
【開(kāi)源】23個(gè)優(yōu)秀的機(jī)器學(xué)習(xí)數(shù)據(jù)集
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)


導(dǎo)讀
本文分享了23個(gè)優(yōu)秀的公共數(shù)據(jù)集,除了介紹數(shù)據(jù)集和數(shù)據(jù)示例外,還介紹了這些數(shù)據(jù)集各自可以解決哪些問(wèn)題。
本文最初發(fā)布于 rubikscode.com 網(wǎng)站,經(jīng)原作者授權(quán)由 InfoQ 中文站翻譯并分享。
Iris 數(shù)據(jù)集的那些示例你是不是已經(jīng)用膩了呢?不要誤會(huì)我的意思,Iris 數(shù)據(jù)集作為入門(mén)用途來(lái)說(shuō)是很不錯(cuò)的,但其實(shí)網(wǎng)絡(luò)上還有很多有趣的公共數(shù)據(jù)集可以用來(lái)練習(xí)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)。在這篇文章中,我會(huì)分享 23 個(gè)優(yōu)秀的公共數(shù)據(jù)集,除了介紹數(shù)據(jù)集和數(shù)據(jù)示例外,我還會(huì)介紹這些數(shù)據(jù)集各自可以解決哪些問(wèn)題。以下是這 23 個(gè)公共數(shù)據(jù)集:
帕爾默企鵝數(shù)據(jù)集
共享單車(chē)需求數(shù)據(jù)集
葡萄酒分類數(shù)據(jù)集
波士頓住房數(shù)據(jù)集
電離層數(shù)據(jù)集
Fashion MNIST 數(shù)據(jù)集
貓與狗數(shù)據(jù)集
威斯康星州乳腺癌(診斷)數(shù)據(jù)集
Twitter 情緒分析和 Sentiment140 數(shù)據(jù)集
BBC 新聞數(shù)據(jù)集
垃圾短信分類器數(shù)據(jù)集
CelebA 數(shù)據(jù)集
YouTube-8M 數(shù)據(jù)集
亞馬遜評(píng)論數(shù)據(jù)集
紙幣驗(yàn)證數(shù)據(jù)集
LabelMe 數(shù)據(jù)集
聲納數(shù)據(jù)集
皮馬印第安人糖尿病數(shù)據(jù)集
小麥種子數(shù)據(jù)集
Jeopardy! 數(shù)據(jù)集
鮑魚(yú)數(shù)據(jù)集
假新聞檢測(cè)數(shù)據(jù)集
ImageNet 數(shù)據(jù)集
1. 帕爾默企鵝數(shù)據(jù)集
這是迄今為止我最喜歡的數(shù)據(jù)集。我在最近寫(xiě)的書(shū)里的大多數(shù)示例都來(lái)自于它。簡(jiǎn)單來(lái)說(shuō),如果你在 Iris 數(shù)據(jù)集上做實(shí)驗(yàn)做膩了就可以嘗試一下這一個(gè)。它由 Kristen Gorman 博士和南極洲 LTER 的帕爾默科考站共同創(chuàng)建。該數(shù)據(jù)集本質(zhì)上是由兩個(gè)數(shù)據(jù)集組成的,每個(gè)數(shù)據(jù)集包含 344 只企鵝的數(shù)據(jù)。 就像 Iris 一樣,這個(gè)數(shù)據(jù)集里有來(lái)自帕爾默群島 3 個(gè)島嶼的 3 種不同種類的企鵝,分別是 Adelie、Chinstrap 和 Gentoo。或許“Gentoo”聽(tīng)起來(lái)很耳熟,那是因?yàn)?Gentoo Linux 就是以它命名的!此外,這些數(shù)據(jù)集包含每個(gè)物種的 culmen 維度。這里 culmen 是鳥(niǎo)喙的上脊。在簡(jiǎn)化的企鵝數(shù)據(jù)中,culmen 長(zhǎng)度和深度被重命名為變量 culmen_length_mm 和 culmen_depth_mm。
就像 Iris 一樣,這個(gè)數(shù)據(jù)集里有來(lái)自帕爾默群島 3 個(gè)島嶼的 3 種不同種類的企鵝,分別是 Adelie、Chinstrap 和 Gentoo。或許“Gentoo”聽(tīng)起來(lái)很耳熟,那是因?yàn)?Gentoo Linux 就是以它命名的!此外,這些數(shù)據(jù)集包含每個(gè)物種的 culmen 維度。這里 culmen 是鳥(niǎo)喙的上脊。在簡(jiǎn)化的企鵝數(shù)據(jù)中,culmen 長(zhǎng)度和深度被重命名為變量 culmen_length_mm 和 culmen_depth_mm。
1.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\penguins_size.csv")data.head()
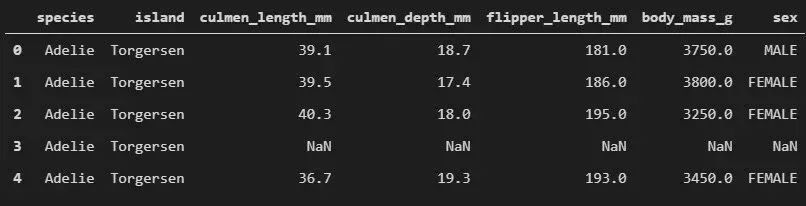 我們使用 Pandas 庫(kù)來(lái)做數(shù)據(jù)可視化,并且加載的是一個(gè)更簡(jiǎn)單的數(shù)據(jù)集。
我們使用 Pandas 庫(kù)來(lái)做數(shù)據(jù)可視化,并且加載的是一個(gè)更簡(jiǎn)單的數(shù)據(jù)集。
1.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
