,
????is_training=True,
????input_ids=self.inputs_seq,
????input_mask=self.inputs_mask,
????token_type_ids=self.inputs_segment,
????use_one_hot_embeddings=False
)
bert_outputs?=?bert_model.get_sequence_output()?#?B?*?(S+2)?*?D
然后在后面接?xùn)|西就可以了,可以接 LSTM,可以接 CRF
if?not?use_lstm:
????hiddens?=?bert_outputs
else:
????with?tf.variable_scope('bilstm'):
????????cell_fw?=?tf.nn.rnn_cell.LSTMCell(300)
????????cell_bw?=?tf.nn.rnn_cell.LSTMCell(300)
????????((rnn_fw_outputs,?rnn_bw_outputs),?(rnn_fw_final_state,?rnn_bw_final_state))?=?tf.nn.bidirectional_dynamic_rnn(
????????????cell_fw=cell_fw,?
????????????cell_bw=cell_bw,?
????????????inputs=bert_outputs,?
????????????sequence_length=inputs_seq_len,
????????????dtype=tf.float32
????????)
????????rnn_outputs?=?tf.add(rnn_fw_outputs,?rnn_bw_outputs)?#?B?*?(S+2)?*?D
????hiddens?=?rnn_outputs
????
with?tf.variable_scope('projection'):
????logits_seq?=?tf.layers.dense(hiddens,?vocab_size_bio)?#?B?*?(S+2)?*?V
????probs_seq?=?tf.nn.softmax(logits_seq)
????
????if?not?use_crf:
????????preds_seq?=?tf.argmax(probs_seq,?axis=-1,?name="preds_seq")?#?B?*?(S+2)
????else:
????????log_likelihood,?transition_matrix?=?tf.contrib.crf.crf_log_likelihood(logits_seq,?self.outputs_seq,?inputs_seq_len)
????????preds_seq,?crf_scores?=?tf.contrib.crf.crf_decode(logits_seq,?transition_matrix,?inputs_seq_len)
其實(shí)我原來不太相信 BERT 在中文上的效果,加上我比較排斥這種不講道理的龐然大物
真正實(shí)驗(yàn)了發(fā)現(xiàn),BERT確實(shí)強(qiáng)啊
把我顯存都給吃光了,但確實(shí)強(qiáng)啊
訓(xùn)練一輪要那么久,但確實(shí)強(qiáng)啊
講不出任何道理,但確實(shí)強(qiáng)啊

相比較單純使用 BERT,增加了 CRF 后效果有所提高但區(qū)別不大,再增加 BiLSTM 后區(qū)別很小,甚至降低了那么一內(nèi)內(nèi)
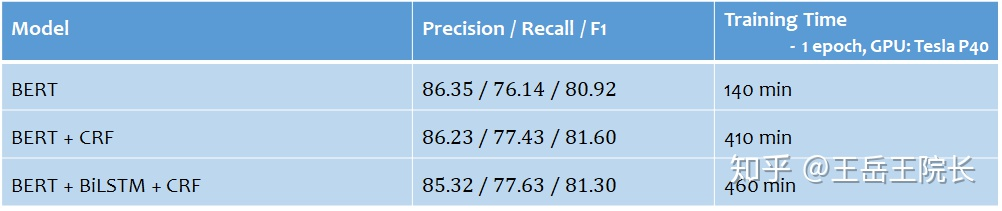
另外,BERT 還有一個(gè)至關(guān)重要的訓(xùn)練技巧,就是調(diào)整學(xué)習(xí)率。BERT內(nèi)的參數(shù)在 fine-tuning 時(shí),學(xué)習(xí)率一定要調(diào)小,特別時(shí)后面還接了別的東西時(shí),一定要按兩個(gè)學(xué)習(xí)率走,甚至需要嘗試多次反復(fù)調(diào),要不然 BERT 很容易就步子邁大了掉溝里爬不上來,個(gè)人經(jīng)驗(yàn)
