HashMap還有ConcurrentHashMap我跟你拼了(第一章)
小故事
????????最近面試流行ConcurrentHashMap,還有這個HashMap為啥線程不安全。我直接說的,如果兩個線程同時操作HashMap的話,如果大家都進(jìn)行一個get操作,再put操作,那么就會導(dǎo)致1號線程get操作完成,put操作之前,2號線程get了舊的值,然后1號線程更新之后的值并沒有被2號線程取到,導(dǎo)致兩次操作的效果變成了一次操作的效果。例如,get一個數(shù)值,進(jìn)行+1操作,結(jié)果兩個線程過去,發(fā)現(xiàn)加了1,并沒有+2。
????????顯然,我已經(jīng)回答錯了,面試官直接說,這是你業(yè)務(wù)上的問題,和人家HashMap沒有關(guān)系。這是你業(yè)務(wù)上沒有控制get和put的原子性導(dǎo)致的。我徹底懵了,我果然是個渣渣。
????????本來想總結(jié)完的,奈何沒有足夠的時間了,明天還有事情,我們下一章接著完善。
????
面試流程
????????能當(dāng)?shù)昧嗣嬖嚬伲且欢ㄊ莻€久經(jīng)沙場的渣男,他并不會像鋼鐵直男那樣直奔主題,而是會由淺入深,緩緩地套路你,直到你進(jìn)入他設(shè)計(jì)好的陷阱之中。所以一般的面試流程都是這樣開始的。
小伙子你了解數(shù)據(jù)結(jié)構(gòu)中的HashMap么?聊聊他的數(shù)據(jù)結(jié)構(gòu)和底層原理?
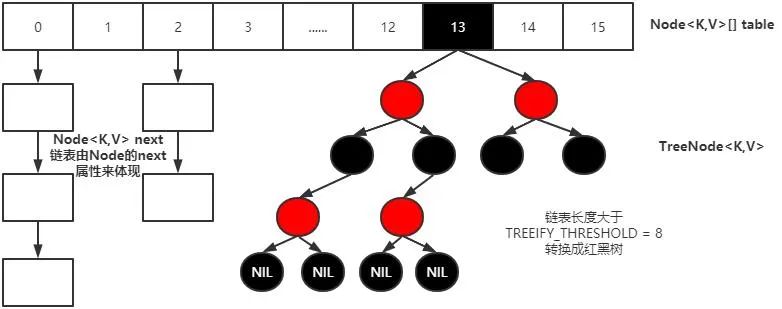
??????? HashMap,這個我知道,我很了解他,不就是個數(shù)組+鏈表嗎。數(shù)組用來散列,鏈表用來解決哈希碰撞。就這么簡單嗎,是不是,完事。哦對了,在JDK1.8的時候,當(dāng)鏈表過長同時數(shù)組容量大于64閾值(最小樹化容量)的時候,鏈表會轉(zhuǎn)變?yōu)榧t黑樹。呵呵,64這個點(diǎn)也被我答出來了,這下沒話說了吧。
那你給我說下鏈表過長是什么意思?
????????就是鏈表長度大于等于8的時候,他就會進(jìn)行樹化,但是一定要注意此時哈希數(shù)組的容量不能小于最小樹化容量64,否則他會再次進(jìn)行擴(kuò)容來分散節(jié)點(diǎn),而不是進(jìn)行樹化。
那你給我說下為什么這個長度是8?