它是練習(xí)解決分類和聚類問(wèn)題的好幫手。在這里,你可以嘗試各種分類算法,如決策樹(shù)、隨機(jī)森林、SVM,或把它用于聚類問(wèn)題并練習(xí)使用無(wú)監(jiān)督學(xué)習(xí)。
1.3 有用的鏈接
在以下鏈接中可以獲得有關(guān) PalmerPenguins 數(shù)據(jù)集的更多信息:
介紹 (https://allisonhorst.github.io/palmerpenguins/articles/intro.html)
GitHub(https://github.com/allisonhorst/palmerpenguins)
Kaggle(https://www.kaggle.com/parulpandey/palmer-archipelago-antarctica-penguin-data)
2. 共享單車(chē)需求數(shù)據(jù)集
這個(gè)數(shù)據(jù)集非常有趣。它對(duì)于初學(xué)者來(lái)說(shuō)有點(diǎn)復(fù)雜,但也正因如此,它很適合拿來(lái)做練習(xí)。它包含了華盛頓特區(qū)“首都自行車(chē)共享計(jì)劃”中自行車(chē)租賃需求的數(shù)據(jù),自行車(chē)共享和租賃系統(tǒng)通常是很好的信息來(lái)源。這個(gè)數(shù)據(jù)集包含了有關(guān)騎行持續(xù)時(shí)間、出發(fā)地點(diǎn)、到達(dá)地點(diǎn)和經(jīng)過(guò)時(shí)間的信息,還包含了每一天每小時(shí)的天氣信息。
2.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的。首先,我們使用數(shù)據(jù)集的每小時(shí)數(shù)據(jù)來(lái)執(zhí)行操作:
data = pd.read_csv(f".\\Datasets\\hour.csv")data.head()
 每日數(shù)據(jù)是下面的樣子:
每日數(shù)據(jù)是下面的樣子:
data = pd.read_csv(f".\\Datasets\\day.csv")data.head()

2.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
由于該數(shù)據(jù)集包含的信息種類繁多,因此非常適合練習(xí)解決回歸問(wèn)題。你可以嘗試對(duì)其使用多元線性回歸,或使用神經(jīng)網(wǎng)絡(luò)。
2.3 有用的鏈接
在以下鏈接中可以獲得關(guān)于該數(shù)據(jù)集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/bike+sharing+dataset)
Kaggle(https://www.kaggle.com/c/bike-sharing-demand)
3. 葡萄酒分類數(shù)據(jù)集
這是一個(gè)經(jīng)典之作。如果你喜歡葡萄樹(shù)或計(jì)劃成為索馬里人,肯定會(huì)更中意它的。該數(shù)據(jù)集由兩個(gè)數(shù)據(jù)集組成。兩者都包含來(lái)自葡萄牙 Vinho Verde 地區(qū)的葡萄酒的化學(xué)指標(biāo),一種用于紅葡萄酒,另一種用于白葡萄酒。由于隱私限制,數(shù)據(jù)集里沒(méi)有關(guān)于葡萄種類、葡萄酒品牌、葡萄酒售價(jià)的數(shù)據(jù),但有關(guān)于葡萄酒質(zhì)量的信息。
3.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\winequality-white.csv")data.head()

3.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這是一個(gè)多類分類問(wèn)題,但也可以被定義為回歸問(wèn)題。它的分類數(shù)據(jù)是不均衡的(例如,正常葡萄酒的數(shù)量比優(yōu)質(zhì)或差的葡萄酒多得多),很適合針對(duì)不均衡數(shù)據(jù)集的分類練習(xí)。除此之外,數(shù)據(jù)集中所有特征并不都是相關(guān)的,因此也可以拿來(lái)練習(xí)特征工程和特征選擇。
3.3 有用的鏈接
以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (https://www.vinhoverde.pt/en/about-vinho-verde)
UCI(https://archive.ics.uci.edu/ml/datasets/Wine+Quality)
4. 波士頓住房數(shù)據(jù)集
雖然我說(shuō)過(guò)會(huì)盡量不推薦其他人都推薦的那種數(shù)據(jù)集,但這個(gè)數(shù)據(jù)集實(shí)在太經(jīng)典了。許多教程、示例和書(shū)籍都使用過(guò)它。這個(gè)數(shù)據(jù)集由 14 個(gè)特征組成,包含美國(guó)人口普查局收集的關(guān)于馬薩諸塞州波士頓地區(qū)住房的信息。這是一個(gè)只有 506 個(gè)樣本的小數(shù)據(jù)集。
4.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\boston_housing.csv")data.head()
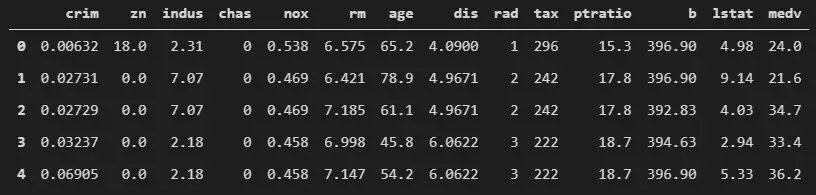
