
Iceberg 實踐 | Flink + Iceberg + 對象存儲,構建數(shù)據(jù)湖方案
數(shù)據(jù)湖和 Iceberg 簡介
未來規(guī)劃
演示方案 存儲優(yōu)化的一些思考
 GitHub 地址
GitHub 地址 一、數(shù)據(jù)湖和 Iceberg 簡介
1. 數(shù)據(jù)湖生態(tài)
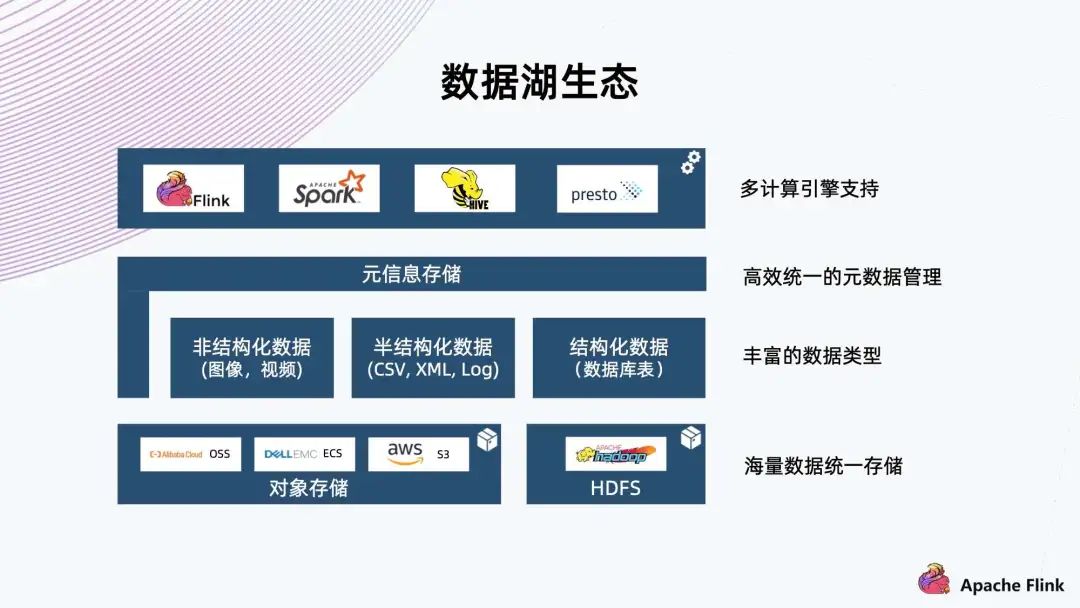
首先我們認為它底下應具備海量存儲的能力,常見的有對象存儲,公有云存儲以及 HDFS;
在這之上,也需要支持豐富的數(shù)據(jù)類型,包括非結構化的圖像視頻,半結構化的 CSV、XML、Log,以及結構化的數(shù)據(jù)庫表;
除此之外,需要高效統(tǒng)一的元數(shù)據(jù)管理,使得計算引擎可以方便地索引到各種類型數(shù)據(jù)來做分析。
最后,我們需要支持豐富的計算引擎,包括 Flink、Spark、Hive、Presto 等,從而方便對接企業(yè)中已有的一些應用架構。
2. 結構化數(shù)據(jù)在數(shù)據(jù)湖上的應用場景
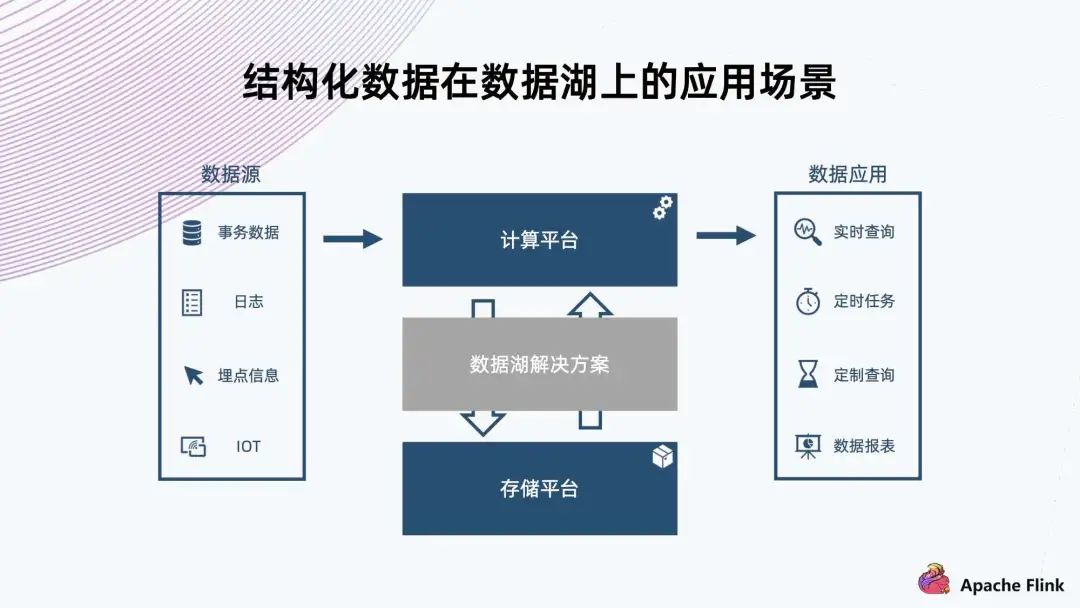
首先,可以看到數(shù)據(jù)源的類型很多,因此需要支持比較豐富的數(shù)據(jù) Schema 的組織; 其次,它在注入的過程中要支撐實時的數(shù)據(jù)查詢,所以需要 ACID 的保證,確保不會讀到一些還沒寫完的中間狀態(tài)的臟數(shù)據(jù); 最后,例如日志這些有可能臨時需要改個格式,或者加一列。類似這種情況,需要避免像傳統(tǒng)的數(shù)倉一樣,可能要把所有的數(shù)據(jù)重新提出來寫一遍,重新注入到存儲;而是需要一個輕量級的解決方案來達成需求。
