
Iceberg 實(shí)踐 | 基于 Flink CDC 打通數(shù)據(jù)實(shí)時(shí)入湖

照片拍攝于2014年夏,北京王府井附近
大家好,我是一哥,今天分享一篇數(shù)據(jù)實(shí)時(shí)入湖的干貨文章。
在構(gòu)建實(shí)時(shí)數(shù)倉的過程中,如何快速、正確的同步業(yè)務(wù)數(shù)據(jù)是最先面臨的問題,本文主要討論一下如何使用實(shí)時(shí)處理引擎Flink和數(shù)據(jù)湖Apache Iceberg兩種技術(shù),來解決業(yè)務(wù)數(shù)據(jù)實(shí)時(shí)入湖相關(guān)的問題。
CDC全稱是Change Data Capture,捕獲變更數(shù)據(jù),是一個(gè)比較廣泛的概念,只要是能夠捕獲所有數(shù)據(jù)的變化,比如數(shù)據(jù)庫捕獲完整的變更日志記錄增、刪、改等,都可以稱為CDC。該功能被廣泛應(yīng)用于數(shù)據(jù)同步、更新緩存、微服務(wù)間同步數(shù)據(jù)等場景,本文主要介紹基于Flink CDC在數(shù)據(jù)實(shí)時(shí)同步場景下的應(yīng)用。
Flink在1.11版本開始引入了Flink CDC功能,并且同時(shí)支持Table & SQL兩種形式。Flink SQL CDC是以SQL的形式編寫實(shí)時(shí)任務(wù),并對CDC數(shù)據(jù)進(jìn)行實(shí)時(shí)解析同步。相比于傳統(tǒng)的數(shù)據(jù)同步方案,該方案在實(shí)時(shí)性、易用性等方面有了極大的改善。下圖是基于Flink SQL CDC的數(shù)據(jù)同步方案的示意圖。
Oracle的變更日志的采集有多種方案,這里采用的Debezium實(shí)時(shí)同步工具作為示例,該工具能夠解析Oracle的changlog數(shù)據(jù),并實(shí)時(shí)同步數(shù)據(jù)到下游Kafka。Flink SQL通過創(chuàng)建Kafka映射表并指定 format格式為debezium-json,然后通過Flink進(jìn)行解析后直接插入到其他外部數(shù)據(jù)存儲(chǔ)系統(tǒng),例如圖中外部數(shù)據(jù)源以Apache Iceberg為例。
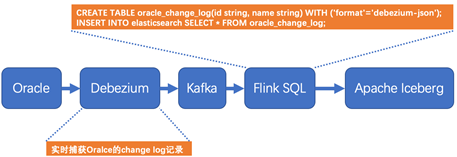
下面詳細(xì)解析一下數(shù)據(jù)同步過程。首先了解一下Debezium抽取的Oracle的change log的格式,以update為例,變更日志上記錄了更新之前的數(shù)據(jù)和更新以后的數(shù)據(jù),在Kafka下游的Flink接受到這樣的數(shù)據(jù)以后,一條update操作記錄就轉(zhuǎn)變?yōu)榱讼萪elete、后insert兩條記錄。日志格式如下所示,該update操作的內(nèi)容的name字段從tom更新為了jerry。
{
"before": { --更新之前的數(shù)據(jù)
"id": 001,
"name": "tom"
},
"after": { --更新之后的數(shù)據(jù)
"id": 001,
"name": "jerry"
},
"source": {...},
"op": "u",
"ts_ms": 1589362330904,
"transaction": null
}
其次再來看一下Flink SQL內(nèi)部是如何處理update記錄的。Flink在1.11版本支持了完整的changelog機(jī)制,對于每條數(shù)據(jù)本身只要是攜帶了相應(yīng)增、刪、改的標(biāo)志,F(xiàn)link就能識(shí)別這些數(shù)據(jù),并對結(jié)果表做出相應(yīng)的增、刪、改的動(dòng)作,如下圖所示changlog數(shù)據(jù)流經(jīng)過Flink解析,同步到下游Sink Database。
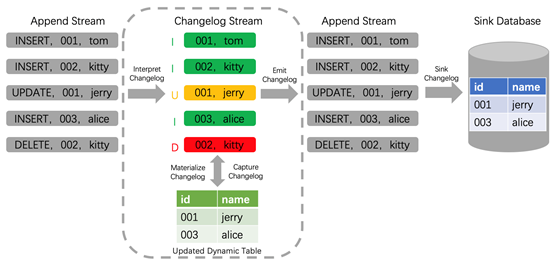
通過以上分析,基于Flink SQL CDC的數(shù)據(jù)同步有如下優(yōu)點(diǎn):
業(yè)務(wù)解耦:無需入侵業(yè)務(wù),和業(yè)務(wù)完全解耦,也就是業(yè)務(wù)端無感知數(shù)據(jù)同步的存在。
性能消耗:業(yè)務(wù)數(shù)據(jù)庫性能消耗小,數(shù)據(jù)同步延遲低。
同步易用:使用SQL方式執(zhí)行CDC同步任務(wù),極大的降低使用維護(hù)門檻。
