
炸裂:PDF表格提取Excel算法開源啦

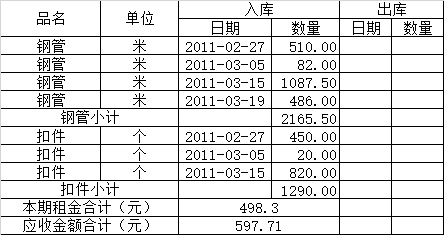
這種情況下你會怎么做呢,新建一個Excel一個一個數(shù)據(jù)敲么,辛辛苦苦半天趕出來,領(lǐng)導還會來一句,怎么這么慢,簡直郁悶死……

效果展示
版面分析+表格識別
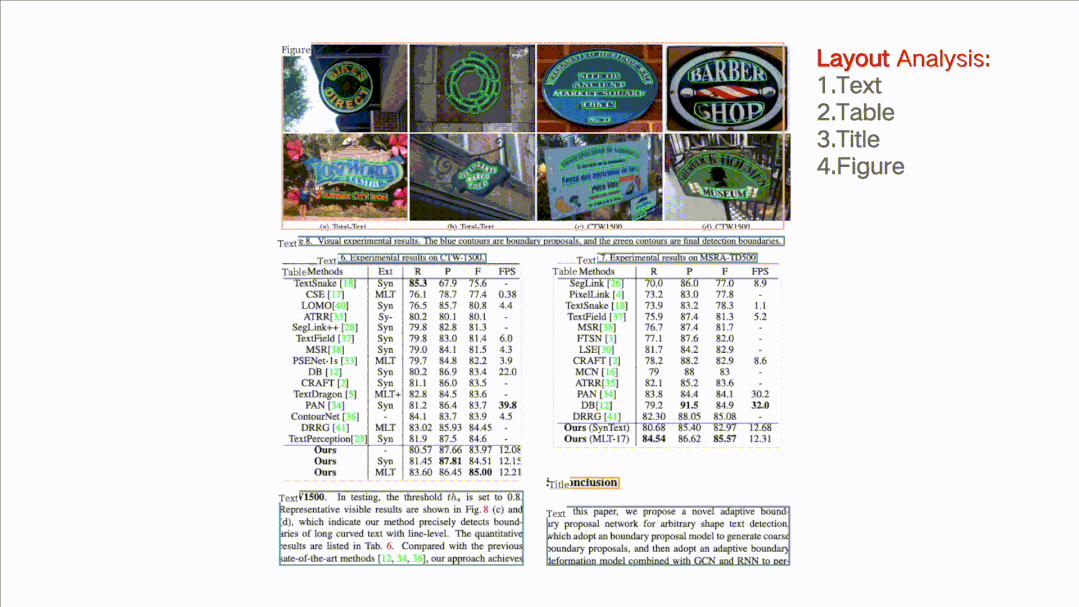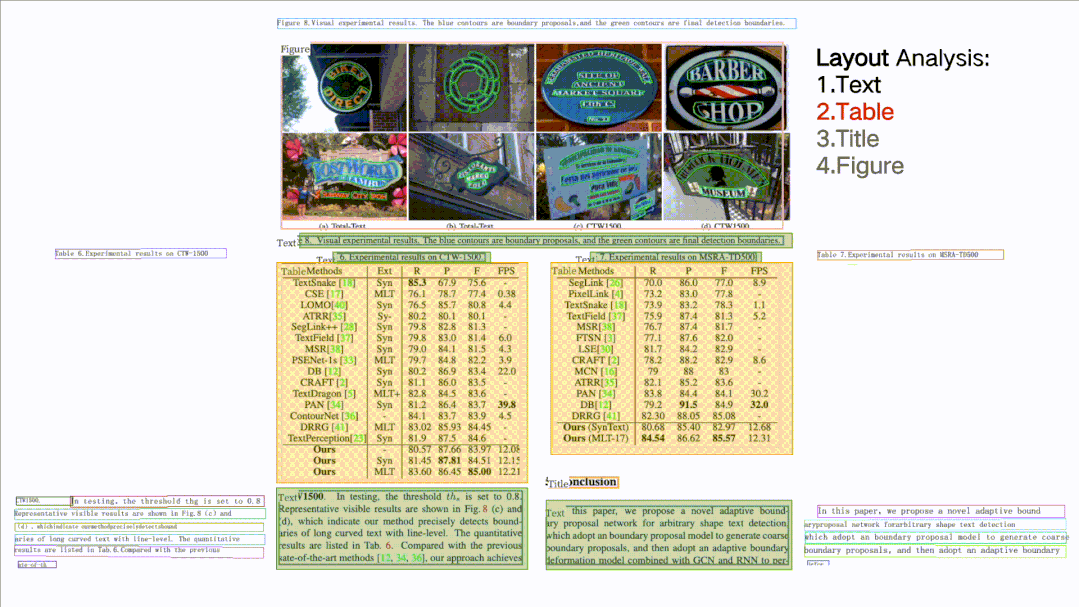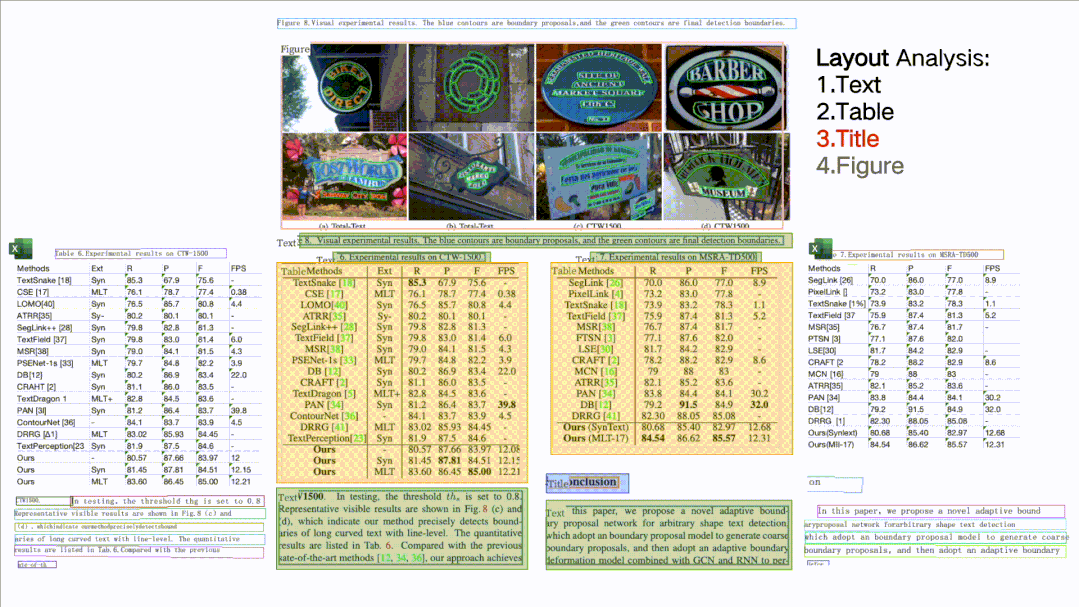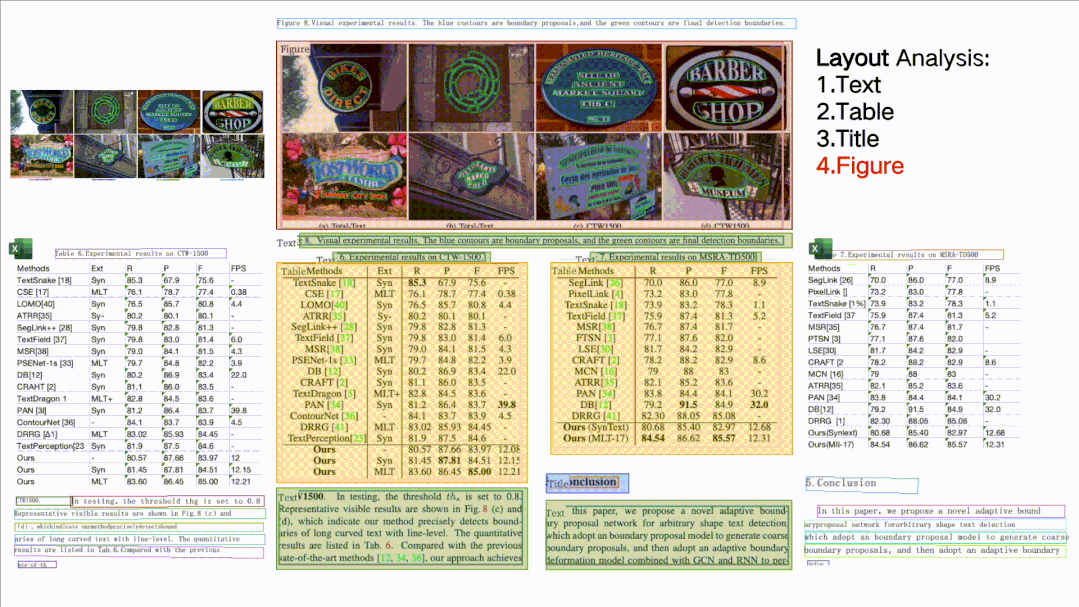
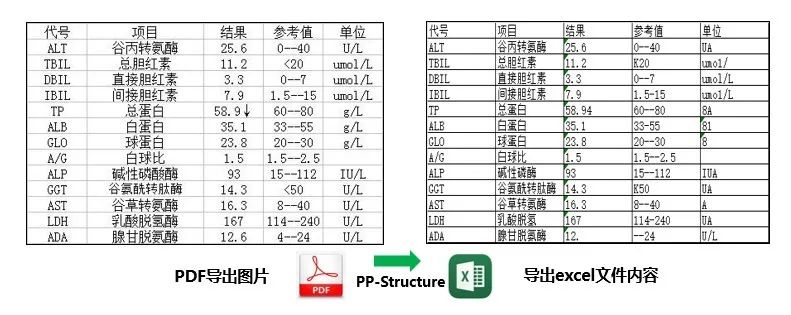
如圖所示,針對一張完整的PDF圖片,這個開源項目可以對文檔圖片中的文本、表格、圖片、標題與列表區(qū)域進行分類。同時還可以利用表格識別技術(shù)完整地提取表格結(jié)構(gòu)信息,使得表格圖片變?yōu)榭删庉嫷腅xcel文件。