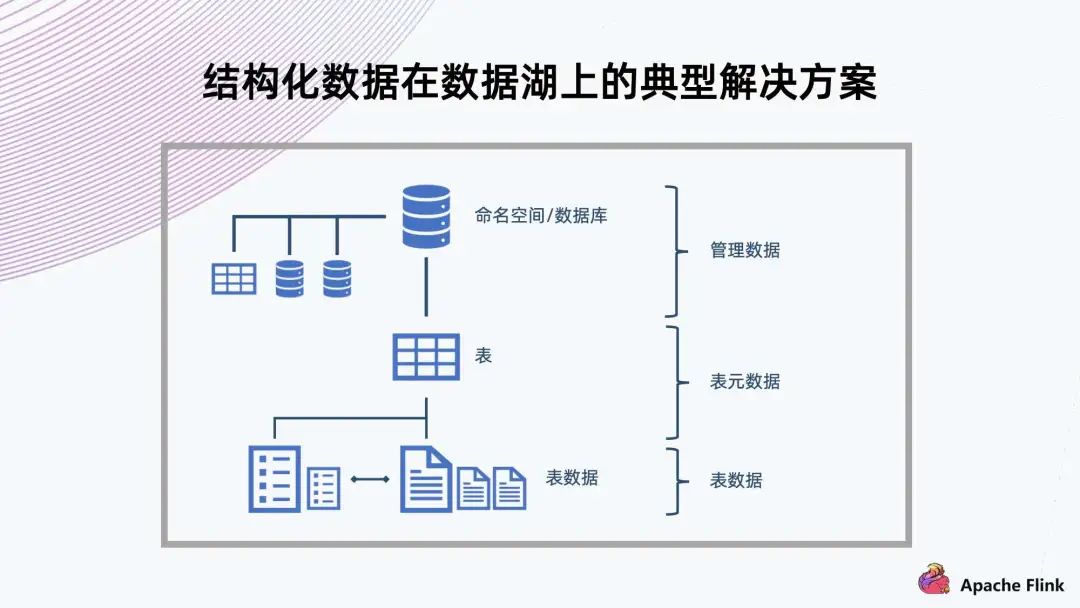
3. 結構化數(shù)據(jù)在數(shù)據(jù)湖上的典型解決方案
4. Iceberg 表數(shù)據(jù)組織架構
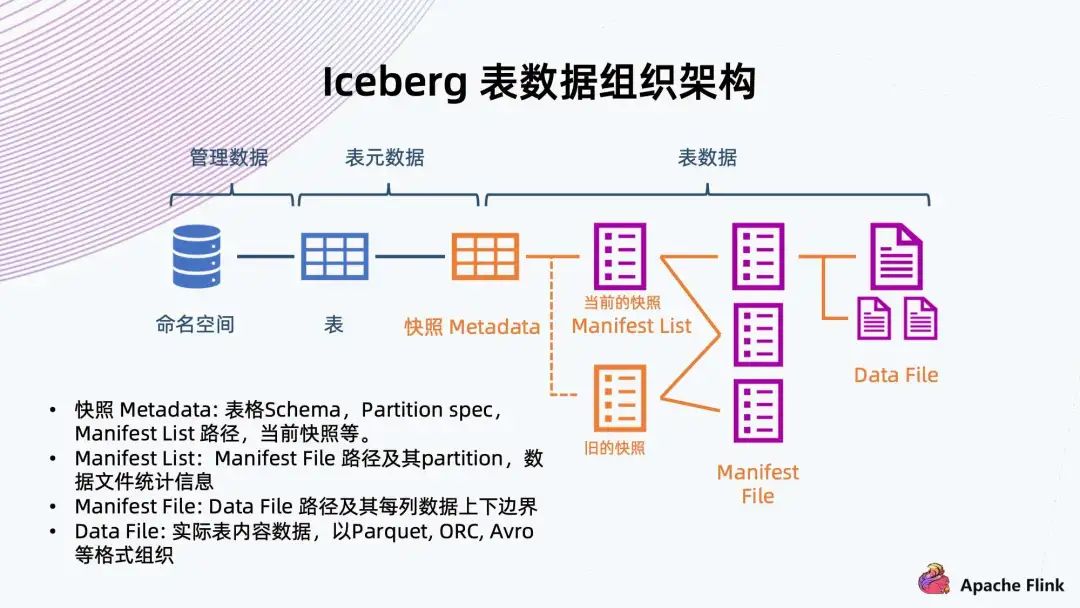
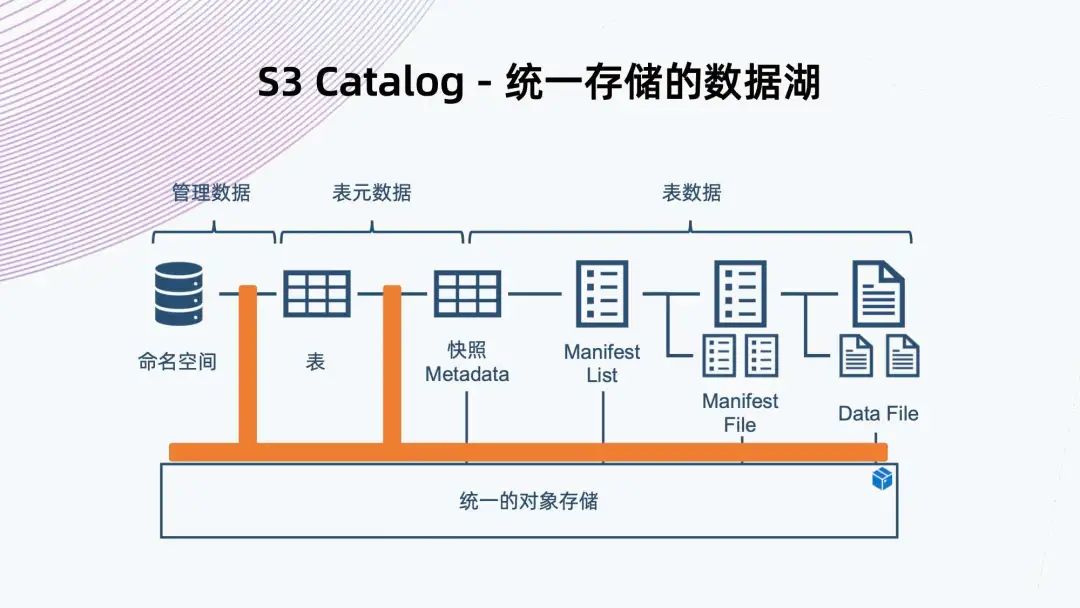
快照 Metadata:表格 Schema、Partition、Partition spec、Manifest List 路徑、當前快照等。 Manifest List:Manifest File 路徑及其 Partition,數(shù)據(jù)文件統(tǒng)計信息。 Manifest File:Data File 路徑及其每列數(shù)據(jù)上下邊界。 Data File:實際表內(nèi)容數(shù)據(jù),以 Parque,ORC,Avro 等格式組織。
可以看到右邊從數(shù)據(jù)文件開始,數(shù)據(jù)文件存放表內(nèi)容數(shù)據(jù),一般支持 Parquet、ORC、Avro 等格式; 往上是 Manifest File,它會記錄底下數(shù)據(jù)文件的路徑以及每列數(shù)據(jù)的上下邊界,方便過濾查詢文件; 再往上是 Manifest List,它來鏈接底下多個 Manifest File,同時記錄 Manifest File 對應的分區(qū)范圍信息,也是為了方便后續(xù)做過濾查詢; Manifest List 其實已經(jīng)表示了快照的信息,它包含當下數(shù)據(jù)庫表所有的數(shù)據(jù)鏈接,也是 Iceberg 能夠支持 ACID 特性的關鍵保障。 有了快照,讀數(shù)據(jù)的時候只能讀到快照所能引用到的數(shù)據(jù),還在寫的數(shù)據(jù)不會被快照引用到,也就不會讀到臟數(shù)據(jù)。