
哪個更好:一個通用模型還是多個專用模型?
 大數(shù)據(jù)文摘授權(quán)轉(zhuǎn)載自數(shù)據(jù)派THU
作者:Samuele Mazzanti
翻譯:歐陽錦
校對:趙茹萱
大數(shù)據(jù)文摘授權(quán)轉(zhuǎn)載自數(shù)據(jù)派THU
作者:Samuele Mazzanti
翻譯:歐陽錦
校對:趙茹萱
我最近聽到一家公司宣稱:“我們在生產(chǎn)中有60個流失模型。”(注:流失模型是一種通過數(shù)學(xué)來建模流失對業(yè)務(wù)的影響。)我問他們?yōu)槭裁催@么多。他們回答說,他們擁有 5 個品牌,在 12 個國家/地區(qū)運(yùn)營,并且由于他們想為每個品牌和國家/地區(qū)的組合開發(fā)一種模型,因此共計 60 種模型。于是,我問他們:“你試過只用一種模型嗎?”?
他們認(rèn)為這沒有意義,因?yàn)樗麄兊钠放票舜酥g非常不同,他們經(jīng)營的目標(biāo)國家也是如此:“你不能訓(xùn)練一個單一的模型并期望它對品牌 A 的美國客戶和對品牌 B 的德國客戶”。
由于在業(yè)內(nèi)經(jīng)常聽到這樣的說法,我很好奇這個論點(diǎn)是否反映在數(shù)據(jù)中,或者只是沒有事實(shí)支持的猜測。
這就是為什么在本文中,我將系統(tǒng)地比較兩種方法:
- 將所有數(shù)據(jù)提供給一個模型,也就是一個通用模型(general model);
- 為每個細(xì)分市場構(gòu)建一個模型(在前面的示例中,品牌和國家/地區(qū)的組合),也就是許多專業(yè)模型(specialized models)。
我將在流行的Python庫Pycaret提供的12個真實(shí)數(shù)據(jù)集上測試這兩種策略。
通用模型與專用模型
這兩種方法究竟是如何工作的?
