
數(shù)倉建模方法論
性能:能夠快速查詢所需的數(shù)據(jù),減少數(shù)據(jù)I/O的吞吐。
成本:減少不必要的數(shù)據(jù)冗余,實現(xiàn)計算結果的復用,降低大數(shù)據(jù)系統(tǒng)中的存儲成本和計算成本。
效率:改善用使用數(shù)據(jù)的體驗,提高使用效率。
質(zhì)量:改善數(shù)據(jù)統(tǒng)計口徑的不一致性,減少數(shù)據(jù)計算錯誤的可能性,提供高質(zhì)量的、一致的數(shù)據(jù)訪問平臺。
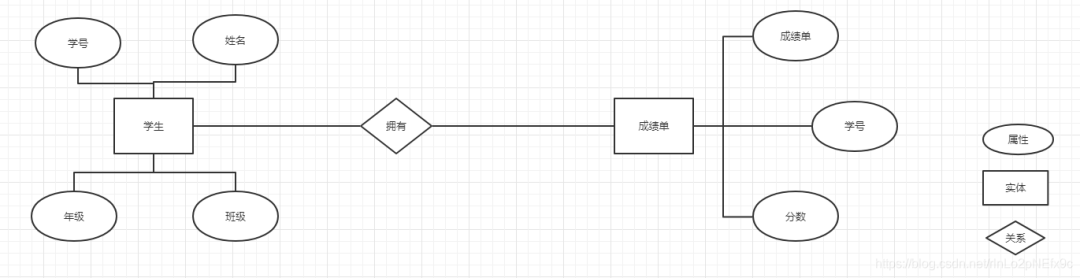
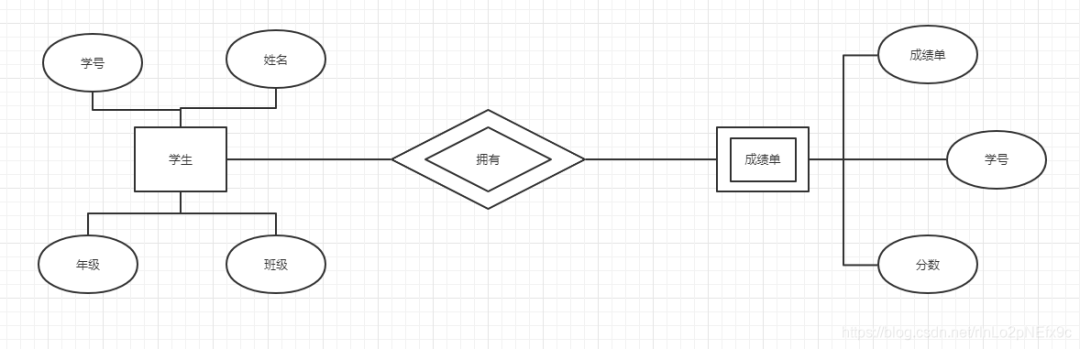


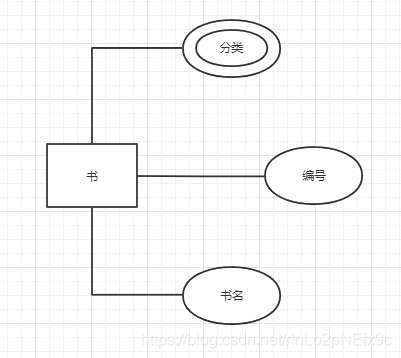
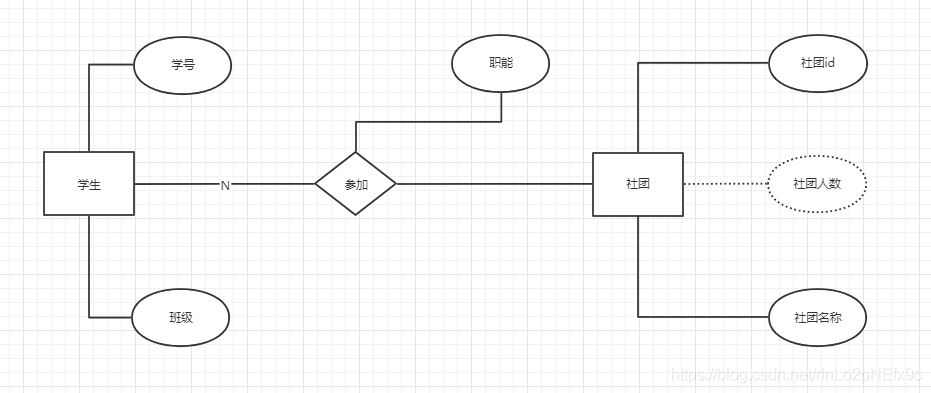
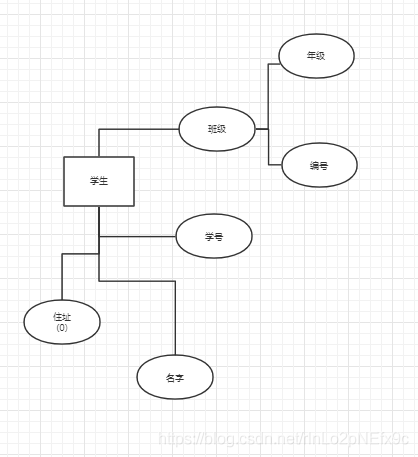

