
一文讀懂|內(nèi)核順序鎖
Linux 內(nèi)核有非常多的鎖機(jī)制,如:自旋鎖、讀寫鎖、信號(hào)量和 RCU 鎖等。本文介紹一種和讀寫鎖比較相似的鎖機(jī)制:順序鎖(seqlock)。
順序鎖與讀寫鎖一樣,都是針對(duì)多讀少寫且快速處理的鎖機(jī)制。而順序鎖和讀寫鎖的區(qū)別就在于:讀寫鎖的讀鎖會(huì)阻塞寫鎖,而順序鎖的讀鎖不會(huì)阻塞寫鎖。
讀鎖原理
為了讓讀鎖不阻塞寫鎖,讀鎖并不會(huì)真正進(jìn)行上鎖操作。那么讀鎖是如何避免在讀取臨界區(qū)數(shù)據(jù)時(shí),數(shù)據(jù)被其他進(jìn)程修改了?
為了解決這個(gè)問題,順序鎖使用了一種類似于版本號(hào)的機(jī)制:序號(hào)。序號(hào)是一個(gè)只增不減的計(jì)數(shù)器,可以從順序鎖對(duì)象的定義看出,如下代碼所示:
typedef struct {
struct seqcount seqcount; // 序號(hào)
spinlock_t lock; // 自旋鎖,寫鎖上鎖時(shí)使用
} seqlock_t;
在讀取臨界區(qū)數(shù)據(jù)前,首先需要調(diào)用 read_seqbegin() 函數(shù)來獲取讀鎖,read_seqbegin() 函數(shù)的核心邏輯是讀取順序鎖的序號(hào)。代碼如下所示:
static inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret;
repeat:
// 讀取順序鎖的序號(hào)
ret = sl->sequence;
// 如果序號(hào)是單數(shù),需要重新獲取
if (unlikely(ret & 1)) {
...
goto repeat;
}
...
return ret;
}
從上面的代碼可以看出,read_seqbegin() 函數(shù)只獲取順序鎖的序號(hào),并不會(huì)進(jìn)行上鎖操作,所以讀鎖并不會(huì)阻塞寫鎖。
注意:序號(hào)是單數(shù)時(shí)需要重新獲取的原因,會(huì)在分析寫鎖實(shí)現(xiàn)原理時(shí)說明。
既然讀鎖并不會(huì)進(jìn)行上鎖操作,如果在讀取臨界區(qū)數(shù)據(jù)時(shí),數(shù)據(jù)被修改了怎么辦呢?答案就是:在退出臨界區(qū)時(shí),比較一下當(dāng)前順序鎖的序號(hào)跟之前讀取的序號(hào)是否一致。如果一致表示數(shù)據(jù)沒有被修改,否則說明數(shù)據(jù)已經(jīng)被修改。如果數(shù)據(jù)被修改了,那么需要重新讀取臨界區(qū)的數(shù)據(jù)。
比較序號(hào)是否一致可以使用 read_seqretry() 函數(shù),所以讀鎖的正確用法如下代碼所示:
do {
// 獲取順序鎖序號(hào)
unsigned seq = read_seqbegin(&seqlock);
// 讀取臨界區(qū)數(shù)據(jù)
...
} while (read_seqretry(&seqlock, seq)); // 對(duì)比序號(hào)是否一致?
read_seqretry() 函數(shù)的實(shí)現(xiàn)非常簡單,如下所示:
static inline unsigned
read_seqretry(const seqlock_t *sl, unsigned start)
{
...
return sl->sequence != start;
}
從上面代碼可以看出,read_seqretry() 函數(shù)只是簡單比較當(dāng)前序號(hào)與之前讀取到的序號(hào)是否一致。
寫鎖原理
從上面的分析可知,讀鎖是通過對(duì)比前后序號(hào)是否一致來判斷數(shù)據(jù)是否被修改的。那么序號(hào)在什么時(shí)候被修改呢?答案就是:獲取寫鎖時(shí)。
獲取寫鎖是通過 write_seqlock() 函數(shù)來實(shí)現(xiàn)的,其實(shí)現(xiàn)也比較簡單,代碼如下所示:
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
sl->sequence++;
...