不僅僅是PDF文件轉(zhuǎn)excel,如果編程能力再強一些,結(jié)合版面分析技術(shù),PDF轉(zhuǎn)Word都不在話下。
而且使用也是非常方便,在完成Python whl包安裝之后,簡單幾行代碼即可完成快速試用。
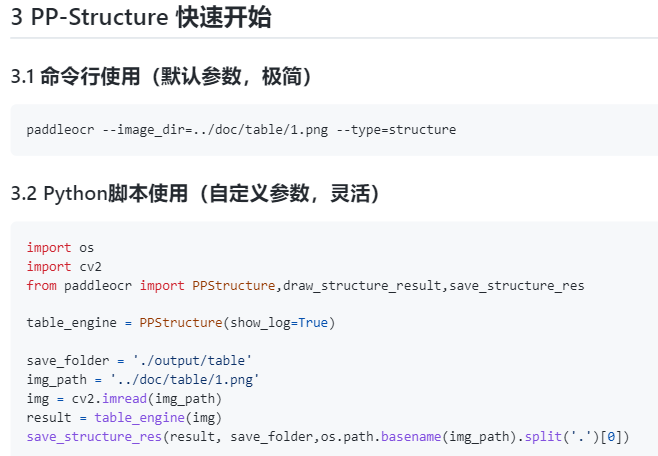
最終結(jié)果會輸出圖片文件夾,Excel表和文字識別結(jié)果,確實是非常方便。
傳送門:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
版面分析與表格識別核心技術(shù)概述
(1)傳統(tǒng)方法:版面分析比較著名的是O’Gorman在1993年TPAMI中發(fā)表的算法Docstrum。通過自下而上的方法依次將圖像中的黑白連通域劃分為文字、文本行與文本塊,從而得到版面布局。