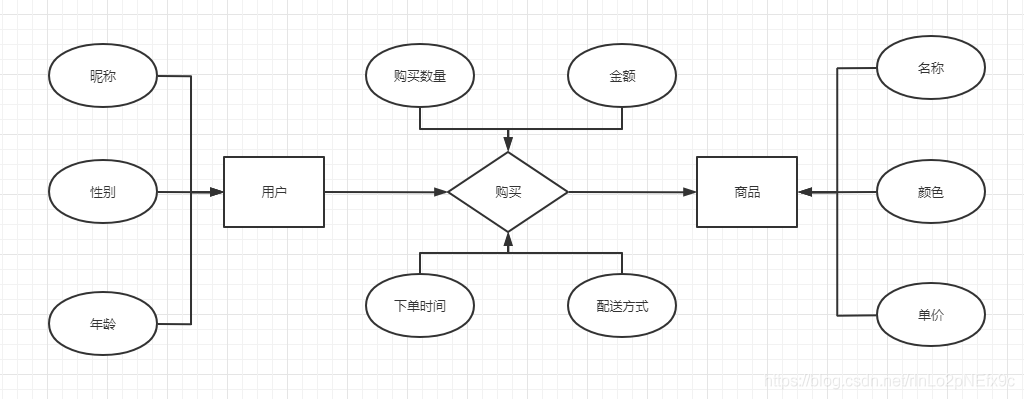


事實表的設計是以能夠正確記錄歷史信息為準則。
維度表的設計是以能夠以適合的角度來聚合主題內(nèi)容為準則。
維表只和事實表關聯(lián),維表之間沒有關聯(lián); 每個維表主鍵為單例,且該主鍵放置在事實表中,作為兩邊連接的外鍵; 以事實表為核心,維度表圍繞核心呈星型分布;
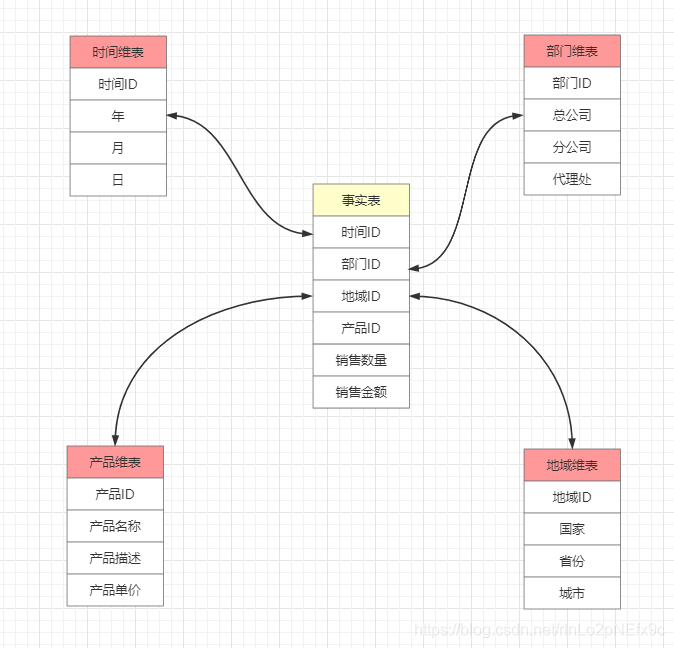