數(shù)據(jù)完整:完整的數(shù)據(jù)庫變更記錄,不會(huì)丟失任何記錄,F(xiàn)link 自身支持 Exactly Once。
通常認(rèn)為數(shù)據(jù)湖是一種支持存儲(chǔ)多種原始數(shù)據(jù)格式、多種計(jì)算引擎、高效的元數(shù)據(jù)統(tǒng)一管理和海量統(tǒng)一數(shù)據(jù)存儲(chǔ)。其中以Apache Iceberg為代表的表格式和Flink計(jì)算引擎組成的數(shù)據(jù)湖解決方案尤為亮眼。Flink社區(qū)方面也主動(dòng)擁抱數(shù)據(jù)湖技術(shù),當(dāng)前Flink和Iceberg在數(shù)據(jù)入湖方面的集成度最高。
那么Apache Iceberg是什么呢?引用官網(wǎng)的定義是:Apache Iceberg is an open table format for huge analytic datasets。也就是Apache Iceberg是一個(gè)大規(guī)模數(shù)據(jù)分析的開放表格式。
Iceberg將數(shù)據(jù)分為元數(shù)據(jù)管理層和數(shù)據(jù)存儲(chǔ)層。首先了解一下Iceberg在文件系統(tǒng)中的布局,第一部分是數(shù)據(jù)文件data files,用于存儲(chǔ)具體業(yè)務(wù)數(shù)據(jù),如下圖中的data files文件。第二部分是表元數(shù)據(jù)文件(Metadata 文件),包含Snapshot文件、Manifest文件等。Snapshot表示當(dāng)前操作的一個(gè)快照,每次commit都會(huì)生成一個(gè)快照,一個(gè)快照中包含多個(gè)Manifest,每個(gè)Manifest中記錄了當(dāng)前操作生成數(shù)據(jù)所對應(yīng)的文件地址,也就是data files的地址。基于snapshot的管理方式,iceberg能夠進(jìn)行time travel(歷史版本讀取以及增量讀取)。Iceberg文件系統(tǒng)設(shè)計(jì)特點(diǎn)如下圖所示:
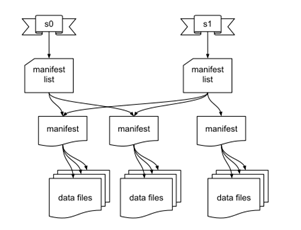
Iceberg的表格式設(shè)計(jì)具有如下特點(diǎn):
ACID:不會(huì)讀到不完整的commit數(shù)據(jù),基于樂觀鎖實(shí)現(xiàn),支持并發(fā)commit,支持Row-level delete,支持upsert操作。 增量快照:Commit后的數(shù)據(jù)即可見,在Flink實(shí)時(shí)入湖場景下,數(shù)據(jù)可見根據(jù)checkpoint的時(shí)間間隔來確定的,增量形式也可回溯歷史快照。 開放的表格式:對于一個(gè)真正的開放表格式,支持多種數(shù)據(jù)存儲(chǔ)格式,如:parquet、orc、avro等,支持多種計(jì)算引擎,如:Spark、Flink、Hive、Trino/Presto。 流批接口支持:支持流式寫入、批量寫入,支持流式讀取、批量讀取。下文的測試中,主要測試了流式寫入和批量讀取的功能。
當(dāng)前使用Flink最新版本1.12,支持CDC功能和更好的流批一體。Apache Iceberg最新版本0.11已經(jīng)支持Flink API方式upsert,如果使用編寫框架代碼的方式使用該功能,無異于鏡花水月,可望而不可及。本著SQL就是生產(chǎn)力的初衷,該測試使用最新Iceberg的master分支代碼編譯嘗鮮,并對源碼稍做修改,達(dá)到支持使用Flink SQL方式upsert。
先來了解一下什么是Row-Level Delete?該功能是指根據(jù)一個(gè)條件從一個(gè)數(shù)據(jù)集里面刪除指定行。那么為什么這個(gè)功能那么重要呢?眾所周知,大數(shù)據(jù)中的行級(jí)刪除不同于傳統(tǒng)數(shù)據(jù)庫的更新和刪除功能,在基于HDFS架構(gòu)的文件系統(tǒng)上數(shù)據(jù)存儲(chǔ)只支持?jǐn)?shù)據(jù)的追加,為了在該構(gòu)架下支持更新刪除功能,刪除操作演變成了一種標(biāo)記刪除,更新操作則是轉(zhuǎn)變?yōu)橄葮?biāo)記刪除、后插入一條新數(shù)據(jù)。具體實(shí)現(xiàn)方式可以分為Copy on Write(COW)模式和Merge on Read(MOR)模式,其中Copy on Write模式可以保證下游的數(shù)據(jù)讀具有最大的性能,而Merge on Read模式保證上游數(shù)據(jù)插入、更新、和刪除的性能,減少傳統(tǒng)Copy on Write模式下寫放大問題。