????????納尼,臥槽,這就觸及我的知識盲點(diǎn)了。為什么是8,難道這是個經(jīng)驗(yàn)數(shù)字?那他是怎么推導(dǎo)來的呢。難道是為了讓數(shù)據(jù)分散的更加均勻?不對,這不符合邏輯啊。正常的邏輯應(yīng)該是鏈表過長肯定會影響查詢效率,所以才需要變?yōu)榧t黑樹來加快查詢,但是這個8是為什么。
網(wǎng)上主流的答案:
????????紅黑樹的平均查找長度是log(n),如果長度為8,平均查找長度為log(8)=3,鏈表的平均查找長度為n/2,當(dāng)長度為8時,平均查找長度為8/2=4,紅黑樹的查找效率更高,這才有轉(zhuǎn)換成樹的必要;鏈表長度如果是小于等于6,6/2=3,而log(6)=2.6,雖然速度也很快的,但是轉(zhuǎn)化為樹結(jié)構(gòu)和生成樹的時間并不會太短。當(dāng)時面試官也是這樣給我解釋的,邏輯上確實(shí)也對。
但是我查看了源碼后,發(fā)現(xiàn)設(shè)計(jì)者真正的想法并不是這樣的。而是:
Because TreeNodes are about twice the size of regular nodes, weuse them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used. Ideally, under random hashCodes, the frequency of
nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because of
resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
????????如果 hashCode的分布離散良好的話,我們基本上用不到紅黑樹這玩意兒(納尼,原來這玩意大部分時候只是個擺設(shè)),因?yàn)楦鱾€值都均勻分布,很少出現(xiàn)鏈表很長的情況。在理想情況下,鏈表長度符合泊松分布,各個長度的命中概率依次遞減,注釋中給我們展示了1-8長度的具體命中概率,當(dāng)長度為8的時候,概率概率僅為0.00000006,這么小的概率,HashMap的紅黑樹轉(zhuǎn)換幾乎不會發(fā)生,因?yàn)槲覀內(nèi)粘J褂貌粫鎯δ敲炊嗟臄?shù)據(jù)。如果我們的數(shù)據(jù)離散性確實(shí)很差,那么這個時候就要變成紅黑樹來提高查詢效率了。
很可能會樹化的代碼案例:
????????在HashMap中,決定某個對象落在哪一個 “桶“,是由該對象的hashCode決定的,JDK無法阻止用戶實(shí)現(xiàn)自己的哈希算法,如果用戶重寫了hashCode,并且算法實(shí)現(xiàn)比較差的話,就很可能會使HashMap的鏈表變得很長,就比如這樣,相信這段代碼小伙伴們看了一定想要罵娘,這又是哪個傻叉寫的屎山,結(jié)果看了一下作者,沃特法克,小丑居然是我自己。
public class HashMapTest {
? ? public static void main(String[] args) {
? ? ? ? Map<User, Integer> map = new HashMap<>();
? ? ? ? for (int i = 0; i < 1000; i++) {
? ? ? ? ? ? map.put(new User("鄙人薛某" + i), i);
? ? ? ? }
? ? }
? ? static class User{
? ? ? ? private String name;
? ? ? ? public User(String name) {
? ? ? ? ? ? this.name = name;
? ? ? ? }
? ? ? ? @Override
? ? ? ? public int hashCode() {
? ? ? ? ? ? return 1;
? ? ? ? }
? ? }
}
????????總結(jié)下來就是,主流的說法也符合邏輯,但是8這個值卻是用上邊這種方法定下來的。所以到時候就看你碰到的面試官是那種面試官了,如果面試官腦子里背的是主流的方法,那么你最好回答主流的,當(dāng)然如果你能把面試官吊打一頓,他也很佩服你也行,但是也別打的太狠,不然你肯定也會與這次面試機(jī)會失之交臂,懂得都懂。
既然鏈表查詢效率不如紅黑樹,為什么不一開始就用紅黑樹,為什么還要用鏈表
這個我們就需要采取JDK源碼中的另一段解釋了,這個解釋也符合常理。
Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins.