多個快照會共享以前的數(shù)據(jù)文件,通過共享這些 Manifest File 來共享之前的數(shù)據(jù)。 再往上是快照元數(shù)據(jù),記錄了當前或者歷史上表格 Scheme 的變化、分區(qū)的配置、所有快照 Manifest File 路徑、以及當前快照是哪一個。 同時,Iceberg 提供命名空間以及表格的抽象,做完整的數(shù)據(jù)組織管理。
5. Iceberg 寫入流程
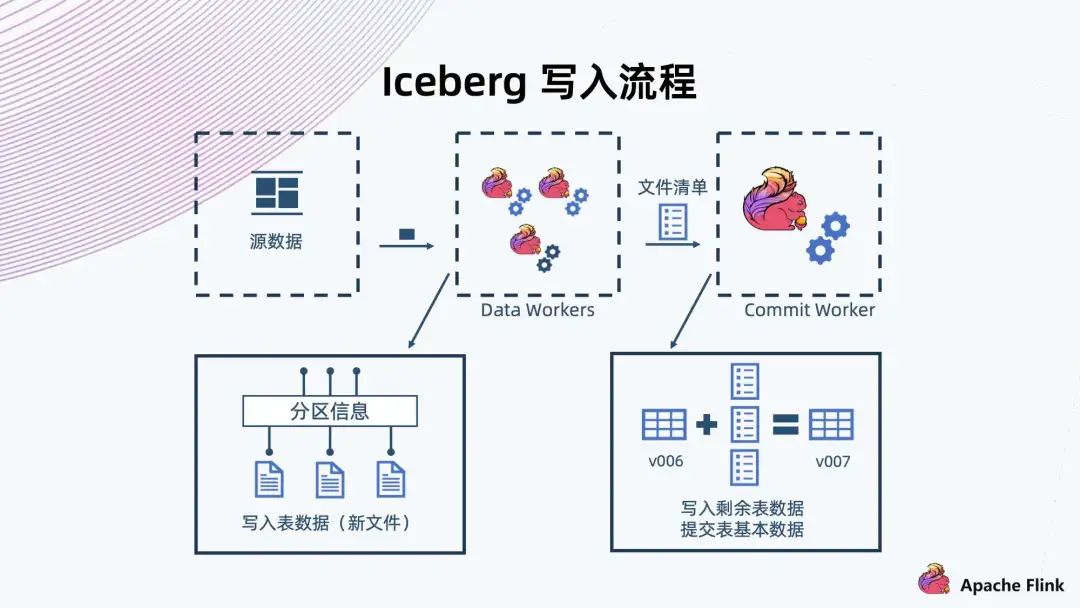
首先,Data Workers 會從元數(shù)據(jù)上讀出數(shù)據(jù)進行解析,然后把一條記錄交給 Iceberg 存儲; 與常見的數(shù)據(jù)庫一樣,Iceberg 也會有預定義的分區(qū),那些記錄會寫入到各個不同的分區(qū),形成一些新的文件; Flink 有個 CheckPoint 機制,文件到達以后,F(xiàn)link 就會完成這一批文件的寫入,然后生成這一批文件的清單,接著交給 Commit Worker; Commit Worker 會讀出當前快照的信息,然后與這一次生成的文件列表進行合并,生成一個新的 Manifest List 以及后續(xù)元數(shù)據(jù)的表文件的信息,之后進行提交,成功以后就形成一個新的快照。
6. Iceberg 查詢流程
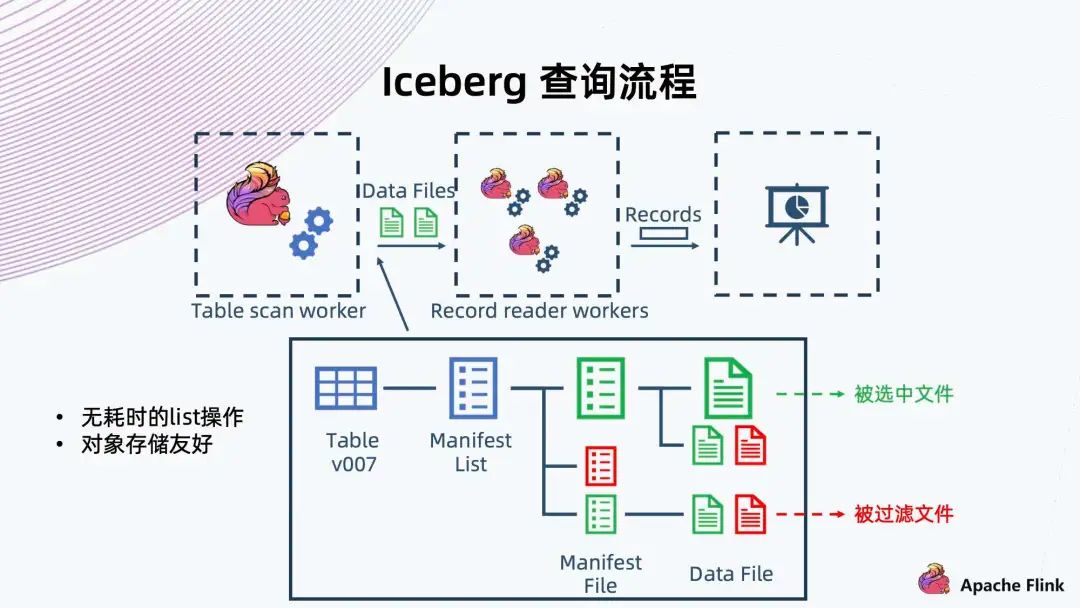
首先是 Flink Table scan worker 做一個 scan,scan 的時候可以像樹一樣,從根開始,找到當前的快照或者用戶指定的一個歷史快照,然后從快照中拿出當前快照的 Manifest List 文件,根據(jù)當時保存的一些信息,就可以過濾出滿足這次查詢條件的 Manifest File; 再往下經(jīng)過 Manifest File 里記錄的信息,過濾出底下需要的 Data Files。