在Apache Iceberg中目前實(shí)現(xiàn)的是基于Merge on Read模式實(shí)現(xiàn)的Row-Level Delete。在 Iceberg中MOR相關(guān)的功能是在Iceberg Table Spec Version 2: Row-level Deletes中進(jìn)行實(shí)現(xiàn)的,V1是沒有相關(guān)實(shí)現(xiàn)的。雖然當(dāng)前Apache Iceberg 0.11版本不支持Flink SQL方式進(jìn)行Row-Level Delete,但為了方便測試,通過對源碼的修改支持Flink SQL方式。在不遠(yuǎn)的未來,Apache Iceberg 0.12版本將會(huì)對Row-Level Delete進(jìn)行性能和穩(wěn)定性的加強(qiáng)。
Flink SQL CDC和Apache Iceberg的架構(gòu)設(shè)計(jì)和整合如何巧妙,不能局限于紙上談兵,下面就實(shí)際操作一下,體驗(yàn)其功能的強(qiáng)大和帶來的便捷。并且順便體驗(yàn)一番流批一體,下面的離線查詢和實(shí)時(shí)upsert入湖等均使用Flink SQL完成。
1,數(shù)據(jù)入湖環(huán)境準(zhǔn)備
以Flink SQL CDC方式將實(shí)時(shí)數(shù)據(jù)導(dǎo)入數(shù)據(jù)湖的環(huán)境準(zhǔn)備非常簡單直觀,因?yàn)镕link支持流批一體功能,所以實(shí)時(shí)導(dǎo)入數(shù)據(jù)湖的數(shù)據(jù),也可以使用Flink SQL離線或?qū)崟r(shí)進(jìn)行查詢。如下測試是使用Flink提供的sql-client完成的:
第一步,新建Kafka映射表,用于實(shí)時(shí)接收Topic中的changlog數(shù)據(jù):
id STRING,
name STRING
) WITH (
'connector' = 'kafka',
'topic' = 'topic_name',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'debezium-json'
);
第二步,新建iceberg結(jié)果表,用于存儲(chǔ)實(shí)時(shí)入湖的數(shù)據(jù):
CREATE TABLE iceberg_catalog.default.IcebergTable ( id STRING, name STRING );
注:
a)其中省略了配置catalog過程
b)當(dāng)前iceberg 0.11默認(rèn)創(chuàng)建表格式版本V1,通過代碼更改版本為V2,以支持upsert方式導(dǎo)入數(shù)據(jù)湖
第三步,啟動(dòng)upsert方式實(shí)時(shí)入湖的Flink任務(wù):
SET table.dynamic-table-options.enabled=true;
INSERT INTO IcebergTable /*+OPTIONS('equality-field-columns'='id')*/ SELECT * FROM KafkaTable;
注:當(dāng)前iceberg 0.11不支持Flink SQL形式upsert,通過修改源碼達(dá)到支持配置指定字段更新功能。
第四步,離線或者實(shí)時(shí)查詢統(tǒng)計(jì)IcebergTable表中的數(shù)據(jù)行數(shù):
a)離線方式
SET execution.type=batch;
SELECT COUNT(*) FROM IcebergTable;
b)實(shí)時(shí)方式
SET execution.type=streaming;
SELECT COUNT(*) FROM IcebergTable;
2,數(shù)據(jù)入湖速度測試
數(shù)據(jù)入湖速度測試會(huì)根據(jù)環(huán)境配置、參數(shù)配置、數(shù)據(jù)格式等不同有所不同,下面是列出主要配置和測試出的數(shù)據(jù)作為參考。
a)資源配置情況
TaskManager 內(nèi)存4G,slot:1
Checkpoint 1分鐘
測試數(shù)據(jù)列數(shù) 10列
測試數(shù)據(jù)行數(shù) 1000萬
iceberg存儲(chǔ)格式 parquet
b)測試數(shù)據(jù)情況
