
一文讀懂微內(nèi)核架構(gòu)

什么是微內(nèi)核架構(gòu)?
微內(nèi)核是一種典型的架構(gòu)模式 ,區(qū)別于普通的設(shè)計(jì)模式,架構(gòu)模式是一種高層模式,用于描述系統(tǒng)級的結(jié)構(gòu)組成、相互關(guān)系及相關(guān)約束。微內(nèi)核架構(gòu)在開源框架中的應(yīng)用非常廣泛,比如常見的 ShardingSphere 還有Dubbo都實(shí)現(xiàn)了自己的微內(nèi)核架構(gòu)。那么,在介紹什么是微內(nèi)核架構(gòu)之前,我們有必要先闡述這些開源框架會使用微內(nèi)核架構(gòu)的原因。
為什么要使用微內(nèi)核架構(gòu)?
微內(nèi)核架構(gòu)本質(zhì)上是為了提高系統(tǒng)的擴(kuò)展性 。所謂擴(kuò)展性,是指系統(tǒng)在經(jīng)歷不可避免的變更時(shí)所具有的靈活性,以及針對提供這樣的靈活性所需要付出的成本間的平衡能力。也就是說,當(dāng)在往系統(tǒng)中添加新業(yè)務(wù)時(shí),不需要改變原有的各個(gè)組件,只需把新業(yè)務(wù)封閉在一個(gè)新的組件中就能完成整體業(yè)務(wù)的升級,我們認(rèn)為這樣的系統(tǒng)具有較好的可擴(kuò)展性。
就架構(gòu)設(shè)計(jì)而言,擴(kuò)展性是軟件設(shè)計(jì)的永恒話題。而要實(shí)現(xiàn)系統(tǒng)擴(kuò)展性,一種思路是提供可插拔式的機(jī)制來應(yīng)對所發(fā)生的變化。當(dāng)系統(tǒng)中現(xiàn)有的某個(gè)組件不滿足要求時(shí),我們可以實(shí)現(xiàn)一個(gè)新的組件來替換它,而整個(gè)過程對于系統(tǒng)的運(yùn)行而言應(yīng)該是無感知的,我們也可以根據(jù)需要隨時(shí)完成這種新舊組件的替換。
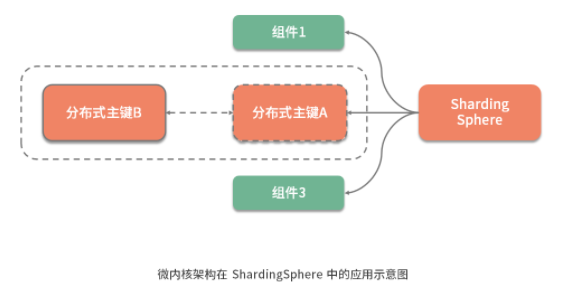
比如在 ShardingSphere 中提供的分布式主鍵功能,分布式主鍵的實(shí)現(xiàn)可能有很多種,而擴(kuò)展性在這個(gè)點(diǎn)上的體現(xiàn)就是, 我們可以使用任意一種新的分布式主鍵實(shí)現(xiàn)來替換原有的實(shí)現(xiàn),而不需要依賴分布式主鍵的業(yè)務(wù)代碼做任何的改變 。
微內(nèi)核架構(gòu)模式為這種實(shí)現(xiàn)擴(kuò)展性的思路提供了架構(gòu)設(shè)計(jì)上的支持,ShardingSphere 基于微內(nèi)核架構(gòu)實(shí)現(xiàn)了高度的擴(kuò)展性。在介紹如何實(shí)現(xiàn)微內(nèi)核架構(gòu)之前,我們先對微內(nèi)核架構(gòu)的具體組成結(jié)構(gòu)和基本原理做簡要的闡述。
什么是微內(nèi)核架構(gòu)?
