6種讓Python程序變慢的壞習慣

大數(shù)據(jù)文摘授權轉(zhuǎn)載自數(shù)據(jù)派THU
作者: Christopher Tao
翻譯:王可汗
校對:王雨桐
隨著Python的流行,用戶數(shù)量也在增加。Python確實相對容易上手,也非常靈活,因此有更多可能的方式來實現(xiàn)一個函數(shù)。
當有多種方法可以實現(xiàn)一件特定的事情時,這意味著每種方法都有優(yōu)缺點。在本文中,我收集了6種編寫Python代碼的典型方法,這些方法可能導致相對較差的性能。
不導入根模塊
在使用Python時,我們無法避免的一件事就是導入模塊,無論是內(nèi)置模塊還是第三方模塊。有時我們可能只需要其中的一個或幾個函數(shù)或?qū)ο蟆T谶@種情況下,我們應該只導入需要的函數(shù)或?qū)ο螅皇菍敫K。
這里有一個簡單的例子。假設我們需要在程序中計算一些數(shù)字的平方根。
低效率示范:
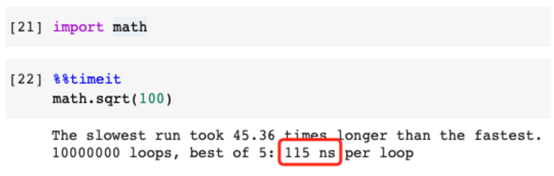
在這個錯誤的示例中,我們導入了math模塊,并使用math.sqrt()訪問該函數(shù)。當然它可以運行,但是如果我們直接導入sqrt()函數(shù),性能會更好。
高效率示范:
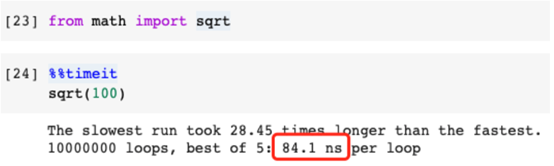
這比原來的快了25%。此外如果我們需要在程序中多次使用平方根函數(shù),代碼將會更整潔。
避免使用點/點鏈接
在Python中訪問對象的屬性或函數(shù)時,使用.是非常直觀的。這種方法大多數(shù)時候都沒有問題。然而如果我們能夠避免使用點或點鏈接,那么性能便會變得更好。
低效率例子:
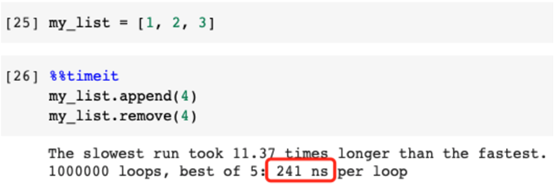
高效率例子:
如果你不相信它能起到同樣的作用,我們可以驗證一下。

注意:我可以預料到許多Python開發(fā)人員會跳出來說,這個例子中的技術有點可笑。事實上即使是我自己,也很少像上面那樣寫代碼。然而我們應該知道怎樣的代碼是更高效的,可以使實現(xiàn)更快。
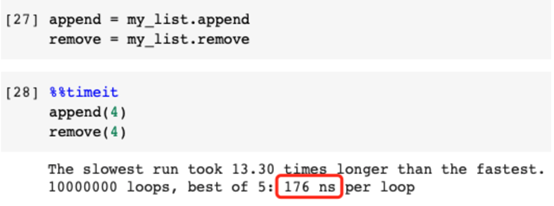
如果我們想要添加列表并從列表中移除項目,我們應該考慮使用這個技巧。這就是為什么我們需要平衡代碼的性能和可讀性。
不使用+連接字符串
字符串在Python中是不可變的。因此當我們使用“+”將多個字符串連接成一個長字符串時,每個子字符串都是單獨操作的。
低效率例子:
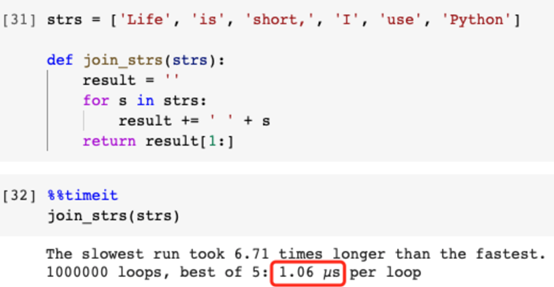
具體來說,對于每個子字符串,它需要請求一個內(nèi)存地址,然后將它與該內(nèi)存地址中的原始字符串連接起來。這就產(chǎn)生了一種開銷。