這個文件拿出來以后,再交給 Recorder reader workers,它從文件中讀出滿足條件的 Recode,然后返回給上層調(diào)用。
7. Iceberg Catalog 功能一覽
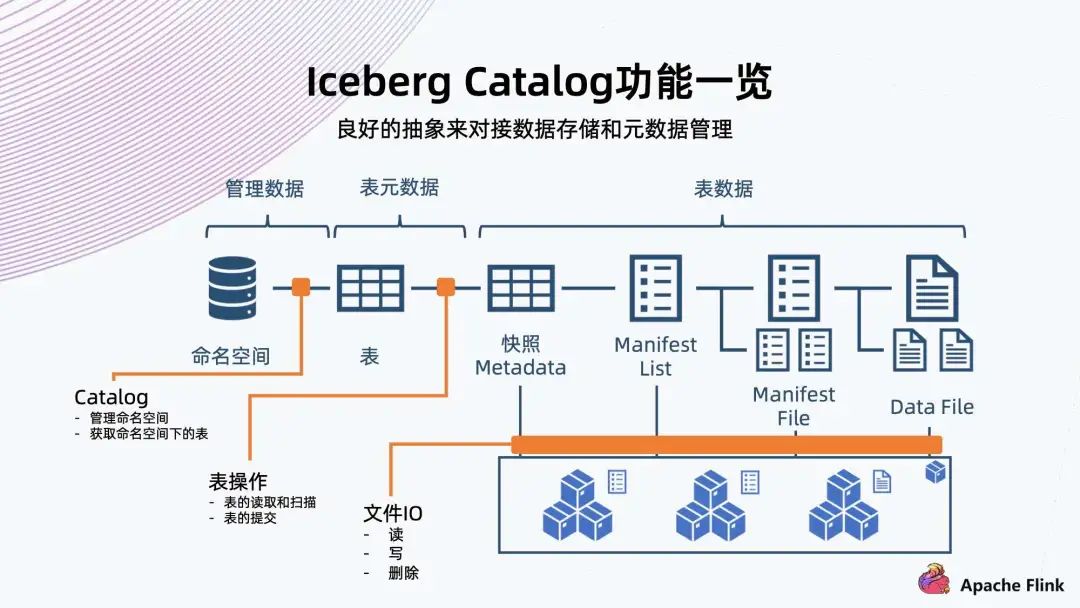
它可以對 Iceberg 定義一系列角色文件; 它的 File IO 都是可以定制,包括讀寫和刪除; 它的命名空間和表的操作 (也可稱為元數(shù)據(jù)操作),也可以定制; 包括表的讀取 / 掃描,表的提交,都可以用 Catalog 來定制。
二、對象存儲支撐 Iceberg 數(shù)據(jù)湖
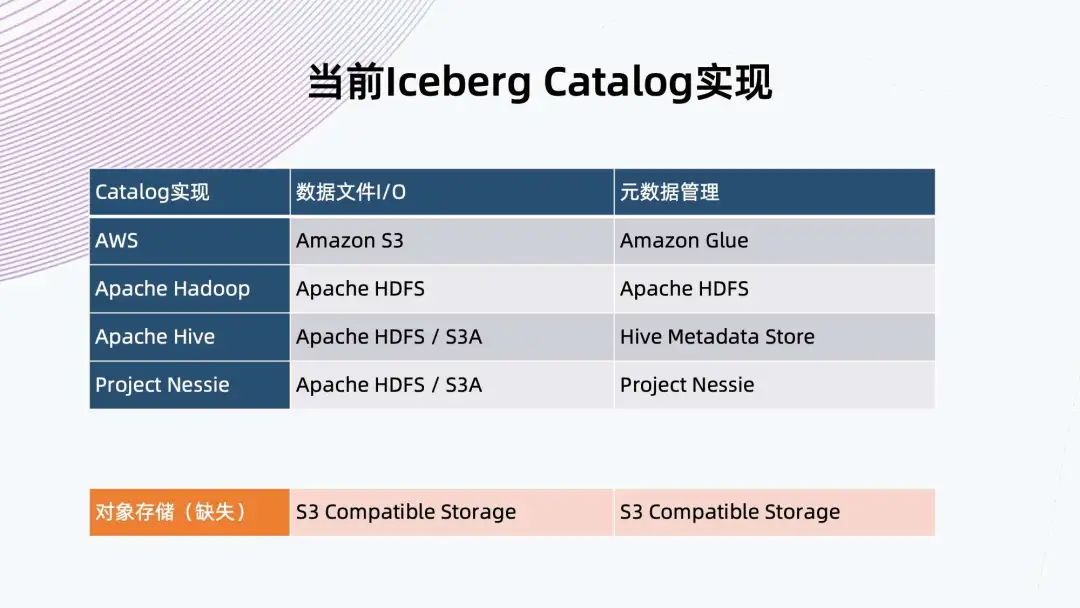
1. 當前 Iceberg Catalog 實現(xiàn)
2. 對象存儲和 HDFS 的比較
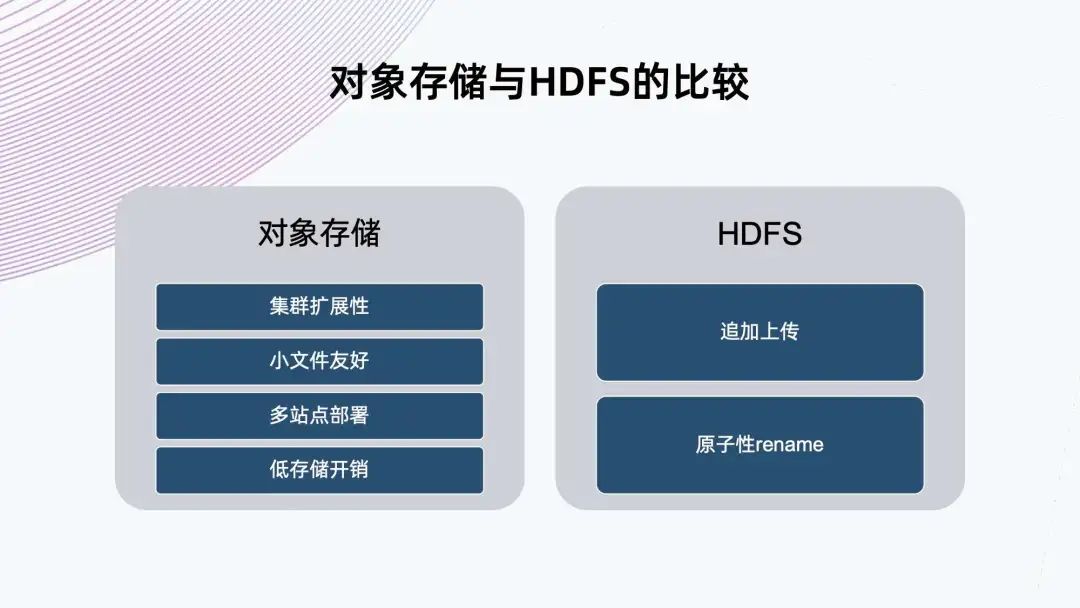
對象存儲在集群擴展性,小文件友好,多站點部署和低存儲開銷上更加有優(yōu)勢; HDFS 的好處就是提供追加上傳和原子性 rename,這兩個優(yōu)勢正是 Iceberg 需要的。
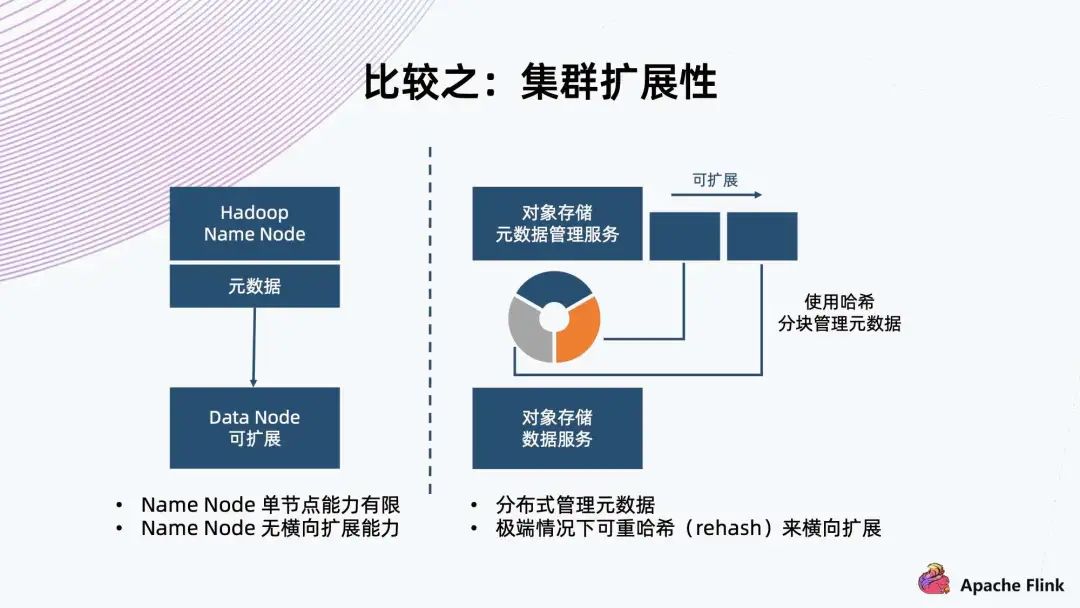
HDFS 架構是用單個 Name Node 保存所有元數(shù)據(jù),這就決定了它單節(jié)點的能力有限,所以在元數(shù)據(jù)方面沒有橫向擴展能力。 對象存儲一般采用哈希方式,把元數(shù)據(jù)分隔成各個塊,把這個塊交給不同 Node 上面的服務來進行管理,天然地它元數(shù)據(jù)的上限會更高,甚至在極端情況下可以進行 rehash,把這個塊切得更細,交給更多的 Node 來管理元數(shù)據(jù),達到擴展能力。