假設(shè)我們有一個數(shù)據(jù)集。數(shù)據(jù)集由預(yù)測變量矩陣(稱為X)和目標(biāo)變量(稱為y)組成。此外,X包含一個或多個可用于分割數(shù)據(jù)集的列(在前面的示例中,這些列是“品牌”和“國家/地區(qū)”)。
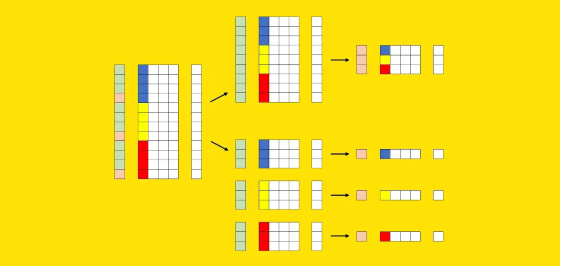
現(xiàn)在讓我們嘗試以圖形方式表示這些元素。我們可以使用X的其中一列來可視化這些段:每種顏色(藍(lán)色、黃色和紅色)標(biāo)識不同的段。我們還需要一個額外的向量來表示訓(xùn)練集(綠色)和測試集(粉色)的劃分。

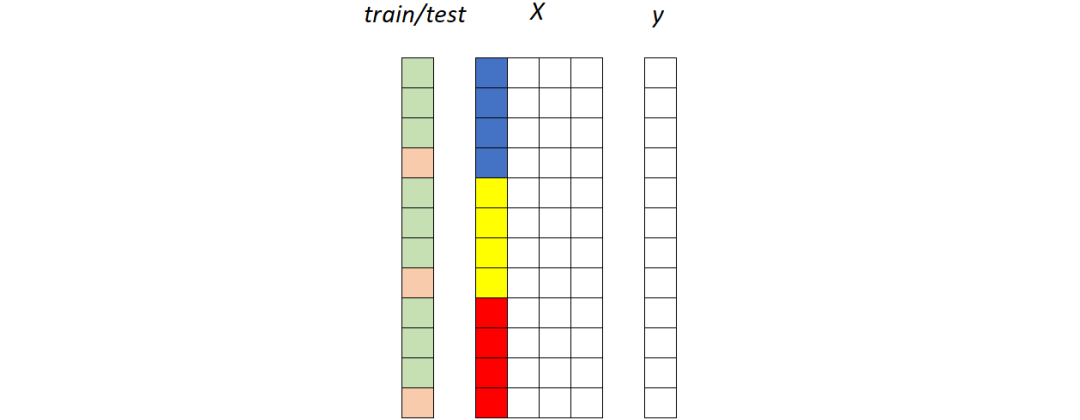 訓(xùn)練集的行標(biāo)記為綠色,而測試集的行標(biāo)記為粉紅色。X 的彩色列是分段列:每種顏色標(biāo)識不同的分段(例如,藍(lán)色是美國,黃色是英國,紅色是德國)。圖源作者。
訓(xùn)練集的行標(biāo)記為綠色,而測試集的行標(biāo)記為粉紅色。X 的彩色列是分段列:每種顏色標(biāo)識不同的分段(例如,藍(lán)色是美國,黃色是英國,紅色是德國)。圖源作者。
鑒于這些要素,以下是這兩種方法的不同之處。
第一種策略:通用模型
在整個訓(xùn)練集上擬合一個獨(dú)特的模型,然后在整個測試集上測量其性能:
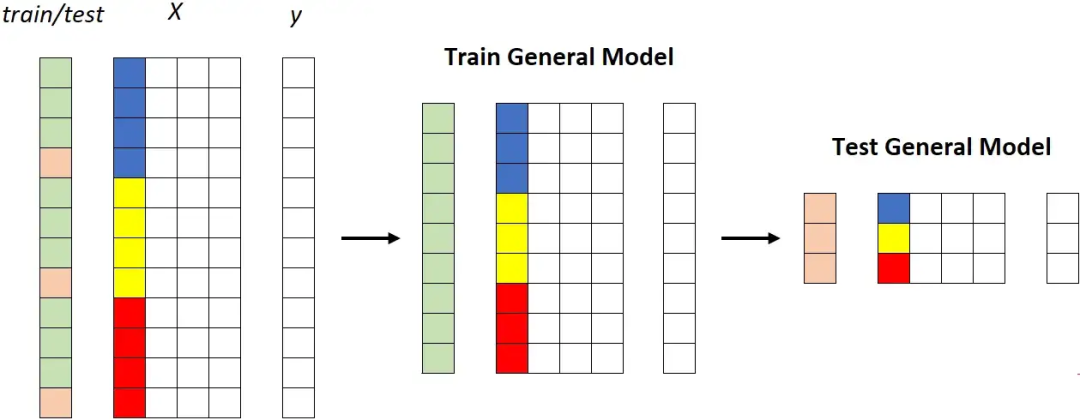 通用模型。所有片段(藍(lán)色、黃色和紅色)都被饋送到同一個模型。圖源作者
通用模型。所有片段(藍(lán)色、黃色和紅色)都被饋送到同一個模型。圖源作者
第二個策略:專業(yè)模型
第二種策略涉及為每個段建立模型,這意味著重復(fù)訓(xùn)練/測試過程k次(其中k是片段數(shù),在本例中為 3)。
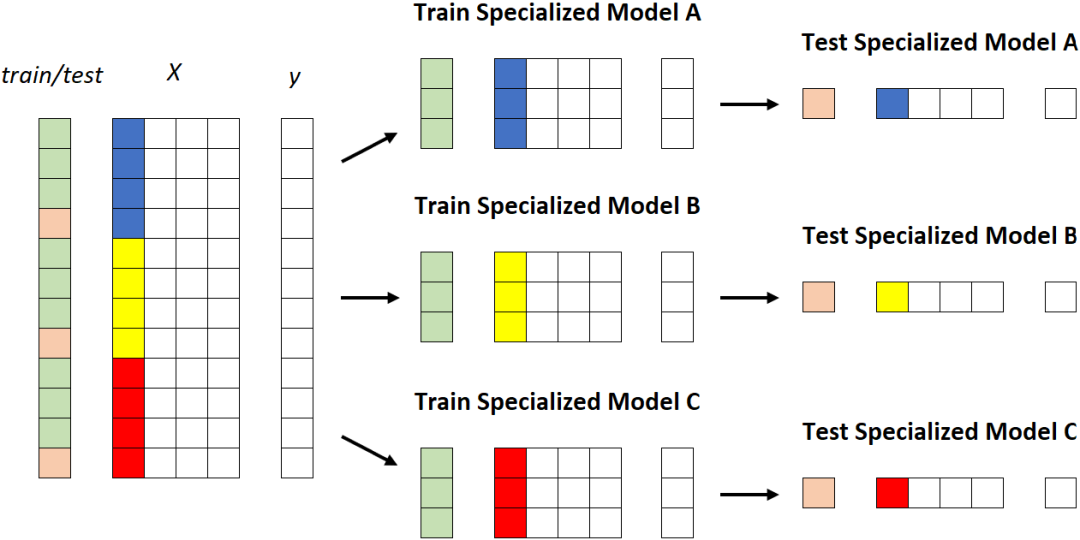 專用模型。每個段被饋送到不同的模型。[作者圖片]
專用模型。每個段被饋送到不同的模型。[作者圖片]