4.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
該數(shù)據(jù)集非常適合練習(xí)回歸任務(wù)。請(qǐng)注意,因?yàn)檫@是一個(gè)小數(shù)據(jù)集,你可能會(huì)得到樂(lè)觀的結(jié)果。
4.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (https://www.cs.toronto.edu/\~delve/data/boston/bostonDetail.html)
Kaggle(https://www.kaggle.com/c/boston-housing)
5. 電離層數(shù)據(jù)集
這也是一個(gè)經(jīng)典數(shù)據(jù)集。它實(shí)際上起源于 1989 年,但它確實(shí)很有趣。該數(shù)據(jù)集包含由拉布拉多鵝灣的雷達(dá)系統(tǒng)收集的數(shù)據(jù)。該系統(tǒng)由 16 個(gè)高頻天線的相控陣列組成,旨在檢測(cè)電離層中的自由電子。一般來(lái)說(shuō),電離層有兩種類型的結(jié)構(gòu):“好”和“壞”。這些雷達(dá)會(huì)檢測(cè)這些結(jié)構(gòu)并傳遞信號(hào)。數(shù)據(jù)集中有 34 個(gè)自變量和 1 個(gè)因變量,總共有 351 個(gè)觀測(cè)值。
5.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\ionsphere.csv")data.head()
5.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這顯然是一個(gè)二元(2 類)分類問(wèn)題。有趣的是,這是一個(gè)不均衡的數(shù)據(jù)集,所以你也可以用它做這種練習(xí)。在這個(gè)數(shù)據(jù)集上實(shí)現(xiàn)高精度也非易事,基線性能在 64% 左右,而最高精度在 94% 左右。
5.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/Ionosphere)
6.Fashion MNIST 數(shù)據(jù)集
MNIST 數(shù)據(jù)集是用于練習(xí)圖像分類和圖像識(shí)別的著名數(shù)據(jù)集,然而它有點(diǎn)被濫用了。如果你想要一個(gè)簡(jiǎn)單的數(shù)據(jù)集來(lái)練習(xí)圖像分類,你可以試試 Fashion MNIST。它曾被《機(jī)器學(xué)習(xí)終極指南》拿來(lái)做圖像分類示例。本質(zhì)上,這個(gè)數(shù)據(jù)集是 MNIST 數(shù)據(jù)集的變體,它與 MNIST 數(shù)據(jù)集具有相同的結(jié)構(gòu),也就是說(shuō)它有一個(gè) 60,000 個(gè)樣本的訓(xùn)練集和一個(gè) 10,000 個(gè)服裝圖像的測(cè)試集。所有圖像都經(jīng)過(guò)尺寸歸一化和居中。圖像的大小也固定為 28×28,這樣預(yù)處理的圖像數(shù)據(jù)被減到了最小水平。它也可作為某些框架(如 TensorFlow 或 PyTorch)的一部分使用。
6.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
6.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
它最適合圖像分類和圖像生成任務(wù)。你可以使用簡(jiǎn)單的卷積神經(jīng)網(wǎng)絡(luò)(CNN)來(lái)做嘗試,或者使用生成對(duì)抗網(wǎng)絡(luò)(GAN)使用它來(lái)生成圖像。
6.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
GitHub(https://github.com/zalandoresearch/fashion-mnist)
Kaggle(https://www.kaggle.com/zalando-research/fashionmnist)
7. 貓與狗數(shù)據(jù)集
這是一個(gè)包含貓狗圖像的數(shù)據(jù)集。這個(gè)數(shù)據(jù)集包含 23,262 張貓和狗的圖像,用于二值圖像分類。在主文件夾中,你會(huì)找到兩個(gè)文件夾 train1 和 test。train1 文件夾包含訓(xùn)練圖像,而 test 文件夾包含測(cè)試圖像。請(qǐng)注意,圖像名稱以 cat 或 dog 開(kāi)頭。這些名稱本質(zhì)上是我們的標(biāo)簽,這意味著我們將使用這些名稱定義目標(biāo)。
7.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
7.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這個(gè)數(shù)據(jù)集有兩重目標(biāo)。首先,它可用于練習(xí)圖像分類以及對(duì)象檢測(cè)。其次,你可以在這里面找到無(wú)窮無(wú)盡的可愛(ài)圖片。
7.3 有用的鏈接
以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (https://www.microsoft.com/en-us/download/details.aspx?id=54765)