表格識別的傳統(tǒng)方法通過腐蝕、膨脹等操作獲得表格線、劃分行列區(qū)域,然后將單元格與文本內(nèi)容相結(jié)合重構(gòu)為表格對象。但是傳統(tǒng)算法主要問題在于,對于版面布局分析和表格結(jié)構(gòu)的提取,圖像處理的方法依賴各種閾值和參數(shù)的選擇,對于不同場景下的文檔圖片難以保證泛化性。
(2)深度學習方法:除了直接使用檢測模型來對版面內(nèi)容進行分類以外,還融合了檢測、分割、圖神經(jīng)網(wǎng)絡、注意力機制等眾多前沿技術(shù)能力。依賴算法工程師對于深度神經(jīng)網(wǎng)絡的精心設計,可以不再依賴閾值與參數(shù),具有更好的泛化性。
PP-Structure 核心技術(shù)解讀
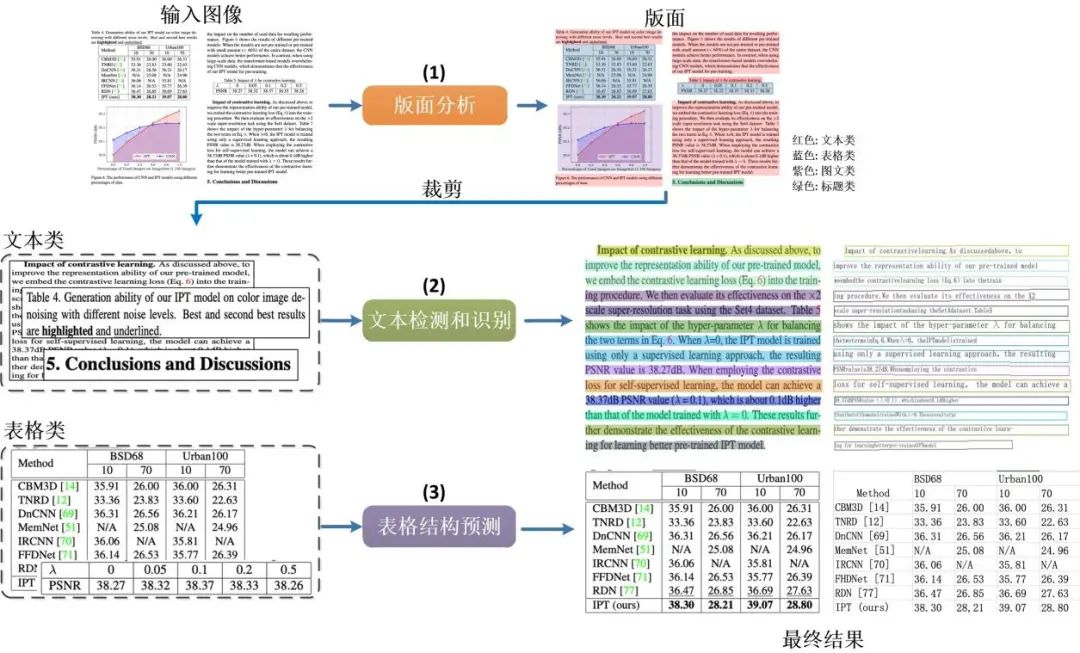
版面分析技術(shù)
Layout-Parser是開源的基于深度學習的文檔圖像分析工具箱,可用于布局檢測,字符識別和許多其他文檔處理任務,包含大量豐富模型,支持自定義DL模型,支持多個文檔布局檢測數(shù)據(jù)集。