參數(shù)優(yōu)化時(shí)分兩個(gè)學(xué)習(xí)率,實(shí)現(xiàn)起來就是這樣
with?tf.variable_scope('opt'):
????params_of_bert?=?[]
????params_of_other?=?[]
????for?var?in?tf.trainable_variables():
????????vname?=?var.name
????????if?vname.startswith("bert"):
????????????params_of_bert.append(var)
????????else:
????????????params_of_other.append(var)
????opt1?=?tf.train.AdamOptimizer(1e-4)
????opt2?=?tf.train.AdamOptimizer(1e-3)
????gradients_bert?=?tf.gradients(loss,?params_of_bert)
????gradients_other?=?tf.gradients(loss,?params_of_other)
????gradients_bert_clipped,?norm_bert?=?tf.clip_by_global_norm(gradients_bert,?5.0)
????gradients_other_clipped,?norm_other?=?tf.clip_by_global_norm(gradients_other,?5.0)
????train_op_bert?=?opt1.apply_gradients(zip(gradients_bert_clipped,?params_of_bert))
????train_op_other?=?opt2.apply_gradients(zip(gradients_other_clipped,?params_of_other))
3. Cascade
上面提到過,如果需要考慮實(shí)體類別,那么就需要擴(kuò)展 BIO 的 tag 列表,給每個(gè)“實(shí)體類型”都分配一個(gè) B 與 I 的標(biāo)簽,但是當(dāng)類別數(shù)較多時(shí),標(biāo)簽詞表規(guī)模很大,相當(dāng)于在每個(gè)字上都要做一次類別數(shù)巨多的分類任務(wù),不科學(xué),也會(huì)影響效果
從這個(gè)點(diǎn)出發(fā),就嘗試把 NER 改成一個(gè)多任務(wù)學(xué)習(xí)的框架,兩個(gè)任務(wù),一個(gè)任務(wù)用來單純抽取實(shí)體,一個(gè)任務(wù)用來判斷實(shí)體類型,直接上圖看區(qū)別
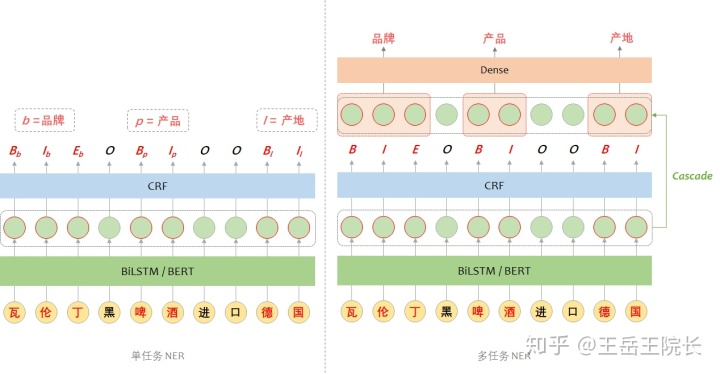
這個(gè)是參考 ACL2020 的一篇論文[2]的思路改的,“Cascade”這個(gè)詞是這個(gè)論文里提出來的。翻譯過來就是“級(jí)聯(lián)”,直觀來講就是“鎖定對(duì)應(yīng)關(guān)系”。結(jié)合模型來說,在第一步得到實(shí)體識(shí)別的結(jié)果之后,返回去到 LSTM 輸出那一層,找各個(gè)實(shí)體詞的表征向量,然后再把實(shí)體的表征向量輸入一層全連接做分類,判斷實(shí)體類型
關(guān)于如何得到實(shí)體整體的表征向量,論文里是把各個(gè)實(shí)體詞的向量做平均,但是我搞了好久也沒明白這個(gè)操作是怎么通過代碼實(shí)現(xiàn)的,后來看了他的源碼,好像只把每個(gè)實(shí)體最開頭和最末尾的兩個(gè)詞做了平均。然后我就更省事,只取了每個(gè)實(shí)體最末尾的一個(gè)詞