Kaggle(https://www.kaggle.com/c/dogs-vs-cats)
8. 威斯康星州乳腺癌(診斷)數(shù)據(jù)集
機(jī)器學(xué)習(xí)和深度學(xué)習(xí)技術(shù)在醫(yī)療保健領(lǐng)域中的應(yīng)用正在穩(wěn)步增長(zhǎng)。如果你想練習(xí)并了解使用此類數(shù)據(jù)的效果,這個(gè)數(shù)據(jù)集是一個(gè)不錯(cuò)的選擇。在該數(shù)據(jù)集中,數(shù)據(jù)是通過(guò)處理乳房腫塊的細(xì)針穿刺(FNA)的數(shù)字化圖像提取出來(lái)的。該數(shù)據(jù)集中的每個(gè)特征都描述了上述數(shù)字化圖像中發(fā)現(xiàn)的細(xì)胞核的特征。該數(shù)據(jù)集由 569 個(gè)樣本組成,其中包括 357 個(gè)良性樣本和 212 個(gè)惡性樣本。這個(gè)數(shù)據(jù)集中有三類特征,其中實(shí)值特征最有趣。它們是從數(shù)字化圖像中計(jì)算出來(lái)的,包含有關(guān)區(qū)域、細(xì)胞半徑、紋理等信息。
8.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\breast-cancer-wisconsin.csv")data.head()
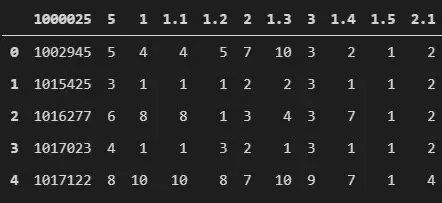
8.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這個(gè)醫(yī)療保健數(shù)據(jù)集適合練習(xí)分類和隨機(jī)森林、SVM 等算法。
8.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
Kaggle(https://www.kaggle.com/uciml/breast-cancer-wisconsin-data)
UCI(https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
9.Twitter 情緒分析和
Sentiment140 數(shù)據(jù)集
在過(guò)去幾年中,情緒分析成為了一種監(jiān)控和了解客戶反饋的重要工具。這種對(duì)消息和響應(yīng)所攜帶的潛在情緒基調(diào)的檢測(cè)過(guò)程是完全自動(dòng)化的,這意味著企業(yè)可以更好更快地了解客戶的需求并提供更好的產(chǎn)品和服務(wù)。這一過(guò)程是通過(guò)應(yīng)用各種 NLP(自然語(yǔ)言處理)技術(shù)來(lái)完成的。這些數(shù)據(jù)集可以幫助你練習(xí)此類技術(shù),實(shí)際上非常適合該領(lǐng)域的初學(xué)者。Sentiment140 包含了使用 Twitter API 提取的 1,600,000 條推文。它們的結(jié)構(gòu)略有不同。
9.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\training.1600000.processed.noemoticon.csv")data.head()

9.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
如前所述,這是一個(gè)用于情緒分析的數(shù)據(jù)集。情緒分析是最常見(jiàn)的文本分類工具。該過(guò)程會(huì)分析文本片段以確定其中包含的情緒是積極的、消極的還是中性的。了解品牌和產(chǎn)品引發(fā)的社會(huì)情緒是現(xiàn)代企業(yè)必不可少的工具之一。
9.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
Kaggle(https://www.kaggle.com/c/twitter-sentiment-analysis2)
Kaggle(https://www.kaggle.com/kazanova/sentiment140)
10.BBC 新聞數(shù)據(jù)集
我們?cè)賮?lái)看這個(gè)類別中另一個(gè)有趣的文本數(shù)據(jù)集。該數(shù)據(jù)集來(lái)自 BBC 新聞。它由 2225 篇文章組成,每篇文章都有標(biāo)簽。所有文章分成 5 個(gè)類別:科技、商業(yè)、政治、娛樂(lè)和體育。這個(gè)數(shù)據(jù)集沒(méi)有失衡,每個(gè)類別中的文章數(shù)量都是差不多的。
10.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\BBC News Train.csv")data.head()

10.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
自然,這個(gè)數(shù)據(jù)集最適合用于文本分類練習(xí)。你也可以更進(jìn)一步,練習(xí)分析每篇文章的情緒。總的來(lái)說(shuō),它適用于各種 NLP 任務(wù)和實(shí)踐。
10.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
