
送書了!分布式人工智能算法詳解
一、單體算法優(yōu)化

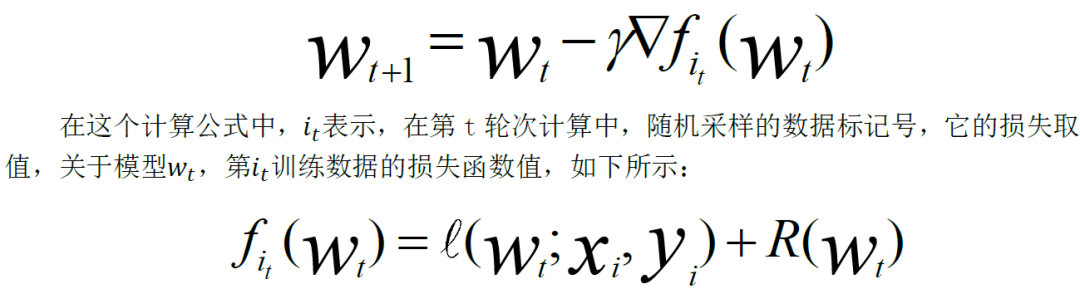
void Stochastic_gradient_descent(){initialize:初始化w0參數(shù)Iterate:for t= 0,1,…,T-1 遍歷所有樣本Selecte:隨機選取樣本計算:獲得梯度更新:更新參數(shù)}

void random_coordinate_descent(){Initialize: 初始化w0參數(shù)Iterate:for t= 0,1,…,T-1 遍歷所有樣本Selecte:隨機選取模型維度計算:獲得梯度更新:更新參數(shù)}

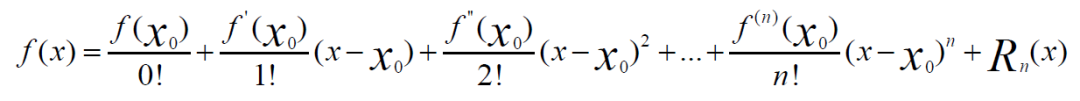
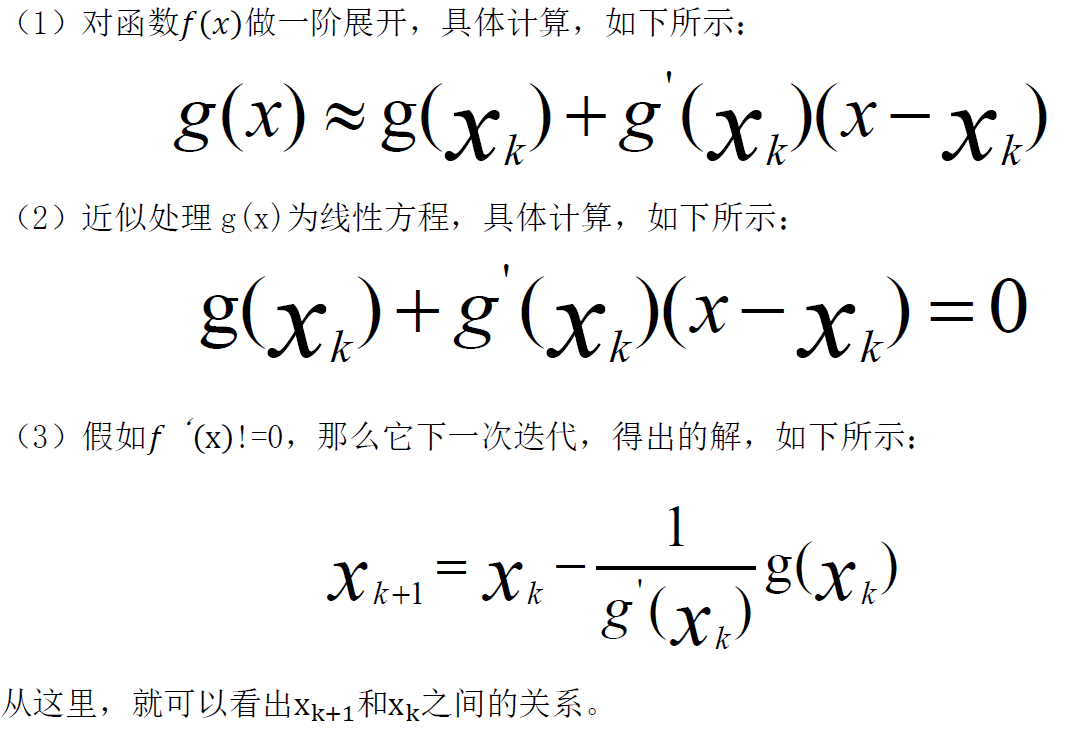