HDFS 基于架構的限制,小文件存儲受限于 Name Node 內(nèi)存等資源,雖然 HDFS 提供了 Archive 的方法來合并小文件,減少對 Name Node 的壓力,但這需要額外增加復雜度,不是原生的。 同樣,小文件的 TPS 也是受限于 Name Node 的處理能力,因為它只有單個 Name Node。對象存儲的元數(shù)據(jù)是分布式存儲和管理,流量可以很好地分布到各個 Node 上,這樣單節(jié)點就可以存儲海量的小文件。 目前,很多對象存儲提供多介質(zhì),分層加速,可以提升小文件的性能。
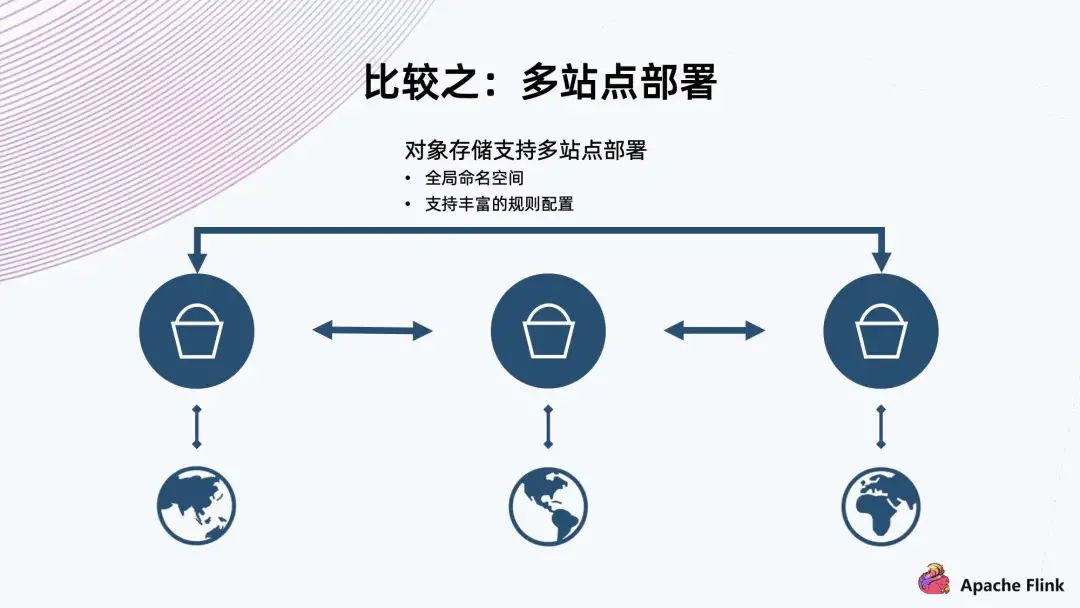
對象存儲支持多站點部署 全局命名空間 支持豐富的規(guī)則配置 對象存儲的多站點部署能力適用于兩地三中心多活的架構,而 HDFS 沒有原生的多站點部署能力。雖然目前看到一些商業(yè)版本給 HDFS 增加了多站點負責數(shù)據(jù)的能力,但由于它的兩個系統(tǒng)可能是獨立的,因此并不能支撐真正的全局命名空間下多活的能力。
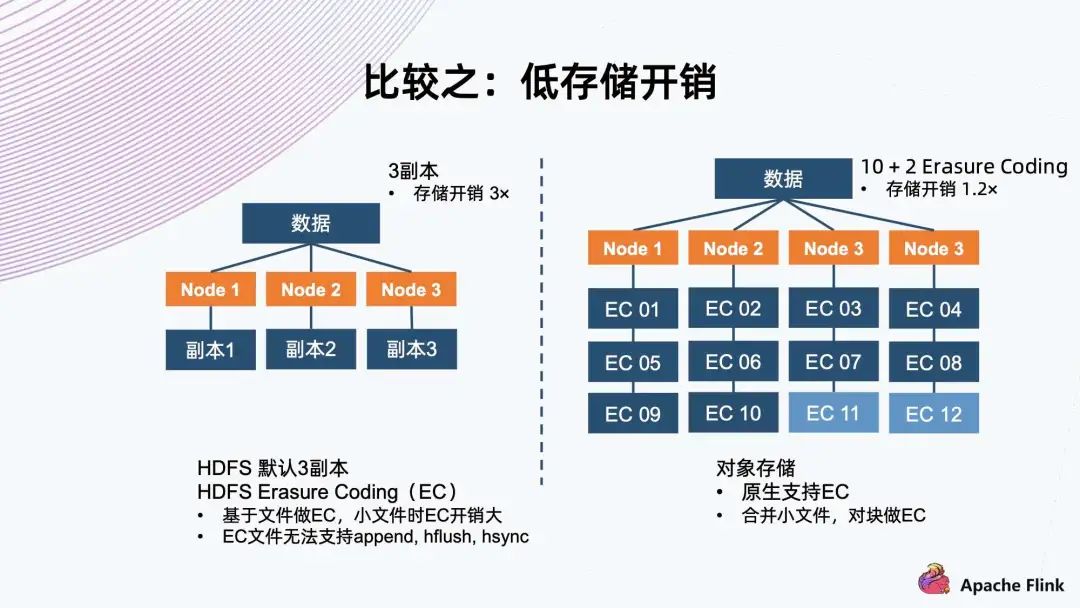
對于存儲系統(tǒng)來說,為了適應隨機的硬件故障,它一般會有副本機制來保護數(shù)據(jù)。 常見的如三副本,把數(shù)據(jù)存三份,然后分開保存到三個 Node 上面,存儲開銷是三倍,但是它可以同時容忍兩個副本遇到故障,保證數(shù)據(jù)不會丟失。 另一種是 Erasure Coding,通常稱為 EC。以 10+2 舉例,它把數(shù)據(jù)切成 10 個數(shù)據(jù)塊,然后用算法算出兩個代碼塊,一共 12 個塊。接著分布到四個節(jié)點上,存儲開銷是 1.2 倍。