????????因?yàn)闃涔?jié)點(diǎn)一般是普通節(jié)點(diǎn)的兩倍大,所以我們通常只有在鏈足夠長的時候使用它。其實(shí)就是這個節(jié)點(diǎn)太占空間了,所以如果在鏈表短的時候查詢效率相差不大,我們就用鏈表就完事了。
那什么條件下,紅黑樹會退化為鏈表。
在紅黑樹節(jié)點(diǎn)移除達(dá)到6的時候,會退化為鏈表結(jié)構(gòu)。
為什么會是6這個數(shù)字,你明明在8的時候樹化的,為什么不在小于8的時候就退化呢。
????????因?yàn)闃浠屯嘶且粋€比較繁瑣的過程,鏈表和樹結(jié)構(gòu)頻繁轉(zhuǎn)換會導(dǎo)致性能降低,所以如果還能將就著用,那就用現(xiàn)成的,別轉(zhuǎn)來轉(zhuǎn)去的。
你能給我講講HashMap的擴(kuò)容嗎。
????????終于到了這個問題了,HashMap的初始默認(rèn)桶數(shù)量(數(shù)組長度)為16,但是我們可以指定默認(rèn)大小,同時指定擴(kuò)容因子,默認(rèn)擴(kuò)容因子為0.75。當(dāng)含有元素的桶的數(shù)量超過負(fù)載因子比例時,會觸發(fā)resize操作,還有當(dāng)鏈表長度達(dá)到8同時發(fā)現(xiàn)數(shù)組容量沒有超過64,也會在樹化方法中觸發(fā)resize而不觸發(fā)樹化操作。
???????具體的擴(kuò)容操作就是,創(chuàng)建一個新的數(shù)組,長度是原來的2倍,然后遍歷原數(shù)組,進(jìn)行rehash操作,因?yàn)樾碌臄?shù)組長度變化了,所以原來節(jié)點(diǎn)的下標(biāo)已經(jīng)不再適用于新數(shù)組的下標(biāo)。
i = (n - 1) & hash(key)你能給我說說JDK1.7和JDK1.8HashMap擴(kuò)容時候的區(qū)別嗎
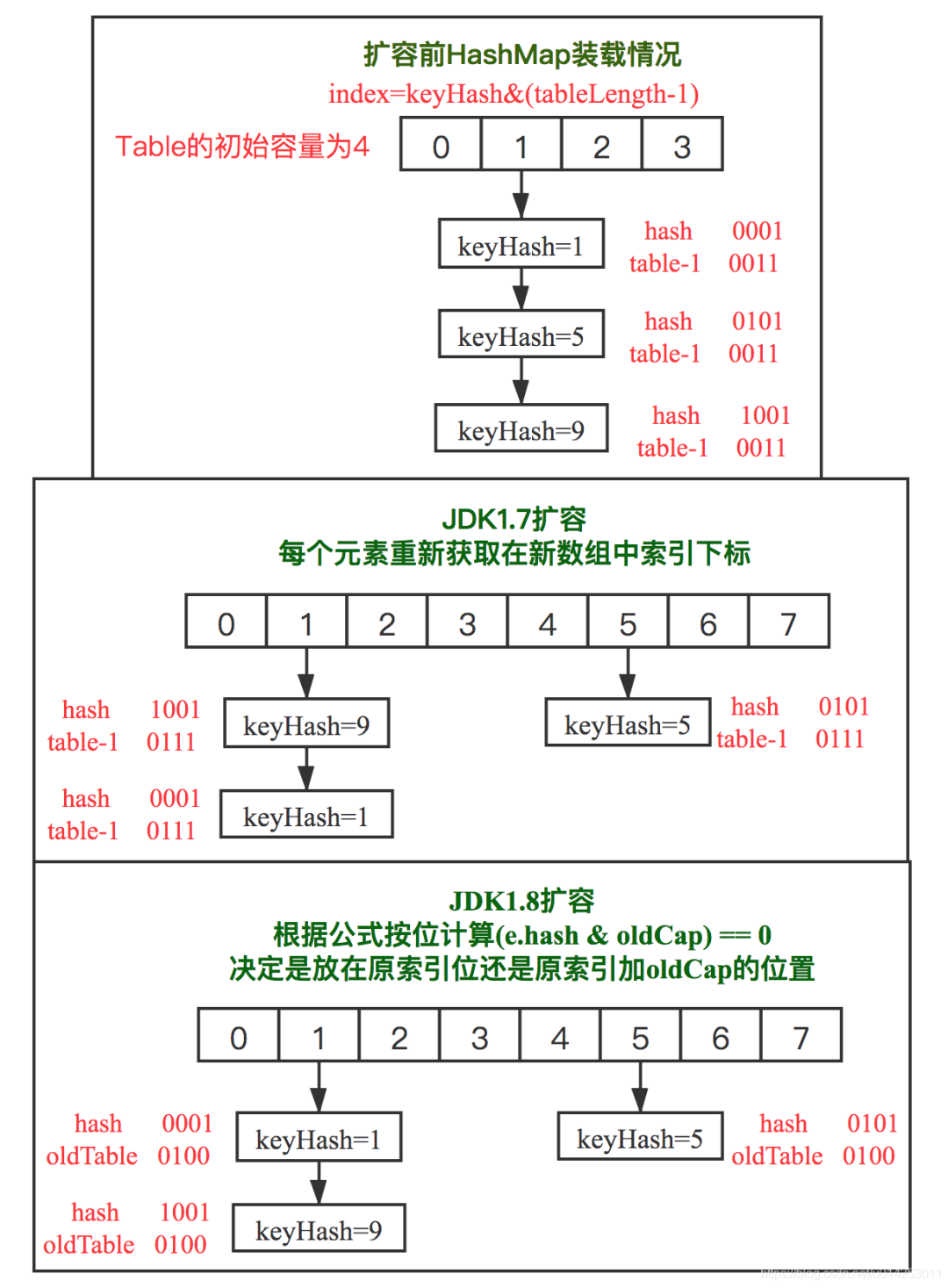
????????我擦,還好我早有準(zhǔn)備。這是Jdk1.7和Jdk1.8的擴(kuò)容之后節(jié)點(diǎn)新的數(shù)組下標(biāo)的計(jì)算方式。很明顯的一點(diǎn),JDK1.7會把節(jié)點(diǎn)全部重新進(jìn)行一次hash操作。
????????