請注意,在實(shí)際用例中,分段的數(shù)量可能是相關(guān)的,從幾十個到數(shù)百個不等。因此,與使用一個通用模型相比,使用專用模型存在幾個實(shí)際缺點(diǎn),例如:
- 更高的維護(hù)工作量;
- 更高的系統(tǒng)復(fù)雜度;
- 更高的(累積的)培訓(xùn)時間;
- 更高的計算成本:
- 更高的存儲成本。
那么,為什么會有人想要這樣做呢?
對通用模型的偏見
專用模型的支持者聲稱,獨(dú)特的通用模型在給定的細(xì)分市場(比如美國客戶)上可能不太精確,因?yàn)樗€了解了不同細(xì)分市場(例如歐洲客戶)的特征。
我認(rèn)為這是因使用簡單模型(例如邏輯回歸)而產(chǎn)生的錯誤認(rèn)識。讓我用一個例子來解釋。
假設(shè)我們有一個汽車數(shù)據(jù)集,由三列組成:
- 汽車類型(經(jīng)典或現(xiàn)代);
- 汽車時代;
- 車價。
我們想使用前兩個特征來預(yù)測汽車價格。這些是數(shù)據(jù)點(diǎn):
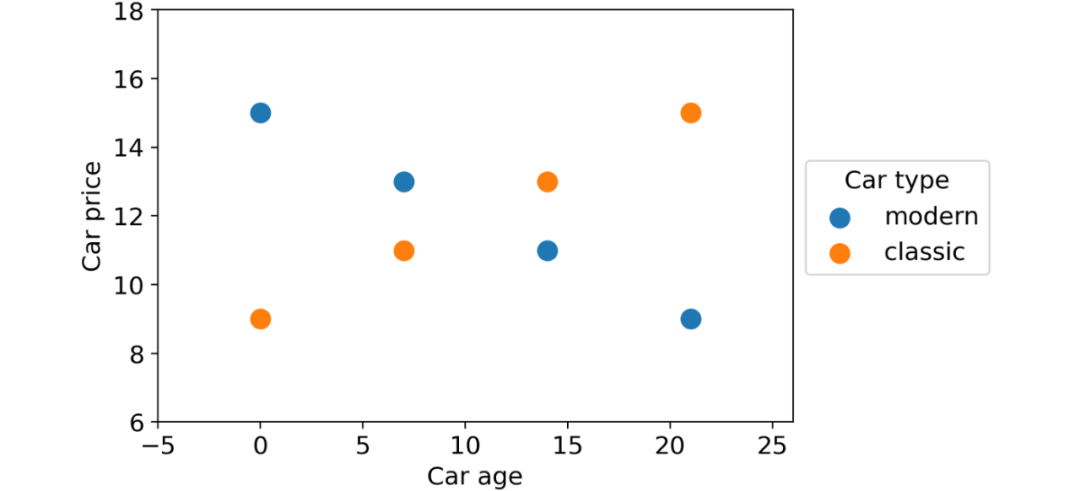 具有兩個部分(經(jīng)典汽車和現(xiàn)代汽車)的數(shù)據(jù)集,顯示出與目標(biāo)變量相關(guān)的非常不同的行為。圖源作者
具有兩個部分(經(jīng)典汽車和現(xiàn)代汽車)的數(shù)據(jù)集,顯示出與目標(biāo)變量相關(guān)的非常不同的行為。圖源作者
如您所見,根據(jù)汽車類型,有兩種完全不同的行為:隨著時間的推移,現(xiàn)代汽車貶值,而老爺車價格上漲。
現(xiàn)在,如果我們在完整數(shù)據(jù)集上訓(xùn)練線性回歸:
linear_regression?=?LinearRegression().fit(df[[?"car_type_classic"?,?"car_age"?]],?df[?"car_price"?]