Kaggle(https://www.kaggle.com/c/learn-ai-bbc)
11. 垃圾短信分類器數(shù)據(jù)集
垃圾消息檢測(cè)是互聯(lián)網(wǎng)中最早投入實(shí)踐的機(jī)器學(xué)習(xí)任務(wù)之一。這種任務(wù)也屬于 NLP 和文本分類工作。所以,如果你想練習(xí)解決這類問(wèn)題,Spam SMS 數(shù)據(jù)集是一個(gè)不錯(cuò)的選擇。它在實(shí)踐中用得非常多,非常適合初學(xué)者。這個(gè)數(shù)據(jù)集最棒的一點(diǎn)是,它是從互聯(lián)網(wǎng)的多個(gè)來(lái)源構(gòu)建的。例如,它從 Grumbletext 網(wǎng)站上提取了 425 條垃圾短信,從新加坡國(guó)立大學(xué)的 NUS SMS Corpus(NSC)隨機(jī)選擇了 3,375 條短信,還有 450 條短信來(lái)自 Caroline Tag 的博士論文等。數(shù)據(jù)集本身由兩列組成:標(biāo)簽(ham 或 spam)和原始文本。
11.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
ham What you doing?how are you?ham Ok lar... Joking wif u oni...ham dun say so early hor... U c already then say...ham MY NO. IN LUTON 0125698789 RING ME IF UR AROUND! H*ham Siva is in hostel aha:-.ham Cos i was out shopping wif darren jus now n i called him 2 ask wat present he wan lor. Then he started guessing who i was wif n he finally guessed darren lor.spam FreeMsg: Txt: CALL to No: 86888 & claim your reward of 3 hours talk time to use from your phone now! ubscribe6GBP/ mnth inc 3hrs 16 stop?txtStopspam Sunshine Quiz! Win a super Sony DVD recorder if you canname the capital of Australia? Text MQUIZ to 82277. Bspam URGENT! Your Mobile No 07808726822 was awarded a L2,000 Bonus Caller Prize on 02/09/03! This is our 2nd attempt to contact YOU! Call 0871-872-9758 BOX95QU
11.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
顧名思義,該數(shù)據(jù)集最適合用于垃圾郵件檢測(cè)和文本分類。它也經(jīng)常用在工作面試中,所以大家最好練習(xí)一下。
11.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/sms+spam+collection)
Kaggle(https://www.kaggle.com/uciml/sms-spam-collection-dataset)
12.CelebA 數(shù)據(jù)集
如果你想研究人臉檢測(cè)解決方案、構(gòu)建自己的人臉生成器或創(chuàng)建深度人臉偽造模型,那么這個(gè)數(shù)據(jù)集就是你的最佳選擇。該數(shù)據(jù)集擁有超過(guò) 20 萬(wàn)張名人圖像,每張圖像有 40 個(gè)屬性注釋,為你的研究項(xiàng)目提供了一個(gè)很好的起點(diǎn)。此外,它還涵蓋了主要的姿勢(shì)和背景類別。
12.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
12.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
我們可以用這個(gè)數(shù)據(jù)集解決多種問(wèn)題。比如,我們可以解決各種人臉識(shí)別和計(jì)算機(jī)視覺(jué)問(wèn)題,它可用來(lái)使用不同的生成算法生成圖像。此外,你可以使用它來(lái)開(kāi)發(fā)新穎的深度人臉偽造模型或深度偽造檢測(cè)模型。
12.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html)
13.YouTube-8M 數(shù)據(jù)集
這是最大的多標(biāo)簽視頻分類數(shù)據(jù)集。它來(lái)自谷歌,擁有 800 萬(wàn)個(gè)帶有注釋和 ID 的 YouTube 分類視頻。這些視頻的注釋由 YouTube 視頻注釋系統(tǒng)使用 48000 個(gè)視覺(jué)實(shí)體的詞匯表創(chuàng)建。該詞匯表也可供下載。請(qǐng)注意,此數(shù)據(jù)集可用作 TensorFlow 記錄文件。除此之外,你還可以使用這個(gè)數(shù)據(jù)集的擴(kuò)展——YouTube-8M Segments 數(shù)據(jù)集。它包含了人工驗(yàn)證的分段注釋。