????????下邊圖片的操作,由于擴(kuò)容總是2的倍數(shù),所以從二進(jìn)制的角度來看,每次擴(kuò)容其實(shí)就是數(shù)組長度左移一位。而我們原來計(jì)算hash的時候是用hash值與舊數(shù)組容量-1的方式計(jì)算。而數(shù)組容量實(shí)際上應(yīng)該是更高位為1。例如舊數(shù)組容量16,那么數(shù)組容量實(shí)際上是1 0000,而我們計(jì)算的時候16-1,實(shí)際上是0 1111。所以如果在新的數(shù)組里面,32 -1 ,二進(jìn)制為 1 1111。如果節(jié)點(diǎn)hash值高位并沒有超越 1 0000,?也就是還是在?0 1111這里面,那么你與新的1 1111 與運(yùn)算之后,還是在低位。所以此時,jdk1.8,如果hash值與舊容量與運(yùn)算?為0,那么就證明在新的數(shù)組中,這個節(jié)點(diǎn)實(shí)際上位置不變。而如果hash值與舊容量與運(yùn)算為1,那么就證明在新的數(shù)組中,該節(jié)點(diǎn)高位為1,同時其低位都是與1進(jìn)行與運(yùn)算,而舊數(shù)組容量恰好就是高位值。所以直接原來的索引+舊數(shù)組容量剛好與重新rehash的值相同。
牛逼,你能說下JDK1.8之前為什么會有死循環(huán)的問題嗎,在什么情境下會發(fā)生。
HashMap1.7當(dāng)中,擴(kuò)容的時候,采用的是頭插法轉(zhuǎn)移結(jié)點(diǎn),在多線程并發(fā)的情況下會造成鏈表死循環(huán)的問題。
假設(shè)有兩個線程,線程1和線程2,兩個線程進(jìn)行hashMap的put操作,觸發(fā)了擴(kuò)容。下面是擴(kuò)容的時候結(jié)點(diǎn)轉(zhuǎn)移的關(guān)鍵代碼
void transfer(Entry[] newTable) {
? ? ? Entry[] src = table;?
? ? ? int newCapacity = newTable.length;
? ? ? for (int j = 0; j < src.length; j++) {?
? ? ? ? ? Entry<K,V> e = src[j];? ? ? ? ? ?
? ? ? ? ? if (e != null) {//兩個線程都先進(jìn)入if
? ? ? ? ? ? ? src[j] = null;?
? ? ? ? ? ? ? do {?
? ? ? ? ? ? ? ? ? Entry<K,V> next = e.next;?
? ? ? ? ? ? ? ? ?int i = indexFor(e.hash, newCapacity);
? ? ? ? ? ? ? ? ?e.next = newTable[i]; //線程1 這里還沒執(zhí)行 停下
? ? ? ? ? ? ? ? ?newTable[i] = e;??
? ? ? ? ? ? ? ? ?e = next;? ? ? ? ? ? ?