得到的系數(shù)是:
?
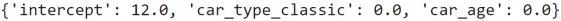 在數(shù)據(jù)集上訓(xùn)練的線性回歸系數(shù)。圖源作者
在數(shù)據(jù)集上訓(xùn)練的線性回歸系數(shù)。圖源作者
這意味著模型將始終為任何輸入預(yù)測相同的值12。
通常,如果數(shù)據(jù)集包含不同的行為(除非您進(jìn)行額外的特征工程),簡單模型將無法正常工作。因此,在這種情況下,人們可能會想訓(xùn)練兩種專門的模型:一種用于經(jīng)典汽車,一種用于現(xiàn)代汽車。
但是讓我們看看如果我們使用決策樹而不是線性回歸會發(fā)生什么。為了使比較公平,我們將生成一棵有3個分支的樹(即3個決策閾值),因?yàn)榫€性回歸也有3個參數(shù)(3個系數(shù))。
decision_tree = DecisionTreeRegressor(max_depth= 2 ).fit(df[
[ "car_type_classic" , "car_age" ]], df[ "car_price" ])
這是結(jié)果:
?
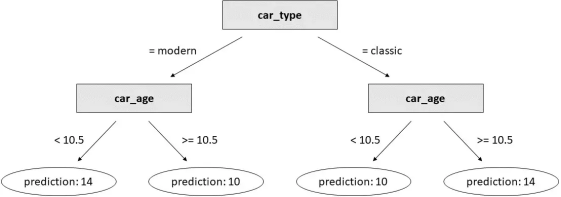 在玩具數(shù)據(jù)集上訓(xùn)練的決策樹。[作者圖片]
在玩具數(shù)據(jù)集上訓(xùn)練的決策樹。[作者圖片]
這比我們用線性回歸得到的結(jié)果要好得多!