具體實(shí)現(xiàn)上這樣寫:在訓(xùn)練時(shí),每個(gè)詞,無論是不是實(shí)體詞,都過一遍全連接,做實(shí)體類型分類計(jì)算 loss,然后把非實(shí)體詞對(duì)應(yīng)的 loss 給 mask 掉;在預(yù)測(cè)時(shí),就取實(shí)體最后一個(gè)詞對(duì)應(yīng)的分類結(jié)果,作為實(shí)體類型。上圖解釋
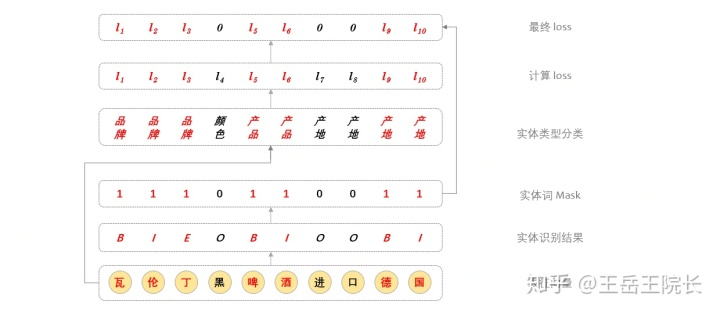
代碼不貼了,感興趣的可以在 git 里看
說一下效果。將單任務(wù) NER 改成多任務(wù) NER 之后,基于 LSTM 的模型效果降低了 0.4%,基于 BERT 的模型提高了 2.7%,整體還是提高更明顯。另外,由于 BIO 詞表得到了縮減,CRF 運(yùn)行時(shí)間以及消耗內(nèi)存迅速減少,訓(xùn)練速度得到提高
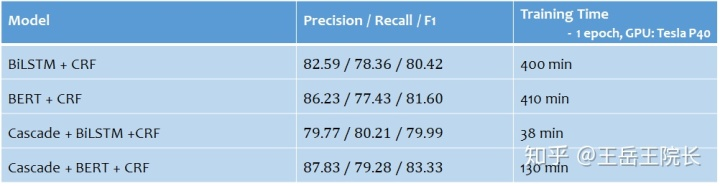
P.S. 另外,既然提到了 NER 中的實(shí)體類型標(biāo)簽較多的問題,就提一下之前看過的一篇文章[3]。這篇論文主要就是為了解決實(shí)體類型標(biāo)簽過多的問題(成千上萬的數(shù)量級(jí))。文中的方法是:把標(biāo)簽作為輸入,也就是把所有可能的實(shí)體類型標(biāo)簽都一個(gè)個(gè)試一遍,根據(jù)輸入的標(biāo)簽不同,模型會(huì)有不同的實(shí)體抽取結(jié)果。文章沒給代碼,我復(fù)現(xiàn)了一下,效果并不好,具體表現(xiàn)就是無論輸入什么標(biāo)簽,模型都傾向于把所有的實(shí)體都抽出來,不管這個(gè)實(shí)體是不是對(duì)應(yīng)這個(gè)實(shí)體類型標(biāo)簽。也可能是我復(fù)現(xiàn)的有問題,不細(xì)講了,就是順便提一句,看有沒有人遇到了和我一樣的情況
?Scaling Up Open Tagging from Tens to Thousands: Comprehension Empowered Attribute Value Extraction from Product Title. ACL 2019
?
4. Word-Level Feature
中文 NER 和英文 NER 有個(gè)比較明顯的區(qū)別,就是英文 NER 是從單詞級(jí)別(word level)來做,而中文 NER 一般是字級(jí)別(character level)來做。不僅是 NER,很多 NLP 任務(wù)也是這樣,BERT 也是這樣
因?yàn)橹形臎]法天然分詞,只能靠分詞工具,分出來的不一定對(duì),比如“黑啤酒精釀”,如果被錯(cuò)誤分詞為“黑啤、酒精、釀”,那么“啤酒”這個(gè)實(shí)體就抽取不到了。類似情況有很多
但是無論字級(jí)別、詞級(jí)別,都是非常貼近文本原始內(nèi)容的特征,蘊(yùn)含了很重要的信息。比如對(duì)于英文來說,給個(gè)單詞“Geilivable”你基本看不懂啥意思,但是看到它以“-able”結(jié)尾,就知道可能不是名詞;對(duì)于中文來說,給個(gè)句子“小龍女說我也想過過過兒過過的生活”就一時(shí)很難找到實(shí)體在哪,但是如果分好詞給你,一眼就能找到了。就這個(gè)理解力來說,模型跟人是一樣的
在英文 NLP 任務(wù)中,想要把字級(jí)別特征加入到詞級(jí)別特征上去,一般是這樣:?jiǎn)为?dú)用一個(gè)BiLSTM 作為 character-level 的編碼器,把單詞的各個(gè)字拆開,送進(jìn) LSTM 得到向量 vc;然后和原本 word-level 的(經(jīng)過 embedding matrix 得到的)的向量 vw 加在一起,就能得到融合兩種特征的表征向量。如圖所示
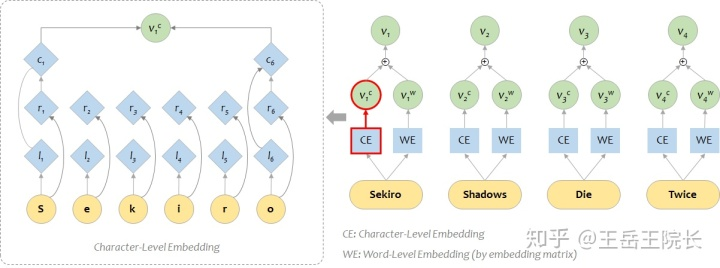
但是對(duì)于中文 NER 任務(wù),我的輸入是字級(jí)別的,怎么把詞級(jí)別的表征結(jié)果加入進(jìn)來呢?
