
數(shù)倉分析 | Snowflake & Delta Lake兩大新型數(shù)倉對比分析
Snowflake & Delta Lake 代表了當前業(yè)內最先進的兩種數(shù)倉形態(tài),并且都得到了市場上用戶的高度認可。
概述
數(shù)據(jù)分析從上世紀 80 年代興起以來,大體經歷了企業(yè)數(shù)倉(EDW)、數(shù)據(jù)湖(Data Lake)、以及現(xiàn)在的云原生數(shù)倉、湖倉一體等過程。企業(yè)數(shù)倉是數(shù)據(jù)倉庫最原始的版本,從當前的視角來看,存在著只能處理結構化數(shù)據(jù)、集中式的存儲和計算、以及成本昂貴等缺點。數(shù)據(jù)湖是伴隨著數(shù)據(jù)爆炸式增長而出現(xiàn)的技術,它能夠存儲結構化以及非結構化的數(shù)據(jù)、擁有分布式的存儲、以及經濟的成本。但由于其“不管后面用不用,先存儲起來”的理念,在數(shù)據(jù)治理、質量審核方面有很多的缺失,因此在后續(xù)實際的使用當中會面臨較多的問題。以 Snowflake 和 Delta Lake 為代表的新興數(shù)倉就是有針對性的去解決上述問題,并充分利用當前卓越技術(如云計算、Hadoop、Spark 等)的新一代企業(yè)數(shù)據(jù)解決方案。
總體來看,Snowflake 像是企業(yè)數(shù)倉(EDW)的 2.0 版本。Delta Lake 則是 Data Lake 的 2.0 版本。
兩個陣營都在爭相成為一站式服務,來處理用戶的任何數(shù)據(jù),以及應對任何場景。
Snowflake 2019 提出 Data Ocean - 支持結構化、半結構化數(shù)據(jù),并提供彈性擴展,存儲便宜、計算按需付費,事務支持,托管服務功能。19 Q3提供數(shù)據(jù)復制功能,使 Snowflake 客戶能夠復制數(shù)據(jù)庫,并使數(shù)據(jù)庫在不同區(qū)域和/或云提供商的多個帳戶之間保持同步。這樣可以確保在區(qū)域性或云提供商中斷的情況下業(yè)務連續(xù)性。它還允許客戶想要遷移到其他區(qū)域或云時所需的可移植性。另一個好處是能夠輕松安全地在區(qū)域和云之間共享數(shù)據(jù)。擴展全球數(shù)據(jù)湖的覆蓋范圍,從而將數(shù)據(jù)湖變成數(shù)據(jù)海洋。
Databricks 2020 基于 Delta Lake 提出 Data Lakehouse 概念。數(shù)據(jù)湖 1.0 版本雖然適用于存儲數(shù)據(jù),但缺少一些關鍵功能:它們不支持事務,它們不強制執(zhí)行數(shù)據(jù)質量,并且缺乏一致性/隔離性,幾乎不可能混合添加和讀取以及批處理和流式作業(yè)。由于這些原因,數(shù)據(jù)湖的許多承諾尚未實現(xiàn),并且在許多情況下導致失去數(shù)據(jù)倉庫的許多好處。Data Lakehouse 提供事務支持,強制的模式要求及健壯的治理和審核機制,除了提供對 BI 分析的支持,Data Lakehouse 還支持存算分離,數(shù)據(jù)格式開放性,非結構化到結構化數(shù)據(jù)類型全支持,以及支持機器學習、科學計算及 AI 等工作負載,并提供端到端流等功能。
下面對 Snowflake 和 Delta Lake 分別做一個詳細介紹。
Snowflake 介紹
Snowflake 是完全建立在云上的企業(yè)級數(shù)據(jù)倉庫解決方案。Snowflake 是云原生的因為它針對并基于云環(huán)境進行了根本性的重新設計,處理引擎和其他大部分組件都是從新開始開發(fā)的。Snowflake 在亞馬遜及其他云上提供即付即用的服務。用戶只需將數(shù)據(jù)導入云,就可以立即利用他們熟悉的工具和界面進行管理和查詢。從 2012 年底,Snowflake 開始計劃實施,到 2015 年 6 月,Snowflake 已經可以大體可用。目前,Snowflake 已經被越來越多的組織采用,每天管理者幾百上千萬次的查詢以及 PB 級以上的數(shù)據(jù)。
Snowflake 的關鍵特點如下:
*?純粹的 SaaS 服務體驗:用戶不需要購買機器、聘請數(shù)據(jù)庫管理員或安裝軟件。用戶要么已經在云中擁有數(shù)據(jù),要么上傳數(shù)據(jù)。然后,就可以使用 Snowflake 的圖形界面或 ODBC 等標準化接口立即操作和查詢數(shù)據(jù)。與其他數(shù)據(jù)庫即服務(DBaaS)產品不同,Snowflake 的服務覆蓋了整個用戶體驗。用戶無需調優(yōu),無需物理設計,無需存儲整理任務。
*?關系型語法兼容:Snow?ake 對 ANSI SQL 和 ACID 事務提供了全面的支持。大多數(shù)用戶幾乎不需要更改就可以遷移現(xiàn)有工作負載。
*?半結構化數(shù)據(jù)支持:自動模式發(fā)現(xiàn)(schema)及列式存儲等功能使得 Snowflake 可以像普通關系數(shù)據(jù)一樣處理無 schema、半結構化的數(shù)據(jù),并沒有額外開銷。
*?彈性
*?高可用
*?數(shù)據(jù)持久性
*?經濟:以上都是云原生所帶來的好處。
*?安全:Snowflake 中所有的數(shù)據(jù)包括臨時文件及網(wǎng)絡傳輸都是端到端加密的,沒有任何信息會暴露。并且基于角色的權限控制使用戶能夠在 SQL 級別上執(zhí)行細粒度的訪問控制。
Snowflake 核心技術
存儲和計算分離
Shared-nothing 架構目前已經成為高性能數(shù)據(jù)倉庫的主流體系結構,主要原因有兩個:可擴展性和商用廉價硬件。在 Shared-nothing 結構中,每個查詢處理器節(jié)點都有自己的本地磁盤。表是跨節(jié)點水平分區(qū)的,每個節(jié)點只負責其本地磁盤上的行。這種設計可以很好地擴展星型模式查詢,因為將一個小的(廣播的)維度表與一個大的(分區(qū)的)事實表連接起來只需要很少的帶寬。而且,由于共享數(shù)據(jù)結構或硬件資源幾乎沒有爭用,因此不需要昂貴的定制硬件。這種方法是很容易理解的并具有良好優(yōu)點的軟件設計。
不過,純粹的 Shared-nothing 結構有一個重要的缺點:它將計算資源和存儲資源緊密耦合,這在某些場景中會導致問題。
異構工作負載:雖然硬件是同樣的,但工作負載通常不是。有些任務需要高 IO,輕計算,有些需要重計算,輕 IO。因此,硬件配置需要在平均利用率較低的情況下進行權衡。
節(jié)點關系變化:如果一些節(jié)點發(fā)生更改,或者是由于節(jié)點故障,或者是用戶調整系統(tǒng)大小,則大量數(shù)據(jù)需要重新 shuffle。由于相同的節(jié)點同時負責數(shù)據(jù) shuffle 和查詢,因此會對性能有顯著的影響,從而限制了靈活性和可用性。
在線升級:雖然可以通過數(shù)據(jù)復制、系統(tǒng)節(jié)點交替升級等技術減少影響,但總體上還是比較困難。
在本地環(huán)境,這些問題,發(fā)生的頻率較小,通常都可以容忍。但在云上,云服務商有很多不同規(guī)格的節(jié)點,只要正確的選擇就能充分利用資源,而節(jié)點的故障等引起的關系變化是常態(tài),用戶也有強烈的需求需要在線升級和彈性擴展。因此,基于上述等等原因,Snowflake 選擇了存儲和計算分離設計。
存儲和計算由兩個松耦合、獨立可擴展的服務來處理。計算是通過 Snowflake 的(專有的)shared-nothing 引擎提供的。存儲是通過亞馬遜 S3(或 Azure 對象存儲,Google云存儲) 提供的。同時,為了減少計算節(jié)點和存儲節(jié)點之間的網(wǎng)絡流量,每個計算節(jié)點在本地磁盤上緩存了一些表的數(shù)據(jù)。
存儲和計算分離的另一個好處是,本地磁盤空間不用存儲整個數(shù)據(jù),這些數(shù)據(jù)可能非常大,而且大部分是冷數(shù)據(jù)(很少訪問)。本地磁盤專門用于臨時數(shù)據(jù)和緩存,兩者都是熱數(shù)據(jù)(建議使用高性能存儲設備,如 SSD)。因此,緩存了熱數(shù)據(jù),性能就接近甚至超過純 shared-nothing 結構的性能。Snowflake 稱這種新的體系結構為 multi-cluster、shared-data 架構。
架構介紹
Snowflake 是一個面向服務的體系結構,由高度容錯和獨立可擴展的服務組成。這些服務通過 RESTful 接口進行通信,分為三個體系結構層:
* 數(shù)據(jù)存儲。該層使用 amazon s3 存儲表數(shù)據(jù)和查詢結果。
* 虛擬倉庫。系統(tǒng)的“肌肉”。該層通過彈性的虛擬集群(稱為虛擬倉庫),執(zhí)行查詢。
* 云服務。系統(tǒng)的“大腦”。這一層是管理虛擬倉庫、查詢、事務和圍繞虛擬倉庫的所有元數(shù)據(jù)的服務的集合,包含數(shù)據(jù)庫元信息、訪問控制信息、加密密鑰、使用情況統(tǒng)計等。
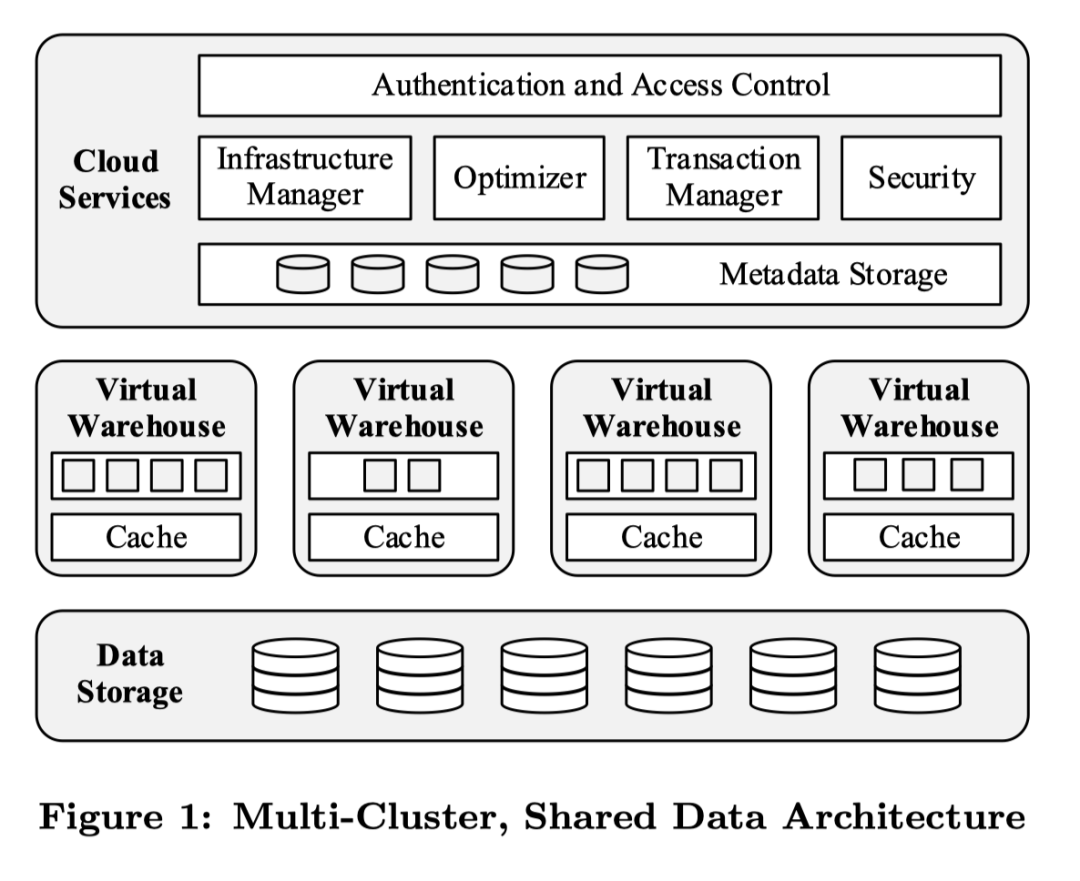
數(shù)據(jù)存儲
Snowflake 數(shù)據(jù)存儲直接采用了 Amazon S3 等云存儲服務,并沒有自己開發(fā),而是將精力投入在了數(shù)據(jù)處理優(yōu)化的其他方面。
S3 是一個對象存儲,具有一個相對簡單的基于 HTTP 的 PUT/GET/DELETE 接口。對象(即文件)只能完全寫入。甚至不可能將數(shù)據(jù)附加到文件的末尾。文件的確切大小需要在 PUT 請求中前就確定。并且,S3 支持對部分(范圍)文件的 GET 請求。
Snowflake 存儲的數(shù)據(jù)格式采用的是列存 + 每個表文件都有一個文件頭,其中包含文件中每列的偏移量,以及其他元數(shù)據(jù)。因為 S3 允許對部分文件執(zhí)行 GET 請求,所以查詢只需要下載文件頭和它們需要的列。
Snowflake 不僅在表數(shù)據(jù)上使用 S3。當本地磁盤空間耗盡時,它還使用 S3 存儲由查詢(例如,大量連接)生成的臨時數(shù)據(jù),以及大型查詢結果。將 temp 數(shù)據(jù)溢出到 S3,系統(tǒng)可以計算任意大的查詢,而不會出現(xiàn)內存不足或磁盤不足的錯誤。將查詢結果存儲在 S3 中,實現(xiàn)了客戶端交互新方式并簡化查詢處理,因為它消除了對傳統(tǒng)數(shù)據(jù)庫系統(tǒng)中的服務端游標的需要。
元數(shù)據(jù),例如 catalog 信息,由 S3 文件、統(tǒng)計信息、鎖、事務日志等組成,存儲在可伸縮的事務 KV 存儲中,這也是云服務的一部分。
虛擬倉庫(Virtual Warehouses)
虛擬倉庫層由 EC2 實例集群組成。
虛擬倉庫的彈性與隔離
VM 層是純計算資源,可以按照需求創(chuàng)建、銷毀或者在任意時刻改變大小。創(chuàng)建或者銷毀一個 VM 對數(shù)據(jù)庫狀態(tài)沒有任何影響。當沒有查詢時候,用戶可以關閉所有的 VM 資源。這種彈性容許用戶獨立于數(shù)據(jù)層,按照需求動態(tài)的伸縮他們的計算資源。
每個查詢只在一個 VW 上運行。工作節(jié)點不會在 VW 之間共享,從而使查詢具有強大性能隔離。(Snowflake 計劃后續(xù)會加強工作節(jié)點共享)。每個用戶可以在任何給定的時間運行多個 VW,而每個 VW 又可以運行多個并發(fā)查詢。每個 VW 都可以訪問相同的共享表,而無需物理復制數(shù)據(jù)。
另一個與彈性有關的重要結果是,通常可以用大致相同的價格獲得更好的性能表現(xiàn)。例如,在具有 4 個節(jié)點的系統(tǒng)上,數(shù)據(jù)加載需要 15 小時,而在具有 32 個節(jié)點的系統(tǒng)上,數(shù)據(jù)加載可能只需要 2 小時。由于計算是按時間付費的,所以總體成本非常相似,但用戶體驗卻截然不同。因此,彈性是 Snowflake 架構最大的優(yōu)點和區(qū)別之一,因為需要一種新穎的設計來利用云的獨特功能。
虛擬倉庫的本地緩存和文件竊取
每一個 worker 節(jié)點在本地磁盤上緩存了一些表數(shù)據(jù)。緩存的文件是一些表文件,即節(jié)點過去訪問過的 S3 對象。準確地說,緩存保存文件頭和文件的各個列,因為查詢只下載它們需要的列。緩存在工作節(jié)點的工作時間內有效,并在并發(fā)和后續(xù)工作進程(即查詢)之間共享。Snowflake 使用最近最少使用(LRU)策略替換緩存文件。為了提高命中率并避免 VW 的工作節(jié)點之間對單個表文件進行冗余緩存,查詢優(yōu)化器使用表文件名上的一致哈希將輸入文件集分配給工作節(jié)點。因此,訪問同一表文件的后續(xù)查詢或并發(fā)查詢將在同一工作節(jié)點上執(zhí)行。
除了緩存,傾斜處理在云數(shù)據(jù)倉庫中尤為重要。由于虛擬化問題或網(wǎng)絡爭用,某些節(jié)點的執(zhí)行速度可能比其他節(jié)點慢得多。在這點上,Snowflake 在掃描文件的時候就處理了這個問題。每當工作進程完成對其輸入文件集的掃描時,它就會從其對等進程請求其他文件,這個過程稱之為文件竊取。當請求到達時,如果一個 worker 發(fā)現(xiàn)它的輸入文件集合中還有許多文件要處理,這個時候又有其他 worker 請求幫助,這個 worker 將這個請求中他需要的查詢的范圍內的一個剩余文件的處理權力轉移給其他 worker。然后其他 worker 直接從 S3 下載文件,而不是從這個 worker 下載。這種設計確保了文件竊取不會給當前 worker 增加額外的處理負擔。
虛擬倉庫執(zhí)行引擎
Snowflake 自己實現(xiàn)了 SQL 執(zhí)行引擎。并且構建的引擎是列式的、向量化的和基于 push 的。
* 列式存儲在數(shù)據(jù)分析場景更適用,因為它更有效地使用了 CPU 緩存和 SIMD 指令,并且能進行更有效的壓縮。
* 向量化執(zhí)行。與 MapReduce 相比,Snowflake 避免了中間結果的物化。相反,數(shù)據(jù)是以 pipeline 方式處理的,每次以列成批處理幾千行。這種方法由 VectorWise(最初是 MonetDB/X100)首創(chuàng),這能節(jié)省 I/O 并大大提高了緩存效率。
* 基于 push 的執(zhí)行是指,關系運算符將過濾推送到其下游運算符,而不是等待這些運算符拉取數(shù)據(jù)。
云服務
虛擬倉庫是臨時的、特定于用戶的資源。相反,云服務層在很大程度上是多租戶的。這一層的每個服務訪問控制、查詢優(yōu)化器、事務管理器和其他服務都是長期存在的,并在許多用戶之間共享。多租戶提高了利用率并減少了管理開銷,這比傳統(tǒng)體系結構中每個用戶都有一個完全私有的系統(tǒng)在體系結構上具有更好的規(guī)模經濟。并且每個服務都被復制以實現(xiàn)高可用性和可擴展性。
查詢管理和優(yōu)化
用戶所有的查詢都通過云服務層。云服務層處理查詢生命周期的所有早期階段:解析、對象解析、訪問控制和計劃優(yōu)化。優(yōu)化器完成后,生成的執(zhí)行計劃將分發(fā)給部分查詢節(jié)點。當查詢執(zhí)行時,云服務會不斷跟蹤查詢的狀態(tài),收集性能指標并檢測節(jié)點故障。所有查詢信息和統(tǒng)計信息都存儲起來,進行審計和性能分析。用戶可以通過 Snowflake 圖形界面監(jiān)視和分析之前和正在進行的查詢。
并發(fā)控制
如前所述,并發(fā)控制完全由云服務層處理。Snowflake 是為分析工作而設計的,這些工作往往會有大量讀取、批量或隨機插入以及批量更新。與大多數(shù)系統(tǒng)一樣,我們決定通過快照隔離(Snapshot Isolation)實現(xiàn) ACID 事務。
在 SI 下,事務的所有讀取都會看到事務啟動時數(shù)據(jù)庫的一致性快照。通常,SI 是在多版本并發(fā)控制(MVCC)之上實現(xiàn)的,因此每個更改的數(shù)據(jù)庫對象的一個副本都會保留一段時間。
MVCC 是使用 S3 等服務存儲后自然的選擇(因為文件不可變更),只有將文件替換為包含更改的其他文件,才能實現(xiàn)更改。因此,表上的寫操作(insert、update、delete、merge)通過添加和刪除相對于上一個表版本的整個文件來生成新版本的表。在元數(shù)據(jù)(在全局鍵值存儲中)中跟蹤文件的添加和刪除,這種形式對屬于特定表版本的文件集計算非常高效。
除了 SI 之外,Snowflake 還使用這些快照來實現(xiàn)時間旅行(Time Travel)和高效的數(shù)據(jù)庫對象復制。
剪枝優(yōu)化
Snowflake 無法使用 B+ 樹或其他類似索引結構來做剪枝優(yōu)化,因為它們嚴重依賴隨機訪問。因此 Snowflake 使用了另一種在大規(guī)模數(shù)據(jù)處理常用的技術:最小-最大值剪枝。系統(tǒng)維護給定數(shù)據(jù)塊(記錄集、文件、塊等)的數(shù)據(jù)分布信息,特別是塊內的最小值和最大值。根據(jù)查詢謂詞的不同,這些值可用于確定給定查詢可能不需要給定的數(shù)據(jù)塊。與傳統(tǒng)索引不同,這種元數(shù)據(jù)通常比實際數(shù)據(jù)小幾個數(shù)量級,因此存儲開銷小,訪問速度快。
除了靜態(tài)剪枝,Snowflake 還在執(zhí)行過程中執(zhí)行動態(tài)剪枝。例如,作為 hash join 處理的一部分,Snowflake 收集有關 build-side 記錄中 join key 分布的統(tǒng)計信息。然后將此信息推送到 probe-side,并用于過濾 probe side 的整個文件,甚至可能跳過這些文件。
Delta Lake 介紹
Delta Lake 是 Spark 背后的公司 Databricks 開發(fā)的數(shù)據(jù)倉庫表存儲層管理技術(table storage layer)。Delta Lake 通過使用壓縮至 Apache Parquent 格式的事務性日志來提供ACID,Time Travel 以及海量數(shù)據(jù)集的高性能元數(shù)據(jù)操作(比如快速搜索查詢相關的上億個表分區(qū))。同時 Delta Lake 也提供一些高階的特性,比如自動數(shù)據(jù)布局優(yōu)化,upsert,緩存以及審計日志等。
根據(jù) Delta Lake 與云客戶工作的經驗來看,客戶在云上管理數(shù)據(jù)的主要痛點是性能及一致性無法滿足,這些一致性以及性能方面的問題對企業(yè)的數(shù)據(jù)團隊產生了很大的挑戰(zhàn)。大多數(shù)的企業(yè)數(shù)據(jù)是持續(xù)更新的,所以需要原子寫的解決方案,多數(shù)涉及到用戶信息的數(shù)據(jù)需要表范圍的更新以滿足GDPR這樣的合規(guī)要求。即使是內部的數(shù)據(jù)也需要更新操作來修正錯誤數(shù)據(jù)以及集成延遲到達的記錄。
Delta Lake 的核心概念很簡單:Delta Lake 使用存儲在云對象中的預寫日志,以 ACID 的方式維護了哪些對象屬于 Delta table 這樣的信息。對象本身寫在 parquet 文件中,使已經能夠處理Parquet格式的引擎可以方便地開發(fā)相應的 connectors。這樣的設計可以讓客戶端以串行的方式一次更新多個對象,替換一些列對象的子集,同時保持與讀寫 parquet 文件本身相同的高并發(fā)讀寫性能。日志包含了為每一個數(shù)據(jù)文件維護的元數(shù)據(jù),如 min/max 統(tǒng)計信息。相比“對象存儲中的文件”這樣的方式,元數(shù)據(jù)搜索相關數(shù)據(jù)文件速度有了數(shù)量級的提升。最關鍵的是,Delta Lake 的設計使所有元數(shù)據(jù)都在底層對象存儲中,并且事務是通過針對對象存儲的樂觀并發(fā)協(xié)議實現(xiàn)的(具體細節(jié)因云廠商而異)。這意味著不需要單獨的服務來維護 Delta table 的狀態(tài),用戶只需要在運行查詢時啟動服務器,享受存儲計算擴展分離帶來的好處。
基于這樣的事務性設計,Delta Lake 能夠提供在傳統(tǒng)云數(shù)據(jù)湖上無法提供的解決用戶痛點的特性,包括:
* Time travel:允許用戶查詢具體時間點的數(shù)據(jù)快照或者回滾錯誤的數(shù)據(jù)更新。
* Upsert,delete 以及 merge 操作:高效重寫相關對象實現(xiàn)對存儲數(shù)據(jù)的更新以及合規(guī)工作流(比如 GDPR)
* 高效的流I/O:流作業(yè)以低延遲將小對象寫入表中,然后以事務形式將它們合并到大對象中來提高查詢性能。支持快速“tail”讀取表中新加入數(shù)據(jù),因此作業(yè)可以將 Delta 表作為一個消息隊列。
* 緩存:由于 Delta 表中的對象以及日志是不可變的,集群節(jié)點可以安全地將他們緩存在本地存儲中。
* 數(shù)據(jù)布局優(yōu)化:在不影響查詢的情況下,自動優(yōu)化表中對象的大小,以及數(shù)據(jù)記錄的聚類(clustering)(將記錄存儲成 Zorder 實現(xiàn)多維度的本地化)。
* Schema 演化:當表的 schema 變化時,允許在不重寫 parquet 文件的情況下讀取舊的 parquet 文件。
* 日志審計:基于事務日志的審計功能。
這些特性改進了數(shù)據(jù)在云對象存儲上的可管理性和性能,并且結合了數(shù)倉和數(shù)據(jù)湖的關鍵特性創(chuàng)造了“湖倉”的典范:直接在廉價的對象存儲上使用標準的 DBMS 管理功能。
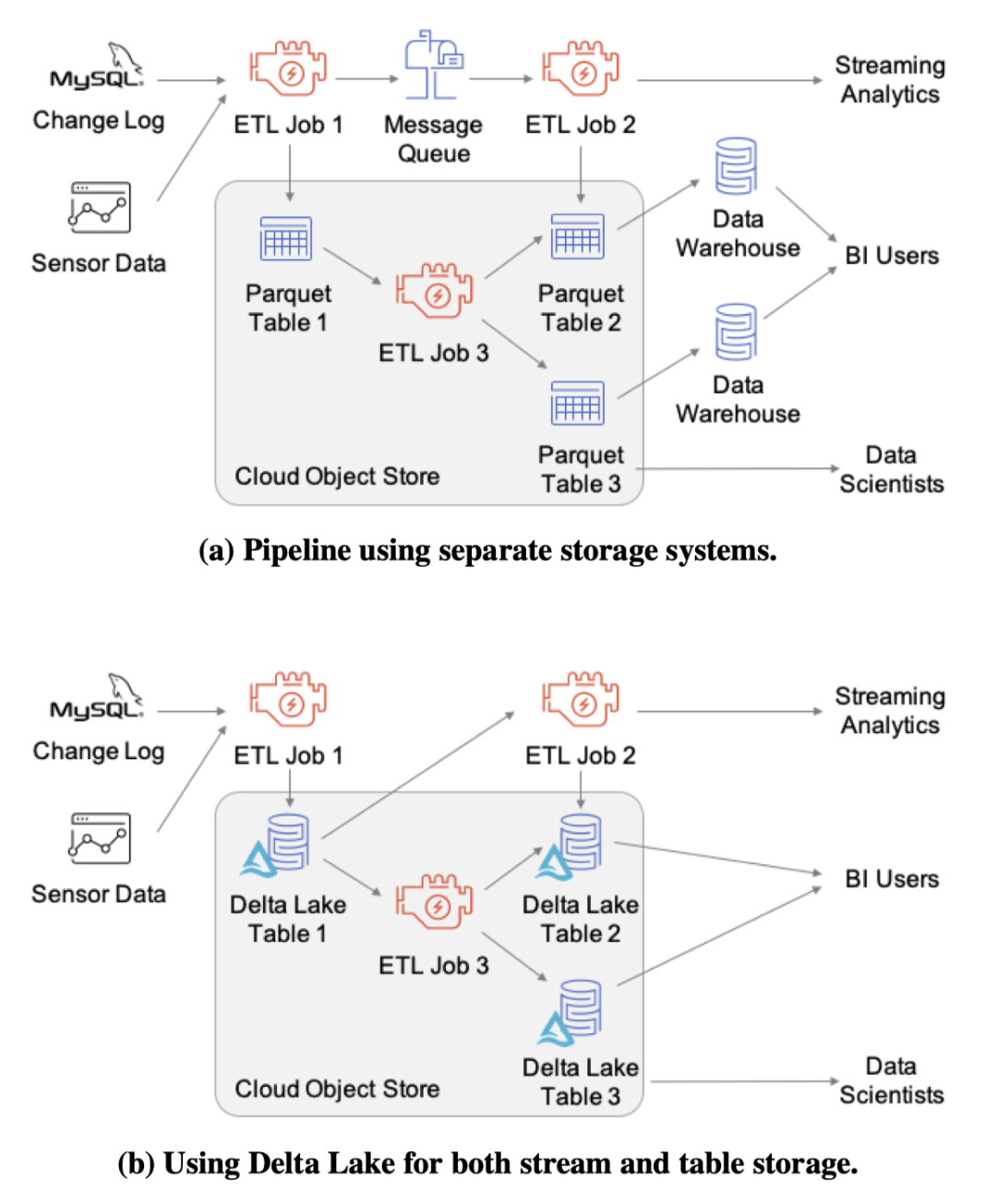
?
Delta Lake 存儲格式及訪問協(xié)議
Delta Lake 表是云對象存儲或文件系統(tǒng)上的一個目錄,其中包含了表數(shù)據(jù)對象和事務操作日志(以及 checkpoint 日志)對象。客戶端使用樂觀并發(fā)控制協(xié)議來更新這些數(shù)據(jù)結構。
存儲格式示例如下所示:

?
數(shù)據(jù)對象
Delta Lake 中,數(shù)據(jù)對象采用 parquet 格式存儲,數(shù)據(jù)對象可分區(qū),并且名稱為唯一的 GUID。
日志對象
Delta Lake 日志對象存儲在表的 _delta_log 子目錄中,它包含一系列連續(xù)的遞增數(shù)字作為 ID 的 JSON 對象用于存儲日志記錄,以及某些特定日志對象的檢查點,這些檢查點將檢查點之前的日志合并為 Parquet 格式。每個日志記錄對象(比如 000003.json)包含了在前一個版本的表基礎上進行的操作數(shù)組。這些操作數(shù)組用于保存數(shù)據(jù)對象信息,數(shù)據(jù)對象的添加記錄還可以包括數(shù)據(jù)統(tǒng)計信息,例如總記錄條數(shù)以及每列的最小/最大值和空計數(shù)。
另外 Delta Lake 的日志對象還可以保存一些額外信息,比如更新應用事務 ID。Delta Lake 為應用程序提供了一種將應用程序的數(shù)據(jù)包括在日志記錄中的方法,允許應用程序在其日志記錄對象中寫入帶有 appId 和版本字段的自定義 txn 操作,這樣該日志對象就可以用來跟蹤應用程序特定的信息,例如應用程序輸入流的對應偏移量。這對于實現(xiàn)端到端事務性應用很有用。例如,寫入 Delta 表的流處理系統(tǒng)需要知道先前已經提交了哪些寫入,才能實現(xiàn)Exactly Once 語義:如果流作業(yè)崩潰,則需要知道其哪些寫入先前已寫入表中,以便它可以從輸入流中的正確偏移處開始重播后續(xù)寫入。
日志 checkpoint
日志 checkpoint 的主要作用是對日志對象(json 文件)進行定期壓縮,刪除冗余,冗余的操作包括:
* 對同一數(shù)據(jù)對象先執(zhí)行添加操作,然后執(zhí)行刪除操作。可以刪除添加項,因為數(shù)據(jù)對象不再是表的一部分。根據(jù)表的數(shù)據(jù)retention配置,應將刪除操作保留為墓碑具體來說,客戶端使用在刪除操作中的時間戳來決定何時從存儲中刪除對象。
* 同一對象的多個添加項可以被最后一個替換,因為新添加項只能添加統(tǒng)計信息。
* 來自同一 appId 的多個 txn 操作可以被最新的替換,因為最新的 txn 操作包含其最新版本字段
* changeMetadata 以及協(xié)議操作也可以進行合并以僅保留最新的元數(shù)據(jù)。
checkpoint 采用 parquet 格式保存,這種面向列的文件對于查詢表的元數(shù)據(jù)以及基于數(shù)據(jù)統(tǒng)計信息查找哪些對象可能包含與選擇性查詢相關的數(shù)據(jù)來說是非常理想的存儲格式。默認情況下,客戶端每10個事務會寫入一個檢查點。為了便于查找,另外還有一個 _last_checkpoint 文件用于保存最新的 Checkpoint ID。
讀表操作
Delta Lake 按以下步驟對表進行讀取:
1. 在 table 的 log 目錄讀取 _last_checkpoint 對象,如果對象存在,讀取最近一次的 checkpoint ID
2. 在對象存儲 table 的 log 目錄中執(zhí)行一次 LIST 操作,如果“最近一次 checkpoint ID”存在,則以此 ID 做 start key;如果它不存在,則找到最新的 .parquet 文件以及其后面的所有 .json 文件。這個操作提供了數(shù)據(jù)表從最近一次“快照”去恢復整張表所有狀態(tài)所需要的所有文件清單。
3. 使用“快照”(如果存在)和后續(xù)的“日志記錄”去重新組成數(shù)據(jù)表的狀態(tài)(即,包含 add records,沒有相關 remove records 的數(shù)據(jù)對象)和這些數(shù)據(jù)對象的統(tǒng)計信息。
4. 使用統(tǒng)計信息去定位讀事務的 query 相關的數(shù)據(jù)對象集合。
5. 可以在啟動的 spark cluster 或其他計算集群中,并行的讀取這些相關數(shù)據(jù)對象。
這個訪問協(xié)議的每一步中都有相關的設計去規(guī)避對象存儲的最終一致性。比如,客戶端可能會讀取到一個過期的 _last_checkpoint 文件,仍然可以用它的內容,通過 LIST 命令去定位新的“日志記錄”文件清單,生產最新版本的數(shù)據(jù)表狀態(tài)。這個 _last_checkpoint 文件主要是提供一個最新的快照 ID,幫助減少 LIST 操作的開銷。同樣的,客戶端能容忍在 LIST 最近對象清單時的不一致(比如,日志記錄 ID 之間的 gap),也能容忍在讀取日志記錄中的數(shù)據(jù)對象時,還不可見,通過等一等/重試的方式去規(guī)避。
寫事務
一個寫入數(shù)據(jù)的事務,一般會涉及最多 5 個步驟,具體有幾步取決于事務中的具體操作:
1. 找到一個最近的日志記錄 ID,比如 r,使用讀事務協(xié)議的 1-2 步(比如,從最近的一次 checkpoint ID 開始往前找)。事務會讀取表數(shù)據(jù)的第 r 個版本(按需),然后嘗試去寫一個 r+1 版本的日志記錄文件。
2. 讀取表數(shù)據(jù)的 r 版本數(shù)據(jù),如果需要,使用讀事務相同的步驟(比如,合并最新的checkpoint .parquet 和 較新的所有 .json 日志記錄文件,生成數(shù)據(jù)表的最新狀態(tài),然后讀取數(shù)據(jù)表相關的數(shù)據(jù)對象清單)
3. 寫入事務相關的數(shù)據(jù)對象到正確的數(shù)據(jù)表路徑,使用 GUID 生成對象名。這一步可以并行化。最后這些數(shù)據(jù)對象會被最新的日志記錄對象所引用。
4. 嘗試去寫本次寫事務的日志記錄到 r+1 版本的 .json 日志記錄對象中 ,如果沒有其他客戶端在嘗試寫入這個對象(樂觀鎖)。這一步需要是原子的(atomic),如果失敗需要重試。
5. 此步可選。為 r+1 版本的日志記錄對象,寫一個新的 .parquet 快照對象。然后,在寫事務完成后,更新 _last_checkpoint 文件內容,指向 r+1 的快照。
關于隔離級別
Delta Lake 寫事務實現(xiàn)了線性隔離級別,也使得事務的日志記錄 ID 可以線性的增長。Delta Lake 讀事務是 snapshot isolation 級別或者 serializability 的。根據(jù)默認的讀數(shù)據(jù)流程(如上所述),讀取過程是快照隔離級別的,但是客戶端如果想達到線性化(serializable)的讀取,可以發(fā)出一個“read-write”的事務,假裝 mock 一次寫事務然后再讀,來達到線性化。
Delta 中的高級功能
* Time Travel(時間旅行)
* 高效效的更新,刪除和合并
* 流式的數(shù)據(jù)導入和消費
* 數(shù)據(jù)布局優(yōu)化(OPTIMIZE Command / Z-Ordering by Multiple Attributes)
* 緩存
* 審計日志
* Schema 演變和增強
Delta 探討 & 局限
首先,Delta Lake 目前只支持單表的序列化級別的事務,因為每張表都有它自己的事務日志。如果有跨表的事務日志將能打破這個局限,但這可能會顯著的增加并發(fā)樂觀鎖的競爭(在給日志記錄文件做 append 時)。在高 TPS 的事務場景下,一個 coordinator 是可以承接事務 log 寫入的,這樣能解決事務直接讀寫對象存儲。
然后,在流式工作負載下,Delta Lake 受限于云對象存儲的 latency。比如,使用對象存儲的 API 很難達到 ms 級的流式延遲要求。另外一邊看,我們發(fā)現(xiàn)大企業(yè)的用戶一般都跑并行的任務,在使用 Delta Lake 去提供秒級的服務延遲在大多數(shù)場景下也是能夠接受的。
第三,Delta Lake 目前不支持二級索引(只有數(shù)據(jù)對象級別的 min/max 統(tǒng)計),我們已經開始著手開發(fā)一個基于 Bloom filter 的 index 了。Delta 的 ACID 事務能力,允許我們以事務的方式更新這些索引。
Snowflake & Delta Lake 對比總結
Snowflake 擁有很純粹的 SaaS 服務體驗,開箱即用,用戶無需任何調優(yōu),具有非常大的易用性。Delta Lake 更像是數(shù)倉的底層基礎設施,但 Databricks 公司也提供了開箱即用的一整套方案,基于 Delta Lake,并包含 Delta Engine、機器學習、科學計算及可視化平臺等。
彈性和成本方面,兩者依賴云平臺,都提供了相應的能力。
數(shù)據(jù)開放性方面,Delta Lake 優(yōu)于 Snowflake。Delta Lake 采用了開放的 Apache Parquet 格式,因此不受計算引擎的綁定,可以輕易在數(shù)據(jù)集上構建機器學習、科學計算等應用。這也是 Databricks 在大力推動發(fā)展的方向。Snowflake 由于使用的是內部專有格式,在性能上可能有特殊的定制化提升,但接入外部計算引擎上就會存在難度。每個對接的計算引擎或框架都需要專門定制開發(fā)相應的 connector。
實時數(shù)據(jù)支持方面 Delta Lake 優(yōu)于 Snowflake,Delta Lake 提供了流式數(shù)據(jù)的寫入和讀取,提供的數(shù)據(jù)實時性為秒級。Snowflake 也提供了一個 Snowpipe 工具用以微批的形式寫入數(shù)據(jù),提供的數(shù)據(jù)實時性為分鐘級。
支持的平臺類型上,Delta Lake 更豐富。Snowflake 為云而生,并只支持各類云平臺。Delta Lake 不限定于云平臺,還可以支持 Hadoop 等大數(shù)據(jù)平臺,甚至你將數(shù)據(jù)部署在本地環(huán)境,Delta Lake 也能支持。
參考資料
[1]The Snow?ake Elastic Data Warehouse
[2]Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
[3]Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
[4]https://mp.weixin.qq.com/s/PgpTUs_B2Kg3T5klHEpFVw
[5]https://www.sohu.com/a/431026284_315839
[6]https://www.datagrom.com/data-science-machine-learning-ai-blog/snowflake-vs-databricks
大鯨,網(wǎng)易數(shù)帆有數(shù)實時數(shù)倉開發(fā)工程師,曾從事搜索系統(tǒng)、實時計算平臺等相關工作。