關(guān)鍵是基于樹的模型(例如 XGBoost、LightGBM 或 Catboost)能夠處理不同的行為,因?yàn)樗鼈兲焐涂梢院芎玫靥幚硖卣鹘换ァ?/span>
這就是為什么在理論上沒有理由比一個通用模型更喜歡幾個專用模型的主要原因。但是,一如既往,我們并不滿足于理論解釋。我們還想確保這一猜想得到真實(shí)數(shù)據(jù)的支持。
實(shí)驗(yàn)細(xì)節(jié)
在本段中,我們將看到測試哪種策略效果更好所需的 Python 代碼。如果您對細(xì)節(jié)不感興趣,可以直接跳到下一段,我將在這里討論結(jié)果。
我們的目標(biāo)是定量比較兩種策略:
- 訓(xùn)練一個通用模型;
- 訓(xùn)練許多個專用模型。
比較它們的最明顯方法如下:
1. 獲取數(shù)據(jù)集; 2. 根據(jù)一列的值選擇數(shù)據(jù)集的一部分; 3. 將數(shù)據(jù)集拆分為訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集; 4. 在整個訓(xùn)練數(shù)據(jù)集上訓(xùn)練通用模型; 5. 在屬于該段的訓(xùn)練數(shù)據(jù)集部分上訓(xùn)練專用模型; 6. 比較通用模型和專用模型在屬于該段的測試數(shù)據(jù)集部分上的性能。
圖形化:
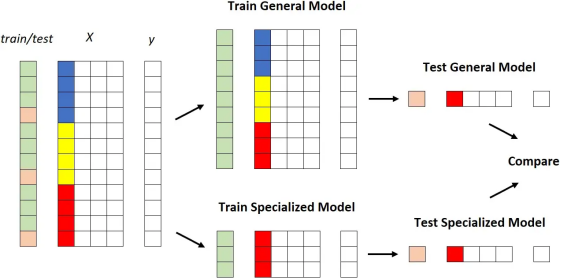 X 中的彩色列是我們用來對數(shù)據(jù)集進(jìn)行分層的列。[作者圖片]
X 中的彩色列是我們用來對數(shù)據(jù)集進(jìn)行分層的列。[作者圖片]
這工作得很好,但是,由于我們不想被隨機(jī)性愚弄,我們將重復(fù)這個過程:
- 對于不同的數(shù)據(jù)集;
- 使用不同的列來分割數(shù)據(jù)集本身;
- 使用同一列的不同值來定義段。
換句話說,這就是我們要用偽代碼做的:
for each dataset:
train general model on the training set
for each column of the dataset:
for each value of the column:
train specialized model on the portion of the training set for which column = value
compare performance of general model vs. specialized model
實(shí)際上,我們需要對這個過程做一些微小的調(diào)整。
首先,我們說過我們正在使用數(shù)據(jù)集的列來分割數(shù)據(jù)集本身。這適用于分類列和具有很少值的離散數(shù)字列。對于剩余的數(shù)字列,我們必須通過分箱(binning)使它們分類。
其次,我們不能簡單地使用所有的列。如果我們這樣做,我們將會懲罰專用模型。事實(shí)上,如果我們根據(jù)與目標(biāo)變量無關(guān)的列選擇細(xì)分,就沒有理由相信專門的模型可以表現(xiàn)得更好。為避免這種情況,我們將只使用與目標(biāo)變量有某種關(guān)系的列。
此外,出于類似的原因,我們不會使用所有細(xì)分列的值。我們將避免過于頻繁(超過50%)的值,因?yàn)槠谕诖蠖鄶?shù)數(shù)據(jù)集上訓(xùn)練的模型與在完整數(shù)據(jù)集上訓(xùn)練的模型具有不同的性能是沒有意義的。我們還將避免測試集中少于100個案例的值,因?yàn)榻Y(jié)果肯定不會很重要。
鑒于此,這是我使用的完整代碼:
for dataset_name in tqdm(dataset_names):
# get data
y, num_features, cat_features, n_classes = get_dataset(dataset_name)
# split index in training and test set, then train general model on the training set
ix_test = train_test_split(X.index, test_size=.25, stratify=y)
model_general = CatBoostClassifier().fit(X=X.loc[ix_train,:], y=y.loc[ix_train], cat_features=cat_features, silent=True)
pred_general = pd.DataFrame(model_general.predict_proba(X.loc[ix_test, :]), index=ix_test, columns=model_general.classes_)
# create a dataframe where all the columns are categorical:
# numerical columns with more than 5 unique values are binnized
X_cat = X.copy()
:, num_features] = X_cat.loc[:, num_features].fillna(X_cat.loc[:, num_features].median()).apply(lambda col: col if col.nunique() <= 5 else binnize(col))
# get a list of columns that are not (statistically) independent
# from y according to chi 2 independence test
candidate_columns = get_dependent_columns(X_cat, y)
for segmentation_column in candidate_columns:
# get a list of candidate values such that each candidate:
# - has at least 100 examples in the test set
# - is not more common than 50%
vc_test = X_cat.loc[ix_test, segmentation_column].value_counts()
nu_train = y.loc[ix_train].groupby(X_cat.loc[ix_train, segmentation_column]).nunique()
nu_test = y.loc[ix_test].groupby(X_cat.loc[ix_test, segmentation_column]).nunique()
candidate_values = vc_test[(vc_test>=100) & (vc_test/len(ix_test)<.5) & (nu_train==n_classes) & (nu_test==n_classes)].index.to_list()
for value in candidate_values:
# split index in training and test set, then train specialized model
# on the portion of the training set that belongs to the segment
ix_value = X_cat.loc[X_cat.loc[:, segmentation_column] == value, segmentation_column].index
ix_train_specialized = list(set(ix_value).intersection(ix_train))
ix_test_specialized = list(set(ix_value).intersection(ix_test))
model_specialized = CatBoostClassifier().fit(X=X.loc[ix_train_specialized,:], y=y.loc[ix_train_specialized], cat_features=cat_features, silent=True)
pred_specialized = pd.DataFrame(model_specialized.predict_proba(X.loc[ix_test_specialized, :]), index=ix_test_specialized, columns=model_specialized.classes_)
# compute roc score of both the general model and the specialized model and save them
roc_auc_score_general = get_roc_auc_score(y.loc[ix_test_specialized], pred_general.loc[ix_test_specialized, :])
roc_auc_score_specialized = get_roc_auc_score(y.loc[ix_test_specialized], pred_specialized)
=?results.append(pd.Series(data=[dataset_name,?segmentation_column,?value,?len(ix_test_specialized),?y.loc[ix_test_specialized].value_counts().to_list(),?roc_auc_score_general,?roc_auc_score_specialized],index=results.columns),ignore_index=True
為了便于理解,我省略了一些實(shí)用函數(shù)的代碼,get_dataset例如get_dependent_columns和get_roc_auc_score。但是,您可以在此GitHub存儲庫中找到完整代碼。
結(jié)果
為了對通用模型與專用模型進(jìn)行大規(guī)模比較,我使用了Pycaret(MIT許可下的 Python庫)中提供的12個真實(shí)世界數(shù)據(jù)集。
對于每個數(shù)據(jù)集,我發(fā)現(xiàn)列與目標(biāo)變量顯示出一些顯著關(guān)系(獨(dú)立性卡方檢驗(yàn)的p值<1%)。對于任何一列,我只保留不太罕見(它們必須在測試集中至少有100個案例)或過于頻繁(它們必須占數(shù)據(jù)集的比例不超過50%)的值。這些值中的每一個都標(biāo)識數(shù)據(jù)集的一個片段。
對于每個數(shù)據(jù)集,我在整個訓(xùn)練數(shù)據(jù)集上訓(xùn)練了一個通用模型(CatBoost,沒有參數(shù)調(diào)整)。然后,對于每個片段,我在屬于相應(yīng)片段的訓(xùn)練數(shù)據(jù)集部分上訓(xùn)練了一個專門的模型(同樣是CatBoost,沒有參數(shù)調(diào)整)。最后,我比較了兩種方法在屬于該段的測試數(shù)據(jù)集部分上的性能(ROC曲線下的面積)。
讓我們看一下最終輸出:
?
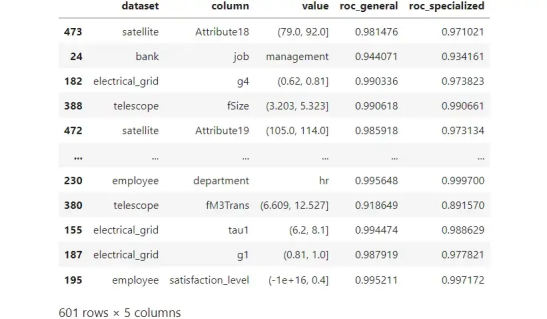 12 個真實(shí)數(shù)據(jù)集的模擬結(jié)果。每行都是一個段,由數(shù)據(jù)集、列和值的組合標(biāo)識。圖源作者。
12 個真實(shí)數(shù)據(jù)集的模擬結(jié)果。每行都是一個段,由數(shù)據(jù)集、列和值的組合標(biāo)識。圖源作者。
原則上,要選出獲勝者,我們可以只看“roc_general”和“roc_specialized”之間的區(qū)別。然而,在某些情況下,這種差異可能是偶然的。因此,我也計算了差異何時具有統(tǒng)計顯著性(有關(guān)如何判斷兩個ROC分?jǐn)?shù)之間的差異是否顯著的詳細(xì)信息,請參閱本文)。
因此,我們可以在兩個維度上對601比較進(jìn)行分類:通用模型是否優(yōu)于專用模型以及這種差異是否顯著。這是結(jié)果:
?