它同樣可以容忍同時出現(xiàn)兩個塊故障,這種情況可以用剩余的 10 個塊算出所有的數(shù)據(jù),這樣減少存儲開銷,同時達到故障容忍程度。 HDFS 默認使用三副本機制,新的 HDFS 版本上已經(jīng)支持 EC 的能力。經(jīng)過研究,它是基于文件做 EC,所以它對小文件有天然的劣勢。因為如果小文件的大小小于分塊要求的大小時,它的開銷就會比原定的開銷更大,因為兩個代碼塊這邊是不能省的。在極端情況下,如果它的大小等同于單個代碼塊的大小,它就已經(jīng)等同于三副本了。 同時,HDFS 一旦 EC,就不能再支持 append、hflush、hsync 等操作,這會極大地影響 EC 能夠使用的場景。對象存儲原生支持 EC,對于小文件的話,它內(nèi)部會把小文件合并成一個大的塊來做 EC,這樣確保數(shù)據(jù)開銷方面始終是恒定的,基于預先配置的策略。
3. 對象存儲的挑戰(zhàn):數(shù)據(jù)的追加上傳
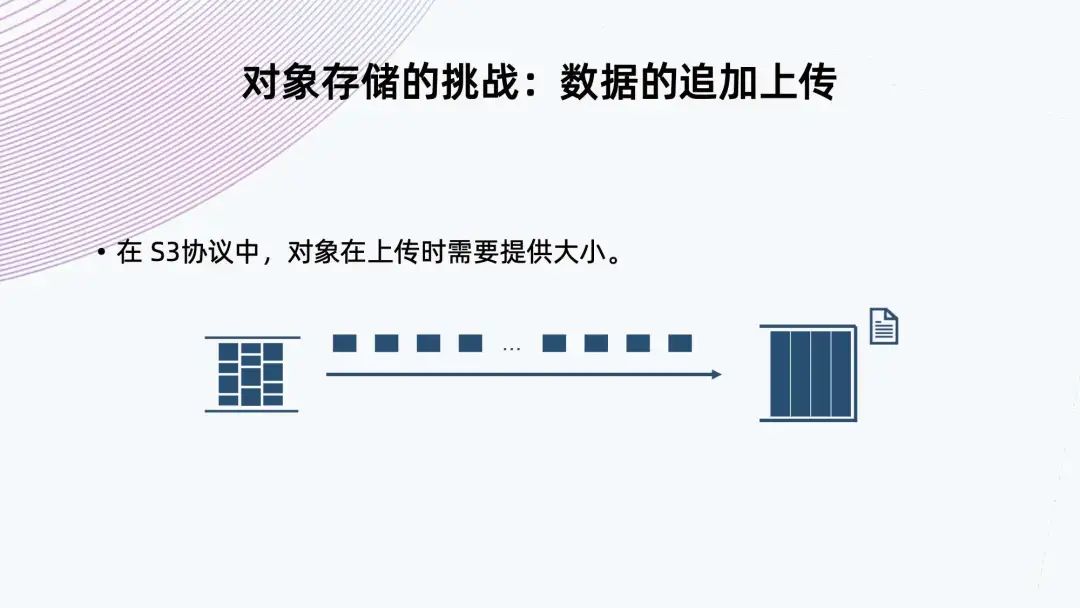
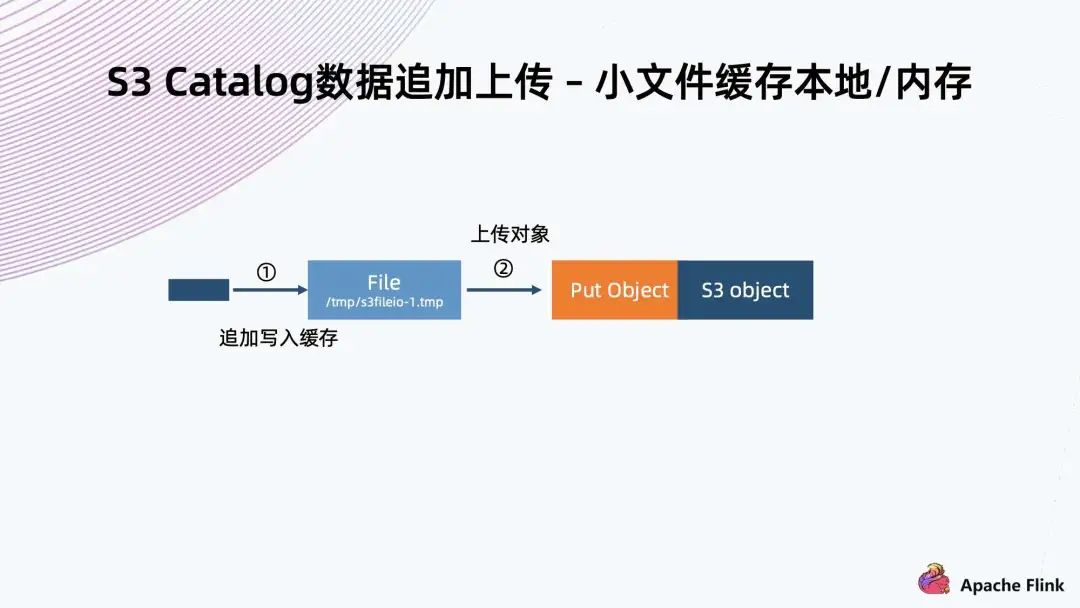
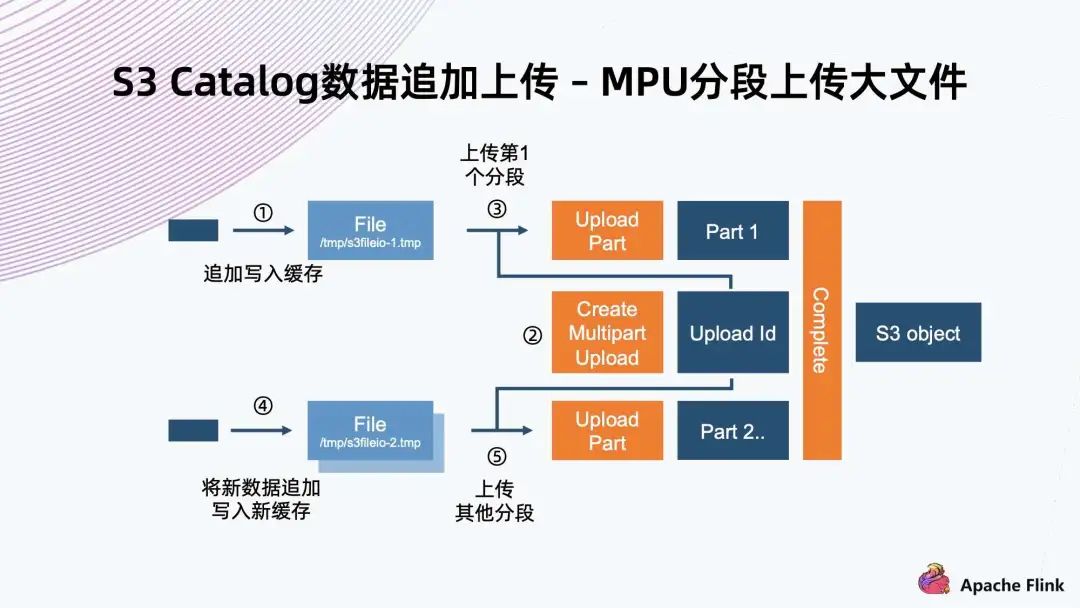
第一步先創(chuàng)建初始化的 MPU,拿到一個 Upload ID,然后給每一個分段賦予一個 Upload ID 以及一個編號,這些分塊就可以并行上傳; 在上傳完成以后,還需要一步 Complete 操作,這樣相當于通知系統(tǒng),它會把基于同一個 Upload ID 以及所有的編號,從小到大排起來,組成一個大文件; 把機制運用到數(shù)據(jù)追加上傳場景,常規(guī)實現(xiàn)就是寫入一個文件,把文件緩存到本地,當達到分塊要求大小時,就可以把它進行初始化 MPU,把它的一個分塊開始上傳。后面每一個分塊也是一樣的操作,直到最后一個分塊上傳完,最后再調(diào)用一個完成操作來完成上傳。