高效率例子:
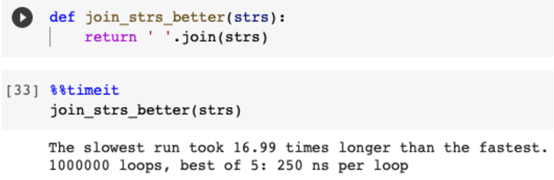
然而當我們使用join()函數(shù)時,該函數(shù)事先知道所有子字符串,并根據(jù)最終的字符串長度分配內(nèi)存地址。因此省去了為每個子字符串分配內(nèi)存的開銷。
注意點:強烈建議盡可能多地使用join()函數(shù)。然而,有時我們可能只想連接兩個字符串。或者只是為了方便起見,我們想使用“+”。在這些情況下,使用“+”號可以獲得更好的可讀性和更短的代碼長度。
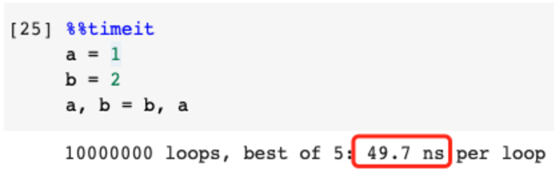
不使用臨時變量進行值交換
許多算法需要兩個變量的值交換。在大多數(shù)其他編程語言中,通常要引入一個臨時變量來實現(xiàn),如下所示。
低效率示范:
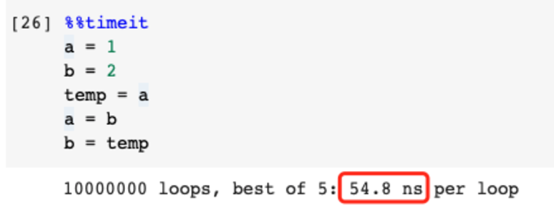
很明顯我們需要一個臨時變量作為過渡。當變量b的值被傳遞給變量a時,它用于保存變量a的值,然后a的值可以被賦給變量b。
高效率示范:
然而在Python中,我們不需要使用臨時變量。Python有如下內(nèi)置語法來實現(xiàn)這個值交換。這不僅提升了效率,而且使代碼更加整潔。
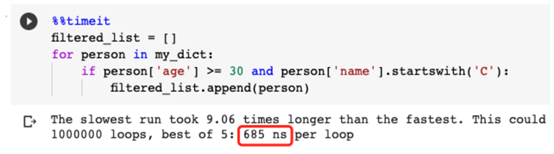
在if條件下使用短路邏輯(short-circuit)
短路計算在許多編程語言中都存在,Python也是如此。它指的是一些布爾運算符的計算邏輯,只有在第一個參數(shù)不足以確定整個表達式的值時,才執(zhí)行或計算第二個參數(shù)。讓我們用一個例子來演示。假設我們有如下列表。
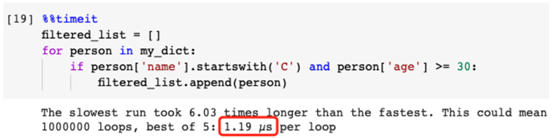
my_dict = [ { 'name': 'Alice', 'age': 28 }, { 'name': 'Bob', 'age': 23 }, { 'name': 'Chris', 'age': 33 }, { 'name': 'Chelsea', 'age': 2 }, { 'name': 'Carol', 'age': 24 }]我們的工作是篩選名單,找出姓名以“C”開頭、年齡在30歲以上的所有人。
低效率示范:
有兩個條件都需要滿足:
名字以“C”開頭 年齡≥30歲
原文標題:
Six Bad Manners that Make YourPython Program Slower
原文鏈接:
https://towardsdatascience.com/6-bad-manners-makes-your-python-program-slower-15b6fce62927