數(shù)據(jù)入湖分為append和upsert兩種方式。append方式只能新增數(shù)據(jù),不能對結(jié)果數(shù)據(jù)進(jìn)行更新操作;upsert方式即能夠?qū)Y(jié)果數(shù)據(jù)更新。
append方式使用場景是導(dǎo)入數(shù)據(jù)之前已經(jīng)明確該表數(shù)據(jù)不需要更新,如離線數(shù)據(jù)導(dǎo)入數(shù)據(jù)湖的場景,append方式下導(dǎo)入數(shù)據(jù)速度如下:
INSERT INTO IcebergTable SELECT * FROM KafkaTable;
并行度1 12.2萬/秒
并行度2 19.6萬/秒
并行度4 28.3萬/秒
update方式使用場景是既有插入的數(shù)據(jù)又有對之前插入數(shù)據(jù)的更新的場景,如數(shù)據(jù)庫實(shí)時(shí)同步,upsert方式下導(dǎo)入數(shù)據(jù)速度,該方式需要指定在更新時(shí)以那個(gè)字段查找,類似于update語句中的where條件,一般設(shè)置為表的主鍵即可,如下:
INSERT INTO IcebergTable /*+OPTIONS('equality-field-columns'='id')*/ SELECT * FROM KafkaTable;
導(dǎo)入的數(shù)據(jù) 只有數(shù)據(jù)插入 只有數(shù)據(jù)更新
并行度1 3.2萬/秒 2.9萬/秒
并行度2 4.9萬/秒 4.2萬/秒
并行度4 6.1萬/秒 5.1萬/秒
c)結(jié)論
append方式導(dǎo)入速度遠(yuǎn)大于upsert導(dǎo)入數(shù)據(jù)速度。在使用的時(shí)候,如沒有更新數(shù)據(jù)的場景時(shí),則不需要upsert方式導(dǎo)入數(shù)據(jù)。 導(dǎo)入速度隨著并行度的增加而增加。 upsert方式數(shù)據(jù)的插入和更新速度相差不大,主要得益于MOR原因。
3,數(shù)據(jù)入湖任務(wù)運(yùn)維
在實(shí)際使用過程中,默認(rèn)配置下是不能夠長期穩(wěn)定的運(yùn)行的,一個(gè)實(shí)時(shí)數(shù)據(jù)導(dǎo)入iceberg表的任務(wù),需要通過至少下述四點(diǎn)進(jìn)行維護(hù),才能使Iceberg表的入湖和查詢性能保持穩(wěn)定。
Table table = ...
Actions.forTable(table)
.rewriteDataFiles()
.targetSizeInBytes(100 * 1024 * 1024) // 100 MB
.execute();
Table table = ...
Actions.forTable(table)
.expireSnapshots()
.expireOlderThan(System.currentTimeMillis())
.retainLast(5)
.execute();
Table table = ...
Actions.forTable(table)
.removeOrphanFiles()
.execute();
每次提交snapshot均會(huì)自動(dòng)產(chǎn)生一個(gè)新的metadata文件,實(shí)時(shí)數(shù)據(jù)入庫會(huì)頻繁的產(chǎn)生大量metadata文件,需要通過如下配置達(dá)到自動(dòng)刪除metadata文件的效果。
| Property | Description |
|---|---|
| write.metadata.delete-after-commit.enabled | Whether to delete old metadata files after each table commit |
| write.metadata.previous-versions-max | The number of old metadata files to keep |
4,數(shù)據(jù)入湖問題討論
這里主要討論數(shù)據(jù)一致性和順序性問題。
Q1: 程序BUG或者任務(wù)重啟等導(dǎo)致數(shù)據(jù)傳輸中斷,如何保證數(shù)據(jù)的一致性呢?
Answer:數(shù)據(jù)一致保證通過兩個(gè)方面實(shí)現(xiàn),借助Flink實(shí)現(xiàn)的exactly once語義和故障恢復(fù)能力,實(shí)現(xiàn)數(shù)據(jù)嚴(yán)格一致性。借助Iceberg ACID能力來隔離寫入對分析任務(wù)的不利影響。
Q2:數(shù)據(jù)入湖否可保證全局順序性插入和更新?