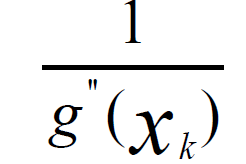
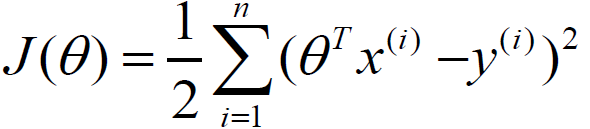
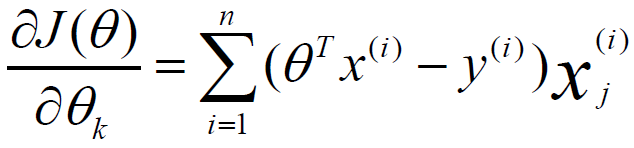
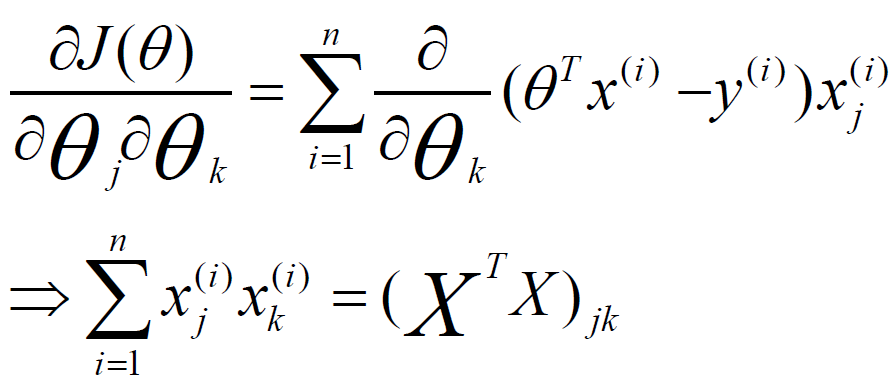
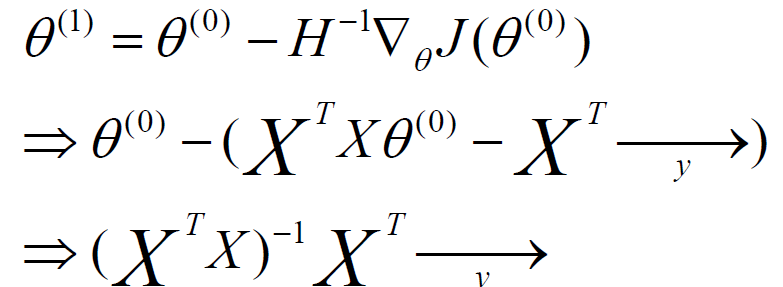
二、分布式異步隨機梯度下降
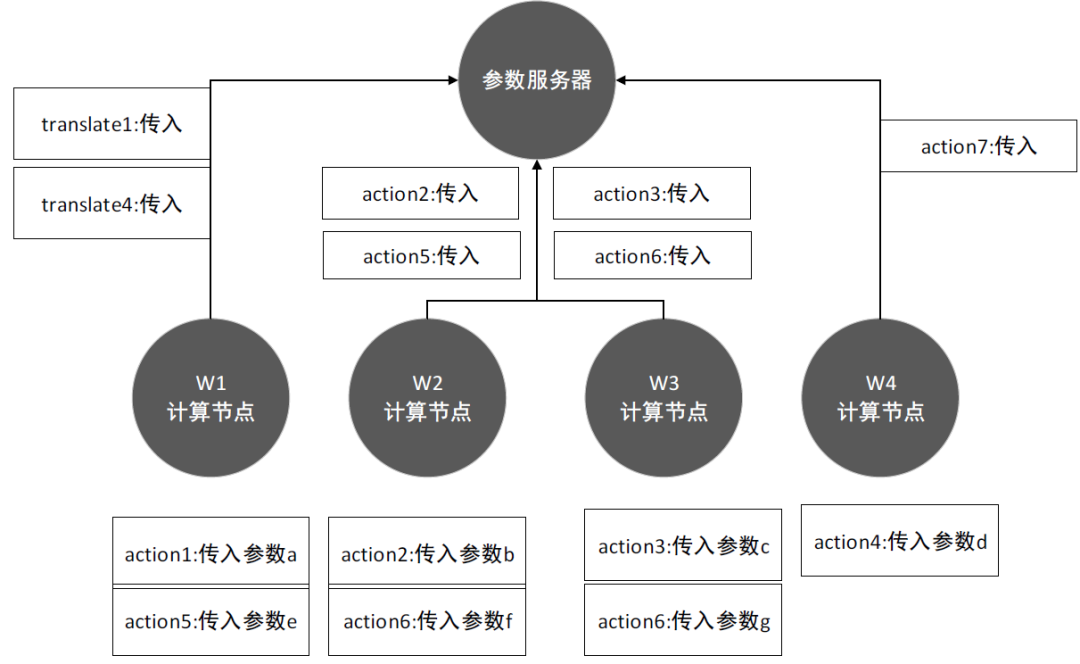
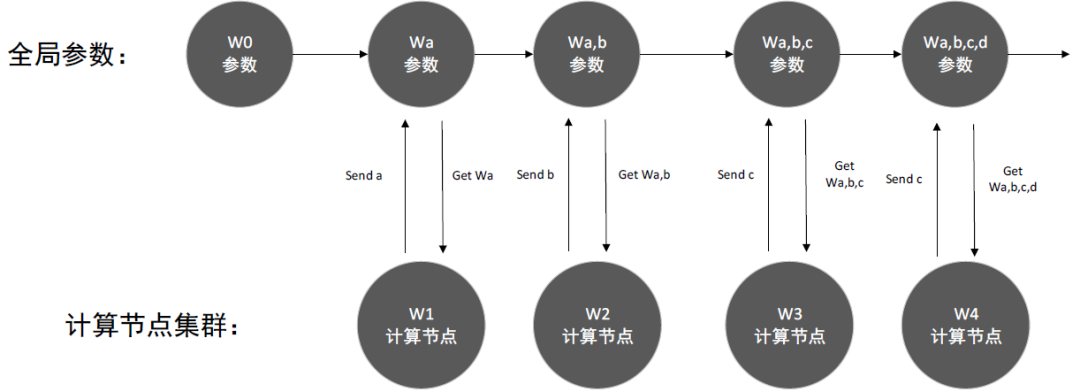
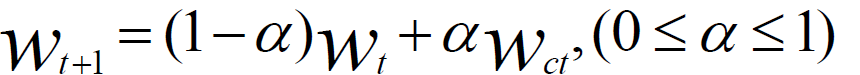
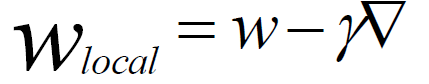
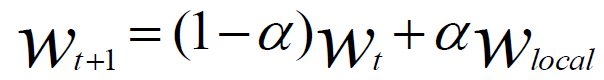
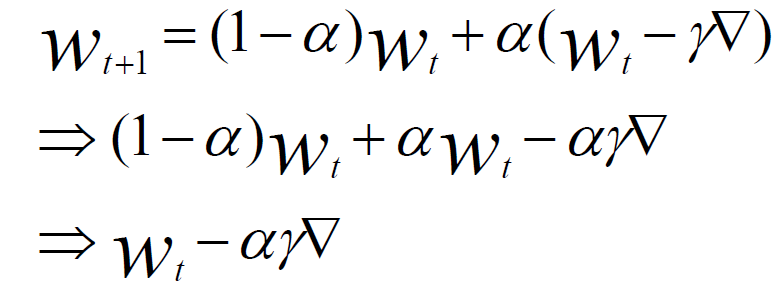
void SGD_Client(){ProcedureWork(Parameterw,Mini-batch-sizeNcInitialize:total gradientg = 0For all i∈{1...Nc} do+ ComputeGradient(data,w)End ForServer.Update(c,g)stepc ←stepc +1}
void SGD_Server(){Procedure DispatchJob(Client c,Parameter wt)Call procedure Work(wt,Nc)for client cEndProcedure Update(Client c,Gradient g)wt+1 ←wt ? AdaGrad(g)t←t+1If c is the last client whose stepc =the server step thenstep←step+1End IfIf running thenDispatchJob(c,wt)End IfEnd}
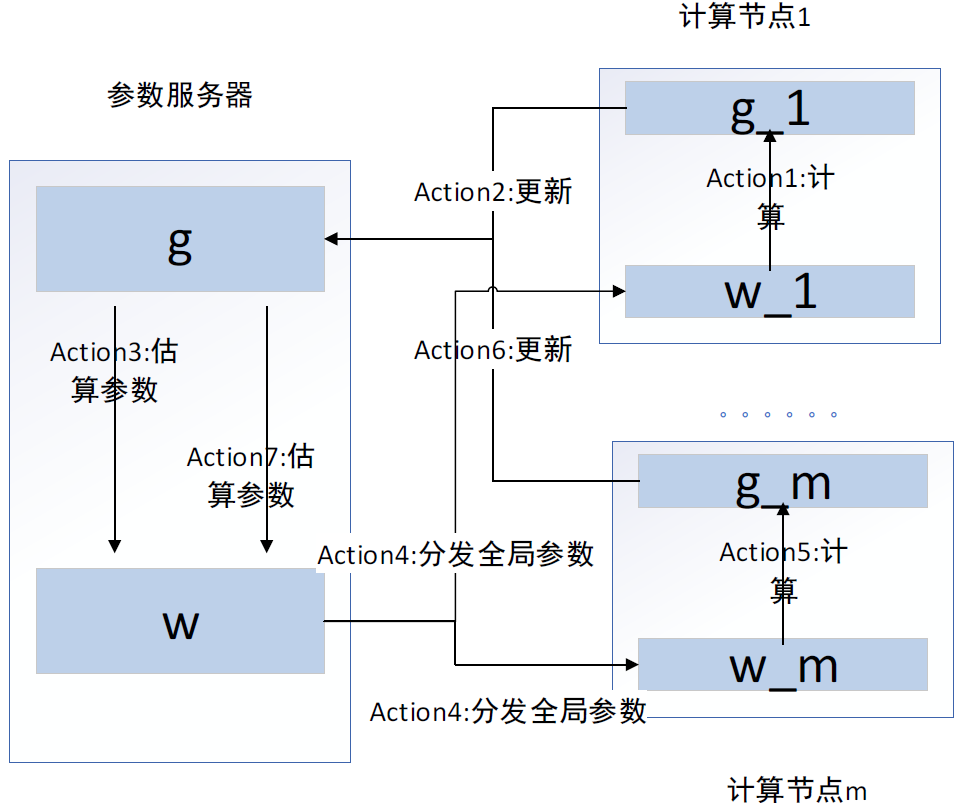
本書摘自機械工業(yè)出版社---《分布式人工智能:基于TensorFlow RTOS與群體智能體系》一書,經授權刊登此公號。


如果你對以上內容感興趣
快在留言區(qū)大聲告訴我們
截止2月1日晚八點
留言獲贊數(shù)最高的五位同學各贈一本
《分布式人工智能基于TensorFlow、RTOS與群體智能體系》

沒有抽中的粉絲不要氣餒,可在當當網購買此書,快快來搶購吧。
上述內容,如有侵犯版權,請聯(lián)系作者,會自行刪文。
評論
圖片
表情