
K8S, AI 大模型推理優(yōu)化的新選擇!
▼ 最近直播超級多, 預約 保你有收獲
今晚直播: 《 大模型Agent應(yīng)用落地實戰(zhàn) 》
— 1 —
AI 大模型訓練和推理
Docker 容器和 Kubernetes 已經(jīng)成為越來越多 AI 應(yīng)用首選的運行環(huán)境和平臺。一方面,Kubernetes 幫助用戶標準化異構(gòu)資源和運行時環(huán)境、簡化運維流程;另一方面,AI 這種重度依賴 GPU 的場景可以利用 K8S 的彈性優(yōu)勢節(jié)省資源成本。在 AIGC/大模型的這波浪潮下,以 Kubernetes 上運行 AI 應(yīng)用將變成一種事實標準。
大模型訓練和推理是企業(yè)重要應(yīng)用,但企業(yè)往往面臨著 GPU 管理復雜、資源利用率低,以及全生命周期管理中工程效率低下等挑戰(zhàn)。通過創(chuàng)建 kubernetes 集群,使用 KServe + vLLM 部署推理服務(wù)。適用于以下場景:
- 大模型訓練:基于 Kubernetes 集群微調(diào)開源大模型,可以屏蔽底層資源和環(huán)境的復雜度,快速配置訓練數(shù)據(jù)、提交訓練任務(wù),并自動運行和保存訓練結(jié)果。
- 大模型推理:基于 Kubernetes 集群部署推理服務(wù),可以屏蔽底層資源和環(huán)境的復雜度,快速將微調(diào)后的大模型部署成推理服務(wù),將大模型應(yīng)用到實際業(yè)務(wù)場景中。