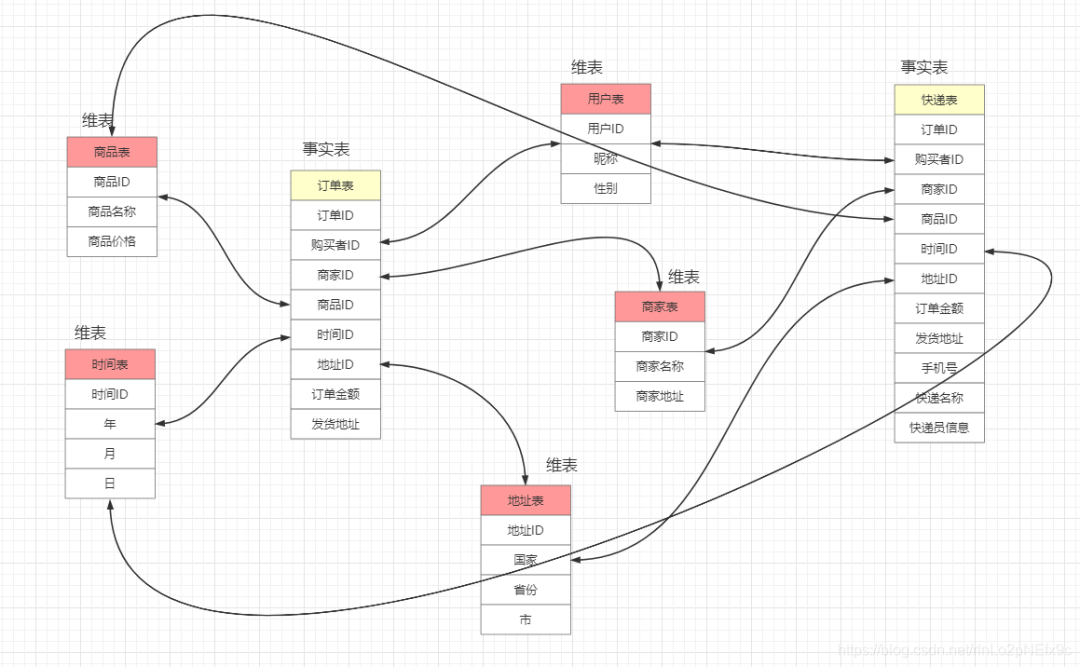
第一個也是最簡單的方法是重寫現(xiàn)有的記錄而不跟蹤變動。幸運的是,這個方法被許多維度所接受。例如,如果一個部門名稱從“財務”變?yōu)椤柏攧蘸蜁嫛保愫芸赡懿⒉恍枰涗涍@種歷史變化。但是,從客戶和學生的角度看,常常有必要保持跟蹤姓名、婚姻狀態(tài)、教育程度和其它屬性的變化——你的應用必要能夠獲得當前的以及歷史的數(shù)值。拉鏈表最常用。
管理維度慢慢改變的第二個方法是數(shù)值發(fā)生變化時創(chuàng)建一個新的記錄,并將舊的記錄標記為舊記錄。
第三個也是最后的一個方法是維護在維表的同一行中不同列的變化域的歷史數(shù)值。
與源系統(tǒng)完成獨立。 所有數(shù)據(jù)基于時間戳,即便數(shù)據(jù)質(zhì)量很低,也不能清洗掉數(shù)據(jù)。 可以適應源數(shù)據(jù)的各種變化,并可以靈活的實現(xiàn)模型擴展。 數(shù)據(jù)的來源可以完全追蹤,并且數(shù)據(jù)處理作業(yè)可以支持重載。


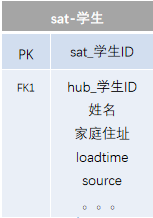


我們看一下Anchor模型的組成。
1.Anchors:類型于Data Vault的Hub,代表業(yè)務實體,且只有主鍵。
2.Attributes:功能類型于Data Vault的Satellite,但是它更加規(guī)范化,將其全部k-v結構化,一個表只有一個Anchors的屬性描述。
3.Ties:就是Anchors之間的關系,單獨用表來描述,類似于Data Vault的Link,可以提升整體模型關系的擴展能力。
4.Knots:代表那些可能會在多個Anchors中公用的屬性的提煉,比如性別、狀態(tài)等這種枚舉類型且被公用的屬性。
評論
圖片
表情