缺點是 MPU 的分片數(shù)量有上限,S3 標準里可能只有 1 萬個分片。想支持大文件的話,這個分塊就不能太小,所以對于小于分塊的文件,依然是要利用前面一種方法進行緩存上傳; MPU 的優(yōu)點在于并行上傳的能力。假設做一個異步的上傳,文件在緩存達到以后,不用等上一個分塊上傳成功,就可以繼續(xù)緩存下一個,之后開始上傳。當前面注入的速度足夠快時,后端的異步提交就變成了并行操作。利用這個機制,它可以提供比單條流上傳速度更快的上傳能力。
4. 對象存儲的挑戰(zhàn):原子提交
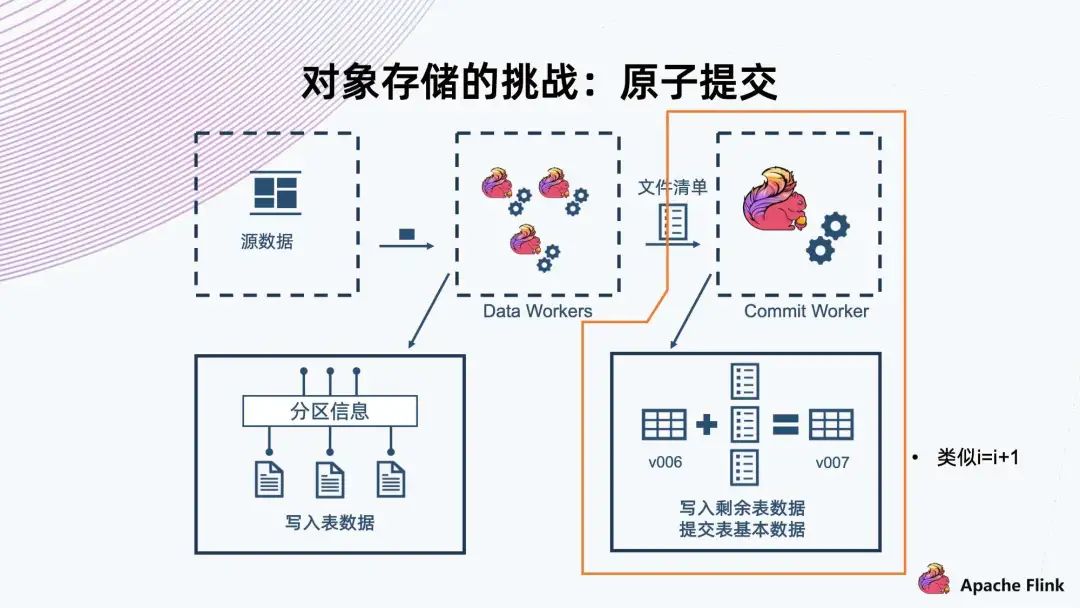
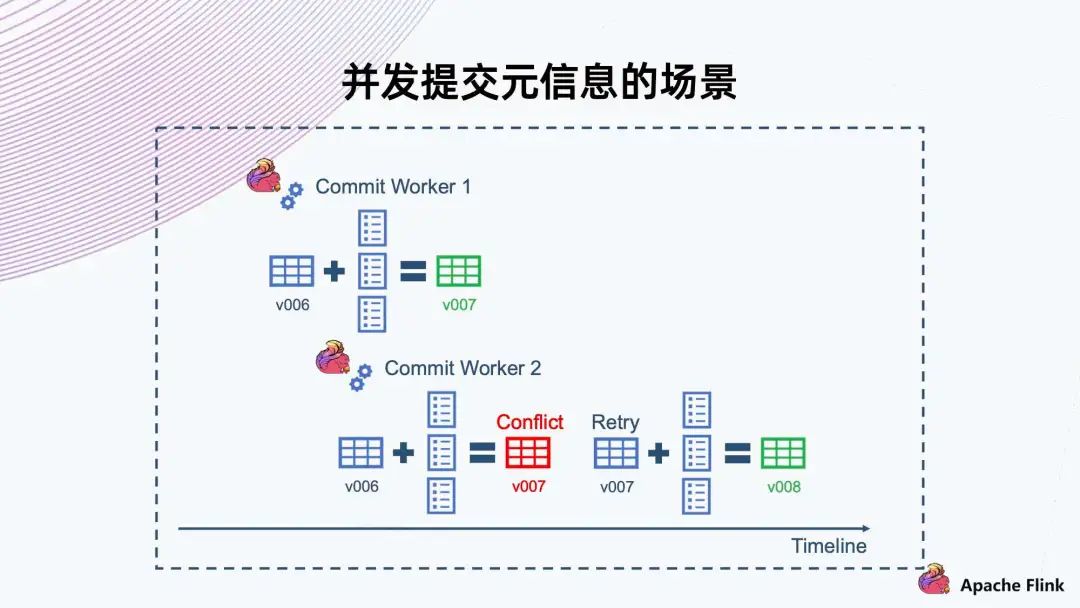
這里 Commit Worker 1 拿到了 v006 版本,然后合并自己的文件,提交 v007 成功。 此時還有另一個 Commit Worker 2,它也拿到了 v006,然后合并出來,且也要提供 v007。此時我們需要一個機制告訴它 v007 已經(jīng)沖突,不能上傳,然后讓它自己去 Retry。Retry 以后取出新的 v007 合并,然后提交給 v008。
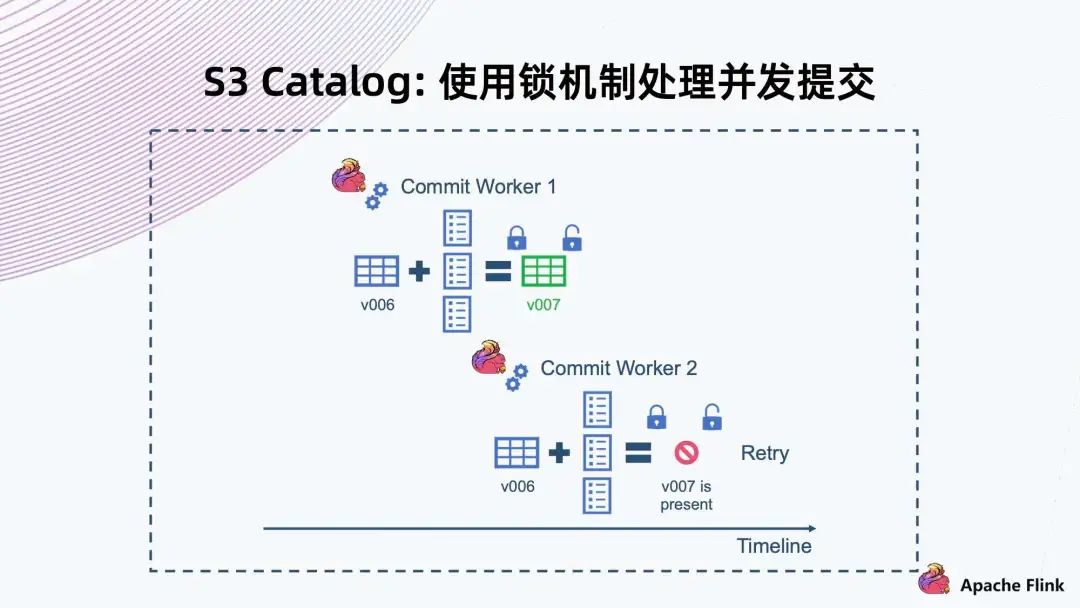
首先,Commit Worker 1 拿到 v006,然后合并文件,在提交之前先要獲取這一把鎖,拿到鎖以后判斷當前快照版本。如果是 v006,則 v007 能提交成功,提交成功以后再解鎖。 同樣,Commit Worker 2 拿到 v006 合并以后,它一開始拿不到鎖,要等 Commit Worker 1 釋放掉這個鎖以后才能拿到。等拿到鎖再去檢查的時候,會發(fā)現(xiàn)當前版本已經(jīng)是 v007,與自己的 v007 有沖突,因此這個操作一定會失敗,然后它就會進行 Retry。
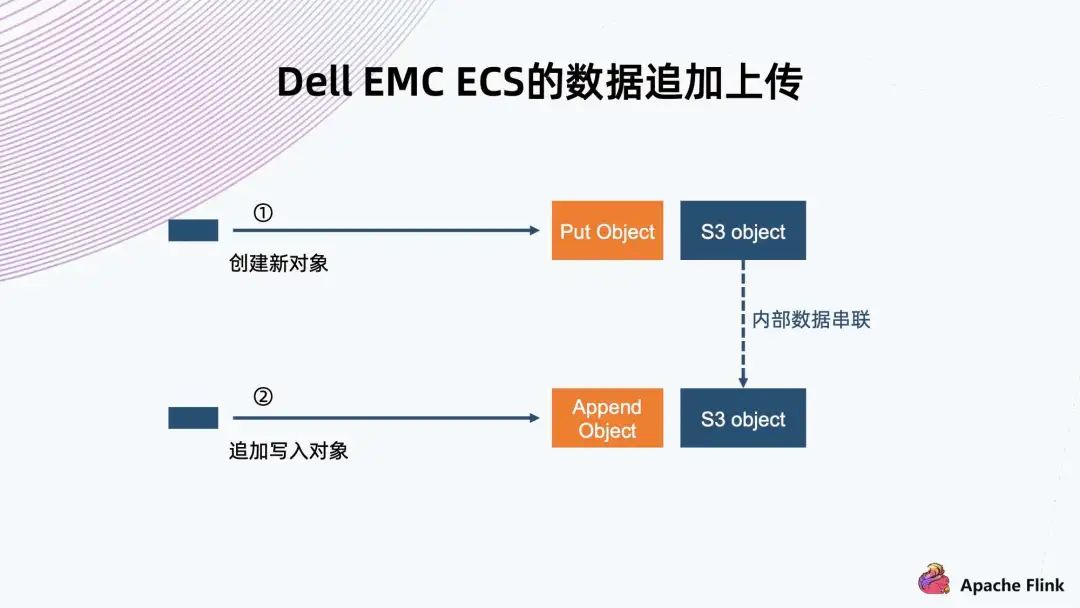
5. Dell EMC ECS 的數(shù)據(jù)追加上傳
6. Dell EMC ECS 在并發(fā)提交下的解決方案
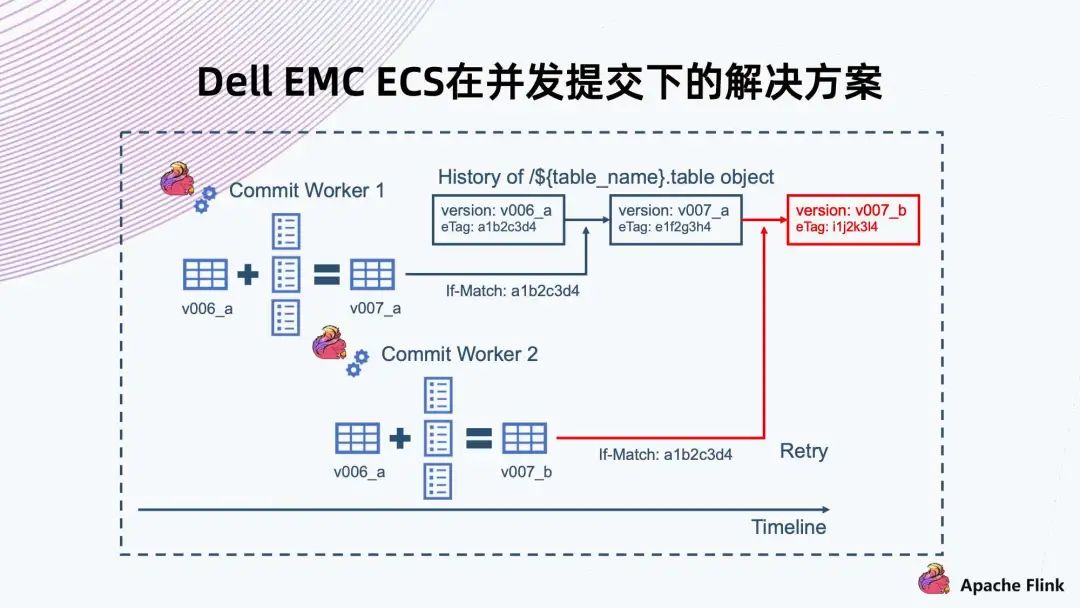
If-Match 就是說在 Commit Worker 1 提交拿到 v006 的時候,同時拿到了文件的 eTag。提交的時候會帶上 eTag,系統(tǒng)需要判斷要覆蓋文件的 eTag 跟當前這個文件真實 eTag 是否相同,如果相同就允許這次覆蓋操作,那么 v007 就能提交成功; 另一種情況,是 Commit Worker 2 也拿到了 v006 的 eTag,然后上傳的時候發(fā)現(xiàn)拿到 eTag 跟當前系統(tǒng)里文件不同,則會返回失敗,然后觸發(fā) Retry。
7. S3 Catalog - 統(tǒng)一存儲的數(shù)據(jù)
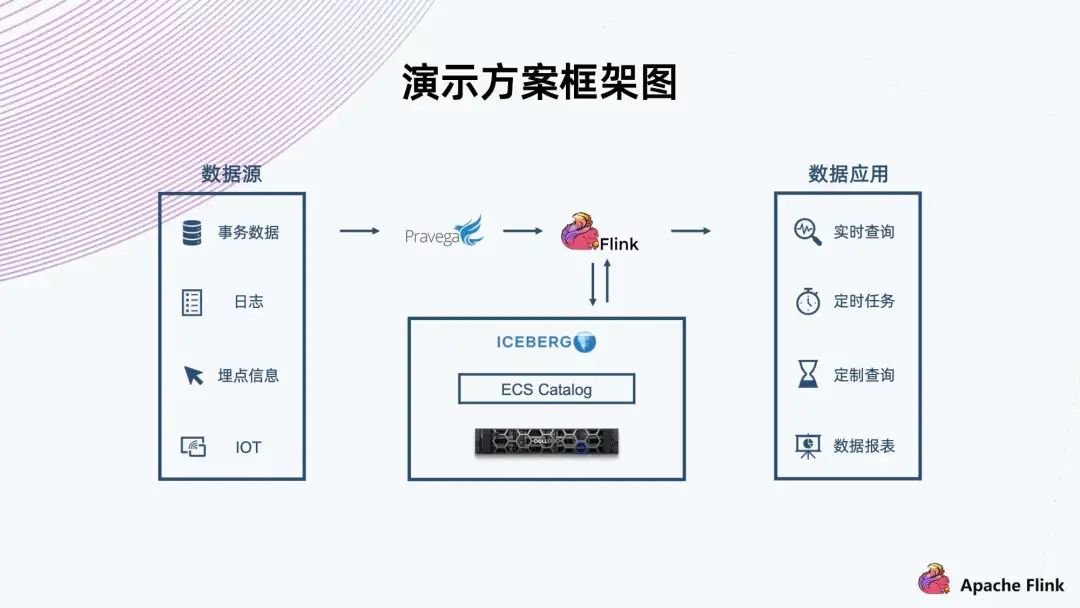
三、演示方案
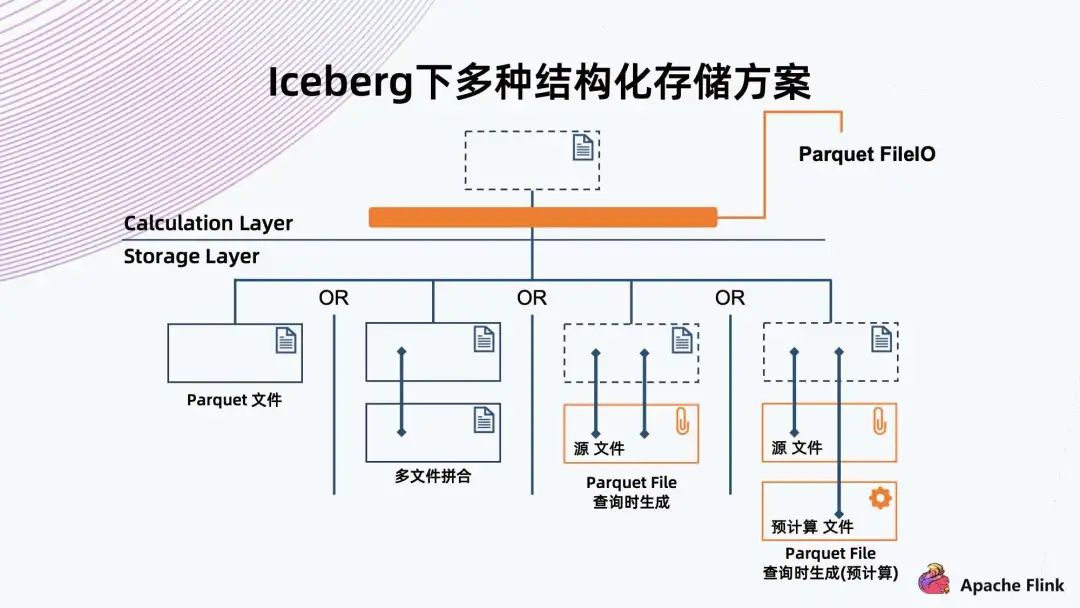
四、存儲優(yōu)化的一些思考
另外~《Apache Flink-實時計算正當時》電子書重磅發(fā)布,本書將助您輕松 Get Apache Flink 1.13 版本最新特征,同時還包含知名廠商多場景 Flink 實戰(zhàn)經(jīng)驗,學用一體,干貨多多!快掃描下方二維碼獲取吧~
(本次為搶鮮版,正式版將于 7 月初上線)

更多 Flink 相關技術交流,可掃碼加入社區(qū)釘釘大群~
▼ 關注「Flink 中文社區(qū)」,獲取更多技術干貨 ▼
 戳我,立即報名!
戳我,立即報名!評論
圖片
表情