ACL2018 有個(gè)文章[4]是做這個(gè)的,提出了一種 Lattice-LSTM 的結(jié)構(gòu),但是涉及比較底層的改動(dòng),不好實(shí)現(xiàn)。后來在 ACL2020 論文里看到一篇文章[5],簡(jiǎn)單明了。然后我就再簡(jiǎn)化一下,直接把字和詞分別通過 embedding matrix 做表征,按照對(duì)應(yīng)關(guān)系,拼在一起就完事了,看圖就懂
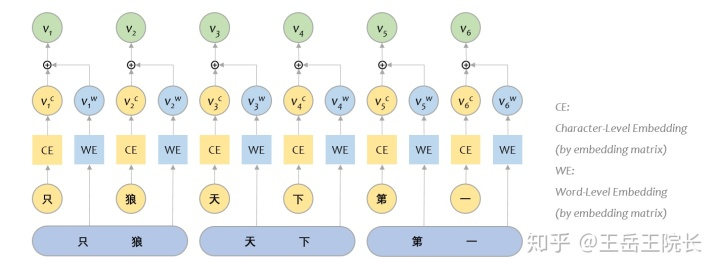
具體代碼就不放了,感興趣可以上 git 看
從結(jié)果上看,增加了詞級(jí)別特征后,提升很明顯

很可惜,我還沒有找到把詞級(jí)別特征結(jié)合到 BERT 中的方法。因?yàn)?BERT 是字級(jí)別預(yù)訓(xùn)練好的模型,如果單純從 embedding 層這么拼接,那后面那些 Transformer 層的參數(shù)就都失效了
上面的論文里也提到了和 BERT 結(jié)合的問題,論文里還是用 LSTM 來做,只是把句子通過 BERT 得到的編碼結(jié)果作為一個(gè)“額外特征”拼接過來。但是我覺得這不算“結(jié)合”,至少不應(yīng)該。但是也非常容易理解為什么論文里要這么做,BERT 當(dāng)?shù)赖哪甏恢v道理,打不過就只能加入,方法不同也得強(qiáng)融,么得辦法

5. Weight of Loss
本來打算到這就結(jié)束了,后來臨時(shí)決定再加一點(diǎn),因?yàn)楦杏X這點(diǎn)應(yīng)該還挺有意思的
大多數(shù) NLP task 的評(píng)價(jià)指標(biāo)有這三個(gè):Precision / Recall / F1Score,Precision 就是找出來的有多少是正確的,Recall 是正確的有多少被找出來了,F(xiàn)1Score是二者的一個(gè)均衡分。這里有三點(diǎn)常識(shí)
方法固定的條件下,一般來說,提高了 Precision 就會(huì)降低 Recall,提高了 Recall 就會(huì)降低 Precision,結(jié)合指標(biāo)定義很好理解
通常來說,F(xiàn)1Score 是最重要的指標(biāo),為了讓 F1Score 最大化,通常需要調(diào)整權(quán)衡 Precision 與 Recall 的大小,讓兩者達(dá)到近似,此時(shí) F1Score 是最大的
但是 F1Score 大,不代表模型就好。因?yàn)榻Y(jié)合工程實(shí)際來說,不同場(chǎng)景不同需求下,對(duì) P/R 會(huì)有不同的要求。有些場(chǎng)景就是要求準(zhǔn),不允許出錯(cuò),所以對(duì) Precision 要求比較高,而有些則相反,不希望有漏網(wǎng)之魚,所以對(duì) Recall 要求高
對(duì)于一個(gè)分類任務(wù),是很容易通過設(shè)置一個(gè)可調(diào)的“閾值”來達(dá)到控制 P/R 的目的的。舉個(gè)例子,判斷一張圖是不是 H 圖,做一個(gè)二分類模型,假設(shè)模型認(rèn)為圖片是 H 圖的概率是 p,人為設(shè)定一個(gè)閾值 a,假如 p>a 則認(rèn)為該圖片是 H 圖。默認(rèn)情況 p=0.5,此時(shí)如果降低 p,就能達(dá)到提高 Recall 降低 Precision 的目的
但是 NER 任務(wù)怎么整呢,他的結(jié)果是一個(gè)完整的序列,你又不能給每個(gè)位置都卡一個(gè)閾值,沒有意義