從組成結(jié)構(gòu)上講, 微內(nèi)核架構(gòu)包含兩部分組件:內(nèi)核系統(tǒng)和插件 。這里的內(nèi)核系統(tǒng)通常提供系統(tǒng)運(yùn)行所需的最小功能集,而插件是獨(dú)立的組件,包含自定義的各種業(yè)務(wù)代碼,用來向內(nèi)核系統(tǒng)增強(qiáng)或擴(kuò)展額外的業(yè)務(wù)能力。在 ShardingSphere 中,前面提到的分布式主鍵就是插件,而 ShardingSphere 的運(yùn)行時(shí)環(huán)境構(gòu)成了內(nèi)核系統(tǒng)。
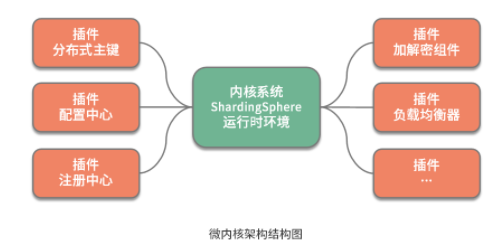
那么這里的插件具體指的是什么呢?這就需要我們明確兩個(gè)概念,一個(gè)概念就是經(jīng)常在說的 API ,這是系統(tǒng)對外暴露的接口。而另一個(gè)概念就是 SPI(Service Provider Interface,服務(wù)提供接口),這是插件自身所具備的擴(kuò)展點(diǎn)。就兩者的關(guān)系而言,API 面向業(yè)務(wù)開發(fā)人員,而 SPI 面向框架開發(fā)人員,兩者共同構(gòu)成了 ShardingSphere 本身。
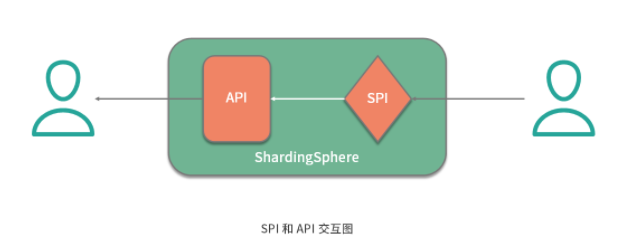
可插拔式的實(shí)現(xiàn)機(jī)制說起來簡單,做起來卻不容易,我們需要考慮兩方面內(nèi)容。一方面,我們需要梳理系統(tǒng)的變化并把它們抽象成多個(gè) SPI 擴(kuò)展點(diǎn)。另一方面, 當(dāng)我們實(shí)現(xiàn)了這些 SPI 擴(kuò)展點(diǎn)之后,就需要構(gòu)建一個(gè)能夠支持這種可插拔機(jī)制的具體實(shí)現(xiàn),從而提供一種 SPI 運(yùn)行時(shí)環(huán)境 。
如何實(shí)現(xiàn)微內(nèi)核架構(gòu)?
事實(shí)上,JDK 已經(jīng)為我們提供了一種微內(nèi)核架構(gòu)的實(shí)現(xiàn)方式,就是JDK SPI。這種實(shí)現(xiàn)方式針對如何設(shè)計(jì)和實(shí)現(xiàn) SPI 提出了一些開發(fā)和配置上的規(guī)范,ShardingSphere、Dubbo 使用的就是這種規(guī)范,只不過在這基礎(chǔ)上進(jìn)行了增強(qiáng)和優(yōu)化。所以要理解如何實(shí)現(xiàn)微內(nèi)核架構(gòu),我們不妨先看看JDK SPI 的工作原理。
JDK SPI
SPI(Service Provider Interface)主要是被框架開發(fā)人員使用的一種技術(shù)。例如,使用 Java 語言訪問數(shù)據(jù)庫時(shí)我們會使用到 java.sql.Driver 接口,不同數(shù)據(jù)庫產(chǎn)品底層的協(xié)議不同,提供的 java.sql.Driver 實(shí)現(xiàn)也不同,在開發(fā) java.sql.Driver 接口時(shí),開發(fā)人員并不清楚用戶最終會使用哪個(gè)數(shù)據(jù)庫,在這種情況下就可以使用 Java SPI 機(jī)制在實(shí)際運(yùn)行過程中,為 java.sql.Driver 接口尋找具體的實(shí)現(xiàn)。
下面我們通過一個(gè)簡單的示例演示一下JDK SPI的使用方式:
首先我們定義一個(gè)生成id鍵的接口,用來模擬id生成
public interface IdGenerator {
/**
* 生成id
* @return
*/
String generateId();
}
然后創(chuàng)建兩個(gè)接口實(shí)現(xiàn)類,分別用來模擬uuid和序列id的生成
public class UuidGenerator implements IdGenerator {
@Override
public String generateId() {
return UUID.randomUUID().toString();
}
}
public class SequenceIdGenerator implements IdGenerator {
private final AtomicLong atomicId = new AtomicLong(100L);
@Override
public String generateId() {
long leastId = this.atomicId.incrementAndGet();
return String.valueOf(leastId);
}
}
在項(xiàng)目的 resources/META-INF/services目錄下添加一個(gè)名為com.github.jianzh5.spi.IdGenerator的文件,這是 JDK SPI 需要讀取的配置文件,內(nèi)容如下:
com.github.jianzh5.spi.impl.UuidGenerator
com.github.jianzh5.spi.impl.SequenceIdGenerator
創(chuàng)建main方法,讓其加載上述的配置文件,創(chuàng)建全部IdGenerator 接口實(shí)現(xiàn)的實(shí)例,并執(zhí)行生成id的方法。
public class GeneratorMain {
public static void main(String[] args) {