13.1 數(shù)據(jù)集樣本
你可以使用以下命令下載它們:
mkdir -p ~/yt8m/2/frame/traincd ~/yt8m/2/frame/traincurl data.yt8m.org/download.py | partition=2/frame/train mirror=us python
13.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
你可以使用這個(gè)數(shù)據(jù)集執(zhí)行多種操作。比如可以使用它跟進(jìn)谷歌的競(jìng)賽,并開(kāi)發(fā)準(zhǔn)確分配視頻級(jí)標(biāo)簽的分類算法。你還可以用它來(lái)創(chuàng)建視頻分類模型,也可以用它練習(xí)所謂的時(shí)間概念定位,也就是找到并分享特定的視頻瞬間。
13.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (https://arxiv.org/abs/1609.08675)
下載 (http://research.google.com/youtube8m/)
14. 亞馬遜評(píng)論數(shù)據(jù)集
情緒分析是最常見(jiàn)的文本分類工具。這個(gè)過(guò)程會(huì)分析文本片段以確定情緒傾向是積極的、消極的還是中性的。在監(jiān)控在線會(huì)話時(shí)了解你的品牌、產(chǎn)品或服務(wù)引發(fā)的社會(huì)情緒是現(xiàn)代商業(yè)活動(dòng)的基本工具之一,而情緒分析是實(shí)現(xiàn)這一目標(biāo)的第一步。該數(shù)據(jù)集包含了來(lái)自亞馬遜的產(chǎn)品評(píng)論和元數(shù)據(jù),包括 1996 年 5 月至 2018 年 10 月的 2.331 億條評(píng)論。
14.1 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這個(gè)數(shù)據(jù)集可以為任何產(chǎn)品創(chuàng)建情緒分析的入門(mén)模型,你可以使用它來(lái)快速創(chuàng)建可用于生產(chǎn)的模型。
14.2 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹和下載 (https://jmcauley.ucsd.edu/data/amazon/)
15. 紙幣驗(yàn)證數(shù)據(jù)集
這是一個(gè)有趣的數(shù)據(jù)集。你可以使用它來(lái)創(chuàng)建可以檢測(cè)真鈔和偽造鈔票的解決方案。該數(shù)據(jù)集包含了從數(shù)字化圖像中提取的許多指標(biāo)。數(shù)據(jù)集的圖像是使用通常用于印刷檢查的工業(yè)相機(jī)創(chuàng)建的,圖像尺寸為 400x400 像素。這是一個(gè)干凈的數(shù)據(jù)集,包含 1372 個(gè)示例且沒(méi)有缺失值。
15.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\data_banknote_authentication.csv")data.head()
15.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
它是練習(xí)二元分類和應(yīng)用各種算法的絕佳數(shù)據(jù)集。此外,你可以修改它并將其用于聚類,并提出將通過(guò)無(wú)監(jiān)督學(xué)習(xí)對(duì)這些數(shù)據(jù)進(jìn)行聚類的算法。
15.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/banknote+authentication#)
Kaggle(https://www.kaggle.com/ritesaluja/bank-note-authentication-uci-data)
16.LabelMe 數(shù)據(jù)集
LabelMe 是另一個(gè)計(jì)算機(jī)視覺(jué)數(shù)據(jù)集。LabelMe 是一個(gè)帶有真實(shí)標(biāo)簽的大型圖像數(shù)據(jù)庫(kù),用于物體檢測(cè)和識(shí)別。它的注釋來(lái)自兩個(gè)不同的來(lái)源,其中就有 LabelMe 在線注釋工具。簡(jiǎn)而言之,有兩種方法可以利用這個(gè)數(shù)據(jù)集。你可以通過(guò) LabelMe Matlab 工具箱下載所有圖像,也可以通過(guò) LabelMe Matlab 工具箱在線使用圖像。
16.1 數(shù)據(jù)集樣本
標(biāo)記好的數(shù)據(jù)如下所示:
16.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
它是用于對(duì)象檢測(cè)和對(duì)象識(shí)別解決方案的絕佳數(shù)據(jù)集。
16.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹和下載 (http://labelme.csail.mit.edu/Release3.0/index.php)