GitHub地址:
https://github.com/Layout-Parser/layout-parser
表格識別技術(shù)
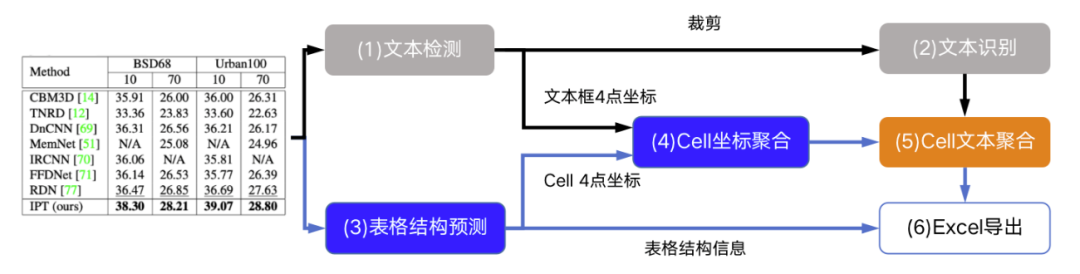

(4)Cell坐標聚合模塊,主要用來解決如何將跨行單元格的文本重新拼接在一個單元格內(nèi)的問題。它通過計算由文本檢測算法獲得的文本框坐標(紅色框)與表格結(jié)構(gòu)預測模塊得到的Cell坐標(藍色框)之間的IOU和頂點距離來進行單行到多行的聚合。使用IOU判斷哪些紅色框同屬于一個藍色框,使用頂點距離和IOU判斷紅色框的排列順序。
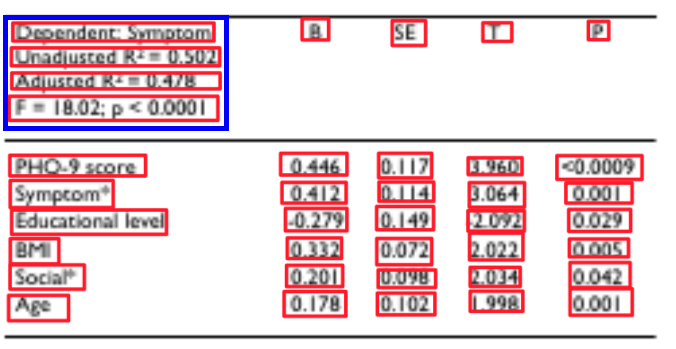
(5)Cell文本聚合模塊,根據(jù)已有的紅色文本框順序,按照從上到下從左到右順序利用(4)Cell坐標聚合模塊的結(jié)果將(2)文本識別結(jié)果和進行拼接,這樣對于多行文本的單元格內(nèi)容即可拼接成一個字符串。