 601 比較的總結(jié)。“general > specialized”表示通用模型的ROC曲線下面積高于專用模型,“specialized > general”則相反。“顯著”/“不顯著”表明這種差異是否顯著。圖源作者。
601 比較的總結(jié)。“general > specialized”表示通用模型的ROC曲線下面積高于專用模型,“specialized > general”則相反。“顯著”/“不顯著”表明這種差異是否顯著。圖源作者。
很容易看出,通用模型在89%的時間(454+83/601)優(yōu)于專用模型。但是,如果我們堅持重要的案例,一般模型在95%的時間(87個中的83個)優(yōu)于專用模型。
出于好奇,我們也將87個重要案例可視化為一個圖表,x軸為專用模型的ROC分?jǐn)?shù),y軸為通用模型的ROC分?jǐn)?shù)。
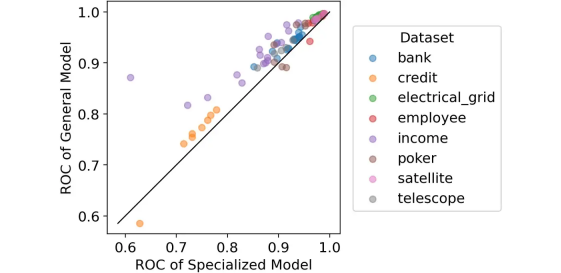 比較:專用模型的 ROC 與通用模型的 ROC。僅包括顯示出顯著差異的部分。圖源作者。
比較:專用模型的 ROC 與通用模型的 ROC。僅包括顯示出顯著差異的部分。圖源作者。
對角線上方的所有點(diǎn)都標(biāo)識了通用模型比專用模型表現(xiàn)更好的情況。
但是,更好在哪里?
我們可以計算兩個ROC分?jǐn)?shù)之間的平均差。事實(shí)證明,在87個顯著案例中,通用模型的 ROC 平均比專用模型高2.4%,這是很多!
結(jié)論
在本文中,我們比較了兩種策略:使用在整個數(shù)據(jù)集上訓(xùn)練的通用模型與使用專門針對數(shù)據(jù)集不同部分的許多模型。
我們已經(jīng)看到,沒有令人信服的理由使用專用模型,因?yàn)閺?qiáng)大的算法(例如基于樹的模型)可以在本地處理不同的行為。此外,從維護(hù)工作、系統(tǒng)復(fù)雜性、訓(xùn)練時間、計算成本和存儲成本的角度來看,使用專用模型涉及到幾個實(shí)際的復(fù)雜問題。
我們還在12個真實(shí)數(shù)據(jù)集上測試了這兩種策略,總共有601個可能的片段。在這個實(shí)驗(yàn)中,通用模型在89%的時間里優(yōu)于專用模型。只看具有統(tǒng)計顯著性的案例,這個數(shù)字上升到95%,ROC得分平均提高2.4%。
您可以在這個GitHub存儲庫中找到本文使用的所有Python代碼。
原文標(biāo)題: What Is Better: One General Model or Many Specialized Models? 原文鏈接:
https://towardsdatascience.com/what-is-better-one-general-model-or-many-specialized-models-9500d9f8751d??
 點(diǎn)「在看」的人都變好看了哦!
點(diǎn)「在看」的人都變好看了哦!
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>