}
write_seqlock() 函數(shù)首先會(huì)獲取自旋鎖(所以寫鎖與寫鎖之間是互斥的),然后對(duì)序號(hào)進(jìn)行加一操作。所以,在修改臨界區(qū)數(shù)據(jù)前,寫鎖先會(huì)增加序號(hào)的值,這樣就會(huì)導(dǎo)致讀鎖前后兩次獲取的序號(hào)不一致。我們可以用下圖來說明這種情況:
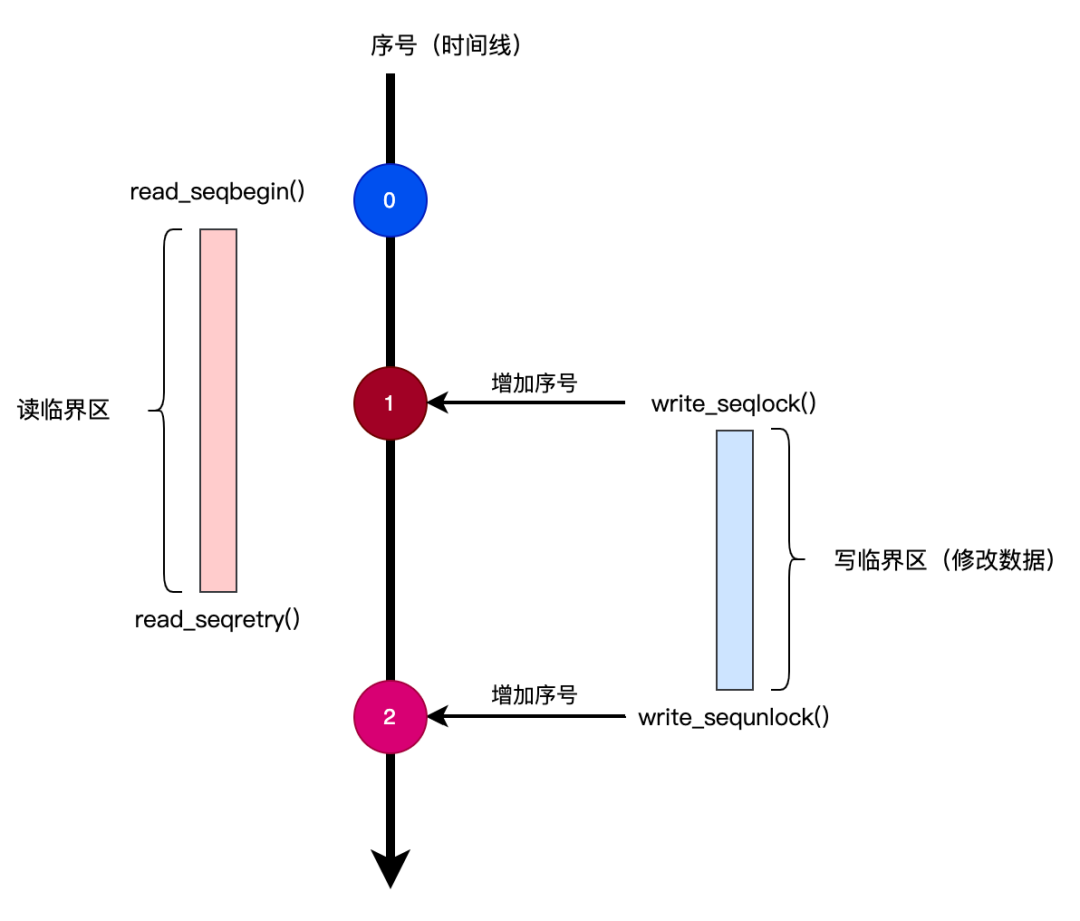 seqlock原理
seqlock原理
可以看出,當(dāng)在讀臨界區(qū)前后獲取的序號(hào)值不一致時(shí),就表示數(shù)據(jù)已經(jīng)被修改,這時(shí)就需要重新讀取被修改后的數(shù)據(jù)。
寫鎖解鎖也很簡單,代碼如下:
static inline void write_sequnlock(seqlock_t *sl)
{
...
s->sequence++;
spin_unlock(&sl->lock);
}
解鎖也需要對(duì)序號(hào)進(jìn)行加一操作,然后釋放自旋鎖。
由于 write_seqlock() 函數(shù)與 write_sequnlock() 函數(shù)都會(huì)對(duì)序號(hào)進(jìn)行加一操作,所以解鎖后,序號(hào)的值必定為雙數(shù)。
我們在分析讀鎖時(shí)看到,如果序號(hào)是單數(shù)時(shí)會(huì)重新獲取序號(hào),直到序號(hào)為雙數(shù)為止。這是因?yàn)樾蛱?hào)單數(shù)時(shí),表示正在更新數(shù)據(jù)。此時(shí)讀取臨界區(qū)的值是沒有意義的,所以需要等到更新完畢再讀取。