- GPU 共享推理: 支持 GPU 共享調(diào)度能力和顯存隔離能力,可將多個推理服務(wù)部署在同一塊 GPU 卡上,提高 GPU 的利用率的同時,也能保證推理服務(wù)的穩(wěn)定運行。
— 2 —
vLLM 大模型推理加速器
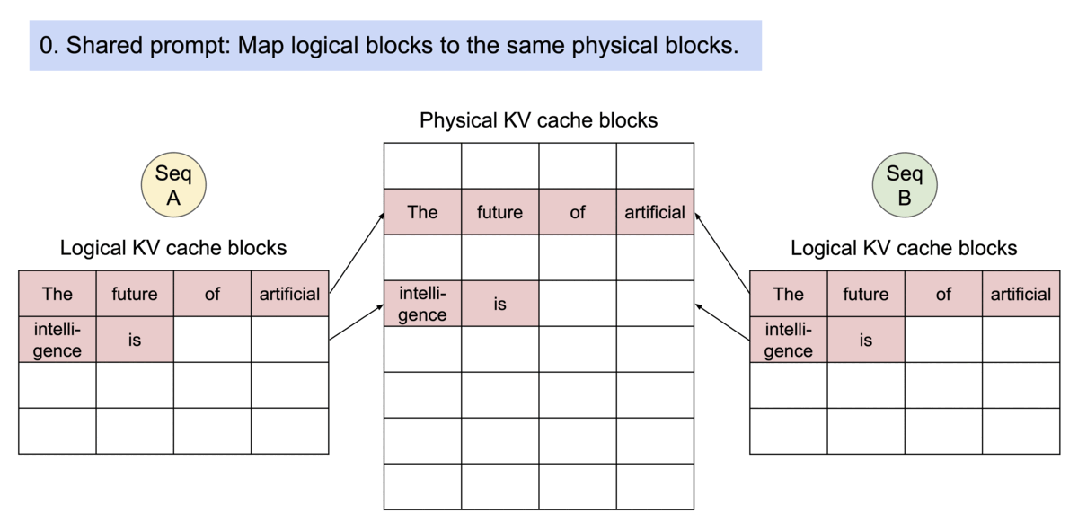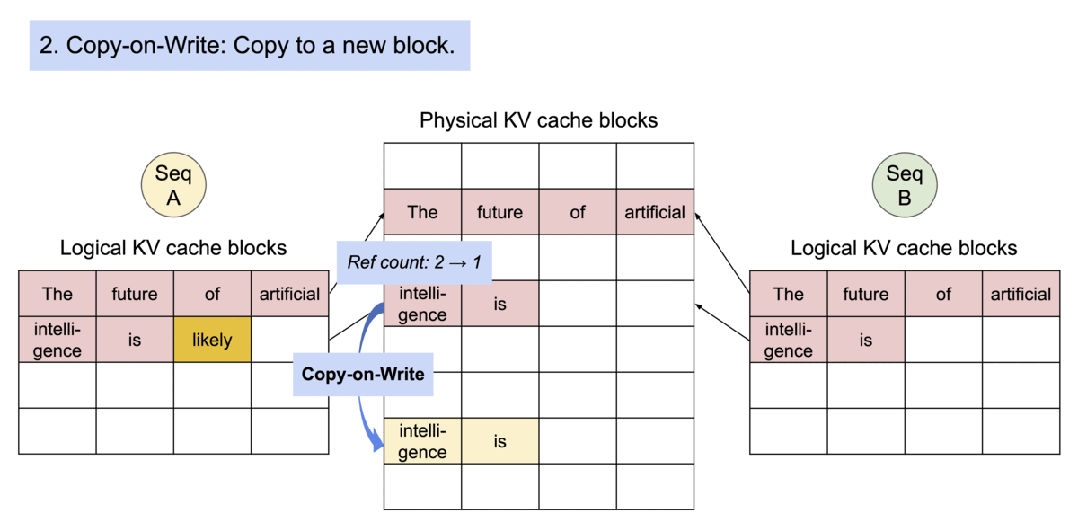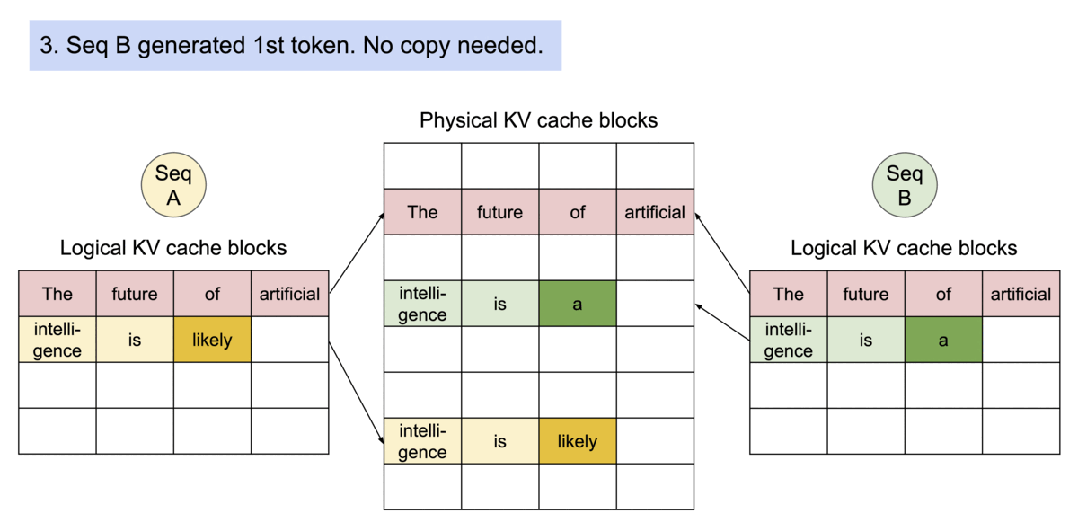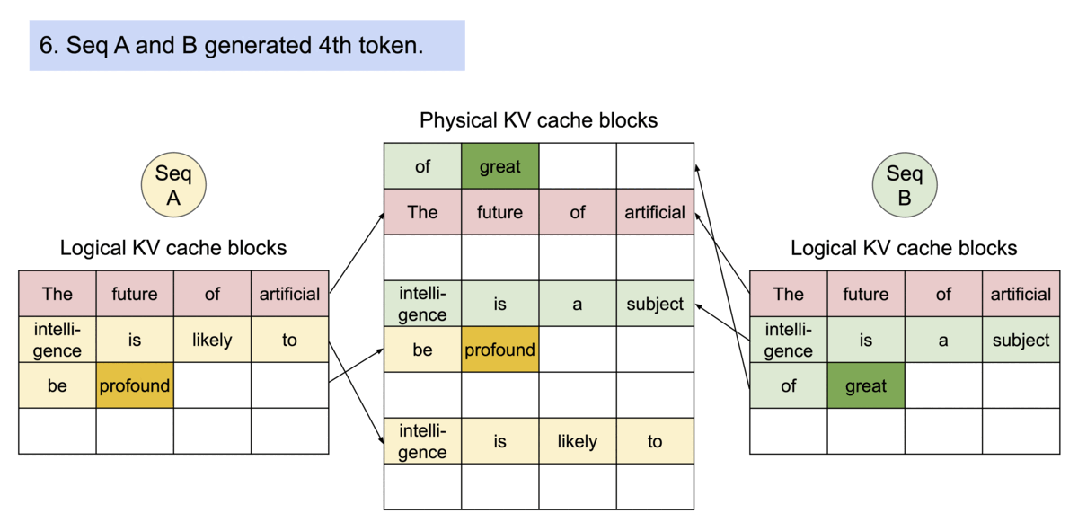
即使在高端 GPU 上,提供 LLM 模型的速度也可能出奇 的慢,平均推理速度大約5秒,vLLM 是一種快速且易于使用的 LLM 推理引擎。它可以實現(xiàn)比 Huggingface Transformer 網(wǎng)絡(luò)結(jié)構(gòu)高 10 倍甚至至 20 倍的吞吐量。它支持連續(xù)批處理以提高吞吐量和 GPU 利用率, vLLM 支持分頁注意力以解決內(nèi)存瓶頸,在自回歸解碼過程中,所有注意力鍵值張量(KV 緩存)都保留在 GPU 內(nèi)存中以生成下一個令牌。 
- vLLM 是一個快速且易于使用的 LLM 推理和服務(wù)庫。
- vLLM 支持了并行取樣,如下所示:
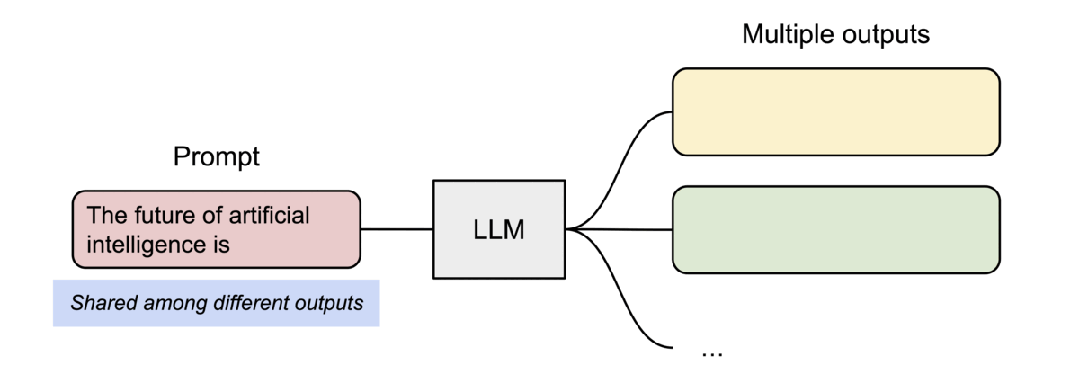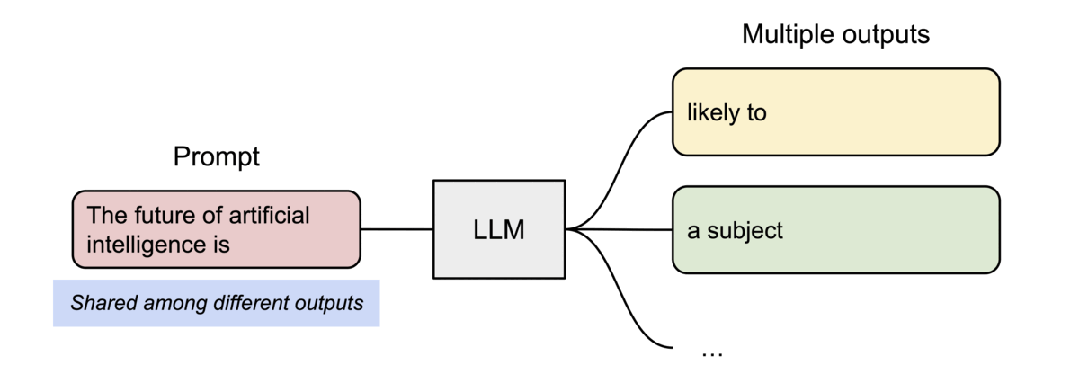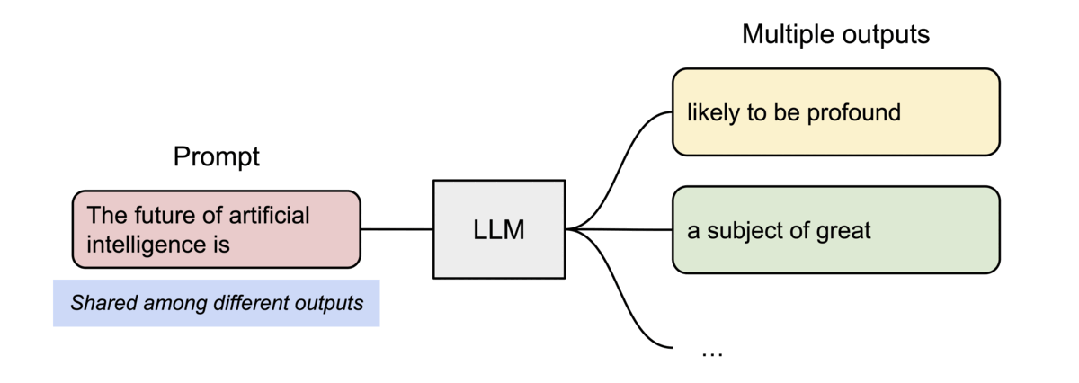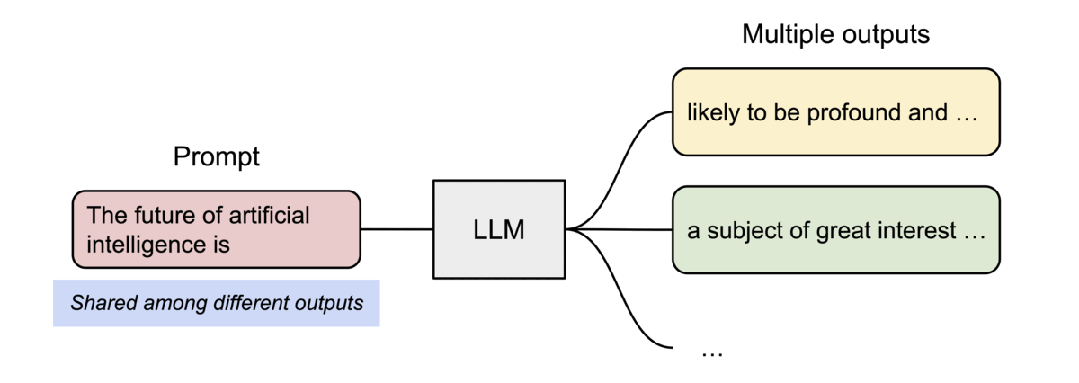
