
深度學(xué)習(xí)結(jié)合樹(shù)搜索求解集裝箱預(yù)翻箱問(wèn)題
論文閱讀筆記,個(gè)人理解,如有錯(cuò)誤請(qǐng)指正,感激不盡!該文分類到Machine learning alongside optimization algorithms。
01 container pre-marshalling problem (CPMP)
對(duì)集裝箱進(jìn)行預(yù)翻箱整理,使得集裝箱的堆放順序符合取箱順序,以盡量減少取箱裝船過(guò)程中的翻箱次數(shù)。如下圖所示,出箱順序?yàn)?234……6,灰色的集裝箱2、4、5擋住了先要出來(lái)的集裝箱1、3,因此需要不斷移動(dòng)灰色的集裝箱到別處去,直到不擋住別的箱子。這樣1可以順利先出,而后是2,接著是3……目標(biāo)是最小化移動(dòng)集裝箱的次數(shù)。

02 tree search中的DNN
樹(shù)搜索大家不會(huì)陌生,深度優(yōu)先、廣度優(yōu)先、分支定界等都屬于樹(shù)搜索策略。將Deep learning集成進(jìn)tree search中,用于求解CPMP。利用深度神經(jīng)網(wǎng)絡(luò)(classification DNN)在分支選擇上進(jìn)行預(yù)測(cè),給出分支的“好壞”,隨后按照分支的“好壞”(好的分支得到最優(yōu)解的可能性更大)繼續(xù)搜索。同時(shí),利用深度神經(jīng)網(wǎng)絡(luò)(regression DNN)對(duì)分支節(jié)點(diǎn)的lower bound進(jìn)行預(yù)測(cè),剪掉不必要的分支。
下圖解釋了搜索過(guò)程中的分支選擇決策,以c節(jié)點(diǎn)為例,通過(guò)將c節(jié)點(diǎn)表示的問(wèn)題和解信息輸入到DNN中,經(jīng)過(guò)隱藏層,在輸出層通過(guò)一個(gè)softmax函數(shù)給出三個(gè)child節(jié)點(diǎn)e、f、g的概率(搜索該分支最終得到最優(yōu)解的概率)。
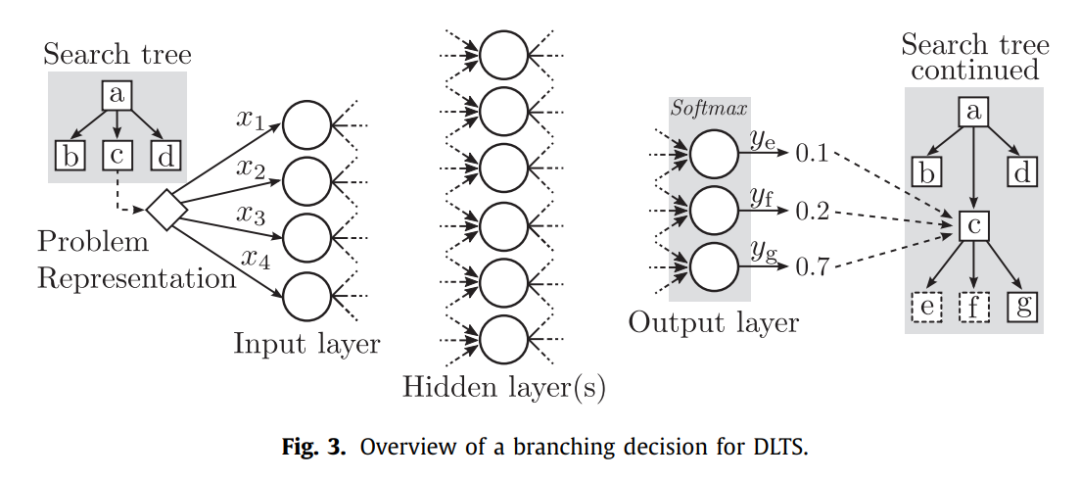
通過(guò)DNN預(yù)測(cè)該節(jié)點(diǎn)的lower bound也是類似的,只不過(guò)該網(wǎng)絡(luò)的輸出只有一個(gè)數(shù)值,即當(dāng)前節(jié)點(diǎn)的得到完整solution的cost(有可能overestimate或者underestimate)。