? ? ? ? ? ? ?} while (e != null);
? ? ? ? ?}
? ? ?}
?}
線程1和線程2 都進(jìn)入if,然后線程1沒有拿到cpu的資源在上面代碼注釋的地方停下了。此時的變量指針如下圖所示:
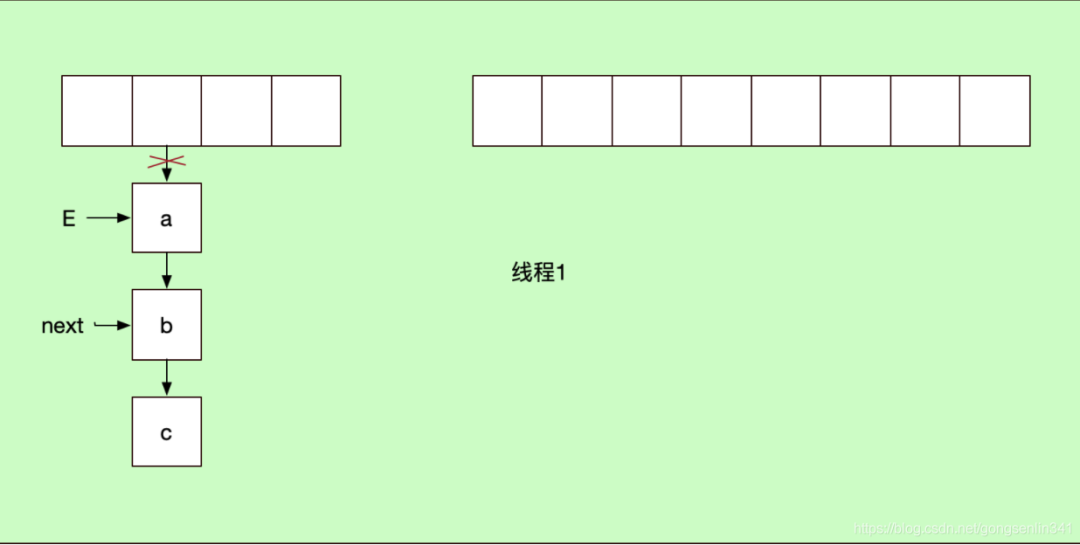
記住 線程1中 E變量指向a結(jié)點(diǎn),next變量指向b結(jié)點(diǎn)。
下面是線程2 拿到cpu的資源,執(zhí)行結(jié)點(diǎn)轉(zhuǎn)移
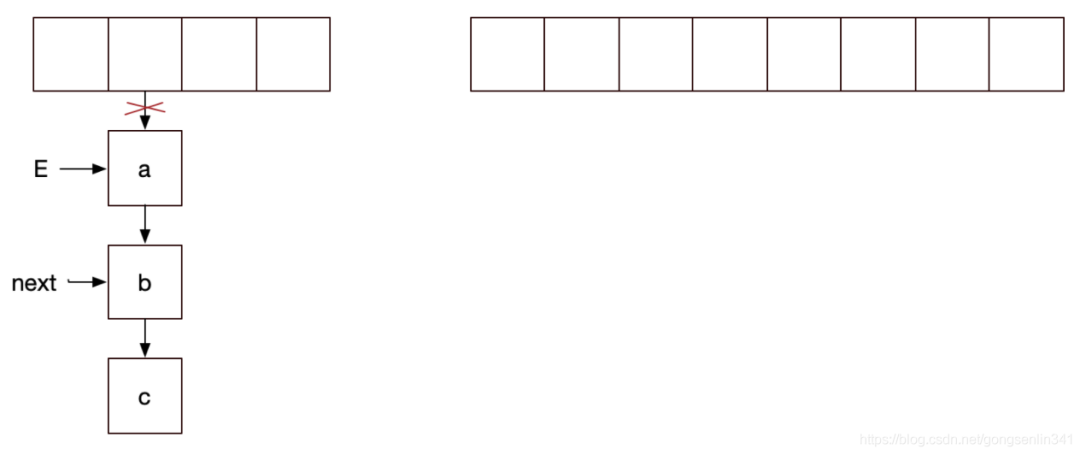
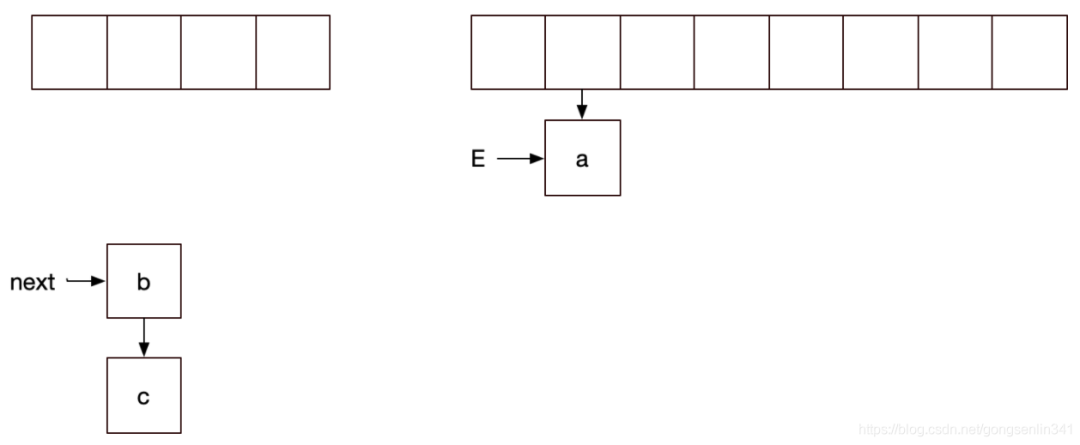
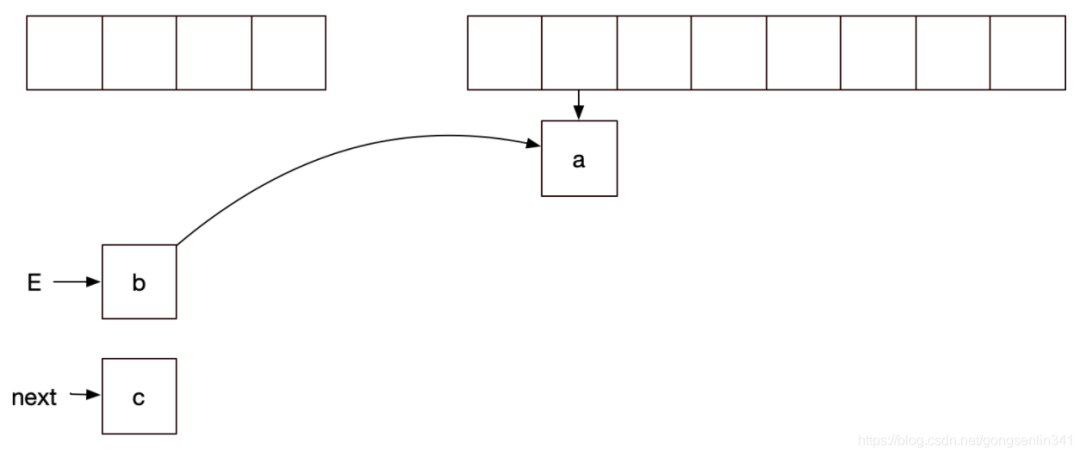
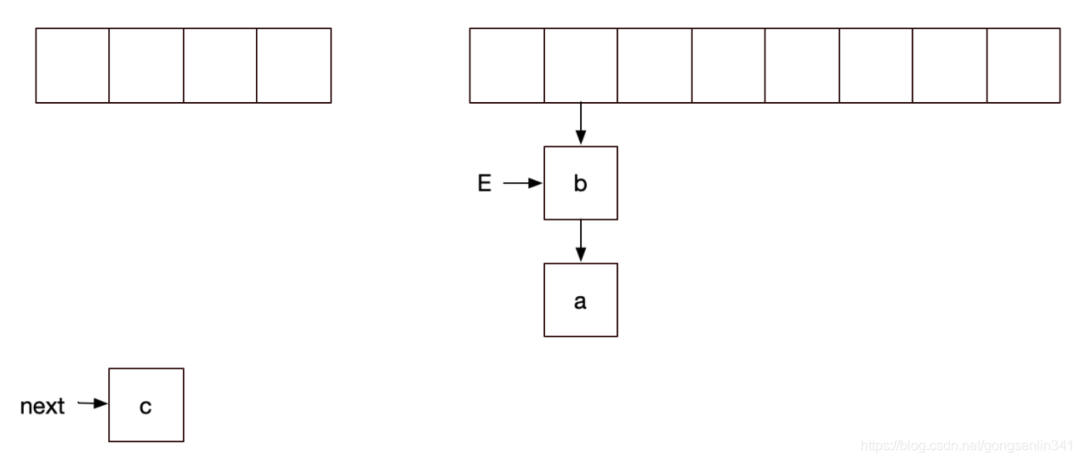