然后我想了一個(gè)辦法,通過控制模型學(xué)習(xí)時(shí)的 Loss 來控制 P/R:如果模型沒有識(shí)別到一個(gè)本應(yīng)該識(shí)別到的實(shí)體,就增大對(duì)應(yīng)的 Loss,加重對(duì)模型的懲罰;如果模型識(shí)別到了一個(gè)不應(yīng)該識(shí)別到的實(shí)體,就減小對(duì)應(yīng)的 Loss,當(dāng)然是選擇原諒他
實(shí)現(xiàn)上也是通過 mask 來實(shí)現(xiàn),看圖就懂
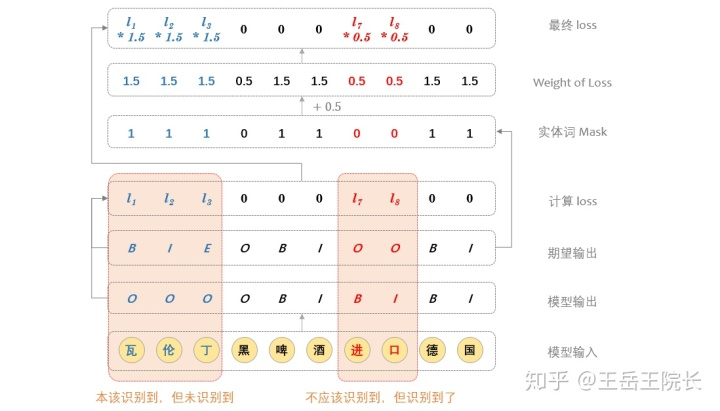
實(shí)現(xiàn)也非常簡(jiǎn)單,放一下對(duì)應(yīng)的代碼
#?logits_bio?是預(yù)測(cè)結(jié)果,形狀為?B*S*V,softmax?之后就是每個(gè)字在BIO詞表上的分布概率,不過不用寫softmax,因?yàn)橄旅娴暮瘮?shù)會(huì)幫你做
#?self.outputs_seq_bio?是期望輸出,形狀為?B*S
#?這是原本計(jì)算出來的?loss
loss_bio?=?tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_bio,?labels=self.outputs_seq_bio)?#?B?*?S
#?這是根據(jù)期望的輸出,獲得?mask?向量,向量里出現(xiàn)1的位置代表對(duì)應(yīng)的字是一個(gè)實(shí)體詞,而?O_tag_index?就是?O?在?BIO?詞表中的位置
masks_of_entity?=?tf.cast(tf.not_equal(self.outputs_seq_bio,?O_tag_index),?tf.float32)?#?B?*?S
#?這是基于?mask?計(jì)算?weights
weights_of_loss?=?masks_of_entity?+?0.5?#?B??*S
#?這是加權(quán)后的?loss
loss_bio?=?loss_bio?*?weights_of_loss?#?B?*?S
從實(shí)驗(yàn)效果來看,原本 Precision 遠(yuǎn)大于 Recall,通過權(quán)衡,把兩個(gè)分?jǐn)?shù)拉到同個(gè)水平,可以提升最終的 F1Score

除此之外,在所有深度學(xué)習(xí)任務(wù)上,都可以通過調(diào)整 Loss 來達(dá)到各種特殊的效果,還是挺有意思的,放飛想象,突破自我
總結(jié)
總結(jié)放在開頭了,就這樣
完結(jié),撒花

「參考」
Bidirectional LSTM-CRF Models for Sequence Tagging A Novel Cascade Binary Tagging Framework for Relational Triple Extraction Scaling Up Open Tagging from Tens to Thousands: Comprehension Empowered Attribute Value Extraction from Product Title Chinese NER Using Lattice LSTM Simplify the Usage of Lexicon in Chinese NER
The End
往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群請(qǐng)掃碼進(jìn)群(如果是博士或者準(zhǔn)備讀博士請(qǐng)說明):