17. 聲納數(shù)據(jù)集
如果你對(duì)地質(zhì)學(xué)感興趣,會(huì)發(fā)現(xiàn)這個(gè)數(shù)據(jù)集非常有趣。它是利用聲納信號(hào)制成的,由兩部分組成。第一部分名為“sonar.mines”,包含 111 個(gè)模式,這些模式是使用在不同角度和不同條件下從金屬圓柱體反射的聲納信號(hào)制成的。第二部分名為“sonar.rocks”,由 97 個(gè)模式組成,同樣是通過(guò)反射聲納信號(hào)制成,但這次反射的是巖石上的信號(hào)。它是一個(gè)不均衡數(shù)據(jù)集,包含 208 個(gè)示例、60 個(gè)輸入特征和一個(gè)輸出特征。
17.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\sonar.csv")data.head()

17.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
該數(shù)據(jù)集非常適合練習(xí)二元分類。它的制作目標(biāo)是檢測(cè)輸入是地雷還是巖石,這是一個(gè)有趣的問(wèn)題,因?yàn)樽罡叩妮敵鼋Y(jié)果達(dá)到了 88% 的準(zhǔn)確率。
17.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (https://www.is.umk.pl/projects/datasets.html#Sonar)
UCI(https://archive.ics.uci.edu/ml/datasets/Connectionist+Bench+(Sonar,+Mines+vs.+Rocks))
18. 皮馬印第安人糖尿病數(shù)據(jù)集
這是另一個(gè)用于分類練習(xí)的醫(yī)療保健數(shù)據(jù)集。它來(lái)自美國(guó)國(guó)家糖尿病、消化和腎臟疾病研究所,其目的是根據(jù)某些診斷指標(biāo)來(lái)預(yù)測(cè)患者是否患有糖尿病。該數(shù)據(jù)集包含 768 個(gè)觀測(cè)值,具有 8 個(gè)輸入特征和 1 個(gè)輸出特征。它不是一個(gè)均衡的數(shù)據(jù)集,并且假設(shè)缺失值被替換為 0。
18.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\pima-indians-dataset.csv")data.head()
18.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
它是另一個(gè)適合練習(xí)二元分類的數(shù)據(jù)集。
18.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
介紹 (https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.names)
Kaggle(https://www.kaggle.com/uciml/pima-indians-diabetes-database)
19. 小麥種子數(shù)據(jù)集
這個(gè)數(shù)據(jù)集非常有趣和簡(jiǎn)單。它特別適合初學(xué)者,可以代替 Iris 數(shù)據(jù)集。該數(shù)據(jù)集包含屬于三種不同小麥品種的種子信息:Kama、Rosa 和 Canadian。它是一個(gè)均衡的數(shù)據(jù)集,每個(gè)類別有 70 個(gè)實(shí)例。種子內(nèi)部?jī)?nèi)核結(jié)構(gòu)的測(cè)量值是使用軟 X 射線技術(shù)檢測(cè)的。
19.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\seeds_dataset.csv")data.head()
19.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這個(gè)數(shù)據(jù)集有利于提升分類技能。
19.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/seeds)
Kaggle(https://www.kaggle.com/jmcaro/wheat-seedsuci)
20.Jeopardy! 問(wèn)題數(shù)據(jù)集
這個(gè)數(shù)據(jù)集很不錯(cuò),包含 216,930 個(gè) Jeopardy 問(wèn)題、答案和其他數(shù)據(jù)。它是可用于你 NLP 項(xiàng)目的絕佳數(shù)據(jù)集。除了問(wèn)題和答案,該數(shù)據(jù)集還包含有關(guān)問(wèn)題類別和價(jià)值的信息。
20.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\joepardy.csv")data.head()

20.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這是一個(gè)豐富的數(shù)據(jù)集,可用于多種用途。你可以運(yùn)行分類算法并預(yù)測(cè)問(wèn)題的類別或問(wèn)題的價(jià)值。不過(guò)你可以用它做的最酷的事情可能是用它來(lái)訓(xùn)練 BERT 模型。