Answer:不可以全局保證數(shù)據(jù)生產(chǎn)和數(shù)據(jù)消費(fèi)的順序性,但是可以保證同一條數(shù)據(jù)的插入和更新的順序性。首先數(shù)據(jù)抽取的時(shí)候是單線程的,然后分發(fā)到Kafka的各個(gè)partition中,此時(shí)同一個(gè)key的變更數(shù)據(jù)打入到同一個(gè)Kafka的分區(qū)里面,F(xiàn)link讀取的時(shí)候也能保證順序性消費(fèi)每個(gè)分區(qū)中的數(shù)據(jù),進(jìn)而保證同一個(gè)key的插入和更新的順序性。
新的技術(shù)最終是要落地才能發(fā)揮其內(nèi)在價(jià)值的,針對在實(shí)踐應(yīng)用中面臨的紛繁復(fù)雜的數(shù)據(jù),結(jié)合流計(jì)算技術(shù)Flink、表格式Iceberg,未來落地規(guī)劃主要集中在兩個(gè)方面,一是Iceberg集成到本行的實(shí)時(shí)計(jì)算平臺(tái)中,解決易用性的問題;二是基于Iceberg,構(gòu)建準(zhǔn)實(shí)時(shí)數(shù)倉進(jìn)行探索和落地。
1,整合Iceberg到實(shí)時(shí)計(jì)算平臺(tái)
目前,我所負(fù)責(zé)的實(shí)時(shí)計(jì)算平臺(tái)是一個(gè)基于SQL的高性能實(shí)時(shí)大數(shù)據(jù)處理平臺(tái),該平臺(tái)徹底規(guī)避繁重的底層流計(jì)算處理邏輯、繁瑣的提交過程等,為用戶打造一個(gè)只需關(guān)注實(shí)時(shí)計(jì)算邏輯的平臺(tái),助力企業(yè)向?qū)崟r(shí)化、智能化大數(shù)據(jù)轉(zhuǎn)型。
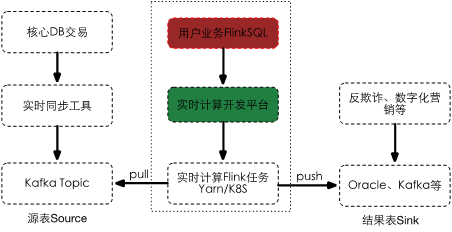
實(shí)時(shí)計(jì)算平臺(tái)未來將會(huì)整合Apache Iceberg數(shù)據(jù)源,用戶可以在界面配置Flink SQL任務(wù),該任務(wù)以upsert方式實(shí)時(shí)解析changlog并導(dǎo)入到數(shù)據(jù)湖中。并增加小文件監(jiān)控、定時(shí)任務(wù)壓縮小文件、清理過期數(shù)據(jù)等功能。
2,準(zhǔn)實(shí)時(shí)數(shù)倉探索
本文對數(shù)據(jù)實(shí)時(shí)入湖從原理和實(shí)戰(zhàn)做了比較多的闡述,在完成實(shí)時(shí)數(shù)據(jù)入湖SQL化的功能以后,入湖后的數(shù)據(jù)有哪些場景的使用呢?下一個(gè)目標(biāo)當(dāng)然是入湖的數(shù)據(jù)分析實(shí)時(shí)化。比較多的討論是關(guān)于實(shí)時(shí)數(shù)據(jù)湖的探索,結(jié)合所在企業(yè)數(shù)據(jù)特點(diǎn)探索適合落地的實(shí)時(shí)數(shù)據(jù)分析場景成為當(dāng)務(wù)之急。
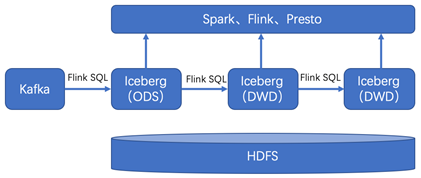
隨著數(shù)據(jù)量的持續(xù)增大,和業(yè)務(wù)對時(shí)效性的嚴(yán)苛要求,基于Apache Flink和Apache Iceberg構(gòu)建準(zhǔn)實(shí)時(shí)數(shù)倉愈發(fā)重要和迫切,作為實(shí)時(shí)數(shù)倉的兩大核心組件,可以縮短數(shù)據(jù)導(dǎo)入、方便數(shù)據(jù)行級(jí)變更、支持?jǐn)?shù)據(jù)流式讀取等。