ServiceLoader<IdGenerator> serviceLoader = ServiceLoader.load(IdGenerator.class);
Iterator<IdGenerator> iterator = serviceLoader.iterator();
while(iterator.hasNext()){
IdGenerator generator = iterator.next();
String id = generator.generateId();
System.out.println(generator.getClass().getName() + " >>id:" + id);
}
}
}
執(zhí)行結(jié)果如下: 
JDK SPI 源碼分析
通過上述示例,我們可以看到 JDK SPI 的入口方法是 ServiceLoader.load() 方法,在這個(gè)方法中首先會嘗試獲取當(dāng)前使用的 ClassLoader,然后調(diào)用 reload() 方法,調(diào)用關(guān)系如下圖所示:

在 reload() 方法中,首先會清理 providers 緩存(LinkedHashMap 類型的集合),該緩存用來記錄 ServiceLoader 創(chuàng)建的實(shí)現(xiàn)對象,其中 Key 為實(shí)現(xiàn)類的完整類名,Value 為實(shí)現(xiàn)類的對象。之后創(chuàng)建 LazyIterator 迭代器,用于讀取 SPI 配置文件并實(shí)例化實(shí)現(xiàn)類對象。
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
在前面的示例中,main() 方法中使用的迭代器底層就是調(diào)用了 ServiceLoader.LazyIterator 實(shí)現(xiàn)的。Iterator 接口有兩個(gè)關(guān)鍵方法:hasNext() 方法和 next() 方法。這里的 LazyIterator 中的 next() 方法最終調(diào)用的是其 nextService() 方法,hasNext() 方法最終調(diào)用的是 hasNextService() 方法,我們來看看 hasNextService()方法的具體實(shí)現(xiàn):
private static final String PREFIX = "META-INF/services/";
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
//META-INF/services/com.github.jianzh5.spi.IdGenerator
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
// 按行SPI遍歷配置文件的內(nèi)容
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析配置文件
pending = parse(service, configs.nextElement());
}
// 更新 nextName字段
nextName = pending.next();
return true;
}
在 hasNextService() 方法中完成 SPI 配置文件的解析之后,再來看 LazyIterator.nextService() 方法,該方法「負(fù)責(zé)實(shí)例化 hasNextService() 方法讀取到的實(shí)現(xiàn)類」,其中會將實(shí)例化的對象放到 providers 集合中緩存起來,核心實(shí)現(xiàn)如下所示:
private S nextService() {
String cn = nextName;
nextName = null;
// 加載 nextName字段指定的類
Class<?> c = Class.forName(cn, false, loader);
if (!service.isAssignableFrom(c)) { // 檢測類型
fail(service, "Provider " + cn + " not a subtype");
}
S p = service.cast(c.newInstance()); // 創(chuàng)建實(shí)現(xiàn)類的對象
providers.put(cn, p); // 將實(shí)現(xiàn)類名稱以及相應(yīng)實(shí)例對象添加到緩存
return p;
}
以上就是在 main() 方法中使用的迭代器的底層實(shí)現(xiàn)。最后,我們再來看一下 main() 方法中使用 ServiceLoader.iterator() 方法拿到的迭代器是如何實(shí)現(xiàn)的,這個(gè)迭代器是依賴 LazyIterator 實(shí)現(xiàn)的一個(gè)匿名內(nèi)部類,核心實(shí)現(xiàn)如下:
public Iterator<S> iterator() {
return new Iterator<S>() {
// knownProviders用來迭代providers緩存
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
// 先走查詢緩存,緩存查詢失敗,再通過LazyIterator加載
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
// 先走查詢緩存,緩存查詢失敗,再通過 LazyIterator加載