線程2停下,輪到線程1
因?yàn)橹熬€程1中E變量指向的是a結(jié)點(diǎn),next變量指向的是b結(jié)點(diǎn),所以如下圖所示:
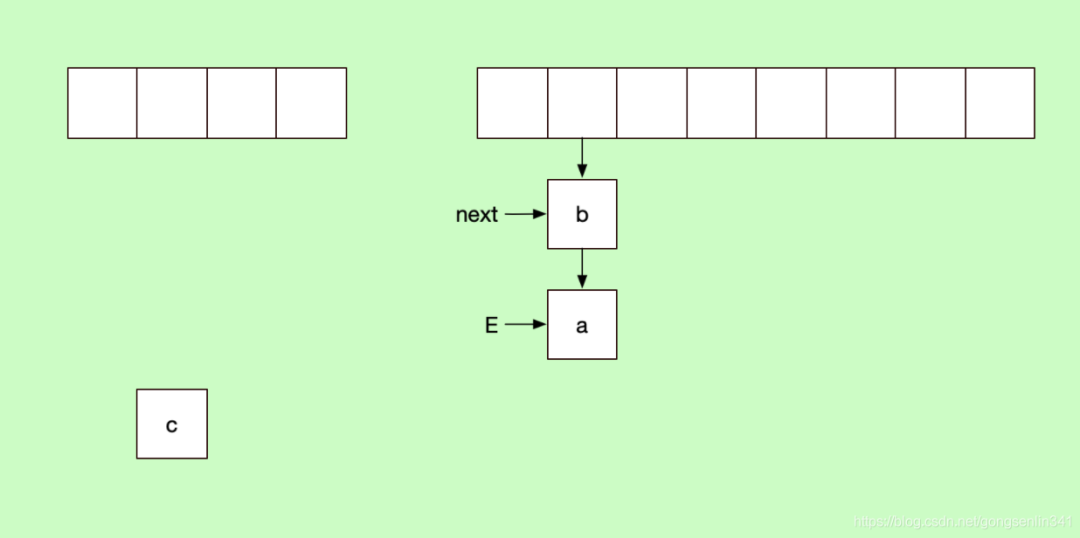
再來看看 剛才線程是在e.next = newTable[i] 這句代碼還沒執(zhí)行的時候停下的,那么現(xiàn)在就要執(zhí)行這一句代碼
void transfer(Entry[] newTable) {
? ? ? Entry[] src = table;?
? ? ? int newCapacity = newTable.length;
? ? ? for (int j = 0; j < src.length; j++) {?
? ? ? ? ? Entry<K,V> e = src[j];? ? ? ? ? ?
? ? ? ? ? if (e != null) {//兩個線程都先進(jìn)入if
? ? ? ? ? ? ? src[j] = null;?
? ? ? ? ? ? ? do {?
? ? ? ? ? ? ? ? ? Entry<K,V> next = e.next;?
? ? ? ? ? ? ? ? ?int i = indexFor(e.hash, newCapacity);
? ? ? ? ? ? ? ? ?e.next = newTable[i]; //線程1剛才在這里停下,所以現(xiàn)在從這一句代碼開始執(zhí)行
? ? ? ? ? ? ? ? ?newTable[i] = e;??
? ? ? ? ? ? ? ? ?e = next;? ? ? ? ? ? ?
? ? ? ? ? ? ?} while (e != null);
? ? ? ? ?}
? ? ?}
?}
此時線程1 執(zhí)行代碼之后,就造成了鏈表的死循環(huán),結(jié)果如下: