
大模型推理再提速!英偉達(dá)推出TensorRT-LLM,專為提升大模型推理速度優(yōu)化的全新框架
本文來自DataLearner官方博客:
https://www.datalearner.com/blog/1051694310279358
隨著大型語言模型(LLM)如 GPT-3 和 BERT 在 AI 領(lǐng)域的崛起,如何在實(shí)際應(yīng)用中高效地進(jìn)行模型推斷成為了一個(gè)關(guān)鍵問題。為此,英偉達(dá)推出了全新的大模型推理提速框架TensorRT-LM,可以將現(xiàn)有的大模型在H100推理速度提升4倍!2016年,英偉達(dá)已經(jīng)推出了TensorRT,此次發(fā)布的TensorRT-LM是在TensorRT基礎(chǔ)上針對大模型進(jìn)一步優(yōu)化的加速推理庫。
TensorRT簡介
TensorRT-LLM簡介
TensorRT-LLM的加速結(jié)果測試
TensorRT簡介
TensorRT是英偉達(dá)的一個(gè)深度學(xué)習(xí)模型優(yōu)化器和運(yùn)行時(shí)庫,它可以將深度學(xué)習(xí)模型轉(zhuǎn)換為優(yōu)化的格式,從而在英偉達(dá)GPU上實(shí)現(xiàn)更快的推斷速度。TensorRT的第一個(gè)版本是在2016年11月發(fā)布的,當(dāng)時(shí)叫做GPU Inference Engine (GIE)。后來在2017年3月,英偉達(dá)將其改名為TensorRT,并發(fā)布了TensorRT 2.0版本。從那以后,英偉達(dá)一直不斷更新和改進(jìn)TensorRT。
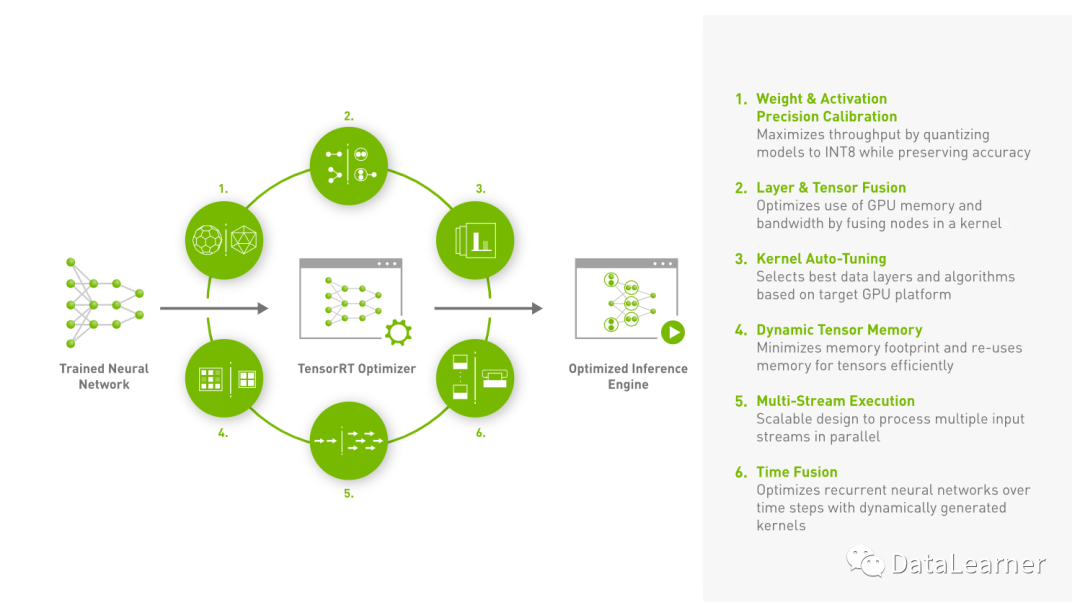
上圖是英偉達(dá)官方針對TensorRT的示意圖,可以看到,TensorRT定位的是將訓(xùn)練結(jié)束的模型優(yōu)化達(dá)到加速目的,因此與你使用的訓(xùn)練框架和訓(xùn)練過程不強(qiáng)相關(guān)。TensorRT通過自動(dòng)識別可以合并的連續(xù)層,并將它們?nèi)诤铣梢粋€(gè)操作。這減少了在 GPU 上的操作數(shù)量,從而提高了執(zhí)行速度。
TensorRT-LLM簡介
TensorRT 是 NVIDIA 的一個(gè)深度學(xué)習(xí)模型優(yōu)化器和運(yùn)行時(shí)庫,旨在為深度學(xué)習(xí)模型在 NVIDIA GPU 上提供快速、高效的推斷。而 TensorRT-LLM 則是其針對大型語言模型的擴(kuò)展,提供了一系列專門的優(yōu)化和功能。
隨著 LLM 的模型參數(shù)數(shù)量不斷增加,傳統(tǒng)的推斷方法在性能和成本上都面臨挑戰(zhàn)。TensorRT-LLM 提供了一種方法,可以在保持模型準(zhǔn)確性的同時(shí),大大提高推斷速度并降低成本。
TensorRT-LLM 首先解析模型結(jié)構(gòu),然后應(yīng)用一系列優(yōu)化技術(shù),如層融合、精度校準(zhǔn)和內(nèi)核選擇。它還利用了并行化技術(shù),如張量并行性,以在多個(gè) GPU 之間分配模型的不同部分。
根據(jù)官方的說明,TensorRT-LLM的主要特點(diǎn):
專為 LLM 設(shè)計(jì):與標(biāo)準(zhǔn)的 TensorRT 不同,TensorRT-LLM 針對大型語言模型的特定需求和挑戰(zhàn)進(jìn)行了優(yōu)化。
集成優(yōu)化:NVIDIA 與多家領(lǐng)先公司合作,將這些優(yōu)化集成到了 TensorRT-LLM 中,以確保 LLM 在 NVIDIA GPU 上的最佳性能。
模塊化 Python API:TensorRT-LLM 提供了一個(gè)開源的模塊化 Python API,使開發(fā)者能夠輕松定義、優(yōu)化和執(zhí)行新的 LLM 架構(gòu)和增強(qiáng)功能。
飛行批處理(In-flight batching):這是一種優(yōu)化的調(diào)度技術(shù),可以更有效地處理動(dòng)態(tài)負(fù)載。它允許 TensorRT-LLM 在其他請求仍在進(jìn)行時(shí)開始執(zhí)行新請求,從而提高 GPU 利用率。
支持新的 FP8 數(shù)據(jù)格式:在 H100 GPU 上,TensorRT-LLM 支持新的 FP8 數(shù)據(jù)格式,這可以大大減少內(nèi)存消耗,同時(shí)保持模型的準(zhǔn)確性。
廣泛的模型支持:TensorRT-LLM 包括了許多在今天生產(chǎn)中廣泛使用的 LLM 的完全優(yōu)化、即用版本,如 Meta Llama 2、OpenAI GPT-2 和 GPT-3 等。
并行化和分布式推斷:TensorRT-LLM 利用張量并行性進(jìn)行模型并行化,這使得模型可以在多個(gè) GPU 之間并行運(yùn)行,從而實(shí)現(xiàn)大型模型的高效推斷。
優(yōu)化的內(nèi)核和操作:TensorRT-LLM 包括了針對 LLM 的優(yōu)化內(nèi)核和操作,如 FlashAttention 和遮蔽多頭注意力等。
簡化的開發(fā)流程:TensorRT-LLM 旨在簡化 LLM 的開發(fā)和部署過程,使開發(fā)者無需深入了解底層的技術(shù)細(xì)節(jié)。
TensorRT-LLM的加速結(jié)果測試
官方給出了GPT-J 6B在TensorRT-LLM加持下的模型推理速度提升結(jié)果,如下圖所示:
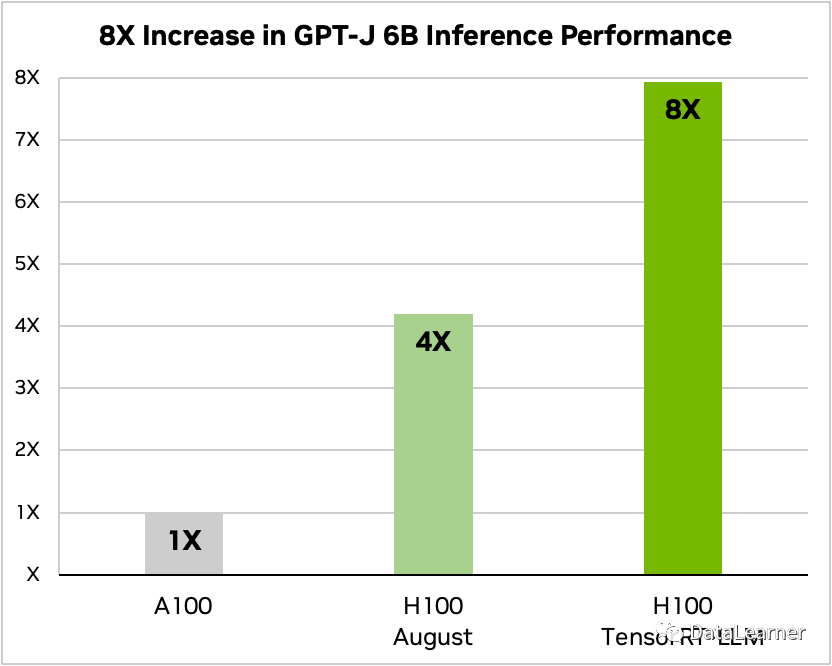
GPT-J 6B是一個(gè)由EleutherAI研究小組創(chuàng)建的開源自回歸語言模型。它是OpenAI的GPT-3的最先進(jìn)替代品之一,在各種自然語言任務(wù)(如聊天、摘要和問答等)方面表現(xiàn)良好。
上圖使用A100作為GPT-J 6B的推理速度基準(zhǔn),H100的推理速度是A100的4倍,而使用了TensorRT-LLM之后的H100推理速度是A100的8倍!提升速度驚人!
而LLaMA2也有很高的速度提升,如下圖所示:
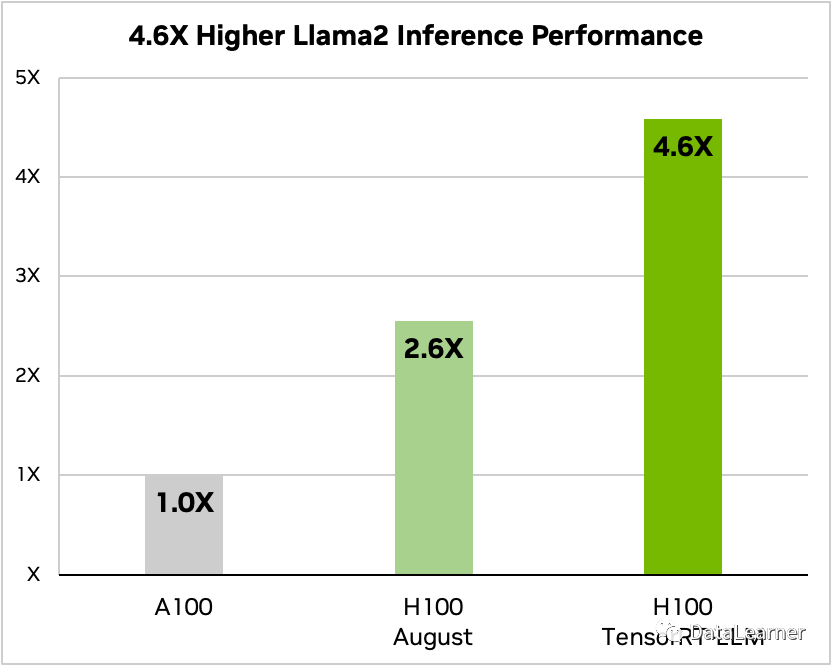
使用A100作為LLaMA2 7B的推理速度(文本摘要)基準(zhǔn),H100的推理速度是A100的2.6倍,而使用了TensorRT-LLM之后的H100推理速度是A100的4.6倍!提升速度也是非常驚人!
目前TensorRT-LLM屬于早期預(yù)覽,只要注冊成為NVIDIA開發(fā)者即可申請使用~
號外!