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
// 省略remove()方法
};
}
JDK SPI 在 JDBC 中的應(yīng)用
了解了 JDK SPI 實(shí)現(xiàn)的原理之后,我們再來看實(shí)踐中 JDBC 是如何使用 JDK SPI 機(jī)制加載不同數(shù)據(jù)庫廠商的實(shí)現(xiàn)類。
JDK 中只定義了一個(gè) java.sql.Driver 接口,具體的實(shí)現(xiàn)是由不同數(shù)據(jù)庫廠商來提供的。這里我們就以 MySQL 提供的 JDBC 實(shí)現(xiàn)包為例進(jìn)行分析。
在 mysql-connector-java-*.jar 包中的 META-INF/services 目錄下,有一個(gè) java.sql.Driver 文件中只有一行內(nèi)容,如下所示:
com.mysql.cj.jdbc.Driver
在使用 mysql-connector-java-*.jar 包連接 MySQL 數(shù)據(jù)庫的時(shí)候,我們會用到如下語句創(chuàng)建數(shù)據(jù)庫連接:
String url = "jdbc:xxx://xxx:xxx/xxx";
Connection conn = DriverManager.getConnection(url, username, pwd);
「DriverManager 是 JDK 提供的數(shù)據(jù)庫驅(qū)動管理器」,其中的代碼片段,如下所示:
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
在調(diào)用 getConnection() 方法的時(shí)候,DriverManager 類會被 Java 虛擬機(jī)加載、解析并觸發(fā) static 代碼塊的執(zhí)行;在 loadInitialDrivers()方法中通過 JDK SPI 掃描 Classpath 下 java.sql.Driver 接口實(shí)現(xiàn)類并實(shí)例化,核心實(shí)現(xiàn)如下所示:
private static void loadInitialDrivers() {
String drivers = System.getProperty("jdbc.drivers")
// 使用 JDK SPI機(jī)制加載所有 java.sql.Driver實(shí)現(xiàn)類
ServiceLoader<Driver> loadedDrivers =
ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
while(driversIterator.hasNext()) {
driversIterator.next();
}
String[] driversList = drivers.split(":");
for (String aDriver : driversList) { // 初始化Driver實(shí)現(xiàn)類
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
}
}
在 MySQL 提供的 com.mysql.cj.jdbc.Driver 實(shí)現(xiàn)類中,同樣有一段 static 靜態(tài)代碼塊,這段代碼會創(chuàng)建一個(gè) com.mysql.cj.jdbc.Driver 對象并注冊到 DriverManager.registeredDrivers 集合中(CopyOnWriteArrayList 類型),如下所示:
static {
java.sql.DriverManager.registerDriver(new Driver());
}
在 getConnection() 方法中,DriverManager 從該 registeredDrivers 集合中獲取對應(yīng)的 Driver 對象創(chuàng)建 Connection,核心實(shí)現(xiàn)如下所示:
private static Connection getConnection(String url, java.util.Properties info, Class<?> caller) throws SQLException {
// 省略 try/catch代碼塊以及權(quán)限處理邏輯
for(DriverInfo aDriver : registeredDrivers) {
Connection con = aDriver.driver.connect(url, info);
return con;
}
}
小結(jié)
本文我們詳細(xì)講述了微內(nèi)核架構(gòu)的一些基本概念并通過一個(gè)示例入手,介紹了 JDK 提供的 SPI 機(jī)制的基本使用,然后深入分析了 JDK SPI 的核心原理和底層實(shí)現(xiàn),對其源碼進(jìn)行了深入剖析,最后我們以 MySQL 提供的 JDBC 實(shí)現(xiàn)為例,分析了 JDK SPI 在實(shí)踐中的使用方式。
掌握了JDK的SPI機(jī)制就等于掌握了微內(nèi)核架構(gòu)的核心,以上,希望對你有所幫助!
SpringBoot開發(fā)秘籍 - 集成Graphql Query
Linux 文件搜索神器 find 實(shí)戰(zhàn)詳解,建議收藏!
搞清楚這 10 幾個(gè)后端面試問題,工作穩(wěn)了!
歡迎關(guān)注微信公眾號:互聯(lián)網(wǎng)全棧架構(gòu),收取更多有價(jià)值的信息。