(6)Excel導出模塊,將(3)表格結(jié)構(gòu)預測結(jié)果html結(jié)果與(5)Cell文本聚合模塊文本結(jié)果結(jié)合,最終導出為Excel輸出。
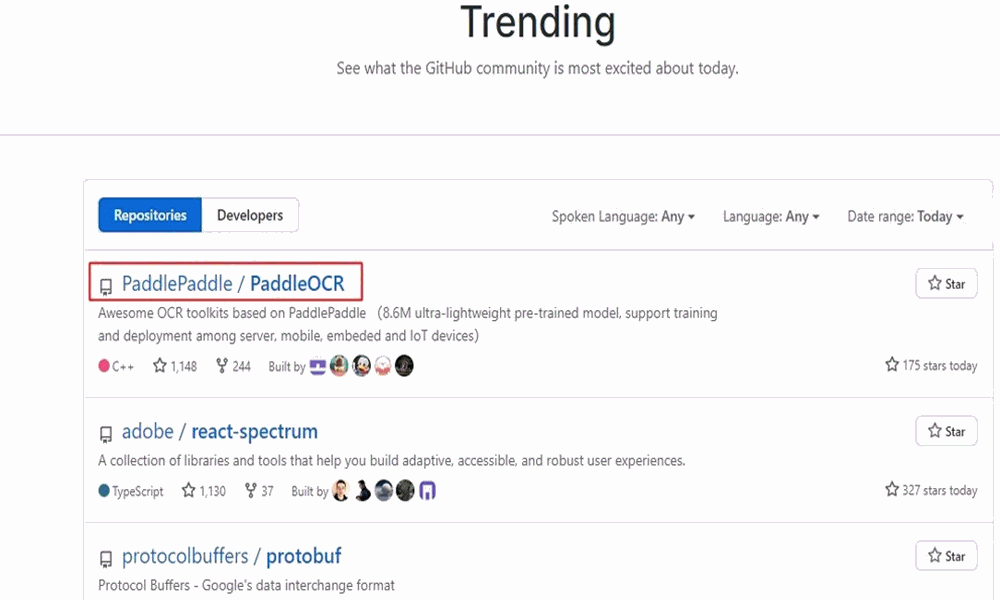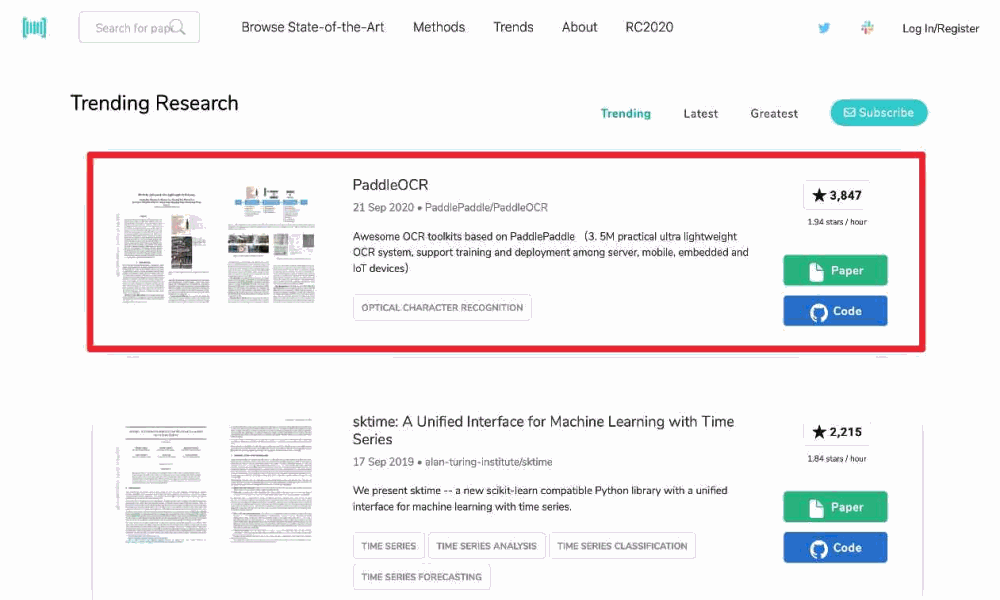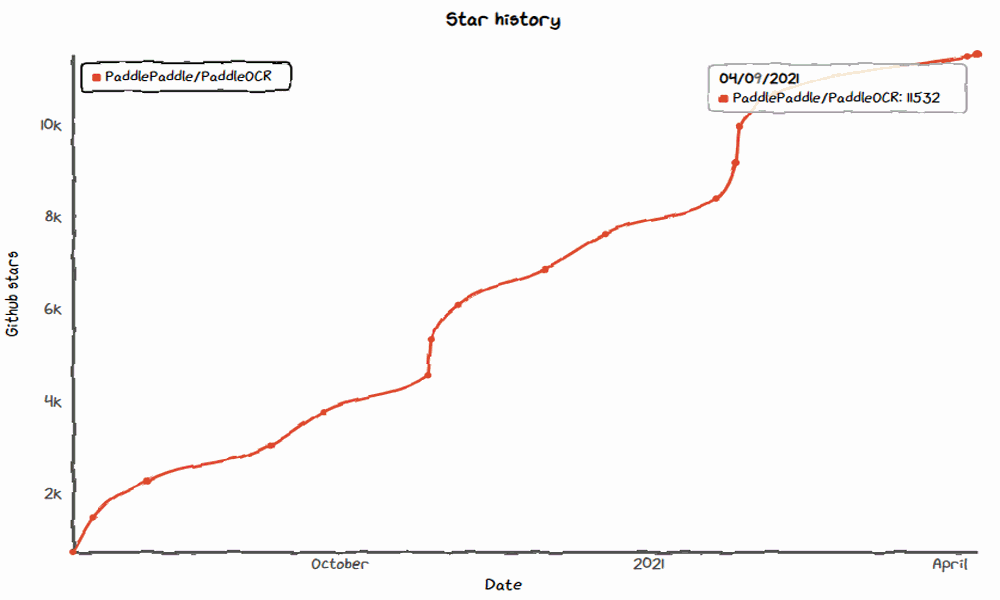
以上所有內(nèi)容均在PaddleOCR項目開源,目前star數(shù)量超過13.5k
相關(guān)延伸:
PaddleOCR歷史表現(xiàn)回顧
2020年6月,8.6M超輕量模型發(fā)布,GitHub Trending 全球趨勢榜日榜第一。
2020年8月,開源CVPR2020頂會算法,再上GitHub趨勢榜單!
2020年10月,發(fā)布PP-OCR算法,開源3.5M超超輕量模型,再下Paperswithcode 趨勢榜第一
2021年1月,發(fā)布Style-Text文本合成算法,PPOCRLabel數(shù)據(jù)標注工具,star數(shù)量突破10000+,截至目前已經(jīng)達到11.5k,在《Github 2020數(shù)字洞察報告》中被評為中國GithubTop20活躍項目。
2021年4月,開源AAAI頂會論文PGNet端到端識別算法,Star突破13k
2021年8月,開源版面分析與表格識別算法
文本檢測識別效果:

這個最強OCR項目,你值得擁有:
https://github.com/PaddlePaddle/PaddleOCR

8月12日(周四)20:15-21:30百度高級研發(fā)工程師將帶我們解讀文檔分析技術(shù)PP-Structure及PaddleOCR應用落地經(jīng)驗,歡迎大家踴躍報名直播課!
掃描二維碼報名,立即加入交流群

·PaddleOCR項目地址·
Gitee:
https://gitee.com/paddlepaddle/PaddleOCR