- vLLM 支持了對多個輸出進行采樣,如下所示:
— 3 —
KServe 大模型推理平臺
KServe 是一個與云無關(guān)的標準大模型推理平臺,專為大模型應(yīng)用高度可擴展而構(gòu)建,KServe 封裝了自動擴展、網(wǎng)絡(luò)、健康檢查和服務(wù)器配置的復雜性,為 大模型應(yīng)用部署帶來了 GPU 自動擴展、零擴縮放和金絲雀發(fā)布等先進的服務(wù)特性。它使得生產(chǎn)大模型應(yīng)用服務(wù)變得簡單、可插拔,它提供了以下特性: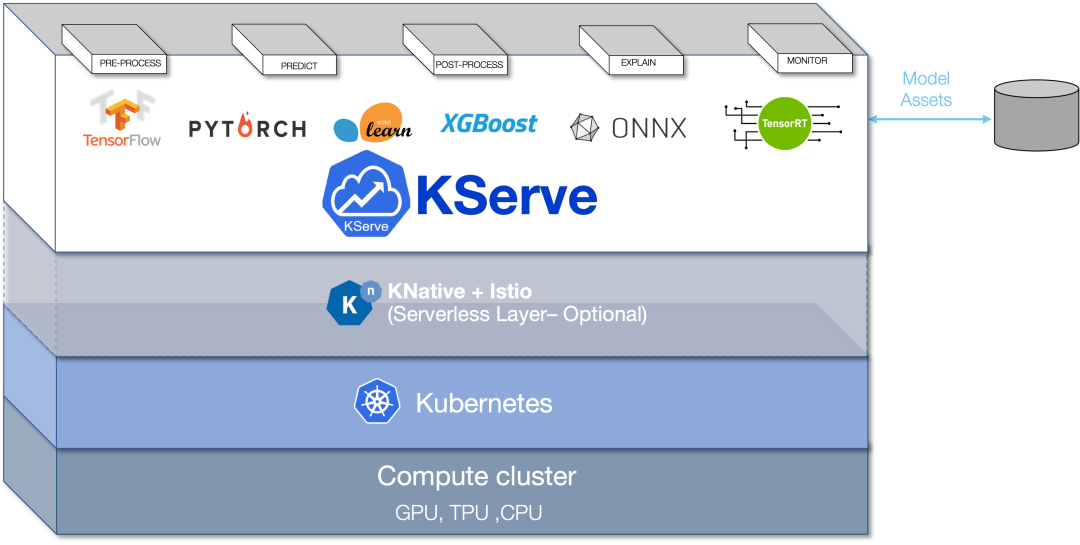
- 跨機器學習框架,提供高性能標準化推理協(xié)議。
- 支持現(xiàn)代無服務(wù)器推理工作負載,具有基于請求在 CPU 和 GPU 的自動縮放(包括縮放至零)。
- 使用ModelMesh 支持 高可擴展性、密度封裝和智能路由。
- 簡單且可插入的生產(chǎn)服務(wù): 用于推理、預/后處理、監(jiān)控和可解釋性。
- 高級部署: 金絲雀部署、Pipeline、InferenceGraph。
—4 —
領(lǐng)取《AI 大模型技術(shù)直播》
我們梳理了下 AI 大模型應(yīng)用開發(fā)的知識圖譜,包括12項核心技能: 大模型內(nèi)核架構(gòu)、大模型開發(fā) API、開發(fā)框架、向量數(shù)據(jù)庫、AI 編程、AI Agent、緩存、算力、RAG、大模型微調(diào)、大模型預訓練、LLMOps 等。 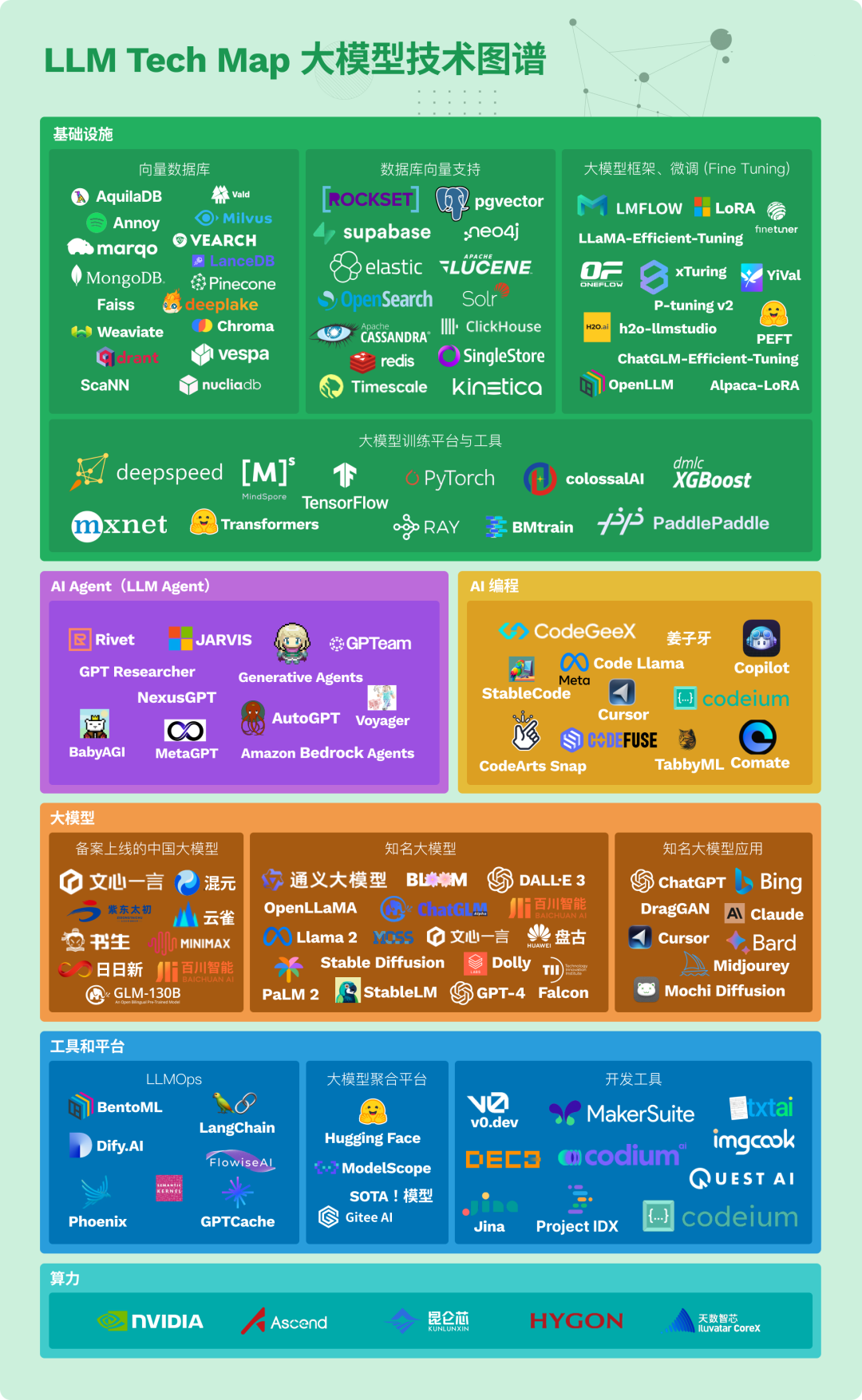
END
評論
圖片
表情