下圖展示了預(yù)測(cè)分支(classification DNN)的具體網(wǎng)絡(luò)形態(tài)。該神經(jīng)網(wǎng)絡(luò)依賴于算例的size,假如訓(xùn)練的算例size為n,那么只能預(yù)測(cè)size為n以及小于n的算例(通過(guò)設(shè)置虛擬點(diǎn))。每一個(gè)集裝箱位都是一個(gè)節(jié)點(diǎn),從而構(gòu)成了DNN的輸入層。在輸入層之后通過(guò)weight sharing,給每一個(gè)tier分配一個(gè)權(quán)重,。這樣就給每一個(gè)container分配了權(quán)重,比如第3層的container,對(duì)應(yīng)的權(quán)重就是。最終輸出層輸出每一個(gè)movement的概率,比如表示的將stack 2上的container移動(dòng)到stack 3上。
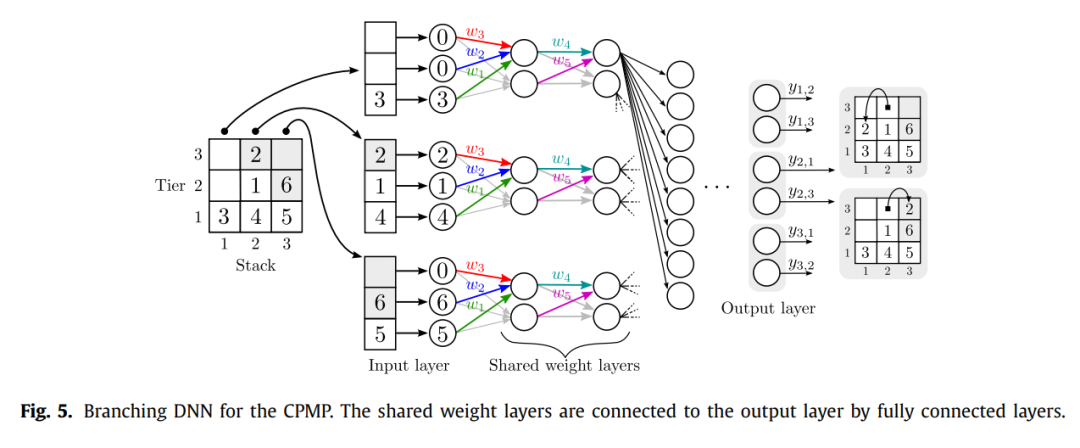
關(guān)于模型訓(xùn)練,樣本通過(guò)精確算法求解獲得,無(wú)法精確獲得的,則是通過(guò)啟發(fā)式算法獲得近似解。
03 搜索策略
將上面的DNN應(yīng)用到tree search中,搜索策略有好幾種,作者實(shí)現(xiàn)了三種結(jié)合DNN的樹(shù)搜索策略:Depth first search、Limited discrepancy search和Weighted beam search。前兩個(gè)的框架如下:

DNN在這些搜索框架中起到的作用主要有:
預(yù)測(cè)各個(gè)分支得到最優(yōu)解的概率,令框架優(yōu)先搜索概率高的支路。 預(yù)測(cè)節(jié)點(diǎn)的lower bound,從而進(jìn)行必要的剪枝。不過(guò)預(yù)測(cè)lower bound是搜索樹(shù)深度為k的倍數(shù)才會(huì)執(zhí)行一次,因?yàn)槿繄?zhí)行需要消耗大量的時(shí)間。
04 實(shí)驗(yàn)結(jié)果
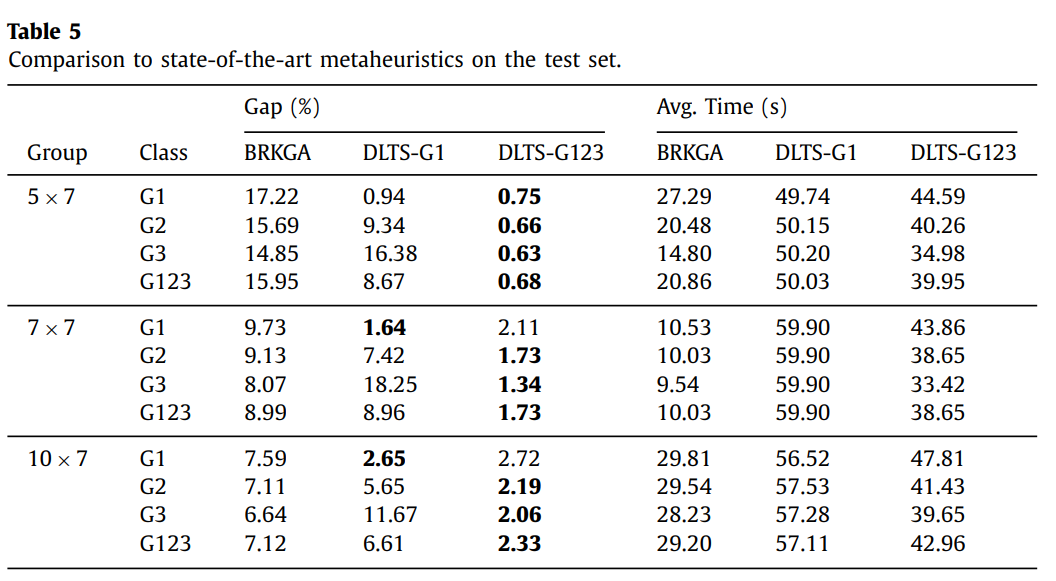
通過(guò)和目前最好的啟發(fā)式算法(BRKGA)進(jìn)行對(duì)比,通過(guò)數(shù)據(jù)集G1訓(xùn)練的模型為DLTS-G1,通過(guò)數(shù)據(jù)集G123訓(xùn)練的模型為DLTS-G123。Gap(%)表示和最優(yōu)解的對(duì)比。從下表可以看出,雖然BRKGA有著更快的求解速度,時(shí)間大概是DLTS的一半,但是得到的Gap卻是DLTS的3到23倍不等。
05 參考文獻(xiàn)
[1] Hottung A , Tanaka S , Tierney K . Deep Learning Assisted Heuristic Tree Search for the Container Pre-marshalling Problem[J]. Computers & Operations Research, 2019.