20.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
Kaggle(https://www.kaggle.com/tunguz/200000-jeopardy-questions)
21. 鮑魚(yú)數(shù)據(jù)集
從本質(zhì)上講這是一個(gè)多分類問(wèn)題,然而,這個(gè)數(shù)據(jù)集也可以被視為一個(gè)回歸問(wèn)題。它的目標(biāo)是使用提供的指標(biāo)來(lái)預(yù)測(cè)鮑魚(yú)的年齡。這個(gè)數(shù)據(jù)集不均衡,4,177 個(gè)實(shí)例有 8 個(gè)輸入變量和 1 個(gè)輸出變量。
21.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\abalone.csv")data.head()
21.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
該數(shù)據(jù)集可以同時(shí)構(gòu)建為回歸和分類任務(wù)。這是一個(gè)很好的機(jī)會(huì),可以使用多元線性回歸、SVM、隨機(jī)森林等算法,或者構(gòu)建一個(gè)可以解決這個(gè)問(wèn)題的神經(jīng)網(wǎng)絡(luò)。
21.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
UCI(https://archive.ics.uci.edu/ml/datasets/abalone)
Kaggle(https://www.kaggle.com/rodolfomendes/abalone-dataset)
22. 假新聞數(shù)據(jù)集
我們生活在一個(gè)狂野的時(shí)代。假新聞、深度造假和其他類型的欺騙技術(shù)都成了我們?nèi)粘I畹囊徊糠郑瑹o(wú)論我們喜歡與否。這個(gè)數(shù)據(jù)集提供了另一個(gè)非常適合練習(xí)的 NLP 任務(wù)。它包含標(biāo)記過(guò)的真實(shí)和虛假新聞,以及它們的文本和作者。
22.1 數(shù)據(jù)集樣本
我們加載數(shù)據(jù),看看它是什么樣的:
data = pd.read_csv(f".\\Datasets\\fake_news\\train.csv")data.head()

22.2 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
這是另一個(gè) NLP 文本分類任務(wù)。
22.3 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
Kaggle(https://www.kaggle.com/c/fake-news/overview)
23.ImageNet 數(shù)據(jù)集
最后這個(gè)數(shù)據(jù)集是計(jì)算機(jī)視覺(jué)數(shù)據(jù)集中的王者——ImageNet。該數(shù)據(jù)集是用來(lái)衡量所有新的深度學(xué)習(xí)和計(jì)算機(jī)視覺(jué)技術(shù)創(chuàng)新的基準(zhǔn)。沒(méi)有它,深度學(xué)習(xí)的世界就不會(huì)變成今天這樣的狀態(tài)。ImageNet 是一個(gè)按照 WordNet 層次結(jié)構(gòu)組織的大型圖像數(shù)據(jù)庫(kù)。這意味著每個(gè)實(shí)體都用一組稱為 -synset 的詞和短語(yǔ)來(lái)描述。每個(gè)同義詞集分配了大約 1000 個(gè)圖像。基本上,層次結(jié)構(gòu)的每個(gè)節(jié)點(diǎn)都由成百上千的圖像描述。
23.1 這個(gè)公共數(shù)據(jù)集適合解決什么問(wèn)題?
它是學(xué)術(shù)和研究界的標(biāo)準(zhǔn)數(shù)據(jù)集。它的主要任務(wù)是圖像分類,但你也可以將其用于各種任務(wù)。
23.2 有用的鏈接
從以下鏈接中可以找到關(guān)于這個(gè)數(shù)據(jù)集的更多信息:
官方網(wǎng)站 (https://image-net.org/)
在本文中,我們探索了 23 個(gè)非常適合機(jī)器學(xué)習(xí)應(yīng)用實(shí)踐的數(shù)據(jù)集。感謝你的閱讀!
作者介紹
Nikola M. Zivkovic 是下列書(shū)籍的作者:《機(jī)器學(xué)習(xí)終極指南》和《面向程序員的深度學(xué)習(xí)》。他喜歡分享知識(shí),還是一位經(jīng)驗(yàn)豐富的演講者。他曾在許多聚會(huì)、會(huì)議上發(fā)表演講,并在諾維薩德大學(xué)擔(dān)任客座講師。
原文鏈接: https://rubikscode.net/2021/07/19/top-23-best-public-datasets-for-practicing-machine-learning
推薦閱讀
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營(yíng)維護(hù)的號(hào),大家樂(lè)于分享高質(zhì)量文章,喜歡總結(jié)知識(shí),歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!